文章目录
- 1、概论
- 2、什么是知识图谱?
- 3、知识图谱构建
- 3.1、构建知识图谱的生命周期
- 3.2、Schema定义
- 3.3、知识抽取
- 3.4、知识融合
- 3.5、知识存储
- 3.6、知识推理
- 4、图谱建设的一些经验
1、概论
知识图谱(KnowledgeGraph)以结构化的形式描述客观世界中的概念实体及其关系,将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织,管理和理解互联网海量信息的能力。
知识图谱关注概念,实体及其关系,其中实体是客观世界中的事物,概念是对具有相同属性的事物的概括和抽象。本体是知识图谱的知识表示基础,可以形式化表示为O={C,H,P,A,I},C为概念集合,如事务性概念和事件类概念,Hshi概念的上下位关系集合,P是属性集合,描述概念所具有的特征,A是规则集合,描述领域规则,I是实例集合,描述实例-属性-值。
2、什么是知识图谱?
知识图谱的定义:“知识图谱本质上是语义网络(Semantic Network)的知识库”。换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)。
什么是对关系图?
图(Graph)是由节点(Vertex)和边(Edge)来构成,但这些图通常只包含一种类型的节点和边。多关系图一般包含多种类型的节点和多种类型的边。

- 知识图谱中,我们通用“
实体(Entity)”来表达图中的节点,用“关系(Relation)”来表达图中的边; - 实体指的是显示世界中的事物比如人、地名、概念、药物、公司等,关系则用来表达不同实体之间的某种联系。
李小龙的关系图谱:

从数据角度来看,知识图谱通过对结果化数据、非结构化数据、半结构化数据进行处理、抽取、整合,转化成“实体—关系—实体”的三元组。

3、知识图谱构建
3.1、构建知识图谱的生命周期
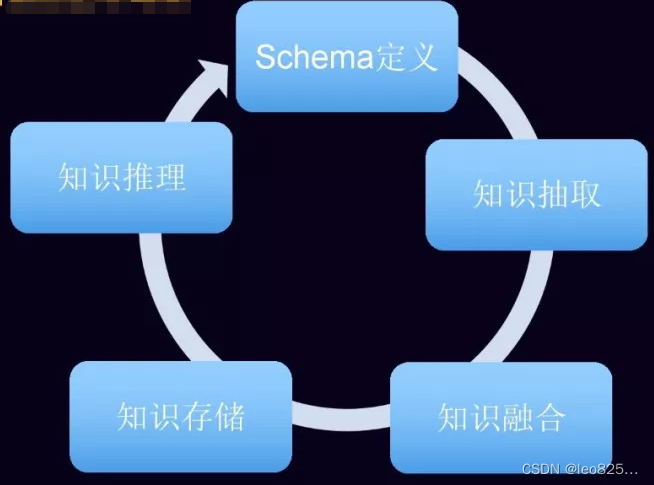
构建知识图谱的生命周期:Schema 定义、知识抽取、知识融合、知识存储、知识推理这样的循环迭代的过程。
- 什么是本体?
Ontology:通常翻译为“本体”。本体本身是个哲学名词。在上个世纪80年代,人工智能研究人员将这一概念引入了计算机领域。Tom Gruber 把本体定义为“概念和关系的形式化描述”。通俗点讲,本体相似于数据库中的 Schema ,比如足球领域,主要用来定义类和关系,以及类层次和关系层次等。OWL 是最常用的本体描述语言。本体通常被用来为知识图谱定义 Schema 。
举个例子:
张三是一个实体,其具有年龄、性别、职业等属性;
同时,张三是一个人,“人类”就是一个概念、类似的还有“国家”,“民族”等抽象概念;
本体是概念的集合,知识图谱本体层的东西就是各种概念及其属性和关系。
3.2、Schema定义
- Schema 是什么?
限定待加入知识图谱数据的格式;相当于某个领域内的数据模型,包含了该领域内有意义的概念类型以及这些类型的属性。 - Schema 有什么作用?
规范结构化数据的表达,一条数据必须满足Schema预先定义好的实体对象及其类型,才被允许更新到知识图谱中。
3.3、知识抽取
从各种数据源中进行实体识别、关系识别,从而抽取实体、关系、属性以及实体间的关系,属性的值,完成本体的知识表达,具体可以参照前文关于知识库的表达部分。对于知识图谱来说,数据源我们知道有结构化数据,非结构化数据和半结构化数据。
数据来源一般有:
- 业务的关系数据,这些数据通常包含在公司内数据库中;一般是结构化数据,或者是系统交互中Jison数据,虽然没有结构化,但是仍然可以通过功能进行存储,这种数据一般定义好本体库可以直接使用;
- 网上公开发布的可以抓取的数据,通常以网页形式存在,这种一般要通过爬虫技术,通过本体库相关关键词进行数据的爬取并结构化;
- 相关合同、文件等,比如一些保险合同、电子发票信息等;这种一般需要自然语言处理技术,进行数据信息的结构化提取。
信息的抽取是知识图谱构建的第一步,关键的点是:如何从数据源中自动抽取到实体、关系、以及属性等机构化技术。
实体抽取又称为实体识别,就是从文本中自动识别出来命名的实体,它是信息抽取中最基础的部分。
关系抽取就是进行语义的识别,抽取到实体间的关系,这个是信息抽取中最关键的部分,也是形成网状知识结构的基础。
关系的识别运用到各种算法模型以及机器学习的方法,属性抽取实现的是实体属性的完整勾勒。
3.4、知识融合
主要是新知识的融合、整合、判别同义、近义、消除歧义、矛盾。
比如,某些实体数据在显示世界中有多种表达方式,公司的注册名称、公司的简称等,要对这些知识进行同义融合,再比如某些特定的称谓也许对应着多个不同的实体。
知识融合包括两部分:实体链接和知识合并。
- 实体链接:是指对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。一般是从知识库中选中一些候选的对象,然后通过相似度将指定对象链接到正确的实体。流程如下:通过实体抽取获取实体指称项——通过实体消歧(解决同名实体歧义)和共指消解(多个指称指向同一实体进行相应的合并)——将实体指称链接到知识库对应实体。
- 知识合并:从第三方知识库产品或是已有的结构化数据中进行知识的获取,一般是合并外部知识库和和合并关系数据库,合并中要避免实体与关系的冲突问题,防止不必要的冗余。
3.5、知识存储
知识图谱主要有两种存储方式:一种是基于 RDF 的存储;另一种是基于图数据库的存储。它们之间的区别如下图所示。RDF 一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。其次,RDF 以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。

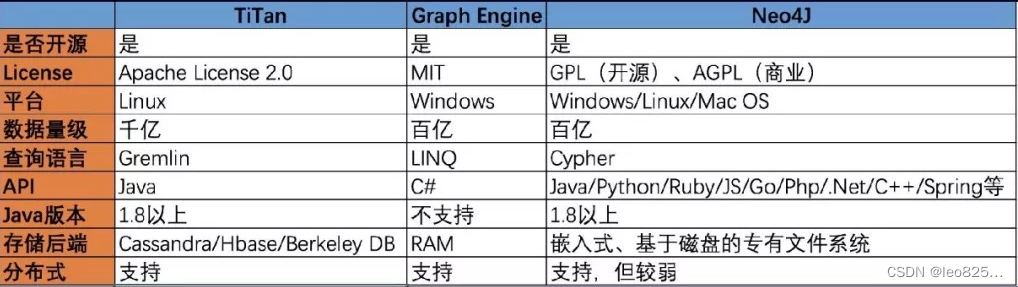
知识存储,就是如何选择数据库,从选择层面,我们有图数据库,有NoSQL的数据库,也有关系型数据库,数据库有很多选择。具体什么样的情况下选择什么样的数据库?通常是如果说知识图谱的关系结构非常的复杂、关系非常的多,这时候建议使用这个图数据库,比如Neo4J这样的数据库。顺便了解一下目前主流的几款图数据库,Titan、Graph Engine、Neo4J这个三个分别都是开源的,然后Titan是Apache旗下的,Graph Engine是MIT的License,Neo4J是GPL开源的,既有商业版,也有也有开源免费版。然后它们的平台,像Titan是Linux,Graph是windows。而数据的支撑量级,像Titan是后端存储,基于Cassandra/Hbase/BDB这样的分布式存储引擎,可以支持更大的数据量,千亿级的数据量级;Neo4J商业版也可以支持到百亿级的,但是它的非商业版在数据量级比较大的时候,一般是在几千万级的时候就可能会出现一些问题。
3.6、知识推理
知识推理这边有几种方法,基于符号的推理、基于 OWL 本体的推理、基于图的方法(PRA算法)、基于分布式知识语义 标识方法(Trans系列模型)、TransR 模型、基于深度学习的推理。
知识图谱不仅仅是根据关系的检索,更大的核心用途是推理,发现图谱中的隐藏关系,而不是发现新知识。
1)通过实体间的关系推理相关关系
通过多实体间的关系,可以推断其他的关系,比如张三和李四之间是夫妻关系,王五是张三的领导,王五居住在A城市,我们可以推论李四也居住在A城市。
2)通过实体间的关系推理相关属性
通过多实体间的关系,实体的属性值,可以推断其实体的属性值。这个与通过实体间的关系推论关系道理类似,也可以通过一个实体间的关系、根据实体的属性推断另一个实体的属性。
在AI中涉及到推理的方法有很多,有基于逻辑的推理,有基于深度学习的推——这个就是基于图谱的推理,也就是通过关系、属性的因素做的推理。
4、图谱建设的一些经验
我们在知识图谱建设当中的一些经验:
- 第一,界定好范围,就是要有一个明确的场景和问题的定义,不能说为了知识图谱而知识图谱。如果没有想清楚知识图谱有什么样的应用的场景,或者能解决什么样的问题,这样的知识图谱是比较难以落地的。一些明确的场景,比如解决商品数据的搜索问题,或者从产品说明书里面做相关问题的回答。
- 第二,做好schema的定义,就是上面讲到的对于schema或者本体的定义。第一步确定好场景和问题以后,就基于这样的场景或者问题,再进行相关领域的schema的定义。定义这个领域里概念的层次结构、概念之间的关系的类型,这样做是确保整个知识图谱是比较严谨的,知识的准确性是比较可靠的。知识的模型的定义,或者schema的定义,大部分情况下是通过这个领域的知识专家的参与,自上而下的方式去定义的。
- 第三,数据是知识图谱构建基础。数据的梳理就比较重要,最需要什么样的数据?依赖于我们要解决的问题是什么,或者我们的应用场景是什么?基于问题和场景,梳理出领域相关的问题、相关的数据,包括结构化的数据、半结构化数据、无结构化的数据,结合百科跟这个领域相关的数据,领域的词典,或者领域专家的经验的规则。
- 第四,不要重复去造轮子,很多百科的数据和开放知识图谱的数据,是可以融合到我们的领域知识图谱中。
- 第五,要有验证和反馈机制,需要有管理后台,用户可以不断的和知识图谱系统进行交互,不断的进行确认和验证,确保知识图谱每一步推理和计算都是准确的。
- 第六,知识图谱构建是持续迭代的系统工程,不可能一蹴而就。