开始用上一篇文章讲到的Spring依赖注入的步骤,用两个例子来推导一下整个过程,举例子有助于了解真相。
先用一个最简单的例子:没有依赖的单例bean的创建。
推导过程是需要上一篇文章的步骤的,要参照步骤一步一步来。
无依赖的单例Bean的创建
假设要创建单例bean A:
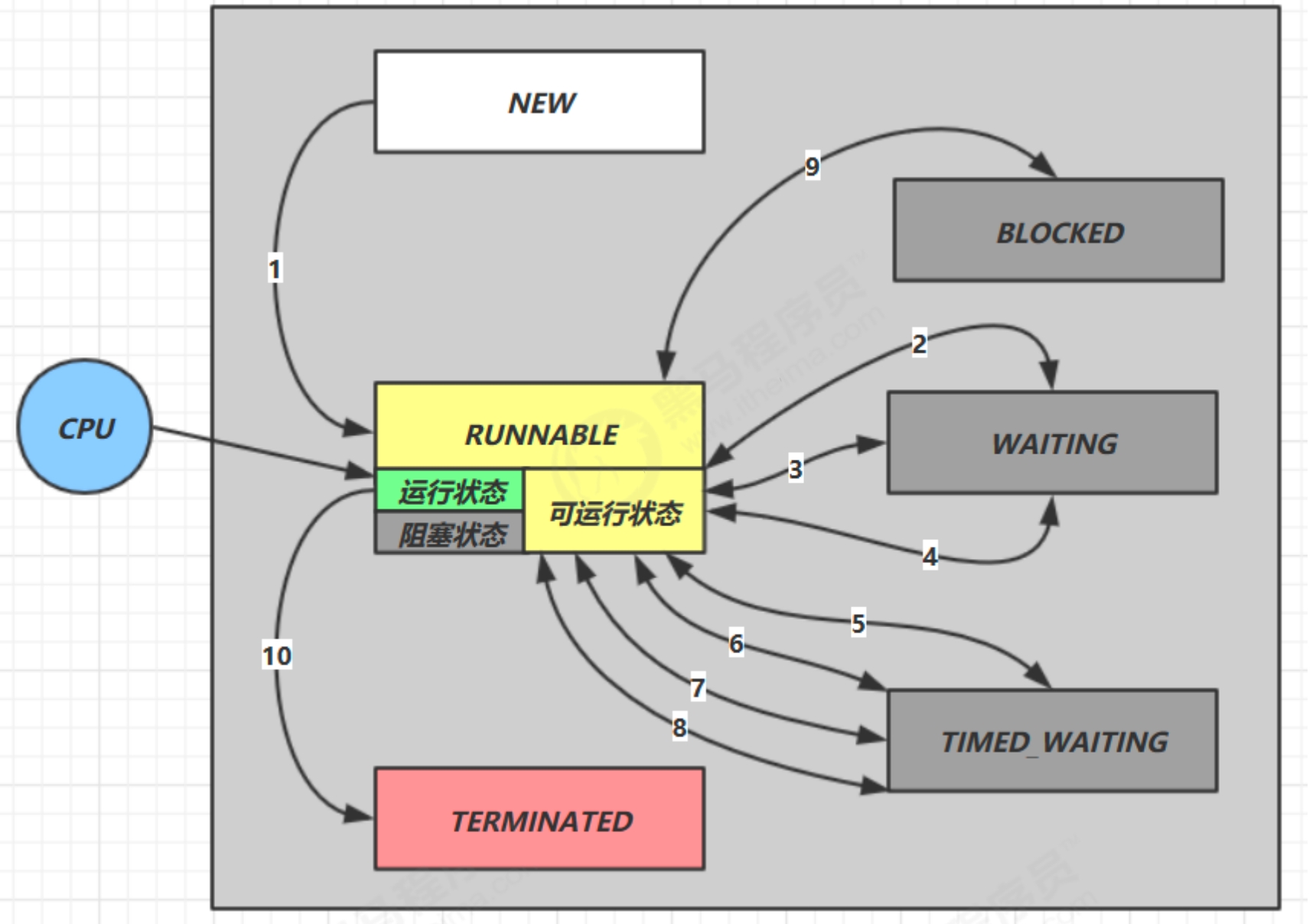
- 首先,getBean->deGetBean方法,调用getSingleton(beanName,true)方法。
- getSingleton(beanName,true)一次检查一级、二级、三级缓存,都没有A对象,返回null。
- 检查Dependon,假设没有设置,不需要创建DependOn对象。
- 调用getSingleton(beanName,factory)方法:检查一级缓存中不存在,将当前bean的name放入“正在创建中”列表,调用createBean创建bean。
- createBean创建A的实例,检查到当前bean在“正在创建中”列表中,则将当前bean放入三级缓存中。
- 调用populateBean进行属性填充,由于A对象没有依赖任何对象,所以不需要注入其他对象,直接完成属性填充。
- 调用返回到第4步getSingleton(beanName,factory)方法中,完成bean创建后,将当前bean name从“正在创建中”列表中移除。
- 将bean A从三级缓存、二级缓存中移除,放入一级缓存中。
- 完成bean A的创建。
循环依赖的单例Bean的创建过程
A依赖B,B依赖A,假设都是属性的互相依赖,即:
@Component
public class A {
@Autowired
private B b;
}
@Component
public class B {
@Autowired
private A a;
}
个人认为复杂的循环依赖都可以转化为我依赖你、你依赖我这种模式,所以我们还是试图把这个例子说的清楚明白一点,关键步骤用图示的方式说明。
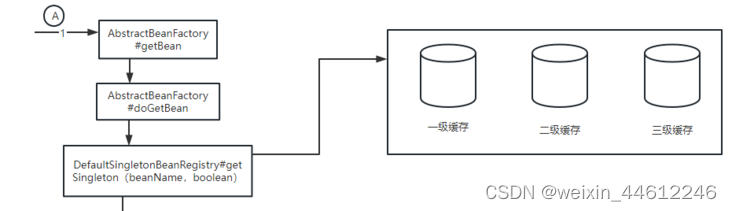
假设首先创建A实例。
-
执行到getSingleton(beanName,boolean)方法的时候,三个缓存都空:
-
然后,接着执行到doCreateBean的时候,会把A的工厂方法放入到三级缓存,如图:
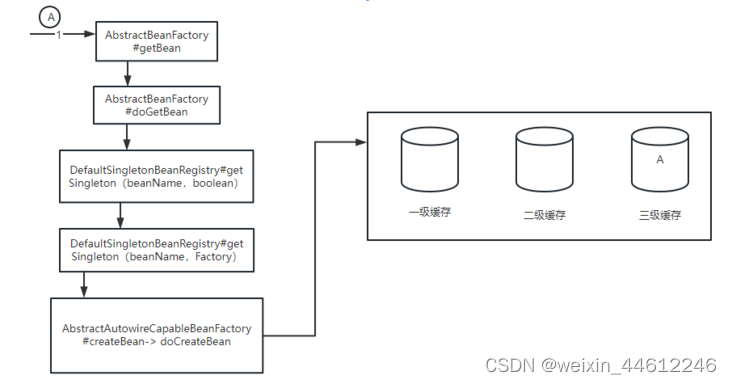
-
接下来就是populateBean方法,为bean A执行属性填充,查找到需要注入bean B,调用getBean,如图,用蓝色箭头表示,当执行到getSingleton(beanName,boolean)方法的时候,三个缓存中都没有bean B:
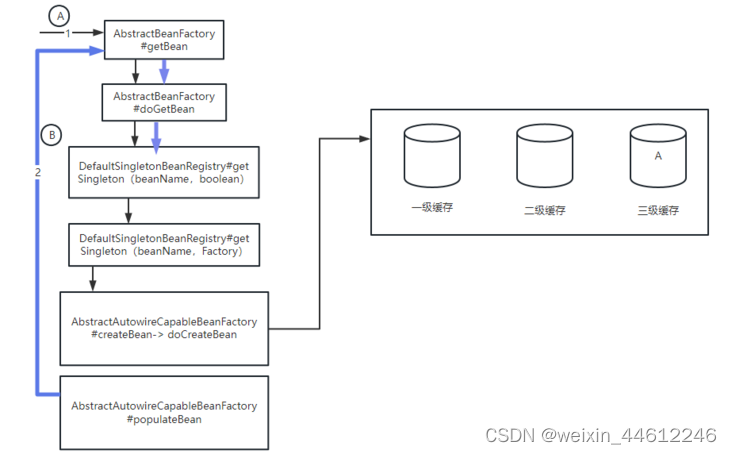
-
继续执行到doCreateBean的时候,会把B的工厂方法放入到三级缓存:
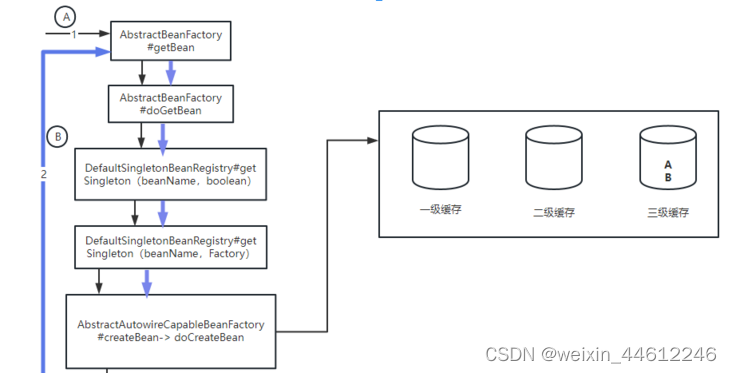
-
然后到populateBean方法,为bean B执行属性填充,查找到需要注入bean A。
-
调用getBean(A),如图,用红色箭头表示,当执行到getSingleton(beanName,boolean)方法的时候,三级缓存中存在bean A,所以,利用工厂方法创建A对象,放入二级缓存,返回bean A,并将A从三级缓存移除:
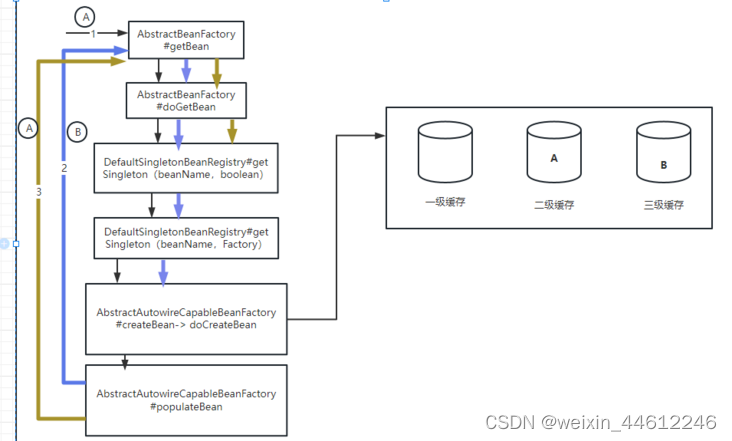
-
返回到步骤5,将bean A赋值给bean B的属性a,完成bean B的属性填充。之后返回到第4步,完成bean B的doCreateBean方法,将Bean B放入一级缓存,同时将Bean B从二级、三级缓存移除:
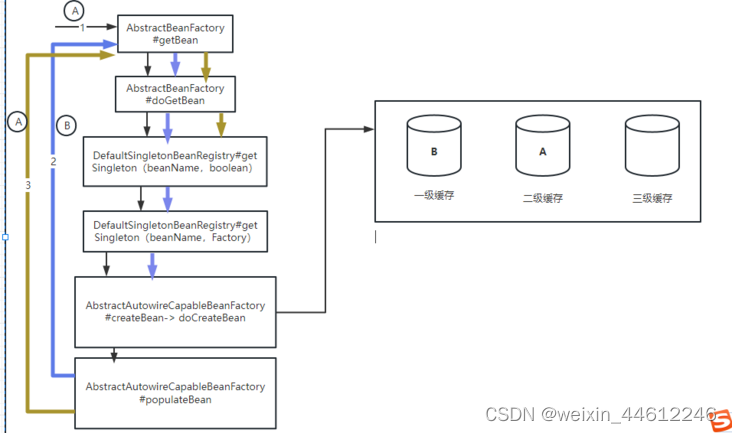
这一步完成之后,Bean B完成了创建,也完成了他的属性A的依赖注入,但是注入的Bean A是个半成品,还放在二级缓存中,尚未完成创建。
但是由于Bean A的创建流程还没有结束,所以不会有问题,接下来的步骤会完成Bean A的创建。
8. 流程返回到第3部,bean A的populateBean方法获取到了已经完成创建的bean B对象,完成Bean A的属性注入。
9. 之后继续执行bean A的doCreateBean的后续逻辑,完成Bean A的创建,将Bean A放入到一级缓存,并从二级、三级缓存移除:
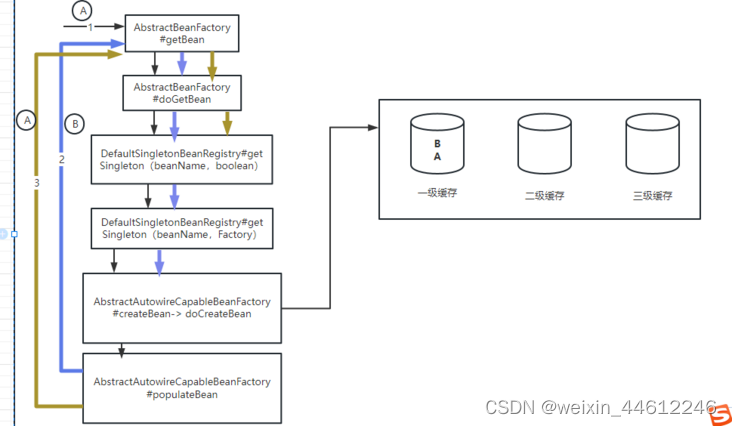
- 完成bean A和bean B的创建,完成A、B之间的依赖注入。
小结
用图解的方式说明Spring通过三级缓存解决依赖注入的过程。其实个人理解,对于更加复杂的依赖关系,注入过程无非就是在以上10个步骤之间不断递归调用的过程。
据说有一个问题是,Spring三级缓存的必要性,后面的文章会尝试回答这个问题。
上一篇 Spring FrameWork从入门到NB -三级缓存解决循环依赖内幕 (一)





![强化学习从基础到进阶-案例与实践[6]:演员-评论员算法(advantage actor-critic,A2C),异步A2C、与生成对抗网络的联系等详解](https://ai-studio-static-online.cdn.bcebos.com/818c1c2e603341f881dd57fb59e109c81702722156be4e6481b276b894c51290)