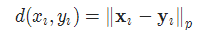文章目录
- Balanced Energy Regularization Loss for Out-of-distribution Detection
- 摘要
- 本文方法
- Balanced Energy regularization loss
- 实验结果
Balanced Energy Regularization Loss for Out-of-distribution Detection
摘要
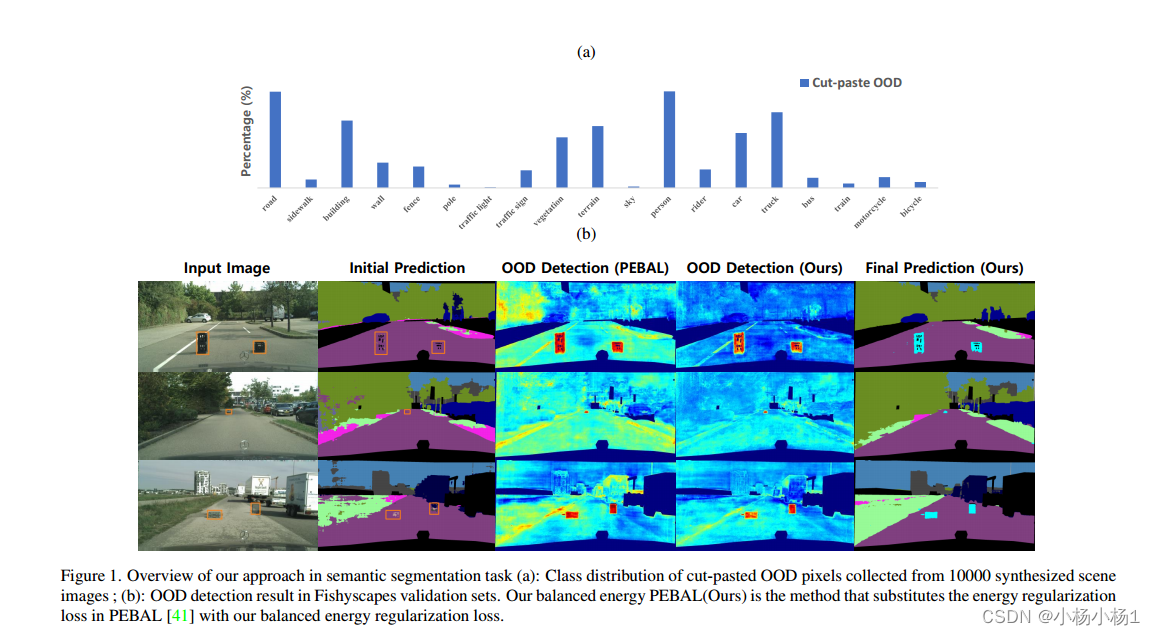
在超分布(out of distribution, OOD)检测领域,已有的一种使用辅助数据作为超分布数据的方法取得了良好的效果。然而,该方法为所有辅助数据提供了相等的损失,以区分它们与内层数据。然而,根据我们的观察,在各种任务中,辅助OOD数据的跨类分布普遍不平衡。我们提出了一种平衡的能量正则化损失,它简单但通常对各种任务有效。
本文方法
- 我们的平衡能量正则化损失利用辅助数据的类不同先验概率来解决OOD数据中的类不平衡问题。
- 主要概念是正则化来自多数类的辅助样本,比来自少数类的样本更重。我们的方法在语义分割、长尾图像分类和图像分类方面的OOD检测比先前的能量正则化损失有更好的表现。
- 代码地址
本文方法
基于能量的OOD检测(EnergyOE)还利用训练(ID)数据的交叉熵损失和辅助(OOD)数据的正则化损失。然而,EnergyOE提出的能量正则化损失能量与LOE不同,由
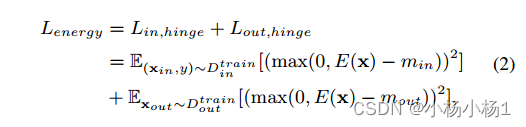
能量函数E(x;f)计算为logit经温度缩放后的LogSumExp,大多数情况下,温度T=1。能量正则化损失是能量与每个现有(ID)数据和辅助(OOD)数据的铰链损失的平方之和
Balanced Energy regularization loss
给定OOD样本的性质,我们的平衡能量正则化损失对OOD训练数据执行各种正则化。OOD样本的属性用新的术语Z来建模,用来衡量样本是属于多数类还是少数类。我们损失的主要思想是对多数类别的OOD样本使用比少数类别的OOD样本更大的正则化
对于OOD数据,我们创建了Z项来衡量样本是属于多数还是少数类别。我们需要OOD分布的先验概率来确定哪个类是多数。通过对表示为辅助数据的OOD数据的预训练模型进行推理,我们得到Ni,即被分类为i类的样本数量。接下来,通过
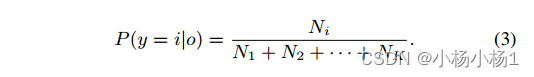
使用判别神经分类器f,通过对f的输出softmax得到给定图像x的第i类的后验概率,即
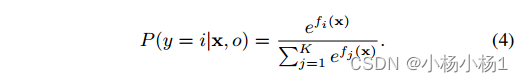
x属于第i类的后验概率越高,x属于第i类的概率就越高。第i类的先验概率越高,第i类成为多数类的概率就越高。因此P(y = i|o)和P(y = i|x, o)的乘积越高,x属于多数类i的可能性就越高。根据这个结果,度量x属于多数类可能性的度量Z定义为
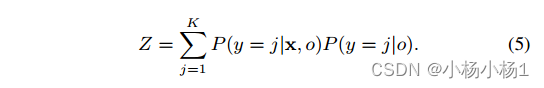
此外,我们利用超参数γ建立了附加广义先验概率模型。类间的先验差异程度由超参数γ控制。最后,将广义版本Zγ定义为
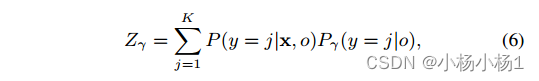
为了数值稳定性,我们在先验概率P(y = i|o)乘以自身γ次后应用l1归一化。如果γ=0,则我们建立均匀先验概率模型,并且Zγ变为恒定值1k。如果γ是负的,我们建立先验概率的逆分布模型。随着γ的增加,类之间的先验概率之差也会增加。

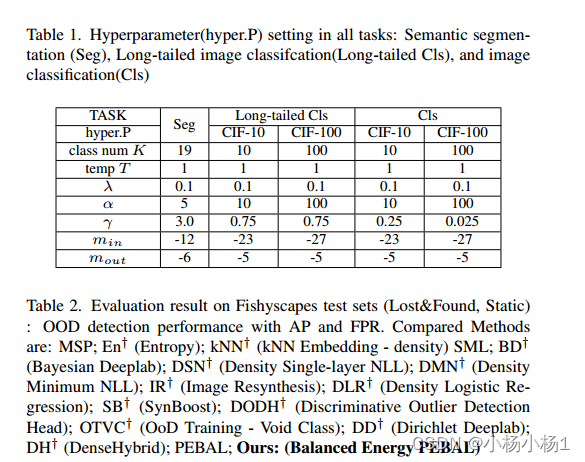
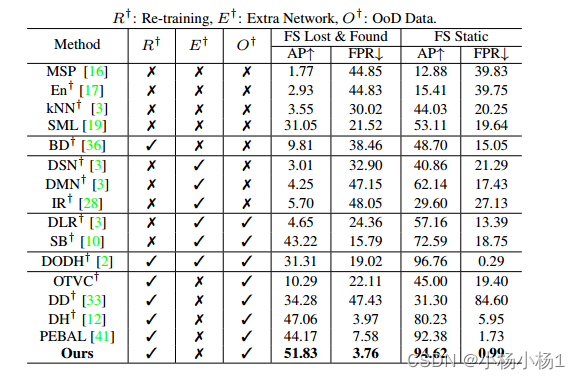
实验结果