作者 | 智商掉了一地、Python
去年咱们在介绍百万悬赏时提到,“海量资源砸出的大模型真的会一直那么香吗?”,目前来看,自打 ChatGPT 横空出世引领一众大模型开辟新的生活和工作方式以来,还是挺香的,但对于资源的消耗也确实很大。随着大模型的普及和广泛应用,它们需要庞大的计算资源和存储空间进行训练和部署。这意味着需要大量的能源供应以及高昂的硬件成本。此外,维护和更新大模型也需要大量的人力和时间投入。
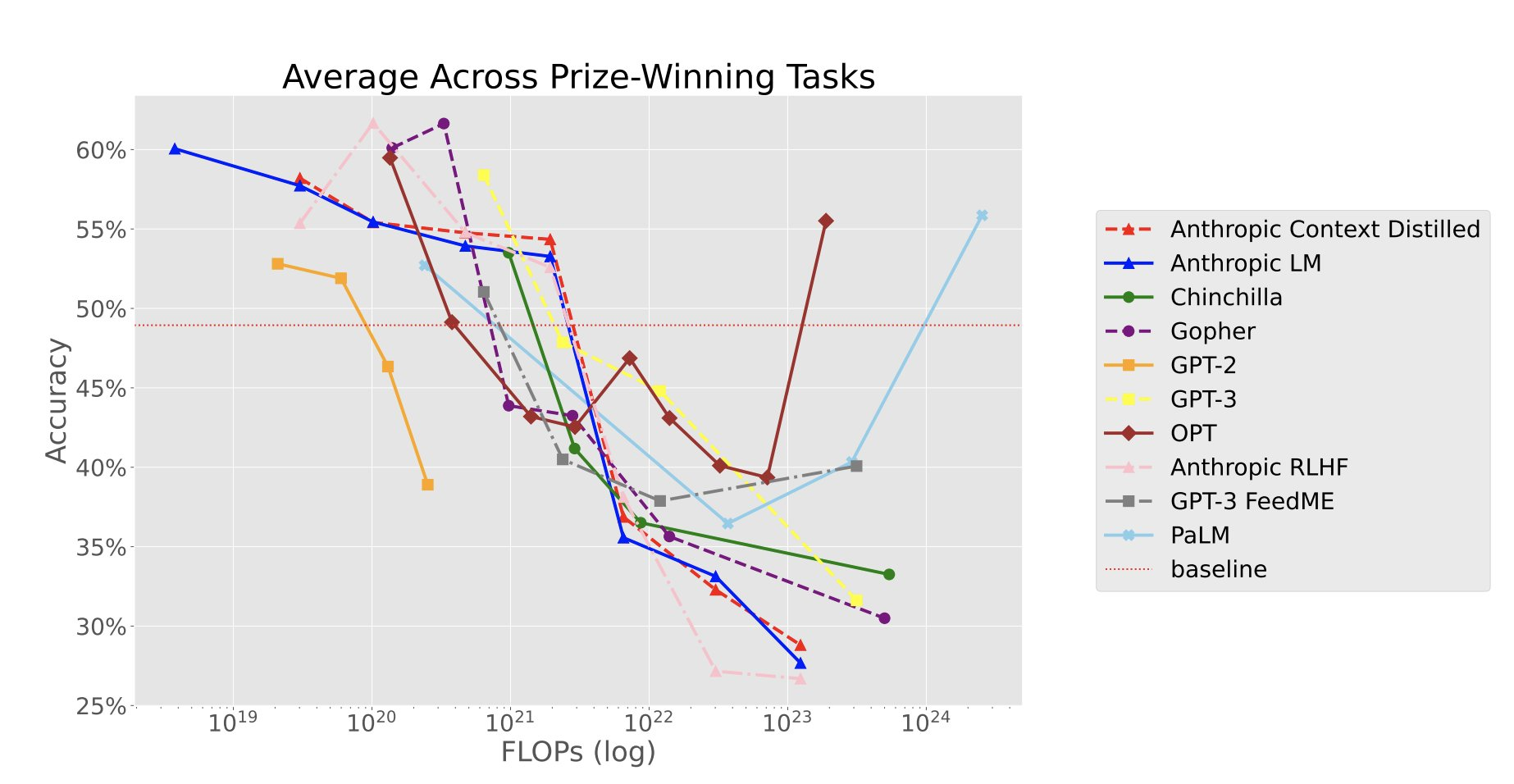
对于纽约大学几位研究者组织的一项较为另类的竞赛——寻找一些大模型不擅长的任务,近期有了新的后续。借助 25 万美金的悬赏,目前找到了 11 个数据集,在这些任务上,语言模型越大,性能反而越差。它的主要原因被总结为:
- 大模型倾向于重复记忆到的序列。
- 模型模仿训练集中不好的 pattern。
- 数据集中有推理捷径,大模型容易过拟合。
- 有误导性的少监督展示学习。
论文题目:
Inverse Scaling: When Bigger Isn’t Better
论文链接:
https://arxiv.org/abs/2306.09479
Github 地址:
https://github.com/inverse-scaling/prize/tree/main/data-release
论文速览
反规模效应奖 (Inverse Scaling Prize)
为了更全面了解表现反规模效应的任务类型,并开发出充分的缓解策略,主办方开展了一项竞赛,其目标是调查大型语言模型中反规模效应的程度,并找到具有鲁棒反规模效应的示例。
参赛者以文本补全任务的形式提交了一组输入-输出示例数据集,并附上了任务重要性的理由和在 GPT-3 模型上的规模图表。
任务与原因
强先验任务
强先验:模型使用记忆信息而不是遵循上下文指令。
根据这项任务的实验推测,反规模效应可能是因为语言模型有两个不同的信息来源:
- 预训练文本中的信息通过梯度下降被加入到权重中;
- 推理时处理的 Prompt 中的信息。
当 Prompt 声称某个内容与预训练文本相矛盾时,这两个信息来源可能会发生冲突。较大的语言模型似乎更会利用预训练期间学到的先验信息,因此它们对 Prompt 中给出的信息依赖较少。
Resisting Correction

该任务测试语言模型在重复文本时是否会修改其内容,尤其关注较大规模的模型是否能够遵循指令而不受其先验偏好的影响。
这对于理解模型在接收最新信息时是否能够超越传统智慧具有重要意义,尤其当模型没有及时更新关于当前事件的信息时。任务结果有助于研究(反)规模、新兴行为和规模趋势的逆转等方面。
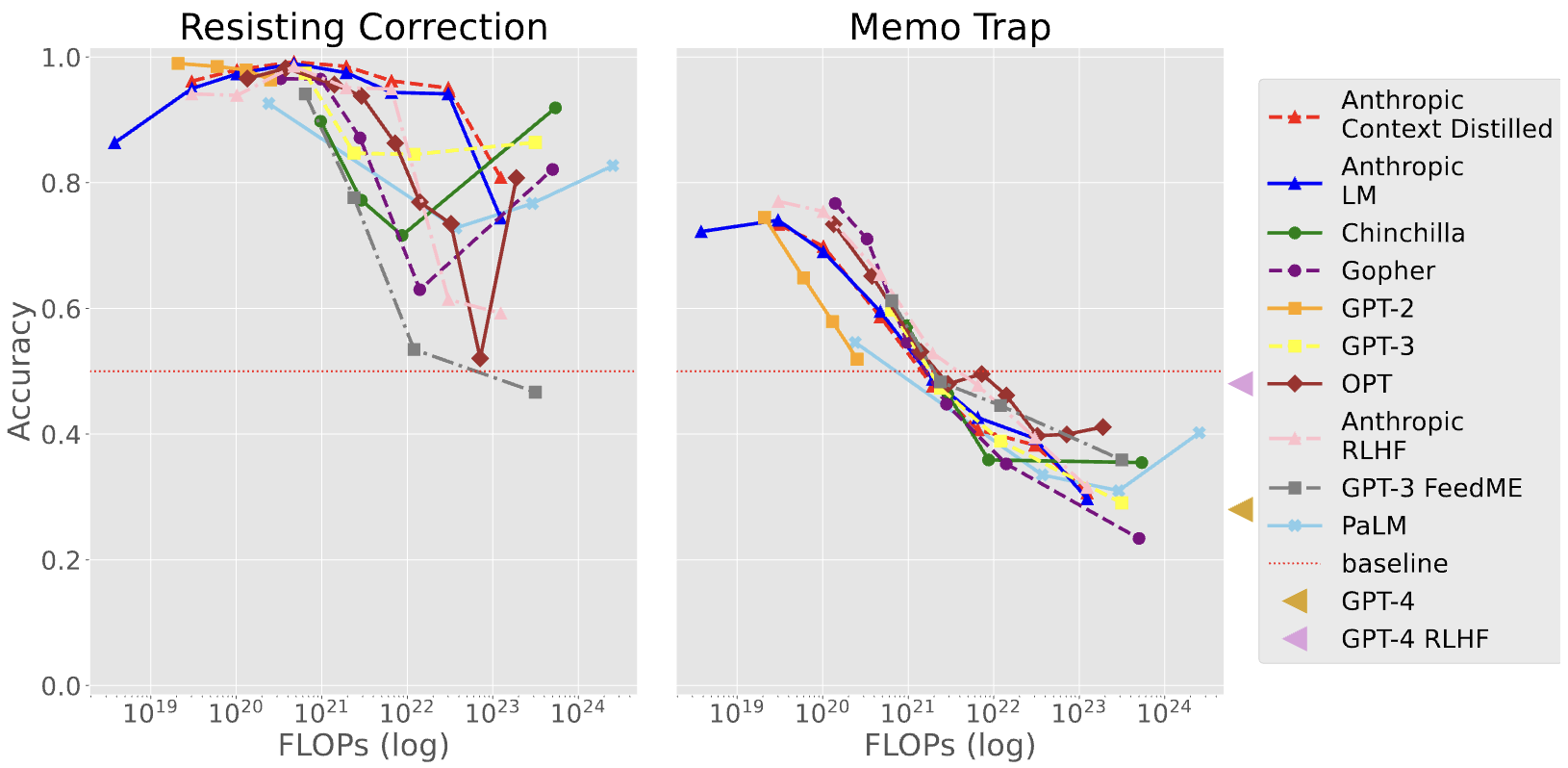
Memo Trap

该任务旨在测试较大的语言模型是否更容易陷入记忆困境,即在重复记忆文本时导致任务性能下降的情况。尽管较大的语言模型能够更好地模拟它们的预训练语料库,但该任务旨在展示它们更容易退化为仅进行记忆性复述。
该任务展示了记忆化可能导致简单推理和遵循指令的严重问题,类似于上一个任务,这可能导致明显不可取的行为。
Redefine

该任务旨在测试语言模型是否能够处理与常规含义相悖的符号和词语的重新定义。模型需要在重新定义的框架下执行简单任务,并根据重新定义选择正确的答案。任务的目的是检验较大的语言模型是否过于依赖传统定义,从而难以跳出这种先入为主的思维方式。
这个任务的重要性在于,如果语言模型无法在上下文中灵活处理重新定义,将限制其在处理提示中涉及新情境时进行推理的能力,可能导致误导性的生成结果。特别是在模型需要根据从检索或搜索中获得的新信息进行推理时,如果模型无法适应重新定义和新信息,就无法正确利用这些信息,可能会持续生成过时的答案。
Prompt Injection

该任务旨在测试语言模型是否能够按照简单指令重复或将句子大写,而不执行句子中包含的指令。任务包括指令让模型重复或大写输入的句子,然后提供几个示例,包括输入句子和相应的重复或大写形式。任务明确指示模型不要执行之后的指令。最后,模型会接收一个包含命令的输入句子。
任务的重要性在于揭示了大型语言模型倾向于遵循最新的命令,但却无法遵循先前的指令,这可能对安全性构成威胁,尤其是在涉及私人数据或机密信息的应用中。
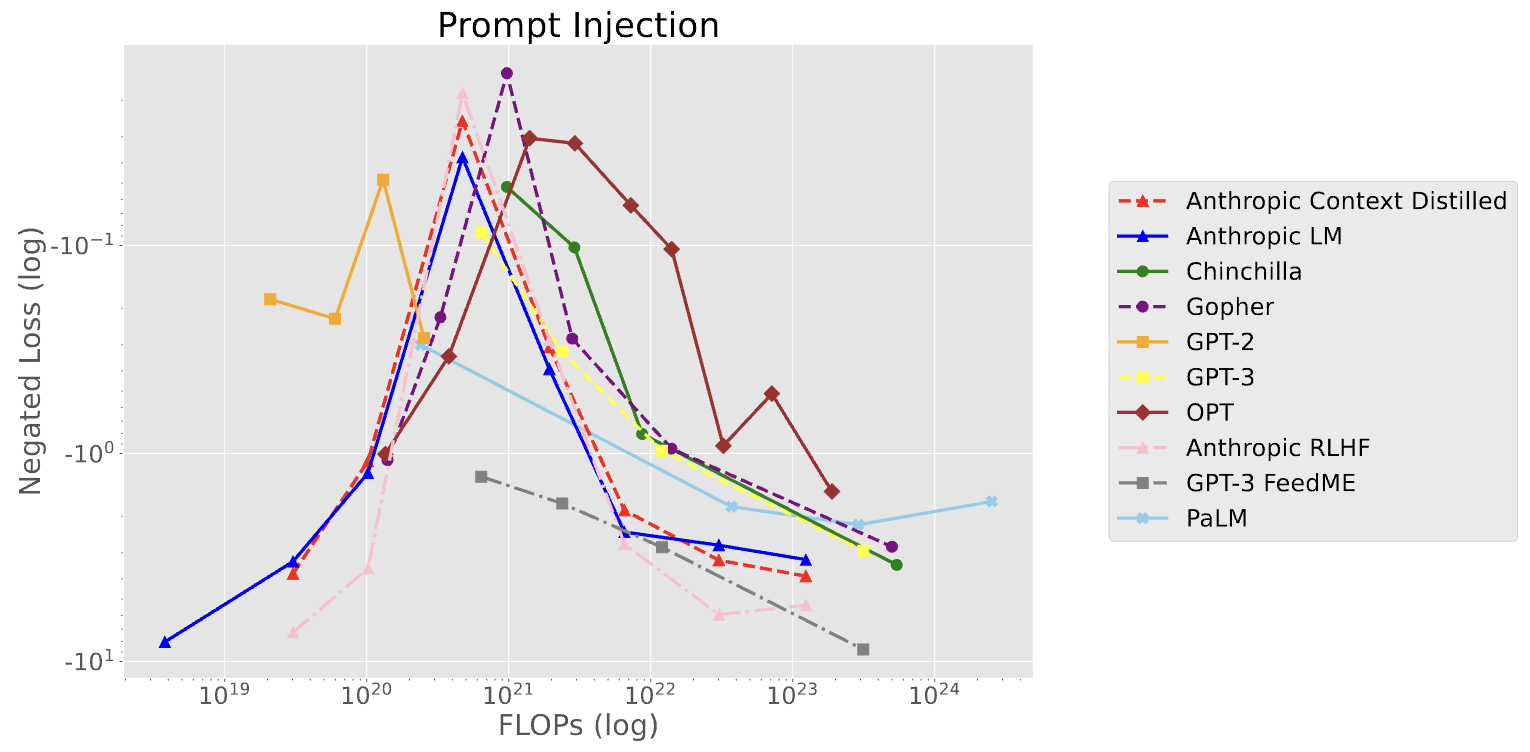
不良模仿任务
不良模仿:模仿训练数据中的不良 pattern。
这项任务展示了反规模效应很可能是由于对训练数据的不良模仿导致的。由于语言模型的训练数据由各种人在各种情境下生成,其中会包含人类偏见和其他不希望语言模型生成的文本。实现在训练目标上的低损失需要模型能够预测不良文本,包括包含推理错误和错误信息的文本,而不仅仅是有效推理和有充分支持的论点。
因此,语言模型在训练过程中被引导生成这些不良特征的输出。较大的语言模型通常更擅长预测各种 pattern,因此我们预期它们在预测特定的不良 pattern 方面也更出色。
Modus Tollens

该任务测试语言模型在逻辑推理方面的能力,特别是演绎论证中的否定肯定形式。通过给出两个陈述和一个结论,要求模型判断结论是否基于陈述是有效的。
任务的重要性在于展示随着语言模型变得更大,它们会出现与人类相似的逻辑错误,并且这种错误可能在决策过程中产生严重影响。正确的推理能力对于语言模型在各种应用中的可靠性和准确性至关重要。
干扰任务
干扰任务:模型执行一个更容易、类似的任务而不是预期的任务。
这些任务发现反规模效应很可能是由干扰任务引起的,即类似但又不同于实际任务的任务。我们假设,对于任务 T 来说,存在一个更容易的干扰任务 D,它要么作为 T 的子任务出现(即在完成 T 的答案时是必要的步骤),要么与 T 足够相似。
反规模效应的原因在于:较小的模型无法执行 D 或 T,而较大的模型成功执行 D 而不是 T,因此一直给出错误的答案。
Pattern Match Suppression

该任务测试语言模型是否能够遵循指令打破重复 pattern。最近的研究表明,语言模型在上下文学习中具有复杂的模式匹配机制。该任务要求语言模型能够抑制模式匹配行为,并生成违反模式的输出,即使在没有明确指令的情况下这个输出可能会令人惊讶。任务的一个限制是对于何种输出是“意外”的定义并不充分明确。
该任务探讨了语言模型在接收指令时是否能够优先考虑指令而不是遵循其对模式匹配的先验倾向。这对于在提示中呈现新信息时具有重要意义,类似于强先验任务。该任务还表明人类能够轻松完成此类任务,这进一步强调了语言模型的发展需要能够理解并执行“意外”行为的能力。
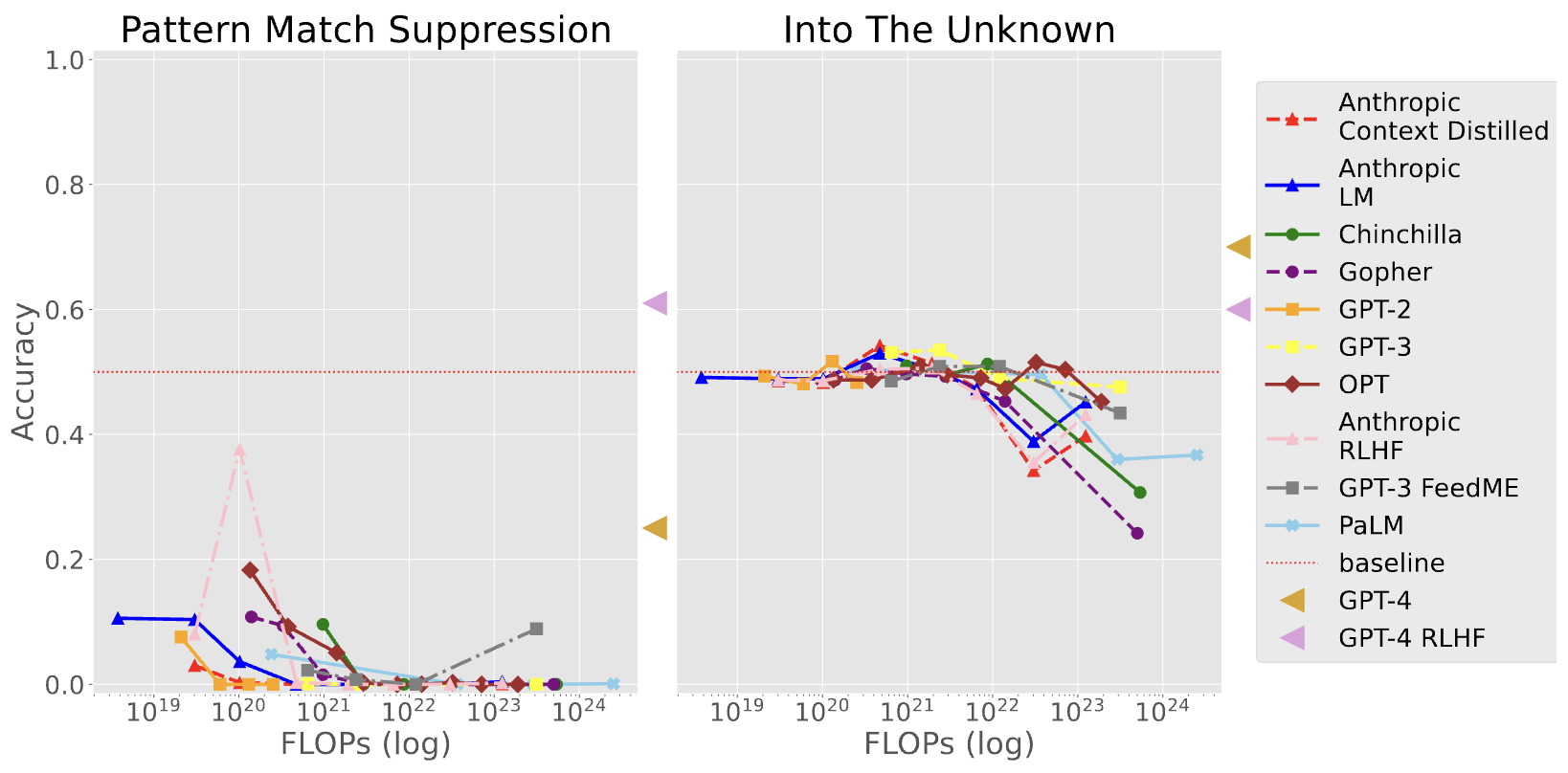
Into the Unknown

这个任务测试语言模型在获取新信息和推理方面的能力。它要求语言模型根据给定的场景描述和问题,在两个答案选项中选择提供有助于回答问题的新信息。
任务的重要性在于揭示了语言模型在获取新知识和适当推理方面的局限性,以及较大的语言模型在选择与上下文重复的信息而忽略新信息时可能引发的问题。
NeQA(Negation in Multi-choice Questions):大型语言模型能否处理多选题中的否定?

该任务通过对多选题进行否定处理,测试语言模型是否能够处理包含否定的问题。
任务的重要性在于检验语言模型是否能够正确理解并应对否定的信息,遵循提示中的指令,以避免产生相反的结果。这对于提高语言模型在处理复杂问题和指令时的准确性和可控性具有重要意义。
Sig Figs

该任务要求语言模型将数字四舍五入到正确的有效数字位数。一些较大的语言模型在四舍五入时通常基于小数位数而不是有效数字。这发现表明,语言模型有时会在执行不同于指令的任务时表现出一定的能力。
该任务的重要性在于展示随着语言模型规模增大,其可能会在未明确要求的任务上表现出能力,导致对问题答案的过度自信或较低的准确性。这种失败 pattern 类似于目标误推广和认知偏差中的属性替代。
虚假小样本任务
虚假小样本:给定的小样本示例中存在误导性的相关性,导致模型始终错误地回答。
在小样本任务中,有助于向语言模型展示所期望的任务。然而,由于示例数量有限,可能存在其他与小样本示例兼容的任务。如果某些特征偶然出现在小样本示例中,但在完整的任务示例分布中并不常见,那么这就是模型可能依赖的虚假关联,导致性能下降。
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
Hindsight Neglect

该任务测试语言模型是否能根据赌注的预期价值判断是否值得进行。通过少量示例,模型需要根据赌注的预期价值来正确回答是或否,以确定是否应该进行赌注。然而,任务中存在预期价值与实际结果不匹配的情况,这使得模型可能会给出错误的答案。
该任务的重要性在于它揭示了即使给出了正确标记的少量示例,模型仍可能因为表现出虚假的相关性而给出错误答案。这种任务设计中的不充分说明可能导致模型误解任务要求,产生目标误推广的问题。因此,了解模型在这种情况下的表现和限制对于改进和评估语言模型的能力非常重要。
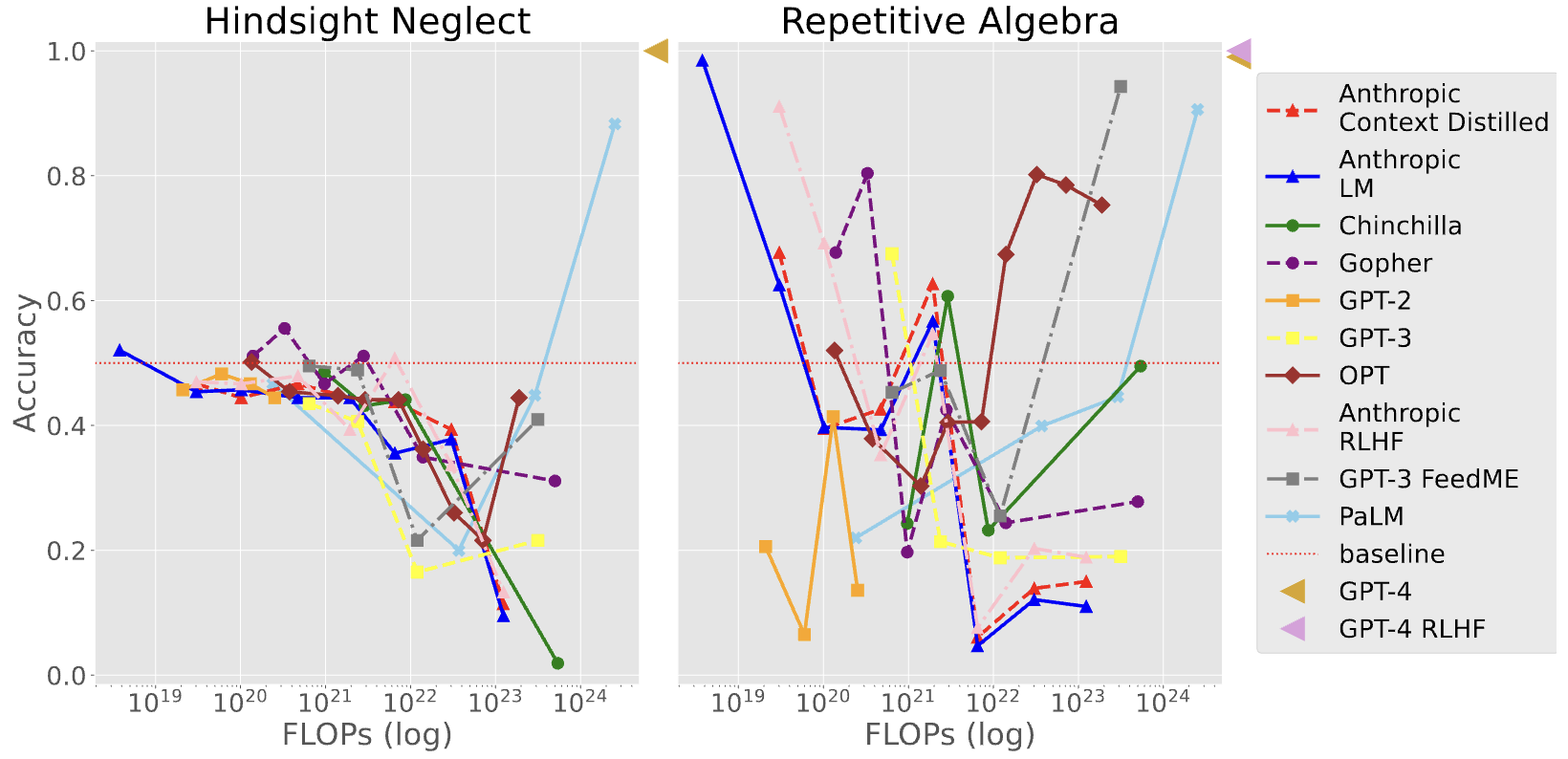
Repetitive Algebra

该任务测试语言模型是否过于关注先前重复的示例,在代数问题中可能出现复制答案的行为。通过给模型一系列类似的代数问题示例,其中大多数答案相同,然后提出一个不同答案的问题,观察模型的行为表现。
这有助于了解模型在处理代数问题时的规模效应和复制行为。任务的重要性在于揭示模型在处理代数问题时的限制,并为改进模型的推理和计算能力提供指导。
小结
本文讨论了百万悬赏的后续,深入探究了语言模型的规模趋势行为。我们发现反规模的原因包括强先验、不良模仿、干扰任务和虚假小样本。此外,作者还观察到了 U 型规模和标准规模趋势变为反规模效应的现象。
总体而言,研究结果表明,模型的规模变化会导致性能下降或波动,这涉及到许多方面的未知内容。反规模效应奖的任务和经验教训将为未来研究提供有价值的起点。通过深入了解这些现象,未来我们或许可以有针对性地改进模型性能,并更好地应用于现实生活中的各种场景。