背景介绍
随着 IT 技术与大数据的不断发展,越来越多的企业开始意识到数据的价值,通过大数据分析,可以帮助企业更深入地了解用户需求、更好地洞察市场趋势。目前大数据分析在每个业务运营中都发挥着重要作用,成为企业提升市场竞争力的关键举措之一。通常企业会构建数据湖仓,将多个数据源通过数据集成技术,汇集一起进行数据分析。由此,数据集成成为了构建数据湖仓的必经之路,然而企业在数据集成过程中却面临很多棘手问题。
- 全量+增量数据集成割裂。
传统的数据集成大多仅支持全量数据,对于全量+增量的一并集成,则需要分别部署链路,获取到数据后再手动合并。
- 多个数据源头,操作与维护复杂。
表结构频繁变更,无法自动同步表结构变更到数据湖仓,手动维护成本高。另外无法”一键”整库同步,追加同步对象操作复杂等。
- 数据获取时效性差。
传统的数据集成技术建模路径较长,按照T+1的方式同步到数据仓库中,时效性差。需要做到实时数据集成和分析,才能帮助用户根据最新的数据做出更快、更准确的决策。
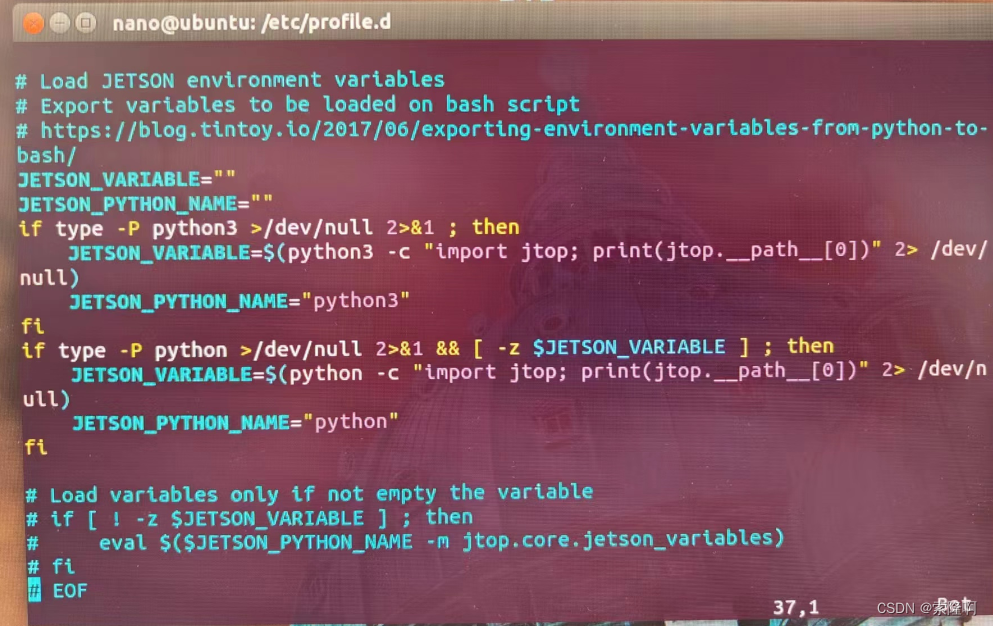
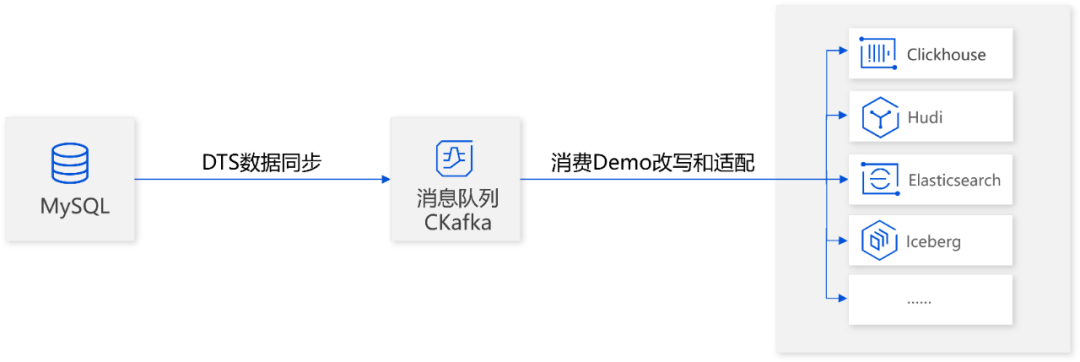
基于数据集成的核心痛点和用户诉求,近期腾讯云数据传输服务 DTS 联合 CKafka 重磅发布全新数据集成方案,该方案采取全增量数据一起的同步方式,将数据源先同步到 CKafka,再从 CKafka 消费数据投递到数据湖仓,可以有效帮助用户解决数据湖仓建设前期数据集成的问题。
基于 DTS 的数据集成方案
DTS 在做数据集成方案的初期,产研团队做了非常充分的调研,并分析出了用户的核心诉求,主要聚焦以下四个方面:
-
支持全量+增量数据同步:方便快速将全量+增量数据全部同步至下游数据分析工具中。
-
按序消费:数据消费时需要按照数据生产的顺序进行。
-
数据不丢失:数据在下游消费时至少要出现一次,不能丢失业务数据。
-
维护便捷:库表结构变更,或者库表对象追加需要方便操作。
DTS 的「数据订阅」模块可以应用于数据集成并分发到下游的场景中,但订阅模块主要处理增量数据,无法实现全量+增量一起同步。经过多次的技术探讨和验证后,我们最终决定基于「数据同步」模块来做数据集成,技术方案:数据源先通过 DTS 同步数据到 CKafka,再从 CKafka 消费数据投递到数据湖仓。
不过实际落地中,我们还是遇到了一些挑战。
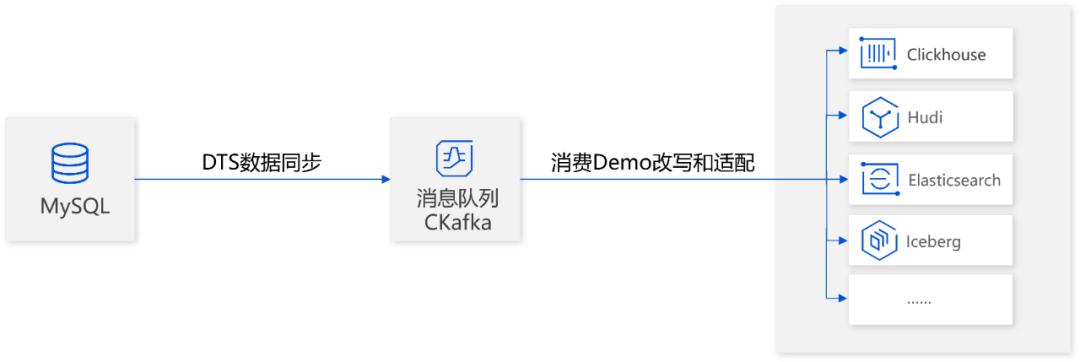
全量部分数据块很大,如何提升导出导入效率?
使用 DTS 数据同步模块来做数据集成,可以满足全量+增量一起同步的诉求,但在大数据场景下,又不得不面临两个问题:对于大表(如10亿行以上),如何提升同步作业效率?对于超大的存量数据,在全量阶段遇到任务中断时,如何确保数据重入?
基于以上问题,DTS 设计了分块导出方案,针对大表场景(如10亿行以上),从源库导出数据时将一张大表分为多个分块,一个分块连接一个线程,这样一张大表就可实现多分块同时导出,提升大表的同步效率。
在导入到目标 CKafka 时,也是按照分块导入的,同时这些分块都会进行标记,如果 CKafka 发生重启,可以根据标记来识别中断的分块位置,从中断的分块开始继续向目标 CKafka 写入。使用这个方式,在遇到 CKafka 异常时,就不需要从头重新写,大大提升用户体验。
多分区,如何保证按序消费?
为了提升用户消费的速率,消息投递到 CKafka 时一般采用投递到 CKafka 的多个分区的形式,多个分区可以并行消费以提升消费速率,但在多分区处理过程中,会涉及投递顺序的问题,需要保证投递到每个分区的消息与业务生产的消息顺序保持一致。
在实现中,DTS 向 CKafka 投递消息时,按照源库日志解析后的顺序来写入,因此可以实现写入 CKafka 顺序与业务生成顺序的一致。
- 全局顺序性
DTS 在拉取源库的 Binlog 日志时,采用单线程机制,先保证日志解析结果与业务生产顺序保持一致,等写入到 CKafka 的多个分区时,再按照多线程并发,最终实现了每个分区的消息都是按序排列。
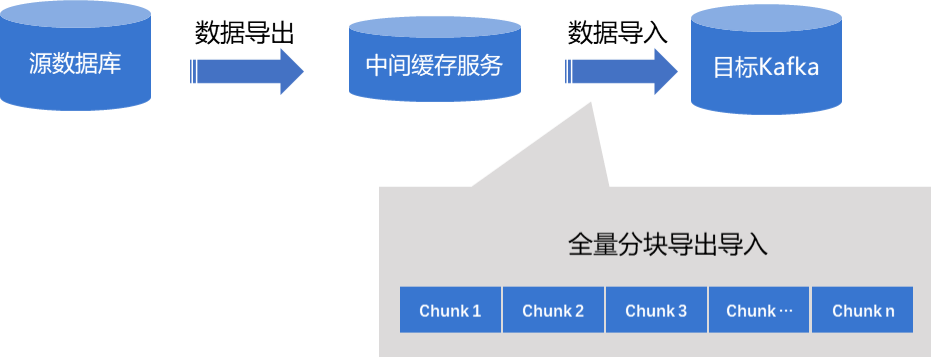
这里需要说明下,投递到多 Topic+ 多分区这种形式中,每个分区内的消息都是按顺序投递的,但是多个分区同时消费时,无法保证分区间按序消费,如果用户对消费到的消息顺序有严格要求,建议选择投递到单 Topic+ 单分区的形式。
- 表级别顺序性
在选择按表名分区的场景中,源库同一个表的数据变更都会投递到目标 Topic 下的同一个分区中,因为日志的解析是按序排列,所以投递到 Topic 分区中的消息也是按序排列。
总之, 不论选择哪种分区策略,DTS 都可以保证投递到各分区中消息的顺序性。
如何保证数据不丢?
要保证同步到 CKafka 的数据一条都不丢,那么所有的数据就需要有迹可循,哪些已经同步过了、哪些还没有同步过,都必须清楚可查。于是 DTS 通过对数据做标记,标识数据同步位置,以此来实现数据准确同步。
全量阶段,数据按照分块机制进行导出导入,DTS 导入到目标端 CKafka 的每个分块都会进行标记,CKafka 异常时,可以识别中断的分块位置继续导入。
增量阶段,DTS 内部处理源库的日志解析时会插入标记,来识别数据写入到 CKafka 的位置,如果任务中断再恢复,通过 DTS 内部标记,可以找到中断的位置,继续增量同步。
库表变更,能否灵活同步?
业务数据库经常会有库表结构的变更,而数据集成需要能识别并自动同步这些变更字段,否则,库表结构每变更一次,就需要手动改一次集成程序,这个维护工作量非常大。在 DTS 以前的链路传输中,库表结构变更的自动同步能力就已经具备了,直接集成即可。但是我们本次需要解决的是,当同步任务已经启动,用户想要追加/删除一个新的库表对象,如何做到一键化操作,让用户便捷维护。
这里,我们以追加一个表对象为例,同步任务已经在进行中,但是运行过程中发现需要新增一个表对象(例如表A),对用户来说,只需要在 DTS 任务列表页,进行一步可视化点击操作即可完成。
动态修改同步对象的过程中,其实 DTS 底层做了很多工作,对用户操作层面进行了简化,如上述操作案例:新增一个表对象(例如表A),DTS 需要同步表 A 的历史存量数据,同时,已有的同步任务1还不能受影响。所以在实现中,我们在 DTS 后台构造了一个临时任务2,来负责同步表A的存量数据,当任务2完成后,再将任务1和任务2合并,以此来实现动态追加同步对象的效果。
相对于一般的集成工具,DTS 在库表结构的变更,库表对象增加/删除等方面都是非常友好的,用户只需要在 Web 界面进行操作,一次配置,即可享受长期便利,大大减少用户的维护成本。
接下来,给大家重点介绍 DTS 的数据集成方案是如何配置的。
DTS+CKafka+数据湖仓 生产实践
实践场景
数据源头为 MySQL,通过 DTS 获取 MySQL 的全量+增量数据到消息队列 CKafka,然后适配消费 Demo,将消息投递到数据湖仓。
前期准备
-
准备腾讯云 CKafka 实例,并创建好消费组和消费 Topic。
-
准备源数据库 MySQL。
-
准备执行 DTS 任务的账号,并授权源库和目标库的对应权限。
-
准备数据湖仓。
数据同步
DTS 的操作比较简单,在腾讯云 Web 界面进行4个步骤即可,无需环境部署。
步骤1:创建 DTS 任务。
购买一个 DTS 任务,源库选择 MySQL,目标库选择 CKafka。
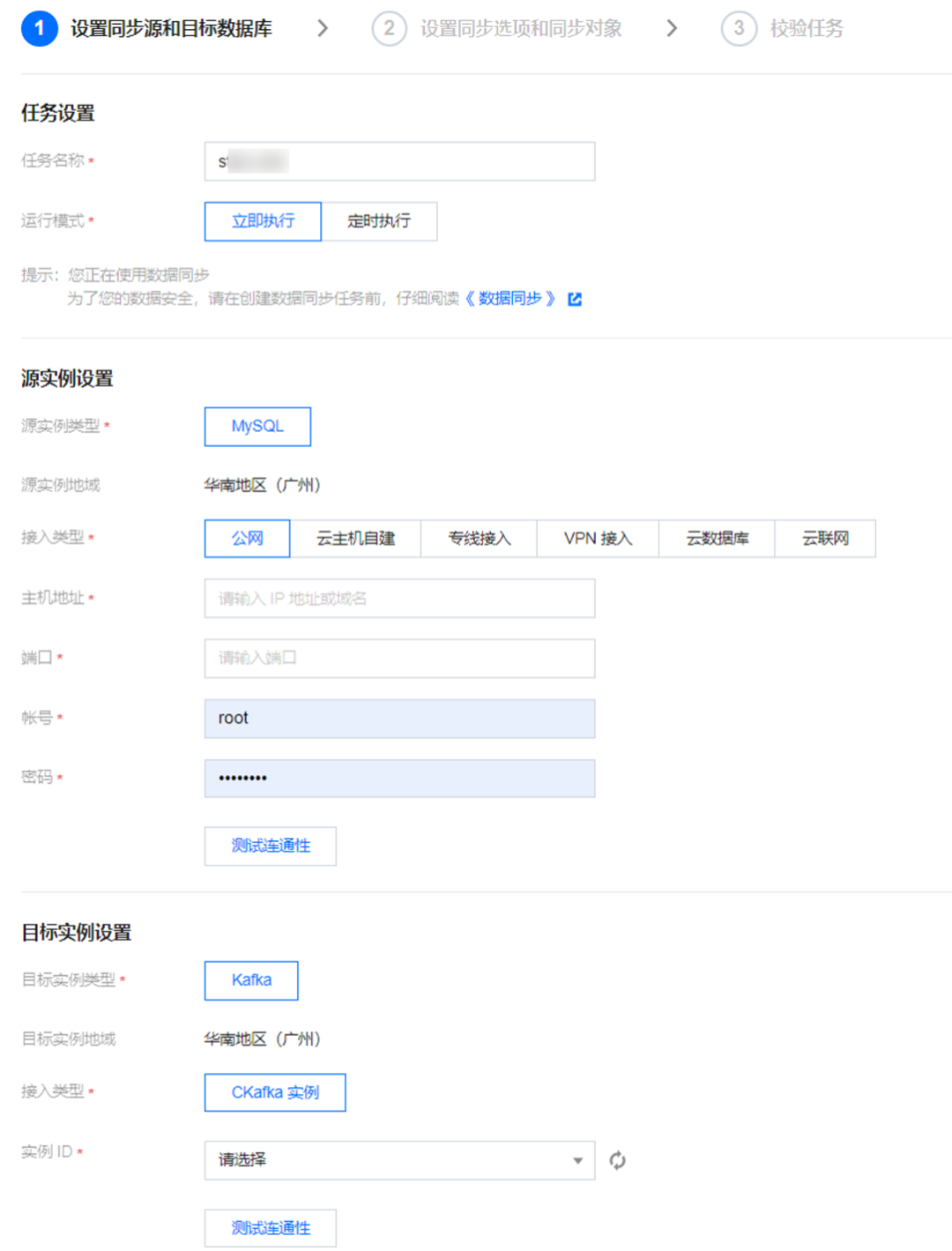
步骤2:设置同步源和目标数据库。
配置 DTS 连接源库和目标库,源库配置中填入 MySQL 的主机地址/端口/用户名/密码,目标库选择 CKafka 实例 ID。
这个步骤主要是验证 DTS 到源和目标库的网络是否打通,对应的用户权限是否满足要求,如果源库有安全组设置需要允许 DTS IP访问,否则网络不通。
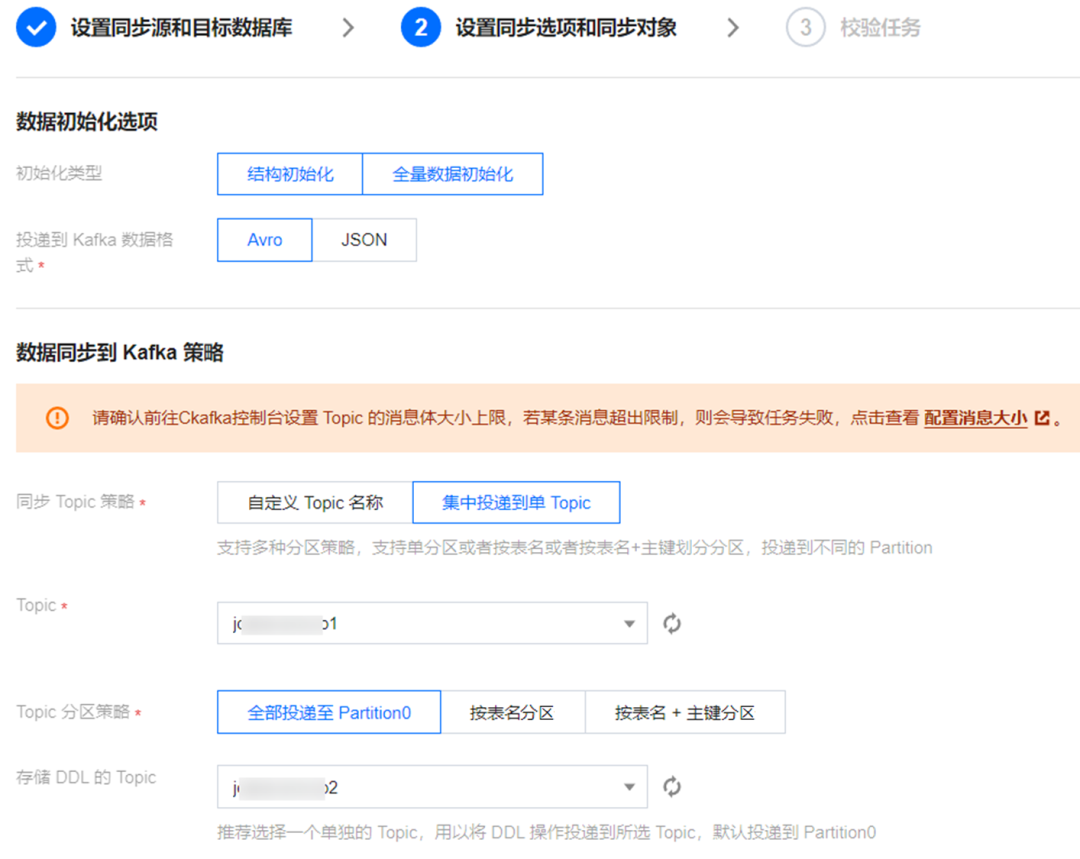
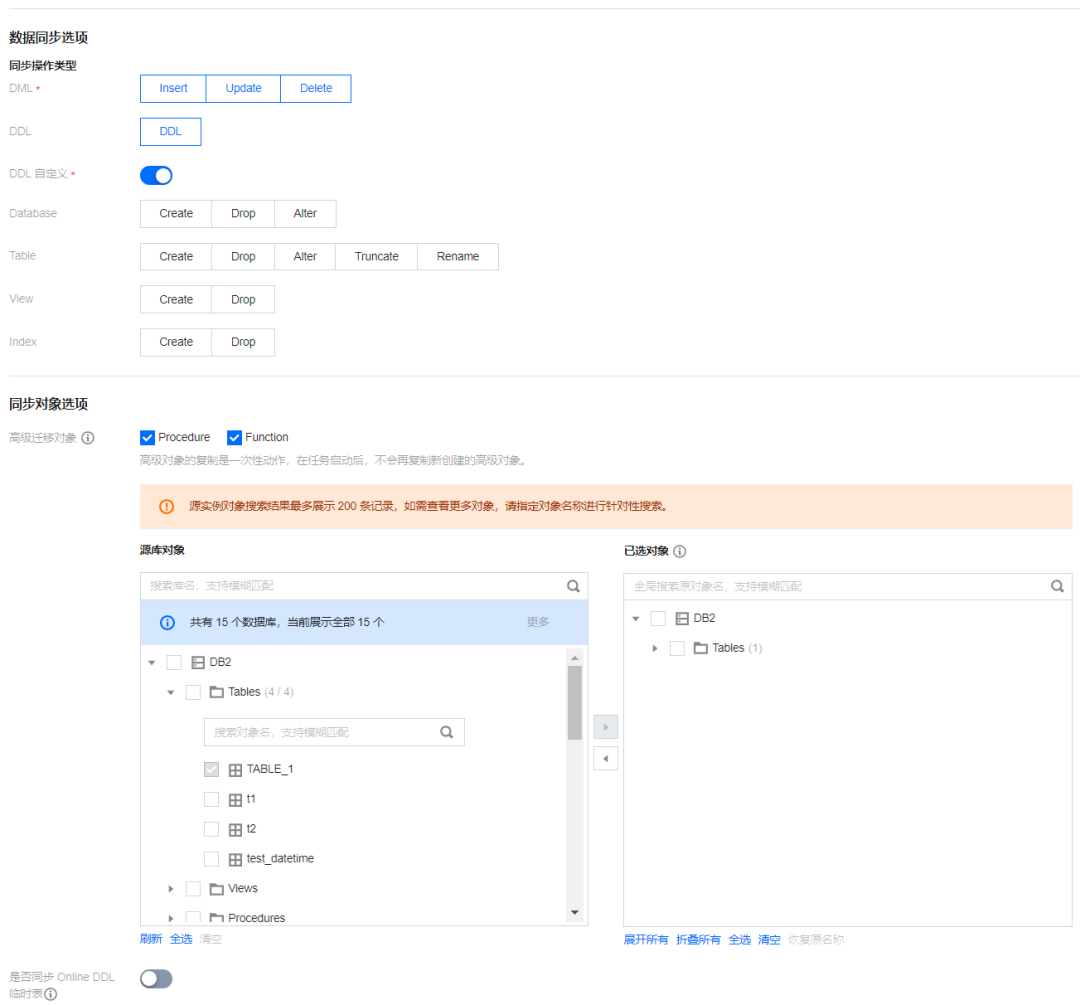
步骤3:配置数据同步选项。
这个步骤主要是选择同步的数据格式(Avro、JSON)、数据投递到 CKafka 的哪个 Topic 下、分区策略等。
-
对于库表结构的变更,一键勾选 DDL,即可在后续自动同步库表结构的变更数据。
-
选定同步的库表对象后,如果有需要追加,在任务启动后通过修改任务即可添加。
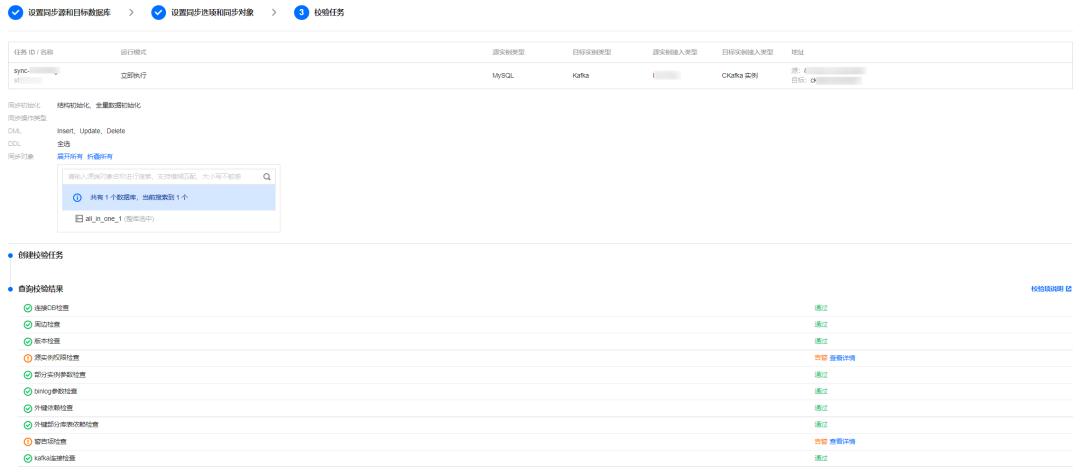
步骤4:校验任务。
上述配置完成后,DTS 会对源和目标库的各项参数进行预校验,如 Binlog 必须开启,并且 binlog_format 需要设置为 row 模式等等,以保证数据同步结果的正确性。
预校验通过后同步任务就可以启动了。
数据消费和投递
步骤1:下载消费 Demo 样例。
DTS 同步任务正常运行后,下载 DTS 消费 Demo 样例,将 Demo 包解压后运行,进行数据消费。
这里以 Go 语言为例,解压 Demo 包后运行 go build -o subscribe ./main/main.go,生成可执行文件 subscribe。
然后运行 ./subscribe --brokers=xxx --topic=xxx --group=xxx --trans2sql=true。这里的 Brokers、Topic、Group 分别填入 CKafka 的地址、消费 Topic 名称、消费组名称。
运行结果显示如下,表示 CKafka 正常连接,消费链路已打通。

步骤2:测试数据结果。
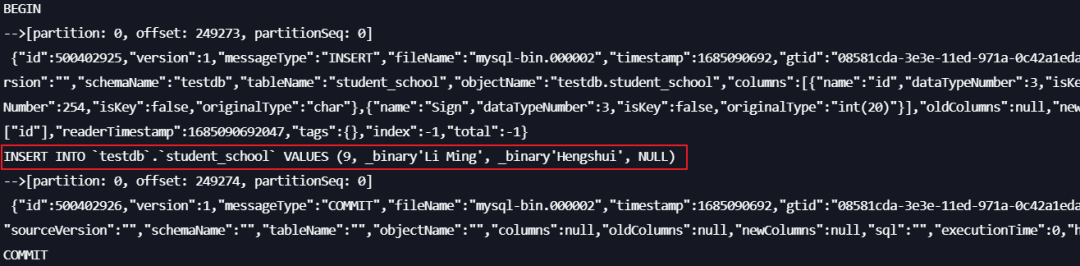
在源数据库上插入一条数据。
INSERT INTO student_school (id, name, school_name) VALUES (9, 'Li Ming', 'Hengshui');
在消费端即可查看到对应数据。
步骤3:修改 Demo,增加适配到后端数仓的代码逻辑。
DTS 提供的消费 Demo 仅对数据做了打印处理,用户需要在 Demo 基础上自行编写数据处理到后端数据湖仓的适配逻辑。
实践效果
使用 DTS 同步到 CKafka 的链路形式替代之前使用 Canal 组件的链路,最终实现高性能传输、高稳定性保障的同时有效降低了运维成本。
-
传输性能高:DTS 的传输性能与用户实际网络延时、带宽、数据本身的规格配置都有关系,在用户源端和目标端规格都比较高,网络无瓶颈的情况下,项目实测 DTS 全量阶段的 RPS 最高可达30万/s,增量阶段最高可达1.5万/s。
-
稳定性强:DTS 可提供高 SLA 保证,任务稳定性极强。
-
运维成本低:用户之前使用 Canal 组件时,平均每月大概需要半个人力投入到研发和运维中,改用 DTS 后,任务配置完成后基本无需运维人员投入,大大减少运维成本。
DTS 提供的同步到 CKafka 数据集成方案具有通用性,目前已成功应用在出行、零售、游戏、互联网、金融等多个行业,并收获了用户的良好口碑。
总结和展望
DTS 目前已上线了 MySQL 系列数据库同步到 Kafka 的链路,为用户在大数据集成中提供了便捷的技术通道,后续为了满足用户更多的需求和更高的使用体验,DTS 和 CKafka 将聚焦「数据库生态」和「产品体验」上持续发力。
-
数据库生态方面:持续拓宽数据库生态,支持其他类型的数据库同步到 CKafka,如MongoDB,Oracle,PostgreSQL 等同步到 CKafka。
-
产品体验方面:支持更多高阶特性,如全量阶段支持数据可重入,投递到多 Topic 的策略优化等等。