目录
为什么选择 Milvus?
Milvus 的工作原理是什么?
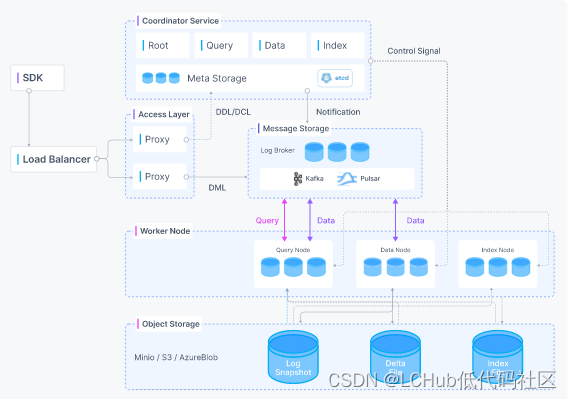
Milvus 由存储层和计算层组成,为了增强弹性和灵活性,Milvus 中的所有组件都是无状态的。系统由四个层级组成:
Milvus 用于什么?
如今,已有数百种 Milvus 应用案例常用于构建基于相似性搜索的应用程序。任何依赖或处理非结构化数据的公司都可以获得多种。
Milvus 是一个高度灵活、可靠和极速的云原生开源向量数据库。它支持嵌入向量的相似性搜索和人工智能应用程序,并致力于让向量数据库对每个组织都可用。Milvus 可以存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的十亿级嵌入向量。

Milvus 在2019年创建,用于存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。Zilliz 将 Milvus 贡献给 LF AI & Data Foundation 作为孵化阶段项目,并于2021年6月毕业。现在,开源的 Milvus 是业界领先的向量数据库解决方案。
建立在强大且不断增长的社区基础上。
- 20000+GitHub 星标
- 2,512+Slack 社区
- 3,408,603+下载次数
- 242+贡献者
为什么选择 Milvus?
构建相似性搜索的原型很简单,但在生产环境中却很困难。嵌入向量作为高度复杂的多坐标数值,不适合传统的表格数据结构。一些开发者使用向量库将嵌入向量存储在内存索引中以执行相似性搜索。
然而,更新索引并非易事,需要向量数据库中固有的向量工作流工具。而且,当解决规模需求时,构建托管向量的解决方案很快就会变得昂贵。
Milvus 是一个云原生的开源向量数据库,用于支持嵌入向量的相似性搜索和人工智能应用程序。
易于使用使用 Milvus 向量数据库,您可以在不到一分钟的时间内创建一个大规模的相似性搜索服务。同时提供简单直观的 SDK,支持多种不同的编程语言。
极速Milvus 具有高效利用硬件资源的能力,并提供先进的索引算法,使检索速度提升 10 倍。
高可用性Milvus 向量数据库已经经过数千个企业用户在各种用例中的验证。通过对各个系统组件的深度隔离,Milvus 具有极高的韧性和可靠性。
高可扩展性Milvus 具备分布式和高吞吐量的特性,使其非常适合处理大规模的向量数据。
云原生Milvus 向量数据库采用系统化的云原生方法,将计算与存储分离,允许您进行横向和纵向扩展。
功能丰富支持各种数据类型,提供增强的向量搜索和属性过滤功能,支持自定义函数(UDF),可配置的一致性级别、时间旅行等等。
Milvus 的工作原理是什么?
Milvus 由存储层和计算层组成,为了增强弹性和灵活性,Milvus 中的所有组件都是无状态的。系统由四个层级组成:
访问层访问层由一组无状态的代理组成,作为系统的前端层和用户的端点。
协调服务协调服务将任务分配给工作节点,充当系统的大脑。
工作节点工作节点作为执行器,按照协调服务的指令执行用户触发的 DML/DDL 命令。
存储存储是系统的支柱,负责数据持久化。它包括元数据存储、日志代理和对象存储。
Milvus 用于什么?
如今,已有数百种 Milvus 应用案例常用于构建基于相似性搜索的应用程序。任何依赖或处理非结构化数据的公司都可以获得多种。
语义文本搜索处理和查询跨多个向量的文本,如意图、位置和先前的搜索历史,可以为更准确、更细致的结果提供必要的上下文。
定向广告向量数据库可用于定向广告,以提高广告定位的相关性和效果。在这种情况下,数据库可以存储和索引与用户行为、人口统计信息和兴趣相关的大量数据,这些数据被映射到与用户相同的空间,使定向广告就像在 Milvus 中执行查询一样简单。

电子商务像 Milvus 这样的向量数据库可以通过结合多个非结构化数据源(如搜索历史和过去的购买记录)来支持产品推荐引擎。UGC 推荐用户生成的内容包括各种格式,从简单的文本(博客文章、新闻文章)到短视频和长视频。每个内容片段在向量数据库中都有一个单独的向量表示。这种向量表示使得推荐新内容就像在之前用户喜欢或参与过的内容上进行查询一样简单。
风险控制和反欺诈反欺诈系统还可以使用向量表示来编码操作和其他数据点之间的相似性。例如,反欺诈系统可以比较表示不同交易或行为的向量,以识别可能表示更高欺诈风险或其他非法活动的相似性。
新药发现在药物发现中,化合物的向量表示包括整体结构和生物学特性。向量数据库可以将此数据存储和索引为高维向量,只需进行查询即可实现新药发现。