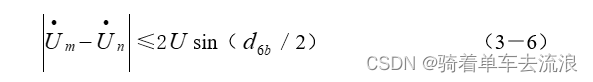通常在使用VITS进行声音克隆的时候出现声音沙哑或者大佐味,就是日本腔调,这个一方面是由于模型训练的问题,如果觉得模型训练没有问题的话就是参数,或者其他原因。这里介绍一个通用的解决办法。
文章目录
- 声音预测参数
- 音频生成
声音预测参数
按照以下图片进行设置获取模型。
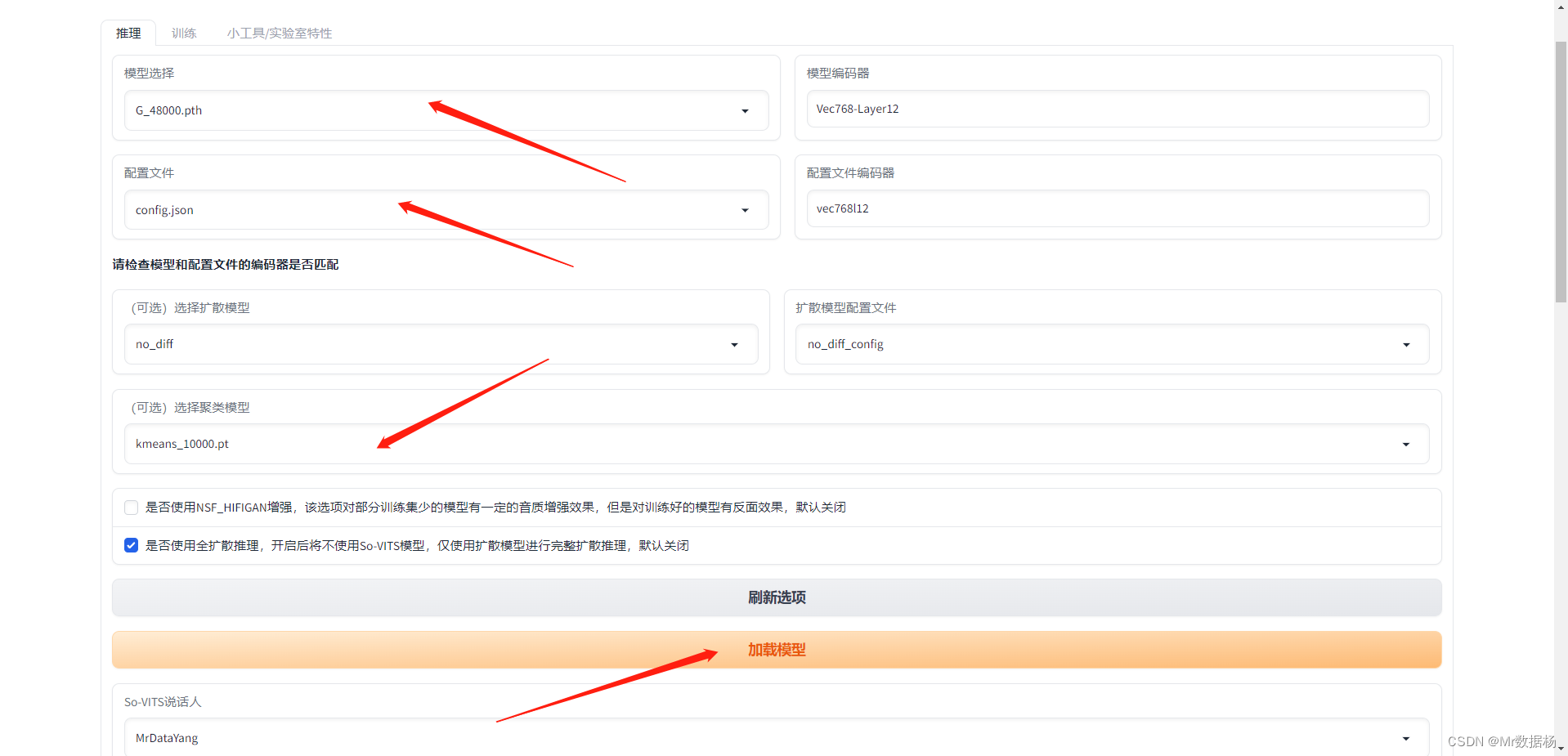
上传好音频之后点击这些选项,然后生成音频。
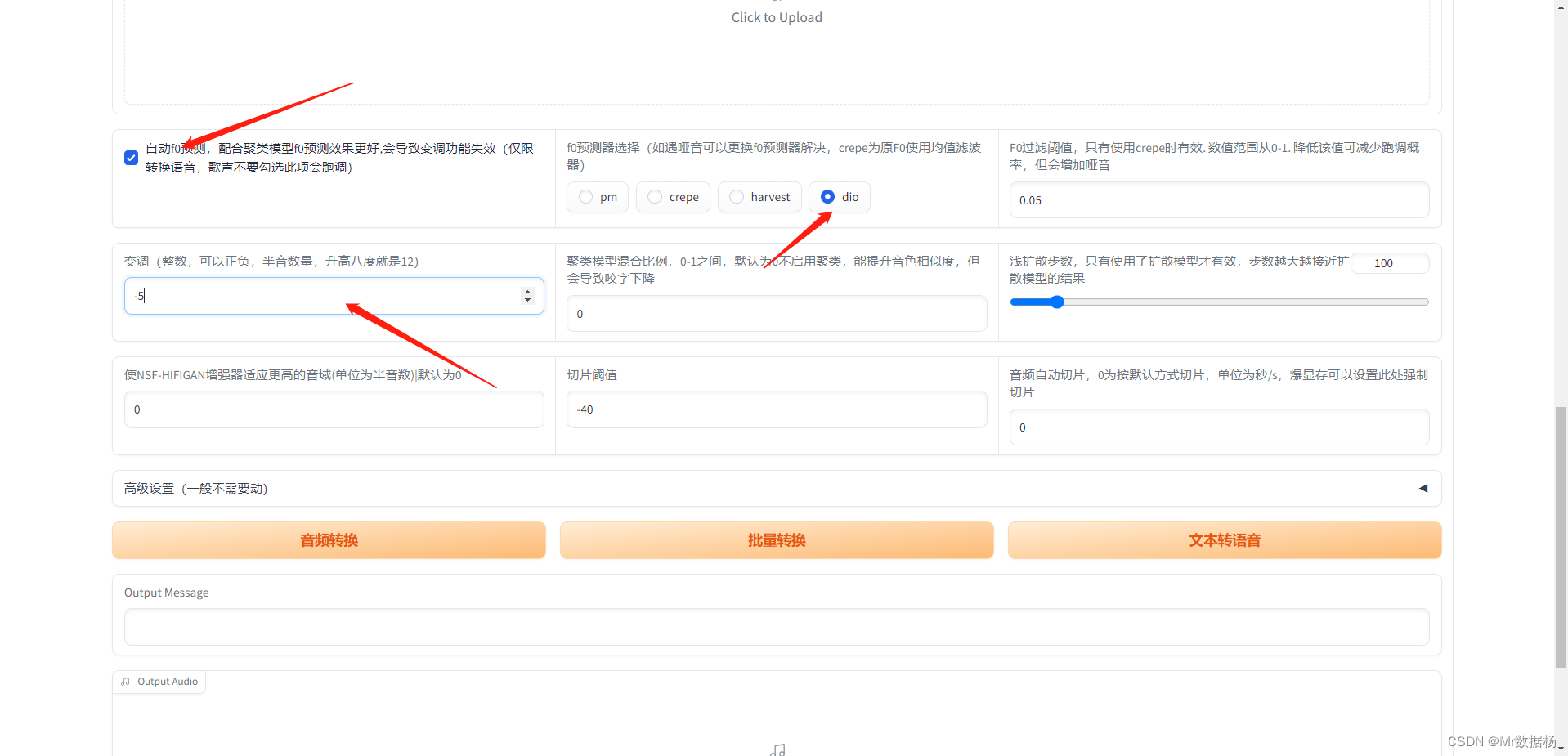
音频生成
首先使用微软的TTS进行文本转语音的操作,这里有个技巧就是不要整篇文字扔进去,拆分分段生成音频,然后克隆。具体为什么自己体会吧,这个是我尝试了多少次成功的。
先整理好你的文件目录如图。
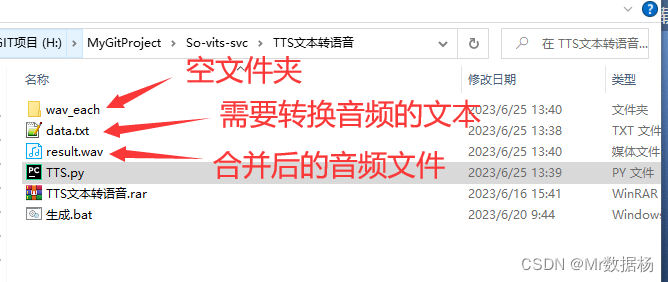
这里面的TTS_apiKey要换成你的,split_and_accumulate方法后面的50是拆分字数间隔。