作者:~小明学编程
文章专栏:Java数据结构
格言:目之所及皆为回忆,心之所想皆为过往

目录
前言
常量字段
构造方法
put方法
确定初始容量
为何我们的数组的大小要是2的n次幂
hash为何要异或其高位
扩容机制
前言
我们在前面的文章中已经简单的介绍了我们的哈希表,其基本的工作原理是什么我们已经讲述了,并且我们还简单了实现了哈希表,但是我们Java中的HashMap是怎么实现并且它的实现过程是怎么样的呢?今天我们就通过对源码的解析来深入的探讨下面三个问题。
1.如果我们new HashMap(19),那么我们的bucket数组有多大?
2.HashMap什么时候开辟bucket数组占用内存?
3.HashMap何时扩容?
常量字段
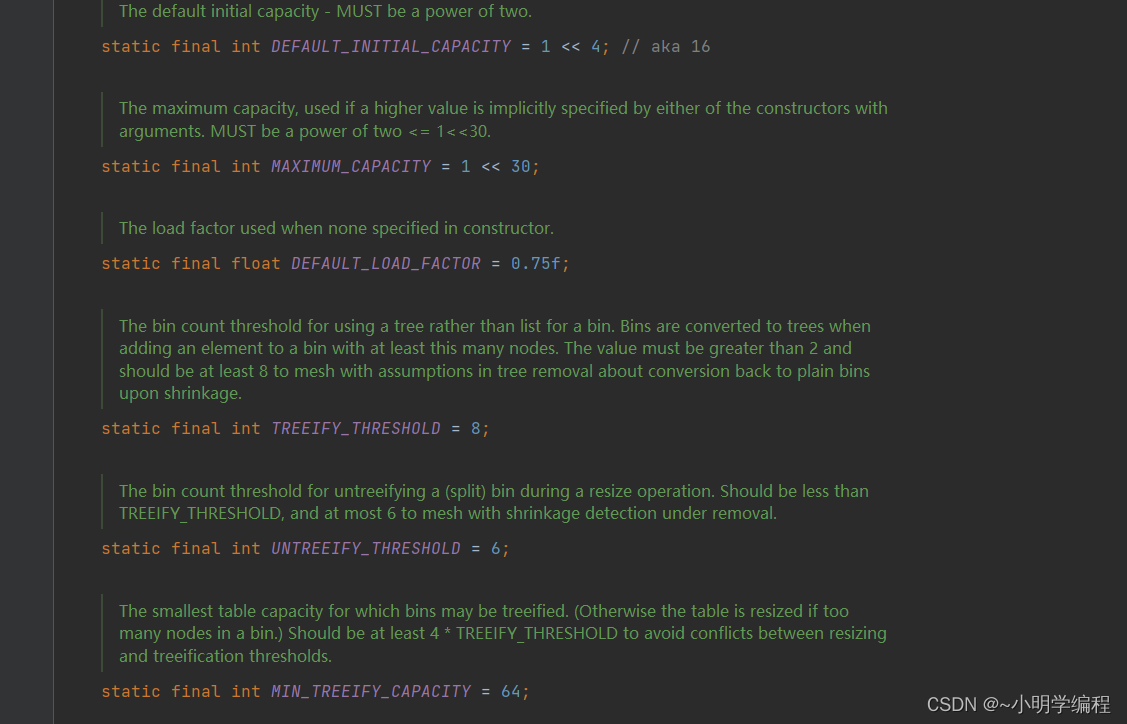
首先先给大家介绍一下这几个常量所表示的含义是什么。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
默认的初始容量,意思就是我们的HashMap的底层数组bucket的数组的默认容量的大小是16。
static final int MAXIMUM_CAPACITY = 1 << 30;
数组所能扩容的最大容量,当我们的底层数组的大小超过这个数值的时候我们将不再进行扩容。
static final float DEFAULT_LOAD_FACTOR = 0.75f;我们默认的负载因子的大小。
static final int TREEIFY_THRESHOLD = 8;
static final int MIN_TREEIFY_CAPACITY = 64;
树化的条件,当我们hash值所对应的那条链表的长度超过8,并且数组的总长度超过64的时候我们的链表将转化为红黑树。
static final int UNTREEIFY_THRESHOLD = 6;
链表化的条件,当我们扩容数组之后需要重新hash,当我们发现当前红黑树的大小小于6的时候,我们的红黑树就会重新变成链表。
构造方法
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}我们可以看到我们的构造方法进行了重载,所以当我们不传参数,传入一个参数,传两个参数都将调用不同的方法。
当我们不传参数的时候,我们的构造方法将会初始化我们的负载因子为我们的默认值0.75,传入一个参数的话也就是我们初始的容量,这时将会调用我们含有两个参数的构造方法,我们看到我们两个参数的构造方法首先是进行一些异常处理然后给我们的负载因子loadFactor赋值,再然后就是通过tableSizeFor这样的方法返回一个是2的次幂并且大于我们传入的参数的值将其赋给threshold,这个值在后面将会作为确定我们开辟的数组多大的值,这也回答了我们的问题
如果我们new HashMap(19),那么我们的bucket数组有多大?
我们的bucket的大小为32。
put方法
put方法中有我们想要的东西,想要解开后面的两个问题就得去put里面去寻找答案。
确定初始容量

我们的put方法里面返回的是一个putVal方法,下面我们就进到putVal里面去一探究竟吧。
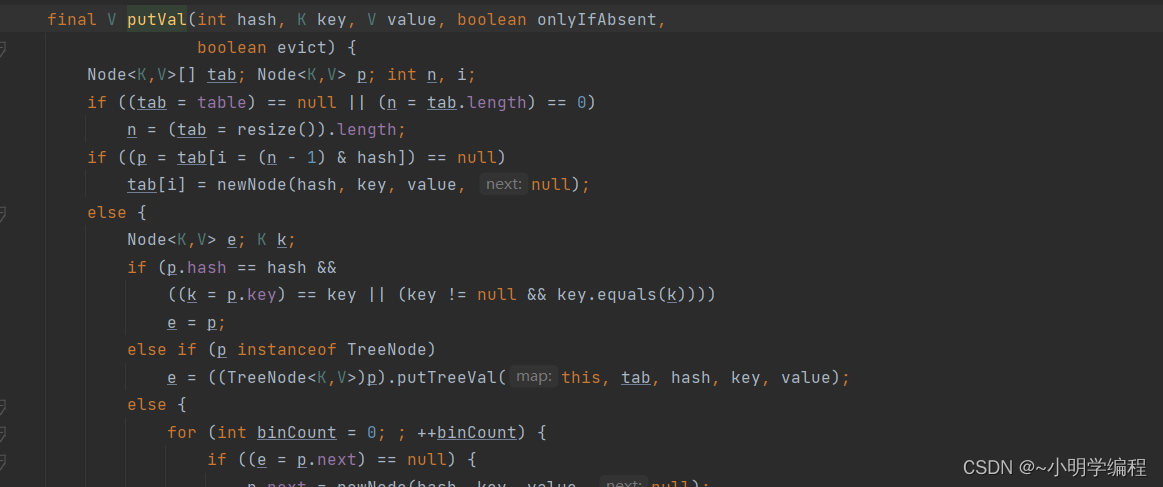
从前向后看首先因为我们没有传入初始的容量的话我们将会进入第一个if语句,然后我们将会进行扩容进入我们的resize()方法当中。

最后找到我们这段代码:
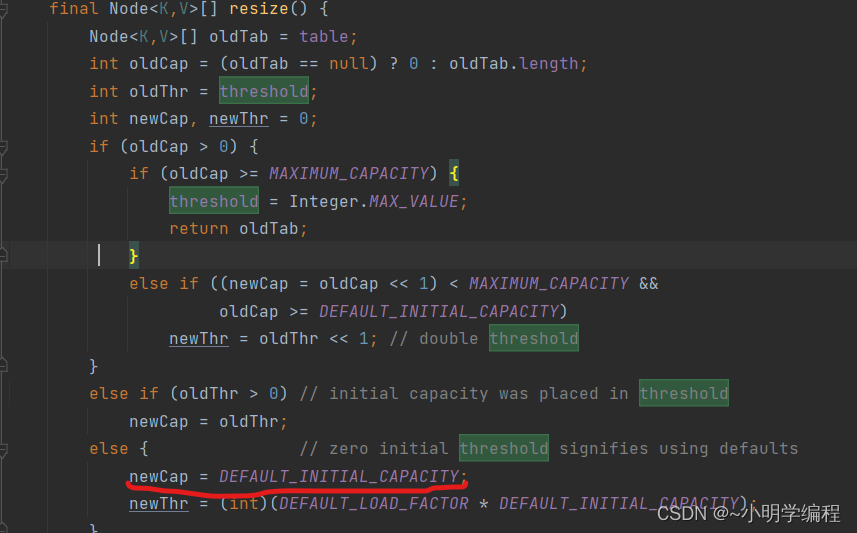 得到我们的新的容量为默认容量16.
得到我们的新的容量为默认容量16.
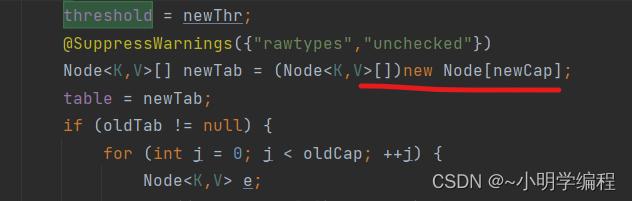
这里开始扩容了,所以综上所述得出我么的HashMap在第一次进行put操作的时候给我们的bucket数组占用空间。
为何我们的数组的大小要是2的n次幂
前面我们在说数组容量大小的时候要是2的n次幂,但是我们为什么要有这个要求呢?
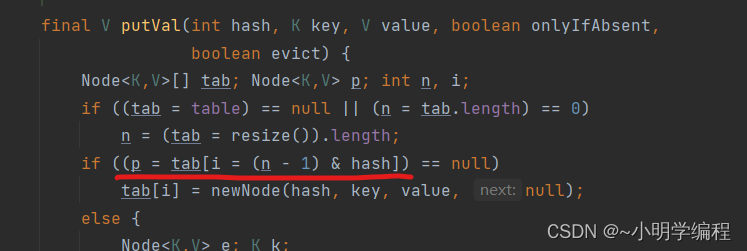
我么把视线再次调回到putVal这个方法中,这里我们的p是我们的链表首节点的地址,它的得出来源于 tab[i = (n - 1) & hash], (n - 1) & hash就是算出我们的数组下标,n是我们的数组长度是个偶数,(n - 1) & hash就相当于hash%n但是我们不这样写因为:
1.我们的&运算符的效率相比%要快。
2.n-1肯定是个奇数所以二进制的最低为肯定为1,比如15的二进制1111,这个时候如果&我们的hash最低位可能是1也可能是0,但是如果我们n不是偶数的话,n-1可能为偶数那么最低值就是0这时候进行&运算的话最低位绝对为0,这时我们看到我们n-1的有效位一共才4为你这一下子就确定了一位,明显降低了我们的随机性,增大了碰撞的概率。
hash为何要异或其高位
现在我们再次把视线往前拨,

拨到我们hash的产生,

当我们的key不为空的时候我们原本的hash要异或上hash的右移16位,16位刚好是我们int32字节的前半部分,因为我们的数组容量一般不会要用到我们32个比特位的高16位(65535以上的长度了),一般都是后16位,如此一来高16位基本用不上了,这是我们不想看到的,我们就想怎么能在低16位中同时也能体现出我们高16位的特征呢?
所以我们就想到将hash右移16位再去异或原本的hash,这样我们的的低位也能体现出我们高位的特征,再一次增强了随机性。
扩容机制
我们的实现调回到putVal,先去判断一下我们的p是不是树节点是的话就在树里面添加元素,然后循环判断我们当前链表的节点树是否大于等于7是的话我们将对其树化,

最后我们看看当前节点是否大于容量,是的话就扩容,
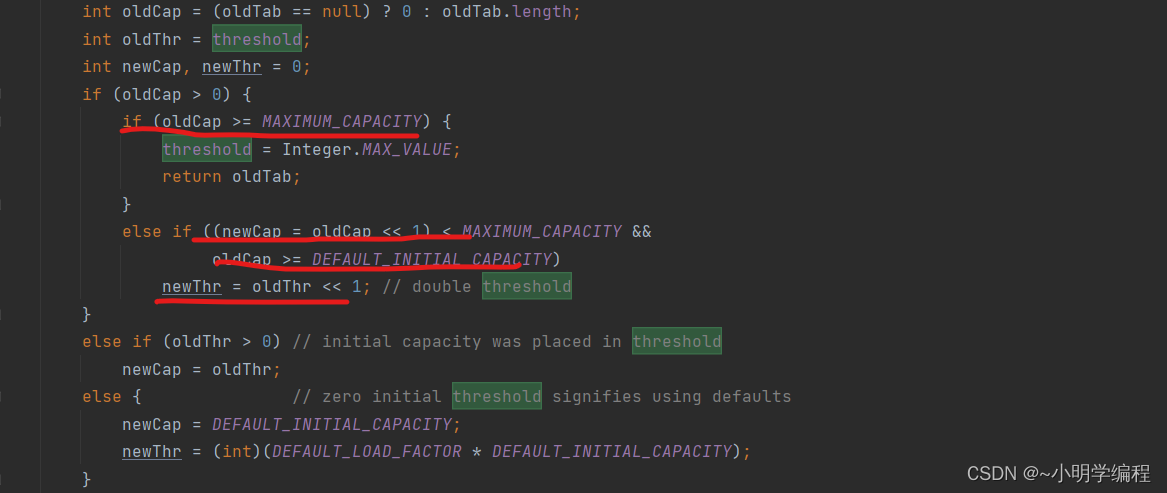
我们大致看一下扩容的情况,首先看一下是判断一个最大容量的问题,然后就是扩容之后是否大于最大容量,其中扩容的时候是左移两位,也就是扩大二倍,同时也解惑了最后一个问题,HashMap何时扩容,答案是超过负载因子的时候扩容。