目录
- 前言
- 1.1 训练误差和泛化误差
- 1.2 模型选择
- 1.2.1 验证数据集
- 1.2.3 K K K折交叉验证
- 1.3 欠拟合和过拟合
- 1.3.1 模型复杂度
- 1.3.2 训练数据集大小
- 1.4 多项式函数拟合示例
- 1.4.1 生成数据集
- 1.4.2 定义、训练和测试模型
- 1.4.3 三阶多项式函数拟合(正常)
- 1.4.4 线性函数拟合(欠拟合)
- 1.4.5 训练样本不足(过拟合)
- 总结
前言
前几篇文章基于Fashion-MNIST数据集的实验中,我们评价了机器学习模型在训练数据集和测试数据集上的表现。如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不一定更准确。这是为什么呢?
1.1 训练误差和泛化误差
通俗来讲,训练误差(training error)指模型在训练数据集上表现出的误差和泛化误差(generalization error)指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。计算训练误差和泛化误差可以使用之前介绍过的损失函数,例如线性回归用到的平方损失函数和softmax回归用到的交叉熵损失函数。
在机器学习里,我们通常假设训练数据集(训练题)和测试数据集(测试题)里的每一个样本都是从同一个概率分布中相互独立地生成的。基于该独立同分布假设,给定任意一个机器学习模型(含参数),它的训练误差的期望和泛化误差都是一样的。例如,如果我们将模型参数设成随机值,那么训练误差和泛化误差会非常相近。但我们从前面几节中已经了解到,模型的参数是通过在训练数据集上训练模型而学习出的,参数的选择依据了最小化训练误差。所以,训练误差的期望小于或等于泛化误差。也就是说,一般情况下,由训练数据集学到的模型参数会使模型在训练数据集上的表现优于或等于在测试数据集上的表现。由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。
机器学习模型应关注降低泛化误差。
1.2 模型选择
在机器学习中,通常需要评估若干候选模型的表现并从中选择模型。这一过程称为模型选择(model selection)。可供选择的候选模型可以是有着不同超参数的同类模型。以多层感知机为例,我们可以选择隐藏层的个数,以及每个隐藏层中隐藏单元个数和激活函数。为了得到有效的模型,我们通常要在模型选择上下一番功夫。下面,我们来描述模型选择中经常使用的验证数据集(validation data set)。
1.2.1 验证数据集
从严格意义上讲,测试集只能在所有超参数和模型参数选定后使用一次。不可以使用测试数据选择模型,如调参。由于无法从训练误差估计泛化误差,因此也不应只依赖训练数据选择模型。鉴于此,我们可以预留一部分在训练数据集和测试数据集以外的数据来进行模型选择。这部分数据被称为验证数据集,简称验证集(validation set)。例如,我们可以从给定的训练集中随机选取一小部分作为验证集,而将剩余部分作为真正的训练集。
1.2.3 K K K折交叉验证
由于验证数据集不参与模型训练,当训练数据不够用时,预留大量的验证数据显得太奢侈。一种改善的方法是
K
K
K折交叉验证(
K
K
K-fold cross-validation)。在
K
K
K折交叉验证中,我们把原始训练数据集分割成
K
K
K个不重合的子数据集,然后我们做
K
K
K次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他
K
−
1
K-1
K−1个子数据集来训练模型。在这
K
K
K次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
1.3 欠拟合和过拟合
模型训练中经常出现的两类典型问题:一类是模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting);另一类是模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。在实践中,我们要尽可能同时应对欠拟合和过拟合。虽然有很多因素可能导致这两种拟合问题,在这里我们重点讨论两个因素:模型复杂度和训练数据集大小。
1.3.1 模型复杂度
为了解释模型复杂度,我们以多项式函数拟合为例。给定一个由标量数据特征 x x x和对应的标量标签 y y y组成的训练数据集,多项式函数拟合的目标是找一个 K K K阶多项式函数
y ^ = b + ∑ k = 1 K x k w k \hat{y} = b + \sum_{k=1}^K x^k w_k y^=b+k=1∑Kxkwk
来近似 y y y。在上式中, w k w_k wk是模型的权重参数, b b b是偏差参数。与线性回归相同,多项式函数拟合也使用平方损失函数。特别地,一阶多项式函数拟合又叫线性函数拟合。
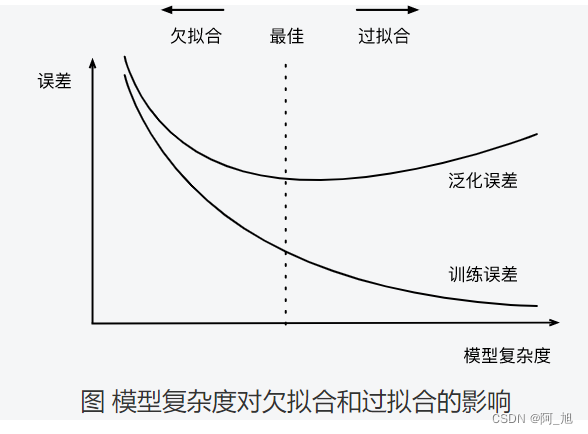
因为高阶多项式函数模型参数更多,模型函数的选择空间更大,所以高阶多项式函数比低阶多项式函数的复杂度更高。因此,高阶多项式函数比低阶多项式函数更容易在相同的训练数据集上得到更低的训练误差。给定训练数据集,模型复杂度和误差之间的关系通常如下图所示。给定训练数据集,如果模型的复杂度过低,很容易出现欠拟合;如果模型复杂度过高,很容易出现过拟合。应对欠拟合和过拟合的一个办法是针对数据集选择合适复杂度的模型。
1.3.2 训练数据集大小
影响欠拟合和过拟合的另一个重要因素是训练数据集的大小。一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
1.4 多项式函数拟合示例
为了理解模型复杂度和训练数据集大小对欠拟合和过拟合的影响,下面我们以多项式函数拟合为例来实验。首先导入实验需要的包或模块。
%matplotlib inline
import torch
import numpy as np
import sys
import d2lzh_pytorch as d2l
1.4.1 生成数据集
我们将生成一个人工数据集。在训练数据集和测试数据集中,给定样本特征 x x x,我们使用如下的三阶多项式函数来生成该样本的标签:
y = 1.2 x − 3.4 x 2 + 5.6 x 3 + 5 + ϵ , y = 1.2x - 3.4x^2 + 5.6x^3 + 5 + \epsilon, y=1.2x−3.4x2+5.6x3+5+ϵ,
其中噪声项 ϵ \epsilon ϵ服从均值为0、标准差为0.01的正态分布。训练数据集和测试数据集的样本数都设为100。
n_train, n_test, true_w, true_b = 100, 100, [1.2, -3.4, 5.6], 5
# torch.randn:用来生成随机数字的tensor,这些随机数字满足标准正态分布(0~1)
features = torch.randn((n_train + n_test, 1))
# torch.cat()把多个tensor进行拼接,poly_features.shape=200*3
poly_features = torch.cat((features, torch.pow(features, 2), torch.pow(features, 3)), 1)
labels = (true_w[0] * poly_features[:, 0] + true_w[1] * poly_features[:, 1]
+ true_w[2] * poly_features[:, 2] + true_b)
# np.random.normal()的意思是一个正态分布,噪声
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
看一看生成的数据集的前两个样本。
features[:2], poly_features[:2], labels[:2]
输出:
(tensor([[-1.0613],
[-0.8386]]), tensor([[-1.0613, 1.1264, -1.1954],
[-0.8386, 0.7032, -0.5897]]), tensor([-6.8037, -1.7054]))
1.4.2 定义、训练和测试模型
我们先定义作图函数semilogy,其中
y
y
y 轴使用了对数尺度。
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None,
legend=None, figsize=(3.5, 2.5)):
d2l.set_figsize(figsize)
d2l.plt.xlabel(x_label)
d2l.plt.ylabel(y_label)
d2l.plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
d2l.plt.semilogy(x2_vals, y2_vals, linestyle=':')
d2l.plt.legend(legend)
和线性回归一样,多项式函数拟合也使用平方损失函数。因为我们将尝试使用不同复杂度的模型来拟合生成的数据集,所以我们把模型定义部分放在fit_and_plot函数中。
num_epochs, loss = 100, torch.nn.MSELoss()
def fit_and_plot(train_features, test_features, train_labels, test_labels):
net = torch.nn.Linear(train_features.shape[-1], 1)
# 通过Linear文档可知,pytorch已经将参数初始化了,所以我们这里就不手动初始化了
batch_size = min(10, train_labels.shape[0])
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y.view(-1, 1))
optimizer.zero_grad()
l.backward()
optimizer.step()
train_labels = train_labels.view(-1, 1)
test_labels = test_labels.view(-1, 1)
train_ls.append(loss(net(train_features), train_labels).item())
test_ls.append(loss(net(test_features), test_labels).item())
print('final epoch: train loss', train_ls[-1], 'test loss', test_ls[-1])
semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('weight:', net.weight.data,
'\nbias:', net.bias.data)
1.4.3 三阶多项式函数拟合(正常)
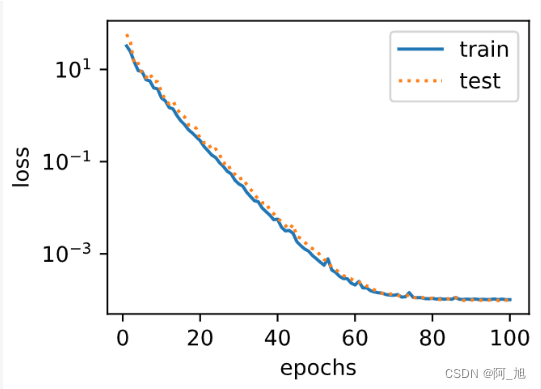
我们先使用与数据生成函数同阶的三阶多项式函数拟合。实验表明,这个模型的训练误差和在测试数据集的误差都较低。训练出的模型参数也接近真实值: w 1 = 1.2 , w 2 = − 3.4 , w 3 = 5.6 , b = 5 w_1 = 1.2, w_2=-3.4, w_3=5.6, b = 5 w1=1.2,w2=−3.4,w3=5.6,b=5。
fit_and_plot(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:])
输出:
final epoch: train loss 0.00010175639908993617 test loss 9.790256444830447e-05
weight: tensor([[ 1.1982, -3.3992, 5.6002]])
bias: tensor([5.0014])
1.4.4 线性函数拟合(欠拟合)
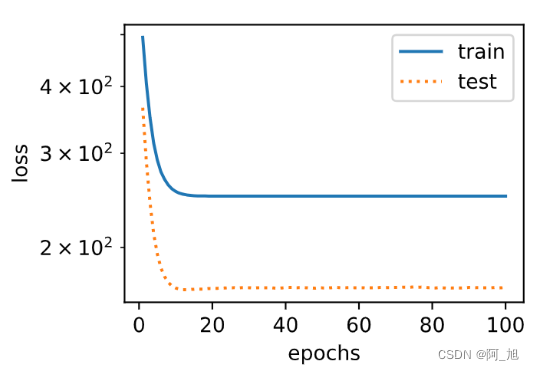
我们再试试线性函数拟合。很明显,该模型的训练误差在迭代早期下降后便很难继续降低。在完成最后一次迭代周期后,训练误差依旧很高。线性模型在非线性模型(如三阶多项式函数)生成的数据集上容易欠拟合。
fit_and_plot(features[:n_train, :], features[n_train:, :], labels[:n_train],
labels[n_train:])
输出:
final epoch: train loss 249.35157775878906 test loss 168.37705993652344
weight: tensor([[19.4123]])
bias: tensor([0.5805])
1.4.5 训练样本不足(过拟合)
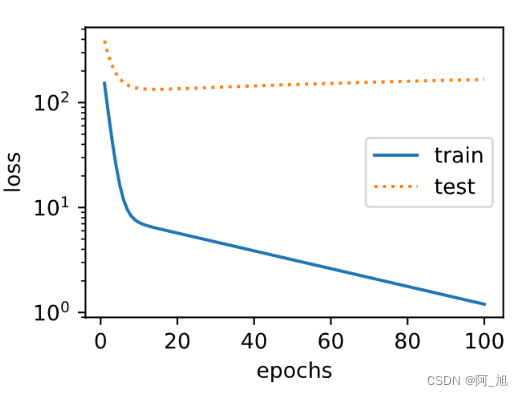
事实上,即便使用与数据生成模型同阶的三阶多项式函数模型,如果训练样本不足,该模型依然容易过拟合。让我们只使用两个样本来训练模型。显然,训练样本过少了,甚至少于模型参数的数量。这使模型显得过于复杂,以至于容易被训练数据中的噪声影响。在迭代过程中,尽管训练误差较低,但是测试数据集上的误差却很高。这是典型的过拟合现象。
fit_and_plot(poly_features[0:2, :], poly_features[n_train:, :], labels[0:2],
labels[n_train:])
输出:
final epoch: train loss 1.198514699935913 test loss 166.037109375
weight: tensor([[1.4741, 2.1198, 2.5674]])
bias: tensor([3.1207])
总结
- 由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。机器学习模型应关注降低泛化误差。
- 可以使用验证数据集来进行模型选择。
- 欠拟合指模型无法得到较低的训练误差,过拟合指模型的训练误差远小于它在测试数据集上的误差。
- 应选择复杂度合适的模型并避免使用过少的训练样本。
如果内容对你有帮助,感谢点赞+关注哦!
关注下方GZH:阿旭算法与机器学习,可获取更多干货内容~欢迎共同学习交流

![[附源码]计算机毕业设计考试系统Springboot程序](https://img-blog.csdnimg.cn/2d5623fc7680479a8c78832f77730a61.png)