背景
对于一个互联网平台,特别是 toB 的 PaaS/SaaS 平台,热点 key 是一个绕不过去的问题。作为一个开放的系统,平台每天要承载来自大量的外部系统或者海量终端的请求,虽然所有的请求都需要满足开放平台定义好的鉴权规则,但是突发的请求或者异常的请求,却总是不期而至。
对于 toB 系统来说,这样的请求至少包括以下几种类型:
-
客户错误使用姿势导致的异常流量
PaaS 平台往往以 API 和 SDK 的方式对外提供服务,虽然我们会提供各种demo和解决方案来指导客户以更优雅的方式使用我们的服务,但是你永远无法预测某个客户以一种你预想不到的方式调用我们的 API。
-
来自未知攻击者的流量
以云信为例,我们的服务器常年受到各种四层、七层攻击。四层流量一般不会直接到后台服务器,但是对于七层流量就除了通用的 waf 防护之外,也需要在业务层能及时发现和定位来源。
-
客户压测
没错,客户经常会在没有事先通知的情况给我们一个大惊喜,为了保护我们的系统不被突如其来的流量打垮,我们必须快速识别这样的流量并作出合适的反馈。
-
客户的客户,错误使用姿势导致的异常流量
对于 toB 产品,平台直接面对的往往是开发者或者说企业,客户的客户除了 C 端客户之外,也可能是其他企业,这种复杂的关系导致不确定性大大增加。
-
客户被攻击产生的到平台的异常流量
我们也不时收到来自客户的请求,反馈他们被黑产刷了,希望我们帮忙提供解决方案,这些黑产往往使用各种工具,也往往伴随着大流量,PaaS/SaaS 厂商属于躺枪的角色。
为了应对上述各种突发和异常流量带来的系统稳定性风险,开放平台往往会针对租户级别设置一些接口的 QPS 限制(频控系统),从而保护系统。但是频控往往是在入口层(API)设置规则,并不能完整描述突发异常流量对系统产生压力的根本原因(比如某个 redis-key 或者某个数据库行),也就是说频控系统是面向外部视角的,而风险源却是面向内部资源的,从风险点本身看,频控系统的逻辑有时候显得有一些粗放。此外,由于各种各样的原因,频控配置的设置往往也不能覆盖完整,而且随着系统的不断演讲,相关参数也需要不断进行调整。
因此在频控系统之外,还需要一个热点探测平台,热点探测系统聚焦于产生系统稳定性风险的热点本身,从而可以精确的评估和发现风险点。
为什么要自研
我们调研了已有的热点探测的方案,比如京东的 hotkey(https://gitee.com/jd-platform-opensource/hotkey),搜狐的 hotCaffeine(https://github.com/sohutv/hotcaffeine),对内咨询了网易云音乐的 hotCaffiene 内部 fork 版本,在分析了功能特点和我们的需求后,基于以下几个原因,我们决定在参考上述方案的基础上进行自研。
-
上述开源方案均和 etcd 强绑定,etcd 在系统中扮演了配置中心和注册中心的角色,并且无法使用其他服务替代,我们期望复用已有的配置中心和注册中心,而不需要再单独维护一套 etcd 集群。
-
上述开源方案更多侧重于热 key 缓存,而非监控本身。
-
我们期望框架尽可能的精简,有最小的依赖。
-
我们希望以插件化的方式开放相关接口,从而可以更方便的对接到不同部门的内部系统中,以更方便的开发自定义业务逻辑
基于上述原因,我们决定自研 camellia-hot-key 这样的热 key 探测框架。
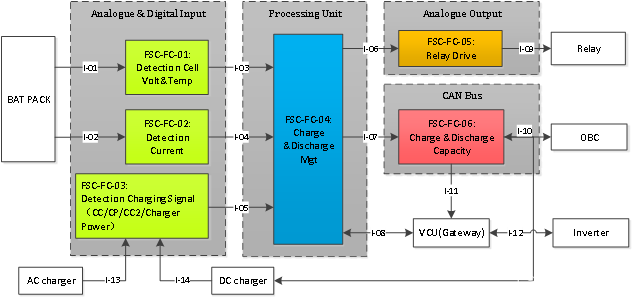
系统架构
架构图

架构原理
作为一个通用的热点探测平台,在设计时首先需要解决以下几个问题:
-
怎么收集和统计热点 key 的数量?
-
怎么定义和管理热点 key 的规则?
-
怎么使用热点 key 的探测结果?
怎么收集和统计热点key的数量?
由于热点 key 是一个全局维度的定义,因此必然需要一个中心化的服务器来汇总,第一反应就是使用 redis 之类的中心化缓存来作为一个集中的计数器管理工具。但是面对海量的 key,redis 却存在一些很显著的性能瓶颈,即使不考虑性能问题,产生的资源开销也是巨大的,因此我们需要设计一个低资源开销的方案。
当我们重新审视热 key 探测的场景可以发现,实际上我们并不需要实时,而仅需要准实时(百 ms 级别)即可满足绝大部分场景。因此通过本地缓存和批量处理,将可以极大的降低中心化服务器的压力,而且也能通过灵活的调整缓存时长和批量大小来满足不同业务的不同需求。而对于服务器本身,参考 redis-cluster 的 slot 分片的思路,我们可以将 hot-key-server 按照一定规则进行 hash 分片,从而保证相同的 key 路由到相同的 server 节点,从而把热 key 的计算完全本地化,配合前面说的本地缓存+批量处理,最终可以以较小的代价完成大量 key 的统计和计算。
除了中心化服务器之外,在收集和统计上还需要处理一个海量 key 的问题。显然我们不能粗暴的在一个时间窗口内记录下所有 key,一个简单的思路是使用 LRU/LFU 等算法来进行内存控制。为此,我们考察了【ConcurrentLinkedHashMap/Guava/Caffeine】等开源框架(这几个是同一个作者在不同时间实现的,对作者 @Ben Manes 表示敬意),Caffeine 号称进程缓存之王,其 W-TinyLFU 算法提供了最优缓存命中率,在热点探测场景下也能让我们不会错过热 key,因此 Caffeine 无疑是我们的第一选择。但再进一步分析后,我们最终选择了混用 ConcurrentLinkedHashMap 和 Caffeine,以达到最优的性能。
经过上面的分析,基本的服务器架构就比较清晰明了了,整个系统包括 SDK 和 server 两部分:SDK 使用 Caffeine 来收集 key,并定时上报给 server;server 收到后,依然使用 Caffeine 来进行收集和计算 key。而对于不同的 namespace,因为数量可预期,则使用 ConcurrentLinkedHashMap 来进行管理(仅需要简单的 lru 进行系统保护即可)。
怎么定义和管理热点 key 的规则?
热 key 探测显然是一个需要灵活变更热 key 规则的服务,热 key 规则主要包括 2 部分:
-
一个是什么 key 需要探测。
-
一个是什么样的 key 算热 key。
前者我们提供了前缀匹配、完全匹配、子串包含、匹配所有等不同的 key 规则匹配模式,方便业务进行不同维度的配置,并且提供规则列表的概念,按照定义的优先级进行匹配。
对于后者,我们开放了时间窗口、热 key 阈值两个参数来定义热 key。时间窗口是一个滑动的窗口,以 1000ms 内 500 次这样的规则为例,框架内部会以 100ms 为一个滑动小窗口,取最近 10 个小窗口(100ms*10=1000ms)组成一个 1000ms 的目标窗口进行计数,这种方式一方面可以第一时间识别出热 key,另一方面对于热 key 的探测也不会存在跳跃的问题。
对于热 key 规则的使用,除了在 server 端之外,框架也会下发给 SDK,从而对于不需要的 key,可以直接在 SDK 侧丢弃,从而减少不必要的网络传输。
作为一个通用的热 key 探测服务,显然会服务于不同的业务线,即使是同一个业务线,也会有不同的业务场景。因此对于热 key 规则之外,我们定义了 namespace 的概念,每个 namespace 下可以定义 1 个或者多个规则,一个服务支持同时配置多个 namespace,各个 namespace 之间互相隔离。
怎么使用热点 key 的探测结果?
首先,框架内我们预设了一个可选的 hot-key-cache 方式,这是 SDK+server 共同完成的。针对一些热点查询场景,在检测到热 key 后,server 会自动把检测结果下发给 SDK,SDK 会自动把结果缓存起来,从而避免查询请求的穿透,保护后端的缓存/数据库服务,并且为了保证缓存的时效性,server 还会把缓存结果的更新/删除事件通知给关联的 SDK 端,从而尽可能的保证缓存值在第一时间获得更新,SDK 也会把缓存命中情况上报给 server,方便服务器进行数据统计。
除此之外,server 会主动把探测结果推送给业务定义好的回调中,业务可以自行进行自定义的处理,如报警、限流、加黑等。
在接入初期,你可能并不知道如何设定热 key 规则,设置的小了,可能会被热 key 通知给淹没,设置的大了又可能发挥不了效果,因此 server 还内置了一个热 key 的 topN 探测功能,把 namespace 下访问请求最多的 key 告知业务,业务可以据此进行故障定位,或者以此为依据设置符合业务实际的热 key 规则。
插件化和自定义扩展口
前面讲了热 key 探测框架的基本原理,而 camellia-hot-key 在设计之初就考虑到了不同业务线的不同需求,因此采用了插件化的设计原则,方便业务在不修改框架源码的前提下,可以更灵活的使用,也能更容易的和已有系统进行打通。插件化主要体现在以下几点:
-
注册中心
不同于已有的开源热 key 服务,camellia-hot-key 不和任何注册中心进行绑定,你仅需实现相关接口,即可非常快速的和已有的注册中心进行整合,如 zk(内置)、eureka(内置)、etcd、consul、nacos 等。
-
配置中心
camellia-hot-key 不和任何配置中心进行绑定,而是定义了 HotKeyConfigService 配置接口,你仅需实现该接口,即可非常快的把热 key 规则托管到你已有的配置中心中(camellia-hot-key 内置了本地配置文件+nacos 两种方式)。
HotKeyConfigService 配置接口定义如下:
public abstract class HotKeyConfigService {
/**
* 获取HotKeyConfig
* @param namespace namespace
* @return HotKeyConfig
*/
public abstract HotKeyConfig get(String namespace);
/**
* 初始化后会调用本方法,你可以重写本方法去获取到HotKeyServerProperties中的相关配置
* @param properties properties
*/
public void init(HotKeyServerProperties properties) {
}
//回调方法
protected final void invokeUpdate(String namespace) {
//xxxx
}
}
此外,在 camellia-hot-key 的设计中,配置中心仅需要和 server 进行交互,SDK 会通过 server 自动获取到配置(配置初始化+配置更新),而不需要和配置中心直连,从而尽可能的简化 SDK 的逻辑(让 SDK 更瘦)。
监控端点和自定义回调
camellia-hot-key 的 server 提供了 http 的监控端点(json 格式/promethus 格式),用于暴露服务器等基本信息(如 qps、堆积等)。
此外还提供了丰富的回调接口,包括但不限于:
-
HotKeyCallback
热 key 探测回调,会把热 key 通过本回调实时推送给业务侧,除了推送热 key 本身以及当前计数外,还会同时把热 key 命中的规则和热 key 的来源一起回调给业务。
-
HotKeyTopNCallback
热 key 的 topN 回调,这是一个全局维度的 topN 统计(会汇总多个 server 节点的数据),框架会定时回调给业务(默认 1 分钟)。
-
HotKeyCacheStatsCallback
在启用热 key 缓存功能的情况下,SDK 会定时上报热 key 缓存的命中情况,服务器会通过这个回调接口把统计数据回调给业务。
友好的 SDK 接口
为了适配不同的应用场景,框架对外提供了 CamelliaHotKeyMonitorSDK 和CamelliaHotKeyCacheSDK 两种不同的 SDK。
-
CamelliaHotKeyMonitorSDK
用于单纯的热 key 统计功能,探测结果的处理由业务自行完成,探测结果的处理可以在 SDK 侧进行,也可以在 server 侧进行。核心接口只有一个:
/**
* 推送一个key用于统计和检测热key
* @param namespace namespace
* @param key key
* @param count count
* @return Result 结果
*/
Result push(String namespace, String key, long count);-
CamelliaHotKeyCacheSDK
封装了热 key 缓存的功能,SDK 会自动把探测到的热 key 进行本地缓存,业务接入方仅需实现 ValueLoader 接口即可。核心接口包括以下三个:
/**
* 获取一个key的value
* 如果是热key,则会优先获取本地缓存中的内容,如果获取不到则会走loader穿透
* 如果不是热key,则通过loader获取到value后返回
*
* 如果key有更新了,hot-key-server会广播给所有sdk去更新本地缓存,从而保证缓存值的时效性
*
* 如果key没有更新,sdk也会在配置的expireMillis之前尝试刷新一下(单机只会穿透一次)
*
* @param namespace namespace
* @param key key
* @param loader value loader
* @return value
*/
<T> T getValue(String namespace, String key, ValueLoader<T> loader);
/**
* key的value被更新了,需要调用本方法给hot-key-server,进而广播给所有人
* @param namespace namespace
* @param key key
*/
void keyUpdate(String namespace, String key);
/**
* key的value被删除了,需要调用本方法给hot-key-server,进而广播给所有人
* @param namespace namespace
* @param key key
*/
void keyDelete(String namespace, String key);性能
对于 Camellia-hot-key,我们进行了大量的优化和调优,主要包括如下:
-
传输协议
SDK 和 server 使用长链接(基于 netty4)和服务器进行交互,并且摒弃了 json/文本等协议,转而使用了更加精简的二进制协议,从而优化了性能(为了尽可能减少外部依赖,没有使用 pb 等第三方序列化库)。
-
无锁化设计
SDK 到 server 有一层 hash,保证相同 key 被相同 server 处理。此外,server 在收到消息后,同样会根据 key 进行 hash 分流,从而相同 key 只会被一个线程处理,极大的简化了滑动窗口的设计,也避免了锁(全流程无锁化)。
-
JDK-17
我们使用 jdk8 和 jdk17 分别进行测试,发现相同吞吐量的情况下,jdk17 比 jdk8 有更低的 CPU 占用。
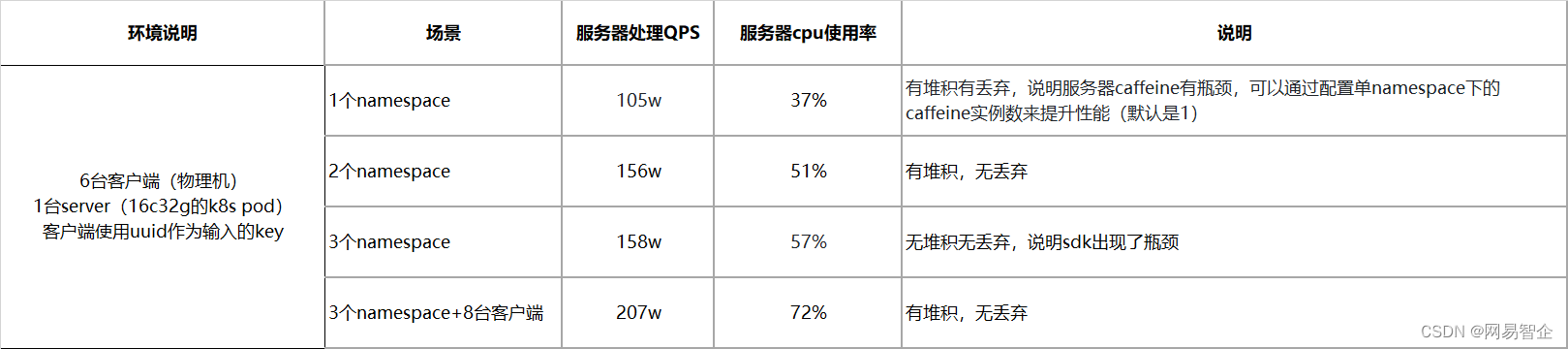
以下是一个简单的性能测试结果:
我们都怎么使用
作为一个通用的热 key 探测框架,智企内部多条业务线均接入了该框架,并且通过相关自定义接口无缝的接入到了已有的系统中,以 IM 为例,我们在以下业务流程中接入了热点探测服务:
-
对于来自 IM-SDK 的请求,根据 uid+租户 id+接口以及租户 id+接口做了两个维度的探测,从而识别异常的 C 端客户和异常的租户。
-
对于来自 IM-openAPI 的请求,根据租户 id+接口做了探测,从而识别异常的租户和异常接口。
-
底层数据库层面,以 db 为例。我们通过 mybatis 的 plugin 插件,做到了以业务不侵入的方式接入热点探测功能,探测的 key 我们采用如下方式进行拼装:type #租户 id#sql#param,这样做的好处,一方面可以在识出热点后,可以快速定位来源租户,另一方面也可以对 select/update/insert/delete 等不同 SQL 操作类型以及不同的租户设置不同的规则
-
缓存方面,以 redis 为例。除了 redis-key 本身之外,为了方便定位来源,还会把租户 id 拼装到探测 key 里面,特别的,对于 dao_cache,还集成了 CamelliaHotKeyCacheSDK,从而在必要的时候开启 cache 功能保护 redis。
上面讲的是输入,至于输出,基于框架提供的自定义接口,我们对接到了内部的监控报警系统,方便第一时间感知到热点;并且也会把数据实时写入到数据平台,方便后续进行追溯。未来还会对接到频控流控系统,从而可以在感知到异常流量后第一时间自动进行屏蔽。
总结
为什么要开源
在开发 camellia-hot-key 框架时,我们就将其作为开源项目 camellia 的一部分进行设计,在不夹杂业务逻辑的情况下,精简内核,从而方便大家可以在不修改源码的情况下直接对接到各自的系统中。
我们期望有更多的人使用,而不仅仅是被网易智企一家公司使用,我们期望能发挥他的最大功能和价值。
因此欢迎各位开源爱好者积极来找茬,大家一起对 camellia 进行不断的完善和改进,从而做到真正的共赢。
体验试用
camellia 是云信的一个开源项目,除了 hot-key 之外,还有 redis-proxy、id-gen、delay-queue 等诸多被生产环境充分验证的组件,欢迎大家一键三连:点赞(Star)、关注(PR)、评论(issue)!
github 地址:https://github.com/netease-im/camellia