文章目录
- 1.消息队列核心概念
- 1.1.为什么要引入消息队列
- 1.2.消息队列的流派
- 2.Kafka消息队列基本概念
- 2.1.Kafka消息队列基本概念
- 2.2.Kafka与Zookeeper的关系
- 2.3.Kafka消息队列各组件概念
- 2.4.Kafka消息队列应用场景
- 3.部署Kafka消息队列
- 3.1.搭建Zookeeper分布式协调服务
- 3.2.部署Kafka消息队列
- 3.3.启动Kafka并查看启动进程
- 3.4.在Zookeeper中查看Kafka写入的节点信息
- 4.kafka配置文件参数含义
- 5.Kafka服务管理命令
1.消息队列核心概念
1.1.为什么要引入消息队列
1)使用消息队列之前的系统调度方式
应用系统在使用消息队列之前,各系统之间的调用都是通过同步的方式进行通信的。
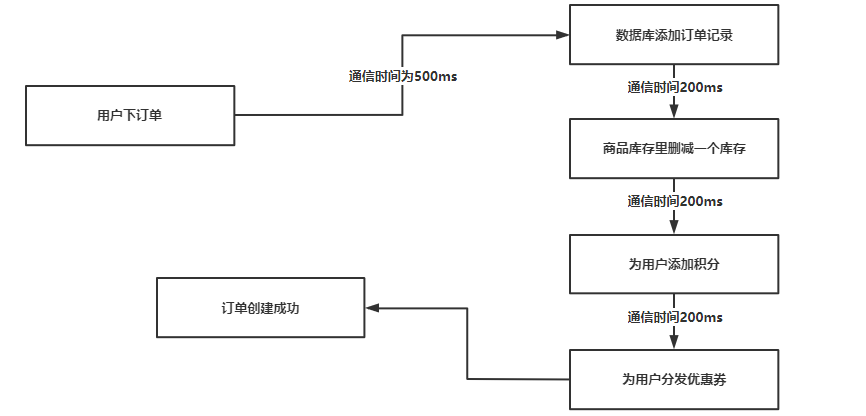
如下图所示,当用户下订单后,首先在数据库中添加订单的记录,然后到商品的库存中进行删减,然后为用户添加相应的积分,然后为用户分发优惠卷,最后才完成一个订单的创建。
使用同步方式进行系统通信是非常消耗时间的,用户下单—数据库添加订单记录会花费500毫秒,在往下游依次调用多个系统都会消耗200ms,所有的系统处理完之后再反馈给用户说订单创建成功了,整个流程跑完大概会小号2-5秒的一个时间,对于用户体验来说不友好。
并且在同步方式中,如果有其中一个服务调度失败了,就会导致用户无法成功下单。
2)使用消息队列之后的系统调度方式
为了解决以上描述的问题,就需要使用MQ消息队列中间件了。
当系统架构中引入了消息队列,用户下单完成后向消息队列中发送一条消息数据后,就会返回给用户订单创建完成,此时仅仅花费50毫秒的时间,消息数据进入到消息队列后,会被分配到某一个队列中,需要与订单系统联动的系统,就会去消息队列中订阅这个队列,然后消费订单系统产生的消息数据,进行相应的业务逻辑处理。
用户下单部分属于上游处理,后端各系统之间的调用属于下游处理,当下单完成的消息数据进入消息队列之后,返回给用户下单完成,此时上游部分的数据就处理完成了,而下游部分各系统之间的相互调用,对于用户而言是无感知的,即使两三秒内完成数据处理用户也是无所谓的,下游部分中各系统调用如果某个系统产生了异常,也不会对整个下单流程产生问题,某个系统产生问题会通过分布式事物中间件来解决。
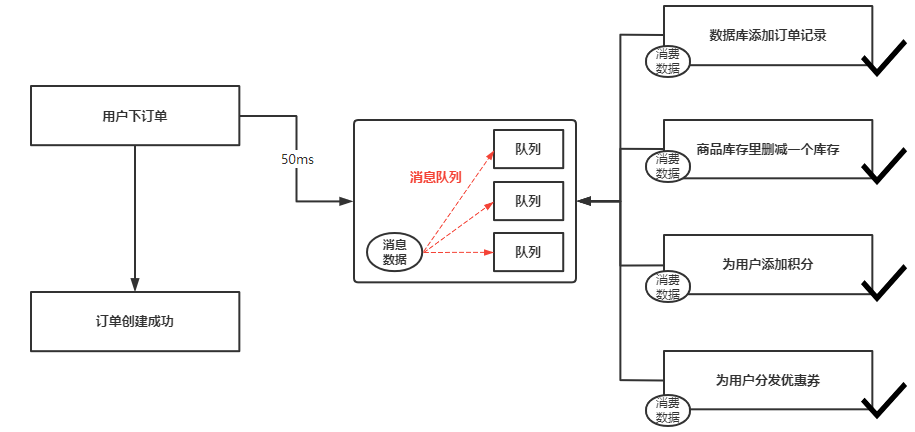
当系统中引入了消息队列后,用户下单完成仅需几十到几百毫秒,对于用户体验来说是非常友好的。
引用消息队列之后,各系统的通信方式就会从同步变化为异步,使用异步通信可以加大程序的吞吐量,各个系统直接订阅消息队列,可以同时去处理业务逻辑。
1.2.消息队列的流派
消息队列这类的中间件有很多,大体功能都很相似,主流的MQ消息队列分为以下几种:
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
- ZeroMQ
所有的消息队列中间件可以分为两大流派,架构不同。
1)有Broker的消息队列中间件
有Broker的消息队列中间件,Broker相当于一个中转站,所有的消息数据都会通过Broker转发到特定的队列中,生产者只需要将消息数据转发给Broker就不需要管了,Broker会将数据转到队列中,然后推送给消费者。
有Broker的消息队列还可以细分为两种:
-
重Topic
- 重Topic指的是Broker只能将数据转发给Topic进行存储,Topic其实就相当于队列的概念了,所有的消息数据根据不同的种类分别存储在不同的Topic中,很多情况下一个应用系统可能就只有一个Topic。
- Kafka、ActiveMQ就是重Topic类型的消息队列中间件。
- 例如ELK日志采集系统中,FIlebeat采集到的程序日志就会存储到Kafka中的某个Topic中。
-
轻Topic
- 轻量Topic指的是发送者发送的消息数据,是通过一些逻辑计算,然后将数据存储在某个Topic队列中,不依赖Broker将数据发送到队列中,在这种架构中,队列是非常轻量的,消费者只关心自己从哪一个队列中读取数据,生产者也不需要关系消息数据最终存储在哪一个队列中。
- 轻量Topic与重量Topic的区别就在于轻量不需要Broker转发消息数据到Topic,而重量就需要Broker将数据转发到特定的Topic。
- RabbitMQ就是典型的轻Topic消息队列中间件。
2)无Broker的消息队列中间件
无Broker的消息队列中间件典型代表就是ZeroMQ,这个MQ消息队列就是为解决通信问题而诞生,就把MQ当做一个库,而并非一个中间件,在这种消息队列中,每个节点既是消费者又是生产者,直接读取和消费数据,不进行存储。
2.Kafka消息队列基本概念
官方文档地址:https://kafka.apache.org/
2.1.Kafka消息队列基本概念
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于 2010 年贡献给了Apache基金会并成为顶级开源项目。
Kafka是一个分布式消息队列系统,通过由高性能的TCP网络协议进行通信服务端和客户端组成,Kafka的性能极其强悍,常应用于大数据领域。
Kafka需要与Zookeeper一起使用,在Kafka3.x版本以后将不依赖于Zookeeper分布式协调服务。
Kafka的优势:
- 高吞吐量、低延迟:Kafka每秒可以处理几十万条消息数据,延迟仅有几毫秒。
- 扩展性强:支持动态扩展节点、
- 持久性、可靠性高:消息数据可以持久化到本地磁盘,并且支持数据备份防止数据丢失。
- 容错性:允许集群中节点故障,只要集群中有一个节点存活就可以使用。
- 高并发:支持上千个客户端同时读写。
2.2.Kafka与Zookeeper的关系
Kafka需要与Zookeeper配合使用,下面来总结一下两者的关系。
- Kafka中通常会有多个Broker,Kafka需要通过Zookeeper来管理集群的配置,选举出Leader节点。
- Kafka依托于Zookeeper来注册Broker的信息,消费者会在Zookeeper注册消费者信息,同时也是通过Zookeeper来发现Kafka中的Broker列表。
- Kafka的消息数据都是存储在Topic中的,Kafka会将Topic的元数据(信息)存储在Zookeeper中,维护Topic和Broker的关系,只存储元数据不存储消息数据。
- 在Zookeeper中Broker与Topic的节点列表通常是这样的:
/brokers/topics/topic_name。
- 在Zookeeper中Broker与Topic的节点列表通常是这样的:
- 消息发送者会在Zookeeper中注册相关信息,在Zookeeper中获取Broker以及Topic的信息,然后将消息数据写入到指定的Kafka Topic中。
Kafka的所有元数据信息都是存储在Zookeeper中的,具体的消息数据还是存储在Kafka中,发送者和消费者都会在Zookeeper中注册信息,通过Zookeeper来获取要存储或者消费的Kafka Broker列表。
Kafka使用Zookeeper的原因:Kafka中会有若干个Broker,Broker需要通过分布式协调服务来维护,统一管理Broker的配置信息,客户端和消费者直接从配置中心获取Broker的信息,为Broker与Broker之间的请求建立安全协议,而这种分布式协调服务中Zookeeper是最可靠的。
2.3.Kafka消息队列各组件概念
-
Broker
- 一个Kafka节点就是一个Broker,多个Broker可以组成一个Kafka集群。
-
Topic
- 消息数据的最终存储点,一般一个应用程序会将所有的消息数据存储在同一个Topic中,发送到Kafka集群的每条消息都需要指定Topic。
-
Producer
- 消息生产者,向Broker发送消息数据的客户端
-
Consumer
- 消息消费者,从Broker中读取消息数据的客户端。
-
ConsumerGroup
- 每一个消费者都会属于一个特定的消费者组,一条消息数据可以被多个不同的ConsumerGroup进行消费,但是一个ConsumerGroup中只能有一个Consumer在消费这条消息数据。
-
Partition
- 分区概念,一个Topic可以分为多个Partition,每个Partition内部消息是有序的
2.4.Kafka消息队列应用场景
1)日志采集
常用ELK日志数据采集的存储端,当日志量非常庞大时,同时写入ES集群,会导致ES集群崩溃,可以利用Kafka,将日志数据采集到Kafka中,再由Logstash从Kafka中消费数据写入到ES集群。
2)消息系统
在传统的系统架构中,引入MQ消息队列,对应用程序实现应用解耦。
3)用户活动跟踪
kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘;
4)运营指标
Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
3.部署Kafka消息队列
Kafka依赖于Zookeeper,需要先部署一个Zookeeper。
3.1.搭建Zookeeper分布式协调服务
1.安装JAVA环境
[root@kafka ~]# tar xf jdk-8u211-linux-x64.tar.gz -C /data/
[root@kafka ~]# vim /etc/profile
JAVA_HOME=/data/jdk1.8.0_211
PATH=$JAVA_HOME/bin:$PATH
[root@kafka ~]# source /etc/profile
[root@kafka ~]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
2.部署Zookeeper服务
1.部署Zookeeper
[root@kafka ~]# tar xf apache-zookeeper-3.5.8-bin.tar.gz -C /data/
[root@kafka ~]# mv /data/apache-zookeeper-3.5.8-bin/ /data/zookeeper
2.创建数据存储路径
[root@kafka ~]# mkdir /data/zookeeper/zkdata
3.修改配置文件
[root@kafka ~]# cp /data/zookeeper/conf/zoo_sample.cfg /data/zookeeper/conf/zoo.cfg
[root@kafka ~]# vim /data/zookeeper/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/zkdata
clientPort=2181
4.启动Zookeeper
[root@kafka ~]# /data/zookeeper/bin/zkServer.sh start
/usr/local/jdk1.8.0_211/bin/java
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
3.2.部署Kafka消息队列
1.下载kafka二进制文件
[root@kafka ~]# wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.11-2.4.1.tgz
2.安装Kafka
[root@kafka ~]# tar xf kafka_2.11-2.4.1.tgz -C /data/
[root@kafka ~]# mv /data/kafka_2.11-2.4.1/ /data/kafka
3.配置kafka
[root@kafka ~]# vim /data/kafka/config/server.properties
broker.id=0 #broker的id号,集群模式下id号要配置成唯一的
listeners=PLAINTEXT://192.168.81.210:9092 #kafka监听地址
log.dirs=/data/kafka/data/kafka-logs #消息数据存储路径,不要手动创建,让kafka自己生成,否则会启动失败
zookeeper.connect=192.168.81.210:2181 #zookeeper地址
3.3.启动Kafka并查看启动进程
1.启动kafka
[root@kafka ~]# /data/kafka/bin/kafka-server-start.sh -daemon /data/kafka/config/server.properties
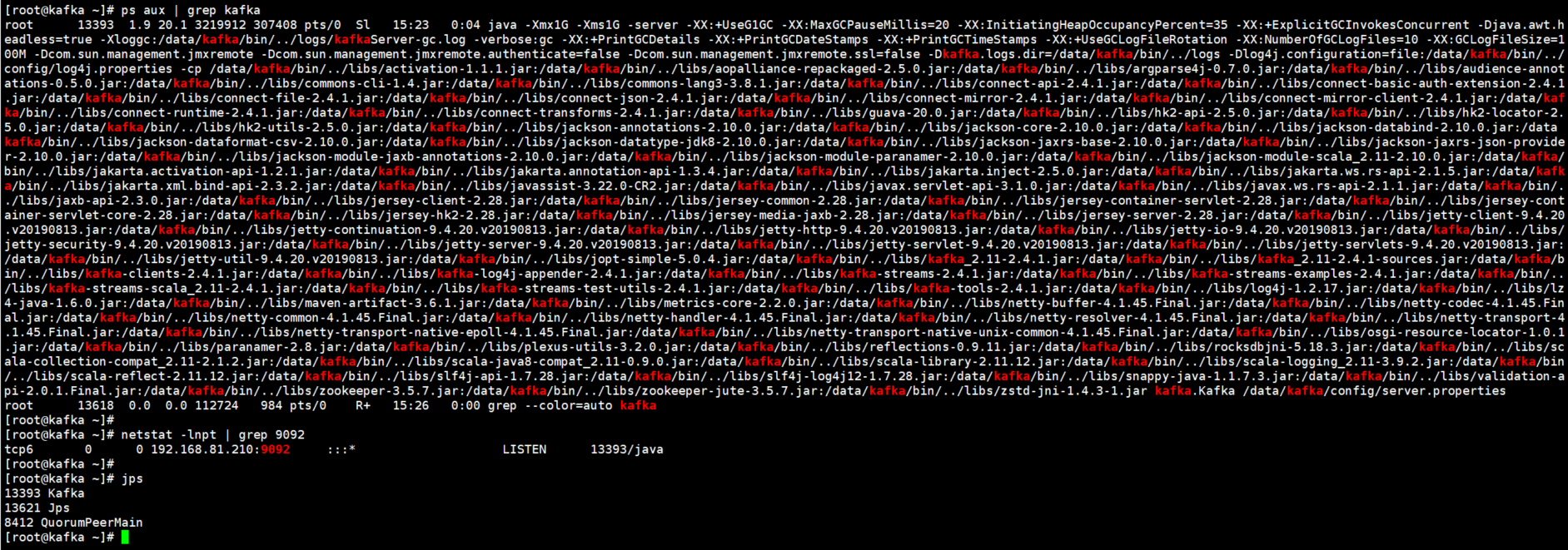
2.查看kafka的端口号以及进程
[root@kafka ~]# netstat -lnpt | grep 9092
tcp6 0 0 192.168.81.210:9092 :::* LISTEN 13393/java
[root@kafka ~]# jps
13393 Kafka
13482 Jps
8412 QuorumPeerMain
3.4.在Zookeeper中查看Kafka写入的节点信息
1.查看kafka创建的根节点
[root@kafka ~]# /data/zookeeper/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 22] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
#除了/zookeeper外所有的节点都是kafka创建的
2.查看每个根节点下的子节点
[zk: localhost:2181(CONNECTED) 27] ls -R /
/
/admin
/brokers #存放kafka的broker信息,包括id信息、topic信息
/cluster #存放kafka集群信息
/config #存放kafka的配置信息
/consumers
/controller
/controller_epoch
/isr_change_notification
/latest_producer_id_block
/log_dir_event_notification
/zookeeper
/admin/delete_topics
/brokers/ids #ids存放kafka broker的节点ID
/brokers/seqid
/brokers/topics #当前kafka节点中还没有topic,所以topics子节点下没有任何其他子节点了
/brokers/ids/0 #broker的id为0
/cluster/id
/config/brokers
/config/changes
/config/clients
/config/topics
/config/users
/zookeeper/config
/zookeeper/quota
4.kafka配置文件参数含义
broker.id=0 #broker的id号,集群模式下id号要配置成唯一的
listeners=PLAINTEXT://192.168.81.210:9092 #kafka监听地址
num.network.threads=3 #处理网络请求的线程数量,线程会将接收到的消息放到内存中然后再写入磁盘
num.io.threads=8 #消息从内存写入磁盘时使用的线程数量,主要是用来处理磁盘IO的线程数量
socket.send.buffer.bytes=102400 #发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #请求套接字的缓冲区大小
log.dirs=/data/kafka/data/kafka-logs #消息数据存储路径
num.partitions=1 #topic在当前broker上的分区个数
num.recovery.threads.per.data.dir=1 #用来设置恢复和清理data下数据的线程数量,segment文件默认会被保留7天
offsets.topic.replication.factor=1 #
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168 #segment数据文件保留的期限,单位小时,也就是7天
log.segment.bytes=1073741824 #日志文件中每个segment的大小,默认为1G
log.retention.check.interval.ms=300000 #定期检查segment文件的大小是否超出闲置,单位是毫秒
zookeeper.connect=192.168.81.210:2181 #zookeeper地址
zookeeper.connection.timeout.ms=6000 #zookeeper链接超时时间
group.initial.rebalance.delay.ms=0 #延迟初始消费者重新平衡的时间
5.Kafka服务管理命令
1.启动kafka
./kafka-server-start.sh -daemon /data/kafka/config/server.properties
2.关闭kafka
./kafka-server-stop.sh



![[React]面向组件编程](https://img-blog.csdnimg.cn/f5c67186beb34ca0aa5a9f97b81f0d53.png)