1. 线程池的概念
1.1 什么是线程池?
线程池也是一种线程的使用方式,前面刚开始学习多线程的时候,我们了解到线程太多,会带来 CPU 的调度开销。
以前我们都是一个线程执行一个任务(一个run方法),就好比搬砖,有100 块砖,可以搞 100 个人,每人搬一块砖,但是这 100 个人的人工费需要花钱呀,也可也一个人搬 100 块砖,慢是慢了点,但是省钱呀!
而线程池这里面维护着多个线程,等待咱们程序猿分配需要执行的并发任务即可!
1.2 为什么需要线程池?
随着程序并发程度的提高,也随着我们对性能要求的标准提高,发现线程的创建也没有那么的轻量化,当我们需要频繁的创建和销毁线程的时候,其实开销还是不小的。
那么如何才能进一步提高效率呢?
搞一个"轻量级线程":协程/纤程 (目前Java 标准库还没有)
使用线程池,来降低创建/销毁线程的开销。
线程池主要就是事先把要使用的线程创建好,放到池子中,需要使用的时候,直接从池里取,用完了,还给池子就行。
取和还 就对比线程 创建和销毁 为什么取和还,比创建和销毁要更高效呢?
因为线程的创建和销毁是交给操作系统内核来进行的!
从池子里取和还是我们自己用户代码就能够实现的!
举个例子:
我上大学的时候,生活费都是俺妈负责给的,都是每个月给一次,所以每次在学校生活一个月后,生活费用完了,都要去找我妈要生活费,现在我要去找我妈要生活费了,我给我妈发消息说:"你的儿子电量不足了!",如果我妈此时在玩手机那还好,收到我的消息后,就能把钱转给我,如果我妈在打牌!那问题就大了,她大概率看不到手机消息。
我现在正饿着肚子呢,我啥时候能吃上饭呢?取决于我妈啥时候打完牌!
啥意思呢?当我向内核申请创建一个线程的时候(向我妈要生活费),内核可能在干其他事(我妈在打牌),并不会第一时间处理我的请求,啥时候处理呢?等他啥时候想起我,或者干完其他事了,比如利用 Thread 类创建/销毁一个线程可能会发生的情况!
于是我想,这样可不行,太麻烦了,干脆我跟我妈商量,让她把一年的生活费都打到一张银行卡上,这样我一个月生活费没了,就直接从银行卡上取就行,这可是随取随到啊,如果让我妈发给我,那还得看她现在忙不忙。
现在我从银行卡取钱,就是自主的,随取随用,就像程序中的"用户态",用户态执行的代码是咱们自己写的代码,想咋干取决于我们自己。
但是,有些操作还是需要通过"内核态"来完成的,比如我不会做饭,这个必须交给内核态(我妈)去完成了,一种间接的方式,内核态进行的操作都是在操作系统内核中完成的,内核会给程序提供一些 API 称为系统调用(比如Thread类),程序可以通过提供的 API 驱使内核完成一些工作,而系统调用里面的内容是直接和内核相关的,这一部分工作不受程序猿控制(我只是喊我妈做饭[调用 API ],我妈具体咋做我不清楚[内核的操作])。
话又说回来,相比如内核来说,用户态,程序执行的行为是可控的,想要某个工作,就会非常干净利落的完成(从池里取/还给池),要是通过内核,从系统这里创建线程,就需要通过系统调用了,让内核来执行,此时你不知道内核身上背负着多少任务,整体过程是不可控的!
所以,为什么需要线程池?本质就是减少创建线程和销毁线程的开销,让控制权交到程序猿手里!
2. Java 标准库自带的线程池
2.1 工厂模式
ExecutorService pool = Executors.newFixedThreadPool(10);通过 Executors.newFixedThreadPool(10); 这个操作就能创建拥有十个线程的线程池了。
这里创建对象的方法与我们之前所有不同,后续这里的 Executors.newFixedThreadPool(10) 这个操作,相当于是把 new 对象给隐藏起来了,使用某个类的静态方法,直接构造出一个对象出来,这样的方法就称为 静态工厂方法!提供这种方法的类,就叫做 工厂类,那么此处的代码,就使用了 工厂模式 这种涉及模式!
工厂模式用简单的话来说,就是使用静态方法来代替构造方法创建对象!
为啥要代替构造方法呢?因为我们有时候可能要构造多种对象,比如需要构造一个点:
可以使用笛卡尔坐标系提供的坐标来构造一个点:x,y
可以使用极坐标来构造一个点:r,α,(α 为角度,r为到原点的距离)
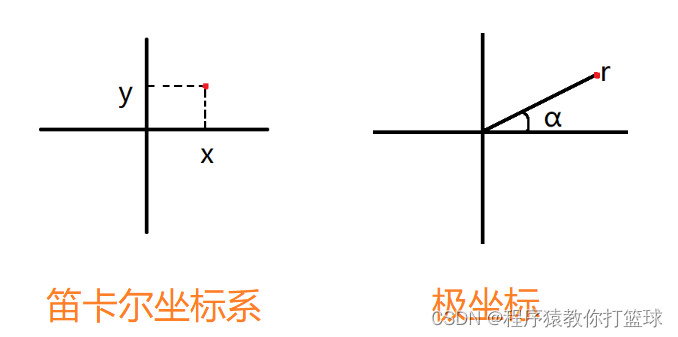
这里能发现,通过笛卡尔的方式构造点和通过极坐标构造点,他们的算法肯定是不同的!
那么如何写构造方法呢?
// 伪代码:
public Point(double x, double y) {
// 通过 x, y 来构造 Point 对象
}
public Point(double r, double a) {
// 通过 r, a 来构造 Point 对象
}这样肯定是会报错的,因为不构成方法重载的条件!
于是我们就想了用静态方法来代替构造方法:
// 伪代码:
public static Point makePointByXY(double x, double y) {
// 通过 x, y 来构造 Point 对象
}
public static Point makePointByRA(double r, double a) {
// 通过 r, a 来构造 Point 对象
}这样一来,我们要是在其他方法中想要通过笛卡尔坐标系创建点,就可以直接:
Point point1 = Point.makePointByXY(1, 2);
如果想使用极坐标创建点,就可以直接这样写:
Point point2 = Point.makePointByRA(1, 2);
如上我们就能通过静态方法,最终返回一个 Point 对象根据不同的方式来构造对象了!
2.2 简单使用线程池
线程池中,提供了 submit 方法,可以给线程池提供若干个任务!
public class MyThreadPool {
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(10);
for (int i = 0; i <= 1000; i++) {
int n = i;
pool.submit(new Runnable() {
@Override
public void run() {
System.out.println("hello + " + n);
}
});
}
}
}注意!上述我们不能直接打印 "hello + " + i,这个涉及变量捕获的语法,具体大家可以复习 JavaSE 语法知识,这里不多介绍。
上述我们的代码给线程池提交了 1000 个任务,这 1000 个任务交给线程池中的十个线程来完成,差不多一个线程执行 100 个 run 方法,但是这里真的有给每个线程分配 100 个任务吗?其实不一定分配的那么均匀!
每个线程会执行完自己的任务,再去取下一个任务执行,具体每个线程能执行多少次任务,都说不准,这个取决于 CPU 的调度。
本质上上述代码提交的 1000 个任务会被放入阻塞队列中,在队列中排队,线程池里的 10 个线程,就依次从阻塞队列中取任务,取到一个任务就执行,执行完了再去阻塞队列中取下一个任务...
如果队列中任务都执行完了呢?由于是阻塞队列,所以当队列为空,还想取元素就会进入 wait 等待状态了。
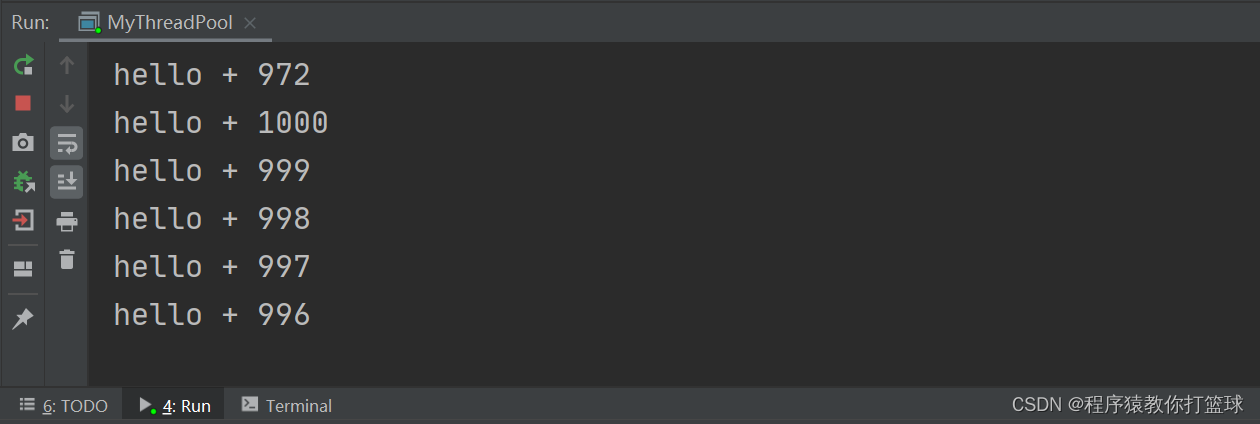
通过程序执行结果也能发现,执行完 1000 个任务之后,程序并没有结束。
3. 常见创建线程池的方法
Executors 类中的静态方法创建线程池:
newFixedThreadPool 执行要创建多少个线程
newSingleThreadExecutor 线程池里只有一个线程
newCachedThreadPool 线程数量是动态变化的,任务多了,就多搞几个线程,任务少了,就少搞几个线程
newScheduledThreadPool 类似于定时器,也是让任务延迟执行,只不过不是用扫描线程执行,而是由线程池里的线程来执行。
上述的这些线程池,都是通过包装 ThreadPoolExecutor 实现出来的,为什么要包装,本质还是因为 ThreadPoolExecutor 这个线程池使用起来太麻烦了,咱们程序猿不喜欢麻烦,所以才提供了工厂类,使用起来更简单!
4. ThreadPoolExecutor 类
4.1 构造方法
既然我们前面使用的工厂方法创建的线程池,本质都是对 ThreadPoolExecutor 类进行包装的,那我们多少得来研究研究这个类。
首先来看这个类的构造方法:
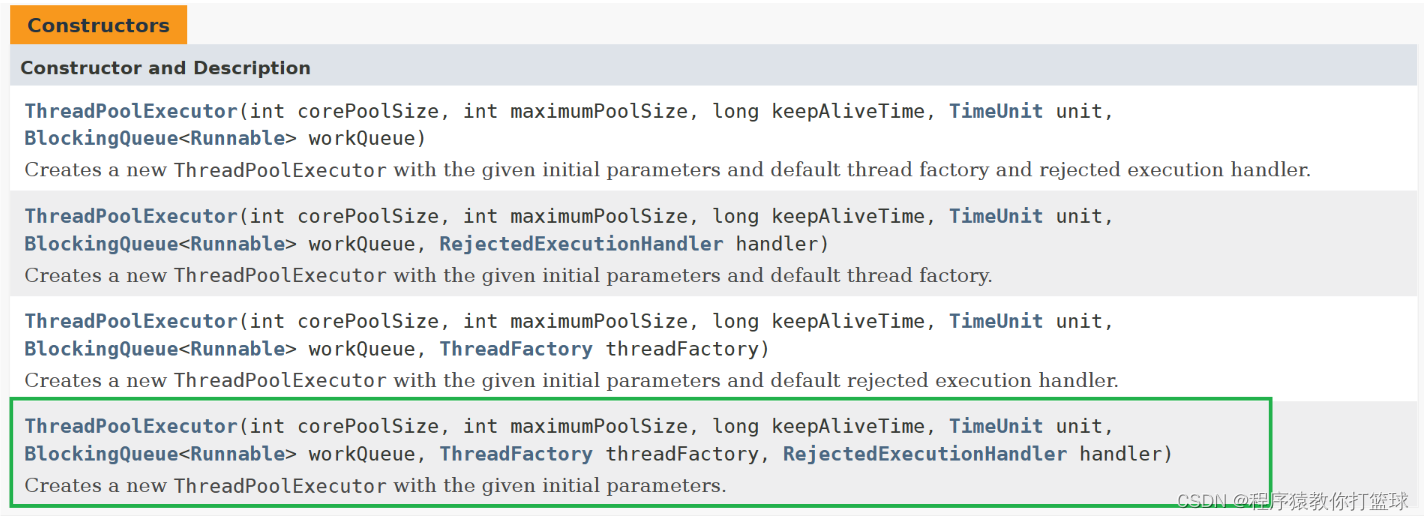
这里主要讲解最后一个构造方法,也是最复杂的构造方法,对于这里的构造方法来讲,咱们需要了解参数列表中形参分别所对应的位置!
● int corePoolSize 和 int maximumPoolSize:
corePoolSize 表示核心线程数量,ThreadPoolExecutor 把里面的线程分为了两类,核心线程和临时线程,这两个线程之和,就是最大线程数量也就是 maximumPoolSize。
如果用生活中的例子来看,就好比正式员工和实习生,可以允许正式员工摸鱼,但不允许实习生摸鱼,如果任务多,显然需要更多的人手(线程),此时就可以多搞一些线程,但是一个程序,不一定始终都有很多任务,有时候任务多,有时候任务少,如果任务少了,还是这么多线程,就不合适了,就需要对现有的线程进行淘汰,淘汰谁呢?正式员工(核心线程)肯定不能淘汰,那当然是淘汰实习生(临时线程)了!
这里就涉及到一个问题,如果以后碰到面试官问,线程池的线程数,设定成多少最合适呢?
网上可能有一些答案,但是这个问题没有准确个数,实际开发中的程序,既不是 CPU 密集型,也不会是 IO 密集型,往往是一部分吃 CPU,一部分吃 IO,具体这个程序吃多少 CPU,等待 IO 是多少?这是不确定的!所以我们需要在实践中确定线程的数量,通过实验/测试的方式,这也印证了一句话,实验是检验真理的唯一标准!
● long keepAliveTime:
描述了临时线程最大存在的时间,如果临时线程在某段时间没有事做,超过了这个最大时间,可能就会被销毁了!
● TimeUnit unit:
时间单位,可以指定s,ms,min
● BlockingQueue<Runnable> workQueue:
工作队列,线程池的任务队列(阻塞队列),为什么这里要用阻塞队列呢?想象以下,每个工作线程都是在不停的尝试 take(取任务),如果有任务就 take 成功,如果没有任务就阻塞...
● ThreadFactory threadFactory:
工厂,用于创建线程,线程池里面也是需要创建线程的!
最后还有一个属性,线程的拒绝策略(重点),这里我们需要单独领出来讲。
4.2 拒绝策略
RejectedExecutionHandler handler
描述了线程池的 "拒绝策略",也是一个特殊的对象,这个对象描述了当线程池的工作队列满了,如果继续添加任务会有啥样的行为!
而标准库给我们提供了四个可选的拒绝策略:
● ThreadPoolExecutor.AbortPolicy:
如果工作队列满了,还需要添加任务就直接抛出 RejectedExecutionException 异常。
● ThreadPoolExecutor.CallerRunsPoliy:
如果工作队列满了,多出来的任务,谁添加的,谁负责执行!
● ThreadPoolExecutor.DiscardOldestPolicy:
如果工作队列满了,丢弃最先注册的任务,最老的任务
● ThreadPoolExecutor.DiscardPolicy:
如果工作队列满了,丢弃最新的任务,也就是工作队列满了后添加的任务。
这里举个生活中的例子方便让大家更好的理解这四种拒绝策略:
假设我是一个大忙人,一天的任务安排的满满当当:
早上:陪小美逛街
中午:陪小花吃饭
下午:陪小宝贝看电影
晚上:陪小宇吃夜宵
这就好比工作队列的任务已经排满了,不能再添加任务了。
此时隔壁老王喊我傍晚去唱歌...
那么我就有四种解决方案:
第一种:本来我今天任务排满了,你还让我去陪你唱歌,简直想累死我,于是我特别生气,我直接躺平,哪都不去了!这就相当于抛出了异常,而且还不能陪小美,小花,小宝贝,小宇了!此时就好比线程池,你选择了 AbortPolicy 拒接策略,如果队列满了,还需要添加任务,就会抛异常,导致其他任务也都执行不了了。
第二种:谁让我去唱歌?老王让的,我拒绝陪他唱歌,因为我今天已经排的满满当当了,让老王自己唱歌去,这就好比选择了 CallerRunsPoliy 拒绝策略。
第三种:老王让我去唱歌啊?好啊,那早上就不陪小美逛街了把,养好精神从中午开始干活,毕竟傍晚还得陪老王唱歌呢!DiscardOldestPolicy 拒绝策略。
第四种:不去不去,与我无关。DiscardPolicy 策略。
当然我们计算机中线程工作队列要执行的任务可能是同一个时间点执行,也可能在不同的时间段执行,上述例子,是为了方便大家的理解,所以一定要结合具体情况具体分析!
5. 实现一个简单的线程池
接下来我们就来实现一个简单的线程池:固定数量线程的线程池!
public class MyThreadPool {
// 存放要执行的任务的队列
private LinkedBlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
public MyThreadPool(int n) {
for (int i = 0; i < n; i++) {
Thread t = new Thread(() -> {
while (true) {
try {
Runnable work = queue.take();
work.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
}
public void submit(Runnable runnable) {
try {
queue.put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}此时上述模拟实现的简单线程池里有一个阻塞队列用来存储要存储的任务,一共开辟 n 线程,循环从队列中取出任务并执行!
我们实现的很简单,主要是了解里面工作的思想!
下期预告:【多线程】锁策略