目录
举一反三-论微服务架构及其应用
ps: 更多微服务信息
ps: 微服务与SOA区别
微服务架构举例
微服务的落地技术
微服务的技术可大致分为五类
举一反三-论微服务架构及其应用
论微服务架构及其应用
微服务提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相沟通。在微服务架构中,每个服务都是一个相对独立的个体,每个服务都可以选择适合于自身的技术来实现。每个服务的部署都是独立的,这样就可以更快地对特定部分的代码进行部署。
请围绕“论微服务架构及其应用”论题,依次从以下三个方面进行论述。
1、概要叙述你所参与管理或开发的软件项目,以及你在其中所承担的主要工作。
2、简要描述微服务优点。
3、具体阐述如何基于微服务架构进行软件设计实现的。
问题1: 同上述。 可以公共使用
问题2:
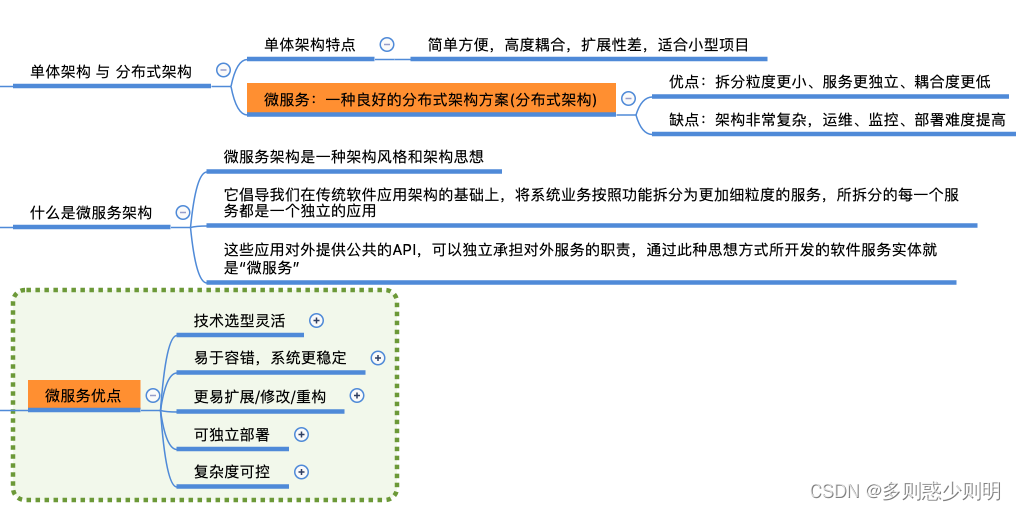
优点概述:
技术选型灵活
在微服务架构中,每个服务都是一个相对独立的个体,每个服务都可以选择合适于自身的技术来实现;
因为对于单块的系统而言,采用一个新的语言,数据库或者框架都会对整个系统产生非常巨大的影响,这样就导致我们在尝试新技术的时候望而却步。
微服务不同,我们完全可以只在一个微服务中采用新技术,然后等成熟之后再推广到其他的服务当中
易于容错,系统更稳定
在单块系统中一个部分出现问题,可能导致整个系统的问题;
微服务架构中,每个服务可以内置可用性的解决方案与功能降级方案,所以比单块系统强大
更易扩展/修改/重构
在单块的系统中我们如果要对系统进行扩展的话,必须是整体的进行扩展;
使用微服务的架构中,可以针对单个服务进行扩展。
在微服务架构中,我们可以在需要时轻易的重写服务,或者删除不再使用的服务
可独立部署
对于大型单块的系统,哪怕是修改了一行代码,都要对其进行重新的整体的部署。 影响大,风险高。
在微服务中,每个服务都是独立部署的,而且还可以实现自动化的部署,这样就可以更快的对特定部分的代码进行部署。
当某个微服务发生变更时,无需编译、部署整个应用。
复杂度可控
对于传统的单块系统来说,系统越大代码库越大,则越难管理,而且还会出现一系列管理方面的问题。
每一个微服务专注于单一功能,并通过定义良好的接口清晰地表述服务边界。由于体积小、复杂度低,每个微服务可由一个小规模开发团队完全掌控(避免代码库过大),易于保持高可维护性,并提高了开发效率。
ps: 更多微服务信息
微服务缺点:
1、开发人员必须处理创建分布式系统的复杂性

2、部署的复杂性
在部署和管理时,由许多不同服务类型组成的系统的操作比较复杂
3、增加内存消耗
微服务架构用多个服务实例取代了1个单体应用程序实例,如果每个服务都运行在自己的JVM中,那么有多少个服务实例,就会有多少个实例在运行时的内存开销
ps: 微服务与SOA区别
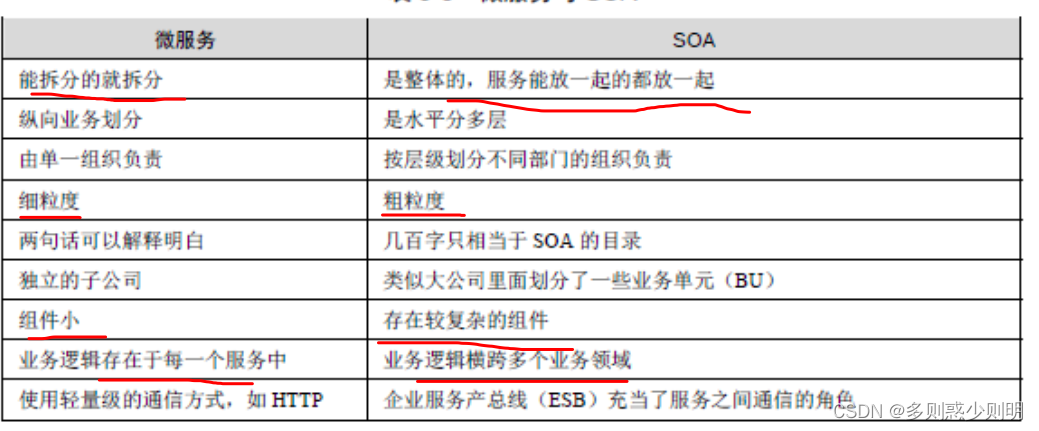
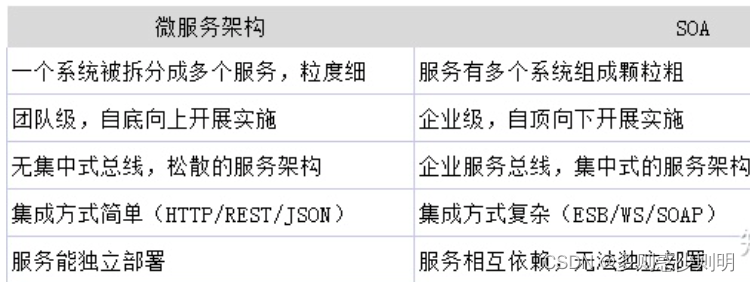
共同点:
都是对单体架构的拆分
区别:
微服务架构举例
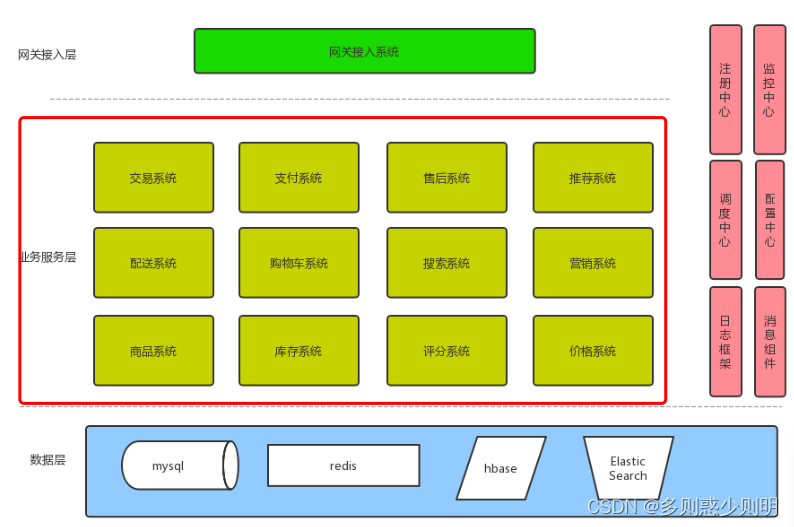
业务服务系统各司其职,每个系统只负责自己业务范围内的职责,比如商品系统仅服务商品相关的服务,创建,更新,查询,上下架等整个的生命周期并被购物车系统依赖,服务系统之间的逻辑关系清晰,且不同系统间只能通过对方提供的接口做访问,管理方便,每个系统拥有自己独立部署服务器,拥有自己的存储数据库,故障可隔离,配合日志,消息,监控,配置中心等分部署微服务下的配合组件做到一个可监控,可隔离,又可通信的服务体系
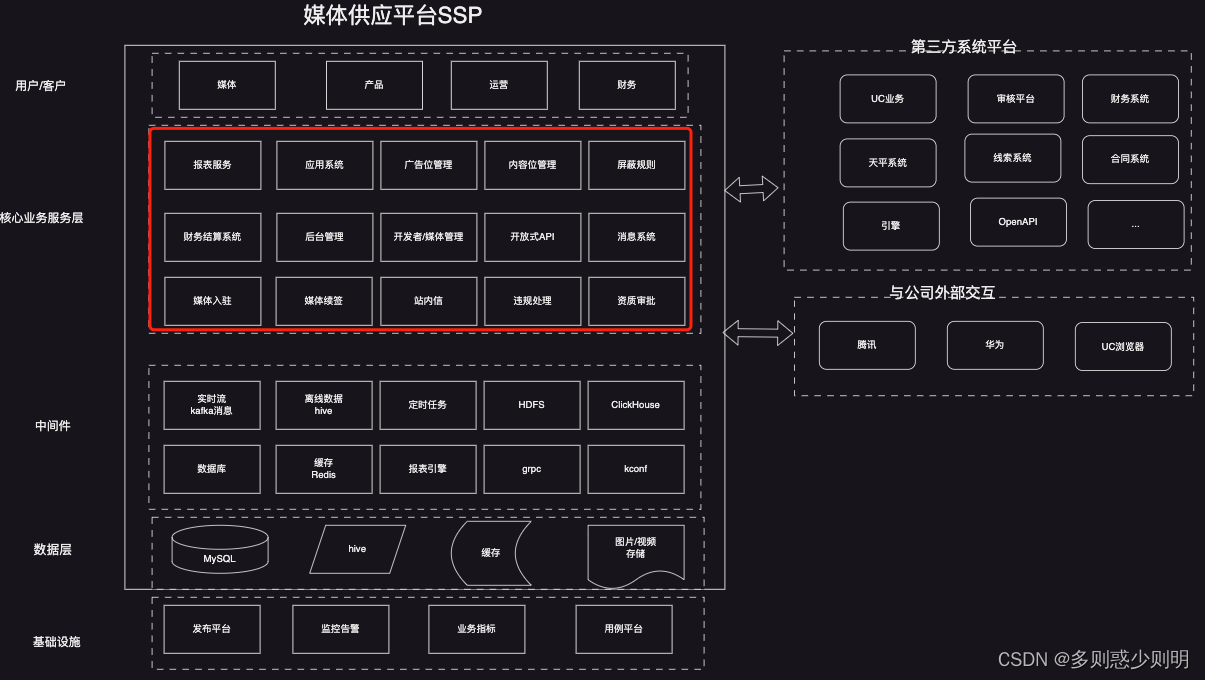
ps: 核心业务服务层,也是微服务实现。
微服务的落地技术
参考:微服务技术概述_Fall_Flower的博客-CSDN博客
微服务技术栈:
- 服务集群。 微服务在拆分的时候会根据业务功能模块,把一个单体项目拆分成功能独立的项目,每个项目完成一部分业务功能,将来独立开发和部署,我们将每个独立的项目称为服务,一个大型互联网项目往往包含数百上千的服务,最终形成服务集群
-
注册中心和配置中心。当一个请求到来的时候,服务a可能会去调服务c,服务c再去调服务e,当业务越来越复杂的时候,服务间的调用关系就会混乱不堪,想靠人去记录和维护是不可能的,这时候就要引出注册中心了。
注册中心能记录每个微服务的ip、端口、能干什么事情,这样当一个服务需要去调用另外一个服务时,它不需要去记录对方的ip、端口信息,只需要去注册中心拉取即可。
配置中心,它可以统一管理服务集群里面所有服务的配置,如果你需要跟新某个服务的配置,只需要修改配置中心相应配置,它会去通知相关服务去修改配置实现配置的热更新。
-
服务网关。服务跑起来之后,当用户来访问时,究竟去访问哪个微服务呢,这时候就需要一个网关组件,网关组件还能让微服务不对外暴露。在访问的时候还会去做一些负载均衡。
-
分布式缓存和分布式搜索。 数据库将来肯定无法抗住高并发,因此我们还会加入分布式缓存。
-
消息队列。在微服务中还需要异步通信的消息队列组件。在一个请求到来时,假设调用了服务a,用时10ms,但是服务a调用了服务c,又用时10ms,而服务a在调用c的时候自己也不能再处理新的请求,这样就降低了整体服务效率。
-
分布式日志和系统监控链路追踪。这么庞大的集群,若某处发生问题是很难定位的,所以这时候有引入了分布式日志,分布式日志可以统一的为所有服务日志做存储、统计、分析,将来出问题就比较好定位了。
-
持续集成。
如此庞大的微服务集群,可能会达到数千上万的服务,部署也成了一个问题。靠人工部署肯定不现实,所以以后还会进行自动化部署。可以利用Jenkins工具对微服务项目进行自动化编译,基于docker做一些打包,形成镜像,再基于k8s技术去实现自动化的部署。这一套工具就被称为:持续集成
结合微服务技术加上持续集成,这才是完整的微服务技术栈。
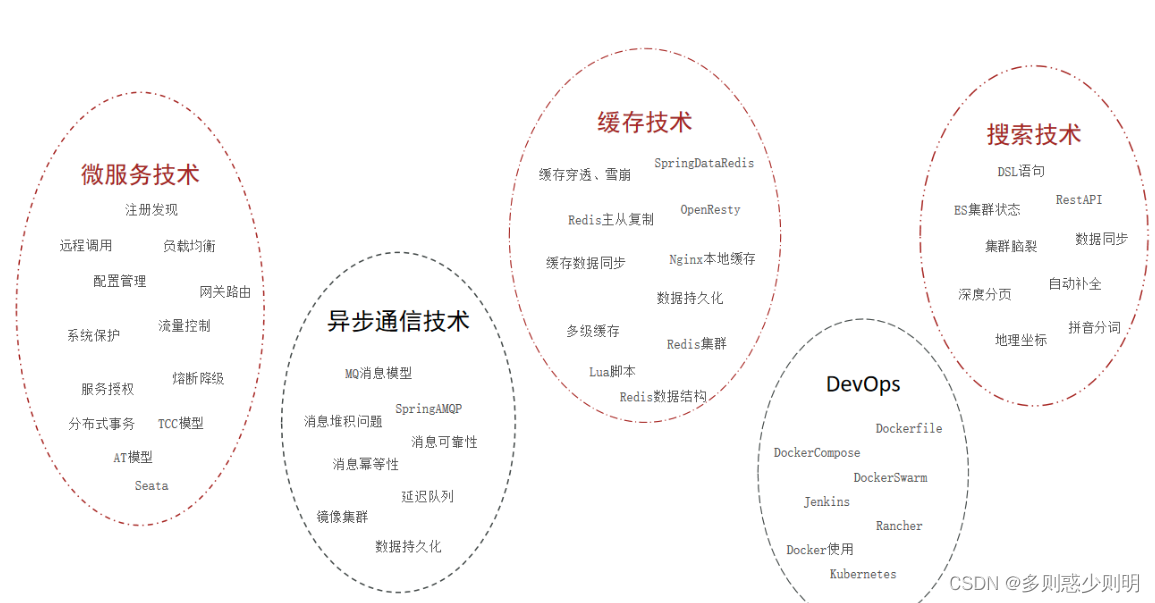
微服务的技术可大致分为五类
实践1——服务通信 :远程的网络通信调用函数的方式就是RPC(Remote Process Call)远程过程调用。
一个 RPC 框架基本需要解决 协议约定、网络传输、服务发现这三个问题。
①协议约定问题(Stub) 指的是怎么规定远程调用的语法,怎么传参数等
②传输协议问题 (RPCRuntime)指的是在网络发生错误、重传、丢包或者有性能问题时怎么办?
③服务发现问题 (插件比如:etcd)指的是如何知道服务端有哪些服务可以调用,从哪个端口访问?
rpc调用过程:
1、调用者(客户端Client)以本地调用的方式发起调用;
2、Client stub(客户端存根)收到调用后,负责将被调用的方法名、参数等打包编码成特定格式的能进行网络传输的消息体;
3、Client stub将消息体通过网络发送给服务端;
4、Server stub(服务端存根)收到通过网络接收到消息后按照相应格式进行拆包解码,获取方法名和参数;
5、Server stub根据方法名和参数进行本地调用;
6、被调用者(Server)本地调用执行后将结果返回给server stub;
7、Server stub将返回值打包编码成消息,并通过网络发送给客户端;
8、Client stub收到消息后,进行拆包解码,返回给Client;
9、Client得到本次RPC调用的最终结果。
gRPC 是一款高性能、开源的 RPC 框架,产自 Google,基于 ProtoBuf 序列化协议进行开发,支持多种语言。(ps: rpc是一种协议,grpc是基于rpc协议实现的一种框架)
grpc优点
- Protocol Buffers 压缩性高,速度快。
- HTTP 2.0 流传输。
- 支持多语言。
grpc缺点
- 可读性差。
- 对浏览器支持有限。
- 外部组件支持较差
ps :
- RPC主要用于公司内部的服务调用,性能消耗低,传输效率高,服务治理方便。
- HTTP主要用于对外的异构环境,浏览器接口调用,APP接口调用,第三方接口调用等。
实践2——异步化服务通信:RPC属于同步服务通信,若我们需要使用异步化的服务通信可以借助rocketmq或者kafka之类的消息中间件。
Kafka 是一个分布式流式处理平台。这到底是什么意思呢?
流平台具有三个关键功能:
1、消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
2、容错的持久方式存储记录消息流: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险·。
3、流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。Kafka 主要有两大应用场景:
消息队列 :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
数据处理: 构建实时的流数据处理程序来转换或处理数据流。
和其他消息队列相比,Kafka的优势在哪里?
1、极致的性能 :基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
2、生态系统兼容性无可匹敌 :Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
实践3——服务限流:在服务入口层面加上一个限流器。google的guava rateLimit就可以提供。 在高并发下一旦服务有问题或异常,将影响大批量流量、大量用户。 rateLimit是线程安全的,所以在并发环境中可以直接使用,无需额外的同步。每个URL使用各自的RateLimiter而不是公用一个,占用的内存也不大。
实际使用中,通常先使用tryAcquire()检测尝试获取许可证,如果可行再去执行请求; 否则,可以等待一段时间,知道许可证可用,或者适当拒绝。