78.子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例2:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10nums中的所有元素 互不相同
思路
本题的特征在于,想收获的结果集并不在叶子节点上,而是在每一个子节点上。
树形图
树形图如下:
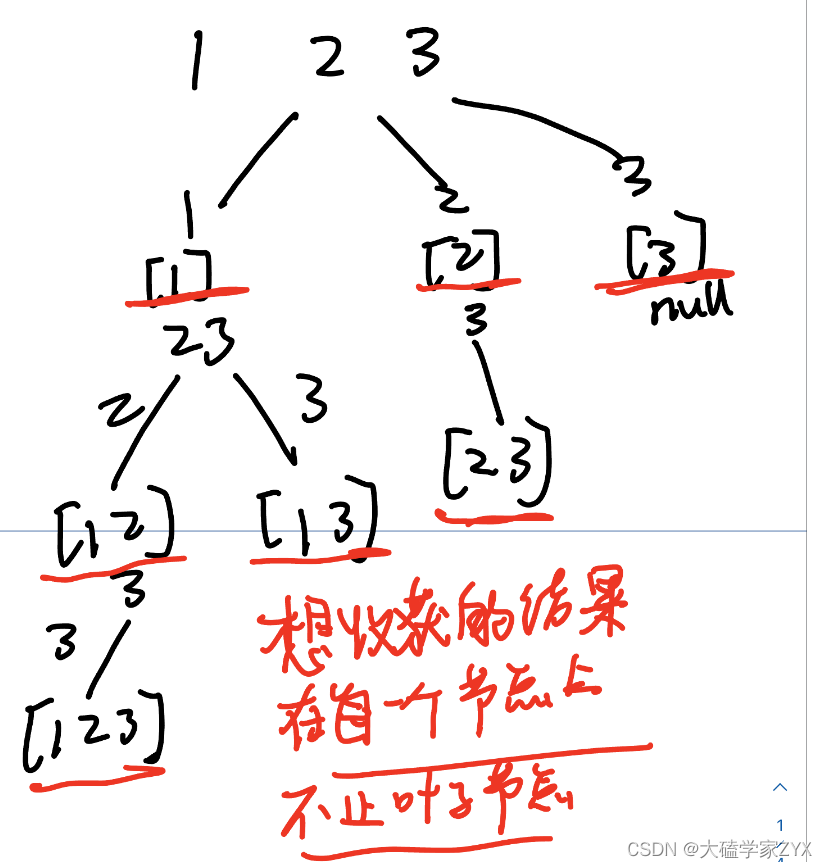
即使是分割回文串,也是在分割到了最后,才获取分割结果result。
但是这道题目是选择子集,子集在每一个子节点上面都有结果!
如果把子集问题、组合问题、分割问题都抽象为一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。
那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!
(for从0开始是后面的排列问题,排列问题顺序不同结果不同。startIndex开始就是为了组合问题防顺序不同的重复)
伪代码
void backtracking(vector<int>&path,vector<vector<int>>&result,vector<int>&nums,int startIndex){
//终止条件:剩余集合都是空的情况,也就是startIndex遍历到了空集合的位置!
if(startIndex==nums.size()){
//到了叶子节点
return;
}
//单层搜索:本题需要每一个节点都收割,切出来的所有结果都是子集
for(int i=startIndex;i<nums.size();i++){
//收获单个元素,把单个结果放进path里面
path.push_back(nums[i]);
//result的位置
result.push_back(path);
//递归
backtracking(path,result,nums,i+1);
//回溯
path.pop_back();
}
}
最开始的写法
- 超出内存限制,原因是传入递归的时候发生了无限递归,应该传入i+1而不是直接传startIndex!
class Solution {
public:
void backtracking(vector<int>&path,vector<vector<int>>&result,vector<int>& nums,int startIndex){
if(startIndex==nums.size()){
return;
}
for(int i=startIndex;i<nums.size();i++){
path.push_back(nums[i]);
result.push_back(path);
backtracking(path,result,nums,startIndex);
path.pop_back();
}
}
vector<vector<int>> subsets(vector<int>& nums) {
vector<int>path;
vector<vector<int>>result;
int startIndex=0;
backtracking(path,result,nums,startIndex);
return result;
}
};
debug测试1:无限递归,超出内存限制
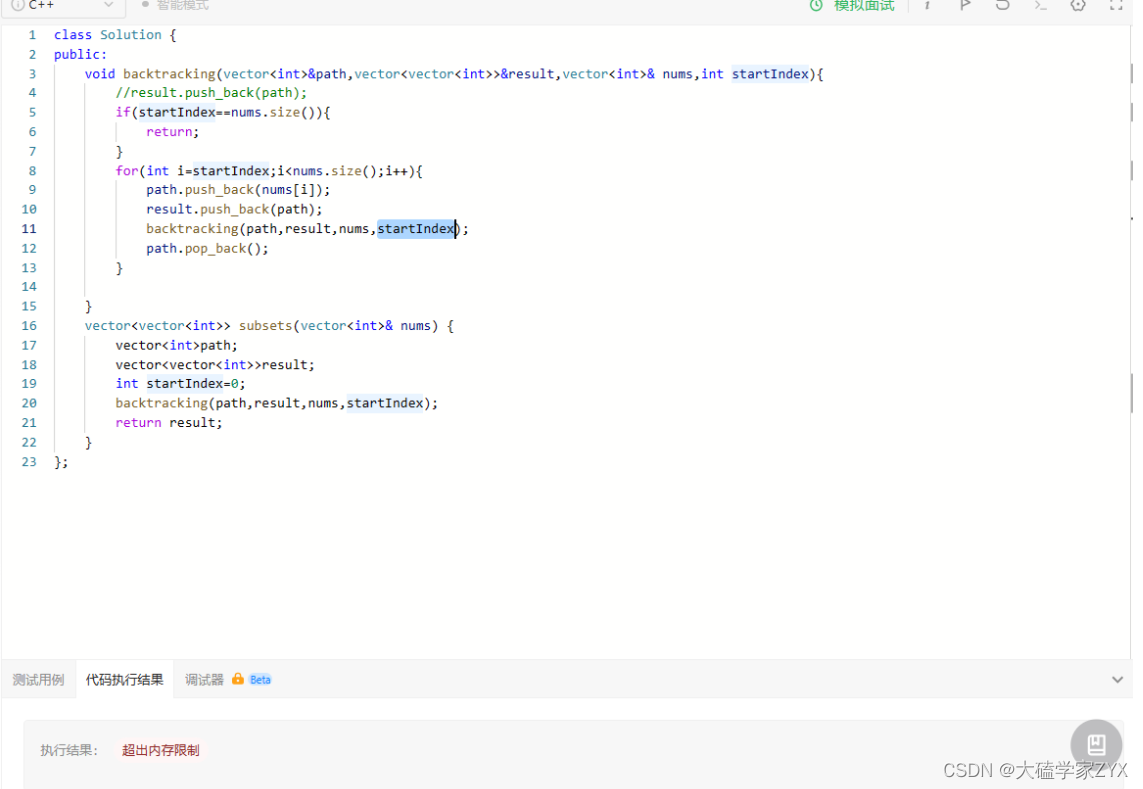
原因是在生成子集时遇到了无限递归,这是因为在递归回溯函数 backtracking 中,在调用函数时没有正确的更新 startIndex 参数,应该传入 i+1而不是 startIndex 。
debug测试2:逻辑问题,没加上空子集
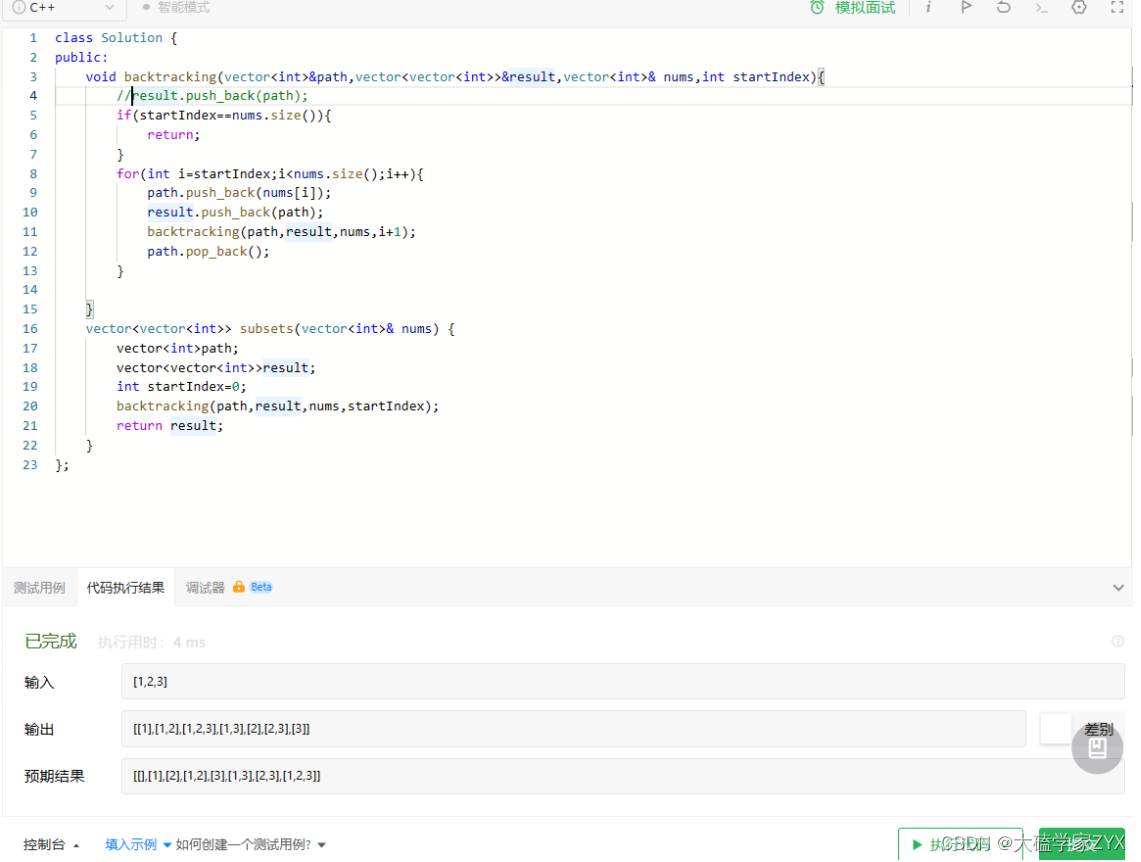
预期输出中空子集也是一部分。
有两种修改方案,一个是在主函数一开始就在result里面加空子集,另一个是把result.push_back移到递归最开始。这样就能保证带有最初的空子集。
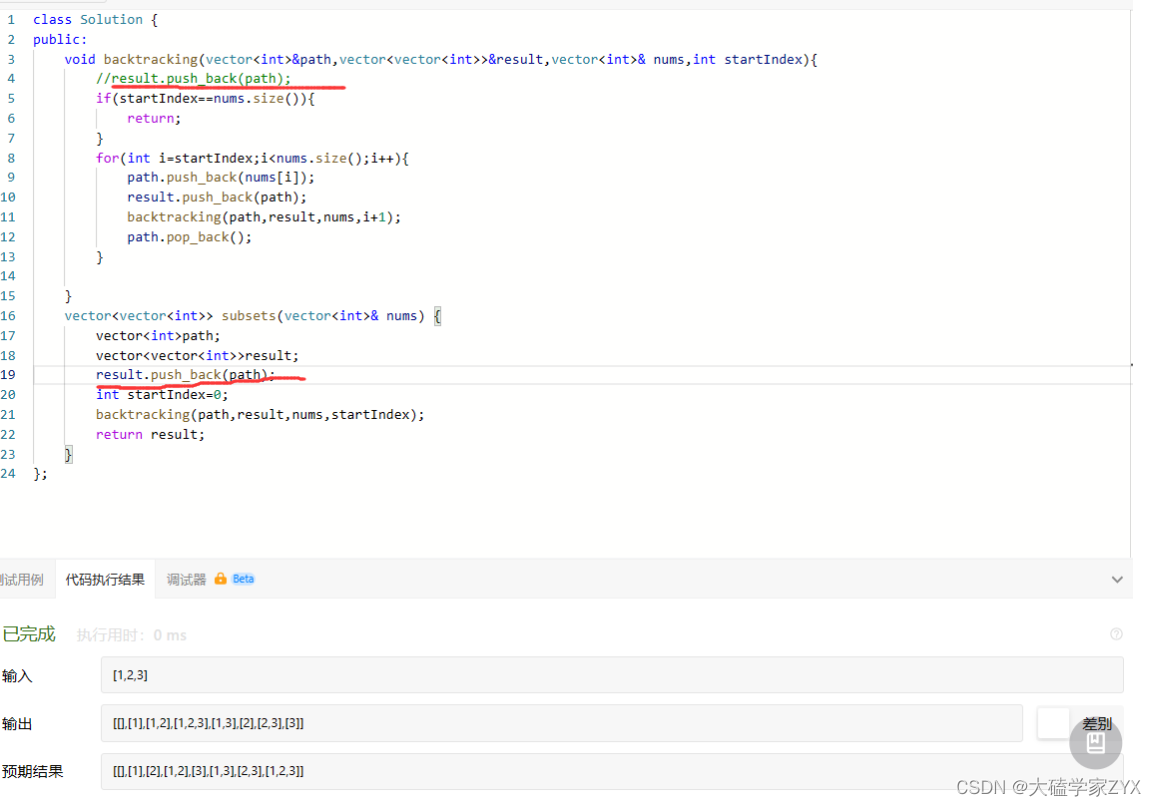
完整版
- 一定要注意startIndex的问题,这只是一个参数,传入的时候需要传递归下去的东西
class Solution {
public:
void backtracking(vector<int>&path,vector<vector<int>>&result,vector<int>& nums,int startIndex){
//result.push_back(path);
if(startIndex==nums.size()){
return;
}
for(int i=startIndex;i<nums.size();i++){
path.push_back(nums[i]);
result.push_back(path);
backtracking(path,result,nums,i+1);
path.pop_back();
}
}
vector<vector<int>> subsets(vector<int>& nums) {
vector<int>path;
vector<vector<int>>result;
result.push_back(path);
int startIndex=0;
backtracking(path,result,nums,startIndex);
return result;
}
};
时间复杂度
子集问题的时间复杂度是 O(2^n)。
对于这个问题,我们需要生成一个集合的所有子集。对于一个大小为n的集合,子集的总数量是2^n。这是因为每个元素都有两种可能:存在或不存在于一个子集中。因此,我们需要在所有可能的组合中进行遍历,也就是说我们需要2的n次方操作。
90.子集Ⅱ(去重)
- 本题是子集问题与组合总和Ⅱ去重问题的结合,没有新东西,可以用于快速复习
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例1
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
示例2
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10
思路
本题与子集的区别就在于,本题的集合是有重复的!也就是说涉及到去重的问题,类似40.组合总和Ⅱ:DAY29:回溯算法(四)组合总和+组合总和Ⅱ_大磕学家ZYX的博客-CSDN博客
组合总和Ⅱ中主要是树层去重和树枝去重,本题也要从这个角度来考虑。
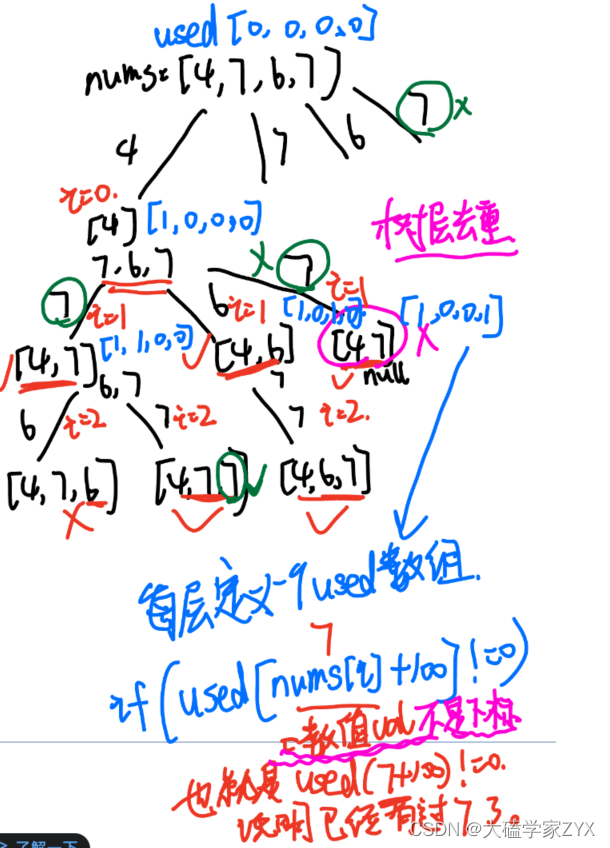
树形图
树层去重和树枝去重,一个重要的变量就是used数组。
我们通过used来统计每个元素被使用了多少次,从而达到只进行树层去重,但不进行树枝去重的目的。
(因为本题示例1可以看出,输出有[1,2,2],说明本题认为这两个2只是数值相同,但是是不同元素,也就意味着树枝不能去重,只有树层可以!)
树层上相邻两个元素重复取,得到的就是重复的子集,此处树层指的是所有的树层,并不仅仅指第一层的树层!
- 树枝指的就是向下的方向↓,树层指的就是横着的方向→
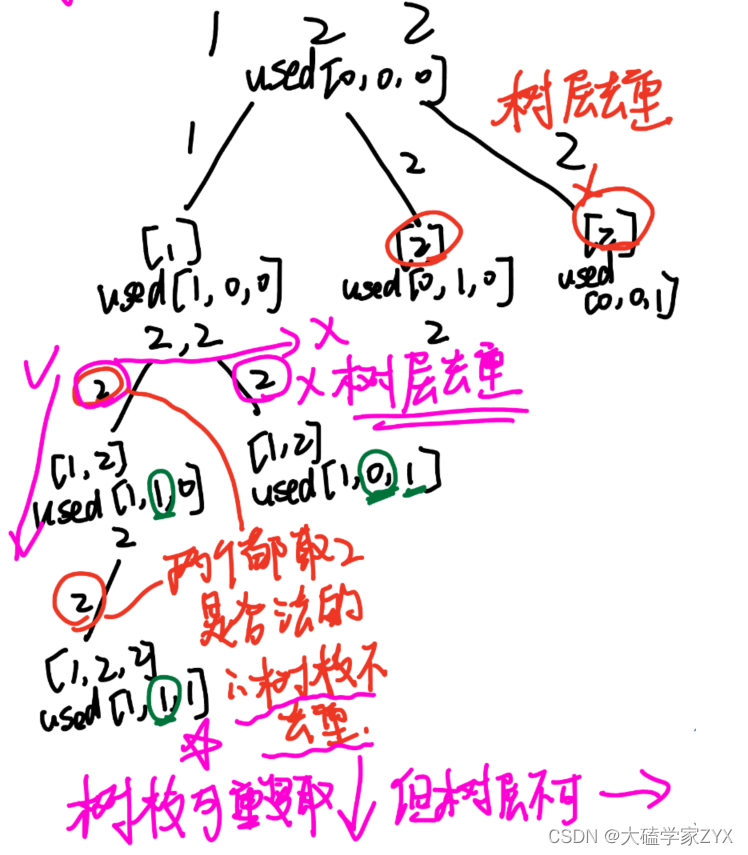
去重注意点:
- 去重需要先排序,排序之后才能让重复元素相邻在一起,才能进行去重的判断!
- 去重要进行树层去重和树枝去重的区分,这个区分主要靠的就是和原数组相同大小的used数组!这个used数组统计每个元素被使用的次数,才能分得开树层和树枝!
- used数组区分树层和树枝的原理,可以看上图绿色笔画出的部分。
当nums[i]==nums[i-1]的时候,区分nums[i-1]是树层还是树枝,需不需要被去重,主要就是看used[i-1]是不是等于0!如果=1说明是树枝,=0才说明是树层!
去重逻辑:
if(i>=1&&nums[i]==nums[i-1]&&used[i-1]==0){//下标越界问题,i>=1才行
continue;
}
完整版
本题代码实际上是 78.子集 和 40.组合总和Ⅱ 的结合!去重逻辑和组合总和Ⅱ完全一样,剩余逻辑和子集一样。
class Solution {
public:
void backtracking(vector<int>&path,vector<vector<int>>&result,vector<int>&nums,vector<int>&used,int startIndex){
//终止条件
if(startIndex==nums.size()){
return;
}
//单层搜索
for(int i=startIndex;i<nums.size();i++){
//去重
if(i>=1&&nums[i]==nums[i-1]&&used[i-1]==0){
continue;
}
//收集结果,统计used
path.push_back(nums[i]);
result.push_back(path);
used[i] += 1;
//递归
backtracking(path,result,nums,used,i+1);
//回溯
path.pop_back();
used[i] -= 1;
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
vector<int>path;
vector<vector<int>>result;
//used需要和nums大小相等,因为上来就需要访问used下标,所以必须先初始化
vector<int>used(nums.size(),0);
int startIndex=0;
//先把空子集加进去
result.push_back(path);
//排序
sort(nums.begin(),nums.end());
//传入回溯函数
backtracking(path,result,nums,used,startIndex);
return result;
}
};
注意:
- 一定要注意,涉及到i-1就会存在数组下标越界的问题!因为i是从0开始的!所以涉及i-1,i-2一定要先看i有没有设置i>=1等条件。
- 去重操作中,used需要和nums大小相等,因为上来就需要访问used下标,所以必须先初始化used,也就是
vector<int>used(nums.size(),0);
时间复杂度
这个问题的时间复杂度也是O(2^n)。
对于这个问题,还是需要遍历所有可能的子集组合,这些组合的数量还是2^n(n是集合的大小)。虽然在这个问题中有重复的元素,在遍历的过程中跳过了这些重复的子集,但实际上并没有减少需要遍历的子集的数量。所以,时间复杂度仍然是2的n次方。
491.递增子序列(也算子集问题)
-
本题和子集Ⅱ只是看上去像!实际上要注意区分!这个题实际上也算子集问题,因为也需要在前面的子节点就进行收割,结果不局限于叶子节点!
-
本题还需要掌握用set进行树层去重的方式,因为不能排序,所以不能用used数组来去重,set去重和排序+used数组去重是有区别的!
给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。
数组中可能含有重复元素,如出现两个整数相等,也可以视作递增序列的一种特殊情况。
示例1
输入:nums = [4,6,7,7]
输出:[[4,6],[4,6,7],[4,6,7,7],[4,7],[4,7,7],[6,7],[6,7,7],[7,7]]
示例2
输入:nums = [4,4,3,2,1]
输出:[[4,4]]
提示:
1 <= nums.length <= 15-100 <= nums[i] <= 100
思路
本题和子集问题有点像,实际上也是在找子集。递增子序列就是求有序的子集,且不能有相同递增子序列意味着也需要去重。
在去重的一般处理中,我们是通过排序,再加一个used标记数组来达到去重的目的。但是本题显然不能排序,排序就全是递增了。
很多题解里说这道题是图论里面的深度优先搜索,其实所有的回溯算法都可以说是深搜。
树形图
本题也算是子集问题,因为结果分布在各个节点上,不止叶子节点!但是本题对节点的子集长度有要求,所以并不是所有的子集都会取。
树层不可重复,因为前面的一定可以包含后面的,并不存在后面的多了元素和前面不同的情况。树层相同,后面就会相同。
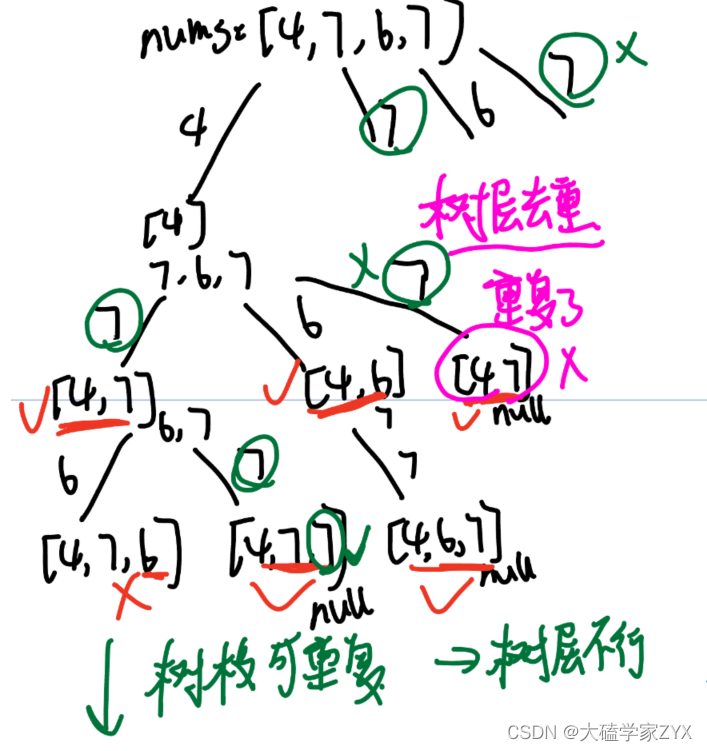
取数原则
- 取数的时候,当前取的数字必须要比集合里的前一个数字要大。
- 树层里取过的元素,不能再取,树层去重
- 因为本题是不能排序的,所以去重也不能用used数组+排序来做,只能用set来做去重。
伪代码
if(path.size()<2)的判断放在循环外面的原因,是因为对于每一个节点的子集长度,都需要进行判断!类似于子集问题里把每个节点收集结果的result放在最前面一样!- 针对每个节点的子集都要判断的条件,就最好放在for循环的外面。其实放里面也可以,可能会显得不那么清晰。
void backtracking(vector<int>&path,vector<vector<int>>&result,vector<int>&nums,unordered_set<int>set,int startIndex){
//终止条件,子集问题其实不写也没事,因为startIndex总会走到nums的最后!
if(startIndex==nums.size()){
return;
}
//去重辅助:set
unordered_set<int>set;
//单层搜索
for(int i=startIndex;i<nums.size();i++){
//如果新加的元素小于子集path最右边的元素,就不取,注意需要写条件path不为空,排除path的初始情况!
if(!path.empty()&&nums[i]<path.back()){
continue;//舍弃分支
}
if(set.find(nums[i])!=set.end()){
//树层里面有过这个元素
continue;//舍弃分支
}
path.push_back(nums[i]);
//本题要求结果长度>=2,长度小于2不收割
if(path.size()>=2){
result.push_back(path);
}
set.insert(nums[i]);
//递归
backtracking(path.result,nums,set,i+1);
//回溯
path.pop_back(); //注意这里回溯只回溯path。result和set都不回溯!!
}
}
uset去重和used数组去重的区别
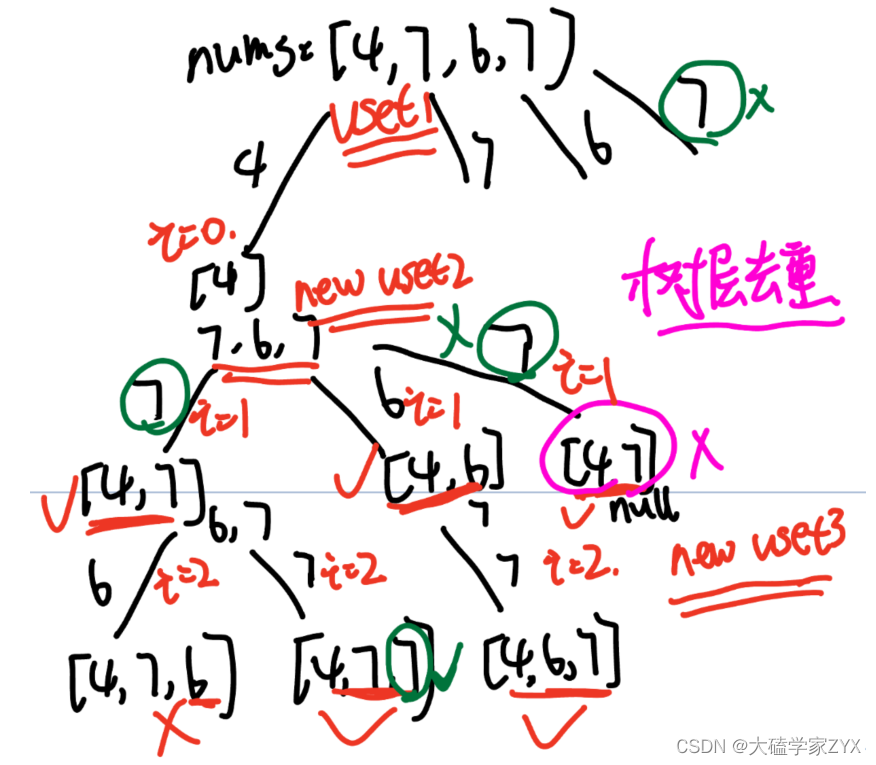
1.为什么uset去重不能回溯,used数组去重必须回溯?
因为我们进入每一层递归的时候,都会重新定义uset。也就是说,uset是每一层递归单独的树层统计!每向下进入一次新的递归,就会建立一个新的uset!
每层新建uset的情况如下图所示。当backtracking(i+1)的时候,进入新的递归,就会新建一个本层的set用于记录本层的树层节点!因此每一层递归,都对应一个uset!每层uset的情况如下图:
而used数组需要回溯,是因为used数组是记录树枝里面哪些元素用过,防止去重的时候连树枝的相同元素一起删掉!我们可以看一下子集Ⅱ题目里面,used数组的去重树:
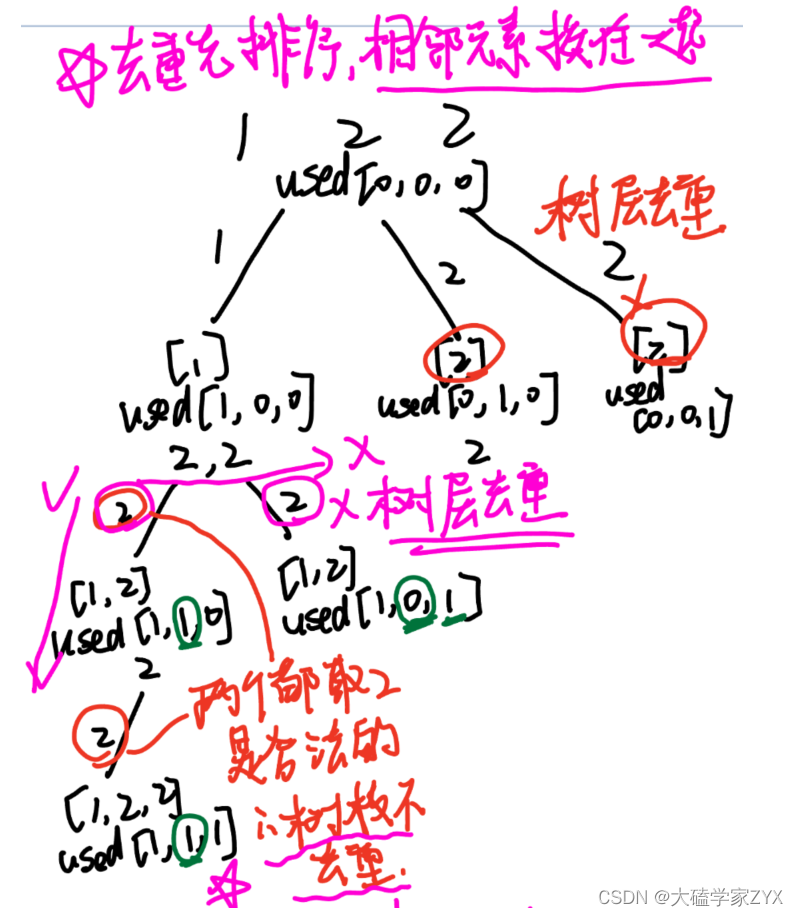
used数组是记录下来path里面用过了哪些元素,所以path里面加了元素,used数组就要做对应标记;path里面pop掉了,used数组也要做对应标记!否则,会让已经pop掉的元素影响树层去重时的判断,不能达到把树层和树枝分开的目的。
而uset比较来说,一个uset仅仅负责本层里面的树层元素统计,也就是记录本层内取过了哪些元素,和path是没有关系的。
2.为什么递增子序列这道题不能用子集Ⅱ的used数组这种方法?
在"子集 II"问题中,我们用的去重方法是基于已经排序过的数组。如果我们不预先进行排序,就不能使用子集Ⅱ中的使用used数组的去重方式,因为used数组只考虑了输入nums数组的当前元素nums[i]和nums[i-1],如果不排序,那么这个used数组没有意义,相同的元素可能会分布在数组的任意位置,这样就无法通过简单地比较相邻元素来判断是否重复了。
3.数组去重和set去重在效率上的区别?
在计算机内存中,数组的存储方式相对于哈希表更为直接和连续。
数组中每个元素的内存地址可以直接计算得出,访问的速度非常快,可以做到常数时间复杂度O(1)。此外,因为数组元素在内存中是连续存储的,所以在读取数组时可以利用到CPU的缓存预取(cache prefetching)机制,进一步提高访问速度。
而对于哈希表,虽然理论上其查找、插入、删除操作的时间复杂度都是O(1),但是实际情况下可能会受到哈希冲突的影响,导致实际操作的时间复杂度增加。哈希冲突是指不同的键值通过哈希函数计算得到相同的哈希地址,处理哈希冲突需要额外的计算和存储开销。
另外,哈希表的内存存储也不是连续的,无法利用到CPU的缓存预取机制。
因此,尽管哈希表在理论上能够提供非常快的操作速度,但是在实际操作中,特别是在处理小规模数据时,使用数组可能会得到更好的效率。当然,这也依赖于具体的应用场景和数据特性,某些情况下,例如处理大规模的、离散的数据,哈希表可能会表现得更优秀。
去重方式总结
每层递归定义一个uset的方式,其实也可以解决组合总和Ⅱ和子集Ⅱ里面树层去重的问题。每层定义一个uset,是除了排序+used数组之外另一种去重方式。
我们这里用的是uset来去重,其实用数组也可以,并且数组效率会更高一些!
完整版
- 递增不需要单独写函数判断,只需要判断path最后一个元素和当前元素大小即可
- unordered_set是在每层单独定义,不需要作为参数传入下一层
class Solution {
public:
void backtracking(vector<int>&path,vector<vector<int>>&result,vector<int>& nums,int startIndex){
//终止条件
if(startIndex==nums.size()){
return;
}
unordered_set<int>uset;
//单层搜索
for(int i=startIndex;i<nums.size();i++){
//不递增,去掉分支
if(!path.empty()&&nums[i]<path.back()){
continue;
}
//重复,去掉分支
if(uset.find(nums[i])!=uset.end()){
continue;
}
uset.insert(nums[i]);
path.push_back(nums[i]);
//长度满足条件,才将当前节点子集加入result
if(path.size()>=2){
result.push_back(path);
}
//递归
backtracking(path,result,nums,i+1);
//回溯,set不回溯,result收集所有结果也不回溯
path.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
vector<int>path;
vector<vector<int>>result;
int startIndex=0;
backtracking(path,result,nums,startIndex);
return result;
}
};
数组优化取代set
以上代码用了unordered_set<int>来记录本层元素是否重复使用。
其实用数组来做哈希,效率就高了很多。
注意题目中说了,数值范围是[-100,100],所以完全可以用数组来做哈希,不存在下标过大浪费内存空间的问题!
程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且每次重新定义set,insert的时候其底层的符号表也要做相应的扩充,也是费事的。
正如在代码随想录哈希表:总结篇!(每逢总结必经典) (opens new window)中说的那样,数组,set,map都可以做哈希表,而且数组干的活,map和set都能干,但如果数值范围小的话,能用数组尽量用数组!
优化完整版
- 这种used数组和排序+used数组的区别在于,此处的数组是数值val的数组,而排序法的used数组是下标i的数组!
- 本方法去重逻辑:
if(used[nums[i]+100]!=0) - 排序法去重逻辑:
if(i>=1&&nums[i]==nums[i-1]&&used[i-1]==0)
class Solution {
public:
void backtracking(vector<int>&path,vector<vector<int>>&result,vector<int>& nums,int startIndex){
//终止条件
if(startIndex==nums.size()){
return;
}
//定义used数组,大小200,是因为数据范围[-100,100],这是为了避免下标负数
int used[201]={0};
//单层搜索
for(int i=startIndex;i<nums.size();i++){
//不递增,去掉分支
if(!path.empty()&&nums[i]<path.back()){
continue;
}
//重复,去掉分支,used数组判断
if(used[nums[i]+100]!=0){
continue;
}
//used数组累计本层次数
used[nums[i]+100] += 1;
path.push_back(nums[i]);
//长度满足条件,才将当前节点子集加入result
if(path.size()>=2){
result.push_back(path);
}
//递归
backtracking(path,result,nums,i+1);
//回溯,set不回溯,result收集所有结果也不回溯
path.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
vector<int>path;
vector<vector<int>>result;
int startIndex=0;
backtracking(path,result,nums,startIndex);
return result;
}
};
优化后的树形图
我们从优化后的树形图可以看出来,原有的排序+used下标数组的方式,当相同元素没有放在一起的时候,是没有意义的。排序+下标数组的判断树层方式是used[i-1]==0,是下标数组,而不是数值数组!
使用数组和set去重的区别
在第一种方法中,利用unordered_set(哈希表)来处理重复元素,它的优点是查找速度快(平均时间复杂度为O(1)),缺点是哈希表的内存消耗较大,因为需要存储每一个元素的哈希值,且哈希函数计算也会消耗一定的时间。并且在哈希表存在哈希冲突的情况下,实际的查找时间可能会高于O(1)。
优化方法中,利用了一个固定大小的数组来处理重复元素。这种方法的优点在于数组的内存消耗较小,且查找和修改的时间复杂度为O(1),并且不存在哈希冲突的问题。但是这种方法的缺点是如果数据的范围非常大,那么可能需要一个非常大的数组来进行去重,这在某些情况下可能是不可接受的。
但本题数据范围是[-100,100],在数组下标允许的范围内!下标处理只需要定义大小为200的数组,再让nums[i]对应的下标为nums[i]+100,就可以避免下标负数的问题。
这种优化方法used数组和另一种used数组的区别
两者的主要区别在于,"递增子序列"问题中的**used数组是按值(数组元素的值)索引,是used[nums[i]]**.
而"子集 II"问题中的**used数组是按位置(数组元素的位置)索引,也就是used[i-1]**。
在"递增子序列"这个问题中,used数组实际上是一个值为布尔类型的“哈希表”,它的索引是数组元素的值,内容表示这个值是否在当前的递归层级中被使用过。
而在"子集 II"这个问题中,used数组的索引是数组元素的位置(下标),内容也表示这个位置的元素是否被使用过。这个方法的前提是输入数组已经被排序,所以当我们遇到与前一个元素值相同的元素时,我们可以通过检查前一个元素是否被使用过来决定是否应该跳过当前元素。
数组比起哈希表的优点
总的来说,使用数组优化的方法在这个问题上的主要优点是空间复杂度较小,且查找和修改的时间复杂度都是O(1)。在数据范围较小的情况下,这种方法的效率会比使用unordered_set来处理重复元素更高。
数组优化方法的空间复杂度是O(N),其中N为数组的大小,即201;而unordered_set的空间复杂度是O(n),其中n为nums的长度。
时间复杂度
时间复杂度方面,数组去重和set去重,两种方法都是O(2^n),因为在最坏情况下需要遍历所有可能的子序列。
我们对数组中的每个元素都有两种选择:选择它或者不选择它。所以,总共有2^n种可能的子序列,其中n是数组的长度
但由于数组访问时间比unordered_set快,所以在实际运行时间上,数组优化可能会快一些。