python年报爬取更新
本人测试发现,ju chao网的年报爬取距离我上一篇博客并没有啥变化,逻辑没变,应好多朋友的需要,这里补充代码
import json
import os
import requests
web_url = '改成网站的域名,因为csdn屏蔽'
def load_json():
with open("./stock.json", encoding="utf-8", mode="r") as f:
return json.loads(f.read())
def query_report(_stock, time_span):
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
data = {
'pageNum': '1',
'pageSize': '30',
'column': 'szse',
'tabName': 'fulltext',
'plate': '',
'stock': f'{_stock["code"]},{_stock["orgId"]}',
'searchkey': '',
'secid': '',
'category': 'category_ndbg_szsh',
'trade': '',
'seDate': time_span,
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
response = requests.post(
web_url+'/new/hisAnnouncement/query',
headers=headers,
data=data,
)
return response.json()
def download_pdf(d_url, _bank, _file_name):
resp = requests.get(web_url + d_url, verify=False)
if not os.path.exists(os.path.join(os.path.abspath("./"), _bank)):
os.mkdir(os.path.join(os.path.abspath("./"), _bank))
with open(f"./{_bank}/{_file_name}.pdf", mode="w", encoding="utf-8") as f:
f.write(resp.text)
def name_to_stock(_bank):
for item in stock_dic["stockList"]:
if item["zwjc"] == _bank:
return item
if __name__ == '__main__':
stock_dic = load_json()
bank_list = ["平安银行", "深南电A", "天健集团"]
for bank in bank_list:
stock = name_to_stock(bank)
if not stock:
print("[x]未找到该企业")
exit(0)
query_result = query_report(_stock=stock, time_span='2022-12-26~2023-06-27')
print(f"[*]搜索【{bank}】找到:")
for res in query_result['announcements']:
print(f"\t[*]{res['adjunctUrl']} {res['announcementTitle']}", end="")
download_pdf(res['adjunctUrl'], bank, res['announcementTitle'])
print(f"\r\t[*]{res['adjunctUrl']} {res['announcementTitle']} ........... ok")
print("下载完毕~")
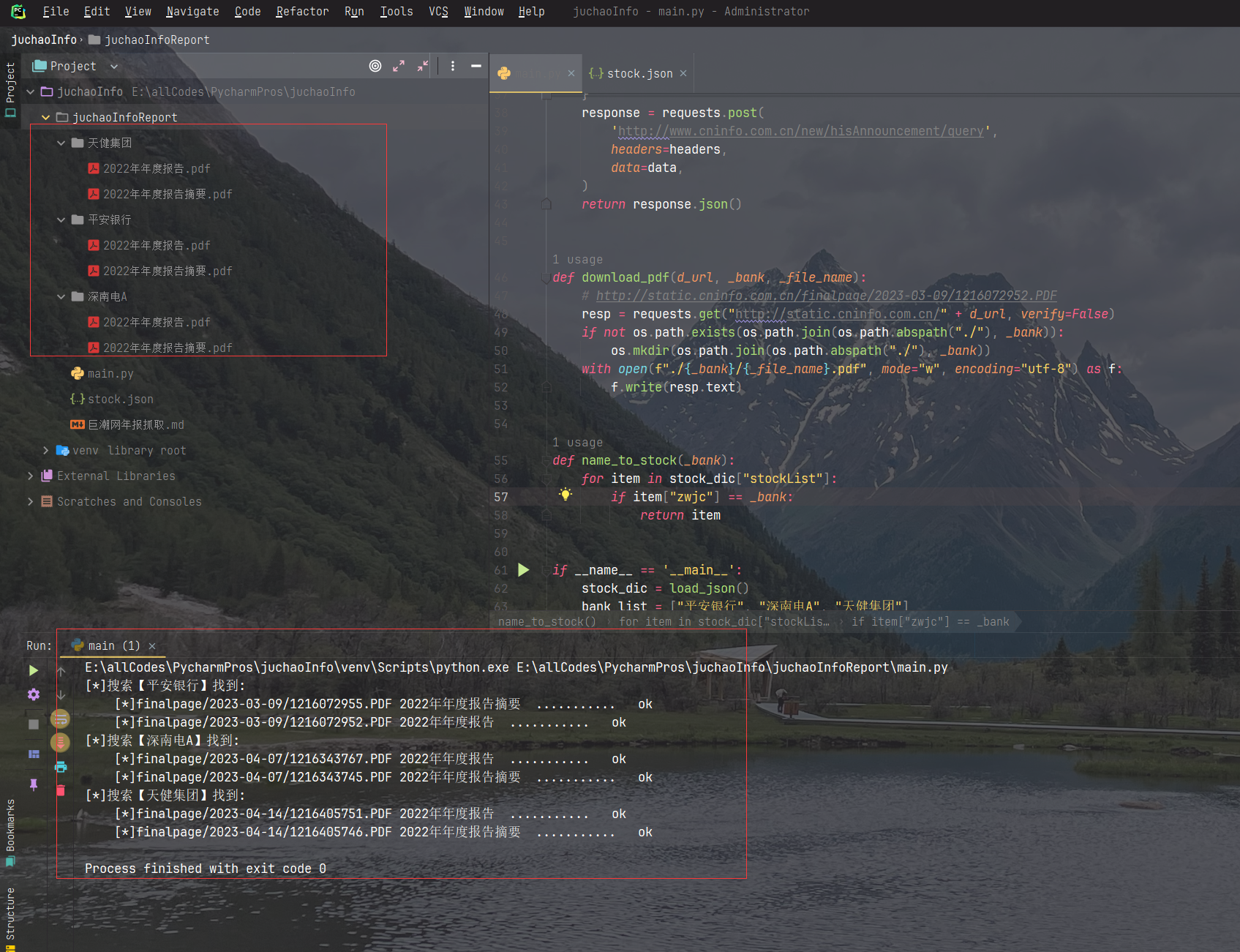
运行结果: