java 八股文
java篇
java 面向对象有哪些特征
封装 多态和继承
arrayList 和 LinkedList 的区别
数据结构不同,一个是数组一个是链表
arrayList 适合 随机访问 读多,插入和删除少
LinkedList 适合插入 和删除 多,按次序遍历的情况
再有 数组的扩容 ,以及容器的继承体系可以参见我的博客 java 容器
对象的创建过程
申请空间 设置默认值,调用init 方法 将 按照类中声明的次序,依次执行所有域初始化语句和初始化代码块。最后在使用 构造方法初始化
可以结合 volatitle 考察 指令重排序 带来的 并发问题,比如 构造工厂 双检查 之后 对象空指针的问题
在多说两句 synchronized 是保证不了 重排序(保证最终一致性) 和 可见性(可见性的保证是通过串行化保证的,但是一个进入锁的代码块,一个不进入锁的代码块,这种可见性是保证不了的,是volatitle 的工作)。
对象在内存中的存储布局
-
对象头: markword( 哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等 ) 占 8个字节 类型指针占4个字节
markword详细信息解释
-
成员变量具体占几个字节视具体情况。
-
最后补全的话,是 保证大小能被8整除。

对象是如何通过引用定位的
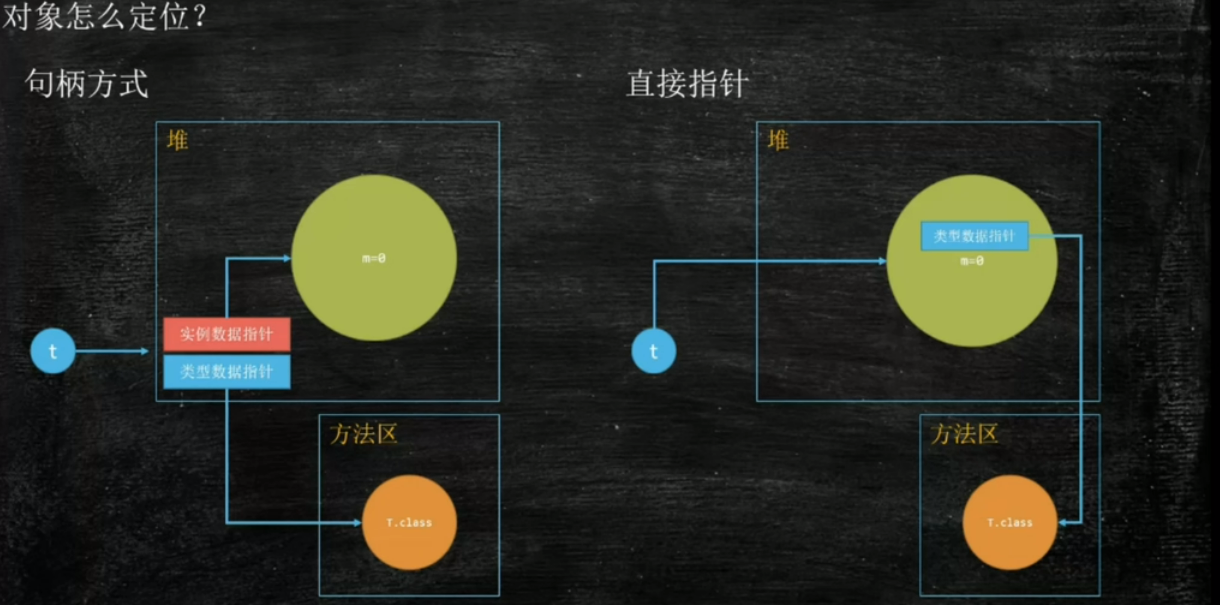
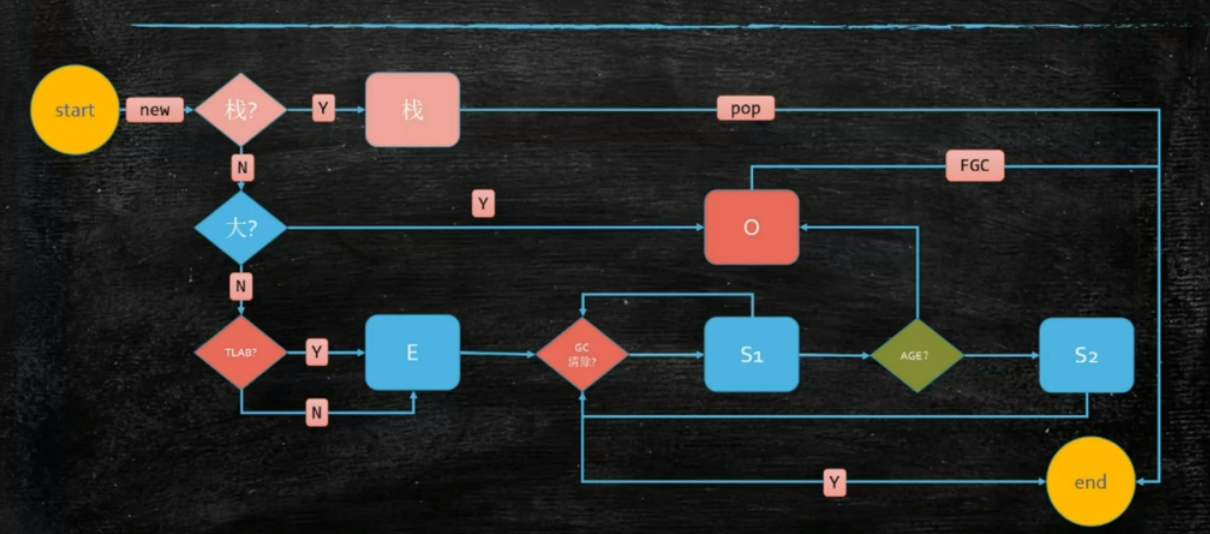
对象怎么分配
刷新了概念,对象也可以在栈上分配,关键是什么时候不能在栈上分配呢(1. 对象的大小比栈帧 2 逃逸分析)
TLAB的全称是Thread Local Allocation Buffer,即线程本地分配缓存区。创建对象时,需要在堆上为新生的对象申请指定大小的内存,如果同时有大量线程申请内存的话,可以通过锁机制确保不会申请到同一块内存,在JVM运行中,内存分配是一个极其频繁的动作,使用锁这种方式势必会降低性能。
所以就出现了TLAB,JVM通过使用TLAB来避免多线程冲突,每个线程使用自己的TLAB,这样就保证了不使用同步,也不会出现线程安全问题,提高了对象分配的效率。
synchronuzed 和lock 的区别
lock 是一个接口
lock 可以进行中断
lock 可以尝试获取锁
lock 使用codition 实现类似以 object 的 awit 和 notifiy
lock 加锁必须手动释放锁
ThreadLocal
Thread local
分布式篇
分布式id
uuid
数据库主键自增
redis 自增
雪花算法
雪花算法原理
分布式锁
redis 分布式锁
该算法仅仅适合 single 的 具体算法参见如下 Distributed Locks with Redis
SET resource_name my_random_value NX PX 30000
不存在的情况下设置(NX选项),过期时间为30000毫秒(PX选项)。resource_name my_random_value该值必须在所有客户端和所有锁请求中惟一。my_random_value 用来确保锁的属于者
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
锁存在并且属于自己后才释放锁。
zookeeper 分布式锁
mysql 做分布式锁
计数器算法
滑动窗口
漏铜限流算法
令牌桶限流算法
CAP定理
Consistency(一致性)Availability (可用性)Partition tolerance (分区容错性)
分布式中基本保持 ap 和 cp
- Zookeeper: 保证了CP
- Eureka: 保证了AP
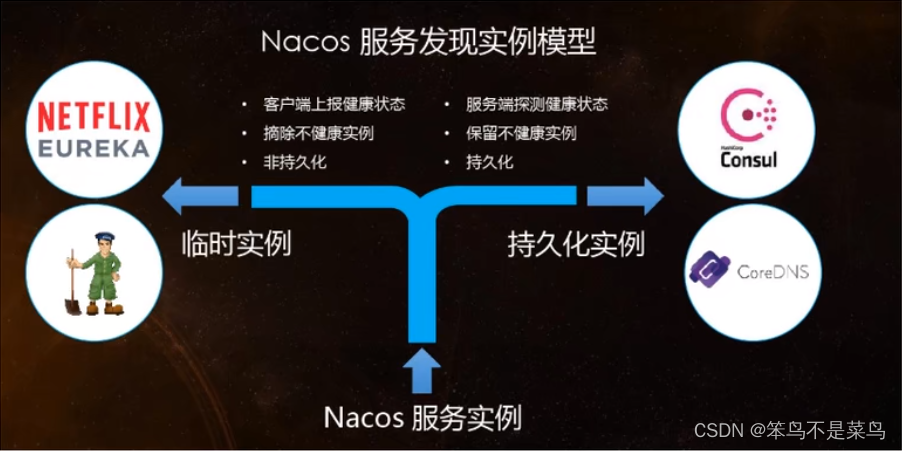
- Nacos: 既实现了CP,也实现了AP,可以自行根据业务场景选择使用哪个。
Base 理论
ASE是Basically Available(基本可用), Soft-state(软状态), Eventually consistent(最终一致)的缩写。
***两阶段提交
***三阶段提交
***tcc解决方案
可靠消息时服务(分布式消息)
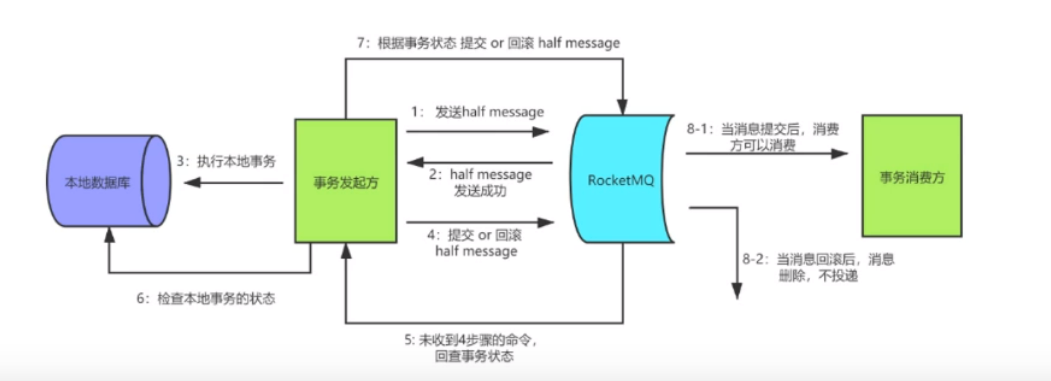
幂等
双写一致性
nacos 原理
nacos 原理
Ribbon 原理
Ribbon 原理
spring security 原理 + spring security oauth 原理
spring security 专栏
JVM 篇
***java垃圾回收器
常见的垃圾回收算法
- 引用计数法 (无法解决循环引用问题)
- 可达性分析算法(跟引用 用来解决循环引用问题)
- 标记清除法(碎片化比较严重,还需要暂停应用程序)
- 标记压缩算法
- 复制算法(垃圾对象少的话是不合适的,需要大量的复制)
- 分代算法
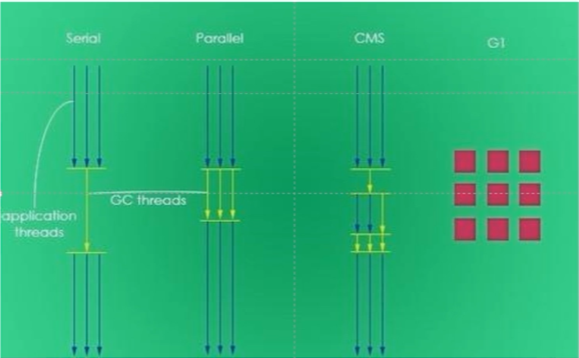
垃圾收集器的种类
serial parallel CMS G1
redis篇
redis 持久化之 rdb 和aof
参见 redis 的 RDB 和 AOF
Redis的过期键删除策略 回收策略
具体参见 过期删除策略
Redis密钥有两种过期方式:被动方式和主动方式
当客户端试图访问密钥时,发现密钥超时,密钥就会被动过期。
当然,这是不够的,因为存在永远不会再次访问的过期密钥。这些键无论如何都应该过期,所以Redis定期随机测试有过期设置的键中的几个键。所有已经过期的键都将从键空间中删除。
具体来说,Redis每秒做10次:
从一组具有相关过期时间的键中测试20个随机键。
删除所有过期的密钥。
如果超过25%的密钥过期,则从步骤1重新开始。
这是一个简单的概率算法,基本上假设我们的样本是整个密钥空间的代表,我们继续过期,直到可能过期的密钥的百分比低于25%
这意味着在任何给定时刻,正在使用内存的已经过期的键的最大数量等于每秒写操作的最大数量除以4。
Redis的回收策略.
参见 Key eviction
# 配置最大内存 将maxmemory设置为零将导致没有内存限制。这是64位系统的默认行为,而32位系统使用3GB的隐式内存限制。
maxmemory 100mb
当到达指定内存空间时,就会触发报错或触发内存回收机制
- noeviction: New values aren’t saved when memory limit is reached. When a database uses replication, this applies to the primary database
- allkeys-lru: Keeps most recently used keys; removes least recently used (LRU) keys
- allkeys-lfu: Keeps frequently used keys; removes least frequently used (LFU) keys
- volatile-lru: Removes least recently used keys with the
expirefield set totrue. - volatile-lfu: Removes least frequently used keys with the
expirefield set totrue. - allkeys-random: Randomly removes keys to make space for the new data added.
- volatile-random: Randomly removes keys with
expirefield set totrue. - volatile-ttl: Removes keys with
expirefield set totrueand the shortest remaining time-to-live (TTL) value.
redis 的集群方案
主从复制集群 : 主从复制集群(手动切换主从) 哨兵
分片集群: 客户端实现路由索引的分片集群,中间件的分片集群,cluster分片集群
redis 主从复制
参见 redis 的主从复制 与 sentinel 模式
redis 缓存的雪崩 缓存的击穿 缓存的穿透在实际中如何处理
缓存的穿透 : 缓存没有 数据库也没有,解决办法,可以给一个默认值
缓存击穿: 由于redis key 过期,导致大量请求进入redis,可以通过加锁 等方式单线程写保护 db,并辅以固定时间+随机值的 失效时间 降低大量失效的问题
缓存雪崩同缓存击穿问题类似
mysql篇
隔离级别
脏写现象与读未提交(read uncommitted)隔离级别
事务 A 和事务 B 同时执行,它们都要对同一条数据进行修改(这条数据的值,假设为 data)。
- 首先是事务 A 将数据的值修改为 data1,暂时不提交事务;
- 然后事务 B 将数据的值修改为 data2,然后立马提交事务;
- 事务 A 可能由于自己的业务系统出现了异常,因此进行回滚操作,将数据的值重新回滚为 data。
在这个过程中,事务 A 一个回滚操作,将事务 B 修改的值也回滚了,一夜回到解放前,事务 B 白忙活一场,这种现象叫做脏写。它的本质就是一个事务将另一个事务提交的修改操作回滚了。
显然在数据库中,肯定不允许这种现象存在。那么该如何解决这种问题呢?加个写锁就能解决,要对数据修改,必须要先获取到这行数据的写锁,否则不能修改。
在事务 A 开启时,对 data 加上写锁,直到事务 A 提交事务以后,才释放锁,在此期间,其他事务由于获取不到锁,也就谈不上对 data 数据进行修改了。
在实际的数据库中,则是将事务的隔离级别设置为读未提交(read uncommitted) ,在该隔离级别下,能保证事务提交之前,其他事务不能同时对这条数据进行修改。
脏读现象与读提交(read committed)隔离级别
事务 A 和事务 B 同时执行,事务 A 先将数据从 data 修改为 data1,然后暂时不提交事务,而是继续向后处理业务逻辑。
然后事务 B 读取这一行数据,读取到值为 data1,然后基于 data1 这个值去处理自己的业务逻辑了。
接着事务 A 在处理后面的业务逻辑时出现了异常,因此要进行回滚操作,将数据从 data1 回滚为 data。
在这个过程中,当事务 B 再去查询时发现数据的值为 data,这就蛋疼了,本来是基于 data1 这个值去做的业务逻辑处理,结果现在发现值却是 data,完蛋了,全 NM 错了,这种现象就是脏读,它的本质就是一个事务读到了另一个事务未提交的值。
为了解决脏读的问题,数据库中定义了读提交(read committed) 隔离级别,它的意思就是,在读数据的时候,只能读到别的事务提交过后的值,对于未提交的事务对数据所做的修改操作,当前事务是无法读取到的。
在读提交的事务隔离级别下,当事务 B 去读取数据时,发现事务 A 还没有提交,因此它不能读取到 data1 这个值,只能读取到 data 这个值。
不可重复读现象与可重复读(repeatable read)隔离级别
假设现在数据库中事务的隔离级别为读提交,也就是未提交的事务修改的值,其他事务是读取不到的,那么在当前事务隔离级别下还会有其他问题吗?
事务 A 和事务 B 同时开启事务,事务 A 先从数据库查询数据,读取到的值为 data,然后事务 A 先不提交事务。
接着事务 B 修改数据,将数据的值从 data 修改为 data1。
如果事务 B 先不提交事务,那么事务 A 此时来读取数据时,能读取到最新的值 data1 吗?不能,因为我们假设了此时事务的隔离级别处于读提交状态。
好,既然不能事务 A 不能读取到最新值,那么现在事务 B 提交事务,接着让事务 A 再次从数据库查询数据,此时能读取到最新的值吗?
能,此时读取到的值为 data1,因为事务 B 已经提交了事务,在读提交的隔离级别下,提交了的事务,其他事务都能读取到最新的值。
但是这有问题啊!在同一个事务内(事务 A),它读取了两次数据,发现前后两次读取到的值分别是 data 和 data1,同一行数据,读到的值却不一样,事务 A 此时心里可能 MMP 了,干啥啊,忽悠我呢!
实际上这就是不可重复读现象,它的本质就是在同一个事务内,多次从数据库读取数据,读取到的值不一样。(注意不可重复读与脏读的区别:脏读是指读到了未提交事务的值,不可重复读指的是其他事务更新数据并提交后,自己前后读取到的数据不一致)
因此,可重复读(repeatable read) 事务隔离级别出现了,它的意思是,在同一个事务内,例如事务 A,多次从数据库读取数据时,每次读取到的值是一样的,即使在此期间有其他事务修改了这条数据的值,也不会导致事务 A 前后两次读取到的值不一样。
幻读现象与串行化(serializable)隔离级别
假设事务 A 和事务 B 并发执行,首先事务 A 先执行了如下 SQL,假设查到了 1 条数据.
然后事务 A 又使用同样的 SQL 语句查询数据,这时会查询出来 11 条数据,比之前查出来的数据多,也就是说看到了更多的数据,这种现象就是幻读。
注意幻读与不可重复读的区别:幻读特指在同一个事务内,前后两次查询,后面的查询,读到了之前没看到的数据;而不可重复读指的是在同一个事务内,针对同一行数据而言,前后两次查询,读取到的值不一样。
为了解决幻读的问题,数据库提出了串行化(Serializable) 这种事务隔离级别。
那么什么是串行化呢?归根结底,出现脏写、脏读、不可重复读、幻读这些问题,都是因为并发导致的,那要一下子全部解决这些问题,最简单的办法就是不要让线程并发执行,让多个线程一个一个执行,也就是串行化(也就是不让并发出现,都没有并发了,也就没有脏写、脏读、不可重复读、幻读这些幺蛾子了)。
| 脏写 | 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|---|
| 读未提交 | √ | |||
| 读提交 | √ | √ | ||
| 可重复读 | √ | √ | √ | |
| 串行化 | √ | √ | √ | √ |
mvcc
菜鸟飞呀飞的文章连接
林晓斌 mysql 45讲
密码 84pc
锁
表锁 行锁 全局锁 间隙锁
***mysql 复制的原理
redo log —— MySQL宕机时数据不丢失的原理
索引
主键索引
聚簇索引
回表
覆盖索引
唯一索引 普通索引 (建议优先使用)
sql 的优化
join 的优化
order by 的优化
最左原则