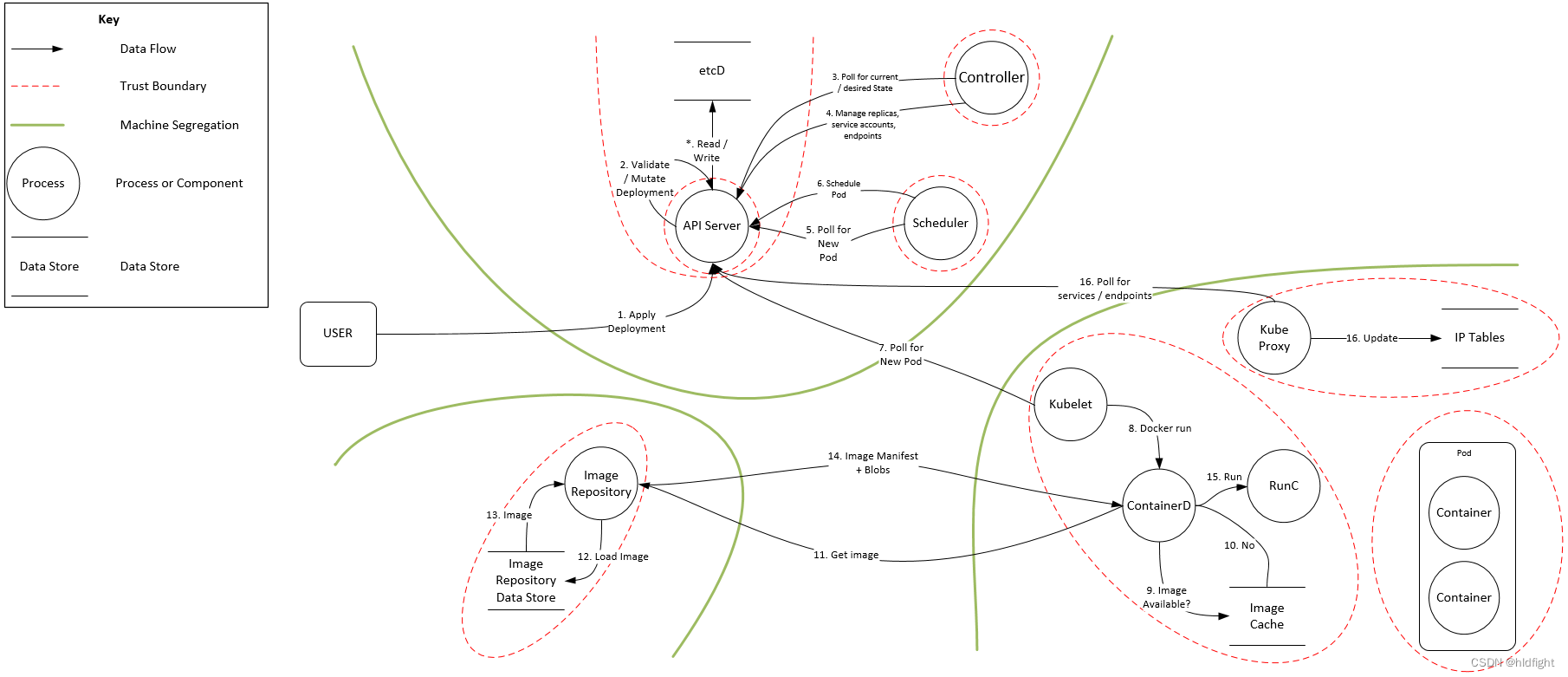
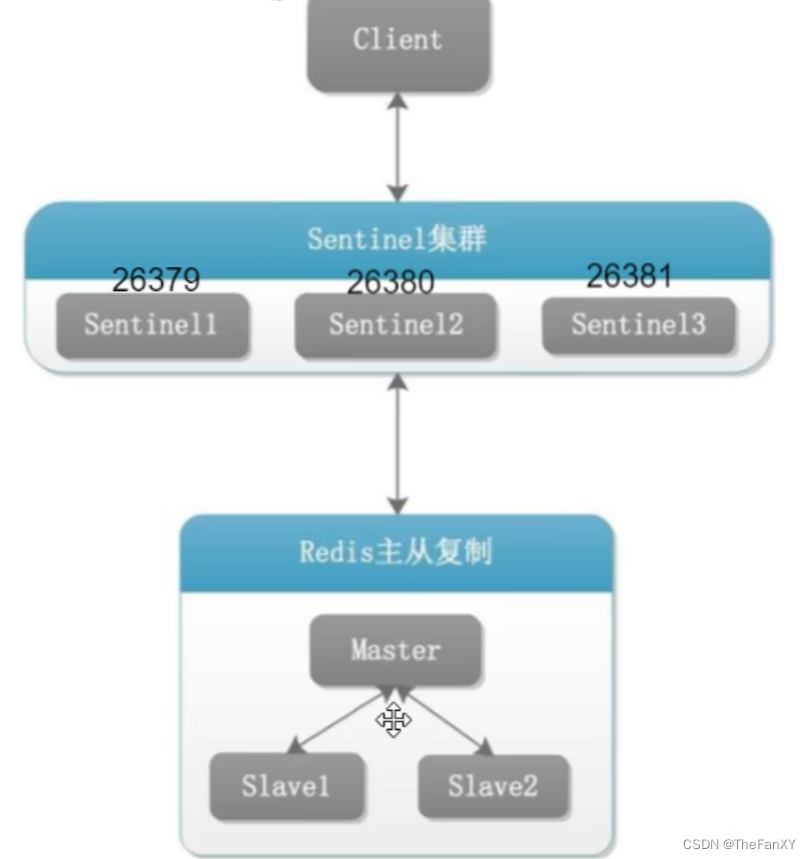
Redis哨兵
Redis Sentinel(哨兵)是 Redis 的高可用性解决方案之一,它可以用于监控和管理 Redis 主从复制集群,并在主节点发生故障时自动将从节点升级为新的主节点,从而保证系统的高可用性和可靠性。
Redis Sentinel 的主要功能如下:
- 监控 Redis 主节点和从节点的状态,包括节点的可用性、延迟等情况。
- 自动发现和识别 Redis 主从复制集群的拓扑结构。
- 在主节点发生故障时,自动将从节点升级为新的主节点,并将其他从节点重新连接到新的主节点。
- 支持 Redis 集群的自动故障转移、故障恢复和配置管理等功能。
- 提供监控和管理 Redis 集群的 API 和命令行工具。

1. 环境配置
(1)配置三个哨兵实例
三个哨兵实例需要三台虚拟机,考虑到机器性能有限,这里将三个哨兵实例配置到一台虚拟机上(这里配置到主节点的那台虚拟机),配置三份不同的哨兵配置文件即可:sentinel26379.conf、sentinel26380.conf、sentinel26381.conf,将它们存放到/myredis下。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ec26k4md-1687955266273)(img/2023-04-15_030538.png)]](https://img-blog.csdnimg.cn/7c86e0fa8fd04a1eb4d8f446c3ca7d1e.png)
(2)修改哨兵配置文件的内容
-
基础配置

- 关闭保护模式:
protected-mode no - 开启后台运行:
daemonize yes - 配置哨兵服务端口号:
port 26379(三个文件要不一样) - 日志文件路径:
logfile "/myredis/sentinel26379.log" - pid文件路径:
pidfile /var/run/redis-sentinel26379.pid - 工作目录:
dir /myredis
- 关闭保护模式:
-
主要配置
-
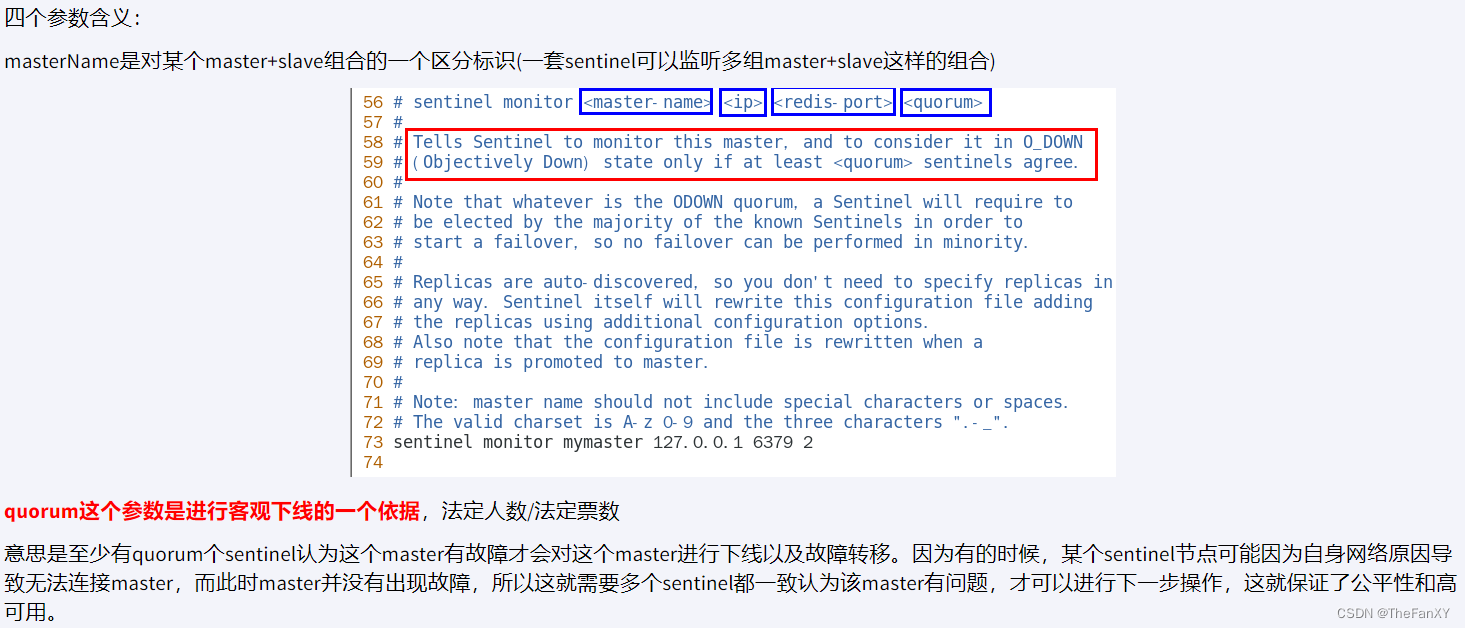
设置要监控的master:
master monitor <master-name> <ip> <redis-port> <quorum>master-name:给master取的名字。
quorum:同意故障迁移的法定票数。即表示有几个哨兵认可主观下线。达到一定票数后认定为客观下线(宕机、不可用)
-
配置连接master服务的密码:
sentinel-auth-pass <master-name> <password>
-
-
其他配置(使用默认即可,重点是主观下线)
-
sentinel down-after-milliseconds <master-name> <milliseconds>指定多少毫秒之后,主节点没有应答哨兵,此时哨兵主观上认为主节点下线 — 主观下线
-
sentinel parallel-syncs <master-name> <nums>表示允许并行同步的slave个数,当master挂了后,哨兵会选出新的master,剩余的slave会向新的master发起同步数据
-
sentinel failover-timeout <master-name> <milliseconds>故障转移的超时时间,进行故障转移时,如果超过设置的毫秒,表示故障转移失败,相当于选举成功,但是数据转移失败了
-
sentinel notification-script <master-name> <script-path>配置当某一事件发生时所需要执行的脚本
-
sentinel client-reconfig-script <master-name> <script-path>客户端重新配置主节点参数脚本
-
去除配置文件的注释,最终配置文件sentinel26379.conf的内容如下,sentinel26380.conf和sentinel26381.conf稍作修改即可
bind 0.0.0.0
daemonize yes
protected-mode no
port 26379
logfile "/myredis/sentinel26379.log"
pidfile /var/run/redis-sentinel26379.pid
dir /myredis
sentinel monitor mymaster 192.168.101.110 6379 2
sentinel auth-pass mymaster 123456
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aL2cW66P-1687955266274)(img/2023-04-15_035110.png)]](https://img-blog.csdnimg.cn/c8bd217ce4e84503a20995a7e8b5a856.png)
(3)配置主节点的访问密码
主节点宕机后,哨兵会选举一个从节点作为主节点,而之前的主节点会变成从节点,所以需要配置访问新主节点的密码。
这里所有节点都设置为同一密码,方便操作。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YYxVO1h5-1687955266275)(img/2023-04-15_040008.png)]](https://img-blog.csdnimg.cn/a93adcd55aed4b0c8eeac00032621445.png)
2. 实操演示
2.1 启动三个redis实例
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FaNL8fJL-1687955266275)(img/2023-04-15_041926.png)]](https://img-blog.csdnimg.cn/b0cb69d26bc446e4af68ee78e2460823.png)
2.2 启动三个哨兵实例
这里在redis(6379)那台机器上启动三个哨兵实例。
启动哨兵服务有两种方式:
- 使用redis-sentinel程序启动:
redis-sentinel sentinel.conf- 使用redis-server程序启动:
redis-server sentinel.conf --sentinel
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9xlzgWHZ-1687955266275)(img/2023-04-15_043016.png)]](https://img-blog.csdnimg.cn/1d600129a4974c72a47f2a052c9be1df.png)
lsof -i|grep redis 可以看到哨兵之间也是有通信的
2.3 测试主从复制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DdqMFZ0g-1687955266276)(img/2023-04-15_044818.png)]](https://img-blog.csdnimg.cn/20f61a55ec954eda94f907ee60b8fb19.png)
2.4 查看sentinel日志文件
工作中排查问题肯定是要去查日志文件,这里可以发现,每个哨兵都会在日志把主机和从机记录,也会把所有其他哨兵一并记录,日志中写明他们保存在 disk,也就是磁盘里,那么我们要去哪里找到他们呢?
其实这里是重写了conf的配置文件,把相应的关系和信息都写入配置文件里了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rLqEPtBC-1687955266276)(img/2023-04-15_045331.png)]](https://img-blog.csdnimg.cn/04ed39a53e2f42f0a3787512aebe5a82.png)
下面查看sentinel26379.log文件的主要内容:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gJdCbHD4-1687955266276)(img/2023-04-15_045716.png)]](https://img-blog.csdnimg.cn/674776a5fe43434e8e48220b44207cda.png)
了解 Broken pipe

新配置保存到磁盘的意思就是新配置信息写入到sentinel.conf文件中,下面查看sentinel26379.conf文件新增的内容:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NzSsauLI-1687955266277)(img/2023-04-15_065615.png)]](https://img-blog.csdnimg.cn/d0fef1376a8746af804e228b6b51c489.png)
2.5 模拟master节点宕机
关闭master节点后,哨兵会重新选举一个从节点作为新的主节点。
首先三个哨兵实例会投票选举一个哨兵实例作为领导者,然后由该哨兵实例来选举一个新的主节点并且进行故障迁移(failover)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cb3tik0Z-1687955266277)(img/2023-04-15_055113.png)]](https://img-blog.csdnimg.cn/371300f708514dcaa21a9cd850814476.png)
-
查看sentinel26379.log日志文件了解哨兵选举的过程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s13RKcNI-1687955266277)(img/2023-04-15_052907.png)]](https://img-blog.csdnimg.cn/fad49a1baab2486e95e1fa400b2b6694.png)
-
查看redis(6379)实例的redis.conf文件哨兵leader新增的内容:
redis(6379)实例由之前的主节点变成从节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dEbWv15C-1687955266278)(img/2023-04-15_062500.png)]](https://img-blog.csdnimg.cn/fb3c8fedbe714eb181a44b59de712719.png)
-
查看redis1(6380)实例的redis.conf文件哨兵leader修改的内容:
redis1(6380)实例由之前的从节点变成主节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m2edawX3-1687955266278)(img/image-20230415063454674.png)]](https://img-blog.csdnimg.cn/af7b4a9b98de4508aea16811b6699135.png)
-
查看redis2(6381)实例的redis.conf文件哨兵leader修改的内容:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4EKYRvr8-1687955266278)(img/2023-04-15_064629.png)]](https://img-blog.csdnimg.cn/1ff1ae9e2a3246a6b8275ea0d32edd60.png)
3. 哨兵选举的流程
-
哨兵检测到主节点不可用:当哨兵检测到主节点不可用时,会将主节点标记为下线状态(sdown),并向其他哨兵发送通知,通知其他哨兵主节点已经下线,其他哨兵也标记主节点下线后(odown),确定主节点不可用。
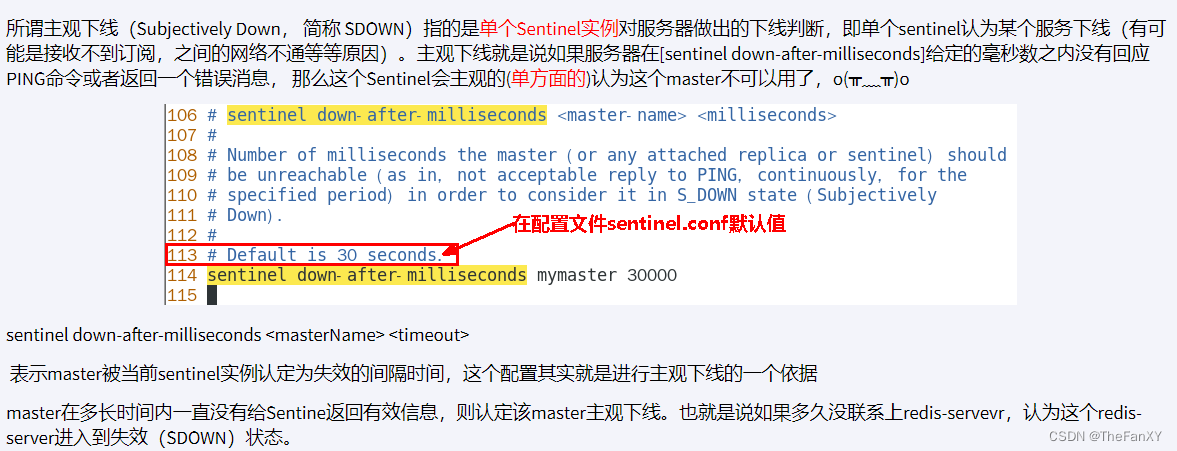
主观下线(sdown):指的是单个Sentinel实例对服务器做出的下线判断,即单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。主观下线就是说如果服务器在
sentinel down-after-milliseconds给定的毫秒数之内没有回应PING命令或者返回一个错误消息, 那么这个Sentinel会主观的(单方面的)认为这个master不可以用了。默认30秒。
客观下线(odown):客观下线需要多个哨兵达成一致意见才能认为主节点真正不可用。
quorum(票数)这个参数是进行客观下线的一个依据。法定人数/法定票数(quorum)。
-
哨兵投票选举哨兵leader:哨兵在检测到主节点不可用后,会进入选举状态,此时哨兵将开始选举哨兵的领导者。(哨兵中选出一个兵王)
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:
1要票,23没有投过,要票成功,2要票,只能要到1,3要票,要不到,都投过,应该是没人手里一张票,具体高级篇会细致讲解![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dDxMmiLj-1687955266278)(img/哨兵选举.png)]](https://img-blog.csdnimg.cn/032618f1724d4fe0bc16228bbdeb284b.png)
-
哨兵leader开始推动故障切换流程并选举出一个新的master
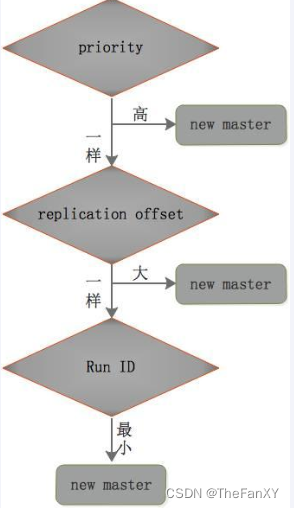
在从节点中选出新的master的规则:
①redis.conf中优先级slave-priority或replica-priority高的从节点优先(数值越小优先级越高)

②复制偏移量(offset)大的从节点优先。
③Run ID最小的从节点优先(按字典顺序、ASCII码值比较),每个redis实例启动后都会随机生成一个40位的run id。 -
选举出新的master后由Sentinel leader完成failover工作(故障切换)
- 执行slaveof no one命令让选出来的从节点成为新的主节点,并通过slaveof命令让其他节点(包括原来的master)成为新主节点的从节点。
- Sentinel leader会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里(写入配置文件)。
- 将之前已下线的老master设置为新选出的新master的从节点,当老master重新上线,它会成为新master的从节点,sentinel leader会让原来的master降级为slave并恢复正常工作。不用上线,就已经在log中写为slave,下次上线会对它重新配置。
4. 小总结
-
哨兵实例的数量应为多个,哨兵本身应该集群,保证高可用
-
哨兵实例的个数应该为奇数,方便投票选出Sentinel Leader
-
各个哨兵实例的配置应该一致
-
哨兵集群+主从复制,并不能保证数据零丢失(引出集群cluster,集群可以解决这一问题)
master宕机后,哨兵需要在一定时间内选出新的master并执行failover操作,这段时间内从节点无法写入数据,造成数据丢失。