人工智能--AI贪吃蛇,每一个代码都有详细的注释,希望多多收藏,点赞,评论
- 1.前言:训练ai玩游戏的可行性
- 2.代码实现思路:
- 3.代码完整实现
- 3.1 Game Game.py 完整实现
- 3.1.1 安装pygame库
- 3.1.2 编写游戏逻辑代码
- 3.2 神经网络 network.py 完整实现
- 3.2.1 安装tensorflow库
- 3.2.2 network.py 代码
- 3.3 训练AI GameAI.py 完整实现
- 3.3.1 GameAI.py完整代码
- 4.开始训练
- 阶段一:前期吃到几个食物,得到较为少的吃食物的策略
- 阶段二:几轮下来,得到一条比较优化的吃食物的路径
- 阶段三:碰撞惩罚几轮下来,会避开自己的身体
- 最终阶段:一天调下来,最好的一次
最近刷知乎看到了一个训练贪吃蛇的视频,自己也想实现一下(正好完成人工智能最后的大作业)。
在网上搜索了好久,也没看见一个完整的代码,只能靠自己了,
所以,冻手,冻手...........
1.前言:训练ai玩游戏的可行性
首先,先去了解了一下其实现的原理:
训练AI玩游戏的原理是通过机器学习算法和大量的数据来构建一个智能体,并通过这个智能体与游戏环境的交互来不断提升其能力。通常采用的方法是强化学习,即让AI与游戏环境进行互动,通过给予奖励和惩罚的方式,让AI不断学习游戏规则和技能,并逐渐提升它在游戏中的表现。
机器学习我学过,但是出现了一个新的词汇“强化学习”,,嗯,,,,再去了解。
漫长的So和科普视频之后:
我的总结:
简单画一下实现原理:

利用本文要实现的例子,解释强化学习流程就是:
在AI贪吃蛇中,状态机制可以根据当前游戏状态来定义AI玩家的行为规则,例如在没有食物的情况下,AI玩家会随机移动,一旦发现食物,就会向食物移动。强化学习则通过奖惩机制来调整AI玩家的行为,例如吃到食物得到正数奖励,碰到自己身体或墙壁则得到负数惩罚。通过这种方式,AI玩家可以逐渐学习到在游戏中的最佳行为,并提高游戏表现水平。
2.代码实现思路:

3.代码完整实现
3.1 Game Game.py 完整实现
代码结构:
class Snake:
def __init__(self)
# 初始化蛇的属性。
pass
def get_head_position(self)
# 获取蛇头的位置。
pass
def turn(self, point)
# 改变蛇的移动方向。
pass
def move(self)
# 移动蛇的位置。
pass
def reset(self)
# 重新开始游戏。
pass
def draw(self, surface)
# 在窗口上绘制蛇。
pass
class Food:
def __init__(self):
# 初始化食物的属性。
pass
def get_position(self):
# 获取食物的位置。
pass
def draw(self, surface):
# 在窗口上绘制食物。
pass
3.1.1 安装pygame库
在命令行下输入以下命令:
pip install pygame
3.1.2 编写游戏逻辑代码
import pygame
import sys
import random
# 定义常量
SCREEN_WIDTH = 800
SCREEN_HEIGHT = 600
POP_SIZE = 10
BLOCK_SIZE = 20
# 定义颜色
BLACK = (0, 0, 0)
WHITE = (255, 255, 255)
GREEN = (0, 255, 0)
RED = (255, 0, 0)
class Snake:
# 初始化()
# 初始化蛇的长度(length),蛇的位置(positions),蛇的移动方向(direction),蛇的颜色(color = Green)
def __init__(self):
self.length = 3
self.positions = [(SCREEN_WIDTH / 2, SCREEN_HEIGHT / 2)]
self.direction = random.choice([(0, 1), (0, -1), (1, 0), (-1, 0)])
self.color = GREEN
# 获得蛇头的坐标()
def get_head_position(self):
return self.positions[0]
# 改变蛇移动方向(point:改变方向)
# 如果改变的方向和蛇的原方向相反,则蛇的方向不改变
# 否则,改变蛇的移动方向
def turn(self, point):
if (point[0] * -1, point[1] * -1) == self.direction:
return
else:
self.direction = point
# 移动()
# 根据当前方向计算下一个位置
def move(self):
cur = self.get_head_position()
x, y = self.direction
new = ((cur[0] + (x * BLOCK_SIZE)) % SCREEN_WIDTH, (cur[1] + (y * BLOCK_SIZE)) % SCREEN_HEIGHT)
self.positions.insert(0, new)
if len(self.positions) > self.length:
self.positions.pop()
# 重新开始()
def reset(self):
self.length = 3
self.positions = [(SCREEN_WIDTH / 2, SCREEN_HEIGHT / 2)]
self.direction = random.choice([(0, 1), (0, -1), (1, 0), (-1, 0)])
# 画蛇(surface:窗口对象)
# 遍历蛇身的位置,将其画在画布上
def draw(self, surface):
for p in self.positions:
r = pygame.Rect((p[0], p[1]), (BLOCK_SIZE, BLOCK_SIZE))
pygame.draw.rect(surface, self.color, r)
pygame.draw.rect(surface, BLACK, r, 1)
class Food:
# 初始化()
# 初始化食物的位置(position)和颜色(color = RED)
def __init__(self):
x = random.randrange(0, SCREEN_WIDTH, BLOCK_SIZE)
y = random.randrange(0, SCREEN_HEIGHT, BLOCK_SIZE)
self.position = (x, y)
self.color = RED
# 获得食物的坐标()
def get_position(self):
return self.position
# 画食物(surface:窗口对象)
# 将食物画在画布上
def draw(self, surface):
r = pygame.Rect((self.position[0], self.position[1]), (BLOCK_SIZE, BLOCK_SIZE))
pygame.draw.rect(surface, self.color, r)
pygame.draw.rect(surface, BLACK, r, 1)
3.2 神经网络 network.py 完整实现
这里,详细讲DQN(Deep Q-learning)算法原理与实现:
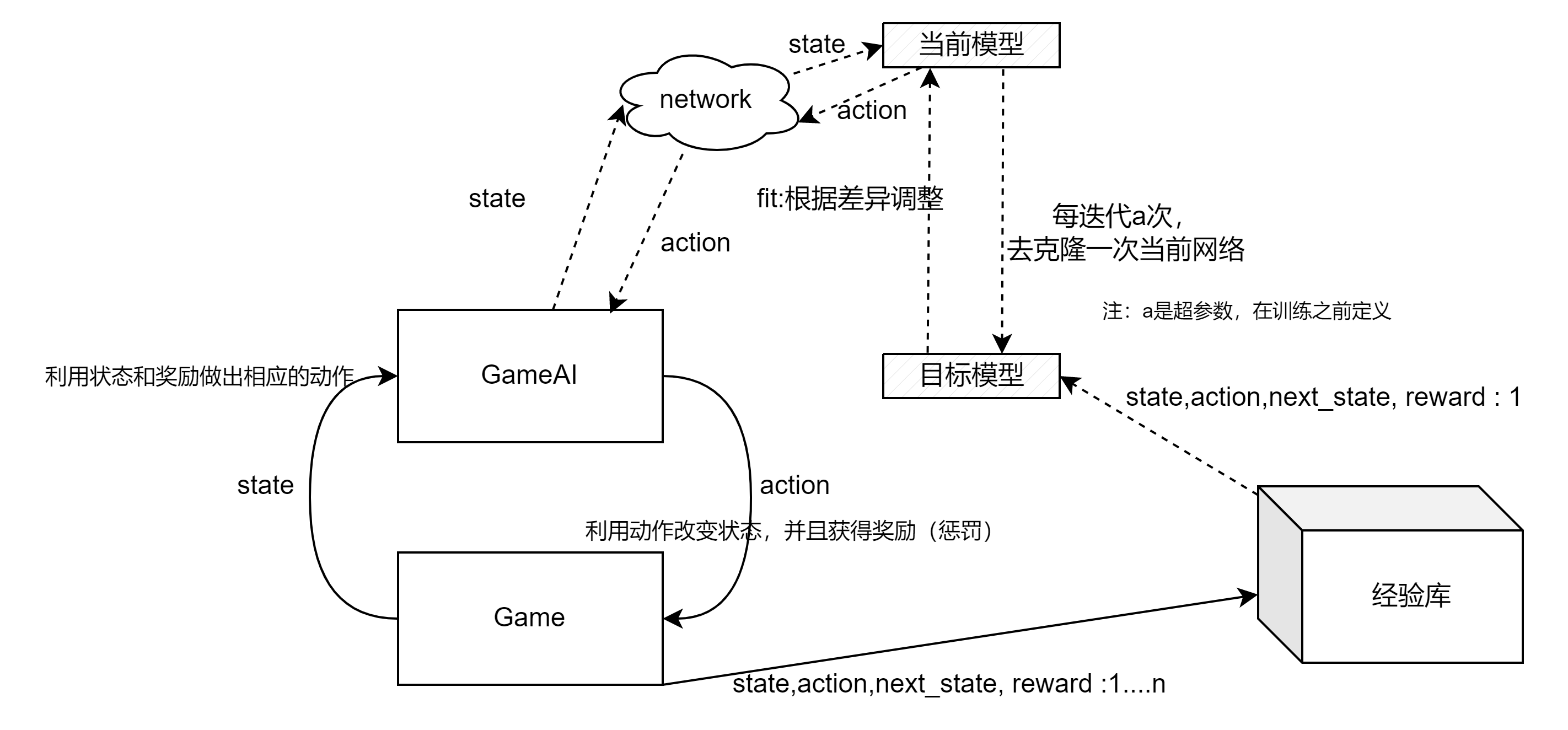
你使用的是两个神经网络:目标模型(target model)和当前模型(current model)。
目标模型是一个辅助网络,用于计算每个状态下可能的最大累积奖励。它的作用是提供一个参考目标,帮助你的当前模型更好地学习和更新。它不会被直接用于决策,而是在一定的时间间隔内从当前模型复制得到。
当前模型是你的主要神经网络,用于根据当前状态估计每个动作的Q值。它根据你的导师提供的奖励和记忆库中的经验进行训练,并逐渐改进对Q值函数的估计。
这个Q值的计算公式是
Q
(
s
,
a
)
=
R
(
s
,
a
)
+
γ
∗
m
a
x
[
Q
(
s
′
,
a
′
)
]
Q(s, a) = R(s, a) + γ * max[Q(s', a')]
Q(s,a)=R(s,a)+γ∗max[Q(s′,a′)]
其中,
- Q(s, a) 表示在状态 s 下采取动作 a 的Q值。
- R(s, a) 表示在状态 s 下采取动作 a 后获得的即时回报(即奖励)。
- γ 是折扣因子(discount factor),用于平衡当前奖励与未来奖励的重要性。
- max[Q(s’, a’)] 表示在下一个状态 s’ 下所有可能的动作 a’ 中,选择具有最高Q值的动作。
Q值的公式表示了一个动作值函数的递归关系,通过不断迭代更新Q值,智能体可以学习到在不同状态下选择最优动作的策略。
γ值一般取[0,1]之间的数,γ值越大,代表的是ai的目光越长远。越容易训练出一个懂大局关的ai,但是训练时间会变长
在每个游戏步骤中,你观察当前状态并根据当前模型选择一个动作。你执行这个动作,然后观察奖励和下一个状态。你将这些经验存储到记忆库中,并从中随机抽样一批经验来进行训练。
3.2.1 安装tensorflow库
在命令行中输入以下命令来安装TensorFlow:
pip install tensorflow
3.2.2 network.py 代码
import numpy as np
from tensorflow import keras
from collections import deque
class SnakeAI:
def __init__(self, buffer_size=1000, batch_size=32):
# 设置参数
self.gamma = 0.99 # 折扣因子
self.input_size = 12 # 输入状态的维度
self.output_size = 4 # 输出动作的维度
self.hidden_size = 100 # 隐藏层大小
self.discount_factor = 0.99 # 训练目标的折扣因子
# 创建神经网络模型
self.model = self.build_model() # 当前策略网络
self.target_model = self.build_model() # 目标策略网络
self.model.compile(optimizer='adam', loss='mse') # 编译模型
self.target_model.compile(optimizer='adam', loss='mse') # 编译目标模型
# 经验回放缓冲区
self.buffer = deque(maxlen=buffer_size)
self.batch_size = batch_size
def build_model(self):
# 构建神经网络模型
model = keras.Sequential()
model.add(keras.layers.Dense(self.hidden_size, input_dim=self.input_size, activation='relu'))
model.add(keras.layers.Dense(self.hidden_size, activation='relu'))
model.add(keras.layers.Dense(self.hidden_size, activation='relu'))
model.add(keras.layers.Dense(self.output_size, activation='linear'))
return model
def get_action(self, state):
# 根据当前状态选择动作
state = np.reshape(state, [1, self.input_size])
q_values = self.model.predict(state)
return np.argmax(q_values[0])
def train_model(self):
# 使用经验回放进行模型训练
if len(self.buffer) < self.batch_size:
return
# 从经验回放缓冲区中随机采样一个批次的数据
batch_indices = np.random.choice(len(self.buffer), self.batch_size, replace=False)
batch = [self.buffer[idx] for idx in batch_indices]
# 解析批次数据
states = np.array([sample[0] for sample in batch])
actions = np.array([sample[1] for sample in batch])
rewards = np.array([sample[2] for sample in batch])
next_states = np.array([sample[3] for sample in batch])
dones = np.array([sample[4] for sample in batch])
# 计算训练目标
targets = rewards + self.gamma * np.amax(self.model.predict_on_batch(next_states), axis=1) * (1 - dones)
target_vec = self.model.predict_on_batch(states)
indexes = np.array([i for i in range(self.batch_size)])
target_vec[[indexes], [actions]] = targets
# 使用批次数据训练模型
self.model.fit(states, target_vec, epochs=1, verbose=0)
def update_target_model(self):
# 更新目标策略网络的权重
self.target_model.set_weights(self.model.get_weights())
def add_experience(self, state, action, reward, next_state, done):
# 将经验添加到经验回放缓冲区中
self.buffer.append((state, action, reward, next_state, done))
3.3 训练AI GameAI.py 完整实现
惩罚机制(Reward System):
- 如果蛇连续直线移动超过一定步数,则给予一个小的惩罚,旨在鼓励蛇不要长时间保持直线移动。
- 如果蛇碰撞到自身的身体,则给予一个较大的负向奖励,表示碰撞到自身是一个严重的错误。
- 如果蛇吃到食物,则给予一个较大的正向奖励,表示吃到食物是一个良好的行为。
- 如果蛇离食物更近了(下一步的距离比当前步更近),则给予一个较小的正向奖励,表示靠近食物是一个好的策略。
- 其他情况下,给予一个小的负向奖励,旨在鼓励蛇尽量避免与自身碰撞和离食物较远。
状态表示(State Representation):
- 朝左、朝右、朝上、朝下四个方向是否有障碍物,用布尔值表示,其中障碍物指的是蛇的身体。
- 食物相对于蛇的位置关系,包括食物在蛇的左侧、右侧、上方、下方四个方向,用布尔值表示。
- 蛇当前的移动方向,分别表示蛇朝左、朝右、朝上、朝下四个方向,用布尔值表示。
3.3.1 GameAI.py完整代码
import pygame
import numpy as np
from game import Snake, Food, SCREEN_WIDTH, SCREEN_HEIGHT, BLOCK_SIZE, POP_SIZE, WHITE
from network import SnakeAI
# 初始化pygame
pygame.init()
font = pygame.font.SysFont('comics', 30)
class Game:
# 初始化()
# 初始化屏幕大小(screen),刷新率(clock),蛇(snake),食物(food),要训练的ai(ai_player),
# 载入已训练的模型(model.load_weights),成绩列表(scores),最好成绩(best_score),步数计数器(i)
def __init__(self, buffer_size=1000, batch_size=32):
self.screen = pygame.display.set_mode((SCREEN_WIDTH, SCREEN_HEIGHT))
self.clock = pygame.time.Clock()
self.snake = Snake()
self.food = Food()
self.ai_player = SnakeAI(buffer_size, batch_size)
# self.ai_player.model.load_weights('best_weights.h5') 有了在打开
self.scores = []
self.best_score = 0
self.i = 0
# 更新模型和蛇的行动()
# 根据当前状态state--model-->获得选择动作action,更新屏幕--奖励机制-->获得奖励,放入经验回放缓冲区--->使用经验回放训练模型
def update(self, ai_player, tran_i):
state = self.get_state() # 获取当前状态
action = ai_player.get_action(state) # 根据当前状态选择动作
v_a = self.snake.direction # 记录原来的移动方向
v_b = self.get_direction(action) # 根据动作得到新的移动方向
self.snake.turn(self.get_direction(action)) # 改变蛇的移动方向
# 判断是否执行了无效转向和转向,若是则重置连续直线步数计数器
if v_a != v_b and (v_a[0]*-1,v_a[1]*-1) != v_b:
self.i = 0
distances = np.sqrt(np.sum((np.array(self.snake.get_head_position()) - np.array(self.food.position)) ** 2))
self.snake.move() # 移动蛇的位置
done = False
if self.snake.get_head_position() == self.food.position:
self.snake.length += 1
self.food = Food()
if self.is_collision():
self.scores.append(self.snake.length)
done = True
next_state = self.get_state() # 获取下一个状态
reward = self.get_reward(done, distances, tran_i) # 根据游戏情况计算奖励
ai_player.add_experience(state, action, reward, next_state, done) # 将经验添加到经验回放缓冲区
ai_player.train_model() # 使用经验回放训练模型
return done
def get_direction(self, action):
# 根据动作索引获取移动方向
if action == 0:
return 0, -1
elif action == 1:
return 0, 1
elif action == 2:
return -1, 0
else:
return 1, 0
def is_collision(self):
# 判断蛇是否发生碰撞(头部位置是否与身体的其他部分重叠)
return self.snake.get_head_position() in self.snake.positions[1:]
def get_reward(self, done, distances, tran_i):
distances_2 = np.sqrt(np.sum((np.array(self.snake.get_head_position()) - np.array(self.food.position)) ** 2))
reward = 0
if tran_i > 50:
reward -= 0.1 # 连续直线20步之后,给与较小的惩罚()
if done:
reward -= 20 # 如果碰撞到自己的身体,则给一个大的负向奖励
elif self.snake.get_head_position() == self.food.position:
reward += 10 # 如果蛇吃到食物,则给予一个较大的正向奖励
elif distances_2 < distances:
reward += 0.2 # 鼓励蛇靠近食物,给与正向奖励
else:
reward -= 0.1 # 惩罚蛇
return reward
def get_state(self):
head = self.snake.get_head_position()
food = self.food.position
left = (head[0] - BLOCK_SIZE, head[1])
right = (head[0] + BLOCK_SIZE, head[1])
up = (head[0], head[1] - BLOCK_SIZE)
down = (head[0], head[1] + BLOCK_SIZE)
state = [
# 朝左方向是否有障碍物
(left in self.snake.positions[1:]),
# 朝右方向是否有障碍物
(right in self.snake.positions[1:]),
# 朝上方向是否有障碍物
(up in self.snake.positions[1:]),
# 朝下方向是否有障碍物
(down in self.snake.positions[1:]),
# 食物是否在蛇的左侧
food[0] < head[0],
# 食物是否在蛇的右侧
food[0] > head[0],
# 食物是否在蛇的上方
food[1] < head[1],
# 食物是否在蛇的下方
food[1] > head[1],
# 蛇的朝向是否朝左
self.snake.direction == (0, -1),
# 蛇的朝向是否朝右
self.snake.direction == (0, 1),
# 蛇的朝向是否朝上
self.snake.direction == (-1, 0),
# 蛇的朝向是否朝下
self.snake.direction == (1, 0),
]
return np.asarray(state, dtype=np.float32)
# 主流程()
# 初始化各个参数,进入游戏循环,直至游戏结束,实时保存模型参数
def run(self):
for _ in range(POP_SIZE):
self.snake.reset()
self.food = Food()
done = False
score = 0
while not done:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
quit()
self.i += 1
done = self.update(ai_player=self.ai_player, tran_i=self.i)
if done:
break
score = self.snake.length
self.screen.fill(WHITE)
self.snake.draw(self.screen)
self.food.draw(self.screen)
pygame.display.update()
self.clock.tick(10000)
self.ai_player.model.save_weights('best_weights.h5')
self.best_score = score
game = Game(buffer_size=10000, batch_size=64)
game.run()
4.开始训练
推荐,多准备几套惩罚机制。比如:
前期惩罚机制(Reward System):
- 如果蛇连续直线移动超过一定步数(这里是50步),则给予一个小的惩罚,即reward减去0.1,旨在鼓励蛇不要长时间保持直线移动。
- 如果蛇碰撞到自身的身体,则给予一个较大的负向奖励,即reward减去20,表示碰撞到自身是一个严重的错误。
- 如果蛇吃到食物,则给予一个较大的正向奖励,即reward加上10,表示吃到食物是一个良好的行为。
- 如果蛇离食物更近了(下一步的距离比当前步更近),则给予一个较小的正向奖励,即reward加上 1-(300-distances_2)/300 ,表示靠近食物是一个好的策略。
- 其他情况下,给予一个小的负向奖励,即reward减去0.1,旨在鼓励蛇尽量避免与自身碰撞和离食物较远。
提示:将第4条中的1修改为较高的数值(比如2),能在模型前期不稳定的情况下更快的找到食物。如果在前期遇到了小蛇怎么都吃不到食物,或者进入了死循环(一直直线行动),放弃吧,此时的小蛇找到了一条摆烂也能拿奖励的路线,请立即重新开始训练,当小蛇能吃到第一枚食物,就能打破僵局。
中期惩罚机制(Reward System):

- 如果蛇连续直线移动超过一定步数(这里是50步),则给予一个小的惩罚,即reward减去0.1,旨在鼓励蛇不要长时间保持直线移动。。
- 如果蛇碰撞到自身的身体,则给予一个较大的负向奖励,即reward减去20,表示碰撞到自身是一个严重的错误。
- 如果蛇吃到食物,则给予一个较大的正向奖励,即reward加上10,表示吃到食物是一个良好的行为。
- 如果蛇离食物更近了(下一步的距离比当前步更近),则给予一个较小的正向奖励,即reward加上 2-(300-distances_2)/300 ,表示靠近食物是一个好的策略。
- 其他情况下,给予一个小的负向奖励,即reward减去0.1,旨在鼓励蛇尽量避免与自身碰撞和离食物较远。
提示:此时ai的可能已经找到一种吃食物的策略,但是还是比较单一,想要打破僵局,可以将第一条的惩罚0.1修改为0.5左右,50步可以修改成30步左右,第4条的2修改成1,去鼓励蛇在有限的步长内拿到食物。
阶段一:前期吃到几个食物,得到较为少的吃食物的策略
- 平移:不断左拐+平移,拿到食物,现在ai吃食物的策略还是比较单一,不急,我们多训练几轮
阶段二:几轮下来,得到一条比较优化的吃食物的路径
- 平移:直直的左拐+平移,拿到食物,现在ai吃食物的策略已经是一条效率蛮不错的路线了

阶段三:碰撞惩罚几轮下来,会避开自己的身体
- 平移+左拐+改变原路径(防碰撞),拿到食物,现在ai可以躲避自己的身体,但是吃食物的效率还是不高,主要原因是策略太少。

这时候可以适当的调整惩罚策略,以便打破僵局(这里指的是策略太少)
接下来的步骤就是 调参,训练, 调参,训练 (感觉能不调就不调,如果真的僵局了,在调整)
最终阶段:一天调下来,最好的一次
- 左+右+防碰撞+平移,拿到食物,ai有几种不错的策略取拿到食物,并且保持存活。