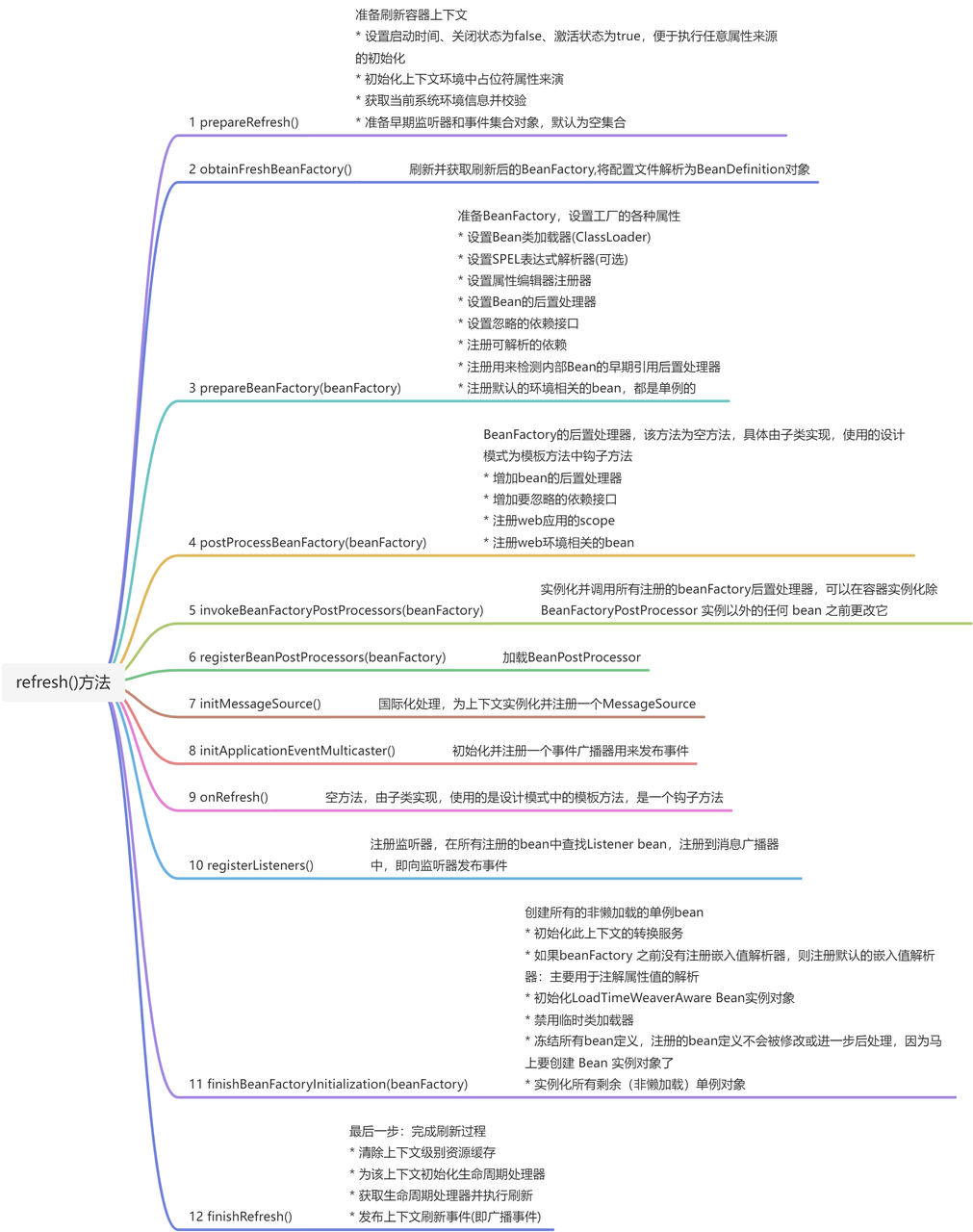
目录
一.前言
二.数据预处理
三.构造神经网络
四.训练
五.评价结果(预测)
一.前言
我们将构建和训练字符级RNN来对单词进行分类。字符级RNN将单词作为一系列字符读取,在每一步输出预测和“隐藏状态”,将其先前的隐藏 状态输入至下一时刻。我们将最终时刻输出作为预测结果,即表示该词属于哪个类。
具体来说,我们将在18种语言构成的几千个名字的数据集上训练模型,根据一个名字的拼写预测它是哪种语言的名字:
$ python predict.py Hinton
(-0.47) Scottish
(-1.52) English
(-3.57) Irish
$ python predict.py Schmidhuber
(-0.19) German
(-2.48) Czech
(-2.68) Dutch项目结构:

二.数据预处理
点击这里下载数据,并将其解压到当前文件夹。
在"data/names"文件夹下是名称为"[language].txt"的18个文本文件。每个文件的每一行都有一个名字,它们几乎都是罗马化的文本 (但是我们仍需要将其从Unicode转换为ASCII编码)
我们最终会得到一个语言对应名字列表的字典,{language: [names ...]}。通用变量“category”和“line”(例子中的语言和名字单词) 用于以后的可扩展性。
下面的的处理数据的代码把上篇文章的数据预处理代码和训练前的张量转换代码算是汇总了一下:
dataPreprocessing.py
from __future__ import unicode_literals, print_function, division
from io import open
import glob
import os
import unicodedata
import string
import torch
class DataPreprocessing:
def __init__(self):
self.all_letters = string.ascii_letters + " .,;'-" # 注意还有空格
# print('string.ascii_letters:', string.ascii_letters) # 大小写的26个字母
# print('all_letters:', self.all_letters)
self.n_letters = len(self.all_letters) + 1 # Plus EOS marker
# print('总的字符数量:', self.n_letters)
def findFiles(self,path):
# glob.glob返回符合匹配条件的所有文件的路径,即路径中可以用正则表达式
return glob.glob(path)
# 将Unicode字符串转换为纯ASCII, 感谢https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(self,s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in self.all_letters
)
# 读取文件并分成几行
def readLines(self,filename):
# strip()返回删除前导和尾随空格的字符串副本
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [self.unicodeToAscii(line) for line in lines]
def processing(self):
# 构建category_lines字典,列表中的每行是一个类别
category_lines = {}
all_categories = []
for filename in self.findFiles('data/names/*.txt'):
# print(filename) filename是一个路径
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = self.readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
if n_categories == 0:
raise RuntimeError('Data not found. Make sure that you downloaded data '
'from https://download.pytorch.org/tutorial/data.zip and extract it to '
'the current directory.')
return category_lines,all_categories,n_categories,self.all_letters,self.n_letters;
data=DataPreprocessing()
#返回值类型分别是 字典,列表,整数,字符串,整数
'''
现在我们有了category_lines,一个字典变量存储每一种语言及其对应的每一行文本(名字)列表的映射关系。
变量all_categories是全部 语言种类的列表,变量n_categories是语言种类的数量,后续会使用。
'''
category_lines,all_categories,n_categories,all_letters,n_letters=data.processing()
#print(category_lines['Italian'][:5])
'''
单词转变为张量
现在我们已经加载了所有的名字,我们需要将它们转换为张量来使用它们。
我们使用大小为<1 x n_letters>的“one-hot 向量”表示一个字母。一个one-hot向量所有位置都填充为0,并在其表示的字母的位置表示为1,
例如"b" = <0 1 0 0 0 ...>.(字母b的编号是2,第二个位置是1,其他位置是0)
我们使用一个<line_length x 1 x n_letters>的2D矩阵表示一个单词,line_length是单词的长度,即此单词包含多少字符
额外的1维是batch的维度,PyTorch默认所有的数据都是成batch处理的。我们这里只设置了batch的大小为1。
'''
# 从all_letters中查找字母索引,例如 "a" = 0
def letterToIndex(letter):
return all_letters.find(letter)
# 仅用于演示,将字母转换为<1 x n_letters> 张量
def letterToTensor(letter):
tensor = torch.zeros(1, n_letters)
tensor[0][letterToIndex(letter)] = 1
return tensor
# 将一个单词(即名字)转换为<line_length x 1 x n_letters>,或一个0ne-hot字母向量的数组
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor
# print(letterToTensor('J'))
# print(lineToTensor('Joy'))
# print(lineToTensor('Joy').size())三.构造神经网络
在autograd之前,要在Torch中构建一个可以复制之前时刻层参数的循环神经网络。layer的隐藏状态和梯度将交给计算图自己处理。这意味着 你可以像实现的常规的 feed-forward 层一样,以很纯粹的方式实现RNN。
这个RNN组件 (几乎是从这里复制的the PyTorch for Torch users tutorial) 仅使用两层 linear 层对输入和隐藏层做处理,在最后添加一层 LogSoftmax 层预测最终输出。
model.py
import torch
import torch.nn as nn
from dataPreprocessing import n_letters,n_categories
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)四.训练
代码中的每句注释都要好好看,精华!!!想要完全理解分段解开相应的代码输出看看是非常有效的办法。
这个项目的很多代码都和上篇文章(字符级RNN生成名字)差不多,所以很多地方就不注释了,上篇已详细注释。
train.py
import torch
from torch import nn
from model import RNN
from dataPreprocessing import n_letters,n_categories,letterToTensor,lineToTensor,all_categories,category_lines
import random
######################################### 训练前的准备 #################################################
n_hidden = 128
#传入的参数分别是字符的总个数,隐藏状态向量的维度,名字(所属国家)种类的个数
rnn = RNN(n_letters, n_hidden, n_categories)
'''
要运行此网络的一个步骤,我们需要传递一个输入(在我们的例子中,是当前字母的Tensor)和一个先前隐藏的状态(我们首先将其初始化为零)。
我们将返回输出(每种语言的概率)和下一个隐藏状态(为我们下一步保留使用)。
'''
# input = letterToTensor('A')
# hidden =torch.zeros(1, n_hidden)
# output, next_hidden = rnn(input, hidden)
#print(output.shape) # torch.Size([1, 18])
#print(next_hidden.shape)# torch.Size([1, 128])
#print(next_hidden)
'''
为了提高效率,我们不希望为每一步都创建一个新的Tensor,因此我们将使用lineToTensor函数而不是letterToTensor函数,并使用切片方法。
这一步可以通过预先计算批量的张量进一步优化。
'''
# input = lineToTensor('Albert')
# print('input.shape:',input.shape)
# print('input[0].shape:',input[0].shape)
# hidden = torch.zeros(1, n_hidden)
# output, next_hidden = rnn(input[0], hidden)
#可以看到输出是一个<1 x n_categories>的张量,其中每一条代表这个单词属于某一类的可能性(越高可能性越大)。
# print('input[0]各类别的可能性:',output)
'''
进行训练步骤之前我们需要构建一些辅助函数。 * 第一个是当我们知道输出结果对应每种类别的可能性时,解析神经网络的输出。
我们可以使用 Tensor.topk函数得到最大值在结果中的位置索引:
'''
#从output中获取对应的种类与下标
def categoryFromOutput(output):
#top_n是output中数值最大的那个,top_i是对应的下标(从0开始)
top_n, top_i = output.topk(1)
# print('top_n:',top_n)
# print('top_i:',top_i)
category_i = top_i[0].item()
return all_categories[category_i], category_i
# print(categoryFromOutput(output))
# 第二个是我们需要一种快速获取训练示例(得到一个名字及其所属的语言类别)的方法:
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
def randomTrainingExample():
category = randomChoice(all_categories)
line = randomChoice(category_lines[category])
#返回种类对应的下标(张量形式)
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long)
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor
# for i in range(10):
# category, line, category_tensor, line_tensor = randomTrainingExample()
# print('category =', category, '/ line =', line)
############################################# 训练神经网络 #####################################################
# 现在,训练过程只需要向神经网络输入大量的数据,让它做出预测,并将对错反馈给它。
# nn.LogSoftmax作为最后一层layer时,nn.NLLLoss作为损失函数是合适的。
criterion = nn.NLLLoss()
'''
训练过程的每次循环将会发生:
.构建输入和目标张量
.构建0初始化的隐藏状态
.读入每一个字母
* 将当前隐藏状态传递给下一字母
.比较最终结果和目标
.反向传播
.返回结果和损失
'''
learning_rate = 0.005 # If you set this too high, it might explode(爆炸). If too low, it might not learn
#line_tensor就是一个单词对应的向量
def train(category_tensor, line_tensor):
hidden = rnn.initHidden()
#梯度清零
rnn.zero_grad()
#前向传播
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
#损失
loss = criterion(output, category_tensor)
#反向传播,计算梯度
loss.backward()
#更新权重
# 将参数的梯度添加到其值中,乘以学习速率
for p in rnn.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item()
# 现在我们只需要准备一些例子来运行程序。由于train函数同时返回输出和损失,我们可以打印其输出结果并跟踪其损失画图。
# 由于有1000个示例,我们每print_every次打印样例,并求平均损失。
import time
import math
n_iters = 100000
print_every = 5000
plot_every = 1000
# 跟踪绘图的损失
current_loss = 0
all_losses = []
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
'''
因为下面的代码没写在函数中,而且predict.py又从train.py里导了包,所以执行predict.py里的代码时,
train.py里的代码也会被执行,所以当训练完毕模型参数保存后要把下面的代码注释掉,需要训练时再重新解开运行
'''
# start = time.time()
#
# for iter in range(1, n_iters + 1):
# category, line, category_tensor, line_tensor = randomTrainingExample()
# output, loss = train(category_tensor, line_tensor)
# current_loss += loss
#
# # 打印迭代的编号,损失,名字和猜测
# if iter % print_every == 0:
# guess, guess_i = categoryFromOutput(output)
# correct = '✓' if guess == category else '✗ (%s)' % category
# print('%d %d%% (%s) %.4f %s / %s %s' % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
#
# # 将当前损失平均值添加到损失列表中
# if iter % plot_every == 0:
# all_losses.append(current_loss / plot_every)
# current_loss = 0
#
# # 画图:从all_losses得到历史损失记录,反映了神经网络的学习情况:
# import matplotlib.pyplot as plt
#
# plt.figure()
# plt.plot(all_losses)
# plt.show()
#
# #保存模型
# torch.save(rnn.state_dict(), './model/myRNN.pth')五.评价结果(预测)
predict.py
import torch
from matplotlib import pyplot as plt, ticker
from dataPreprocessing import n_categories,all_categories,n_letters
from train import randomTrainingExample,categoryFromOutput,lineToTensor
from model import RNN
n_hidden = 128
#传入的参数分别是字符的总个数,隐藏状态向量的维度,名字(所属国家)种类的个数
rnn = RNN(n_letters, n_hidden, n_categories)
#加载已经训练好的模型参数
rnn.load_state_dict(torch.load('./model/myRNN.pth'))
#eval函数(一定用!!!)的作用请参考 https://blog.csdn.net/lgzlgz3102/article/details/115987271
rnn.eval()
'''
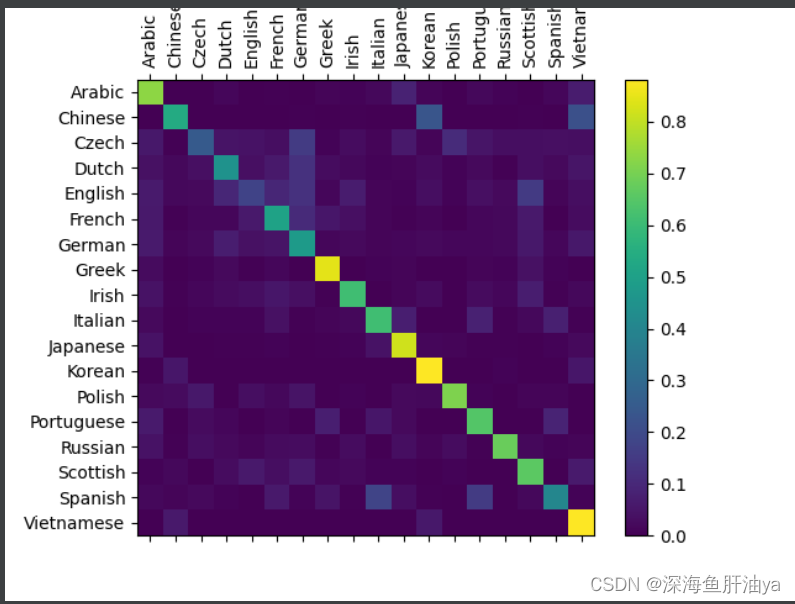
为了了解网络在不同类别上的表现,我们将创建一个混淆矩阵,显示每种语言(行)和神经网络将其预测为哪种语言(列)。
为了计算混淆矩 阵,使用evaluate()函数处理了一批数据,evaluate()函数与去掉反向传播的train()函数大体相同。
'''
# 在混淆矩阵中跟踪正确的猜测
confusion = torch.zeros(n_categories, n_categories)
n_confusion = 10000
# 只需返回给定一行的输出,即对一个人名的预测结果(1*n_categories的二维矩阵)
def evaluate(line_tensor):
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
return output
# 查看一堆正确猜到的例子和记录
for i in range(n_confusion):
#标签
category, line, category_tensor, line_tensor = randomTrainingExample()
#预测结果
output = evaluate(line_tensor)
guess, guess_i = categoryFromOutput(output)
category_i = all_categories.index(category)
confusion[category_i][guess_i] += 1
# 通过将每一行除以其总和来归一化
for i in range(n_categories):
confusion[i] = confusion[i] / confusion[i].sum()
# print(confusion[:3])
# print(confusion[17])
# 设置绘图
'''
你可以从主轴线以外挑出亮的点,显示模型预测错了哪些语言,例如汉语预测为了韩语,西班牙预测为了意大利。
看上去在希腊语上效果很好, 在英语上表现欠佳。(可能是因为英语与其他语言的重叠较多)。
'''
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)
# 设置轴
ax.set_xticklabels([''] + all_categories, rotation=90)
ax.set_yticklabels([''] + all_categories)
# 每个刻度线强制标签
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
# sphinx_gallery_thumbnail_number = 2
plt.show()
#处理用户输入
def predict(input_line, n_predictions=3):
print('\n> %s' % input_line)
with torch.no_grad():
output = evaluate(lineToTensor(input_line))
# 获得前N个类别
# topk函数参考 https://blog.csdn.net/qq_38156104/article/details/109318702
topv, topi = output.topk(n_predictions, 1, True)
print('topv:',topv)
print('topi:', topi)
# predictions = []
for i in range(n_predictions):
#概率
value = topv[0][i].item()
#索引
category_index = topi[0][i].item()
print('(%.2f) %s' % (value, all_categories[category_index]))
# predictions.append([value, all_categories[category_index]])
predict('Dovesky')
predict('Jackson')
predict('Satoshi')输出结果:
> Dovesky
topv: tensor([[-0.5240, -1.3990, -2.5749]])
topi: tensor([[ 2, 14, 4]])
(-0.52) Czech
(-1.40) Russian
(-2.57) English
> Jackson
topv: tensor([[-0.7963, -1.4187, -1.6734]])
topi: tensor([[15, 3, 4]])
(-0.80) Scottish
(-1.42) Dutch
(-1.67) English
> Satoshi
topv: tensor([[-0.9223, -1.0976, -2.0812]])
topi: tensor([[10, 0, 9]])
(-0.92) Japanese
(-1.10) Arabic
(-2.08) Italian








![[附源码]计算机毕业设计框架的食品安全监督平台的设计与实现Springboot程序](https://img-blog.csdnimg.cn/2d334224e1d44e54b6faf404af3e1e26.png)
![[附源码]Python计算机毕业设计Django演唱会门票售卖系统](https://img-blog.csdnimg.cn/81c60f438d5f4c37ba3aec51bc00cfdf.png)

