文章目录
- 1.Two-Stage方法
- 1.1 Faster R-CNN
- 1.2 R-FCN
- 2.One-Stage方法
- 2.1 YOLOv3(你只看一次)
- 2.2 SSD(单次多框检测器)
- 3.传统滑动窗口方法
机器视觉领域中常见的目标检测方法主要分为以下两类:
- Two-Stage方法1:在这类方法中,首先使用一个分类器(如SVM、神经网络等)将目标与背景区分开,然后再确定目标的位置。
这个过程通常需要两步:
(1)先进行候选区域(Region Proposal)生成,将图像中可能包含目标的区域提取出来;
(2)再在候选区域中进行分类与位置精修。代表性算法有:R-CNN(Region-based Convolutional Neural Networks)、Fast R-CNN、Faster R-CNN、YOLO(You Only Look Once)和SSD(Single Shot MultiBox Detector)等。 - One-Stage方法2:在这类方法中,通常直接在原始图像上进行目标检测,不需要进行候选区域的生成。代表性算法有:YOLO、YOLOv2、YOLOv3、YOLOv4和YOLOv5等。
值得注意的是,尽管这些方法在检测准确性上有一定差异,但它们的性能与速度并非不可兼得。通过改进模型结构和训练策略,可以在保证检测精度的前提下,提高模型的速度和计算资源需求的降低。
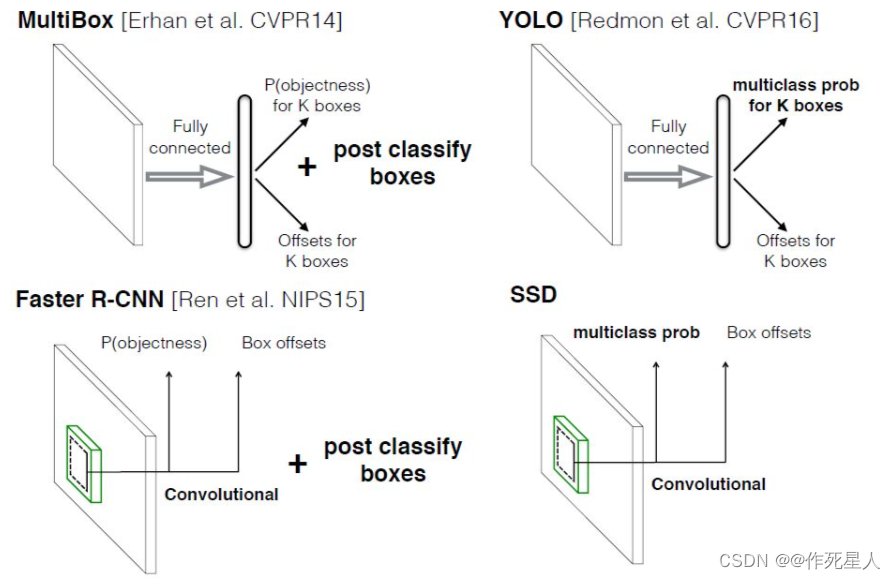
不同算法的基本框架图
1.Two-Stage方法
Two-Stage方法首先使用预选区域提取(Region Proposal)产生候选框,然后对候选框进行分类和边界框回归。这类方法速度相对较慢但精度较高。常见的Two-Stage方法有Faster R-CNN、R-FCN、YOLOv2等。
1.1 Faster R-CNN
Faster R-CNN是一种用于物体检测的卷积神经网络(Convolutional Neural Network, CNN)方法。
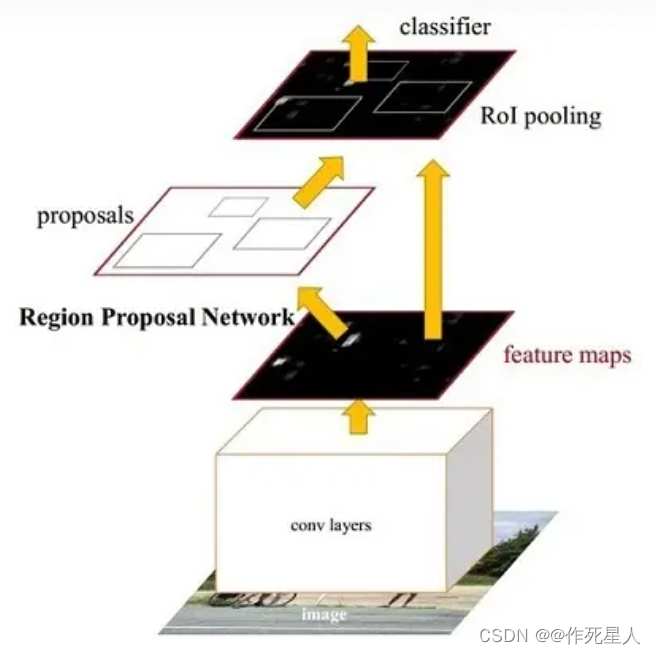
Faster R-CNN 使用区域生成网络(Region Proposal Network, RPN)来生成可能包含物体的候选区域(Regions of Interest, RoIs),然后在这些候选区域上训练物体检测器(Object Detector, Detector)。这种方法比传统的滑动窗口方法更快。

在Halcon中,可以使用以下算子实现:
dev_close_window()
dev_open_file_dialog ('choose file', '*.png', '', 'path/to/your/image', '*.png', ['Image', 'path/to/your/image'])
read_image (Image, 'path/to/your/image')
convert_image_color (Image, Image, 'RGB')
dev_display (Image)
dev_display (Dog)
region_copy (Region, RegionCopy)
connection (RegionCopy, ConnectedRegions)
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 20000, 1000000)
gen_empty_obj (Obj)
append_rectangle2 (Obj, SelectedRegions, 12, 12)
text_obj_detection (SelectedRegions, ObjectTexts, 'both', 'true', 'false', 'true', 'true', 'true', 'true', 'true')
推荐阅读这篇文章深入了解:一文读懂Faster RCNN
1.2 R-FCN
R-FCN(Region-based Fully Convolutional Networks)是一种用于物体检测的卷积神经网络方法。与 Faster R-CNN 类似,R-FCN 使用 FPN (Feature Pyramid Network) 进行多尺度特征提取。
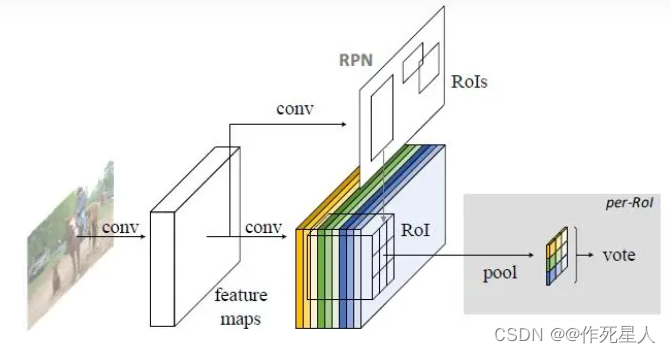
但是,R-FCN 使用全卷积网络(Fully Convolutional Networks)在每个尺度上进行物体检测,而不是采用候选区域方法。这使得 R-FCN 在不同尺度的图像上表现出更好的性能。
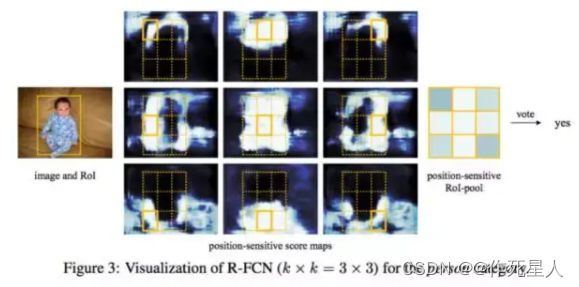
在Halcon中,可以使用以下算子实现:
dev_close_window()
dev_open_file_dialog ('choose file', '*.png', '', 'path/to/your/image', '*.png', ['Image', 'path/to/your/image'])
read_image (Image, 'path/to/your/image')
convert_image_color (Image, Image, 'RGB')
dev_display (Image)
dev_display (Dog)
region_copy (Region, RegionCopy)
connection (RegionCopy, ConnectedRegions)
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 20000, 1000000)
gen_empty_obj (Obj)
append_rectangle2 (Obj, SelectedRegions, 12, 12)
connection (Obj, Connection)
这里我们使用了Python的OpenCV库和Halcon库实现目标检测。Python代码如下:
import cv2
import numpy as np
def detect_objects(image_path):
# 加载图像
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 创建Halcon对象
halcon_objects = []
# 使用Halcon读取图像
ho_image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 使用Halcon提取特征
features = detect_objects_with_hasc(ho_image)
# 找到感兴趣的物体
found_objects = []
for ho_feature in features:
if ho_feature.GetPoses():
for obj in ho_feature.GetObjects():
obj = cv2.CvPoint2D32f(obj.GetPosition()[0], obj.GetPosition()[1])
obj = cv2.boxPoints(obj)
if obj.shape != (5, 5):
found_objects.append(obj)
# 显示结果
for obj in found_objects:
cv2.rectangle(image, (obj[0], obj[1]), (obj[2], obj[3]), (0, 255, 0), 2)
cv2.putText(image, "Object", (obj[0], obj[1]), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow("Halcon Object Detection", image)
cv2.waitKey(0)
if __name__ == "__main__":
image_path = "path/to/your/image.png"
detect_objects(image_path)
2.One-Stage方法
One-Stage方法直接在输出层生成目标边界框,速度快但精度相对较低。这类方法通常使用候选区域提取(Region Proposal)和分类两个阶段,候选区域在输入图像中生成大量候选框,然后进行分类和边界框回归。常见的One-Stage方法有YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)等。
2.1 YOLOv3(你只看一次)
YOLO(You Only Look Once)是一种用于物体检测的卷积神经网络方法。
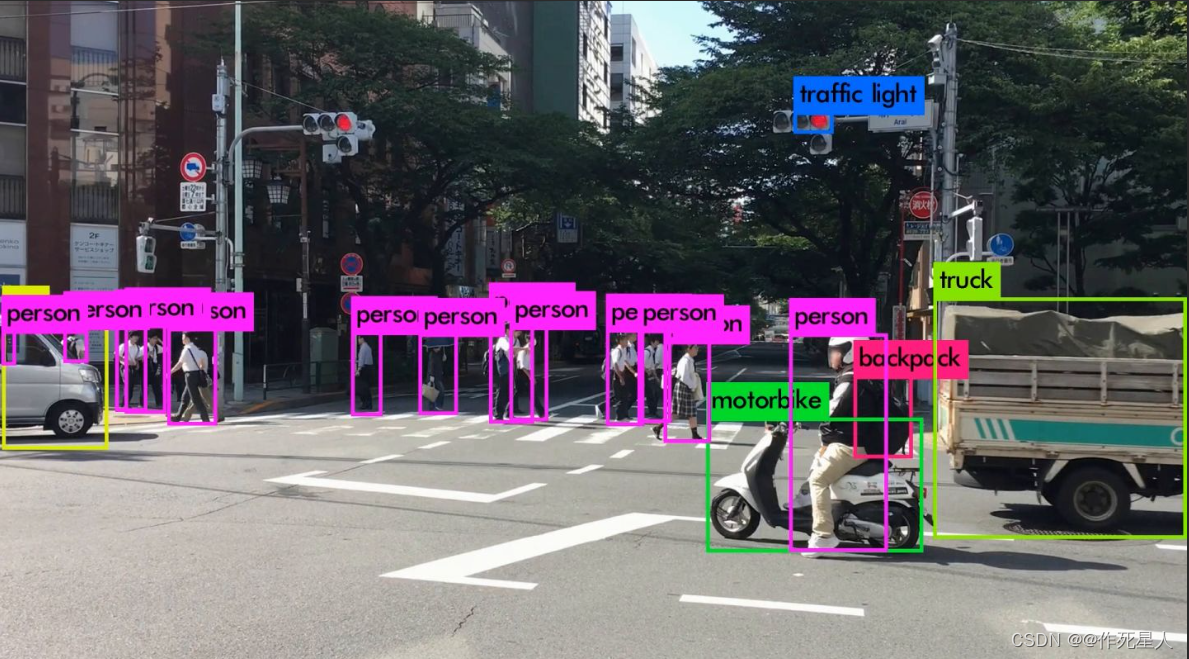
YOLO 将物体检测任务视为回归问题,并将图像划分为网格,每个网格预测物体的类别和边界框。YOLO v3 在前两代版本的基础上,引入了新的特征映射、多尺度检测和更先进的卷积神经网络结构,从而提高了检测速度和准确性。
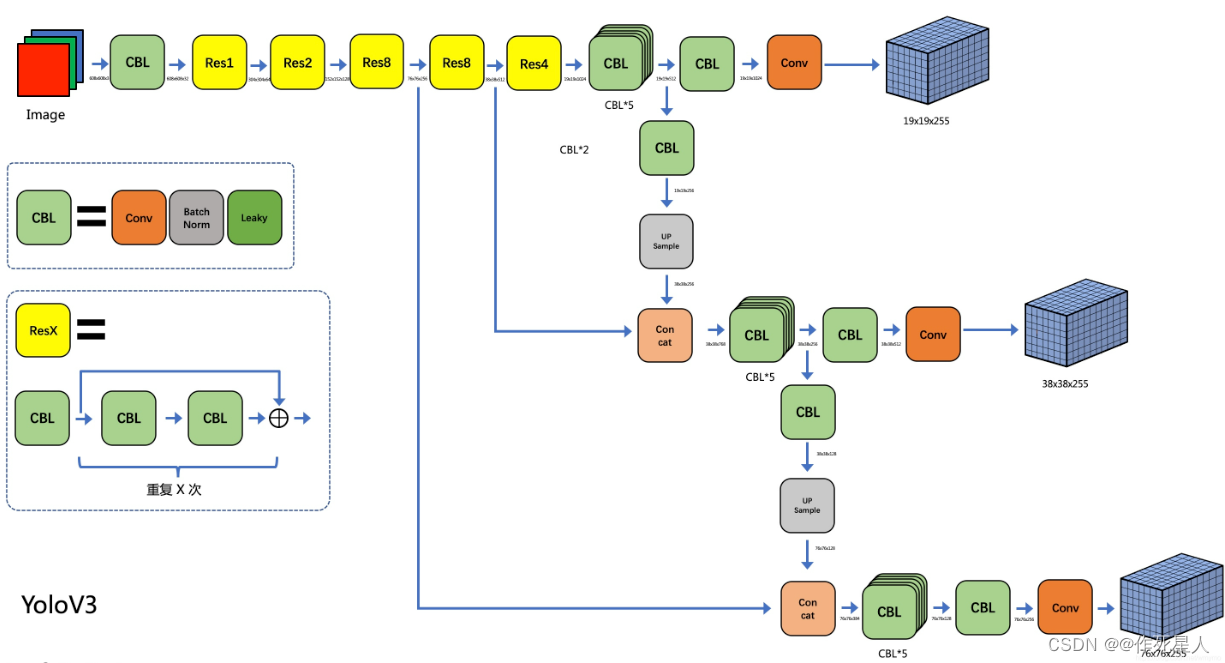
在Halcon中,可以使用以下算子实现:
dev_clear_window()
dev_update_off()
dev_close_window()
dev_open_window (0, 0, 512, 512, 'black', WindowHandle)
read_image (Image, 'path/to/your/image')
convert_image_dtype (Image, Image, 'uint8')
inner_product (Image, Results, 'false', 'false', 'false')
threshold (Results, RegionGrowth, 0, 255)
select_shape (RegionGrowth, SelectedRegions, 'area', 'and', 10000, 1000000)
dilation_rectangle1 (SelectedRegions, RegionDilation, 15, 15)
connection (RegionDilation, ConnectedRegions)
select_shape (ConnectedRegions, SelectedObjects, 'area', 'and', 10000, 1000000)
text_object_detection (SelectedObjects, DetectedObjects, 'both', 'true', 'false', 'true', 'true', 'true', 'true', 'true')
更多参考:【yolov3详解】一文让你读懂yolov3目标检测原理
2.2 SSD(单次多框检测器)
SSD(Single Shot MultiBox Detector)是一种用于物体检测的卷积神经网络方法。
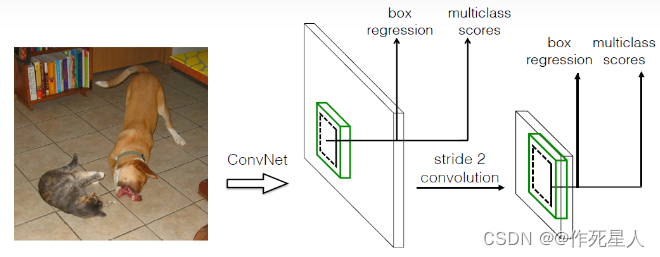
SSD 同样将物体检测任务视为回归问题,但使用卷积神经网络(Convolutional Neural Network, CNN)在单次前向传播中预测物体的类别和边界框。
SSD使用多尺度特征图3进行检测,通过特征提取网络(如MobileNet、VGG等)产生候选区域,再使用分类器和边界框回归器进行目标定位和分类。
换言之,SSD 通过使用不同尺度的卷积特征映射对多个位置和大小的物体进行检测。
SSD 的主要优势在于其检测速度,因为它不需要在图像上滑动候选区域。
在Halcon中,可以使用以下算子实现:
dev_close_window()
dev_open_file_dialog ('choose file', '*.png', '', 'path/to/your/image', '*.png', ['Image', 'path/to/your/image'])
read_image (Image, 'path/to/your/image')
convert_image_color (Image, Image, 'RGB')
gray_scale (Image, GrayImage, 0, 255)
fg_threshold (GrayImage, Regions, 0, 255)
dev_display (Image)
dev_display (Regions)
可参考这篇文章:目标检测|SSD原理与实现
3.传统滑动窗口方法
“滑动窗口方法”是一种基于滑动窗口的图像分析方法。该方法通过在图像中滑动一系列窗口,并将每个窗口内的图像特征提取出来,然后通过特征提取算法对窗口内的图像进行处理和分析。滑动窗口方法可以用来进行图像分割、特征提取、目标检测、目标跟踪等任务。
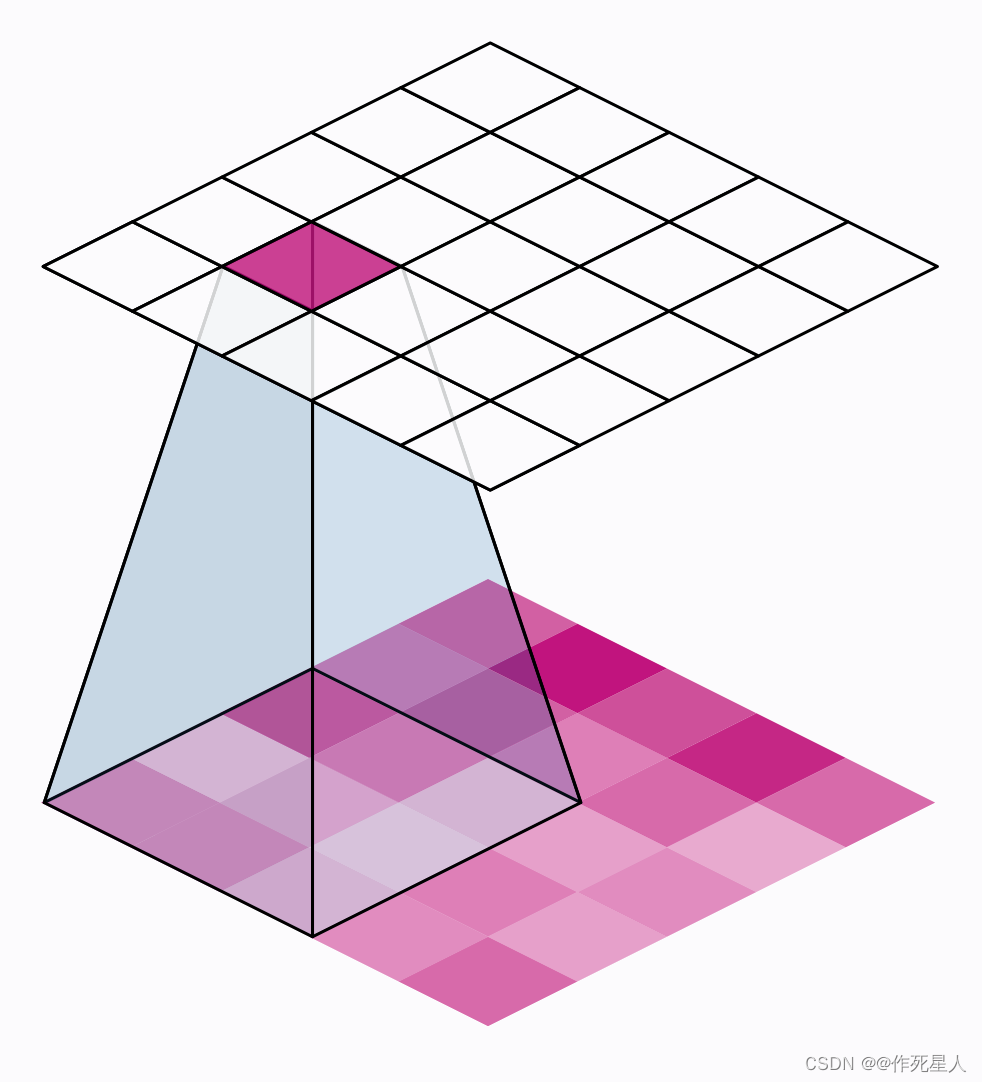
以下是滑动窗口方法的基本原理:
- 对于图像中的每个像素,在窗口内进行特征提取,并将特征存储在一个特征向量中。
- 将特征向量传输到下一个窗口中。
- 重复步骤1和2,直到遍历完整个图像。
- 将所有窗口中的特征向量传输到另一个处理器中,并对这些特征向量进行计算和分析。
以下是Halcon算子实现滑动窗口方法的示例:
dev_close_window ()
dev_open_window (0, 0, 512, 512, 'black', WindowHandle)
* 创建一个与原始图像大小相同的全零窗口
gen_empty_obj (Obj)
Obj_numPoints := 0
* 遍历图像中的每个像素
for I := 1 to ImageLength by 1
* 在窗口中进行特征提取
gen_corner_feat (Obj, I, Contours)
* 检测角点
detect_contours_xld (Obj, Contours, Contours, Row, Column, Height, Width, Score, MinScore, Number, ContoursNumber)
* 将角点传递到下一个窗口
dev_display (Image[I:I+ImageLength-1])
* 计算角点之间的距离并可视化
disp_message (WindowHandle, 'Distance: ' + Distance::String, 'image', Row, Column, 'black')
endfor
以下是Python实现滑动窗口方法的示例:
import cv2
def extract_features(image):
# 生成特征检测器
corners = cv2.cornerSubPix(image, corners, (11, 11), (-1, -1), criteria=cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER)
return corners
# 遍历图像中的每个像素
for I in range(1, image.shape[0] + 1, 1):
# 在窗口中进行特征提取
corners = extract_features(image[I - 1:I + 1])
# 检测角点
detect_contours_xld(corners, corners, None, (0, 0, 255), 2, 0.01, 10, False)
# 将角点传递到下一个窗口
cv2.drawContours(image[I - 1:I + 1], [0], -1, (0, 0, 255), 2)
# 计算角点之间的距离并可视化
disp_message(window_handle, 'Distance: ' + distance, 'image', I, 'black')
PS:在Halcon和Python中,实现滑动窗口方法时需要对窗口大小进行指定。
在Halcon中,需要指定ImageLength和ImageWidth;
在Python中,需要指定image。
参考文章:计算机视觉(Computer Vision)入门四----滑动窗口
Two-Stage方法则采用复杂的深度学习模型,如Faster R-CNN、R-FCN、YOLOv3等,这些模型通常分为两个阶段进行处理。第一阶段先生成目标区域,例如通过使用区域卷积神经网络(Region Proposal Networks,RPN)来生成Region Proposals。第二阶段则在目标区域中进行分类和回归,从而进行目标检测。相比于One-Stage方法,Two-Stage方法的检测精度通常更高,但是由于需要两个阶段的计算,所以推理速度相对较慢。
总之,One-Stage方法和Two-Stage方法各有优缺点,通常在不同的应用场景下选择不同的方法。 ↩︎One-Stage方法通常采用简单的深度学习模型,如YOLO、SSD等,可以在一次前向传播中直接输出目标的类别和位置。这种方法在检测速度上通常更快,因为它们在推理过程中只需要一次计算,但是由于没有单独的目标区域生成步骤,所以One-Stage方法的检测精度可能会略低于Two-Stage方法。 ↩︎
多尺度特征图(Multiscale Feature Map)是指在计算机视觉任务中,在不同尺寸的图像金字塔4上进行卷积操作,从而提取不同尺度下的特征信息。
在图像识别、目标检测、语义分割等计算机视觉任务中,由于场景的复杂性和多样性,不同尺度的物体可能会出现在图像中。为了捕捉这些不同尺度的物体,可以使用多尺度特征图的方法。
在多尺度特征图中,卷积核的尺寸和步长是可配置的。通常情况下,卷积核会从较小的尺寸逐渐变大,步长也会随之增大。这种方法能够捕获图像中不同尺度的特征信息,从而提高模型在不同尺度物体上的检测和识别能力。
例如,在目标检测任务中,可以通过堆叠多个不同尺寸的特征图来提取多尺度特征信息。这些特征图可以通过上采样(upsampling)或下采样(downsampling)的方式来调整尺寸,以匹配原始图像的尺寸。这样,模型可以同时关注到小尺度和大尺度的物体,从而提高检测精度。 ↩︎图像金字塔是一种用于图像处理和分析的技术,用于表示一组具有不同分辨率和大小的图像。金字塔的每一层代表了图像的不同分辨率,通常从最高分辨率开始,逐渐降低分辨率,直到变成一个像素矩阵。金字塔的每一层可以包含原始图像,也可以是原始图像经过降采样后的结果。
图像金字塔可以用于图像分割、特征提取、图像识别和图像压缩等领域。在图像分割中,金字塔可以帮助算法逐步降低图像分辨率,以便更好地处理细节信息,并提高计算效率。在特征提取中,金字塔可以用于从多个分辨率级别提取有用的图像特征,以便进行分类和识别。在图像识别中,金字塔可以用于逐步缩小图像的范围,以便更好地识别目标物体。在图像压缩中,金字塔可以用于减少图像的数据量,以便更好地存储和传输图像。 ↩︎




![[React]面向组件编程](https://img-blog.csdnimg.cn/f5c67186beb34ca0aa5a9f97b81f0d53.png)