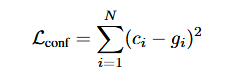目录
- 引言
- 一、`GROUP BY`核心规则与常见错误
- 二、高级分组选项:`ROLLUP`、`CUBE`与`GROUPING SETS`
- 三、窗口函数:在原始行中显示分组聚合结果
- 四、`UNION ALL`合并结果集:解决冗余查询问题
- 五、实验体会
- 结语 (附上实验中表格的信息)
- STUDENT057
- COURSE057
- TEACHER057
- SCORE057
引言
在数据库原理实验中,掌握数据分组查询(GROUP BY)和聚集函数(如AVG、MAX)的使用是核心目标。本次实验以“学生选课成绩”数据为例,深入实践了分组统计、高级分组选项(ROLLUP/CUBE)、窗口函数等关键技术,同时解决了多个典型问题。本文结合实验中的踩坑经历与收获,总结出一套实用的查询技巧。
一、GROUP BY核心规则与常见错误
1. 基础分组:非聚合列必须出现在GROUP BY中
问题场景:
执行以下语句时报错:
SELECT SNO, CNO, AVG(DEGREE)
FROM SCORE057
GROUP BY SNO;
错误信息: 如图所示

原因分析:
GROUP BY要求所有非聚合列(如CNO)必须出现在分组字段中,否则数据库无法确定如何对这些列进行分组。
正确做法:
将分组字段补充完整:
SELECT SNO, CNO, AVG(DEGREE)
FROM SCORE057
GROUP BY SNO, CNO; -- 按学号和课程号分组
2. 分组后的筛选:HAVING与WHERE的区别
核心规则:
WHERE:在分组前过滤数据(针对原始行)。HAVING:在分组后过滤数据(针对分组结果)。
示例:
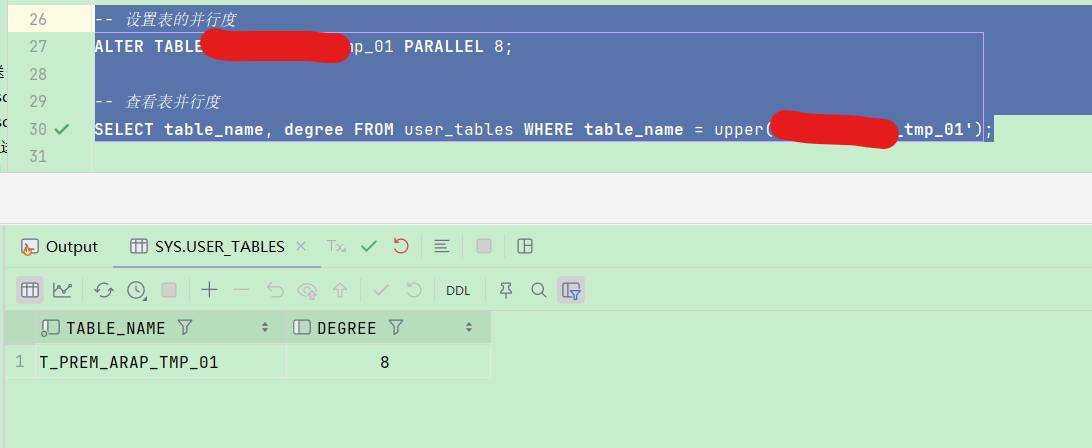
查询平均成绩≥80分的学生学号:
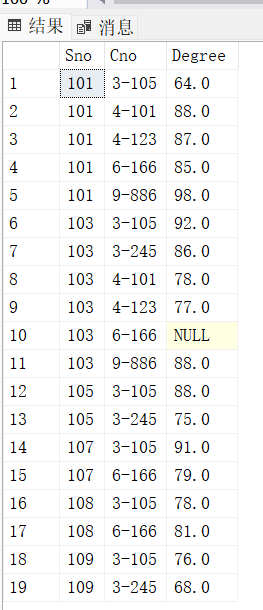
SELECT S.SNO,S.SNAME, AVG(DEGREE) AS 平均分
FROM SCORE057 SC
JOIN student057 S ON SC.Sno= S.Sno
GROUP BY S.SNO,S.SNAME
HAVING AVG(DEGREE) >= 80; -- 对分组后的平均分进行筛选
查询结果如下图所示:
二、高级分组选项:ROLLUP、CUBE与GROUPING SETS
1. ROLLUP:层级汇总(从右到左)
作用:生成多级汇总行,用于快速计算“分组+总计”。
示例:
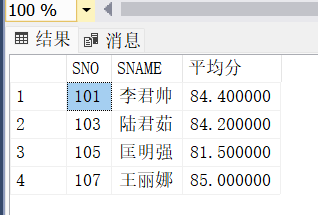
SELECT SNO, CNO, AVG(DEGREE)平均
FROM SCORE057
GROUP BY SNO, CNO WITH ROLLUP;
结果:

结果特点:
- 先按
(SNO, CNO)分组,再按SNO汇总(CNO为NULL),最后生成全表汇总(SNO和CNO均为NULL)。 - 适用于生成“部门→小组→总计”类层级报表。
2. CUBE:全组合汇总
作用:生成所有可能的分组组合(包括单个字段、交叉组合、全汇总)。
示例:
SELECT SNO, CNO, AVG(DEGREE) 平均
FROM SCORE057
GROUP BY CUBE(SNO, CNO);
结果:
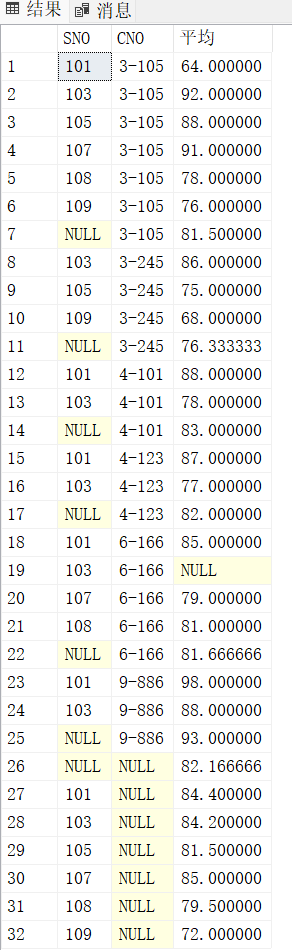
结果特点:
- 包含
(SNO, CNO)、SNO单独分组、CNO单独分组、全汇总(NULL, NULL)等所有组合。 - 适用于多维数据分析(如按学生、课程、全局的成绩汇总)。
3. GROUPING SETS:自定义分组组合
作用:按需指定分组方式,避免生成冗余的汇总行。
示例:
SELECT SNO, CNO, AVG(DEGREE) 平均分
FROM SCORE057
GROUP BY GROUPING SETS (SNO, CNO); -- 仅按SNO和按CNO分组
结果:
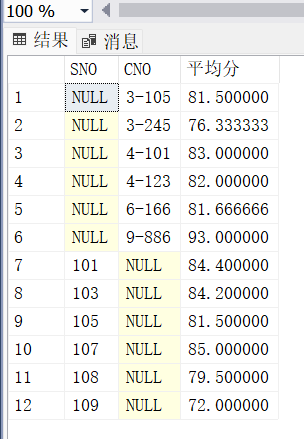
结果特点:
- 生成
SNO单独分组和CNO单独分组的结果,无交叉汇总。 - 灵活控制分组粒度,提升查询效率。
三、窗口函数:在原始行中显示分组聚合结果
场景需求:
查询学生的“学号、课程号、成绩”,并在每行显示该学生的平均分(按学号分区)和该课程的平均分(按课程号分区)。
解决方案:AVG() OVER (PARTITION BY ...)
SELECT
S.SNO 学号,
S.SNAME 姓名,
C.CNO 课程号,
C.CNAME 课程名,
SC.DEGREE 成绩,
AVG(SC.DEGREE) OVER (PARTITION BY S.SNO) AS 学生平均分, -- 按学号分区
AVG(SC.DEGREE) OVER (PARTITION BY C.CNO) AS 课程平均分 -- 按课程号分区
FROM STUDENT057 S
JOIN SCORE057 SC ON S.SNO = SC.SNO
JOIN COURSE057 C ON SC.CNO = C.CNO;
查询结果:
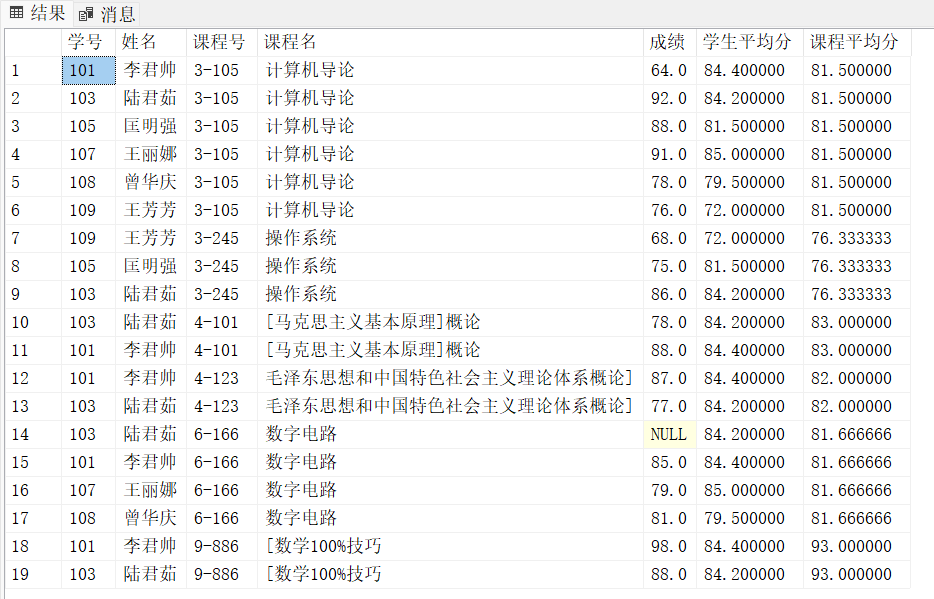
四、UNION ALL合并结果集:解决冗余查询问题
场景需求:
分别查询“每门课程的平均分”和“每位学生的平均分”,并将结果合并为一个报表,避免重复列。 如果按照上题所示的查询方法进行查询会发现查询结果过度冗余,影响表格的阅读。
解决方案:分两次查询后合并
SELECT '平' AS 学号, '均 ' AS 姓名, c.CNO AS 课程号, c.CNAME AS 课程名, AVG(sc.DEGREE) AS 平均
FROM SCORE057 sc
JOIN COURSE057 c ON sc.CNO = c.CNO
GROUP BY c.CNO, c.CNAME
UNION ALL
SELECT s.SNO AS 学号,s.SNAME AS 姓名, '平' AS 课程号,'均' AS 课程名, AVG(sc2.DEGREE) AS 平均
FROM STUDENT057 s
JOIN SCORE057 sc2 ON s.SNO = sc2.SNO
GROUP BY s.SNO, s.SNAME;
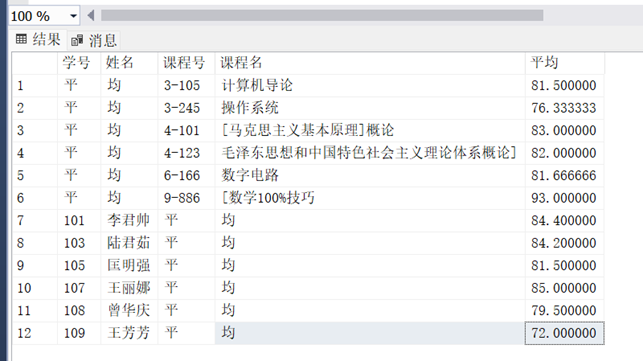
五、实验体会
1. 数据逻辑的严谨性
GROUP BY报错是因为忽略了“非聚合列必须分组”的规则,这提醒我们写查询时需明确“分组依据”与“显示列”的一致性。- 高级分组选项(
ROLLUP/CUBE)的结果差异,本质是对“汇总维度”的不同抽象,需结合业务场景选择。
2. 工具与文档的重要性
- 窗口函数的语法复杂,通过查阅SQL Server文档和调试示例,才理解
OVER子句的分区与排序逻辑。 - 报错信息是最好的老师,例如“列无效”错误直接指向
GROUP BY的规则,按提示修正即可。
3. 复杂查询的拆解思路
- 将“显示学生和课程平均分”的需求拆解为“原始数据→分区聚合→结果合并”,逐步实现避免逻辑混乱。
- 善用
JOIN关联多张表(学生、课程、成绩),确保数据完整性。
结语 (附上实验中表格的信息)
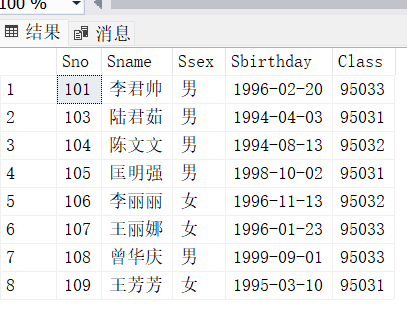
通过本次实验,不仅掌握了GROUP BY、聚集函数、窗口函数等核心查询技术,更重要的是学会了如何通过调试和分析解决实际问题。此次实验中的表格如下图所示:
STUDENT057
COURSE057
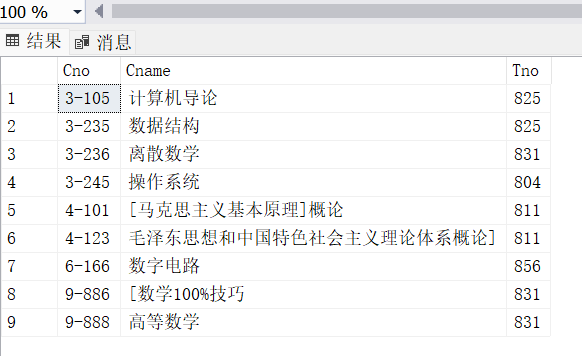
TEACHER057
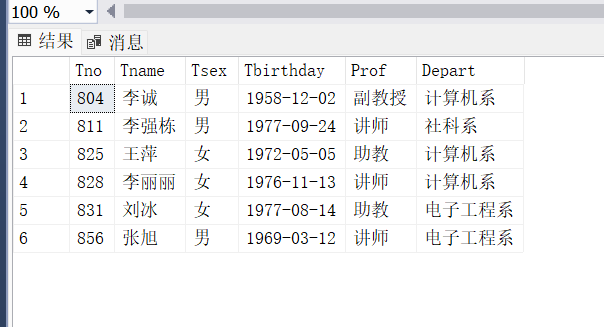
SCORE057