文章目录
- 一、理论基础
- 1.前言
- 2.设计理念
- 2.1 ResNet算法
- 2.1.1 residual(残差结构)模块
- 2.1.2 residual的计算方式
- 2.1.3 ResNet中两种不同的residual
- 2.1.4 Batch Normalization(批归一化)
- 2.2 WideResNet(WRNs)算法
- 2.2.1 宽残差块
- 2.2.2 dropout(丢弃法)
- 2.2.3 卷积大小选择
- 4.评估分析
- 二、实战
- 1.数据预处理
- 2.数据读取
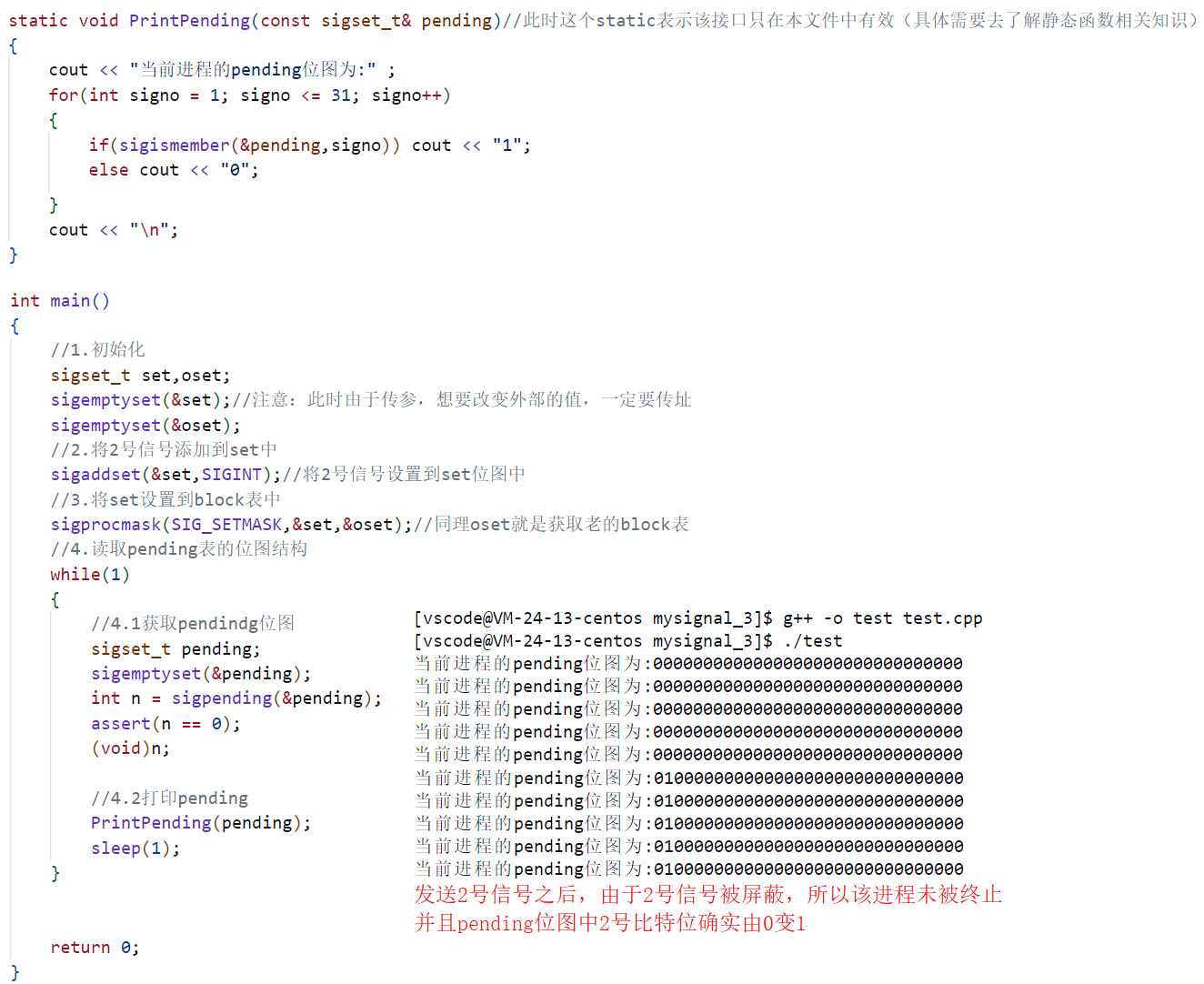
- 3.导入模型
- 4.打印输出模型的参数信息
- 5.模型训练
- 6.结果可视化
- 7.个体预测结果展示
- 三、总结
今天详解一下WideResNet算法,WideResNet(宽残差网络)是在ResNet网络的基础上改进的深度卷积神经网络架构,其主要特点是使用宽卷积层,增加了网络的通道数,从而提高了网络的表达能力和性能。WideResNet已经在图像分类、对象检测、语义分割等领域取得了很好的性能表现。
本次实战就是一个经典的分类问题:鸟类分类。
本次项目实战鸟类数据集主要分为4类,分别为bananaquit(蕉林莺)、Black Skimmer (黑燕鸥类)、Black Throated Bushtiti (黑喉树莺)、Cockatoo (凤头鹦鹉或葵花鹦鹉),总计565张。

一、理论基础
1.前言
在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如GoogLenet,VGG-16,Incepetion等模型。CNN史上的一个里程碑事件是ResNet模型的出现,ResNet可以训练出更深的CNN模型,从而实现更高的准确度。ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),进而训练出更深的CNN网络。
但是随着深度神经网络的继续发展,网络的层数也在不断地增加,而分类准确度每提高百分之一的代价几乎是层数的两倍。所以训练非常深的残差网络有一个问题,那就是特征利用率逐渐下降,这使得残差网络的训练非常慢。因此,为了解决这些问题,人们开始把注意力放在模型的宽度上面,于是就有了Wide Residual Networks (WRNs)架构的出现,该架构比通常使用的细且深的残差网络有着更好的性能。
今天我们就来详细讲解下Wide Residual Networks (WRNs)算法,该算法是基于ResNet的改进,在减少深度的同时增加了模型的宽度,下图为WRNs算法的具体模型配置。

Wideresnet论文原文:《Wide Residual Networks》
2.设计理念
上面已经说过,由于模型深度的继续增加在精度方面已经不能取得良好的回报,因此研究者们就开始从模型的宽度方面开始思索,最后发现了减少模型深度的同时增加模型的宽度也可以提高模型的精度。并且做了对比实验后发现,即使是一个简单的16层深度残差网络使用此架构后在准确性和效率方面也优于所有以前的深度残差网络,包括千层深度网络,在CIFAR、SVHN、COCO上实现了新的最先进的结果,并在ImageNet上实现了重大改进。
在讲解Wide Residual Networks (WRNs)算法之前,我们先讲解一下众所周知的ResNet算法。ResNet是一种深度神经网络模型,首次被提出时在ImageNet数据集上赢得冠军。与传统的深度神经网络不同,ResNet采用了残差单元(residual unit),通过在网络中添加残差单元来解决深度神经网络训练过程中发生的梯度消失和梯度爆炸等问题,并且能够让网络在更深的层数下取得更好的性能。
在ResNet中,每个残差单元内部包含两个卷积层和一个跳跃连接(shortcut),跳跃连接直接将输入信号从一个残差单元传递到下一个残差单元,减轻了梯度消失的问题。ResNet的特殊结构不仅能够提高深度神经网络的表达能力,还大幅度减少了模型的参数量,使得ResNet模型可以在不会过拟合的情况下获得更好的性能。
2.1 ResNet算法
2.1.1 residual(残差结构)模块
在ResNet提出之前,所有的神经网络都是通过卷积层和池化层的叠加组成的。
人们认为卷积层和池化层的层数越多,获取到的图片特征信息越全,学习效果也就越好。但是在实际的实验中发现,随着卷积层和池化层的叠加,不但没有出现学习效果越来越好的情况,反而两种问题:
-
梯度消失和梯度爆炸
- 梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
- 梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
-
退化问题
- 随着层数的增加,预测效果反而越来越差。如图2所示

图2 随着层数增加的预测效果
为了解决梯度消失或梯度爆炸问题, ResNet论文提出通过数据的预处理以及在网络中使用 BN(Batch Normalization)层来解决;
为了解决深层网络中的退化问题, 可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为 残差网络 (ResNets)。ResNet论文提出了 residual结构(残差结构)来减轻退化问题,下图是使用residual结构的卷积网络,可以看到随着网络的不断加深,效果并没有变差,而是变的更好了。(虚线是train error,实线是test error。

2.1.2 residual的计算方式
residual结构使用了一种shortcut的连接方式,也可理解为捷径。让特征矩阵隔层相加,注意F(X)和X形状要相同,所谓相加是特征矩阵相同位置上的数字进行相加。

“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思,它对每层的输入做一个reference(X), 学习形成残差函数, 而不是学习一些没有reference(X)的函数。这种残差函数更容易优化,能使网络层数大大加深。在上图的残差块中它有二层,如下表达式,其中 σ σ σ代表非线性函数ReLU。

然后通过一个shortcut,和第2个ReLU,获得输出y。

当需要对输入和输出维数进行变化时(如改变通道数目),可以在shortcut时对x做一个线性变换Ws,如下式。

2.1.3 ResNet中两种不同的residual

这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个“building block” 。其中右图又称为“bottleneck design”,目的就是为了降低参数的数目,实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1,如右图所示。新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
对于常规ResNet,可以用于34层或者更少的网络中,对于Bottleneck Design的ResNet通常用于更深的如101这样的网络中,目的是减少计算和参数量。
2.1.4 Batch Normalization(批归一化)
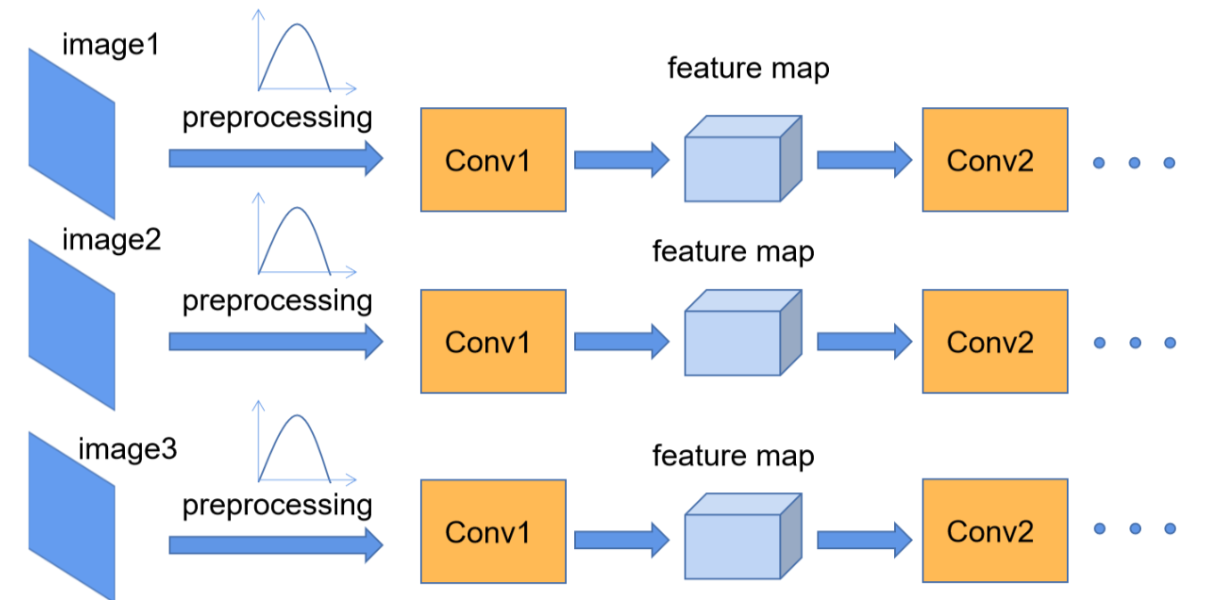
我们在图像预处理过程中通常会对图像进行批归一化处理,这样能够加速网络的收敛,如下图所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了(注意这里所说满足某一分布规律并不是指某一个feature map的数据要满足分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律)。而我们Batch Normalization的目的就是使我们的feature map满足均值为0,方差为1的分布规律。
2.2 WideResNet(WRNs)算法
2.2.1 宽残差块

- 图(a):ResNet的残差块结构
- 图(b):RresNet提出的bottleneck结构,用于更深的层
- 图(c):宽残差块结构,通过增加输出通道的数量使模型变得更宽
- 图(d):在两层卷积中加入了dropout
宽残差块是指在残差块内增加更多的卷积核,从而增加特征通道的数量。传统的残差块由两个卷积层组成,每个卷积层通常只有少量的卷积核。而在WideResNet中,每个残差块都包含两个卷积层,其中第二个卷积层的卷积核数目非常大,相当于将特征通道的数目提高了数倍。
通过增加特征通道的数量,WideResNet可以更好地捕获图像中丰富的特征信息,从而提高模型的准确性。此外,宽残差块还具有更好的梯度流动,能够更快地将梯度传递到较浅层的卷积层,从而加速模型的收敛速度。

如上图所示,Wide-Resnet只比Resnet多了一个加宽因子k,原来架构相当于K=1,N表示组中的块数,即将K改为1就是ResNet网络架构。
网络由一个初始卷积层conv1组成,然后是residual block的conv2、conv3和conv4的3组(每个大小为N),然后是平均池和最终分类层。在实验中,conv1的大小都是固定的,而引入的加宽因子k缩放了三组conv2-4中剩余块的宽度。
与原始架构相比,residual block中的批量归一化、激活和卷积的顺序从conv-BN-ReLU更改为BN-ReLU-conv。 卷积核都用 3 × 3 3\times3 3×3;正则化使用dropout,而ResNet用的BN在这里不好用了。
2.2.2 dropout(丢弃法)
因为网络的加宽导致参数量增加,所以WideResNet的研究者研究了正则化方法。残差网络已经具有提供正则化效果的批量归一化,但是它需要大量的数据扩充,为了避免数据扩充,所以研究者就使用了dropout正则化方法来防止过拟合,但是以前的卷积神经网络的dropout都是放在所有的卷积操作之后的,但是实验中研究者将dropout放入两个 3 × 3 3\times3 3×3卷积之间,而BN操作放在两个残差块之间,但是将顺序做了调整,将Conv->BN->ReLU改成BN->ReLU->Conv,展示了更快的训练和更好的结果。
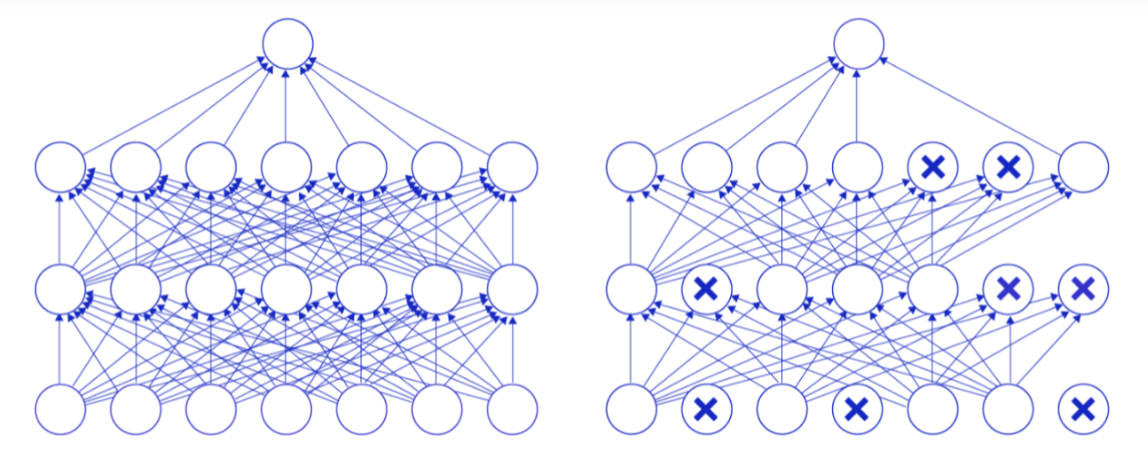
丢弃法(Dropout)是深度学习中一种常用的抑制过拟合的方法,其做法是在神经网络学习过程中,随机删除一部分神经元。训练时,随机选出一部分神经元,将其输出设置为0,这些神经元将不对外传递信号。
下图是Dropout示意图,左边是完整的神经网络,右边是应用了Dropout之后的网络结构。应用Dropout之后,会将标了
×
\times
×的神经元从网络中删除,让它们不向后面的层传递信号。在学习过程中,丢弃哪些神经元是随机决定,因此模型不会过度依赖某些神经元,能一定程度上抑制过拟合。
2.2.3 卷积大小选择
在论文中,作者设 B ( M ) B(M) B(M)表示残差块结构,其中 M M M是块中卷积层的核大小的列表。例如, B ( 3 , 1 ) B(3,1) B(3,1)表示具有 3 × 3 3×3 3×3和 1 × 1 1 × 1 1×1卷积层的残差块(假设正方形空间核)。注意,因为我们不考虑前面解释的瓶颈块,所以特征平面的数量在整个块中总是保持相同。其中作者回答了这样一个问题,即基本残差架构中的每个 3 × 3 3 × 3 3×3卷积层有多重要,它们是否可以由计算成本较低的 1 × 1 1 × 1 1×1层,甚至是 1 × 1 1 × 1 1×1和 3 × 3 3 × 3 3×3卷积层的组合来代替,例如 B ( 1 , 3 ) B(1,3) B(1,3)或 B ( 1 , 3 ) B(1,3) B(1,3)。这可以增加或减少块的代表能力。因此,我们用以下组合进行实验(注意,最后一个组合,即 B ( 3 , 1 , 1 ) B(3,1,1) B(3,1,1)类似于有效的网络中网络架构):

作者首先使用具有不同块类型 B B B的训练过的网络来报告结果(报告的结果在CIFAR-10上),并将WRN-40-2用于块 B ( 1 , 3 , 1 ) B(1,3,1) B(1,3,1)、 B ( 3 , 1 ) B(3,1) B(3,1)、 B ( 1 , 3 ) B(1,3) B(1,3)和 B ( 3 , 1 , 1 ) B(3,1,1) B(3,1,1),因为这些块只有一个 3 × 3 3×3 3×3卷积。为了保持参数数量的可比性,作者训练了其他层数较少的网络:WRN-28-2-B(3,3)和WRN-22-2B(3,1,3)。在图10中提供了结果,包括 5 5 5次运行的中值测试准确度和每个训练时期的时间。块 B ( 3 , 3 ) B(3,3) B(3,3)被证明是最好的,并且 B ( 3 , 1 ) B(3,1) B(3,1)和 B ( 3 , 1 , 3 ) B(3,1,3) B(3,1,3)在精度上非常接近 B ( 3 , 3 ) B(3,3) B(3,3),具有较少的参数和较少的层数。 B ( 3 , 1 , 3 ) B(3,1,3) B(3,1,3)比其他的快一点点。

4.评估分析
不同深度和宽度的WideResNet模型在CIFAR-10与CIFAR-100评估结果如图12所示:
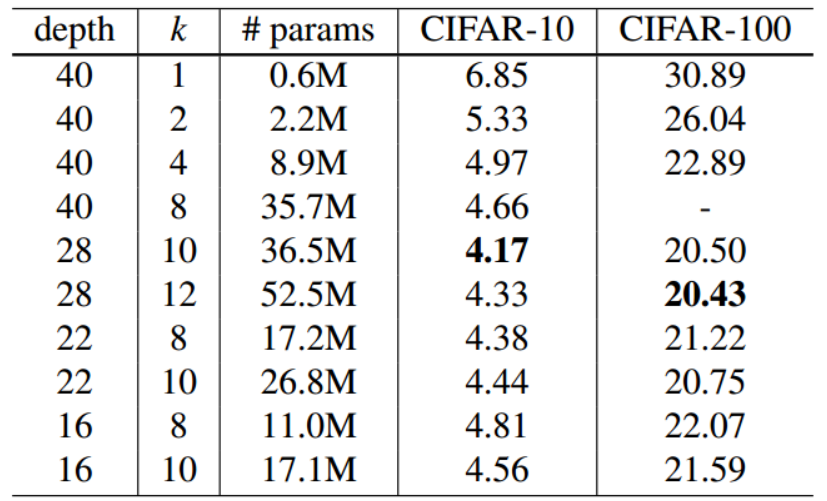
不同方法在CIFAR-10和CIFAR-100上的测试误差,具有适度的数据增加(翻转/转换)和平均值/标准差正常化。结果如图13所示,在第二列中,k是加宽因子。

Dropout引入对网络性能的影响结果如图14所示,总的来说,dropout显示出其自身是一种有效的正则化技术。它可以用来进一步改善加宽的结果,同时也是对加宽因子的补充。与传统的细高Resnet相比,矮胖WRN可具有更好的精度。
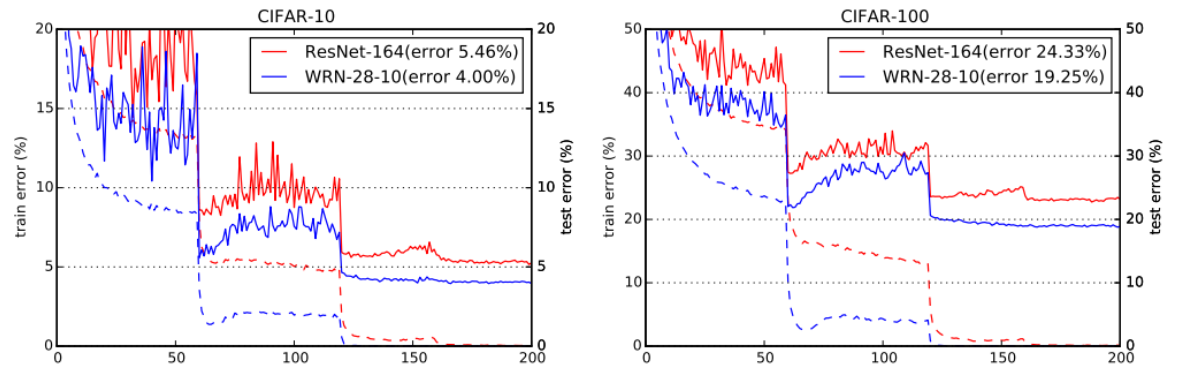
绿色的线表示WideResNet损失误差曲线,红色表示原ResNet损失曲线
下图为速度测试结果,通过结果我们可以看出宽网络比瘦网络的效率要高很多倍。

二、实战
1.数据预处理
- 解压数据集
# 注意路径
!unzip /home/aistudio/data/data223822/bird_photos.zip -d /home/aistudio/work
由于我们处理数据集文件的时候,里面多一个ipynb_checkpoints文件,因此需要通过以下命令删除以下。切记!一定要删除~
%cd /home/aistudio/work
!rm -rf .ipynb_checkpoints
- 划分数据集
import os
import random
train_ratio = 0.7
test_ratio = 1-train_ratio
rootdata = "/home/aistudio/work/"
train_list, test_list = [],[]
data_list = []
class_flag = -1
for a,b,c in os.walk(rootdata):
for i in range(len(c)):
data_list.append(os.path.join(a,c[i]))
for i in range(0, int(len(c)*train_ratio)):
train_data = os.path.join(a, c[i])+' '+str(class_flag)+'\n'
train_list.append(train_data)
for i in range(int(len(c)*train_ratio),len(c)):
test_data = os.path.join(a,c[i])+' '+str(class_flag)+'\n'
test_list.append(test_data)
class_flag += 1
random.shuffle(train_list)
random.shuffle(test_list)
with open('/home/aistudio/work/train.txt','w',encoding='UTF-8') as f:
for train_img in train_list:
f.write(str(train_img))
with open('/home/aistudio/work/test.txt', 'w', encoding='UTF-8') as f:
for test_img in test_list:
f.write(test_img)
2.数据读取
- 导入以下所需库
import paddle
import paddle.nn.functional as F
import numpy as np
import math
import random
import os
from paddle.io import Dataset # 导入Datasrt库
import paddle.vision.transforms as transforms
from PIL import Image
- 使用 paddle.io.DataLoader 定义数据读取器
# 归一化
transform_BZ = transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
class LoadData(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.train_tf = transforms.Compose([
transforms.Resize(32), # 调整图像大小为32x32
transforms.RandomHorizontalFlip(), # 随机左右翻转图像
transforms.RandomVerticalFlip(), # 随机上下翻转图像
transforms.ToTensor(), # 将 PIL 图像转换为张量
transform_BZ # 执行某些复杂变换操作
])
self.val_tf = transforms.Compose([
transforms.Resize(32), # 调整图像大小为32x32
transforms.ToTensor(), # 将 PIL 图像转换为张量
transform_BZ # 执行某些变换操作
])
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x: x.strip().split(' '), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 32. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 32
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img_path = os.path.join('',img_path)
img = Image.open(img_path)
img = img.convert("RGB")
img = self.padding_black(img)
if self.train_flag:
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs_info)
- 加载训练集和测试集
train_data = LoadData("/home/aistudio/work/train.txt", True)
test_data = LoadData("/home/aistudio/work/test.txt", True)
#数据读取
train_loader = paddle.io.DataLoader(train_data, batch_size=32, shuffle=True)
test_loader = paddle.io.DataLoader(test_data, batch_size=32, shuffle=True)
3.导入模型
import math
import paddle.nn as nn
import paddle
import paddle.nn.functional as F
from paddle import fluid
import numpy as np
class BasicBlock(nn.Layer):
def __init__(self, in_planes, out_planes, stride, dropRate=0.0):
super(BasicBlock, self).__init__()
self.bn1 = nn.BatchNorm2D(in_planes)
self.relu1 = nn.ReLU()
self.conv1 = nn.Conv2D(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1)
self.bn2 = nn.BatchNorm2D(out_planes)
self.relu2 = nn.ReLU()
self.conv2 = nn.Conv2D(out_planes, out_planes, kernel_size=3, stride=1,
padding=1)
self.droprate = dropRate
self.equalInOut = (in_planes == out_planes)
self.convShortcut = (not self.equalInOut) and nn.Conv2D(in_planes, out_planes, kernel_size=1, stride=stride,
padding=0) or None
def forward(self, x):
if not self.equalInOut:
x = self.relu1(self.bn1(x))
else:
out = self.relu1(self.bn1(x))
out = self.relu2(self.bn2(self.conv1(out if self.equalInOut else x)))
if self.droprate > 0:
out = F.dropout(out, p=self.droprate, training=True)
out = self.conv2(out)
return paddle.add(x if self.equalInOut else self.convShortcut(x), out)
class NetworkBlock(nn.Layer):
def __init__(self, nb_layers, in_planes, out_planes, block, stride, dropRate=0.0):
super(NetworkBlock, self).__init__()
self.layer = self._make_layer(block, in_planes, out_planes, nb_layers, stride, dropRate)
def _make_layer(self, block, in_planes, out_planes, nb_layers, stride, dropRate):
layers = []
for i in range(int(nb_layers)):
layers.append(block(i == 0 and in_planes or out_planes, out_planes, i == 0 and stride or 1, dropRate))
return nn.Sequential(*layers)
def forward(self, x):
return self.layer(x)
class WideResNet(nn.Layer):
def __init__(self,num_classes, depth=28,widen_factor=1, dropRate=0.0):
super(WideResNet, self).__init__()
nChannels = [16, 16*widen_factor, 32*widen_factor, 64*widen_factor, 64*widen_factor*10]
assert((depth - 4) % 6 == 0)
n = (depth - 4) / 6
block = BasicBlock
# 1st conv before any network block
self.conv1 = nn.Conv2D(3, nChannels[0], kernel_size=3, stride=1,
padding=1)
self.dropout = nn.Dropout(0.3)
# 1st block
self.block1 = NetworkBlock(n, nChannels[0], nChannels[1], block, 1, dropRate)
# 2nd block
self.block2 = NetworkBlock(n, nChannels[1], nChannels[2], block, 2, dropRate)
# 3rd block
self.block3 = NetworkBlock(n, nChannels[2], nChannels[3], block, 2, dropRate)
# global average pooling and classifier
self.bn1 = nn.BatchNorm2D(nChannels[3])
self.relu = nn.ReLU()
self.ID_mat = paddle.eye(num_classes).cuda()
self.fc = nn.Linear(nChannels[3], num_classes)
self.fc.weight.requires_grad = False # Freezing the weights during training
self.nChannels = nChannels[3]
for m in self.sublayers():
if isinstance(m, nn.Conv2D):
n = m.weight.shape[0] * m.weight.shape[1] * m.weight.shape[2]
v = np.random.normal(loc=0.,scale=np.sqrt(2./n),size=m.weight.shape).astype('float32')
m.weight.set_value(v)
elif isinstance(m, nn.BatchNorm):
m.weight.set_value(np.ones(m.weight.shape).astype('float32'))
m.bias.set_value(np.zeros(m.bias.shape).astype('float32'))
def forward(self, x):
out = self.conv1(x)
out = self.block1(out)
out = self.block2(out)
out = self.block3(out)
out = self.relu(self.bn1(out))
out = F.avg_pool2d(out, 8)
out = fluid.layers.reshape(out,(-1, self.nChannels))
out = self.fc(out)
return out
4.打印输出模型的参数信息
import paddle
model = WideResNet(num_classes=4)
params_info = paddle.summary(model,(1, 3, 32, 32))
print(params_info)
打印结果如下所示:

5.模型训练
epoch_num = 60 #训练轮数
batch_size = 16
learning_rate = 0.001 #学习率
val_acc_history = []
val_loss_history = []
def train(model):
print('start training ... ')
# turn into training mode
model.train()
opt = paddle.optimizer.Adam(learning_rate=learning_rate,
parameters=model.parameters())
for epoch in range(epoch_num):
acc_train = []
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
acc_train.append(acc.numpy())
if batch_id % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
avg_acc = np.mean(acc_train)
print("[train] accuracy: {}".format(avg_acc))
loss.backward()
opt.step()
opt.clear_grad()
# evaluate model after one epoch
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(test_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[test] accuracy/loss: {}/{}".format(avg_acc, avg_loss))
val_acc_history.append(avg_acc)
val_loss_history.append(avg_loss)
model.train()
train(model)
paddle.save(model.state_dict(), "model.pdparams")
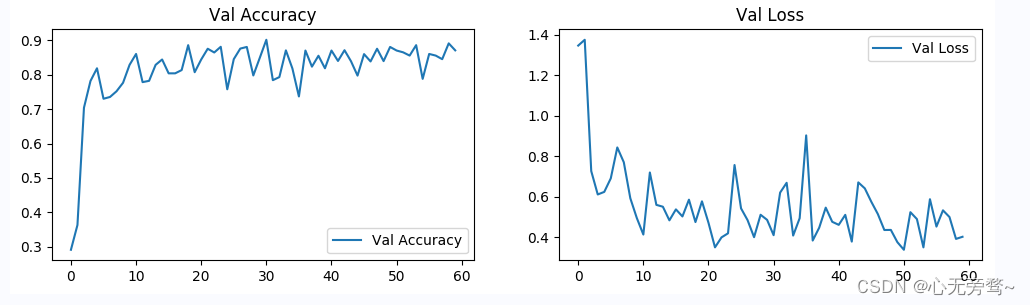
6.结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
epochs_range = range(epoch_num)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, val_acc_history, label='Val Accuracy')
plt.legend(loc='lower right')
plt.title('Val Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, val_loss_history, label='Val Loss')
plt.legend(loc='upper right')
plt.title('Val Loss')
plt.show()
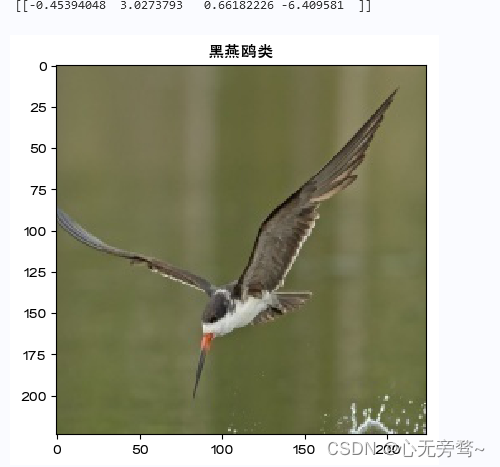
7.个体预测结果展示
data_transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize((32, 32)),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
img = Image.open("/home/aistudio/work/BlackSkimmer/008.jpg")
plt.imshow(img)
image=data_transform(img)
plt.rcParams['font.sans-serif']=['FZHuaLi-M14S']
name=['蕉林莺','黑燕鸥类','黑喉树莺','凤头鹦鹉']
image=paddle.reshape(image,[1,3,32,32])
model.eval()
predict=model(image)
print(predict.numpy()) #明显可以看出是第0个标签大
plt.title(name[predict.argmax(1)])
plt.show()
三、总结
-
WideResNet(宽残差网络)是一种深度卷积神经网络架构,其主要特点是使用宽卷积层,增加了网络的通道数,从而提高了网络的表达能力和性能。该网络通过引入残差连接来缓解深度网络的梯度消失问题,并通过使用批归一化和dropout等正则化技术来提高网络的鲁棒性。WideResNet已经在图像分类、对象检测、语义分割等领域取得了很好的性能表现。
-
宽残差块是指在残差块内增加更多的卷积核,从而增加特征通道的数量。传统的残差块由两个卷积层组成,每个卷积层通常只有少量的卷积核。而在WideResNet中,每个残差块都包含两个卷积层,其中第二个卷积层的卷积核数目非常大,相当于将特征通道的数目提高了数倍。 通过增加特征通道的数量,WideResNet可以更好地捕获图像中丰富的特征信息,从而提高模型的准确性。此外,宽残差块还具有更好的梯度流动,能够更快地将梯度传递到较浅层的卷积层,从而加速模型的收敛速度。
-
在论文中,作者设 B ( M ) B(M) B(M)表示残差块结构,其中 M M M是块中卷积层的核大小的列表。例如, B ( 3 , 1 ) B(3,1) B(3,1)表示具有 3 × 3 3×3 3×3和 1 × 1 1 × 1 1×1卷积层的残差块(假设正方形空间核)。注意,因为我们不考虑前面解释的瓶颈块,所以特征平面的数量在整个块中总是保持相同。其中作者回答了这样一个问题,即基本残差架构中的每个 3 × 3 3 × 3 3×3卷积层有多重要,它们是否可以由计算成本较低的 1 × 1 1 × 1 1×1层,甚至是 1 × 1 1 × 1 1×1和 3 × 3 3 × 3 3×3卷积层的组合来代替,例如 B ( 1 , 3 ) B(1,3) B(1,3)或 B ( 1 , 3 ) B(1,3) B(1,3)。这可以增加或减少块的代表能力。
原文链接:https://aistudio.baidu.com/aistudio/projectdetail/6451612