目录
- 1. 训练
- 1.1 Uniform({1,...,T})
- 1.2 ϵ ∼ N ( 0 , I ) \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) ϵ∼N(0,I)
- 1.3 加噪
- 1.4 加噪图片送入UNet预测加入的噪声
- 1.5 预测的噪声和加入的噪声进行损失计算
- 2. 采样
- 3. 推理
本次训练采用的是cifar数据集,代码和下载好的数据将打包上传在百度网盘。
1. 训练

1.1 Uniform({1,…,T})
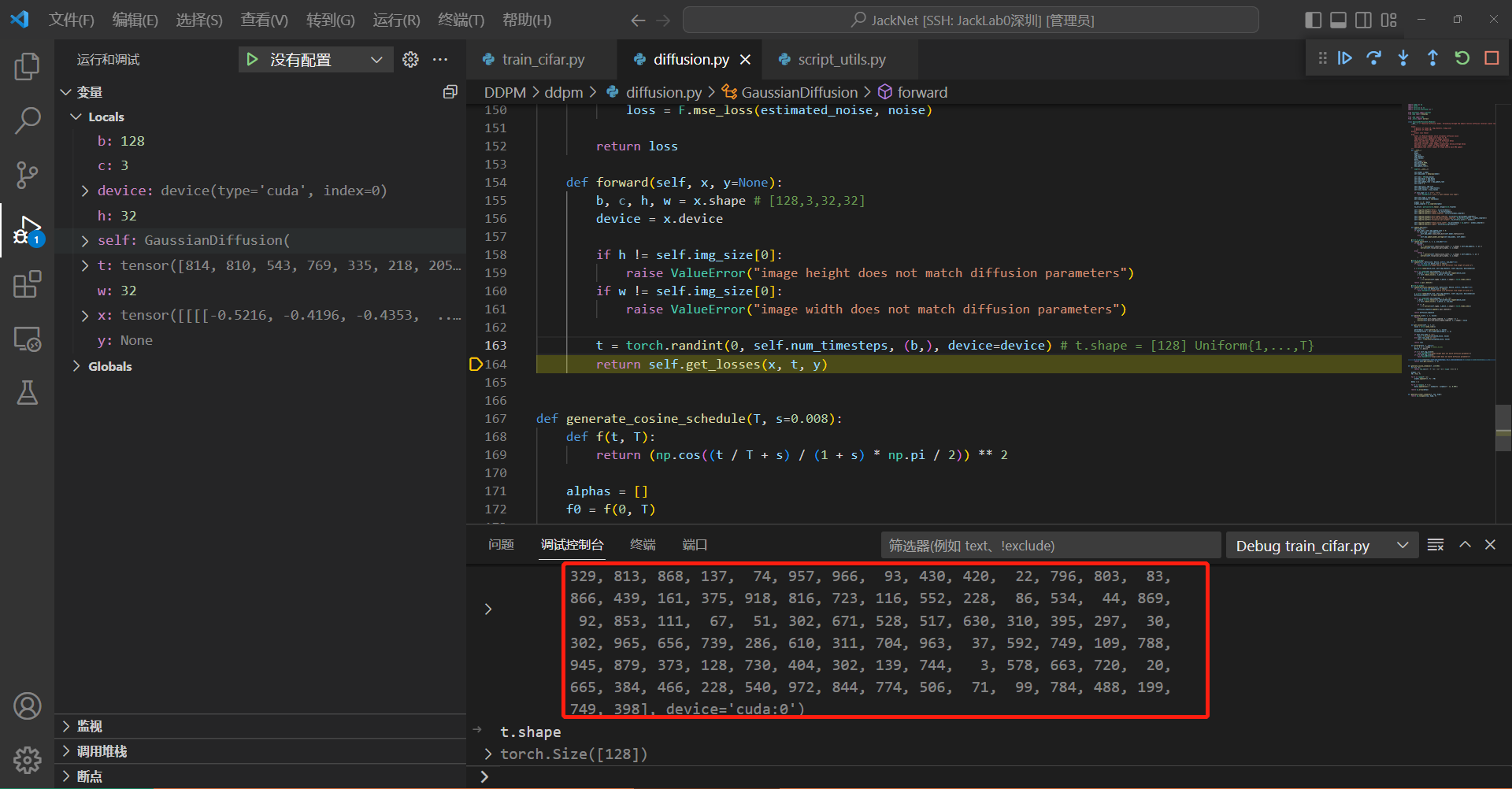
训练过程, t是随机采样获得的, 这一步是核心之一, 相当于伪代码中的 Step3: t ∼ Uniform ( { 1 , … , T } ) t \sim \operatorname{Uniform}(\{1, \ldots, T\}) t∼Uniform({1,…,T})
1.2 ϵ ∼ N ( 0 , I ) \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) ϵ∼N(0,I)
代码142行:生成均值为1,方差为0的标准高斯分布噪声
注意一个细节,t的维度是128,表示一个batchsize一起进行加噪
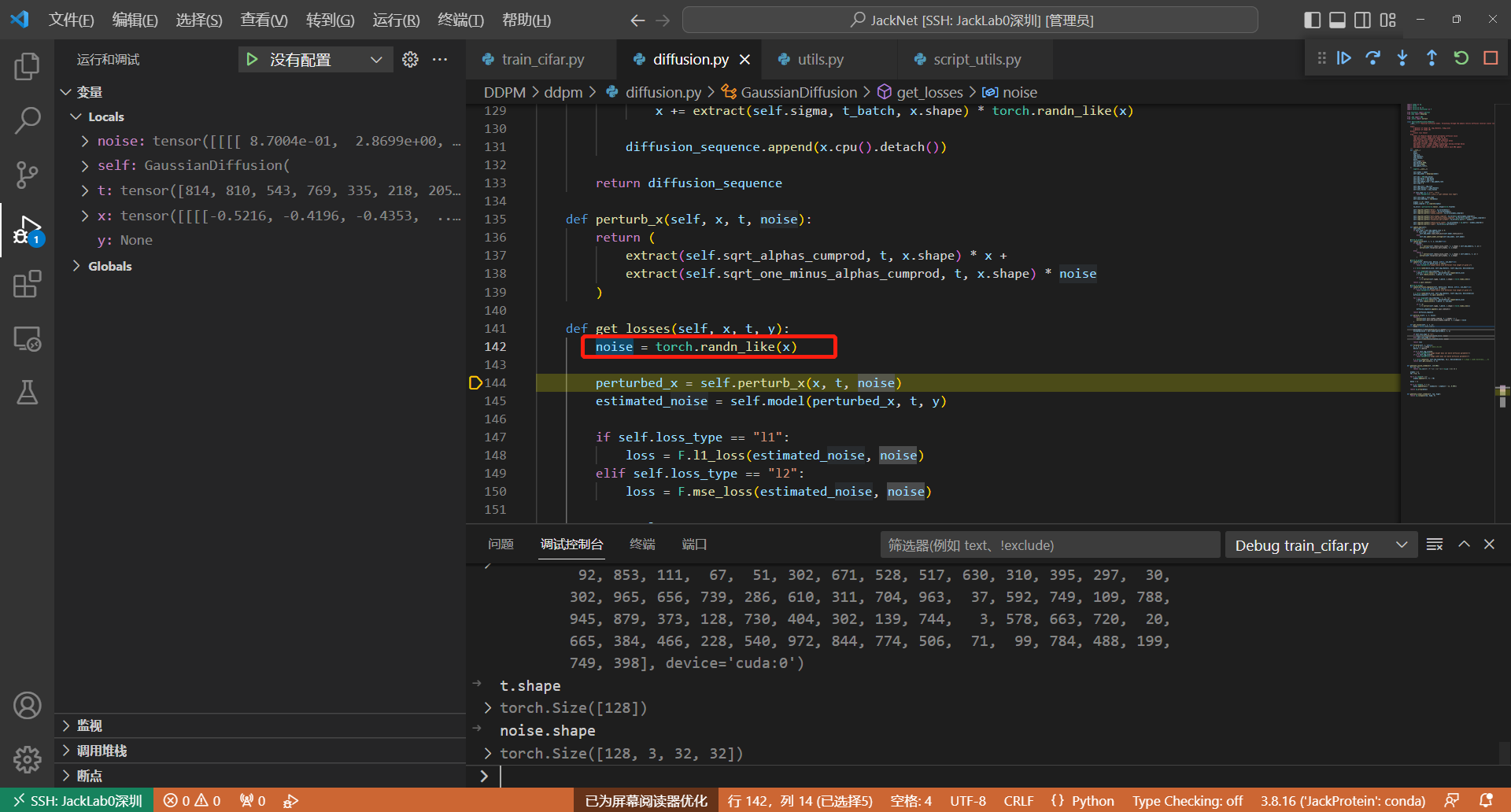
1.3 加噪
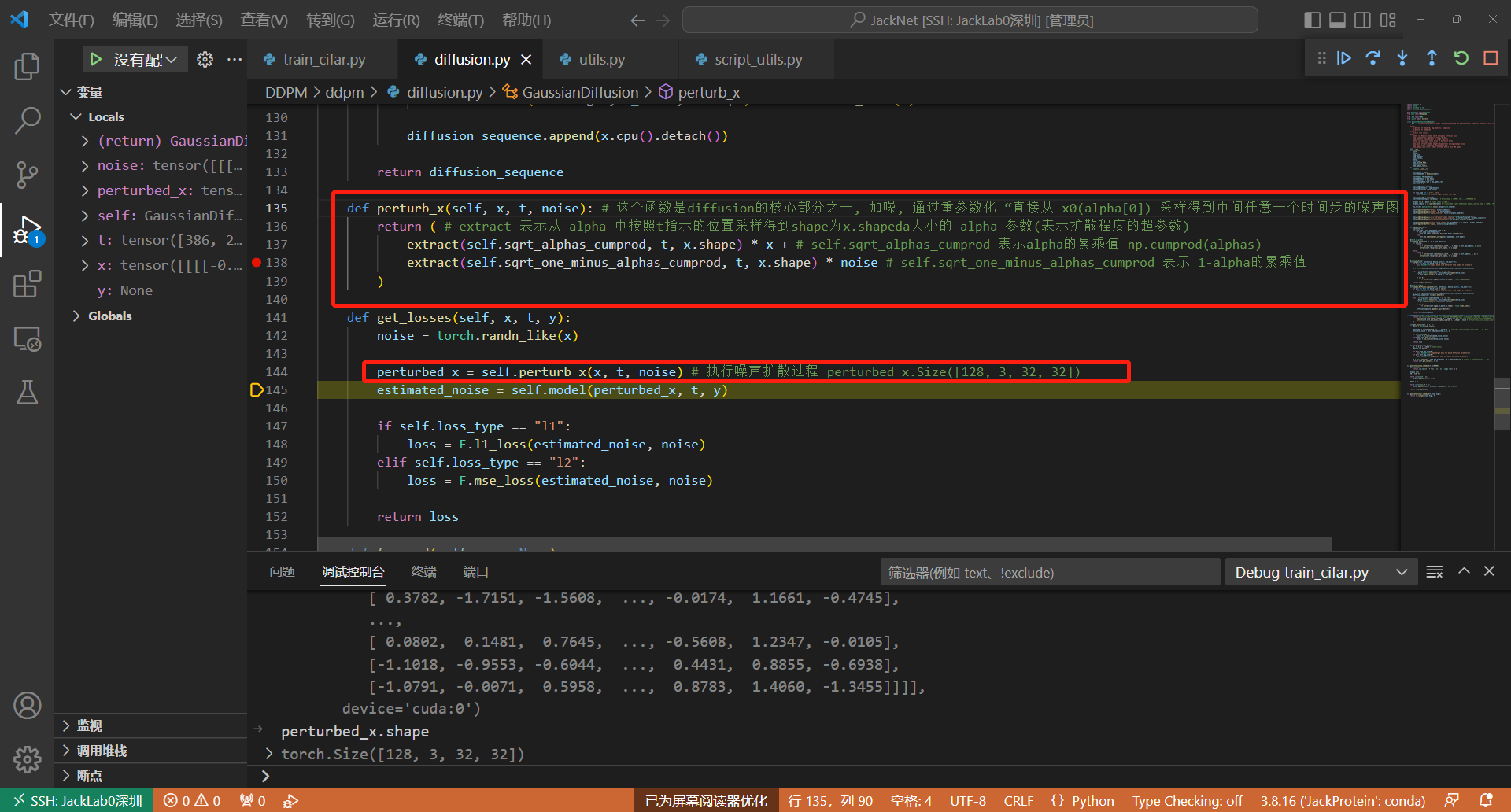
主要的函数代码在144行,这里将随机采样的加噪时间t,生成的noise和一个bath的image一起放入perturb函数中。
这里的加噪公式对应论文中的: q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q\left(\mathbf{x}_{t} \mid \mathbf{x}_{0}\right)=\mathcal{N}\left(\mathbf{x}_{t} ; \sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0},\left(1-\bar{\alpha}_{t}\right) \mathbf{I}\right) q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
采用重参数化技巧后得到如下伪代码表示:
betas = torch.linspace(start=0.0001, end=0.02, steps=1000)
alphas = 1 - betas
# cumprod 相当于为每个时间步 t 计算一个数组 alphas 的前缀乘结果
# https://pytorch.org/docs/stable/generated/torch.cumprod.html
alphas_cum = torch.cumprod(alphas, 0)
alphas_cum_s = torch.sqrt(alphas_cum)
alphas_cum_sm = torch.sqrt(1 - alphas_cum)
# 应用重参数化技巧采样得到 xt
noise = torch.randn_like(x_0)
xt = alphas_cum_s[t] * x_0 + alphas_cum_sm[t] * noise
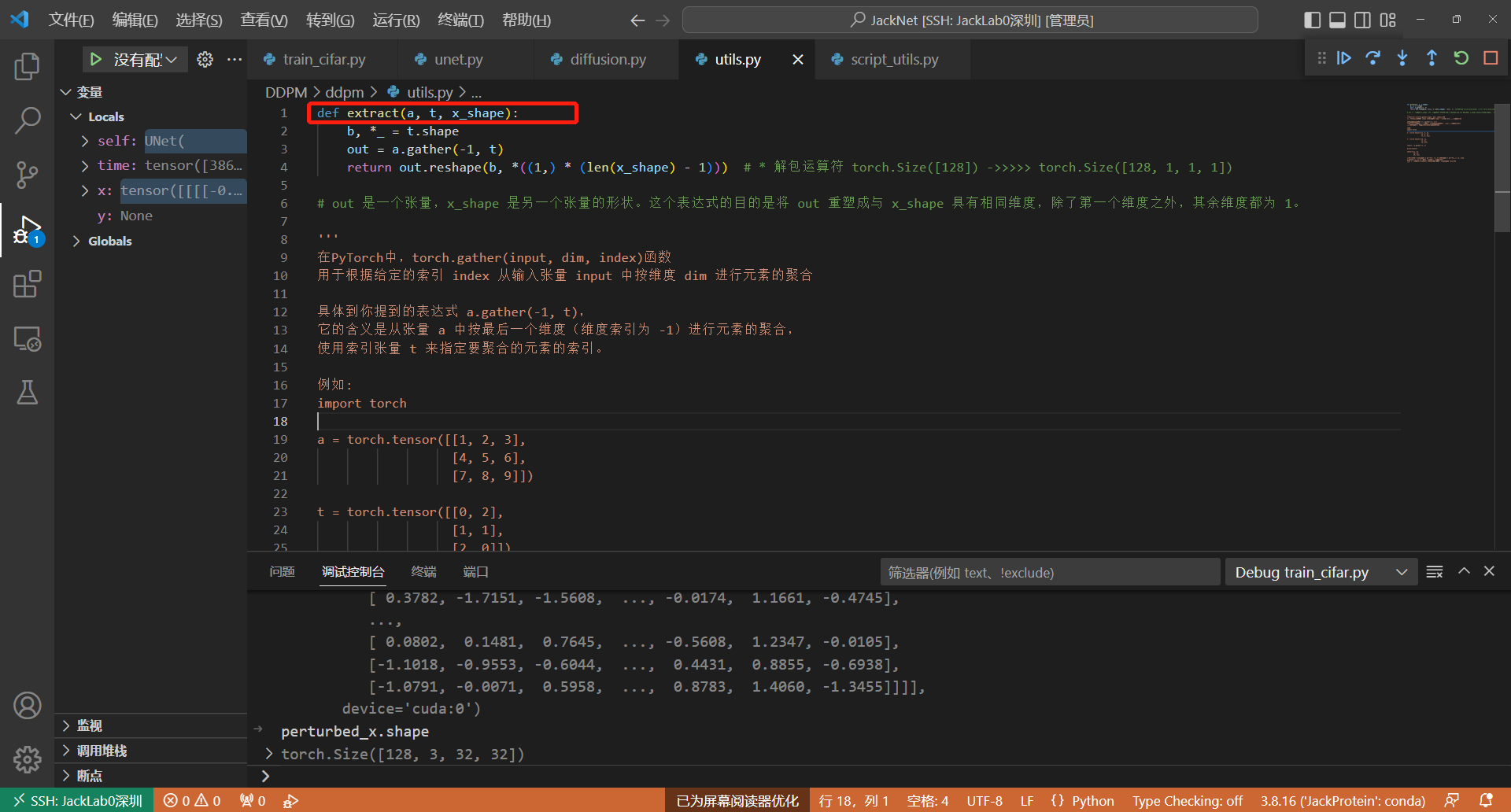
以下为 extract 函数的具体代码:
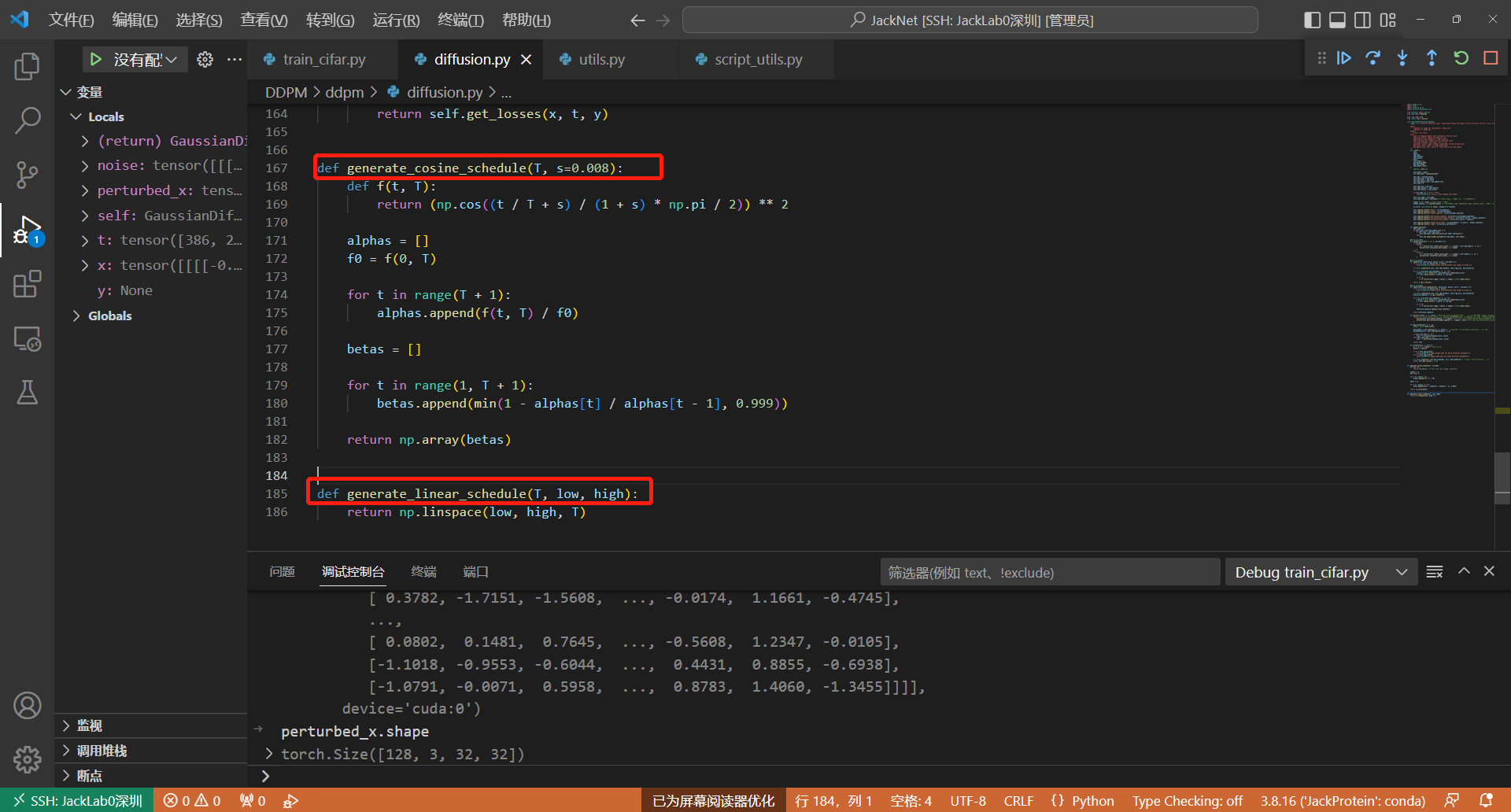
注意:这里的alpha和beta参数是为了控制扩散程度,即改变高斯噪声的均值和方差,他们是一次性生成的,原始DDPM论文是设置 T=1000, β1=0.0001, βT=0.02,代码中对应如下代码:**Line167&185 ** 这里设置了两种超参数的生成方式
这里也可以参考博客 一文弄懂 Diffusion Model DDPM架构图解
1.4 加噪图片送入UNet预测加入的噪声
这部分的代码核心是时间信息如何加入到UNet中,可以参考代码Lin357&369
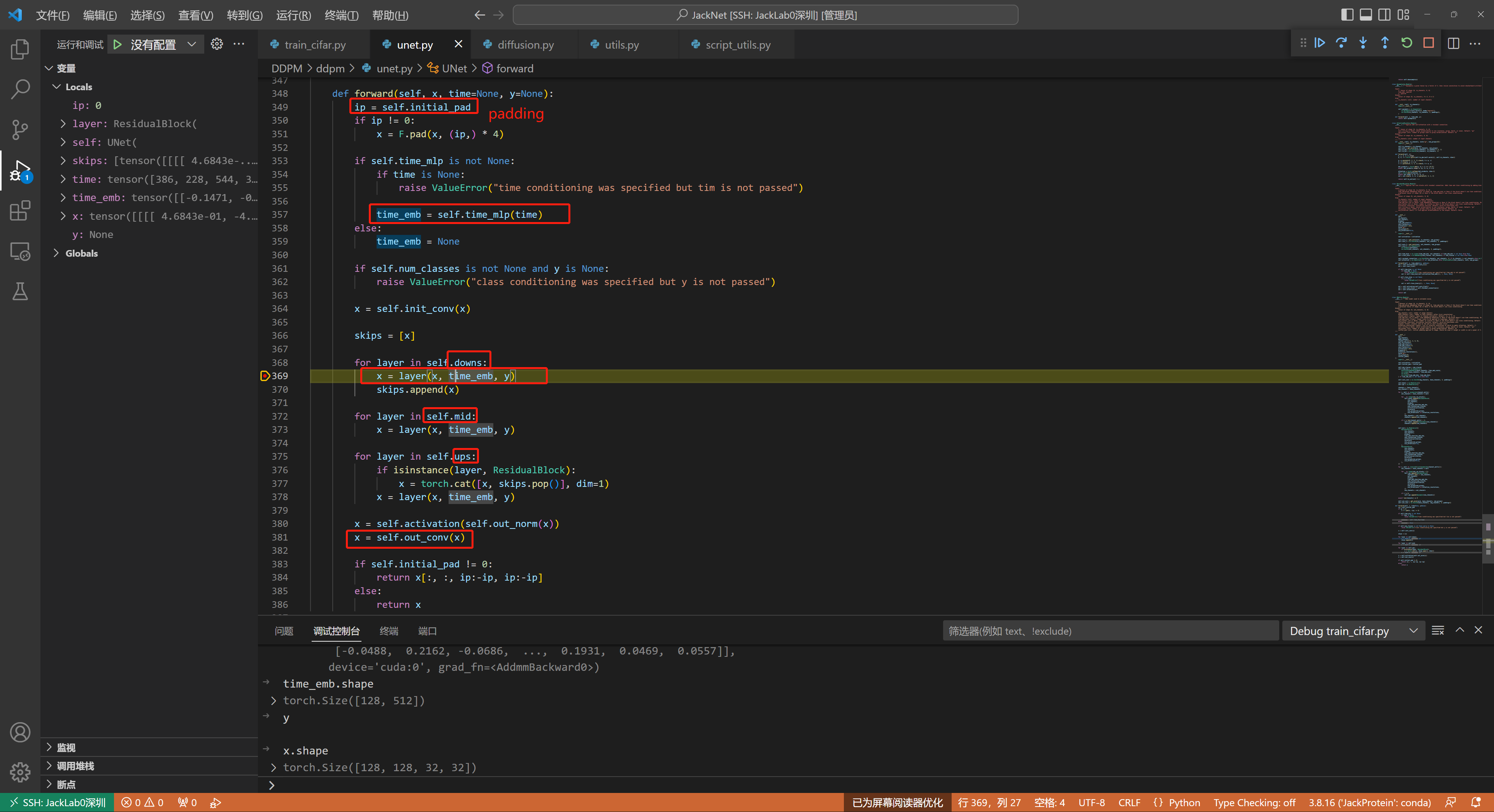
这里每一个time[128]信息会被self.time_mlp编码为一个embeeeding,即time_emb[128,512]
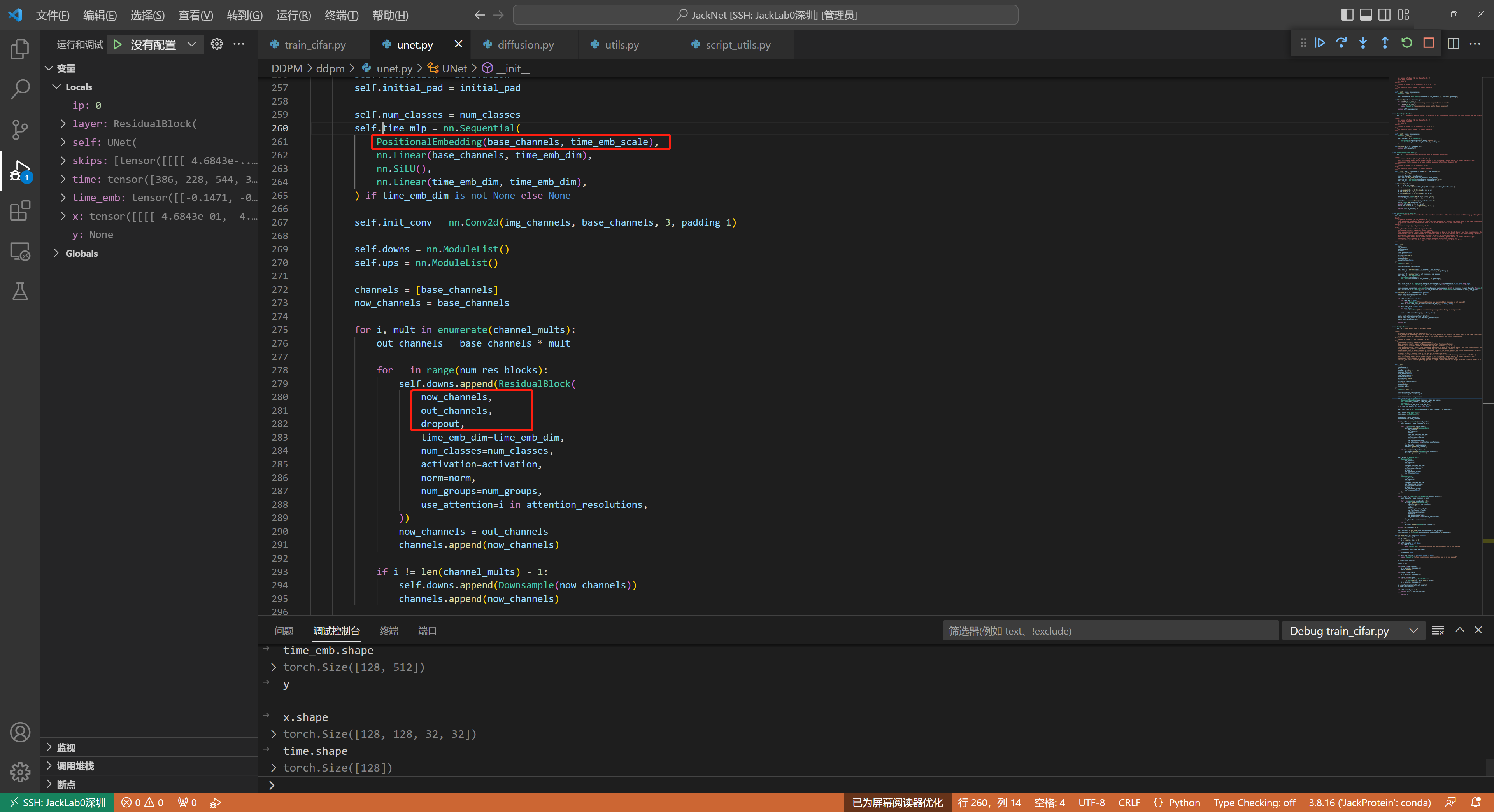
可以参考代码的Line260,这里time会被TimeEmbedding层采用和Transformer一致的三角函数位置编码,将常数转变为向量
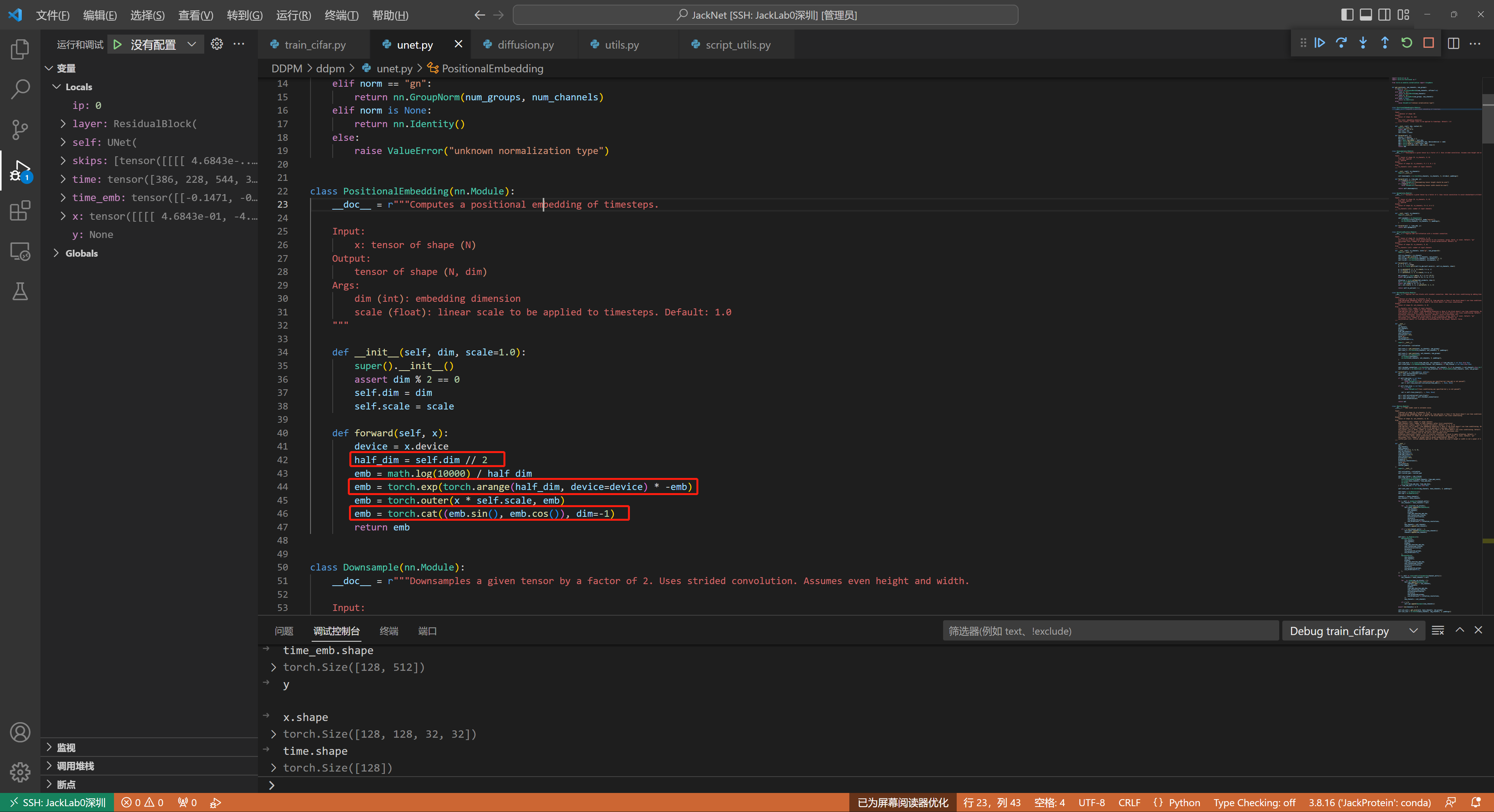
以下是DDMP的UNet整体代码,关键在于理解这个UNet是如何把时间信息和x融合起来的
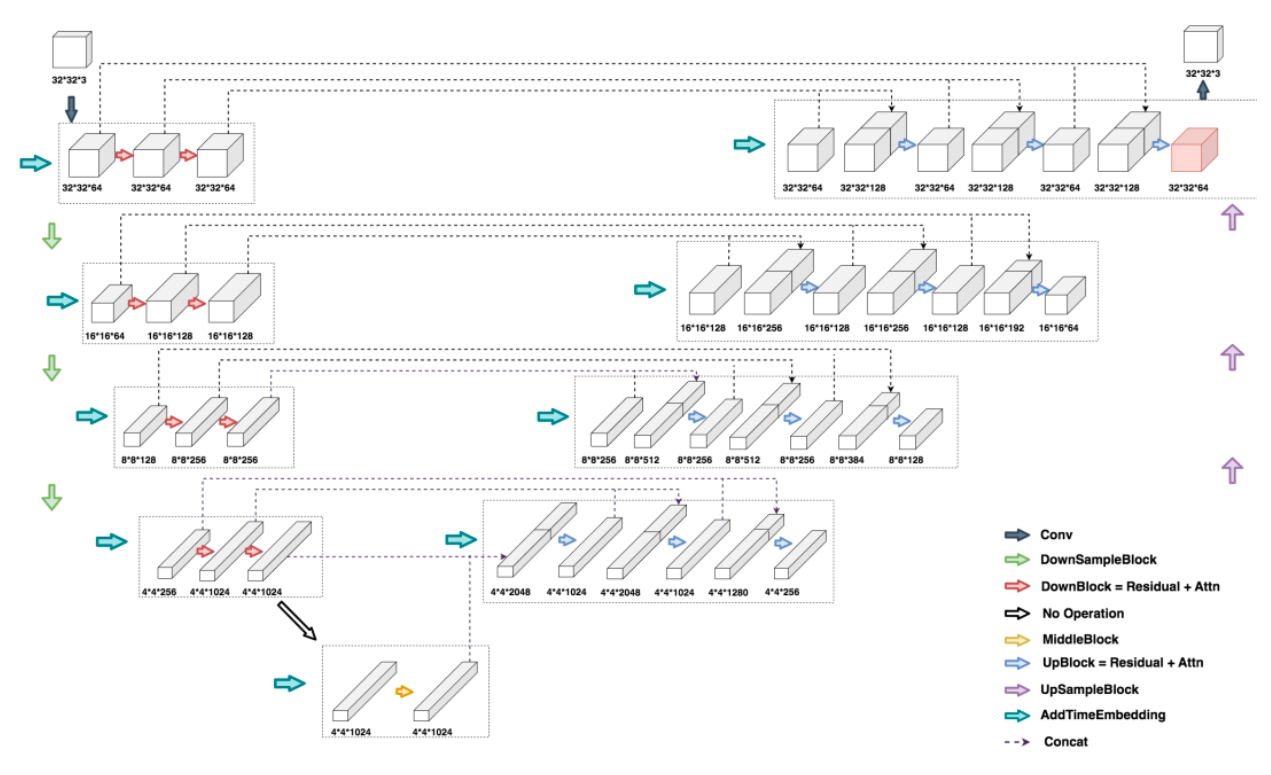
DDPM中的Unet架构
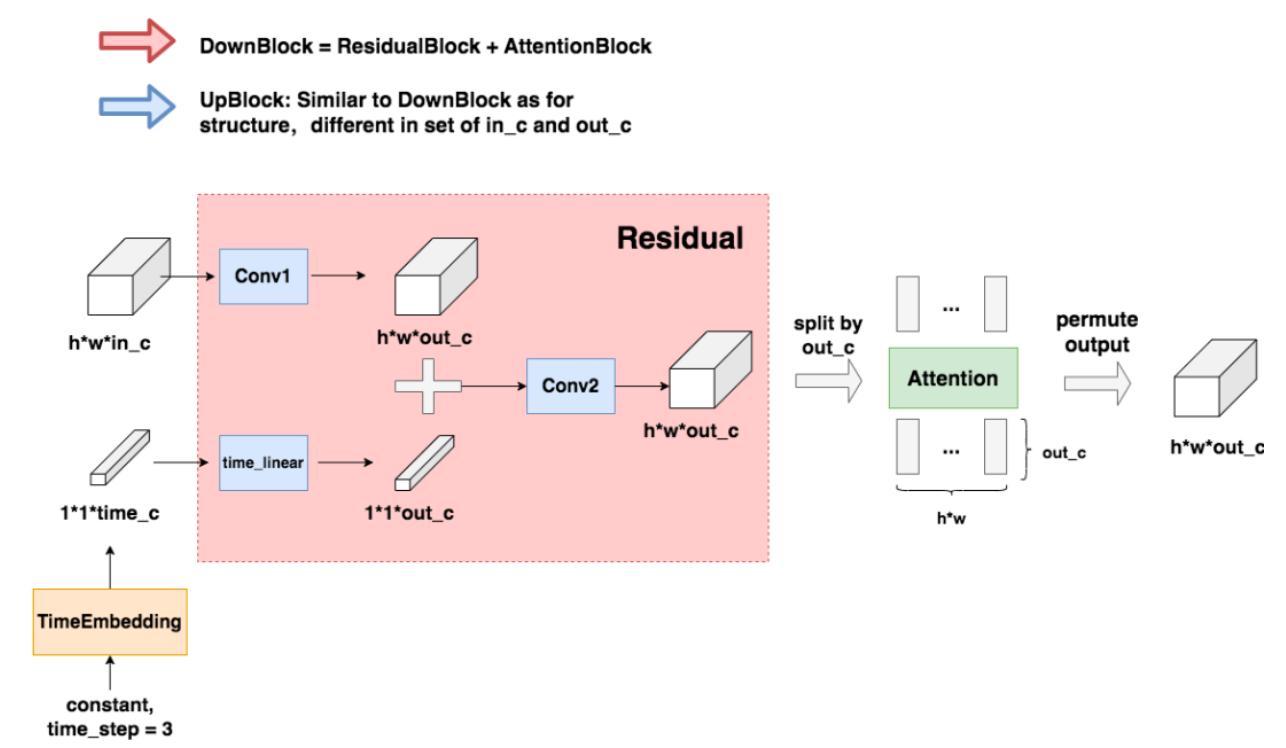
DownBlock和UpBlock
可以参考以下的基础block,Line199,ResidualBlock,就是把time_embedding经过一层nn.Linear,x经过一层nn.Conv2d,然后相加即可融合二者信息
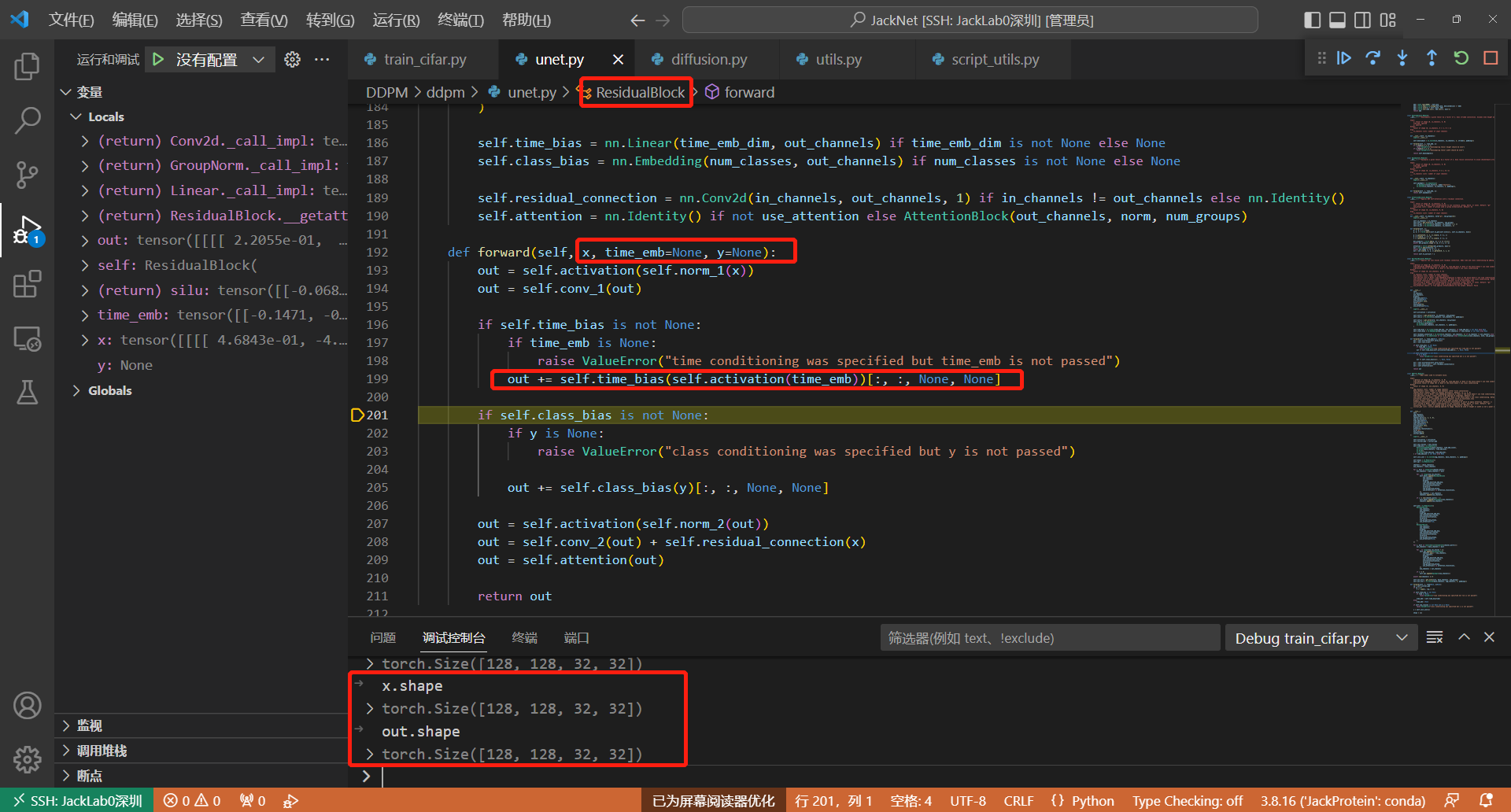
1.5 预测的噪声和加入的噪声进行损失计算
参考Line150,这样UNet模型拥有了预测图片中的噪声分布的能力
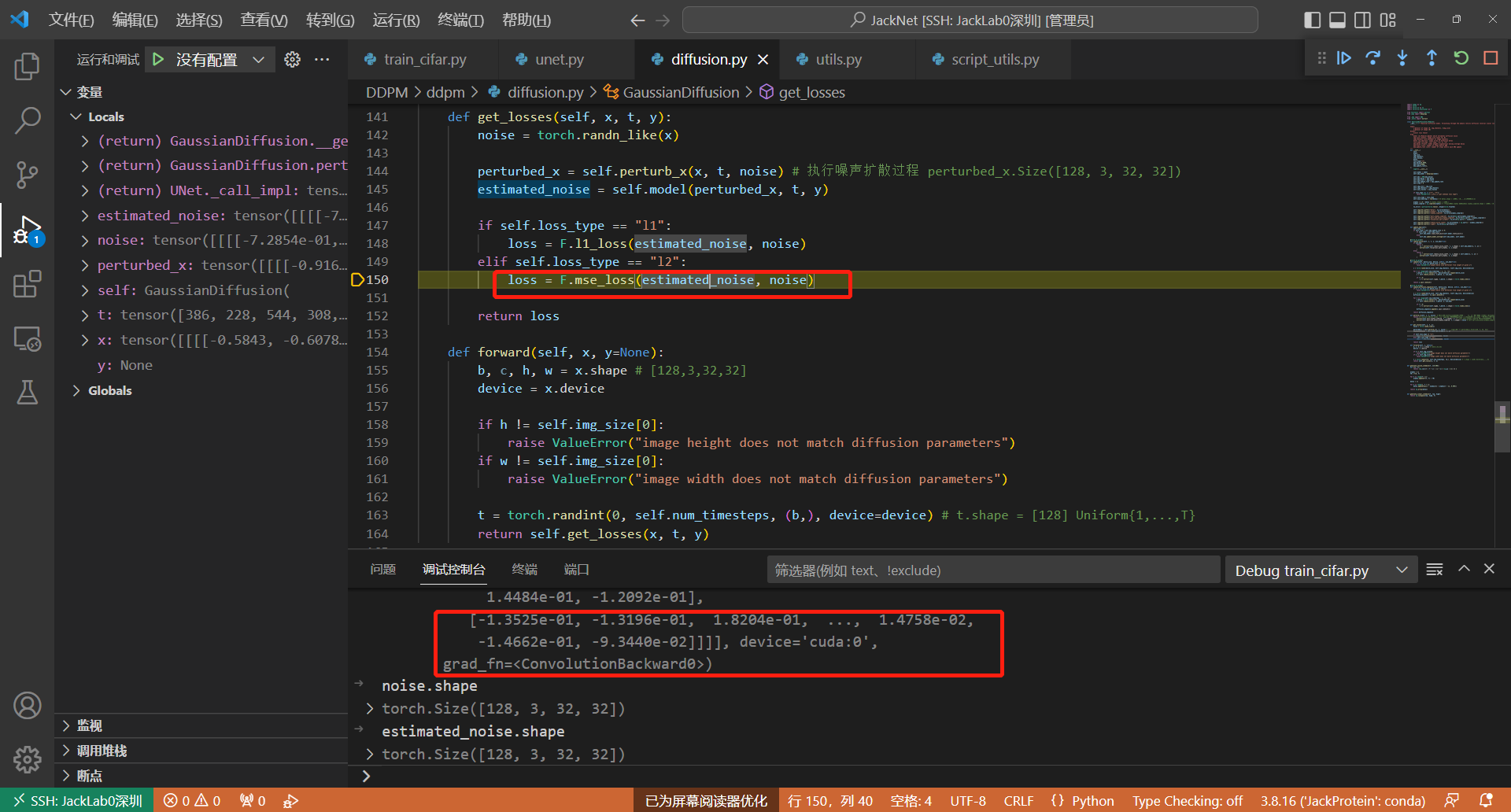
2. 采样

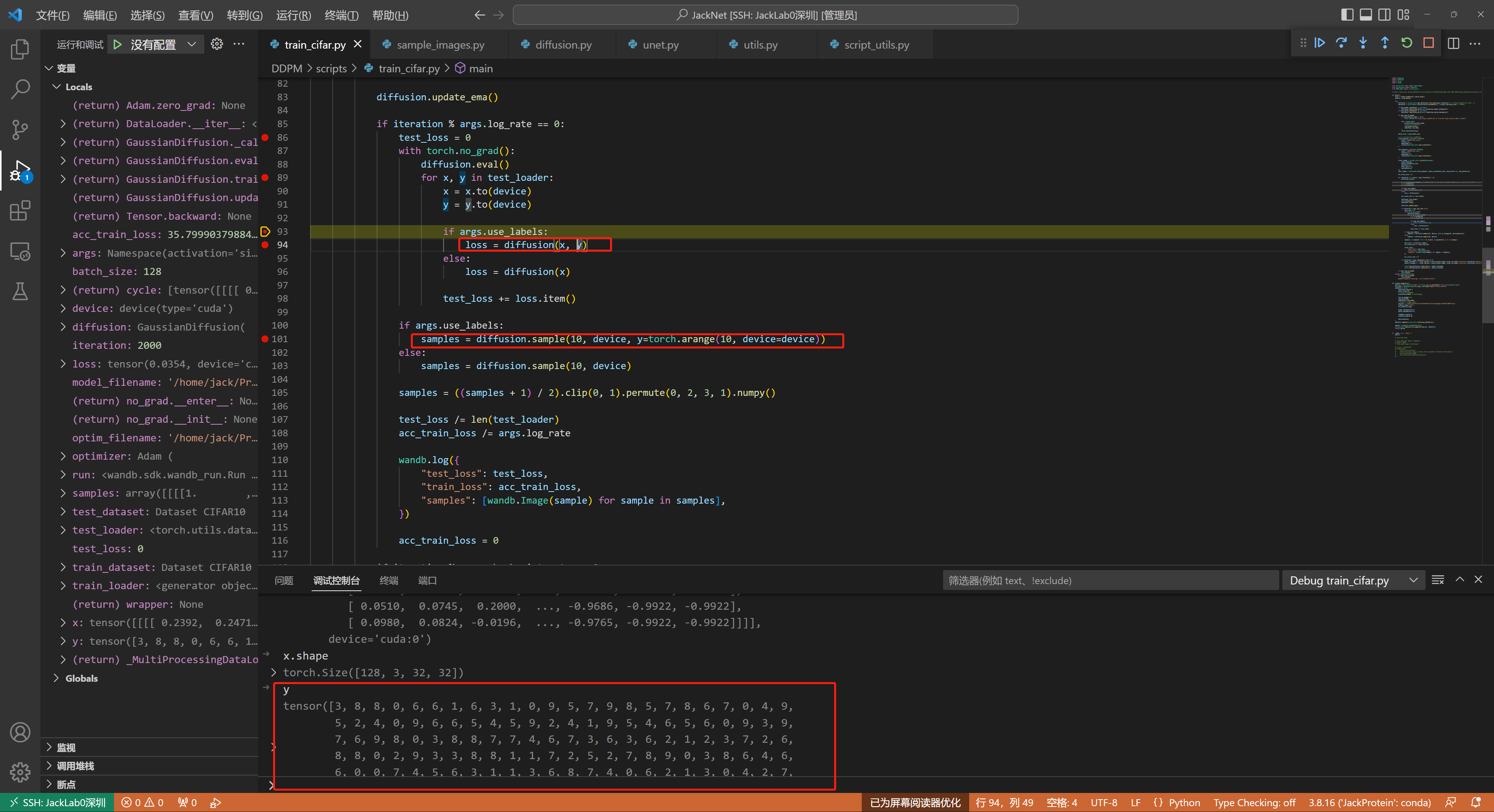
训练1000步,执行一次采样
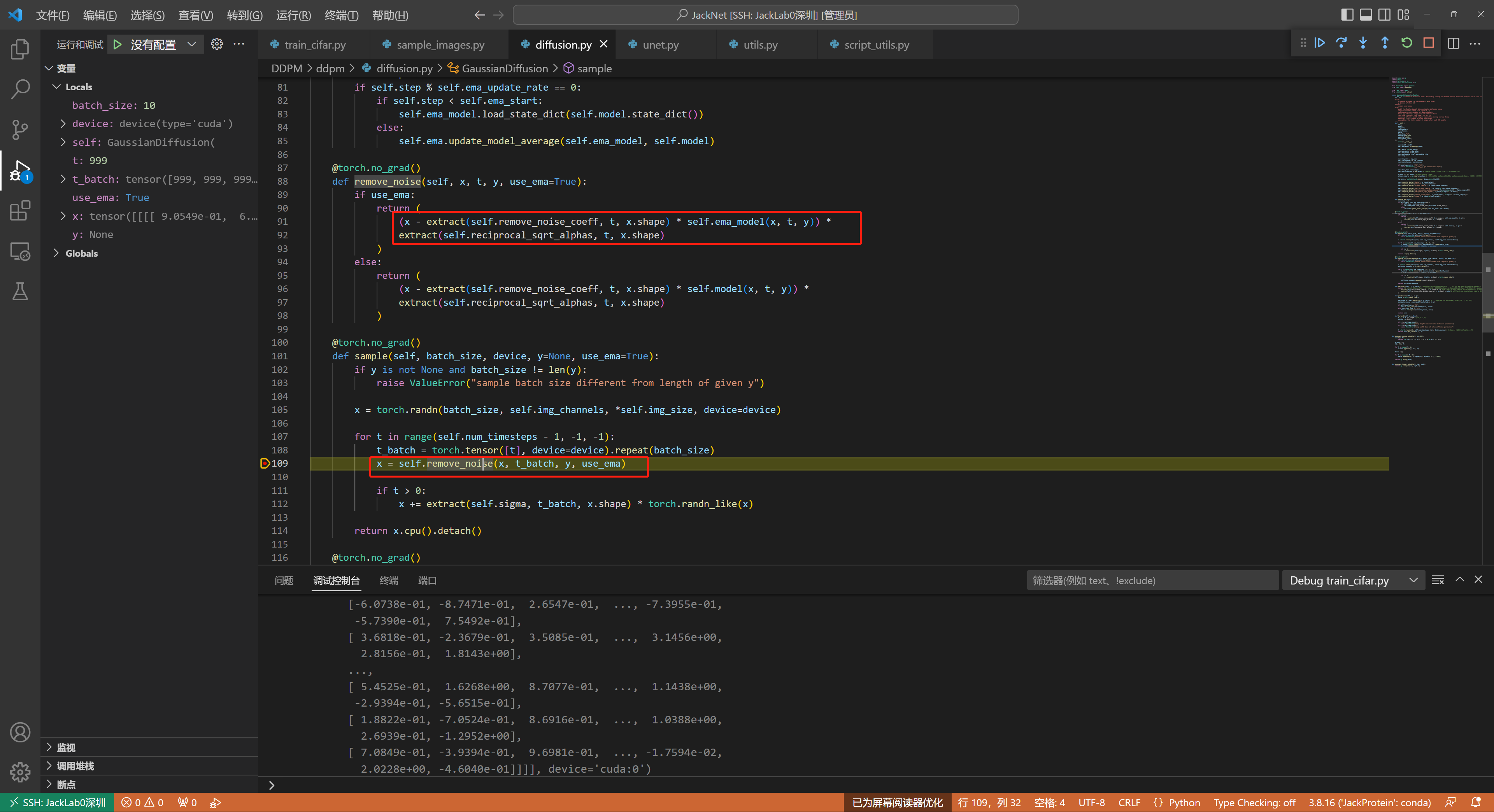
采样函数的具体细节,注意,这时候的t就不是随机生成的t了,而是从1000逐步递减下来的
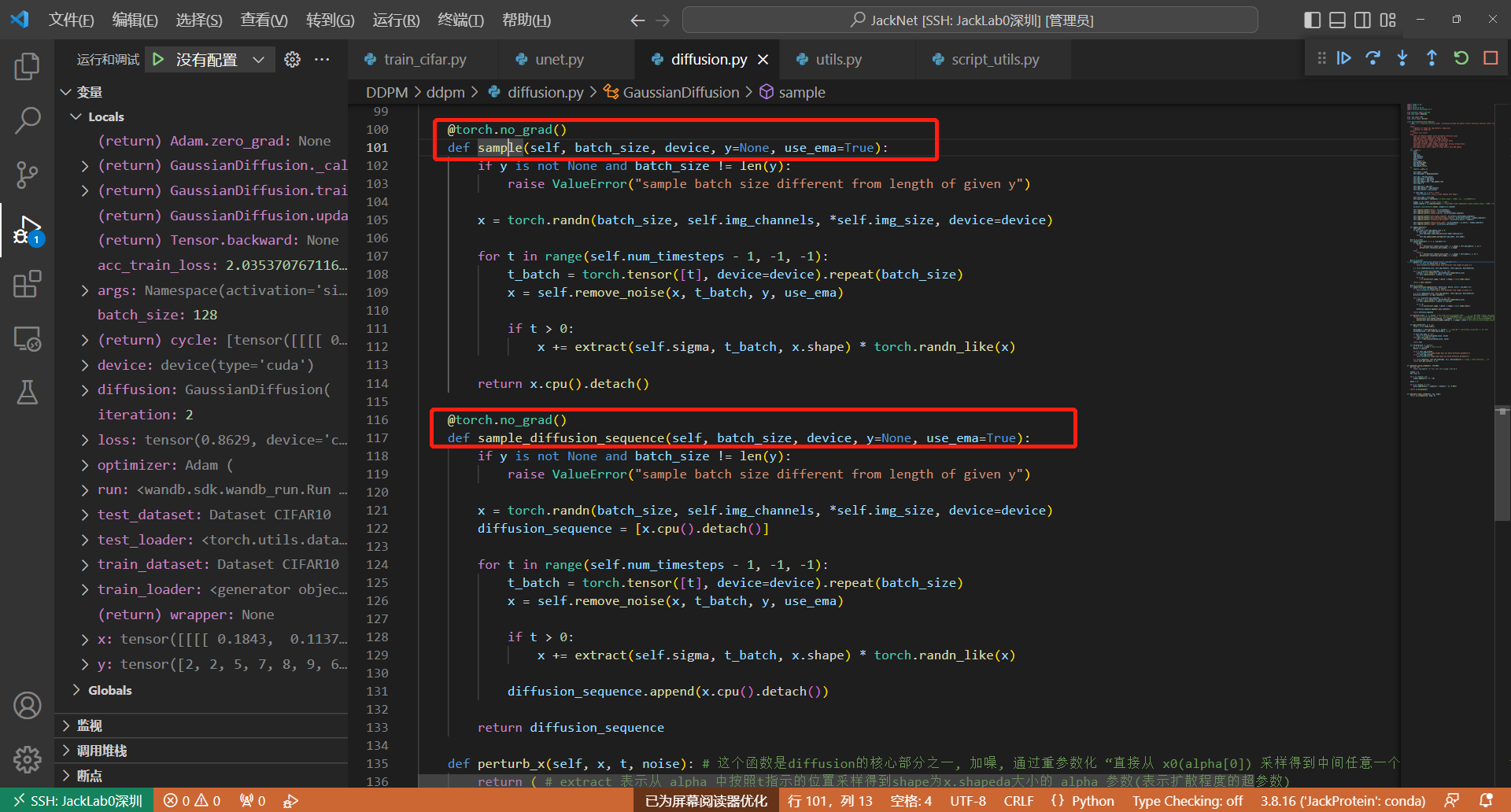
注意,采样函数会过一遍UNet模型,得到UNet预测到的当前时间步的noise,然后用x-noise得到当前时间步的去噪图片,可以参考如下代码Line109:
总结:可以看到虽然前面的推导过程很复杂,但是训练过程却很简单:
- 首先每个迭代就是从数据集中取真实图像 x0,并从均匀分布中采样一个时间步 t,
- 然后从标准高斯分布中采样得到噪声 ε,并根据公式计算得到前向过程的 xt。
- 接着将 xt 和 t 输入到模型让其输出去拟合预测噪声 ε,并通过梯度下降更新模型,一直循环直到模型收敛。
- 而采用的深度学习模型是类似 UNet 的结构。
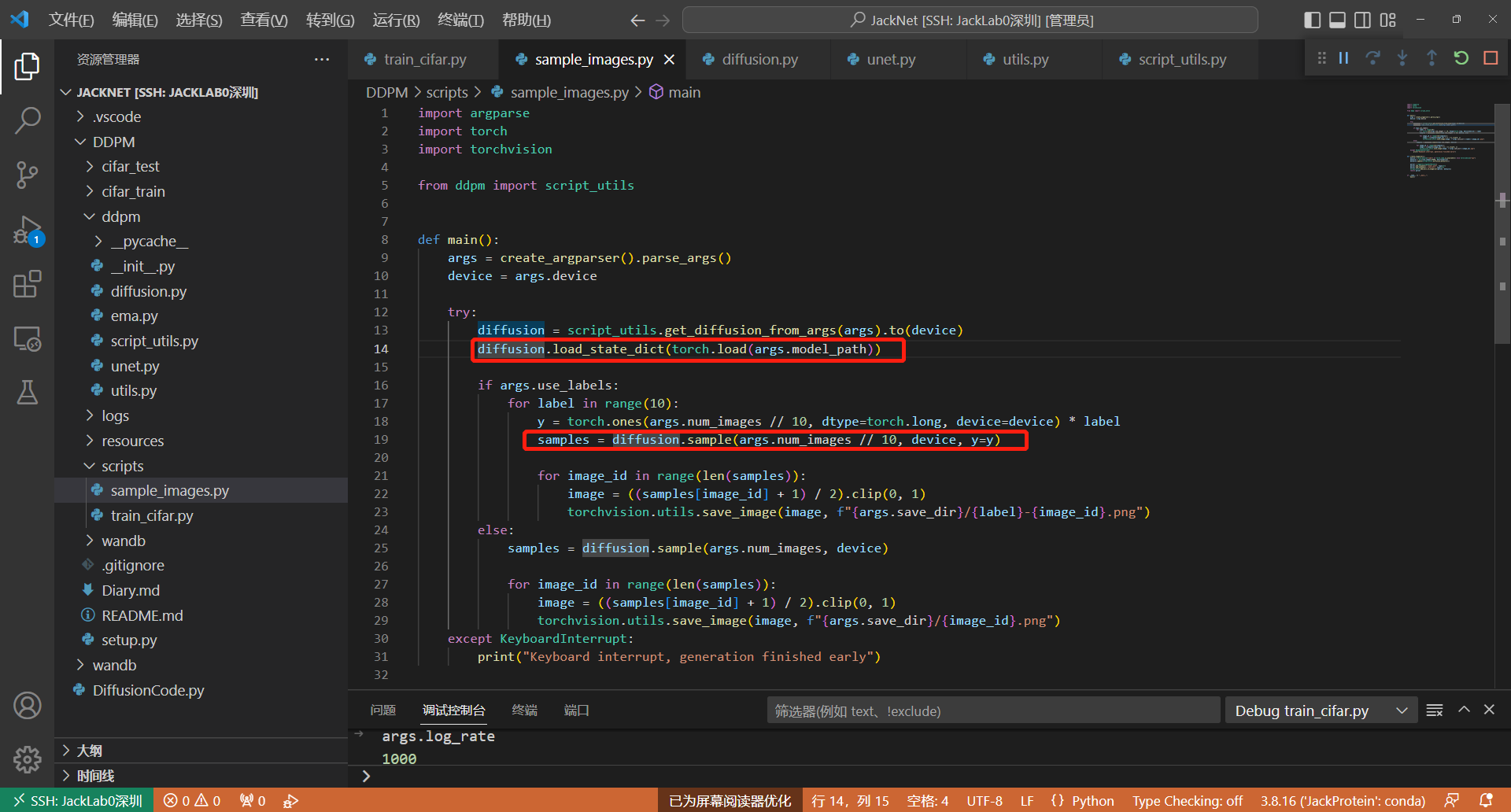
3. 推理
推理过程很简单,给一个随机噪声,使用预训练模型权重,直接过一遍模型参数进行采样,即可得到所需图像。注意,这里label标志着采样的步长。步长越长,去噪效果越好,生成的图片质量越佳。






![[python] 进度条使用](https://img-blog.csdnimg.cn/7ce69f4e666f425483a4f2fb77f6fa90.png)