ChatDB: AUGMENTING LLMS WITH DATABASES AS THEIR SYMBOLIC MEMORY
返回论文和资料目录
论文地址
项目地址
1.导读
清华团队针对大模型LLMs的长期记忆能力进行的改进。改进思路是将LLMs与数据库结合,将信息以符号化的形式存储在数据库中。同时,使用大模型控制数据库的读写。每次与用户交互时,大模型都将结合数据库的信息,得到更优质和基于长期信息的回答。
2.摘要和引言
LLMs目前存在一个很大问题是缺乏长期记忆。
作者将目前解决这个问题的相关工作分为两类:
- 基于指令的记忆:将之前的历史文本和相应文本的 vector embedding 保存下来,需要的时候再利用 vector embedding 间的相似性找到相关的历史信息,然后放到 prompt 中,作为大语言模型的输入,相关的工作有 Auto-GPT 和 Generative Agents 等等。
- 基于矩阵的记忆:利用额外的 memory tokens 或者 memory matrices 来记录历史信息,相关的工作有 Recurrent Memory Transformer 等等。
作者认为上述工作的问题在于:
- 历史信息(记忆)的存储不是结构化的
- 这些信息不是符号化存储的
作者提出如下图所示的ChatDB。可以看到ChatDB主要由LLM控制器模块和记忆模块两部分组成。LLM控制器模块可以是目前主流的任何一个LLM模型,如ChatGPT、LLaMA等。它控制着记忆模块的读写。记忆模块可以是符号性的,也可以是非符号的,或者两者的组合,负责存储历史信息,并在需要时提供信息,以帮助LLM响应用户输入。但在这个工作中,作者专注于使用数据库作为符号记忆的存储介质。这个数据库的SQL语句将由LLM生成。

同时,本文提出记忆链CoM的方式来解决问题。它的思路是将一个用户输入的问题转化为多个步骤,每个步骤可能会使用多次SQL语句来帮助模型提升性能。这个CoM过程在ChatDB框架中例子如下图所示。
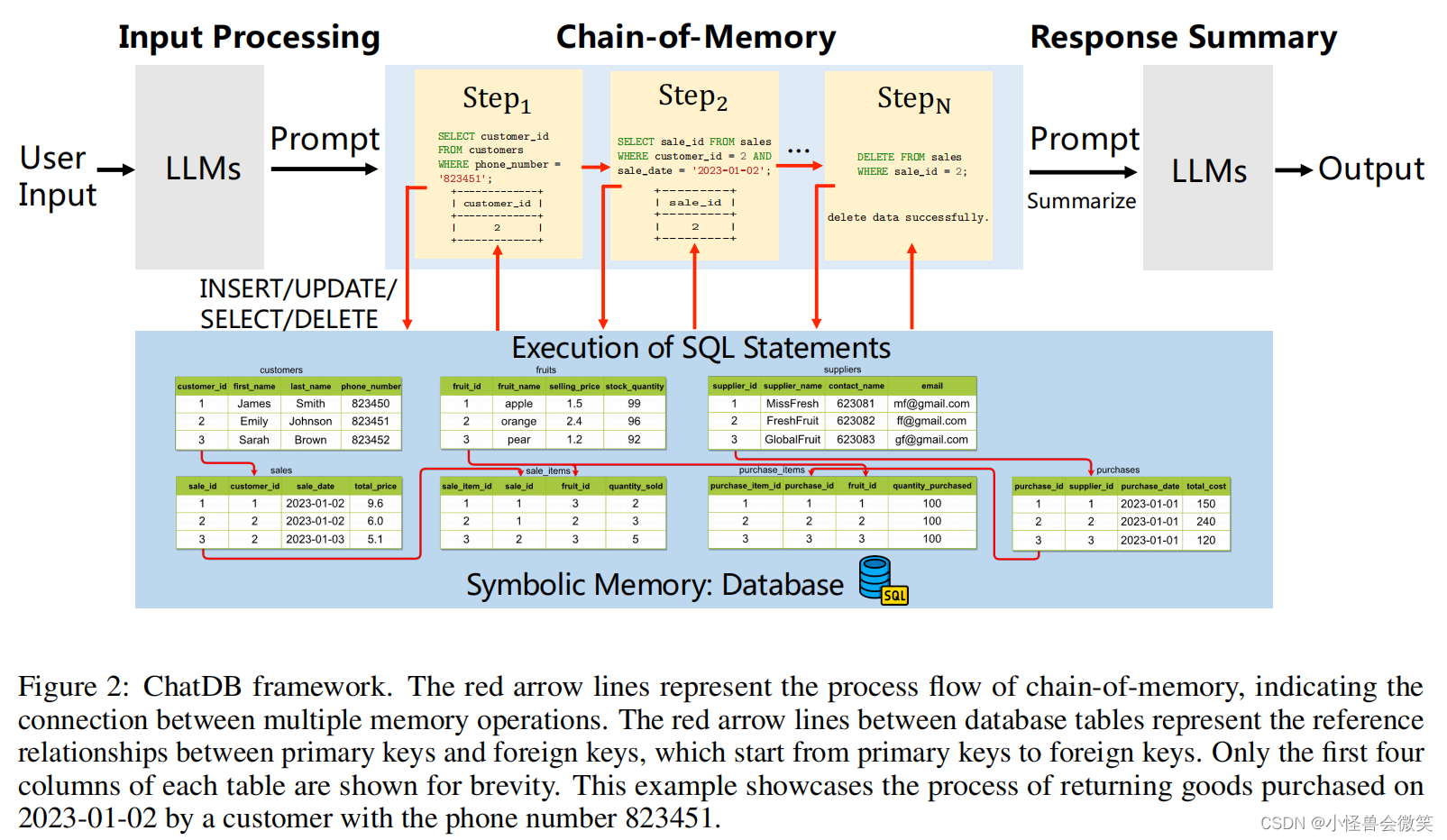
作者觉得他的贡献如下。
- 将数据库作为外部符号内存来增强LLM性能,允许历史数据的结构化存储,并使用SQL语句实现符号和复杂的数据操作。
- 记忆链方法通过将用户输入转换为多步骤的中间记忆操作,实现了有效的记忆操作,这提高了ChatDB的性能,使其能够处理复杂的、多表的数据库交互,提高了准确性和稳定性。
- 实验证明,使用符号内存增强LLM可以提高多跳推理能力,并防止错误积累,从而使ChatDB在合成数据集上的性能显著优于ChatGPT。
3.相关工作
作者这里写的还是很清晰的。
未完待续。。


![[Windows] ImageGlass Kobe v8.9便携版](https://img-blog.csdnimg.cn/img_convert/4125322071497e5a2bb7a2f59afec0d5.jpeg)