【paper】 A latent factor model for highly multi-relational data
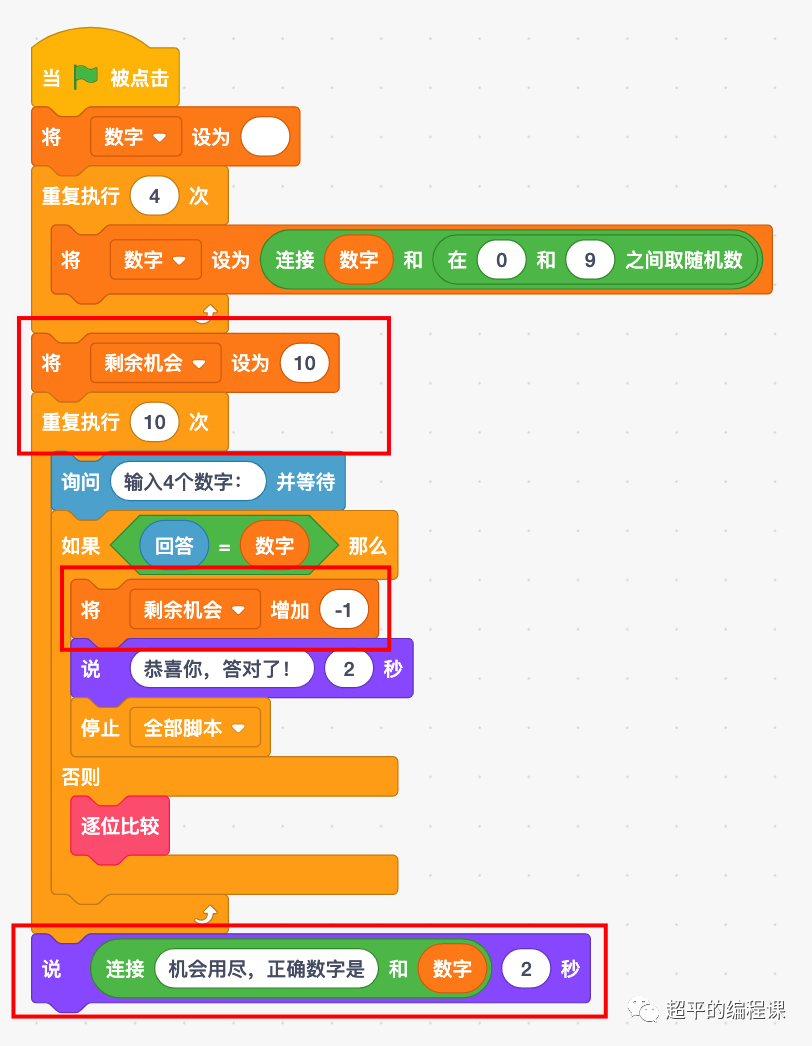
【简介】 这篇文章是法国的研究团队发表在 NIPS 2012 上的文章,还挂了 Antoine Bordes 的名字。文章提出了 LFM(Latent Factor Model),主要贡献有两点:一是定义了 unigram、bigram、trigram 三种方式组合的三元组打分函数;二是将关系矩阵分解为低阶矩阵的组合,这样可以实现参数共享。
其实这种比较老的论文的表达方式、行文结构跟现在的论文都不太一样,再加上时间有限,所以没有看太明白。但这类模型终究是要过一遍的,就这样吧。
模型
文章在 intro 部分介绍了统计关系数据建模的现存难点:
- 频繁出现的关系类型只是一小部分(长尾现象)
- 数据存在噪声并且不完整
- 数据集规模有限
文章称 LFM 是基于概率的,明确考虑了数据的不确定性。这里的不确定性应该不是指的实体和关系包含语义的不确定性,只是指对三元组进行概率打分。
早期的论文中三元组表示都是(subject, relation, object),若三元组成立,写作 Ri(Si,Ok)=1Ri(Si,Ok)=1。
表示及打分函数
logistic 模型进行了如下的定义:
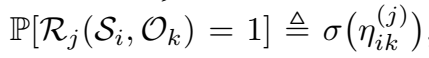
其中,ηik(j)ηik(j) 是一个线性函数:
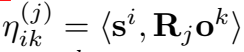
贡献一: 对打分函数 ηik(j)ηik(j) 进行了重新定义
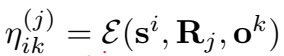
贡献二: 对关系矩阵进行分解
当关系数量比较多时,每个关系下的样本很少,容易引起过拟合。之前的模型曾经使用两种解决方法,一是聚类,二是用向量表示关系。与 RESCAL 的使用一个通用矩阵进行参数化的方法不同,本文提出的解决方法是将关系矩阵分解为 d 秩一矩阵(不知道这里的“一矩阵”是不是指对角矩阵){Θr}1≤r≤d{Θr}1≤r≤d。

分解的稀疏性和 d≪nrd≪nr 可以保证不同关系的参数共享。
Loss
模型训练的目标是最大化下面的 likelihood:
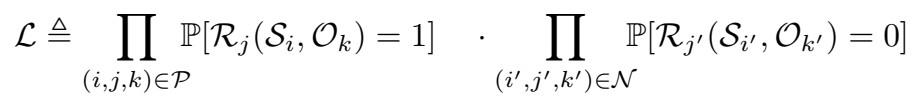
经过推导,可以得到 log-likelihood:
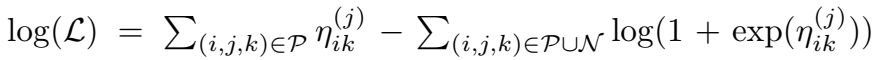
上午推导了一下,前半部分没有对上,可能中间有近似约减消掉的项。
训练目标等价于最小化负的 log-likelihood:

实验
和 RESCAL 一样,在 Kinships、UMLS、Nations 数据集上进行了实验,与 RESCAL、MRC 和 SME 三个 baseline 对比了 AUC 和 log-likelihood。

除了进行关系数据建模,实验部分还学习了动词的语义表示。这部分没细看。
代码
没有代码。
【总结】 本文定义了 unigram、bigram、trigram 进行组合的线性打分函数,并对关系矩阵进行分解实现参数共享。
双线性模型(一)(RESCAL、LFM、DistMult) - 胡萝不青菜 - 博客园