WordCount算是大数据计算领域经典的入门案例,相当于Hello World。
虽然WordCount业务极其简单,但是希望能够通过案例感受背后MapReduce的执行流程和默认的行为机制,这才是关键。
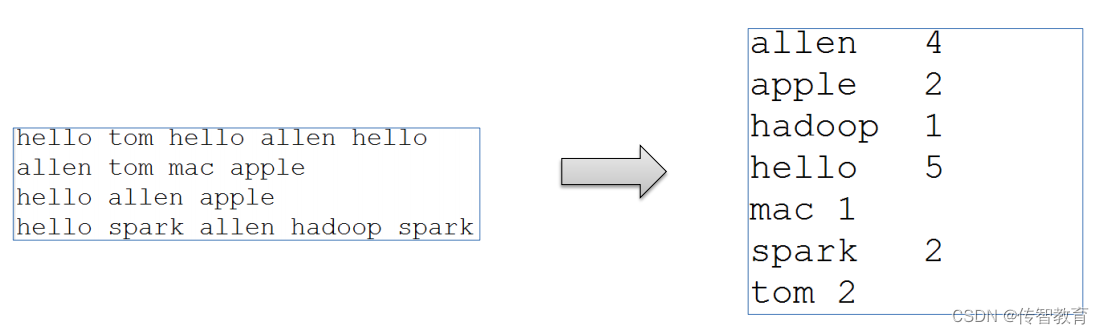
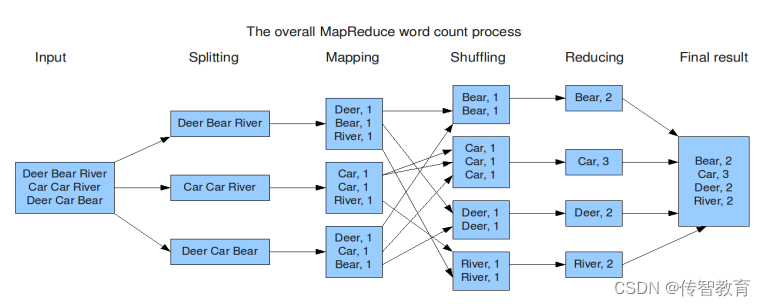
WordCount编程实现思路
map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是<单词,1>。
shuffle阶段核心:经过MR程序内部自带默认的排序分组等功能,把key相同的单词会作为一组数据构成新的kv对。
reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是单词的总次数。
上传课程资料中的文本文件1.txt到HDFS文件系统的/input目录下,如果没有这个目录,使用shell创建。
•hadoop fs -mkdir /input
•hadoop fs -put 1.txt /input
准备好之后,执行官方MapReduce实例,对上述文件进行单词次数统计。
第一个参数:wordcount表示执行单词统计任务;
第二个参数:指定输入文件的路径;
第三个参数:指定输出结果的路径(该路径不能已存在);



![[框架]Spring框架](https://img-blog.csdnimg.cn/9619f614046a4988ac084995f3f37199.png)