相关文章
数字IC前端学习笔记:LSFR(线性反馈移位寄存器)
数字IC前端学习笔记:跨时钟域信号同步
数字IC前端学习笔记:信号同步和边沿检测
数字IC前端学习笔记:锁存器Latch的综合
数字IC前端学习笔记:格雷码(含Verilog实现的二进制格雷码转换器)
数字IC前端学习笔记:FIFO的Verilog实现(一)
数字IC前端学习笔记:FIFO的Verilog实现(二)
数字IC前端学习笔记:仲裁轮询(一)
数字IC前端学习笔记:仲裁轮询(二)
数字IC前端学习笔记:仲裁轮询(三)
数字IC前端学习笔记:仲裁轮询(四)
7.带权重的轮询(第二部分)
上一部分中我们对仲裁的第一种方法的第一种许可方式进行了Verilog设计,接下来将使用Verilog对第一种方法的第二种许可方式进行设计,即当所有用户发出请求时,授权序列为
A,B,C,A,B,A B,C,A,B,A,A ......
以下是代码及仿真结果。
module arbiter_wrr_2(clk,resetb,
req_vec,
req_vec_wt_0,
req_vec_wt_1,
req_vec_wt_2,
req_n_valid,
end_access_vec,
gnt_vec);
input clk;
input resetb;
input [2:0] req_vec;
input [3:0] req_vec_wt_0;
input [3:0] req_vec_wt_1;
input [3:0] req_vec_wt_2;
input req_n_valid;
input [2:0] end_access_vec;
output [2:0] gnt_vec;
reg [2:0] arbiter_state, arbiter_state_nxt;
reg [2:0] gnt_vec, gnt_vec_nxt;
reg [3:0] count_req_vec [2:0];
reg [3:0] count_req_vec_nxt [2:0];
wire [2:0] cnt_reqdone_vec;
reg [2:0] relative_req_vec;
reg [1:0] grant_posn, grant_posn_nxt;
reg [2:0] relative_cntdone_vec;
reg [3:0] req_vec_wt_stored [2:0];
reg [3:0] req_vec_wt_stored_nxt [2:0];
wire [3:0] req_vec_wt [2:0];
parameter IDLE = 3'b001;
parameter ARM_VALUE = 3'b010;
parameter END_ACCESS = 3'b100;
assign req_vec_wt[0] = req_vec_wt_0;
assign req_vec_wt[1] = req_vec_wt_1;
assign req_vec_wt[2] = req_vec_wt_2;
always@(*) begin
relative_req_vec = req_vec;
relative_cntdone_vec = cnt_reqdone_vec;
case(grant_posn)
2'd0: begin relative_req_vec = {req_vec[0], req_vec[2:1]};
relative_cntdone_vec = {cnt_reqdone_vec[0],cnt_reqdone_vec[2:1]}; end
2'd1: begin relative_req_vec = {req_vec[1:0],req_vec[2]};
relative_cntdone_vec = {cnt_reqdone_vec[1:0],cnt_reqdone_vec[2]}; end
2'd2: begin relative_req_vec = {req_vec[2:0]};
relative_cntdone_vec = {cnt_reqdone_vec[2:0]}; end
endcase
end
always@(*) begin
arbiter_state_nxt = arbiter_state;
gnt_vec_nxt = gnt_vec;
count_req_vec_nxt[0] = count_req_vec[0];
count_req_vec_nxt[1] = count_req_vec[1];
count_req_vec_nxt[2] = count_req_vec[2];
grant_posn_nxt = grant_posn;
case(arbiter_state)
IDLE:begin
if(req_n_valid) begin
arbiter_state_nxt = ARM_VALUE;
count_req_vec_nxt[0] = req_vec_wt[0];
count_req_vec_nxt[1] = req_vec_wt[1];
count_req_vec_nxt[2] = req_vec_wt[2];
gnt_vec_nxt = 3'b0;
end
end
ARM_VALUE:begin
if((gnt_vec == 0) ||
(end_access_vec[0] & gnt_vec[0]) ||
(end_access_vec[1] & gnt_vec[1]) ||
(end_access_vec[2] & gnt_vec[2])) begin
if(relative_req_vec[0] & !relative_cntdone_vec[0]) begin
arbiter_state_nxt = END_ACCESS;
case(grant_posn)
2'd0:begin gnt_vec_nxt = 3'b010;
count_req_vec_nxt[1] = count_req_vec[1] - 1'b1;
grant_posn_nxt = 1; end
2'd1:begin gnt_vec_nxt = 3'b100;
count_req_vec_nxt[2] = count_req_vec[2] - 1'b1;
grant_posn_nxt = 2; end
2'd2:begin gnt_vec_nxt = 3'b001;
count_req_vec_nxt[0] = count_req_vec[0] - 1'b1;
grant_posn_nxt = 0; end
endcase
end
else if(relative_req_vec[1] & !relative_cntdone_vec[1]) begin
arbiter_state_nxt = END_ACCESS;
case(grant_posn)
2'd0:begin gnt_vec_nxt = 3'b100;
count_req_vec_nxt[2] = count_req_vec[2] - 1'b1;
grant_posn_nxt = 2; end
2'd1:begin gnt_vec_nxt = 3'b001;
count_req_vec_nxt[0] = count_req_vec[0] - 1'b1;
grant_posn_nxt = 0; end
2'd2:begin gnt_vec_nxt = 3'b010;
count_req_vec_nxt[1] = count_req_vec[1] - 1'b1;
grant_posn_nxt = 1; end
endcase
end
else if(relative_req_vec[2] & !relative_cntdone_vec[2]) begin
arbiter_state_nxt = END_ACCESS;
case(grant_posn)
2'd0:begin gnt_vec_nxt = 3'b001;
count_req_vec_nxt[0] = count_req_vec[0] - 1'b1;
grant_posn_nxt = 0; end
2'd1:begin gnt_vec_nxt = 3'b010;
count_req_vec_nxt[1] = count_req_vec[1] - 1'b1;
grant_posn_nxt = 1; end
2'd2:begin gnt_vec_nxt = 3'b100;
count_req_vec_nxt[2] = count_req_vec[2] - 1'b1;
grant_posn_nxt = 2; end
endcase
end
else begin
gnt_vec_nxt = 3'b0;
count_req_vec_nxt[0] = req_vec_wt_stored[0];
count_req_vec_nxt[1] = req_vec_wt_stored[1];
count_req_vec_nxt[2] = req_vec_wt_stored[2];
end
end
end
END_ACCESS:begin
if((end_access_vec[0] & gnt_vec[0]) ||
(end_access_vec[1] & gnt_vec[1]) ||
(end_access_vec[2] & gnt_vec[2])) begin
arbiter_state_nxt = ARM_VALUE;
if(relative_req_vec[0] & !relative_cntdone_vec[0]) begin
case(grant_posn)
2'd0:begin gnt_vec_nxt = 3'b010;
count_req_vec_nxt[1] = count_req_vec[1] - 1'b1;
grant_posn_nxt = 1; end
2'd1:begin gnt_vec_nxt = 3'b100;
count_req_vec_nxt[2] = count_req_vec[2] - 1'b1;
grant_posn_nxt = 2; end
2'd2:begin gnt_vec_nxt = 3'b001;
count_req_vec_nxt[0] = count_req_vec[0] - 1'b1;
grant_posn_nxt = 0; end
endcase
end
else if(relative_req_vec[1] & !relative_cntdone_vec[1]) begin
case(grant_posn)
2'd0:begin gnt_vec_nxt = 3'b100;
count_req_vec_nxt[2] = count_req_vec[2] - 1'b1;
grant_posn_nxt = 2; end
2'd1:begin gnt_vec_nxt = 3'b001;
count_req_vec_nxt[0] = count_req_vec[0] - 1'b1;
grant_posn_nxt = 0; end
2'd2:begin gnt_vec_nxt = 3'b010;
count_req_vec_nxt[1] = count_req_vec[1] - 1'b1;
grant_posn_nxt = 1; end
endcase
end
else if(relative_req_vec[2] & !relative_cntdone_vec[2]) begin
case(grant_posn)
2'd0:begin gnt_vec_nxt = 3'b001;
count_req_vec_nxt[0] = count_req_vec[0] - 1'b1;
grant_posn_nxt = 0; end
2'd1:begin gnt_vec_nxt = 3'b010;
count_req_vec_nxt[1] = count_req_vec[1] - 1'b1;
grant_posn_nxt = 1; end
2'd2:begin gnt_vec_nxt = 3'b100;
count_req_vec_nxt[2] = count_req_vec[2] - 1'b1;
grant_posn_nxt = 2; end
endcase
end
else begin
gnt_vec_nxt = 3'b0;
count_req_vec_nxt[0] = req_vec_wt_stored[0];
count_req_vec_nxt[1] = req_vec_wt_stored[1];
count_req_vec_nxt[2] = req_vec_wt_stored[2];
end
end
end
endcase
end
assign cnt_reqdone_vec[0] = (count_req_vec[0] == 0);
assign cnt_reqdone_vec[1] = (count_req_vec[1] == 0);
assign cnt_reqdone_vec[2] = (count_req_vec[2] == 0);
always@(posedge clk, negedge resetb) begin
if(!resetb) begin
arbiter_state <= IDLE;
gnt_vec <= 0;
count_req_vec[0] <= 0;
count_req_vec[1] <= 0;
count_req_vec[2] <= 0;
req_vec_wt_stored[0] <= 0;
req_vec_wt_stored[1] <= 0;
req_vec_wt_stored[2] <= 0;
grant_posn <= 2;
end
else begin
arbiter_state <= arbiter_state_nxt;
gnt_vec <= gnt_vec_nxt;
count_req_vec[0] <= count_req_vec_nxt[0];
count_req_vec[1] <= count_req_vec_nxt[1];
count_req_vec[2] <= count_req_vec_nxt[2];
req_vec_wt_stored[0] <= req_vec_wt_stored_nxt[0];
req_vec_wt_stored[1] <= req_vec_wt_stored_nxt[1];
req_vec_wt_stored[2] <= req_vec_wt_stored_nxt[2];
grant_posn <= grant_posn_nxt;
end
end
endmodule代码中使用了和公平轮询类似的代码,不过此时还使用了relative_cntdone_vec信号来保存各个用户的剩余请求次数,注意:一旦出现了空档期,则所有用户的剩余请求次数会重置。
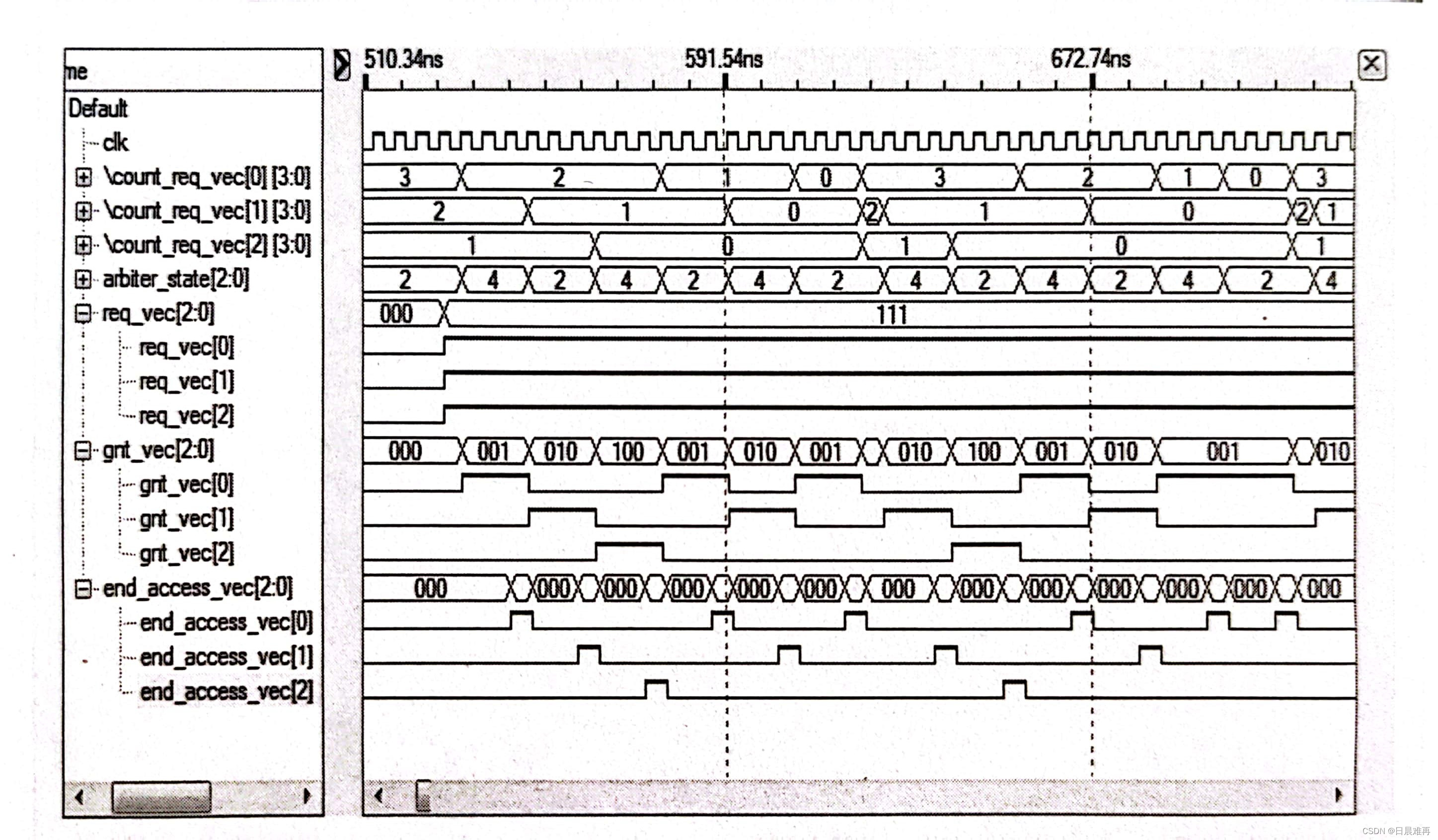
以上内容来源于《Verilog高级数字系统设计技术和实例分析》