B站上面那个翻译我有点看不懂,打算自己啃英文翻译了(有自己意译的部分),然后懒得做字幕,就丢在博客上面了,2.2之前的章节结合那个机翻字幕能看懂
监督学习 part 1(Supervised learning part 1)
Supervised machine learning or more commonly, supervised learning, refers to algorithms that learn x to y or input to output mappings.
监督式机器学习(人们普遍称它为监督学习)指的是这样一种映射关系的算法,它能够通过学习数据x来得到想要的结果y,或者说,输入数据来得到输出结果。

The key characteristic of supervised learning is that you give your learning algorithm examples to learn from.
监督学习重要的特点是你要给你的“学习算法”一些例子来让它从你给的例子中学习。
【注】这句话的意思,你要先举出例子让算法明白要得到的结果是什么,比如你要“告诉”算法,如果出现大写字母A的图像就代表大写字母A,然后当你给出大写字母B的图像时,算法不会识别,当你给出大写字母A的图像时,算法会识别出这是大写字母A,也就是你要提前给算法举例子,告诉他面对不同的情况需要输出什么不同的结果。
That includes the right answers, whereby right answer, I mean, the correct label y for a given input x, and is by seeing correct pairs of input x and desired output label y that the learning algorithm eventually learns to take just the input alone without the output label and gives a reasonably accurate prediction or guess of the output.
你给的例子中应该包含着需要用算法解决的问题的正确答案,我所指的正确答案是:对于给定的输入x都有输出的正确标签y,监督学习算法通过观察所给例子中给定的输入x和期望输出的标签y的正确对应关系最终学会了仅凭借输入而不需要给定正确结果就能给出一个合理准确的预测的输出结果。

Let’s look at some examples. If the input x is an email and the output y is this email, spam or not spam, this gives you your spam filter. Or if the input is an audio clip and the algorithm’s job is output the text transcript, then this is speech recognition.
让我们接下来看一些例子:比如输入的x是一封电子邮件并且输出的y是“这封邮件到底是不是垃圾邮件”,这个算法模型给你提供了一个垃圾邮件过滤器的功能。再比如,输入的x是一段音频片段,这个算法的作用是输出这段音频对应的文字,那么这个就是语音识别。
Or if you want to input English and have it output to corresponding Spanish, Arabic, Hindi, Chinese, Japanese, or something else translation, then that’s machine translation. Or the most lucrative form of supervised learning today is probably used in online advertising.
又比如,如果你想要输入英语并且输出相对应的西班牙语、阿拉伯语、中文、日文或者其他语言的翻译,那么这个就是机器翻译。如今最赚钱的监督学习的形式大概在在线广告中得到了广泛的应用。
Nearly all the large online ad platforms have a learning algorithm that inputs some information about an ad and some information about you and then tries to figure out if you will click on that ad or not. Because by showing you ads they’re just slightly more likely to click on, for these large online ad platforms, every click is revenue, this actually drives a lot of revenue for these companies.
几乎所有的大型互联网广告平台都有一个学习算法,这个学习算法通过输入一些关于广告的信息和关于你的信息,然后尝试计算出是否你会点击它推送给你的广告。因为对于这些大型在线广告平台来说,给你推送你更有可能点击的广告意味着每一次你的点击都能给他们带来收入,这个广告推送算法实际上给这些公司带来了大量的收入。
This is something I once done a lot of work on, maybe not the most inspiring application, but it certainly has a significant economic impact in some countries today. Or if you want to build a self-driving car, the learning would take as input an image and some algorithm information from other sensors such as a radar or other things and then try to output the position of, say, other cars so that your self-driving car can safely drive around the other cars.
这是我曾经投入大量精力的领域,它也许不是最令人激动人心的应用,但是它确实对现如今的一些国家的经济产生了重要的影响,举个例子,如果你想要造一辆自动驾驶汽车,学习算法将图像和传感器提供的算法信息(比如:雷达等)作为输入,然后算法试图输出道路上其他车辆的位置以便于你的自动驾驶汽车能够安全地绕过其他汽车。
Or take manufacturing. I’ve actually done a lot of work in this sector at learning AI. You can have a learning algorithm takes as input a picture of a manufactured product, say a cell phone that just rolled off the production line and have the learning algorithm output whether or not there is a scratch, dent, or other defect in the product. This is called visual inspection and it’s helping manufacturers reduce or prevent defects in their products.
以制造业为例,实际上,我在这个行业的人工智能学习领域做了很多工作。你可以使用学习算法将制造出来的产品的图片作为输入,例如,一台刚刚从生产线上生产出来的手机,然后让学习算法输出这台手机是否存在划分、凹陷或者其他缺陷。这就是所谓的视觉检测,它有助于制造商们减少或者避免出现有缺陷的产品。
In all of these applications, you will first train your model with examples of inputs x and the right answers, that is the labels y. After the model has learned from these input, output, or x and y pairs, they can then take a brand new input x, something it has never seen before, and try to produce the appropriate corresponding output y.
在所有这些应用中,你将首先使用输入x和带有正确答案的标签y的例子来训练你的模型。在模型学习了这些输入输出或者x和y的映射关系后,模型就能接受全新的未见过的输入x并且试图产生适当的相应的输出结果y。

| 输入(X) | 输出(Y) | 应用 |
|---|---|---|
| 电子邮件 | 是否为垃圾邮件(0/1) | 垃圾邮件过滤器 |
| 音频 | 转换成的对应文本 | 语音识别 |
| 英语 | 西班牙语 | 机器翻译 |
| 广告, 用户信息 | 用户是否点击该广告(0/1) | 在线广告 |
| 图像,雷达信息 | 其他车辆的位置 | 自动驾驶汽车 |
| 从生产线上生产出来的手机的图像 | 该产品是否有瑕疵(0/1) | 视觉检测 |
Let’s dive more deeply into one specific example. Say you want to predict housing prices based on the size of the house. You’ve collected some data and say you plot the data and it looks like this.
让我们深入讨论一下下面的这个例子,加入你想通过房子的面积来预测房价,你已经收集了一些数据,假设你根据这些数据绘制了统计图如下图所示。

Here on the horizontal axis is the size of the house in square feet. Yes, I live in the United States where we still use square feet. I know most of the world uses square meters. Here on the vertical axis is the price of the house in, say, thousands of dollars. With this data, let’s say a friend wants to know what’s the price for their 750 square foot house.
这里横坐标代表的是房屋的面积,单位是平方英尺。我住在美国,美国仍采用平方英尺来计算房屋面积,我知道世界上大多数地区使用平方米来计算面积。 纵坐标代表的是房屋价格,单位是千美元,根据这些数据,假设一个朋友想知道他们750平方英尺的房屋价格是多少。
How can the learning algorithm help you? One thing a learning algorithm might be able to do is say, for the straight line to the data and reading off the straight line, it looks like your friend’s house could be sold for maybe about, I don’t know, $150,000. But fitting a straight line isn’t the only learning algorithm you can use. There are others that could work better for this application.
学习算法如何帮助你解决这个问题呢?学习算法可能会做的是通过拟合数据点得到直线,并在直线上读出横坐标房屋面积对应的房屋价格的数值,可以得出你朋友的房屋可能售价大约是15万美元左右,然而,拟合直线的算法并不是你唯一能够使用的算法,还有其他算法可能在这个应用中表现得更好。

For example, routed and fitting a straight line, you might decide that it’s better to fit a curve, a function that’s slightly more complicated or more complex than a straight line. If you do that and make a prediction here, then it looks like, well, your friend’s house could be sold for closer to $200,000.
比如,在画一条拟合直线后,你可能会认为拟合一条曲线更合适,这条曲线的函数图像比直线更加复杂。如果你选择画曲线函数图像做预测,那么看起来,你朋友的房子大概可以卖20万美元。
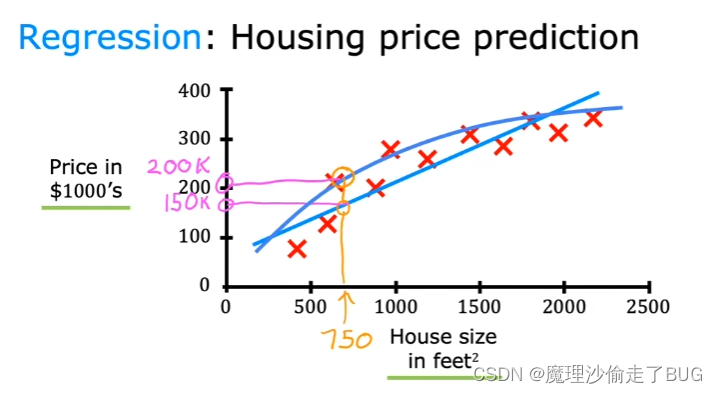
One of the things you see later in this class is how you can decide whether to fit a straight line, a curve, or another function that is even more complex to the data. Now, it doesn’t seem appropriate to pick the one that gives your friend the best price, but one thing you see is how to get an algorithm to systematically choose the most appropriate line or curve or other thing to fit to this data. What you’ve seen in this slide is an example of supervised learning. Because we gave the algorithm a dataset in which the so-called right answer, that is the label or the correct price y is given for every house on the plot.
在这门课程的后面阶段,你将了解如何决定是拟合直线、曲线,还是更复杂的其他函数来处理数据。现在,选择能给你朋友最优价格似乎并不合适,但你会学到如何让算法系统地选择最合适的直线、曲线或其他处理这些数据的方式。这个幻灯片中所展示的是监督学习的一个例子。由于我们给算法提供了一个数据集,其中每栋房子在图表上都标有所谓的正确答案,即标签或正确的价格y。
The task of the learning algorithm is to produce more of these right answers, specifically predicting what is the likely price for other houses like your friend’s house. That’s why this is supervised learning. To define a little bit more terminology, this housing price prediction is the particular type of supervised learning called regression.
学习算法的任务是产生更多的这样的正确答案,具体来说,它可以预测其他类似你朋友房子的可能的价格。再来定义一些术语,这种房价预测是一种特定类型的监督学习,称为回归。
By regression, I mean we’re trying to predict a number from infinitely many possible numbers such as the house prices in our example, which could be 150,000 or 70,000 or 183,000 or any other number in between. That’s supervised learning, learning input, output, or x to y mappings. You saw in this video an example of regression where the task is to predict number. But there’s also a second major type of supervised learning problem called classification. Let’s take a look at what that means in the next video.
在回归算法中,我们试图从无数个可能的数字中预测一个数字,比如刚才我们的示例中的房价,它的价格可以是15万、7万、18.3万或者其他任何介于其中的数字。这就是监督学习,学习输入、输出或者x到y的映射关系。在这个视频中,你看到了一个回归的例子,这个例子的任务是预测一个数字。但是还有第二种被称之为分类的主要类型的监督学习。让我们在下一个视频中来看看这是什么意思。




![[React]面向组件编程](https://img-blog.csdnimg.cn/f5c67186beb34ca0aa5a9f97b81f0d53.png)