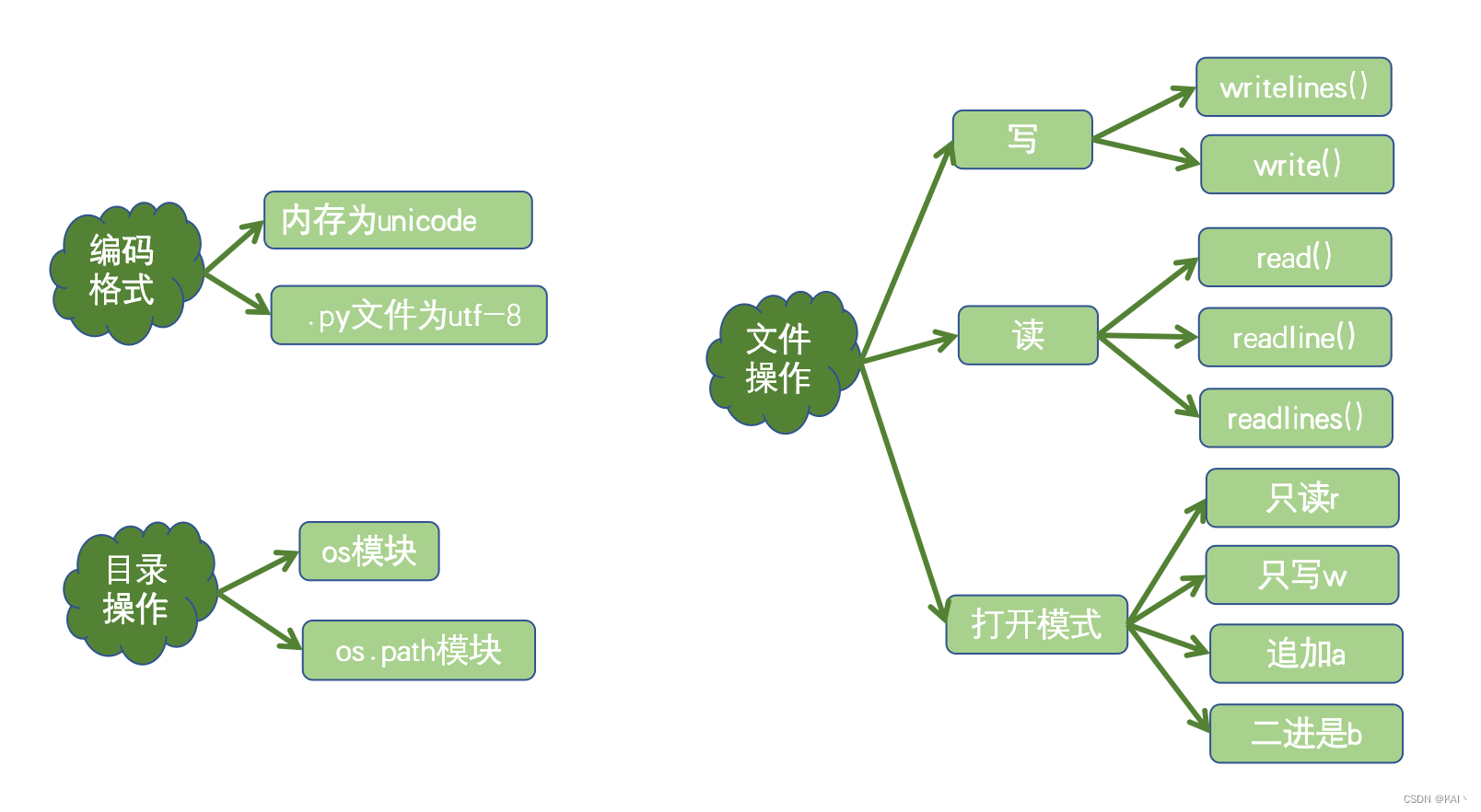
文件操作
编码格式
python3默认的文件编码就是UTF-8
以下内容来源于AI
编码格式是指将字符、符号、数字等信息转化为二进制形式以便计算机能够理解和处理的规则或标准。在计算机领域,常见的编码格式有 ASCII、Unicode、UTF-8 等。
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码):ASCII 是最早的字符编码标准,它使用 7 位二进制数(共 128 个编码)来表示字符。其中,0-31 的编码用于表示控制字符(如换行符、回车符等),32-127 的编码用于表示可显示的字符(包括字母、数字、标点符号等)。ASCII 编码只适用于英语等使用拉丁字母的语言,不支持非拉丁字母和特殊字符。
- Unicode(统一码):Unicode 是一种用于表示字符的国际标准编码。它包含了几乎所有的字符集,涵盖了世界上大多数语言所使用的字符。Unicode 分为不同的编码方案,其中最常用的是 UTF-8、UTF-16 和 UTF-32。
- UTF-8(Unicode Transformation Format-8):UTF-8 是一种可变长度的编码方式,它使用 8 位、16 位或 32 位的编码单元来表示字符。UTF-8 兼容 ASCII 编码,即 ASCII 字符使用单个字节表示,而非 ASCII 字符使用多个字节表示。UTF-8 采用变长编码的方式,使用 1-4 个字节来表示不同范围的字符,使得它能够有效地表示任意 Unicode 字符,并且在存储和传输时占用较少的空间。
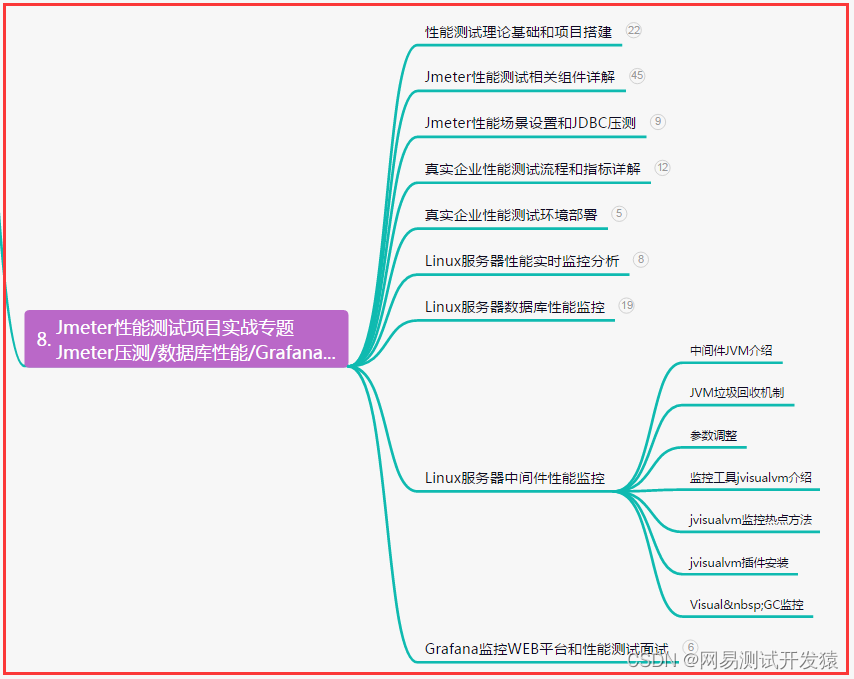
- UTF-16(Unicode Transformation Format-16):UTF-16 采用 16 位的编码单元来表示字符,可以表示 Unicode 字符的所有范围。对于 ASCII 字符和部分非 ASCII 字符,UTF-16 使用 16 位编码单元表示,而对于较大范围的字符,它使用两个 16 位编码单元来表示。UTF-16 分为大端序(Big-Endian)和小端序(Little-Endian)两种方式。
- UTF-32(Unicode Transformation Format-32):UTF-32 使用 32 位的编码单元表示字符,无论是 ASCII 字符还是非 ASCII 字符,都使用相同长度的编码单元。UTF-32 的主要优点是每个字符都占用相同的空间,便于处理和索引,但相对于 UTF-8 和 UTF-16,它会占用更多的存储空间。
编码格式在文本处理、网络通信、数据库存储等方面都起着重要的作用。选择适当的编码格式可以确保字符在不同系统之间的正确传输和显示。在实际应用中,常常使用 UTF-8 编码,因为它既能表示全球范围内的字符,又具有较好的兼容性和节省空间的特点。
他们之间有什么关系吗?
这些编码格式之间存在一定的关系和演变过程。下面是它们之间的一些关系:
- ASCII 是最早的字符编码标准,定义了常用英语字符和控制字符的编码。后来的 Unicode 和 UTF-8 编码都是在 ASCII 的基础上进行扩展和改进的。
- Unicode 是一个字符集,包含了几乎所有语言中的字符,旨在统一全球范围内的字符表示。Unicode 定义了每个字符的唯一标识符(Code Point),但没有规定如何将这些标识符转化为二进制形式存储和传输。
- UTF-8、UTF-16 和 UTF-32 是 Unicode 的具体实现方式,它们定义了如何将 Unicode 字符编码为二进制形式,并且规定了字符在存储和传输时所占用的字节数。
- UTF-8 是一种可变长度的编码方式,它兼容 ASCII 编码,使用 1-4 个字节来表示字符。UTF-8 在存储和传输时具有节省空间的优势,因此被广泛应用于互联网和计算机系统中。
- UTF-16 使用 16 位编码单元来表示字符,可以表示 Unicode 字符的所有范围。它有两种编码方式:大端序(Big-Endian)和小端序(Little-Endian)。
- UTF-32 使用 32 位编码单元来表示字符,每个字符都占用相同的空间,便于处理和索引。UTF-32 在某些特定场景下使用,但相对于 UTF-8 和 UTF-16,它会占用更多的存储空间。
总结起来,ASCII 是最早的字符编码标准,Unicode 定义了字符的唯一标识符,而 UTF-8、UTF-16 和 UTF-32 则是 Unicode 的具体实现方式,定义了字符的二进制编码形式和存储规则。UTF-8 是最常用的编码方式之一,具有广泛的应用。
读写原理
略
读写文件
# 读写文件
def readFile(filePath):
f = open(filePath, 'r')
readlines = f.readlines()
print(readlines)
for i in readlines:
print(i.replace("\n", ''))
f.close()
# 读写文件
def readFile2(filePath):
f = open(filePath, 'r')
readlines = f.readlines()
print(readlines)
# 此时文件指针已经到达行尾,所以这么写无法读取到内容
print(f.read())
# 把文件指针移动到文档首
f.seek(0)
print(f.read())
f.close()
# 写文件
def wirteFile(filePath):
# 会覆盖原有内容
f = open(filePath, 'w')
f.writelines("你好")
f.close()
# 写文件
def wirteAppendFile(filePath):
# 追加文件内容
f = open(filePath, 'a')
# 如何换行追加
f.write("你好++")
f.close()
# 拷贝文件
def copyFile(srcPath, toPath):
srcfile = open(srcPath, "rb")
tofile = open(toPath, "wb")
tofile.write(srcfile.read())
srcfile.close()
tofile.close()
pass
# with语法
def testWith(srcPath):
with open(srcPath, 'r') as f:
print(f.read())
if __name__ == '__main__':
readFile2("1.txt")
testWith("1.txt")
# wirteFile("2.txt")
# wirteAppendFile("2.txt")
# copyFile("/Users/kw/Documents/python.png", "/Users/kw/Documents/python2.png")
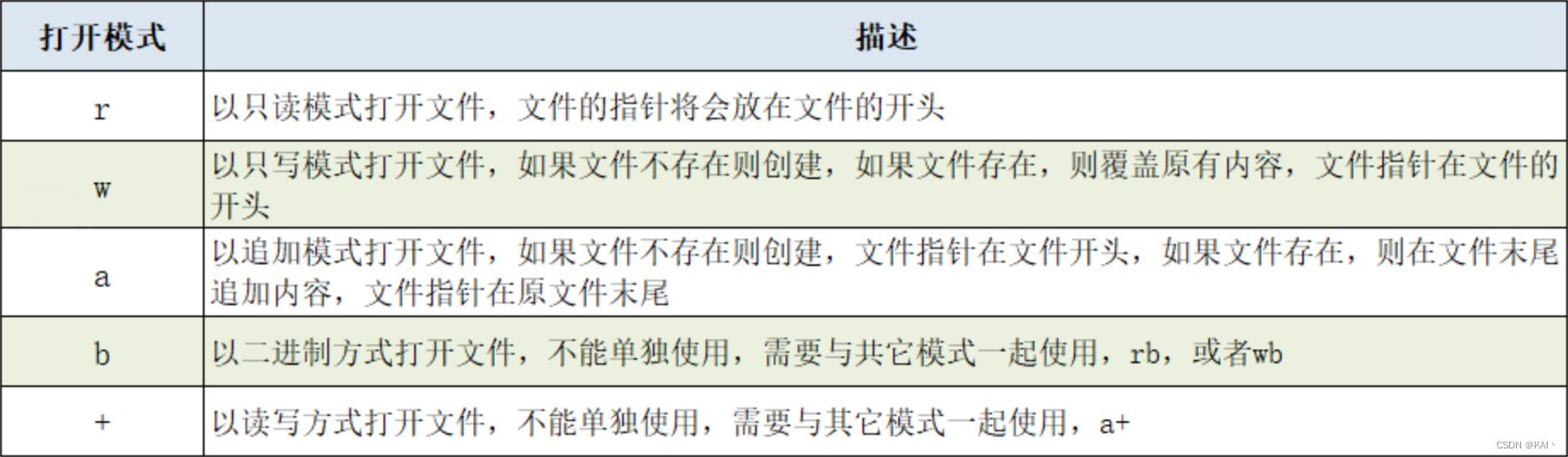
常用的文件打开模式
文件的类型
- 按文件中数据的组织形式,文件分为以下两大类文本文件 :
- 存储的是普通“字符”文本,默认为unicode字符集,可以使用记本事程序打开
- 二进制文件:把数据内容用“字节”进行存储,无法用记事本打开,必须使用专用的软件打开 ,举例:mp3音频文件,jpg图片 .doc文档等
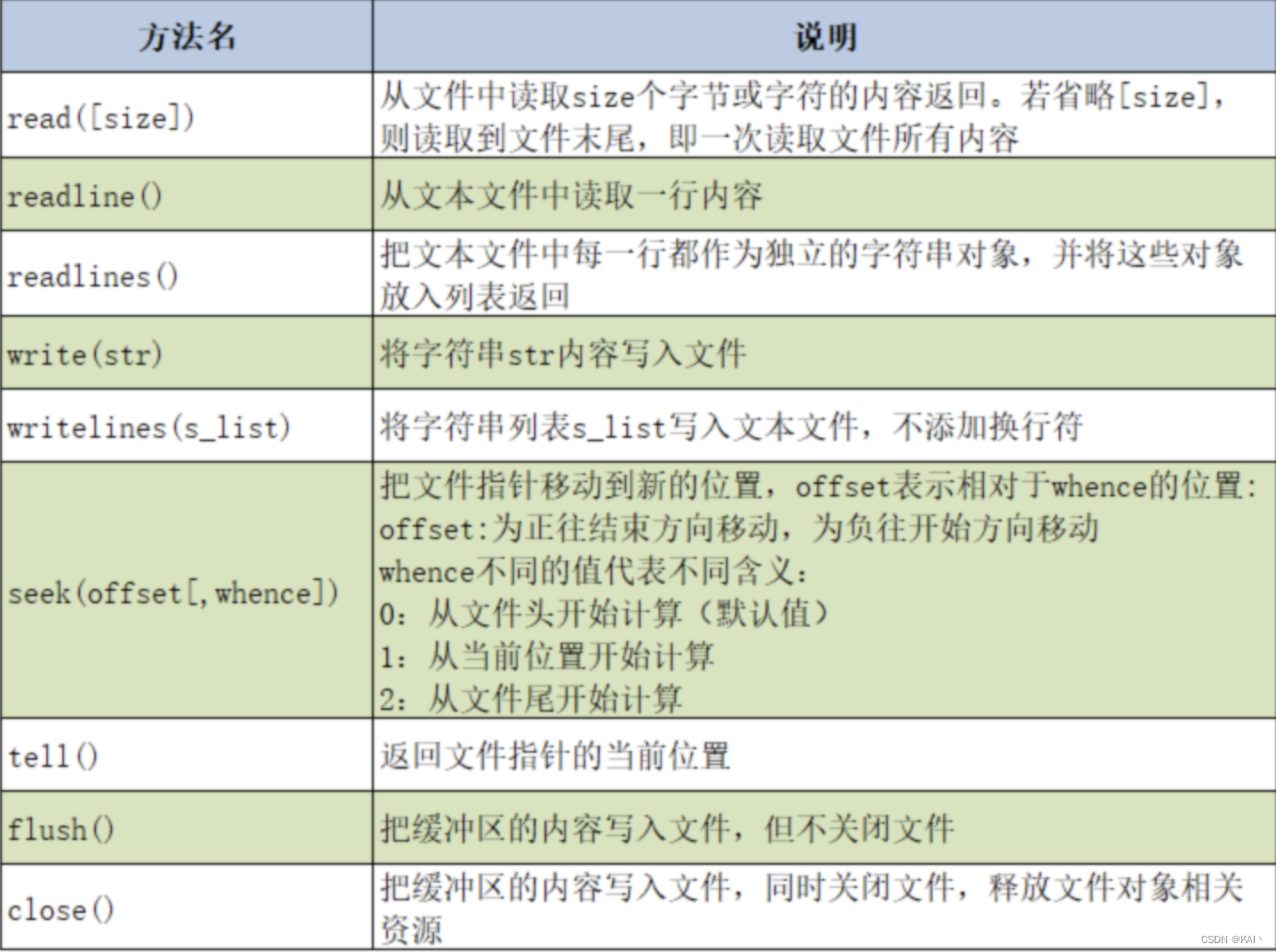
文件对象的常用方法
with语句
基本语法
上下文管理器
with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,以此来达到释放资源的目的
功能类似java中的try-with-reources语句
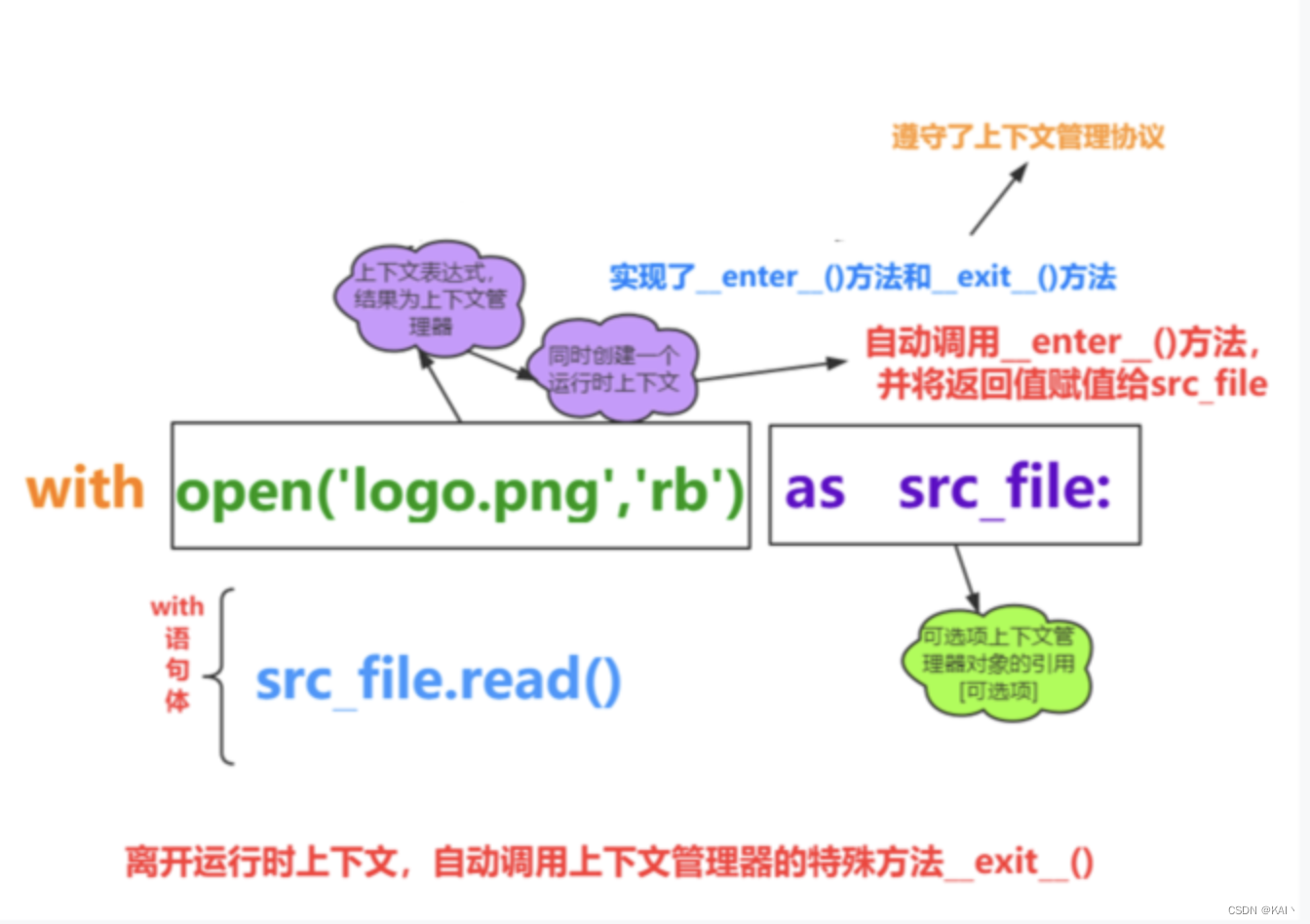
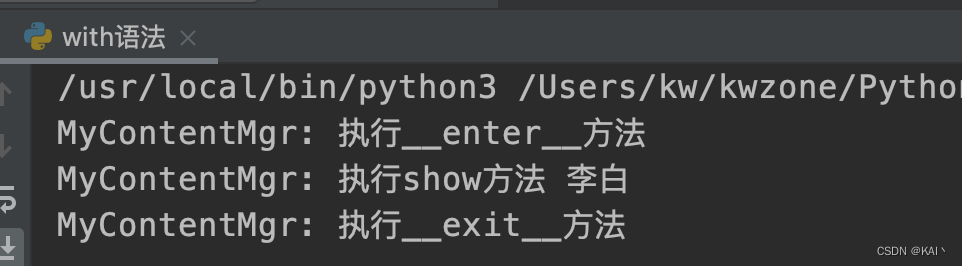
示例
class MyContentMgr(object):
name = '李白'
def __enter__(self):
print("MyContentMgr: 执行__enter__方法")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("MyContentMgr: 执行__exit__方法")
def show(self):
print("MyContentMgr: 执行show方法", self.name)
with MyContentMgr() as mgr:
mgr.show()
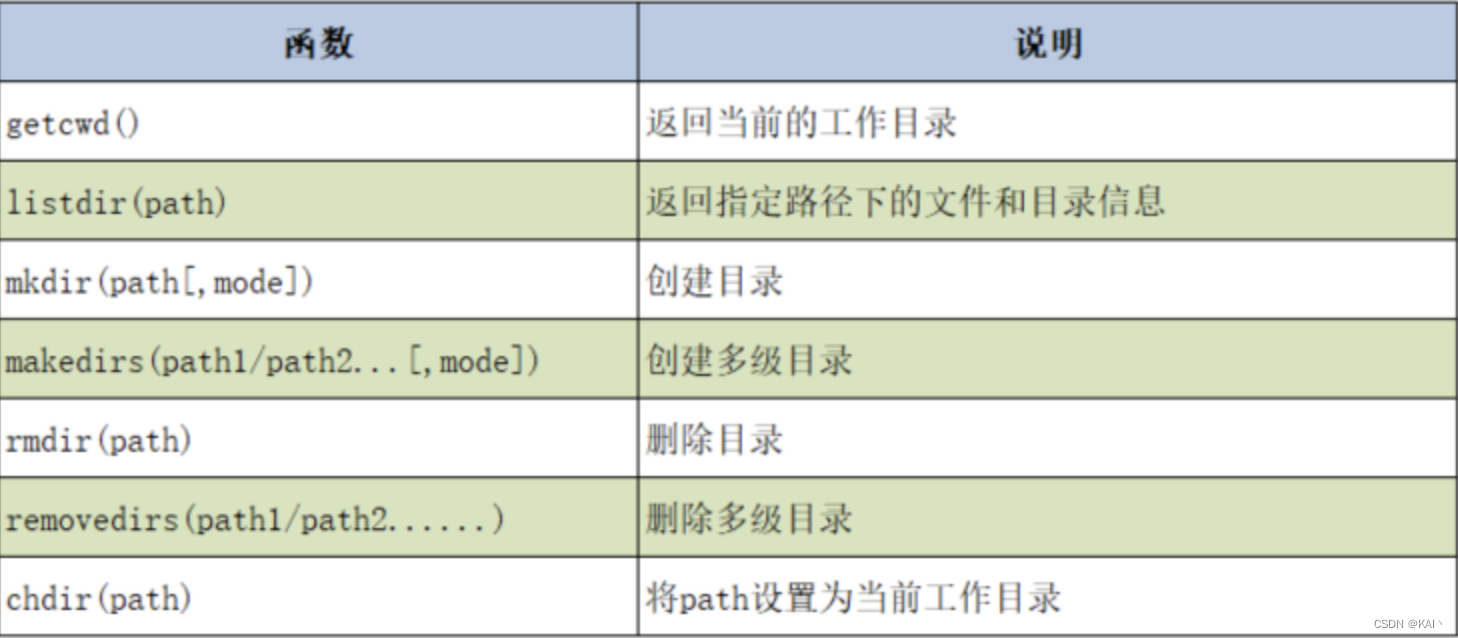
os模块
-
os模块是Python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样。
-
os模块与os.path模块用于对目录或文件进行操作
os常用函数
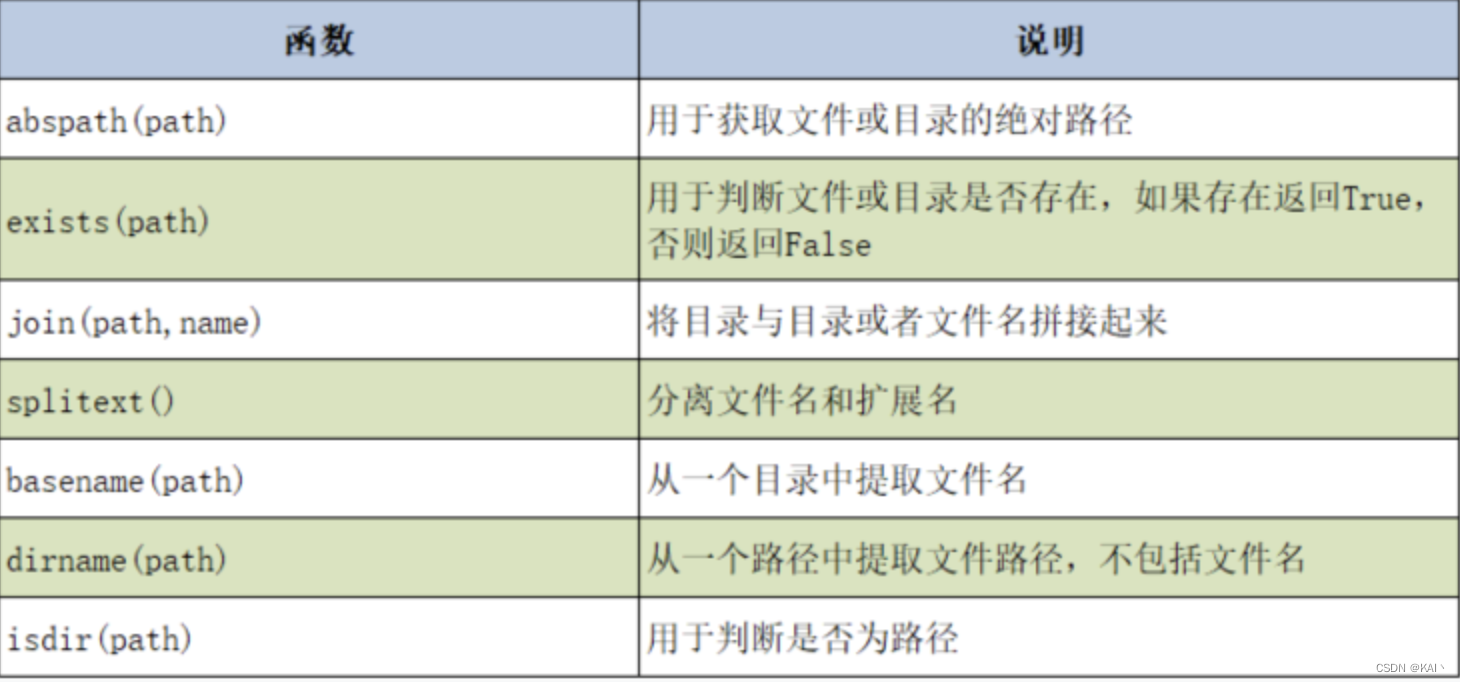
os.path常用函数