前言
String str1 = "明天吃红烧肉";
String str2 = "明天中午吃红烧肉";
String str3 = "明天吃红烧肉?";
String str4 = "吃红烧肉";
用普通的相等判断,只能得到是或否,但如果你在实际的业务需求中,有需要用到两个字符串的相似程度,做进一步的逻辑判断,那么在 Java 的轮子里,我推荐你使用 java-string-similarity
我只讲有用的部分:怎么拿到两个字符串的相似值,我浏览了一下我自己查找资料时所看的博客,有用的关键部分全都七零八落,所以看完这篇文章,保证你开箱即用,我会直接推荐一个我实际应用的相似度算法,并写一个demo
java-string-similarity
你只需要知道,这是个提供各种字符串相似度算法的三方库就好了,总共有十几种算法供君选用,我推荐在我看来,实际意义最大的一个算法:Jaro-Winkler,其他的算法还不如去搞elasticsearch
Jaro-Winkler
基于两个字符串之间的公共字符的数量和顺序,它考虑了典型的拼写偏差,使用前缀比例,对从头匹配的字符串给予更大的权重
说人话就是,在我看来,这个算法,和普通人判断两个字符串的相似程度的逻辑是一致的,头部越像,权重越高,尾部相像,权重不大
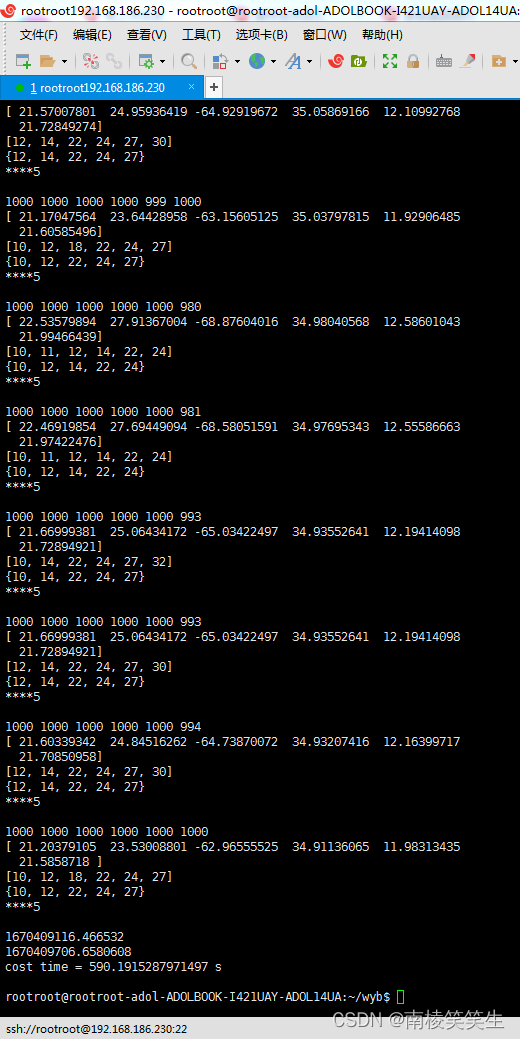
先看下运行结果:

如果关键字在句子的后面部分,相似度会急剧下降,这种情况就需要你另外在java-string-similarity,找寻合适的算法了
demo
maven 引入
<dependency>
<groupId>info.debatty</groupId>
<artifactId>java-string-similarity</artifactId>
<version>2.0.0</version>
</dependency>
使用
public static void main(String[] args) {
JaroWinkler jaroWinkler = new JaroWinkler();
String str1 = "明天吃红烧肉";;
String str2 = "明天中午吃红烧肉";
String str3 = "明天吃红烧肉?";
String str4 = "吃红烧肉";
System.out.println(str1 + " 和 " + str2 + " 的相似度为:" + jaroWinkler.similarity(str1, str2));
System.out.println(str1 + " 和 " + str3 + " 的相似度为:" + jaroWinkler.similarity(str1, str3));
System.out.println(str1 + " 和 " + str4 + " 的相似度为:" + jaroWinkler.similarity(str1, str4));
}
希望有所帮助,完