一、背景
前段时间,在做项目重构的时候,遇到很多地方需要做很多的条件判断。当然可以用很多的if-else判断去解决,但是当时也不清楚怎么回事,就想玩点别的。于是乎,就去调研了规则引擎。
当然,市面上有很多成熟的规则引擎,功能很多,性能很好。但是,就是想玩点不一样的(大家做技术选型别这样,这个是反面教材)。最终一款URule的规则引擎吸引了我,主要还是采用浏览器可直接配置,不需要过多安装,可视化规则也做的不错。经过一系列调研,后面就把它接入了项目中,顺便记录下调研的结果。
二、介绍
规则引擎其实是一种组件,它可以嵌入到程序当中。将程序复杂的判断规则从业务代码中剥离出来,使得程序只需要关心自己的业务,而不需要去进行复杂的逻辑判断;简单的理解是规则接受一组输入的数据,通过预定好的规则配置,再输出一组结果。
当然,市面上有很多成熟的规则引擎,如:Drools、Aviator、EasyRules等等。但是URule,它可以运行在Windows、Linux、Unix等各种类型的操作系统之上,采用纯浏览器的编辑模式,不需要安装工具,直接在浏览器上编辑规则和测试规则。
当然这款规则引擎有开源和pro版本的区别,至于pro版是啥,懂的都懂,下面放个表格,了解下具体的区别
| 特性 | PRO版 | 开源版 |
|---|---|---|
| 向导式决策集 | 有 | 有 |
| 脚本式决策集 | 有 | 有 |
| 决策树 | 有 | 有 |
| 决策流 | 有 | 有 |
| 决策表 | 有 | 有 |
| 交叉决策表 | 有 | 无 |
| 复杂评分卡 | 有 | 无 |
| 文件名、项目名重构 | 有 | 无 |
| 参数名、变量常量名重构 | 有 | 无 |
| Excel决策表导入 | 有 | 无 |
| 规则集模版保存与加载 | 有 | 无 |
| 中文项目名和文件名支持 | 有 | 无 |
| 服务器推送知识包到客户端功能的支持 | 有 | 无 |
| 知识包优化与压缩的支持 | 有 | 无 |
| 客户端服务器模式下大知识包的推拉支持 | 有 | 无 |
| 规则集中执行组的支持 | 有 | 无 |
| 规则流中所有节点向导式条件与动作配置的支持 | 有 | 无 |
| 循环规则多循环单元支持 | 有 | 无 |
| 循环规则中无条件执行的支持 | 有 | 无 |
| 导入项目自动重命名功能 | 有 | 无 |
| 规则树构建优化 | 有 | 无 |
| 对象查找索引支持 | 有 | 无 |
| 规则树中短路计算的支持 | 有 | 无 |
| 规则条件冗余计算缓存支持 | 有 | 无 |
| 基于方案的批量场景测试功能 | 有 | 无 |
| 知识包调用监控 | 有 | 无 |
| 更为完善的文件读写权限控制 | 有 | 无 |
| 知识包版本控制 | 有 | 无 |
| SpringBean及Java类的热部署 | 有 | 无 |
| 技术支持 | 有 | 无 |
三、安装使用
实际使用时,有四种使用URule Pro的方式,分别是嵌入式模式、本地模式、分布式计算模式以及独立服务模式。
但是我们这里不考虑URule Pro,咱自己整个开源版,在开源版集成springboot的基础上做一个二次开发,搜了一圈,其实就有解决方案。大致的项目模块如下:

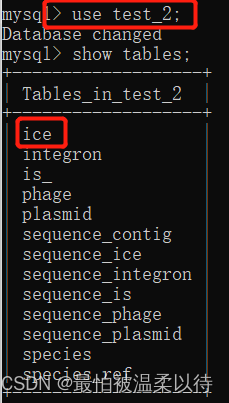
自己创建个空数据库,只需要在edas-rule-server服务中修改下数据库的配置,然后启动服务即可。第一次启动完成,数据库中会创建表。
properties
复制代码spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/urule-data?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false
spring.datasource.username=root
spring.datasource.password=mysql
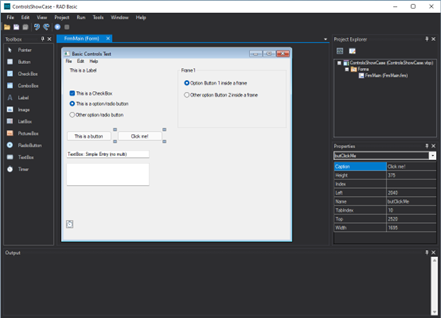
上面说过,它是纯用浏览器进行编辑,配置规则的,只需要打开浏览器,输入地址:http://localhost:8090/urule/frame,看到这个界面,就说明启动成功了。

四、基础概念
3.1整体介绍
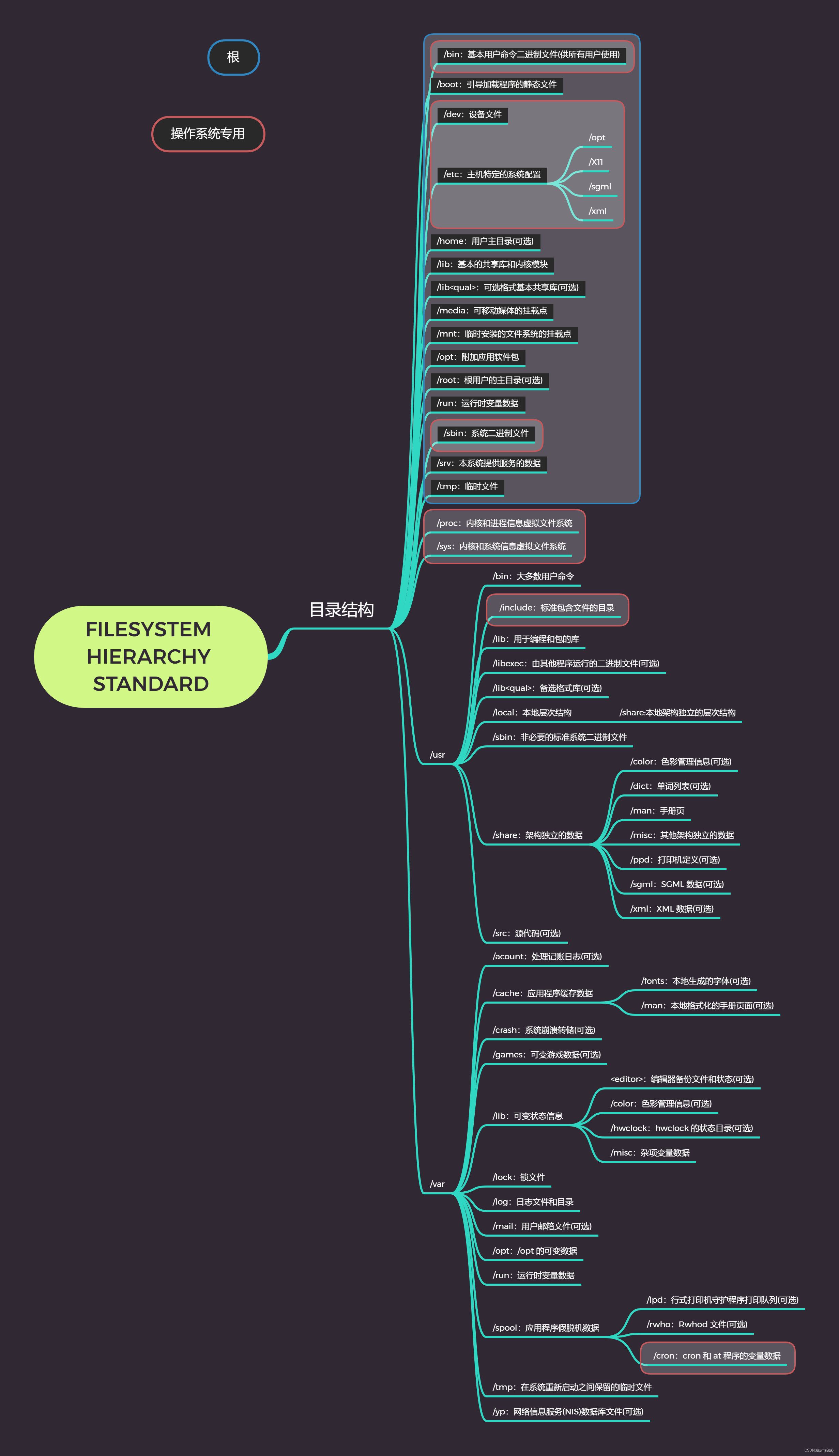
先说下URule它的构成部分,主要是两部分:1、设计器部分 2、规则执行引擎。设计器部分主要是库文件和规则文件构成。下面看下整体的结构图

3.2库文件
如上图介绍的,库文件有4种,包括变量库,参数库,常量库和动作库。其实类似于Java开发的系统中的实体对象,枚举,常量以及方法。
上面说过,规则都是可视化配置的。在配置规则的过程中,就需要引入各种已经定义好的库文件,再结合业务需求,从而配置出符合业务场景的业务规则,所以哪里都有库文件的身影。
3.2.1变量库文件
在业务开发中,我们会创建很多Getter和Setter的Java类,比如PO、VO、BO、DTO、POJO等等,其实这些类new对象后主要起到的作用就是数据的载体,用来传输数据。
在URule中,变量库就是用来映射这些对象,然后可以在规则中使用,最终完成业务和规则的互动。最后上一张图,用来创建变量库
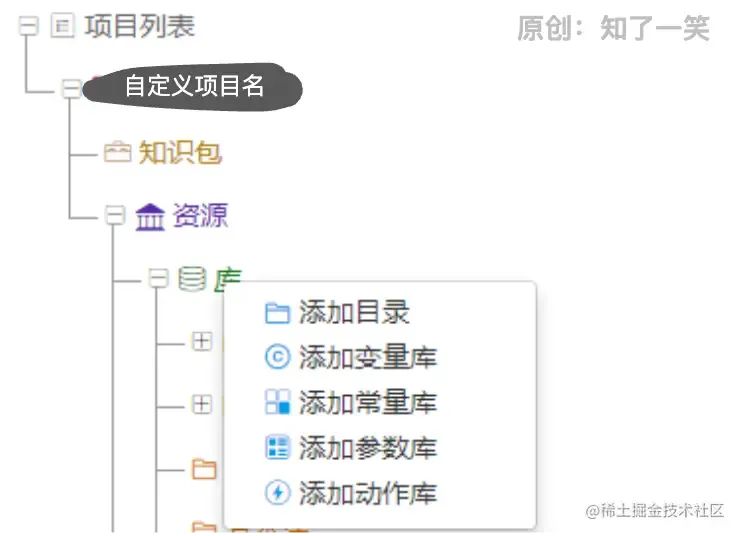
对了,上面废话了这么多可视化配置,这才是第一次展示配置界面,惭愧惭愧。
上图一目了然,在“库”这个菜单底下右键,然后点击添加变量库即可,最后定义自己喜欢的变量库名,当然名字只支持中文或者英文,其他字符不可用。

创建完变量库后,就可以对变量库进行编辑,可以认为就是给POJO添加属性

也不弯弯绕绕讲什么术语,就个人理解。图左边是创建类,其中名称是它的别名,配置规则用它代替这个类。图右边是类的属性,我这里随便写了几个,估计看了懂得都懂。
最后在业务系统中创建对应的类,注意全限定名和配置变量库的类路径一致。
package com.cicada;
import com.bstek.urule.model.Label;
import lombok.Data;
/**
* @author 往事如风
* @version 1.0
* @date 2023/3/3 15:38
* @description
*/
@Data
public class Stu {
@Label("姓名")
private String name;
@Label("年龄")
private int age;
@Label("班级")
private String classes;
}
最后说下这个@Label注解,这个是由URule提供的注解,主要是描述字段的属性,跟变量库的标题一栏一致就行。听官方介绍可以通过这个注解,实现POJO属性和变量库属性映射。就是POJO写好,然后对应规则的变量库就不需要重新写,可以直接生成。反正就有这个功能,这里就直接一笔带过了。



![强化学习从基础到进阶-常见问题和面试必知必答[7]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)

![[C++] 刷题日记](https://img-blog.csdnimg.cn/863681a16bf9432398264c5c22beeafb.png)