paper:Emerging Properties in Self-Supervised Vision Transformers
源码:https://github.com/facebookresearch/dino
20230627周二目前只把第一部分看完了。
论文导读:DINO -自监督视觉Transformers - deephub的文章 - 知乎、
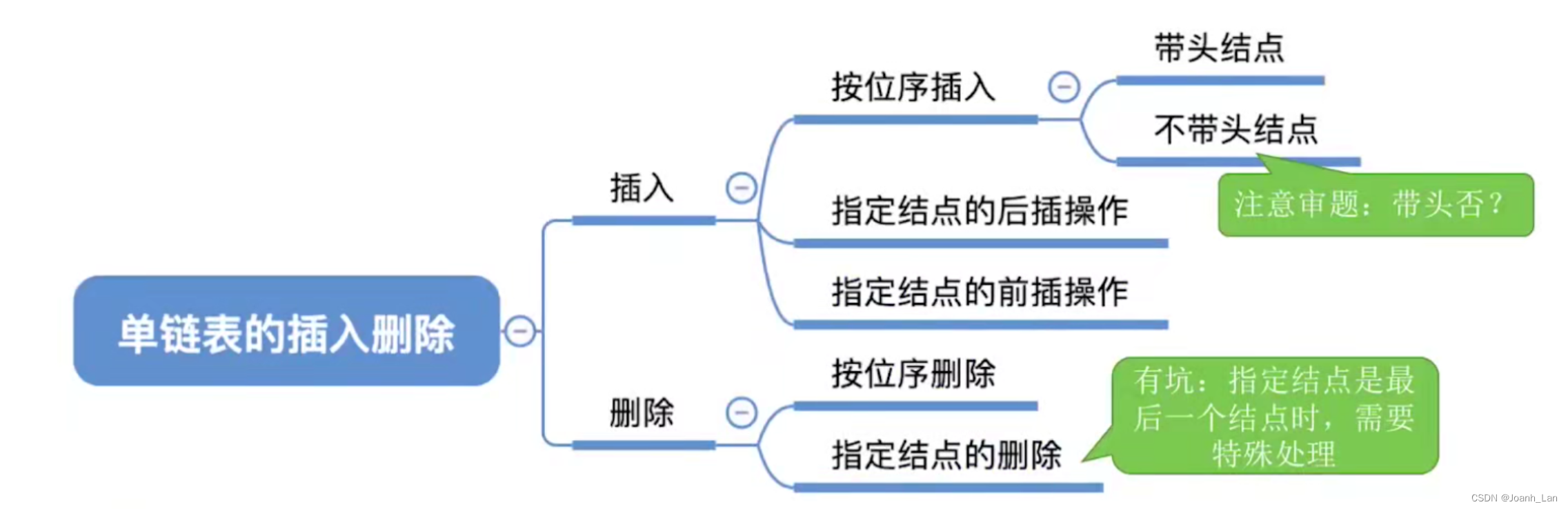
DINO原理
DINO是如何工作的
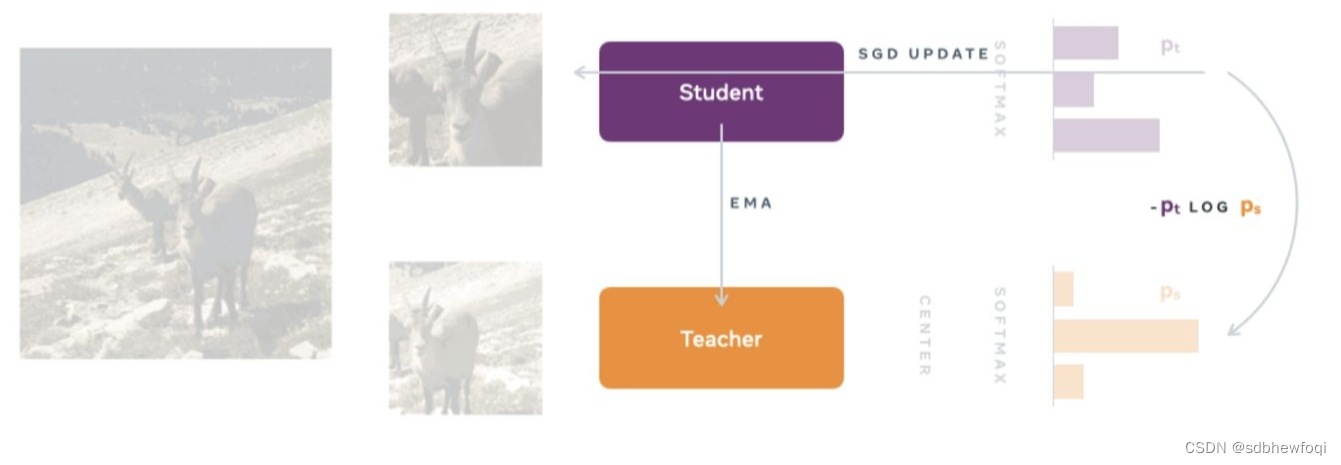
DINO 采用一种称为自蒸馏的方法。 这也是名字的由来:没有标签的自蒸馏
自蒸馏创造了一个教师和一个学生网络。 这两个网络都具有完全相同的模型架构。 DINO 的一大优势在于在这一点上完全灵活:可以使用 新兴的ViT 或 传统的卷积都是可以的,例如流行的 ResNet-50。
DINO 训练过程的简化概述: 一张图片被裁剪成两种尺寸,然后输入学生和教师网络。 对教师的输出应用居中操作,并且两个输出都通过 softmax 层归一化整理。 [2]
为了交叉熵作为损失函数为模型反向传播提供更新参数的策略。
两个 softmax 输出都传递到损失函数中,使用随机梯度下降 (SGD) 执行反向传播。在这里的反向传播是通过学生网络执行的,这时教师的权重尚未更新的原因。 为了更新教师模型,DINO 对学生权重使用指数移动平均 (EMA),将学生网络的模型参数传输到教师网络。

QA
一些我看论文前的问题,
1. DINO是什么?
DINO, which we interpret as a form of self-distillation with no labels.
一种没有labels的自蒸馏的形式。
没有label的知识蒸馏方式。design a simple self-supervised approach that can be interpreted as a form of knowledge distillation with no labels.
2. DINO VIT与 VIT 的关系是?
paper中描述:使用 ViT 训练 DINO。
我理解为:DINO是一种结构,结构里基本的特征提取是VIT。
暂时猜测,DINO VIT是通过数据【以自监督方式预训练】过的;
而 VIT 仅仅是通过数据【以图像分类方式预训练】过的;
3. 其他收获
- 论文里说明,dino vit(Self-supervised ViT) 在without any finetuning的情况下就可以在KNN任务上表现很好。
- vit patch越小,vit性能越好,但会慢。比如16*16比8*8的效果要好。
李沐精读论文:ViT 《An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale》_iwill323的博客-CSDN博客