这篇文章主要介绍了python中如何使用正则表达式提取数据问题。具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教。
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数可创建一个模式字符串和可选的标志参数组成的一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
| 模式 | 描述 |
|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | *匹配0次或多次。贪婪方式,re代表正则表达式 |
| re+ | +匹配1次或多次。 |
| re? | ?匹配0次或1次,非贪婪方式,匹配0次指表达式后面为空的也匹配 |
| re{ n} | 连续匹配 n 个前面表达式。例如, o{2},连续匹配两次o, 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 |
| re{ n,} | 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 |
| re{ n, m} | 表示匹配 连续的 前面的表达式 至少n次,至多 m 次。表达式 油{3,4} 就表示匹配 连续的 油 字 至少3次,至多 4 次 |
| a| b | 匹配a或b |
| (re) | 对正则表达式分组并记住匹配的文本 |
常用正则表达式实例
字符匹配
字符类
| 实例 | 描述 |
|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
特殊字符类
| 实例 | 描述 |
|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到第一个匹配。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | # re.match()函数只能从起始的位置匹配,否则返回None
import re
matchObj = re.match('www', 'www.runoob.com')
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
# (0, 3)
# None
# 使用group(num) 或 groups() 函数来获取用来匹配的正在表达式提取的值。
if matchObj:
print("matchObj.group() : ", matchObj.group())
# 执行结果是matchObj.group() : www
# matchObj.group() 等同于 matchObj.group(0),表示匹配到的完整文本字符
# print ("matchObj.group(1) : ", matchObj.group(1))
# print ("matchObj.group(2) : ", matchObj.group(2))
# re.search 扫描整个字符串并返回第一个成功的匹配。
import re
line = "Cats are smarter than dogs";
searchObj = re.search(r'(.*) are (.*?) ', line, re.M | re.I)
if searchObj:
print("searchObj.group() : ", searchObj.group())
print("searchObj.group(1) : ", searchObj.group(1))
print("searchObj.group(2) : ", searchObj.group(2))
# 执行结果
# searchObj.group() : Cats are smarter
# searchObj.group(1) : Cats
# searchObj.group(2) : smarter
# re.sub()用于替换字符串中的匹配项
import re
phone = "2004-959-559 # 这是一个国外电话号码"
# 删除字符串中的 Python注释,$匹配字符串的末尾。
# 把匹配到的字符串替换为空字符串
num = re.sub(r'#.*$', "", phone)
print("电话号码是: ", num)
# 电话号码是: 2004-959-559
# 删除非数字(-)的字符串,\D 匹配任意非数字
num = re.sub(r'\D', "", phone)
print("电话号码是 : ", num)
# 电话号码是 : 2004959559
"""
findall在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
"""
import re
pattern = re.compile(r'\d+') # 创建个正着表达式对象,查找数字
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)
result3 = pattern.search('runoob 123 google 456')
# 123 只匹配了一次,匹配首个符合要求的字符串
print(result1)
print(result2)
print(result3.group())
# 执行结果:
# ['123', '456']
# ['88', '12']
# 123
|
re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | import re
pattern = re.compile(r'\d+') # 用于匹配至少一个数字
m = pattern.match('one12twothree34four') # 查找头部,没有匹配
print(m)
# None
m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
print(m)
# None
m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
print(m) # 返回一个 Match 对象
# <re.Match object; span=(3, 5), match='12'>
print(m.group(0)) # 可省略 0,获得整个匹配的子串时,可直接使用 group() 或 group(0);
# '12'
print(m.start(0)) # 可省略 0,获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
# 3
print(m.end(0)) # 可省略 0,获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
5
print(m.span(0)) # 可省略 0,返回 (start(group), end(group))。
# (3, 5)
|
执行结果:
None
None
<re.Match object; span=(3, 5), match='12'>
12
3
5
(3, 5)
括号()-分组
括号称之为 正则表达式的 组选择。
组 就是把 正则表达式 匹配的内容 里面 其中的某些部分 标记为某个组。
我们可以在 正则表达式中 标记 多个 组
为什么要有组的概念呢?因为我们往往需要提取已经匹配的 内容里面的 某些部分的信息。
前面,我们有个例子,从下面的文本中,选择每行逗号前面的字符串,也 包括逗号本身 。
苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的
就可以这样写正则表达式 ^.*, 。
但是,如果我们要求 不要包括逗号 呢?
当然不能直接 这样写 ^.*
因为最后的逗号 是 特征 所在, 如果去掉它,就没法找 逗号前面的了。
但是把逗号放在正则表达式中,又会包含逗号。
解决问题的方法就是使用 组选择符 : 括号。
我们这样写 ^(.*), ,结果如下
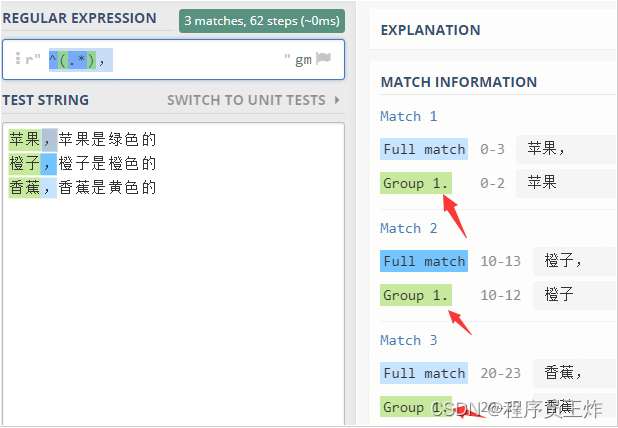
大家可以发现,我们把要从整个表达式中提取的部分放在括号中,这样 水果 的名字 就被单独的放在 组 group 中了。
对应的Python代码如下
| 1 2 3 4 5 6 7 8 | content = '''苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的'''
import re
p = re.compile(r'^(.*),', re.MULTILINE)
for one in p.findall(content):
print(one)
|
多个分组时,怎么取每个分组的值。
比如,我们要从下面的文本中,提取出每个人的 名字 和对应的 手机号
张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901
可以使用这样的正则表达式 ^(.+),.+(\d{11})
可以写出如下的代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | content = '''张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901'''
import re
p = re.compile(r'^(.+),.+(\d{11})', re.MULTILINE)
print(p.findall(content))
#findall()方法返回的是列表
m = p.search(content)
#列表不能调用group,因此需使用search()方法,但search方法只能匹配第一个符合的
print(m.group(1))
print(m.group(2))
for one in p.findall(content):
print(one)
print(type(one))
#执行结果
# [('张三', '15945678901'), ('李四', '13945677701'), ('王二', '13845666901')]
# 张三
# 15945678901
# ('张三', '15945678901')
# <class 'tuple'>
# ('李四', '13945677701')
# <class 'tuple'>
# ('王二', '13845666901')
# <class 'tuple'>
|
当有多个分组的时候,我们可以使用 (?P<分组名>...) 这样的格式,给每个分组命名。
这样做的好处是,更方便后续的代码提取每个分组里面的内容
比如
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import re
p = re.compile(r'^(?P<name>.+),.+(?P<phone>\d{11})', re.MULTILINE)
print(p.finditer(content))
# 返回string中所有与pattern相匹配的全部字串,返回形式为迭代器。
for match in p.finditer(content):
print(match.group('name'))
print(match.group('phone'))
# 执行结果
# <callable_iterator object at 0x00000000027C2518>
# 张三
# 15945678901
# 李四
# 13945677701
# 王二
# 13845666901
|
总结:正则若匹配成功,match()/search()返回的是Match对象,finditer()返回的是Match对象的迭代器,获取匹配结果需要调用Match对象的group()、groups或group(index)方法。
group():母串中与模式pattern匹配的子串;group(0):结果与group()一样;groups():所有group组成的一个元组,group(1)是字符串中第一个匹配成功的子串分组,group(2)是第二个,依次类推,如果index超了边界,抛出IndexError;findall():返回的就是所有匹配的子串数组,就是子串元组组成的列表,例如上面的例子,母串中的第一行组成一个元组,第二行组成一个元组,这些元组共同构成一个list,就是findall()的返回结果。
方括号-匹配几个字符之一
方括号表示要匹配 指定的几个字符之一 。
比如
[abc] 可以匹配 a, b, 或者 c 里面的任意一个字符。等价于 [a-c] 。
[a-c] 中间的 - 表示一个范围从a 到 c。
如果你想匹配所有的小写字母,可以使用 [a-z]
一些 元字符 在 方括号内 失去了魔法, 变得和普通字符一样了。
比如
[akm.] 匹配 a k m . 里面任意一个字符
这里 . 在括号里面不在表示 匹配任意字符了,而就是表示匹配 . 这个 字符
如果在方括号中使用 ^ , 表示 非 方括号里面的字符集合。
比如
| 1 2 3 4 5 6 | content = 'a1b2c3d4e5'
import re
p = re.compile(r'[^\d]' )
for one in p.findall(content):
print(one)
|
[^\d] 表示,选择非数字的字符
输出结果为:
a
b
c
d
e
切割字符串
字符串 对象的 split 方法只适用于 简单的字符串分割。 有时,你需要更加灵活的字符串切割。
比如,我们需要从下面字符串中提取武将的名字。
| 1 | names = '关羽; 张飞, 赵云,马超, 黄忠 李逵'
|
我们发现这些名字之间, 有的是分号隔开,有的是逗号隔开,有的是空格隔开, 而且分割符号周围还有不定数量的空格
这时,可以使用正则表达式里面的 split 方法:
| 1 2 3 4 5 6 | import re
names = '关羽; 张飞, 赵云, 马超, 黄忠 李逵'
namelist = re.split(r'[;,\s]\s*', names)
print(namelist)
|
正则表达式 [;,\s]\s* 指定了,分割符为 分号、逗号、空格 里面的任意一种均可,并且 该符号周围可以有不定数量的空格。
字符串替换
匹配模式替换
字符串 对象的 replace 方法只适应于 简单的 替换。 有时,你需要更加灵活的字符串替换。
比如,我们需要在下面这段文本中 所有的 链接中 找到所以 /avxxxxxx/ 这种 以 /av 开头,后面接一串数字, 这种模式的字符串。
然后,这些字符串全部 替换为 /cn345677/ 。
| 1 2 3 4 5 6 7 8 9 | names = '''
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
'''
|
被替换的内容不是固定的,所以没法用 字符串的replace方法。
这时,可以使用正则表达式里面的 sub 方法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import re
names = '''
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
'''
newStr = re.sub(r'/av\d+?/', '/cn345677/' , names)
print(newStr)
|
sub 方法就是也是替换 字符串, 但是被替换的内容 用 正则表达式来表示 符合特征的所有字符串。
比如,这里就是第一个参数 /av\d+?/ 这个正则表达式,表示以 /av 开头,后面是一串数字,再以 / 结尾的 这种特征的字符串 ,是需要被替换的。
第二个参数,这里 是 '/cn345677/' 这个字符串,表示用什么来替换。
第三个参数是 源字符串。
指定替换函数
刚才的例子中,我们用来替换的是一个固定的字符串 /cn345677/。
如果,我们要求,替换后的内容 的是原来的数字+6, 比如 /av66771949/ 替换为 /av66771955/ 。
怎么办?
这种更加复杂的替换,我们可以把 sub的第2个参数 指定为一个函数 ,该函数的返回值,就是用来替换的字符串。
如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | import re
names = '''
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
'''
# 替换函数,参数是 Match对象
def subFunc(match):
# Match对象 的 group(0) 返回的是整个匹配上的字符串
src = match.group(0)
# Match对象 的 group(1) 返回的是第一个group分组的内容
number = int(match.group(1)) + 6
dest = f'/av{number}/'
print(f'{src} 替换为 {dest}')
# 返回值就是最终替换的字符串
return dest
newStr = re.sub(r'/av(\d+?)/', subFunc , names)
print(newStr)
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # 正则表达式提取
import re
content = '''
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
'''
for one in re.findall(r'([\d.]+)万/每{0,1}月', content):
print(one)
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | #非正则表达式提取
content = '''
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
'''
# 将文本内容按行分割,放入列表,按\r\n,\r(回车),\n(换行)分割
lines = content.splitlines()
# print(lines)
for line in lines:
# 查找'万/月' 在 字符串中什么地方
# find() 方法检测字符串中是否包含子字符串 str ,如果包含的话,返回子字符串开始的索引,
# 不包含的话返回-1
pos2 = line.find('万/月')
# print(pos2)
if pos2 < 0:
# 查找'万/每月' 在 字符串中什么地方
pos2 = line.find('万/每月')
# 都找不到,满足条件,触发continue,不执行后面的代码,跳到循环开头进入下一轮循环
if pos2 < 0:
continue
# 执行到这里,说明可以找到薪资关键字
# 接下来分析 薪资 数字的起始位置
# 方法是 找到 pos2 前面薪资数字开始的位置
idx = pos2 - 1
# 只要是数字或者小数点,就继续往前面找
# isdigit()方法检测字符串是否只由数字组成,如果字符串只包含数字则返回 True 否则返回 False
while line[idx].isdigit() or line[idx] == '.':
idx -= 1
# 现在 idx 指向 薪资数字前面的那个字,
# 所以薪资开始的 索引 就是 idx+1
pos1 = idx + 1
print(line[pos1:pos2])
|
总结
以上为个人经验,希望能给大家一个参考。
点击拿去
50G+学习视频教程
100+Python初阶、中阶、高阶电子书籍



![[ JVM ] 常用参数 优化参考](https://img-blog.csdnimg.cn/f4273bc357724815b1db8fb8d8a513dd.png)

![[rocketmq] 浅谈结构](https://img-blog.csdnimg.cn/ed046cb63e844b5ca196e2b0f513e977.png)