目录
一、目前多数人的写法
二、优化方案
三、总结

大家在实际的开发过程中,会根据某些条件,从数据库表中查询出是否存在符合该条件的数据。无论是刚入行的程序员小白,还是久经沙场多年的程序员老白,都是一如既往的SELECT count(*) ,那么有没有更好的方法呢?往下看:
一、目前多数人的写法
多次REVIEW代码时,发现了如下现象:业务代码中,需要根据某个或某些条件,查询是否存在符合条件的数据,但并不关心存在有多少条数据。普遍的SQL及代码写法如下:
<!-- SQL写法: -->
SELECT count(*) FROM 表名 WHERE 字段1 = 条件1 AND 字段2 = 条件2 ...
/*** Java写法:*/
int nums = xxDao.countXxxxByXxx(入参);
if ( nums > 0 ) {
// 当存在时,执行这里的代码
} else {
// 当不存在时,执行这里的代码
}首先,这种写法没什么毛病,很OK,但是还可以在优化一下的。
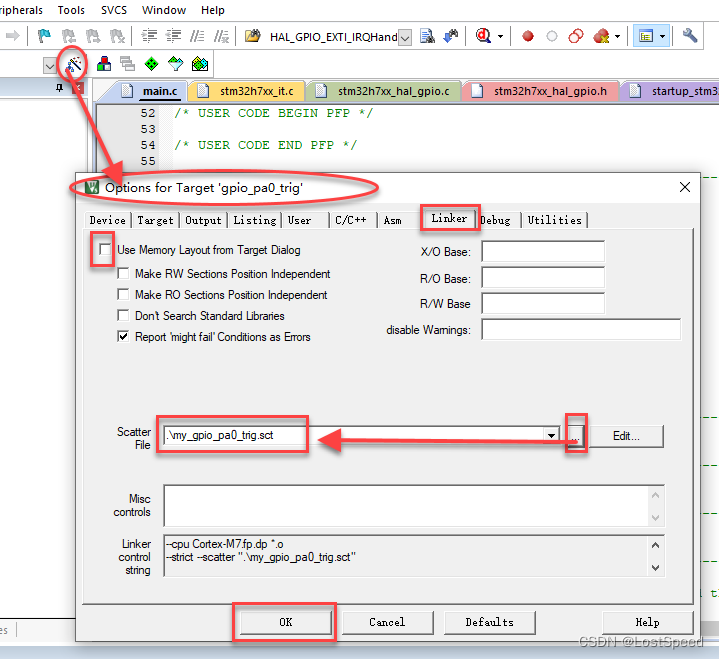
二、优化方案
推荐写法如下:
<!-- SQL写法: -->
SELECT 1 FROM 表名 WHERE 字段1 = 条件1 AND 字段2 = 条件2 LIMIT 1
/*** Java写法:*/
Integer exist = xxDao.existXxxxByXxx(入参);
if ( exist != NULL ) {
// 当存在时,执行这里的代码
} else {
// 当不存在时,执行这里的代码
}这里的SQL不再是使用查询count,而是改用LIMIT 1,让数据库查询时查到一条就返回,不用再继续查找剩余多少条数据了,大大节约了性能的消耗。
三、总结
当根据查询条件查出来的数据量越多,性能提升的越发的明显,在某些情况下,还可以减少联合索引的创建。改进把你的代码优化一下吧。
如果这篇文章对您有所帮助,或者有所启发的话,求一键三连:点赞、评论、收藏➕关注,您的支持是我坚持写作最大的动力。