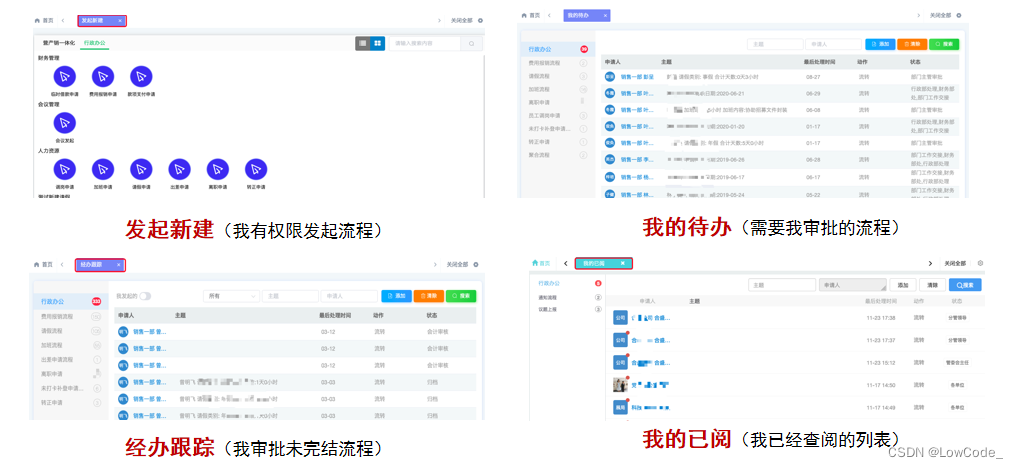
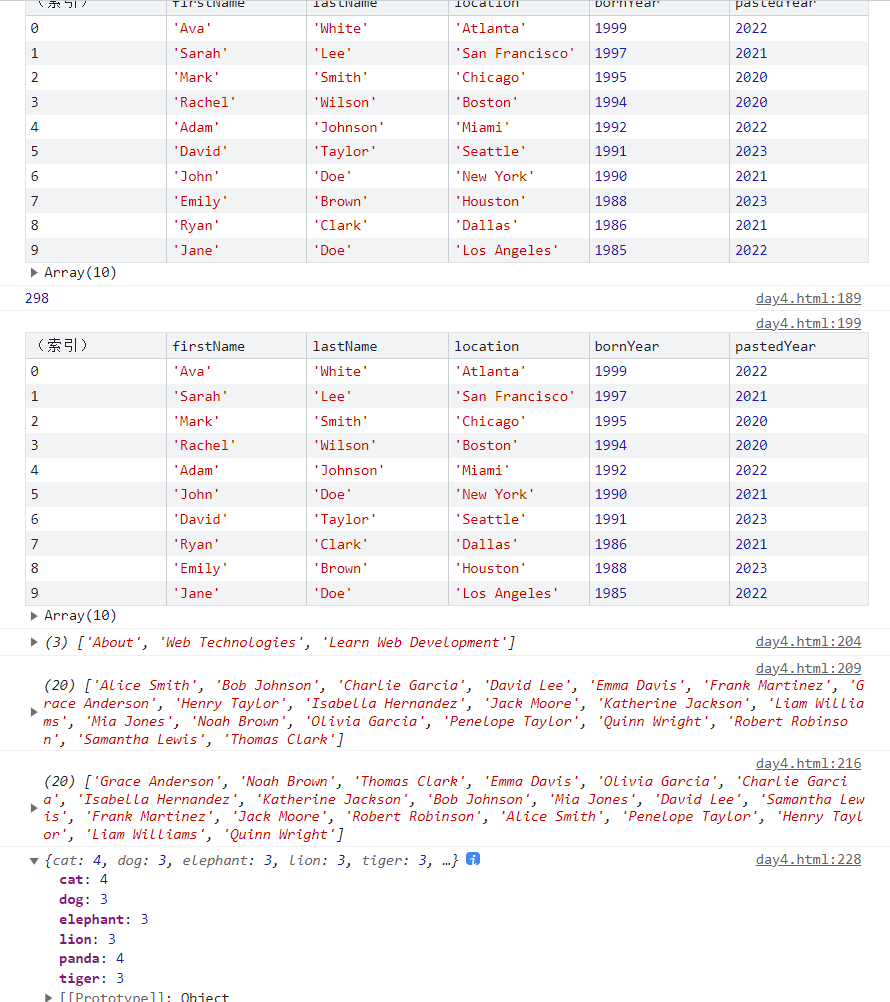
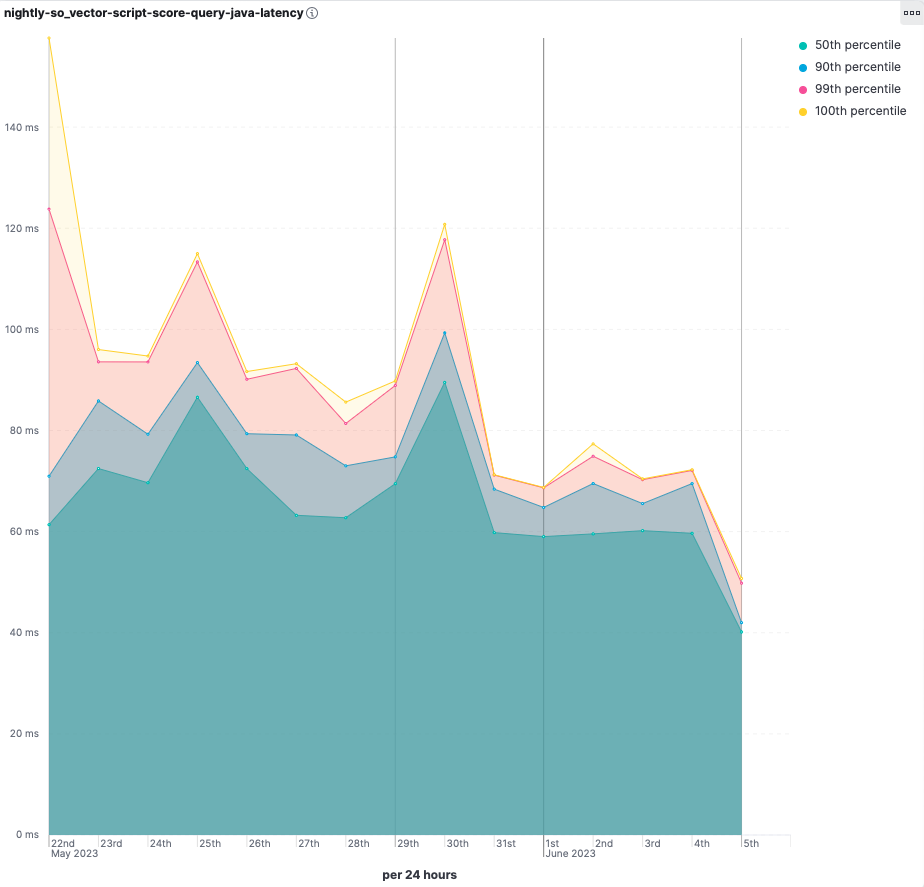
目前各个github上各个库比较杂乱,故此做些整理方便查询
Stable UnCLIP 2.1
New stable diffusion finetune (Stable unCLIP 2.1, Hugging Face) at 768x768 resolution, based on SD2.1-768.
This model allows for image variations and mixing operations as described in Hierarchical Text-Conditional Image Generation with CLIP Latents, and, thanks to its modularity, can be combined with other models such as KARLO.
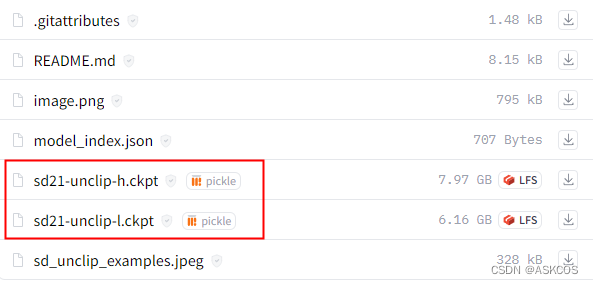
Comes in two variants:
sd21-unclip-l.ckpt :
conditioned on CLIP ViT-L and ViT-H image embeddings
sd21-unclip-h.ckpt:
conditioned on CLIP ViT-L and ViT-H image embeddings
Instructions are available here.
Version 2.1
New stable diffusion model (Stable Diffusion 2.1-v, Hugging Face) at 768x768 resolution and (Stable Diffusion 2.1-base, HuggingFace) at 512x512 resolution, both based on the same number of parameters and architecture as 2.0 and fine-tuned on 2.0, on a less restrictive NSFW filtering of the LAION-5B dataset.
Per default, the attention operation of the model is evaluated at full precision when xformers is not installed. To enable fp16 (which can cause numerical instabilities with the vanilla attention module on the v2.1 model) , run your script with ATTN_PRECISION=fp16 python <thescript.py>
Version 2.0
- New stable diffusion model (Stable Diffusion 2.0-v) at 768x768 resolution. Same number of parameters in the U-Net as 1.5, but uses OpenCLIP-ViT/H as the text encoder and is trained from scratch. SD 2.0-v is a so-called v-prediction model.
- The above model is finetuned from SD 2.0-base, which was trained as a standard noise-prediction model on 512x512 images and is also made available.
- Added a x4 upscaling latent text-guided diffusion model.
- New depth-guided stable diffusion model, finetuned from SD 2.0-base. The model is conditioned on monocular depth estimates inferred via MiDaS and can be used for structure-preserving img2img and shape-conditional synthesis.
- A text-guided inpainting model, finetuned from SD 2.0-base.
Version 1
- sd-v1-1.ckpt:
237k steps at resolution 256x256 on laion2B-en. 194k steps at resolution 512x512 on laion-high-resolution (170M examples from LAION-5B with resolution >= 1024x1024). - sd-v1-2.ckpt:
Resumed from sd-v1-1.ckpt. 515k steps at resolution 512x512 on laion-aesthetics v2 5+ (a subset of laion2B-en with estimated aesthetics score > 5.0, and additionally filtered to images with an original size >= 512x512, and an estimated watermark probability < 0.5. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using the LAION-Aesthetics Predictor V2). - sd-v1-3.ckpt:
Resumed from sd-v1-2.ckpt. 195k steps at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free guidance sampling. - sd-v1-4.ckpt:
Resumed from sd-v1-2.ckpt. 225k steps at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free guidance sampling. - sd-v1-5.ckpt:
Resumed from sd-v1-2.ckpt. 595k steps at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free guidance sampling. - sd-v1-5-inpainting.ckpt:
Resumed from sd-v1-5.ckpt. 440k steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free guidance sampling. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.