1、背景
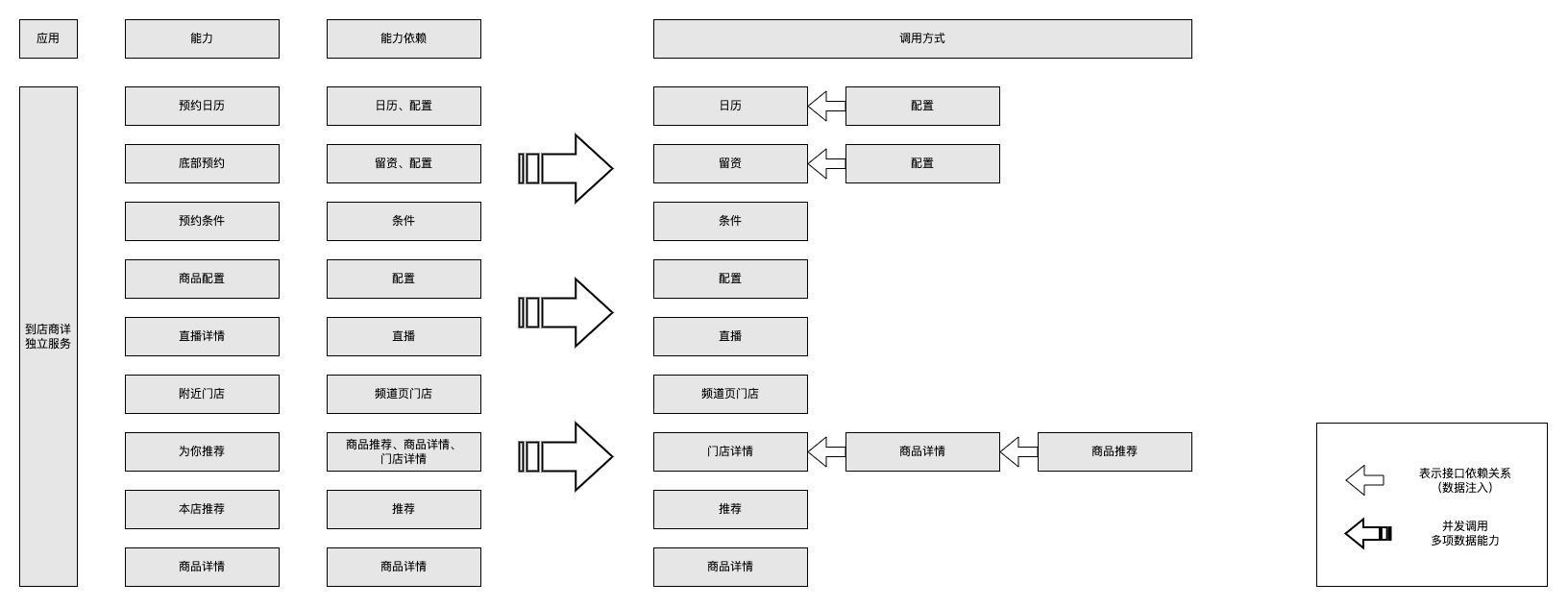
到店商详迭代过程中,需要提供的对外能力越来越多,如预约日历、附近门店、为你推荐等。这其中不可避免会出现多个上层能力依赖同一个底层接口的场景。最初采用的方案是对外API入口进来后获取对应的能力,并发调用多项能力,由能力层调用对应的数据链路,进行业务处理。然而,随着接入功能的增多,这种情况导致了底层数据服务的重复调用,如商品配置信息,在一次API调用过程中重复调了3次,当流量增大或能力项愈多时,对底层服务的压力会成倍增加。
正值618大促,各方接口的调用都会大幅度增加。通过梳理接口依赖关系来减少重复调用,对本系统而言,降低了调用数据接口时的线程占用次数,可以有效降级CPU。对调用方来说,减少了调用次数,可减少调用方的资源消耗,保障底层服务的稳定性。
原始调用方式:
2、优化
基于上述问题,采用底层接口依赖分层调用的方案。梳理接口依赖关系,逐层向上调用,注入数据,如此将同一接口的调用抽取到某层,仅调用一次,即可在整条链路使用。
改进调用方式:

只要分层后即可在每层采用多线程并发的方式调用,因为同一层级中的接口无先后依赖关系。
3、如何分层?
接下来,如何梳理接口层级关系就至关重要。
接口梳理分层流程如下:

第一步:构建层级结构
首先获取到能力层依赖项并遍历,然后调用生成数据节点方法。方法流程如下:构建当前节点,检测循环依赖(存在循环依赖会导致栈溢出),获取并遍历节点依赖项,递归生成子节点,存放子节点。
第二步:节点平铺
定义Map维护平铺结构,调用平铺方法。方法流程如下:遍历层级结构,判断当前节点是否已存在map中,存在时与原节点比较将层级大的节点放入(去除重复项),不存在时直接放入即可。然后处理子节点,递归调用平铺方法,处理所有节点。
第三步:分层(分组排序)
流处理平铺结构,处理层级分组,存储在TreeMap中维护自然排序。对应key中的数据节点Set需用多线程并发调用,以保证链路调用时间
1 首先,定义数据结构用于维护调用链路
Q1:为什么需要定义祖先节点?
A1:为了判断接口是否存在循环依赖。如果接口存在循环依赖而不检测将导致调用栈溢出,故而在调用过程中要避免并检测循环依赖。在遍历子节点过程中,如果发现当前节点的祖先已经包含当前子节点,说明依赖关系出现了环路,即循环依赖,此时抛异常终止后续流程避免栈溢出。
public class DataNode {
/**
* 节点名称
*/
private String name;
/**
* 节点层级
*/
private int level;
/**
* 祖先节点
*/
private List<String> ancestors;
/**
* 子节点
*/
private List<DataNode> children;
}
2 获取能力层的接口依赖,并生成对应的数据节点
Q1:生成节点时如何维护层级?
A1:从能力层依赖开始,层级从1递加。每获取一次底层依赖,底层依赖所生成的节点层级即父节点层级+1。
/**
* 构建层级结构
*
* @param handlers 接口依赖
* @return 数据节点集
*/
private List<DataNode> buildLevel(Set<String> handlers) {
List<DataNode> result = Lists.newArrayList();
for (String next : handlers) {
DataNode dataNode = generateNode(next, 1, null, null);
result.add(dataNode);
}
return result;
}
/**
* 生成数据节点
*
* @param name 节点名称
* @param level 节点层级
* @param ancestors 祖先节点(除父辈)
* @param parent 父节点
* @return DataNode 数据节点
*/
private DataNode generateNode(String name, int level, List<String> ancestors, String parent) {
AbstractInfraHandler abstractInfraHandler = abstractInfraHandlerMap.get(name);
Set<String> infraDependencyHandlerNames = abstractInfraHandler.getInfraDependencyHandlerNames();
// 根节点
DataNode dataNode = new DataNode(name);
dataNode.setLevel(level);
dataNode.putAncestor(ancestors, parent);
if (CollectionUtils.isNotEmpty(dataNode.getAncestors()) && dataNode.getAncestors().contains(name)) {
throw new IllegalStateException("依赖关系中存在循环依赖,请检查以下handler:" + JsonUtil.toJsonString(dataNode.getAncestors()));
}
if (CollectionUtils.isNotEmpty(infraDependencyHandlerNames)) {
// 存在子节点,子节点层级+1
for (String next : infraDependencyHandlerNames) {
DataNode child = generateNode(next, level + 1, dataNode.getAncestors(), name);
dataNode.putChild(child);
}
}
return dataNode;
}
层级结构如下:

3 数据节点平铺(遍历出所有后代节点)
Q1:如何处理接口依赖过程中的重复项?
A1:遍历所有的子节点,将所有子节点平铺到一层,平铺时如果节点已经存在,比较层级,保留层级大的即可(层级大说明依赖位于更底层,调用时要优先调用)。
/**
* 层级结构平铺
*
* @param dataNodes 数据节点
* @param dataNodeMap 平铺结构
*/
private void flatteningNodes(List<DataNode> dataNodes, Map<String, DataNode> dataNodeMap) {
if (CollectionUtils.isNotEmpty(dataNodes)) {
for (DataNode dataNode : dataNodes) {
DataNode dataNode1 = dataNodeMap.get(dataNode.getName());
if (Objects.nonNull(dataNode1)) {
// 存入层级大的即可,避免重复
if (dataNode1.getLevel() < dataNode.getLevel()) {
dataNodeMap.put(dataNode.getName(), dataNode);
}
} else {
dataNodeMap.put(dataNode.getName(), dataNode);
}
// 处理子节点
flatteningNodes(dataNode.getChildren(), dataNodeMap);
}
}
}
平铺结构如下:

4 分层(分组排序)
Q1:如何分层?
A1:节点平铺后已经去重,此时借助TreeMap的自然排序特性将节点按照层级分组即可。
/**
* @param dataNodeMap 平铺结构
* @return 分层结构
*/
private TreeMap<Integer, Set<DataNode>> processLevel(Map<String, DataNode> dataNodeMap) {
return dataNodeMap.values().stream().collect(Collectors.groupingBy(DataNode::getLevel, TreeMap::new, Collectors.toSet()))
}
分层如下:

1.根据分层TreeMap的key倒序即为调用的层级顺序
对应key中的数据节点Set需用多线程并发调用,以保证链路调用时间
4、分层级调用
梳理出调用关系并分层后,使用并发编排工具调用即可。这里梳理的层级关系,level越大,表示越优先调用。
这里以京东内部并发编排框架为例,说明调用流程:
/**
* 构建编排流程
*
* @param infraDependencyHandlers 依赖接口
* @param workerExecutor 并发线程
* @return 执行数据
*/
public Sirector<InfraContext> buildSirector(Set<String> infraDependencyHandlers, ThreadPoolExecutor workerExecutor) {
Sirector<InfraContext> sirector = new Sirector<>(workerExecutor);
long start = System.currentTimeMillis();
// 依赖顺序与执行顺序相反
TreeMap<Integer, Set<DataNode>> levelNodes;
TreeMap<Integer, Set<DataNode>> cacheLevelNodes = localCacheManager.getValue("buildSirector");
if (Objects.nonNull(cacheLevelNodes)) {
levelNodes = cacheLevelNodes;
} else {
levelNodes = getLevelNodes(infraDependencyHandlers);
ExecutorUtil.executeVoid(asyncTpExecutor, () -> localCacheManager.putValue("buildSirector", levelNodes));
}
log.info("buildSirector 梳理依赖关系耗时:{}", System.currentTimeMillis() - start);
// 最底层接口执行
Integer firstLevel = levelNodes.lastKey();
EventHandler[] beginHandlers = levelNodes.get(firstLevel).stream().map(node -> abstractInfraHandlerMap.get(node.getName())).toArray(EventHandler[]::new);
EventHandlerGroup group = sirector.begin(beginHandlers);
Integer lastLevel = levelNodes.firstKey();
for (int i = firstLevel - 1; i >= lastLevel; i--) {
EventHandler[] thenHandlers = levelNodes.get(i).stream().map(node -> abstractInfraHandlerMap.get(node.getName())).toArray(EventHandler[]::new);
group.then(thenHandlers);
}
return sirector;
}
5、 个人思考
-
作为接入内部RPC、Http接口实现业务处理的项目,在使用过程中要关注调用链路上的资源复用,尤其长链路的调用,要深入考虑内存资源的利用以及对底层服务的压力。
-
要关注对外服务接口与底层数据接口的响应时差,分析调用逻辑与流程是否合理,是否存在优化项。
-
多线程并发调用多个平行数据接口时,如何使得各个线程的耗时方差尽可能小?
作者:京东零售 王江波
来源:京东云开发者社区