字符串
171. Excel 表列序号
给你一个字符串 columnTitle ,表示 Excel 表格中的列名称,返回该列名称对应的列序号。
A -> 1
B -> 2
C -> 3
...
Z -> 26
AA -> 27
AB -> 28
...
输入: columnTitle = "A"
输出: 1
输入: columnTitle = "AB"
输出: 28
输入: columnTitle = "ZY"
输出: 701
直观的想,就是将字符串模仿十进制的转换成数字的方式,将字符串使用26进制进行转换。
class Solution{
public:
int titleToNumber(string s){
int res = 0;
for (int i = 0; i < s.size(); ++i){
res = res * 26 + (s[i] - 'A' + 1); //模仿26进制
}
return res;
}
};
165. 比较版本号
给你两个版本号 version1 和 version2 ,请你比较它们。
版本号由一个或多个修订号组成,各修订号由一个 ‘.’ 连接。每个修订号由 多位数字 组成,**可能包含前导零 **。每个版本号至少包含一个字符。修订号从左到右编号,下标从 0 开始,最左边的修订号下标为 0 ,下一个修订号下标为 1 ,以此类推。例如,2.5.33 和 0.1 都是有效的版本号。
比较版本号时,请按从左到右的顺序依次比较它们的修订号。比较修订号时,只需比较 忽略任何前导零后的整数值 。也就是说,修订号 1 和修订号 001 相等 。如果版本号没有指定某个下标处的修订号,则该修订号视为 0 。例如,版本 1.0 小于版本 1.1 ,因为它们下标为 0 的修订号相同,而下标为 1 的修订号分别为 0 和 1 ,0 < 1 。
返回规则如下:如果 version1 > version2 返回 1,如果 version1 < version2 返回 -1,除此之外返回 0。
输入:version1 = "1.01", version2 = "1.001"
输出:0
解释:忽略前导零,"01" 和 "001" 都表示相同的整数 "1"
既然是比较两个字符串每个点之间的数字是否相同,就直接同时遍历字符串比较,因此我们需要使用两个同向访问的指针各自访问一个字符串。比较的时候,数字前导零不便于我们比较,因为我们不知道后面会出现多少前导零,因此应该将点之间的部分转化为数字再比较才方便。
具体做法:
- step 1:利用两个指针表示字符串的下标,分别遍历两个字符串。
- step 2:每次截取点之前的数字字符组成数字,即在遇到一个点之前,直接取数字,加在前面数字乘10的后面。(因为int会溢出,这里采用long记录数字)。
- step 3:然后比较两个数字大小,根据大小关系返回1或者-1,如果全部比较完都无法比较出大小关系,则返回0。
class Solution {
public:
int compareVersion(string version1, string version2) {
int n1 = version1.size();
int n2 = version2.size();
int i = 0, j = 0;
//直到某个字符串结束
while(i < n1 || j < n2){
int num1 = 0;
//从下一个点前截取数字
while(i < n1 && version1[i] != '.'){
num1 = num1 * 10 + (version1[i] - '0');
i++;
}
//跳过点
i++;
int num2 = 0;
//从下一个点前截取数字
while(j < n2 && version2[j] != '.'){
num2 = num2 * 10 + (version2[j] - '0');
j++;
}
//跳过点
j++;
//比较数字大小
if(num1 > num2) return 1;
if(num1 < num2) return -1;
}
//版本号相同
return 0;
}
};
28. 实现 strStr()
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。
**说明:**当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。
输入:haystack = "hello", needle = "ll"
输出:2
暴力匹配:
class Solution
{
public:
int strStr(string haystack, string needle)
{
//处理特殊的情形
if (needle.empty())
return 0;
if (needle.size() > haystack.size())
return -1;
//字符串中找第一个相同字符的终点位置
int end_pos = haystack.size() - needle.size() + 1;
for (int i = 0; i < end_pos; ++i)
{ //遍历字符
if (haystack[i] == needle[0])
{ //若找到第一个相同的字符
int j = 0;
//则在此基础上判断后面的字符串是否相同
while (j < needle.size() && haystack[i + j] == needle[j]) {
++j;
}
//若到了needle的末尾,则说明到了终点
if (j == needle.size())
return i;
}
}
//跳出循环,则说明没有找到,返回-1
return -1;
}
};
14. 最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 ""。
输入:strs = ["flower","flow","flight"]
输出:"fl"
既然是公共前缀,那我们可以用一个字符串与其他字符串进行比较,从第一个字符开始,逐位比较,找到最长公共子串。
具体做法:
- step 1:处理数组为空的特殊情况。
- step 2:因为最长公共前缀的长度不会超过任何一个字符串的长度,因此我们逐位就以第一个字符串为标杆,遍历第一个字符串的所有位置,取出字符。
- step 3:遍历数组中后续字符串,依次比较其他字符串中相应位置是否为刚刚取出的字符,如果是,循环继续,继续查找;如果不是或者长度不足,说明从第i位开始不同,前面的都是公共前缀。
- step 4:如果遍历结束都相同,最长公共前缀最多为第一个字符串。
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
//空字符串数组
if(strs.empty()) return "";
//遍历第一个字符串的长度
for(int i = 0; i < strs[0].size(); i++){
char temp = strs[0][i];
//遍历后续的字符串
for(int j = 1; j < strs.size(); j++) {
//比较每个字符串该位置是否和第一个相同
if(i == strs[j].size() || strs[j][i] != temp) {
//不相同则结束
return strs[0].substr(0, i);
}
}
}
//遍历结束都相同,最长公共前缀最多为第一个字符串
return strs[0];
}
};
字符串套路题
一个模板刷遍所有字符串句子题目!(归纳总结+分类模板+题目分析) - 翻转单词顺序 - 力扣(LeetCode)
这类题目可以分为两类,一类是有前置或者后置空格的,另一类是没有前置和后置空格的。
1、如果有前后置空格,那么必须判断临时字符串非空才能输出,否则会输出空串。
s += " "; //这里在最后一个字符位置加上空格,这样最后一个字符串就不会遗漏
string temp = ""; //临时字符串
vector<string> res; //存放字符串的数组
for (char ch : s) //遍历字符句子
{
if (ch == ' ') //遇到空格
{
if (!temp.empty()) //临时字符串非空
{
res.push_back(temp);
temp.clear(); //清空临时字符串
}
}
else
temp += ch;
}
2、如果没有前后置的空格,不需要判断空串
s += " ";
string temp = "";
vector<string> res;
for (char ch : s)
{
if (ch == ' ')
{
res.push_back(temp);
temp.clear();
}
else
temp += ch;
}
字符串放到数组当中经过处理后,再输出成为字符串。如果有前后置空格,那么必须判断临时字符串非空才能输出,否则会输出空串。
151. 颠倒字符串中的单词
给你一个字符串 s ,颠倒字符串中 单词 的顺序。单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
输入: "the sky is blue"
输出: "blue is sky the"
class Solution {
public:
string reverseWords(string s)
{
if (s.empty()) return "";
//这里在最后一个字符位置加上空格,这样最后一个字符串就不会遗漏
s += " ";
string tmp = "";
vector<string> res;
for (char ch : s){
if (ch == ' '){
if (!tmp.empty()){ // 临时字符串非空
res.push_back(tmp);
tmp.clear();
}
}else{
tmp += ch;
}
}
s.clear();
reverse(res.begin(), res.end());
for (string &str : res){
s += str + ' ';
}
s.pop_back();
return s;
}
};
BM83 字符串变形
对于一个长度为 n 字符串,我们需要对它做一些变形。首先这个字符串中包含着一些空格,就像"Hello World"一样,然后我们要做的是把这个字符串中由空格隔开的单词反序,同时反转每个字符的大小写。比如"Hello World"变形后就变成了"wORLD hELLO"。
给定一个字符串s以及它的长度n(1 ≤ n ≤ 10^6),请返回变形后的字符串。题目保证给定的字符串均由大小写字母和空格构成。
输入:"This is a sample", 16
输出:"SAMPLE A IS tHIS"
将单词位置的反转,那肯定前后都是逆序,不如我们先将整个字符串反转,这样是不是单词的位置也就随之反转了。但是单词里面的成分也反转了啊,既然如此我们再将单词里面的部分反转过来就行。
具体做法:
- step 1:遍历字符串,遇到小写字母,转换成大写,遇到大写字母,转换成小写,遇到空格正常不变。
- step 2:第一次反转整个字符串,这样基本的单词逆序就有了,但是每个单词的字符也是逆的。
- step 3:再次遍历字符串,以每个空间为界,将每个单词反转回正常。
class Solution {
public:
string trans(string s, int n) {
if(n == 0) return s;
string res;
for(int i = 0; i < n; i++){
//大小写转换
if (s[i] <= 'Z' && s[i] >= 'A'){
res += s[i] - 'A' + 'a';
}
else if(s[i] >= 'a' && s[i] <= 'z'){
res += s[i] - 'a' + 'A';
}
else{
res += s[i]; //空格直接复制
}
}
//翻转整个字符串
reverse(res.begin(), res.end());
for (int i = 0; i < n; i++){
int j = i;
//以空格为界,二次翻转
while(j < n && res[j] != ' ') j++;
reverse(res.begin() + i, res.begin() + j);
i = j;
}
return res;
}
};
也可以使用套路解题:
class Solution {
public:
string trans(string s, int n) {
s += ' ';
string tmp;
vector<string> strs;
for(char ch : s){
if(ch != ' '){
tmp += ch;
}else{
strs.push_back(tmp);
tmp.clear();
}
}
reverse(strs.begin(), strs.end());
string res;
for(string str : strs){
string newstr;
for(char ch : str){
if(ch >= 'a' && ch <= 'z'){
newstr += ch -'a' + 'A';
}else if(ch >= 'A' && ch <= 'Z'){
newstr += ch - 'A' + 'a';
}
}
res += newstr + ' ';
}
res.pop_back();
return res;
}
};
58. 最后一个单词的长度
给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开,返回字符串中 最后一个 单词的长度。单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
输入:s = "Hello World"
输出:5
解释:最后一个单词是“World”,长度为5。
输入:s = " fly me to the moon "
输出:4
解释:最后一个单词是“moon”,长度为4。
要不要判断非空取决于给定的字符串有没有前置或者后置的空格,本题当中可能出现,所以需要判断。
class Solution {
public:
int lengthOfLastWord(string s)
{
if (s.empty()) return 0;
s += " ";
string temp = "";
vector<string> res;
for (char ch : s){
if (ch == ' '){
if (!temp.empty()) {
res.push_back(temp);
temp.clear();
}
}else{
temp += ch;
}
}
if (res.empty()) return 0;
return res.back().size();
}
};
反向遍历:
class Solution {
public:
int lengthOfLastWord(string s) {
int index = s.size() - 1;
while (s[index] == ' ') {
index--;
}
int len = 0;
while (index >= 0 && s[index] != ' ') {
len++;
index--;
}
return len;
}
};
557. 反转字符串中的单词 III
给定一个字符串 s ,你需要反转字符串中每个单词的字符顺序,同时仍保留空格和单词的初始顺序。
输入:s = "Let's take LeetCode contest"
输出:"s'teL ekat edoCteeL tsetnoc"
class Solution {
public:
string reverseWords(string s)
{
if (s.empty()) return 0;
s += " ";
string temp = "";
vector<string> res;
for (char ch : s){
if (ch == ' '){
res.push_back(temp);
temp.clear();
}else{
temp += ch;
}
}
s.clear();
for (string &str : res)
{
reverse(str.begin(), str.end());
s += str + ' ';
}
s.pop_back(); //注意最后多加了一个空格要去掉
return s;
}
};
也可直接在字符串上操作:
class Solution {
public:
string reverseWords(string s) {
int n = s.size();
int i = 0;
while (i < n) {
int start = i;
while (i < n && s[i] != ' ') {
i++;
}
int left = start, right = i - 1;
while (left < right) {
swap(s[left], s[right]);
left++;
right--;
}
while (i < n && s[i] == ' ') {
i++;
}
}
return s;
}
};
1816. 截断句子
句子 是一个单词列表,列表中的单词之间用单个空格隔开,且不存在前导或尾随空格。每个单词仅由大小写英文字母组成(不含标点符号)。例如,"Hello World"、"HELLO" 和 "hello world hello world" 都是句子。给你一个句子 s 和一个整数 k ,请你将 s 截断 ,使截断后的句子仅含 前 k 个单词,返回 截断 s 后得到的句子。
输入:s = "Hello how are you Contestant", k = 4
输出:"Hello how are you"
class Solution {
public:
string truncateSentence(string s, int k){
s += " ";
string temp = "";
vector<string> res;
for (char ch : s){
if (ch == ' ') {
res.push_back(temp);
temp.clear();
}else{
temp += ch;
}
}
for (int i = 0; i < k; i++){
temp += res[i] + ' ';
}
temp.pop_back();
return temp;
}
};
1805. 字符串中不同整数的数目
给你一个字符串 word ,该字符串由数字和小写英文字母组成。请你用空格替换每个不是数字的字符。例如,"a123bc34d8ef34" 将会变成 " 123 34 8 34" 。注意:剩下的这些整数为(相邻彼此至少有一个空格隔开):"123"、"34"、"8" 和 "34" ,返回对 word 完成替换后形成的 不同 整数的数目。只有当两个整数的 不含前导零 的十进制表示不同, 才认为这两个整数也不同。
输入:word = "a123bc34d8ef34"
输出:3
解释:不同的整数有 "123"、"34" 和 "8" 。注意,"34" 只计数一次。
给定一个由字母和数字组成的字符串,求所有被字母分隔的不重复的整数的个数(注意有前导0的不算),使用unordered_set。
class Solution {
public:
int numDifferentIntegers(string word){
unordered_set<string> s;
string temp = "";
//在字符串的末尾加上一个字母,这样遍历到最后的时候如果有整数就不会被遗漏
word += 'a';
for (char ch : word){
//如果遇到字母且临时字符串非空,就把它加入集合并重置临时字符串
if (isalpha(ch)) {
if (!temp.empty()) {
s.insert(temp);
temp.clear();
}
}else{ //如果遇到数字
// 如果之前有过前导0 (注意这里不是temp.back()=='0'
// 因为前导0的前面肯定是字母,如果不是字母就不是前导0)
if (temp == "0"){
temp.clear(); //清空前导0
}
temp += ch;
}
}
return s.size(); //集合大小就是不同整数数量
}
};
819. 最常见的单词
给定一个段落 (paragraph) 和一个禁用单词列表 (banned)。返回出现次数最多,同时不在禁用列表中的单词。
题目保证至少有一个词不在禁用列表中,而且答案唯一。禁用列表中的单词用小写字母表示,不含标点符号。段落中的单词不区分大小写,答案都是小写字母。
输入:
paragraph = "Bob hit a ball, the hit BALL flew far after it was hit."
banned = ["hit"]
输出: "ball"
使用哈希表unordered_map来记录单词出现频率。
class Solution {
public:
string mostCommonWord(string paragraph, vector<string> &banned)
{
paragraph += ' ';
string temp = "";
unordered_map<string, int> m; //哈希表记录单词出现频次
unordered_set<string> ban(banned.begin(), banned.end()); //把禁用列表放到集合中方便查找
for (char ch : paragraph) {
if (!isalpha(ch)) {
if (!temp.empty()){
m[temp]++;
temp.clear();
}
}else{
temp += tolower(ch); //注意返回的是小写字母
}
}
vector<string> words;
for (auto p : m){
words.push_back(p.first);
}
//按照频次降序
sort(words.begin(), words.end(), [&](string &s, string &p) { return m[s] > m[p]; }); //按照频次降序
//如果没有禁用单词,直接返回排序后列表首元素
if (banned.empty()) return words[0];
//否则在禁用列表中查找,第一个没有的单词就返回
for (auto w : words){
if (!ban.count(w)){
return w;
}
}
return "";
}
};
824. 山羊拉丁文
给你一个由若干单词组成的句子 sentence ,单词间由空格分隔。每个单词仅由大写和小写英文字母组成。请你将句子转换为 “山羊拉丁文(Goat Latin)”(一种类似于 猪拉丁文 - Pig Latin 的虚构语言)。山羊拉丁文的规则如下:
-
如果单词以元音开头(‘a’, ‘e’, ‘i’, ‘o’, ‘u’),在单词后添加"ma"。例如,单词 “apple” 变为 “applema” 。
-
如果单词以辅音字母开头(即,非元音字母),移除第一个字符并将它放到末尾,之后再添加"ma"。例如,单词 “goat” 变为 “oatgma” 。
-
根据单词在句子中的索引,在单词最后添加与索引相同数量的字母’a’,索引从 1 开始。例如,在第一个单词后添加 “a” ,在第二个单词后添加 “aa” ,以此类推。
返回将 sentence 转换为山羊拉丁文后的句子。
输入:sentence = "I speak Goat Latin"
输出:"Imaa peaksmaaa oatGmaaaa atinLmaaaaa"
class Solution {
public:
string toGoatLatin(string s)
{
s += " ";
string temp = "";
string vowels = "aeiouAEIOU";
vector<string> res;
for (char ch : s){
if (ch == ' '){
res.push_back(temp);
temp.clear();
}else{
temp += ch;
}
}
s.clear();
for (int i = 0; i < res.size(); i++){
// 单词以元音开头
if (vowels.find(res[i][0]) != -1){
s += res[i];
}else{// 以辅音开头
string t = res[i] + res[i][0];
t.erase(t.begin());
s += t;
}
s += "ma";
s.insert(s.size(), i + 1, 'a');
s += ' ';
}
s.pop_back();
return s;
}
};
class Solution {
public:
string toGoatLatin(string sentence) {
sentence += ' ';
vector<string> strs;
string tmp;
for(char ch : sentence){
if(ch != ' '){
tmp += ch;
}else{
strs.push_back(tmp);
tmp.clear();
}
}
string res;
for(int i = 0; i < strs.size(); i++){
string str = strs[i];
if(str[0] != 'a' && str[0] != 'e' && str[0] != 'i' && str[0] != 'o' && str[0] != 'u'
&& str[0] != 'A' && str[0] != 'E' && str[0] != 'I' && str[0] != 'O' && str[0] != 'U'){
str += str[0];
str.erase(str.begin());
}
str += "ma";
for(int j = 0; j < i + 1; j++){
str += 'a';
}
res += str + ' ';
}
res.pop_back();
return res;
}
};
1455. 检查单词是否为句中其他单词的前缀
给你一个字符串 sentence 作为句子并指定检索词为 searchWord ,其中句子由若干用 单个空格 分隔的单词组成。请你检查检索词 searchWord 是否为句子 sentence 中任意单词的前缀。
如果 searchWord 是某一个单词的前缀,则返回句子 sentence 中该单词所对应的下标(下标从 1 开始)。如果 searchWord 是多个单词的前缀,则返回匹配的第一个单词的下标(最小下标)。如果 searchWord 不是任何单词的前缀,则返回 -1 。
字符串 s 的 前缀 是 s 的任何前导连续子字符串。
输入:sentence = "i love eating burger", searchWord = "burg"
输出:4
解释:"burg" 是 "burger" 的前缀,而 "burger" 是句子中第 4 个单词。
给定句子和一个单词,在句子中的所有单词中查找其是否为某个单词前缀,返回该单词索引(从1开始)。
class Solution {
public:
int isPrefixOfWord(string s, string searchWord){
s += " ";
string temp = "";
vector<string> res;
for (char ch : s){
if (ch == ' '){
res.push_back(temp);
temp.clear();
}else{
temp += ch;
}
}
for (int i = 0; i < res.size(); i++){
if (res[i].find(searchWord) == 0){
return i + 1;
}
}
return -1;
}
};
1592. 重新排列单词间的空格
给你一个字符串 text ,该字符串由若干被空格包围的单词组成。每个单词由一个或者多个小写英文字母组成,并且两个单词之间至少存在一个空格。题目测试用例保证 text 至少包含一个单词 。
请你重新排列空格,使每对相邻单词之间的空格数目都 相等 ,并尽可能 最大化 该数目。如果不能重新平均分配所有空格,请 将多余的空格放置在字符串末尾 ,这也意味着返回的字符串应当与原 text 字符串的长度相等。返回 重新排列空格后的字符串 。
输入:text = " this is a sentence "
输出:"this is a sentence"
解释:总共有 9 个空格和 4 个单词。可以将 9 个空格平均分配到相邻单词之间,相邻单词间空格数为:9 / (4 - 1) = 3 个。
很多细节需要考虑。
class Solution {
public:
string reorderSpaces(string text) {
text += " ";
vector<string> res;
string tmp = "";
int count = -1;
for(char ch : text){
if(ch == ' '){
if(!tmp.empty()){
res.push_back(tmp);
tmp.clear();
}
count++;
}else{
tmp += ch;
}
}
int size = res.size();
text.clear();
//注意一个单词要单独考虑,防止分母出现0
if(size == 1){
text += res[0];
text.insert(text.size(), count, ' ');
return text;
}
int left = count % (size - 1); // 末尾的空格数
int n = count / (size - 1); // 单词间的空格数
for(int i = 0; i < res.size() - 1; i++){
text += res[i];
text.insert(text.size(), n, ' ');
}
text += res[size - 1]; //连接最后一个字符串
if(left > 0){
text.insert(text.size(), left, ' ');
}
return text;
}
};
1859. 将句子排序
一个 句子 指的是一个序列的单词用单个空格连接起来,且开头和结尾没有任何空格。每个单词都只包含小写或大写英文字母。我们可以给一个句子添加 从 1 开始的单词位置索引 ,并且将句子中所有单词 打乱顺序 。比方说,句子 "This is a sentence" 可以被打乱顺序得到 "sentence4 a3 is2 This1" 或者 "is2 sentence4 This1 a3" 。
给你一个 打乱顺序 的句子 s ,它包含的单词不超过 9 个,请你重新构造并得到原本顺序的句子。
输入:s = "is2 sentence4 This1 a3"
输出:"This is a sentence"
解释:将 s 中的单词按照初始位置排序,得到 "This1 is2 a3 sentence4" ,然后删除数字。
句子中的每个单词最后都有一个数字,按照数字给单词排序。
class Solution {
public:
string sortSentence(string s) {
s += ' ';
string tmp = "";
vector<string> res;
for(char ch : s){
if(ch == ' '){
res.push_back(tmp);
tmp.clear();
}else{
tmp += ch;
}
}
s.clear();
sort(res.begin(), res.end(), [&](string &a, string &b) { return a.back() < b.back(); });
for(string str : res){
str.pop_back();
s += str + ' ';
}
s.pop_back();
return s;
}
};
回文串
409. 最长回文串
给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的回文串 。在构造过程中,请注意 区分大小写 。比如 “Aa” 不能当做一个回文字符串。
输入:s = "abccccdd"
输出:7
解释:我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。
「回文串」是指倒序后和自身完全相同的字符串,即具有关于中心轴对称的性质:
- 当回文串长度为偶数时,则所有字符都出现了偶数次;
- 当回文串长度为奇数时,则位于中心的字符出现了奇数次,其余所有字符出现偶数次;
根据以上分析,字符串能被构造成回文串的充要条件为:除了一种字符出现奇数次外,其余所有字符出现偶数次。判别流程如下:
- 借助一个 HashMap ,统计字符串 s 中各字符的出现次数;
- 遍历 HashMap ,统计构造回文串的最大长度:
- 将当前字符的出现次数向下取偶数(即若为偶数则不变,若为奇数则减 1 ),出现偶数次则都可组成回文串,因此计入 res ;
- 若此字符出现次数为奇数,则可将此字符放到回文串中心,因此将 odd 置 1 ;
- 返回 res + odd 即可。
class Solution {
public:
int longestPalindrome(string s) {
unordered_map<char, int> map;
int res = 0, odd = 0;
for(char ch : s){
map[ch]++;
}
// 注意要遍历哈希表,而不是zi'fu
for(auto counter : map){
int num = counter.second;
if(num % 2 == 0){
// 若为偶数则直接加上去
res += num;
}else{
// 若为奇数则需去掉中间元素,将 odd 置 1
res += num - 1;
odd = 1;
}
}
return res + odd;
}
};
5. 最长回文子串
给你一个字符串 s,找到 s 中最长的回文子串。
输入:s = "babad"
输出:"bab"
解释:"aba" 同样是符合题意的答案。
输入:s = "cbbd"
输出:"bb"
双指针中心扩散,主要思路:
- 遍历字符串的每一个位置,以该位置作为基点,向两端进行扩展,判断回文;
- 针对每一个基点,需要判断回文字符串可能是偶数或者奇数的两种情形;
- 判断回文字符串时,终止条件是左右方向不越界,且一直满足回文要求;
class Solution {
public:
string longestPalindrome(string s) {
string res = "";
for(int i = 0; i < s.size(); i++){
// 回文字符串可能为奇数的情形
string s1 = Palindrome(s, i, i);
// 回文字符串可能为偶数的情形
string s2 = Palindrome(s, i, i + 1);
res = res.size() > s1.size() ? res : s1;
res = res.size() > s2.size() ? res : s2;
}
return res;
}
// 在 s 中寻找以 s[l] 和 s[r] 为中心的最长回文串
string Palindrome(string s, int left, int right){
// 防止索引越界
while(left >= 0 && right < s.size() && s[left] == s[right]){
// 双指针,向两边展开
left--;
right++;
}
// 返回以 s[l] 和 s[r] 为中心的最长回文串
return s.substr(left + 1, right - left - 1);
}
};
如何判断是否是回文串:
boolean isPalindrome(String s) {
// 一左一右两个指针相向而行
int left = 0, right = s.size() - 1;
while (left < right) {
if (s[left] != s[right]) {
return false;
}
left++;
right--;
}
return true;
}
516. 最长回文子序列
给你一个字符串 s ,找出其中最长的回文子序列,并返回该序列的长度。子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。
输入:s = "bbbab"
输出:4
解释:一个可能的最长回文子序列为 "bbbb" 。
数组dp[i][j]表示字符串s在[i, j]范围内的最长回文子序列的长度为dp[i][j]。
如果s[i]与s[j]相同,那么dp[i][j] = dp[i + 1][j - 1] + 2,即加上 s[i+1..j-1] 中的最长回文子序列就是 s[i..j] 的最长回文子序列。
如果s[i]与s[j]不相同,说明s[i]和s[j]同时加入并不能增加[i,j]区间内回文子串的长度,那么dp[i + 1][j - 1]分别加入s[i]、s[j]看看哪一个可以组成最长的回文子序列。加入s[j]的回文子序列长度为dp[i + 1][j],加入s[i]的回文子序列长度为dp[i][j - 1],那么dp[i][j]一定是取最大的,即:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1])。
初始化:
首先要考虑当i 和j 相同的情况,从递推公式dp[i][j] = dp[i + 1][j - 1] + 2 可以看出递推公式是计算不到i和j相同时候的情况,所以需要手动初始化一下。
当i与j相同,那么dp[i][j]一定是等于1的,即一个字符的回文子序列长度就是1。其他情况dp[i][j]初始为0就行,这样递推公式dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]) 中dp[i][j]才不会被初始值覆盖。
遍历顺序:
从递推公式dp[i][j] = dp[i + 1][j - 1] + 2 和 dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]) 可以看出,dp[i][j]是依赖于dp[i + 1][j - 1] 和 dp[i + 1][j],也就是从矩阵的角度来说,dp[i][j] 下一行的数据。 所以遍历i的时候一定要从下到上遍历,这样才能保证,下一行的数据是经过计算的。
class Solution {
public:
int longestPalindromeSubseq(string s) {
int n = s.size();
vector<vector<int>> dp(n, vector<int>(n));
// base case
for(int i = 0; i < n; i++){
dp[i][i] = 1;
}
// 反着遍历保证正确的状态转移
for(int i = n - 1; i >= 0; i--){
for(int j = i + 1; j < n; j++){
if(s[i] == s[j]){
// 它俩一定在最长回文子序列中
dp[i][j] = 2 + dp[i + 1][j - 1];
}else{
// s[i+1..j] 和 s[i..j-1] 谁的回文子序列更长?
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
}
}
// 整个 s 的最长回文子串长度
return dp[0][n - 1];
}
};
647. 回文子串
给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。回文字符串是正着读和倒过来读一样的字符串,子字符串 是字符串中的由连续字符组成的一个序列。具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
输入:s = "abc"
输出:3
解释:三个回文子串: "a", "b", "c"
输入:s = "aaa"
输出:6
解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa"
布尔类型的dp[i][j]表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。
当s[i]与s[j]不相等,dp[i][j]一定是false;当s[i]与s[j]相等时,有如下三种情况:
- 情况一:下标
i与j相同,同一个字符例如a,当然是回文子串 - 情况二:下标
i与j相差为1,例如aa,也是回文子串 - 情况三:下标:
i与j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了。aba的区间就是i+1与j-1区间,这个区间是不是回文就看dp[i + 1][j - 1]是否为true。
初始化:dp[i][j]初始化为false。
遍历顺序:首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,再对dp[i][j]进行赋值true的。所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的。
class Solution {
public:
int countSubstrings(string s) {
int n = s.size(), res = 0;
vector<vector<bool>> d(n, vector<bool>(n, false));
for(int i = n - 1; i >= 0; i--){
for(int j = i; j < n; j++){
if(s[i] == s[j] && (j - i <= 1 || d[i + 1][j - 1])){
res++;
d[i][j] = true;
}
}
}
return res;
}
};
1312. 让字符串成为回文串的最少插入次数
给你一个字符串 s ,每一次操作你都可以在字符串的任意位置插入任意字符,请你返回让 s 成为回文串的最少操作次数 。「回文串」是正读和反读都相同的字符串。
输入:s = "zzazz"
输出:0
解释:字符串 "zzazz" 已经是回文串了,所以不需要做任何插入操作。
输入:s = "mbadm"
输出:2
解释:字符串可变为 "mbdadbm" 或者 "mdbabdm" 。
回文问题终极篇:最小代价构造回文串 - 云+社区 - 腾讯云 (tencent.com)
二维数组dp[i][j]表示对字符串s[i..j]最少需要进行dp[i][j]次插入才能变成回文串。想求s的最少插入次数,也就是求dp[0][n - 1]的大小(n为s的长度)。
当算出dp[i+1][j-1],即知道了s[i+1..j-1]成为回文串的最小插入次数,那么也就可以认为s[i+1..j-1]已经是一个回文串了,所以通过dp[i+1][j-1]推导dp[i][j]的关键就在于s[i]和s[j]这两个字符。
如果s[i] == s[j],不需要进行任何插入,只要知道如何把s[i+1..j-1]变成回文串即可。
如果s[i] != s[j],有如下步骤:
步骤一,做选择,先将s[i..j-1]或者s[i+1..j]变成回文串。怎么做选择呢?谁变成回文串的插入次数少,就选谁呗。
比如图二的情况,将s[i+1..j]变成回文串的操作次数更小,因为它本身就是回文串,根本不需要插入;同理,对于图三,将s[i..j-1]变成回文串的操作次数更小。然而,如果 s[i+1..j]和s[i..j-1]都不是回文串,都至少需要插入一个字符才能变成回文,所以选择哪一个都一样。
步骤二,根据步骤一的选择,将s[i..j]变成回文串。
如果在步骤一中选择把s[i+1..j]变成回文串,那么在s[i+1..j]右边插入一个字符s[i]一定可以将s[i..j]变成回文;同理,如果在步骤一中选择把s[i..j-1]变成回文串,在s[i..j-1]左边插入一个字符s[j]一定可以将s[i..j]变成回文。
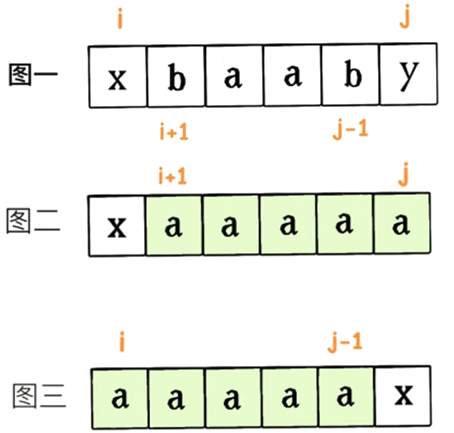
初始化:当i == j时dp[i][j] = 0,因为当i == j时s[i..j]就是一个字符,本身就是回文串,所以不需要进行任何插入操作。
class Solution {
public:
int minInsertions(string s) {
int n = s.size();
// 定义:对 s[i..j],最少需要插入 dp[i][j] 次才能变成回文
vector<vector<int>> dp(n, vector<int>(n, 0));
// base case:i == j 时 dp[i][j] = 0,单个字符本身就是回文
// 从下向上遍历
for (int i = n - 1; i >= 0; i--) {
// 从左向右遍历
for (int j = i + 1; j < n; j++) {
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1];
} else {
dp[i][j] = min(dp[i + 1][j], dp[i][j - 1]) + 1;
}
}
}
return dp[0][n - 1];
}
};
字符串运算
415. 字符串相加
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。
输入:num1 = "11", num2 = "123"
输出:"134"
模拟运算过程。
class Solution {
public:
string addStrings(string num1, string num2) {
int i = num1.size() - 1, j = num2.size() - 1, add = 0;
string res = "";
while (i >= 0 || j >= 0 || add != 0) {
int x = i >= 0 ? num1[i] - '0' : 0;
int y = j >= 0 ? num2[j] - '0' : 0;
int num = x + y + add;
res += '0' + num % 10;
add = num / 10;
i--;
j--;
}
reverse(res.begin(), res.end());
return res;
}
};
43. 字符串相乘
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。**注意:**不能使用任何内置的 BigInteger 库或直接将输入转换为整数。
输入: num1 = "2", num2 = "3"
输出: "6"
输入: num1 = "123", num2 = "456"
输出: "56088"
有两个指针 i,j 在 num1 和 num2 上游走,计算乘积,同时将乘积叠加到 res 的正确位置。num1[i] 和 num2[j] 的乘积对应的就是 res[i + j] 和 res[i + j + 1] 这两个位置。

class Solution {
public:
string multiply(string num1, string num2) {
int m = num1.size(), n = num2.size();
// 结果最多为 m + n 位数
vector<int> res(m + n, 0);
// 从个位数开始逐位相乘
for (int i = m - 1; i >= 0; i--){
for (int j = n - 1; j >= 0; j--) {
int mul = (num1[i] - '0') * (num2[j] - '0');
// 乘积在 res 对应的索引位置
int p1 = i + j, p2 = i + j + 1;
// 叠加到 res 上
int sum = mul + res[p2];
res[p2] = sum % 10;
res[p1] += sum / 10;
}
}
// 结果前缀可能存在 0(未使用的位)
int i = 0;
while (i < res.size() && res[i] == 0){
i++;
}
// 将计算结果转化成字符串
string str;
for (; i < res.size(); i++){
str += '0' + res[i];
}
return str.size() == 0 ? "0" : str;
}
};
445. 两数相加 II
给定两个 非空链表 l1和 l2 来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。可以假设除了数字 0 之外,这两个数字都不会以零开头。
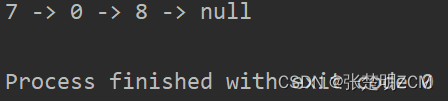
示例:
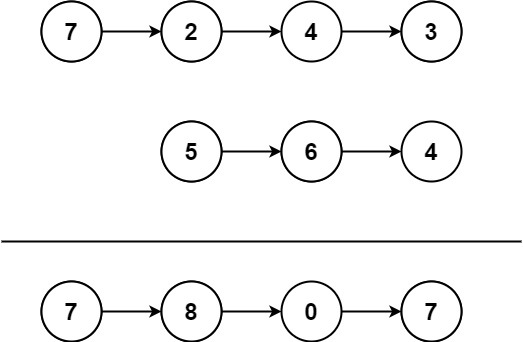
输入:l1 = [7,2,4,3], l2 = [5,6,4]
输出:[7,8,0,7]
本题的主要难点在于链表中数位的顺序与我们做加法的顺序是相反的,为了逆序处理所有数位,可以使用栈:把所有数字压入栈中,再依次取出相加,计算过程中需要注意进位的情况。
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
stack<int> s1, s2;
while(l1){
s1.push(l1->val);
l1 = l1->next;
}
while(l2){
s2.push(l2->val);
l2 = l2->next;
}
int carry = 0, cur = 0; //进位,本位
ListNode* res = nullptr;
while(!s1.empty() || !s2.empty() || carry){
int a = s1.empty() ? 0 : s1.top();
int b = s2.empty() ? 0 : s2.top();
if(!s1.empty()) s1.pop();
if(!s2.empty()) s2.pop();
int sum = a + b + carry;
carry = sum / 10;
cur = sum % 10;
ListNode* node = new ListNode(cur);
node->next = res;
res = node;
}
return res;
}
};
2. 两数之和
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。请你将两个数相加,并以相同形式返回一个表示和的链表。你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
注意要根据进位的结果,判断是否需要在链表的结尾添加结点。
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode* p1 = l1, * p2 = l2;
ListNode* dummy = new ListNode(-1);
ListNode* p = dummy;
int cur = 0, add = 0;
while(p1 || p2 || add){
int val1 = p1 ? p1->val : 0;
int val2 = p2 ? p2->val : 0;
if(p1) p1 = p1->next;
if(p2) p2 = p2->next;
int sum = val1 + val2 + add;
cur = sum % 10;
add = sum / 10;
p->next = new ListNode(cur);
p = p->next;
// 若最后的进位是1,则还要加上去
if(add == 1){
p->next = new ListNode(1);
}
}
return dummy->next;
}
};





![[附源码]计算机毕业设计考试系统Springboot程序](https://img-blog.csdnimg.cn/2d5623fc7680479a8c78832f77730a61.png)