文章目录
- 爬虫基础知识
- 什么是爬虫?
- 爬虫的工作原理
- 爬虫的应用领域
- 爬虫准备工作
- 安装Python
- 安装必要的库和工具
- 网页解析与XPath
- 网页结构与标签
- CSS选择器与XPath
- Xpath 语法
- XPath的基本表达式:
- XPath的谓语(Predicate):
- XPath的轴(Axis):
- XPath的运算符:
- XPath的函数:
- 使用XPath解析网页
- 未完待续...
爬虫基础知识

什么是爬虫?

爬虫是一种自动化程序,用于从互联网上获取数据。它通过模拟浏览器行为,访问指定的网页,并从中提取所需的信息。爬虫工作的核心是发送HTTP请求、获取网页内容、解析网页结构并提取数据。
爬虫的工作原理

爬虫的工作原理可以分为以下几个步骤:
- 发送HTTP请求:爬虫通过发送HTTP请求来访问目标网页。
- 获取网页内容:目标网站接收到请求后,会返回网页的HTML源代码作为响应。
- 解析网页内容:爬虫利用解析技术(如XPath、正则表达式等)对HTML源代码进行解析,从中提取需要的信息。
- 存储数据:爬虫将提取到的数据进行存储,可以保存到本地文件或写入数据库。
爬虫的应用领域

爬虫在各个领域都有广泛应用:
- 数据采集与分析:爬虫可以用于采集互联网上的各种数据,如新闻、商品信息、股票数据等。这些数据可以用于后续的数据分析、挖掘和建模。
- 搜索引擎:搜索引擎利用爬虫技术来获取互联网上的网页信息,并建立搜索索引,以提供给用户相关的搜索结果。
- 舆情监测:企业或政府可以利用爬虫技术来监控社交媒体等平台上的舆情动态,及时获取和分析公众的意见和反馈。
- 价格监测:电商平台可以利用爬虫定期监测竞争对手的商品价格,以调整自己的定价策略。
- 其他领域:爬虫还广泛应用于个性化推荐系统、自然语言处理、机器学习等领域。
爬虫准备工作

安装Python
爬虫通常使用Python进行开发,因此需要先安装Python。您可以从Python官方网站(https://www.python.org/)下载最新版本的Python,并按照安装向导进行安装。
安装必要的库和工具
爬虫开发中需要使用一些常用的库和工具来简化开发流程:
- requests:用于发送HTTP请求和处理响应。可以通过
pip install requests命令安装。 - BeautifulSoup:一个优秀的HTML/XML解析库,可以方便地从网页中提取数据。可以通过
pip install beautifulsoup4命令安装。 - lxml:一个高性能的XML/HTML解析库,可以用于XPath解析。可以通过
pip install lxml命令安装。
网页解析与XPath

网页结构与标签
网页通常使用HTML(超文本标记语言)编写,它由一系列标签组成。标签用于定义网页的结构和呈现。常见的HTML标签有<html>、<head>、<body>、<div>、<p>等等。通过理解这些标签及其嵌套关系,可以更好地理解网页的结构。
CSS选择器与XPath
网页解析可以使用不同的方法,其中两种常见的方法是CSS选择器和XPath。
-
CSS选择器:CSS选择器是一种用于选择HTML元素的语法。它通过使用标签名、类名、ID等属性,可以方便地定位到指定的元素。例如,通过
.classname选择类名为classname的元素,通过#id选择ID为id的元素。 -
XPath:XPath是一种用于在XML和HTML文档中进行选择的语言。XPath使用路径表达式来选择节点或节点集合。例如,使用
//表示选择从根节点开始的所有节点,使用/表示选择当前节点的子节点,使用[]表示筛选条件等。
Xpath 语法
XPath的基本表达式:
# 选择所有名为"book"的节点
xpath_expression = "//book"
# 选择根节点下的所有名为"title"的子节点
xpath_expression = "/root/title"
# 选择当前节点
xpath_expression = "."
# 选择当前节点的父节点
xpath_expression = ".."
nodename:选择指定名称的节点。//nodename:选择文档中所有匹配名称的节点。/:从根节点开始选择。.:选择当前节点。..:选择当前节点的父节点。
XPath的谓语(Predicate):
谓语用于进一步筛选节点,可以使用一些条件进行过滤。
# 选择第2个名为"book"的节点
xpath_expression = "//book[2]"
# 选择最后一个名为"title"的节点
xpath_expression = "//title[last()]"
# 选择位置小于3的名为"book"的节点
xpath_expression = "//book[position()<3]"
# 选择具有属性lang的名为"book"的节点
xpath_expression = "//book[@lang]"
# 选择属性lang的值为"en"的名为"book"的节点
xpath_expression = "//book[@lang='en']"
# 选择文本内容为"Python"的名为"title"的节点
xpath_expression = "//title[text()='Python']"
# 选择属性lang包含"en"的名为"book"的节点
xpath_expression = "//book[contains(@lang, 'en')]"
# 选择属性lang以"en"开始的名为"book"的节点
xpath_expression = "//book[starts-with(@lang, 'en')]"
# 选择属性lang以"en"结束的名为"book"的节点
xpath_expression = "//book[ends-with(@lang, 'en')]"
[]:用于定义谓语条件。[n]:选择第n个节点。[last()]:选择最后一个节点。[position()<n]:选择位置小于n的节点。[@attribute]:选择具有指定属性的节点。[@attribute='value']:选择具有指定属性值的节点。[text()='value']:选择具有指定文本值的节点。[contains(@attribute, 'value')]:选择属性包含特定值的节点。[starts-with(@attribute, 'value')]:选择属性以特定值开始的节点。[ends-with(@attribute, 'value')]:选择属性以特定值结束的节点。
XPath的轴(Axis):
轴用于在节点之间建立关联,常见的轴包括:
# 选择所有祖先节点
xpath_expression = "//book/ancestor::node()"
# 选择所有祖先节点和当前节点自身
xpath_expression = "//book/ancestor-or-self::node()"
# 选择当前节点的属性节点
xpath_expression = "//book/attribute::node()"
# 选择当前节点的所有子节点
xpath_expression = "//book/child::node()"
# 选择当前节点的所有后代节点
xpath_expression = "//book/descendant::node()"
# 选择当前节点的所有后代节点和自身
xpath_expression = "//book/descendant-or-self::node()"
# 选择当前节点之后的所有节点
xpath_expression = "//book/following::node()"
# 选择当前节点之后的所有同级节点
xpath_expression = "//book/following-sibling::node()"
# 选择当前节点的父节点
xpath_expression = "//book/parent::node()"
# 选择当前节点之前的所有节点
xpath_expression = "//book/preceding::node()"
# 选择当前节点之前的所有同级节点
xpath_expression = "//book/preceding-sibling::node()"
# 选择当前节点
xpath_expression = "//book/self::node()"
ancestor:选择所有祖先节点。ancestor-or-self:选择所有祖先节点和当前节点自身。attribute:选择当前节点的属性节点。child:选择当前节点的所有子节点。descendant:选择当前节点的所有后代节点。descendant-or-self:选择当前节点的所有后代节点和自身。following:选择当前节点之后的所有节点。following-sibling:选择当前节点之后的所有同级节点。namespace:选择当前节点的命名空间节点。parent:选择当前节点的父节点。preceding:选择当前节点之前的所有节点。preceding-sibling:选择当前节点之前的所有同级节点。self:选择当前节点。
XPath的运算符:
XPath支持使用运算符进行条件筛选,常见的运算符包括:
# 判断两个值是否相等
xpath_expression = "//book[price=10]"
# 判断两个值是否不相等
xpath_expression = "//book[price!=10]"
# 判断一个值是否小于另一个值
xpath_expression = "//book[price<10]"
# 判断一个值是否大于另一个值
xpath_expression = "//book[price>10]"
# 判断一个值是否小于等于另一个值
xpath_expression = "//book[price<=10]"
# 判断一个值是否大于等于另一个值
xpath_expression = "//book[price>=10]"
# 用于逻辑与操作
xpath_expression = "//book[price=10 and lang='en']"
# 用于逻辑或操作
xpath_expression = "//book[price=10 or lang='en']"
# 用于逻辑非操作
xpath_expression = "//book[not(price=10)]"
=:判断两个值是否相等。!=:判断两个值是否不相等。<:判断一个值是否小于另一个值。>:判断一个值是否大于另一个值。<=:判断一个值是否小于等于另一个值。>=:判断一个值是否大于等于另一个值。and:用于逻辑与操作。or:用于逻辑或操作。not:用于逻辑非操作。
XPath的函数:
XPath提供了一些内置函数,可以在选择节点时进行一些操作和转换。常用的函数包括:
# 选择节点的文本内容
xpath_expression = "//title/text()"
# 选择节点的名称
xpath_expression = "name(//book)"
# 连接多个字符串
xpath_expression = 'concat("Hello", " ", "World")'
# 判断一个字符串是否包含另一个字符串
xpath_expression = 'contains("Hello World", "Hello")'
# 判断一个字符串是否以另一个字符串开始
xpath_expression = 'starts-with("Hello World", "Hello")'
# 判断一个字符串是否以另一个字符串结束
xpath_expression = 'ends-with("Hello World", "World")'
# 获取字符串的长度
xpath_expression = 'string-length("Hello World")'
# 移除字符串两端的空白字符并压缩中间的空白字符
xpath_expression = 'normalize-space(" Hello World ")'
# 计算节点的数量
xpath_expression = 'count(//book)'
text():选择节点的文本内容。name():选择节点的名称。concat():连接多个字符串。contains():判断一个字符串是否包含另一个字符串。starts-with():判断一个字符串是否以另一个字符串开始。ends-with():判断一个字符串是否以另一个字符串结束。string-length():获取字符串的长度。normalize-space():移除字符串两端的空白字符并压缩中间的空白字符。count():计算节点的数量。
使用XPath解析网页
使用XPath解析网页可以方便地定位和提取需要的数据。以下是使用Python的lxml库进行XPath解析csdn中python专栏的示例代码:
import requests
from bs4 import BeautifulSoup
import time
from selenium import webdriver
# 发送HTTP请求获取网页内容
url = "https://blog.csdn.net/nav/python"
# 使用Chrome浏览器,需提前安装ChromeDriver并配置环境变量
driver = webdriver.Chrome()
# 打开网页
driver.get(url)
# 等待网页内容加载完成(根据实际情况调整等待时间)
time.sleep(3)
# 获取完整的网页内容
html = driver.page_source
# 关闭浏览器
driver.quit()
# 解析网页内容
soup = BeautifulSoup(html, "lxml")
# 提取所需信息
articles = soup.select(".Community .active-blog")
# print(articles)
for article in articles:
title = article.select_one(".content .desc").text.strip()
author = article.select_one(".operation .operation-c span").text.strip()
print("标题:", title)
print("作者:", author)
print("-" * 50)
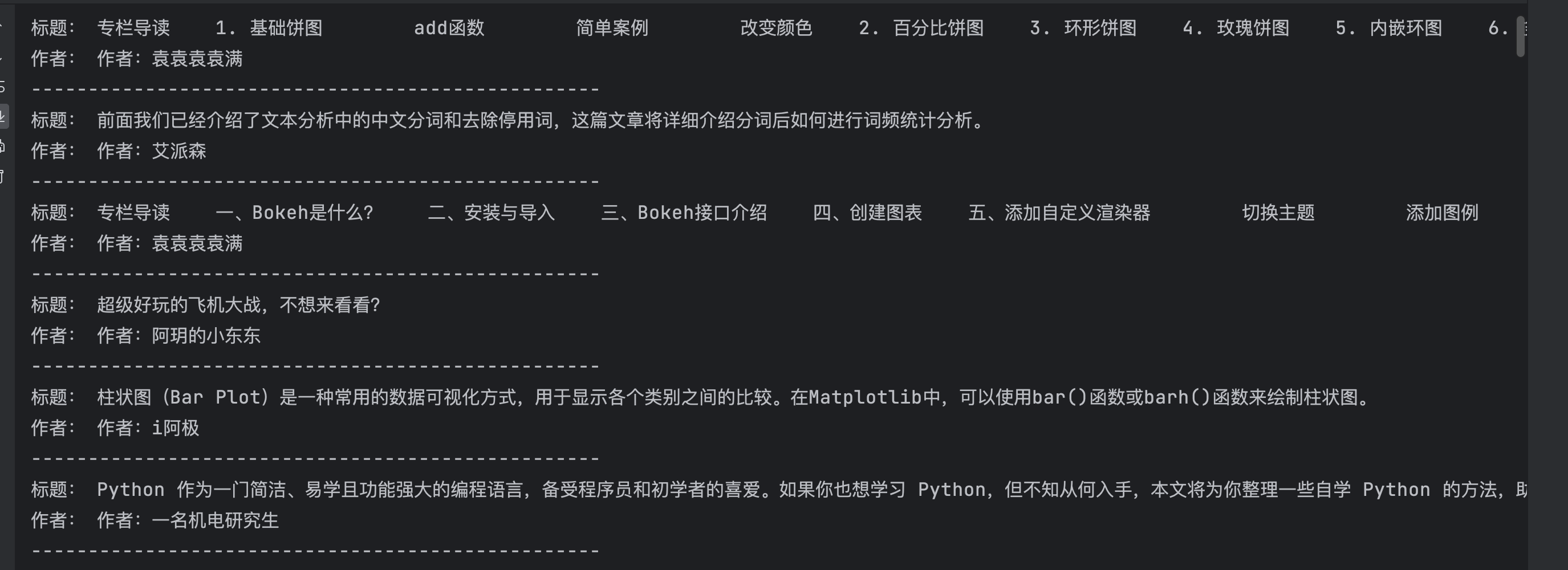
代码中,我们使用requests库发送HTTP请求获取网页内容,然后使用lxml库的etree模块将HTML源代码转换为可解析的树形结构。接下来,我们使用XPath路径表达式来选择所需的节点,并通过xpath()方法提取出标题和作者等信息。
效果如图:
未完待续…