目录
前言
一.磁盘
1.1定义
1.2结构
1.3磁盘的寻找方式
1.4磁盘的逻辑/线性结构
1.5磁盘访问的基本单位
1.6磁盘的管理
二.Linux文件系统
2.1系统结构
2.2属性解析:
2.3inode相关块的解析:
2.4数据块的解析:
前言
学了一段时间的Linux操作系统,我们知道了操作系统对下是能够管理软硬件资源的,这是它的手段;对上能为用户提供相应的服务,这是它的目的。而我们又得明白一个道理,Linux下一切皆文件,指的是任何软硬件设备、驱动、进程等在操作系统下都会被以“文件”的方式进行管理。而真正储存文件数据的磁盘也不例外。
在整个计算机中,唯有两种存储器能够储存相应的文件数据,一个是内存,一个是外村。内存的优点在于读写传输速度很快,缺点就是关了机数据就全都丢失了;而外存——就是磁盘,它读写速度相对内存就很慢了,但是在磁盘中的文件数据可以永久的保存下来,且磁盘的容量也很大。所以在介绍Linux的文件系统之前需要先来了解了解磁盘,用以小见大的方式理解文件系统就很容易了。
一.磁盘
1.1定义
磁盘是计算机主要的存储介质,可以存储大量的二进制数据,并且断电后也能保持数据不丢失。早期计算机使用的磁盘是软磁盘(Floppy Disk,简称软盘),如今常用的磁盘是硬磁盘(Hard disk,简称硬盘)。
磁盘存储着大量的文件数据,当某个进程需要打开磁盘中的文件时,这些文件会被操作系统管理并拿到内存中,放在运行队列排序,等待着CPU的处理和运算——意味着该文件被访问,会发生读写操作。而对于没有被打开的文件来说,需要被管理吗?
举个例子:从浙江一加工厂送到山西太原的一箱快递货车,在被快递员整理后都贴上了各自的取件码,整齐的被放在货架上,然后通知用户来取。所以取之前,快递在货架上静静的放着。这些大量的快递也需要被静态管理,方便用户随时来取。那么没有被打开的文件也是这个道理,它们也需要被管理。
1.2结构
先来看几张磁盘的图片吧:

以上就是磁盘被拆开后的内部结构。
磁盘详细分为六部分:
一是它的外壳,用于密封保护磁盘,因为磁盘的生产环境是在无尘室的,不能有任何灰尘或颗粒的携带,这样会损坏磁盘;
二是它的盘片,如上,光滑到能反光的那个圆盘就是盘片,一个盘片有两个盘面(正反),从这里我们可以想到小时候家里的光盘,它只有一面是光滑的,另一面就是图片形成的;
三是它的磁头臂,磁头臂带着一个磁头,上图左边三角形的那一块就是,它处在盘面的上方,与盘面并没有任何接触,在磁盘上对各个文件的查找全靠磁头臂进行摆动,对各个文件的读写全靠磁头进行。而每一个盘面都会带有一个磁头臂。
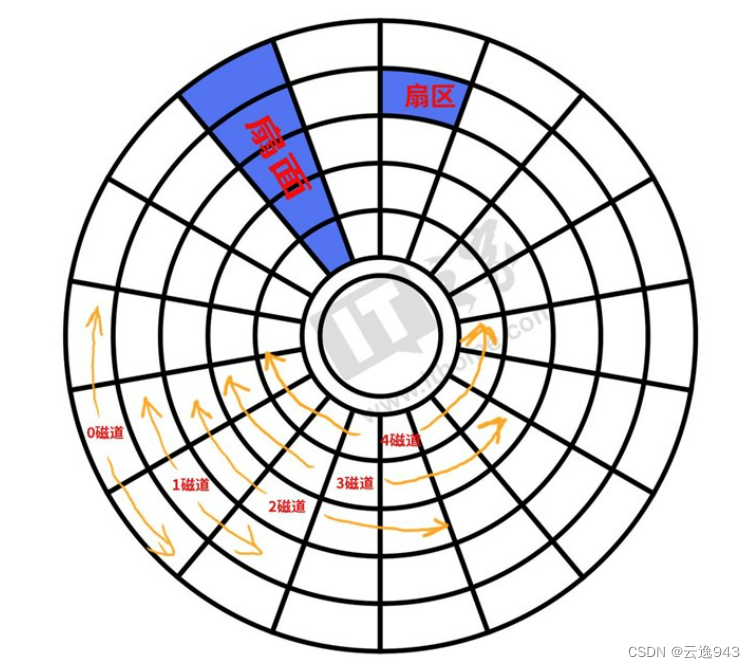
四就是它的磁道和扇区了。如上,该圆盘中从外到里划分成了若干圈,每一圈就是一个磁道。磁道由外向内依次编号,最外侧的是0号磁道。
而从0-360度中又被若干竖线划分成了众多的扇区,扇区的标号比较特殊,是从1开始编号的。对盘面划分成成这么多的领域就是为了方便查找文件,对其进行读写操作。
举个例子:中国有960多万平方公里的土地,划分为34个省,4个直辖市、5个自治区、2个特别行政区。而每个省有个各个市区,每个市区有能划分为多个县镇......。为什么我们的身份证上要写上自己的籍贯呢?就是为了方便管理,当公安要寻找一个有姓名,有图片的人时,系统会根据图片和名字识别出他的居住地在哪个省,哪个市,哪个县,哪个街道,哪个小区,然后就能找到。
所以同样的,磁道和扇区的设立也方便了磁盘对文件的管理,能够快速的查找到该文件在哪个盘片的哪个盘面的哪个磁道的哪个扇区。
划分好扇区后,从图上可知,在一个扇面中,有5个扇区,每个扇区的大小虽然不同,但是它们能存储的数据量是相同的,假设每个扇区的大小为512字节,因为扇区能存储相同容量的原因与扇区的密度有关,越靠近磁面圆心的扇区密度越大,所以每个扇区都一样。

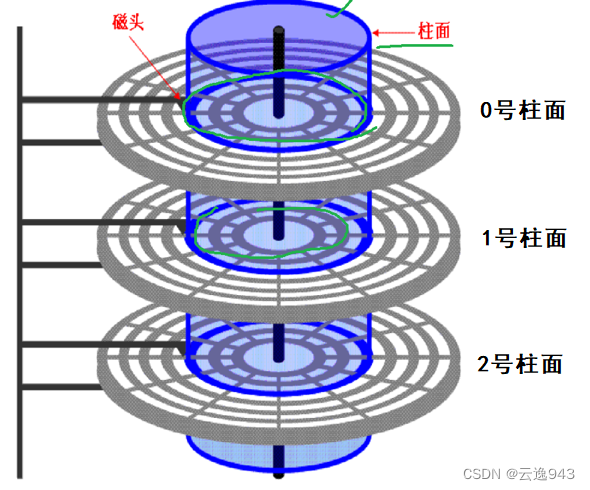
第五部分就是柱面了,因为一个磁盘的容量很大,那么势必要有很多个盘片,众多盘片垒在一块就形成了圆柱,每一个盘片也就是称之为磁盘的柱面。
每一个盘面上的磁头是连接在一个磁臂上的,所有磁头是共进退的,说白了就是磁臂进行来回摆动,它会带动所有的磁头也进行来回摆动,这样做的原因是:在查找文件时,能够同时命令磁臂对所有盘面的某一区域进行寻找,提高了命中率,节省了大量的时间。
第六部分是马达,它会带动盘片进行旋转。
1.3磁盘的寻找方式
磁盘在寻址的时候,基本单位是一个扇区(512字节)的大小,那么在一面上,如何定位一个扇区?
磁盘寻址开始后,盘片们开始旋转,然后磁臂带动众多磁头来回摆动,依此确认是在哪一个盘片的哪一个盘面的哪一个磁道上,最终就能定位出扇区。这种方式被称为CHS寻址法。
CHS寻址模式将硬盘划分为磁头(Heads) 、 柱面(Cylinder)、扇区(Sector)。
硬盘容量=磁头数*柱面数*扇区数*512字节。
1.4磁盘的逻辑/线性结构
从上图中看,磁盘是由一圈又一圈的磁道组成,它是圆形的——这是它的逻辑结构;而线性结构中,它又是由一个矩形长条组成的。
举个磁带的例子:

磁带是由一个小盒内的两个圆圈围绕组成的,录音机中的两个圆形钻头就是用来读取磁带的数据,所以磁带的运行方式按照圆的逻辑思维进行。而我们将磁带从小盒里拽出来,它只不过是一个长条。
磁盘也是同理的,系统对磁盘进行管理,就是对数组进行管理。我们可以把整个磁盘从逻辑上看成一个arr[n]:
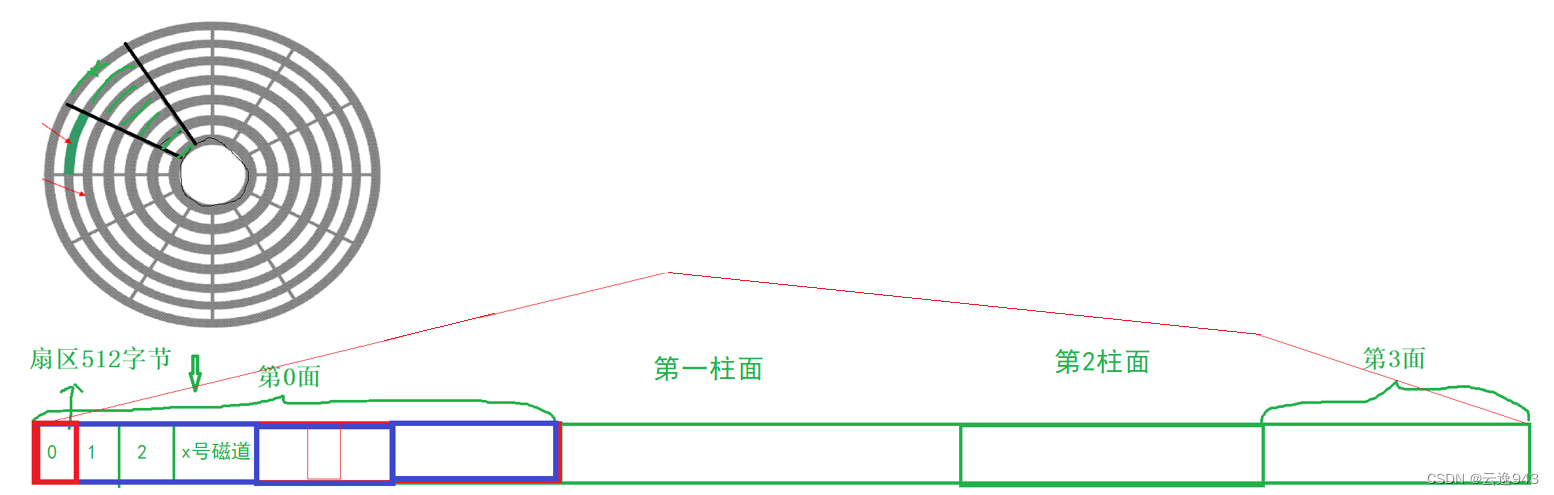
转换成数组后,磁盘的寻址方式也是如此:
例如,我们要寻址第123号磁盘的位置:
假如磁盘中有一个盘片(两个盘面),一面上有10个磁道,一个磁道上有100个扇区
第一步:123/1000=0——0号盘面; 第二步:123/100=1——1号磁道
第三步:123%100=23——23号扇区
所以123号磁盘的位置在第0盘面第1号磁道第23号扇区中。
这种寻址方式被称为LBA寻址模式。
随着硬盘技术的进步,硬盘容量越来越大,CHS寻址模式无法管理超过8064 MB的硬盘,因此工程师们发明了更加简便的LBA寻址方式。在LBA地址中,地址不再表示实际硬盘的实际物理地址(柱面、磁头和扇区) 。LBA编址方式将 CHS这种三维寻址方式转变为一维的线性寻址,它把硬盘所有的物理扇区的C/H/S编号通过一定的规则转变为一线性的编号,系统效率得到大大提高,避免了 烦琐的磁头/柱面/扇区的寻址方式。在访问硬盘时,由硬盘控制器再这种逻辑地址转换为实际硬盘的物理地址。
1.5磁盘访问的基本单位
磁盘访问的基本单位是一个扇区大小——512字节,但依旧很小!OS内的文件系统定制多个扇区的读取是1KB/2KB/4KB,4KB是基本单位。哪怕你只想修改某个10bit大小文件的,也必须将整个4KB对应的扇区(相当于是8个扇区)加载到内存中。
有人会认为这种方式有些浪费空间,小题大做了。其实这种方式的应用是经过科学家们无数次研究测试出来的,这样的好处在于:对数据I/O的效率提高了,可以用空间换取时间。这被称为是空间局部性原理。
在计算机学科的概念中,局部性原理是常用的,指处理器在访问某些数据时短时间内存在重复访问,某些数据或者位置访问的概率极大,大多数时间只访问局部的数据。
空间局部性原理:
在不久的将来将用到的数据很可能与现在正在使用的数据在空间地址上是临近的。这条原理的原因是因为分治思想的处理。当一个模块正在解决一个子问题时,他会申请使用很多局部变量,这些变量不仅空间上连续,而在逻辑上也有关联。因此正在使用的这个数据周围的其他数据也是很可能会被用到。
所以将4KB的扇区加载到内存就是为了这种情况的发生做出的措施,节省了时间,增加了数据的命中率 。
内存的管理也是如此,内存被划分为了4KB大小的空间,因为内存空间共有4GB大小,换算一下就是4GB/4KB=100多万个4KB大小的小内存空间。
1.6磁盘的管理
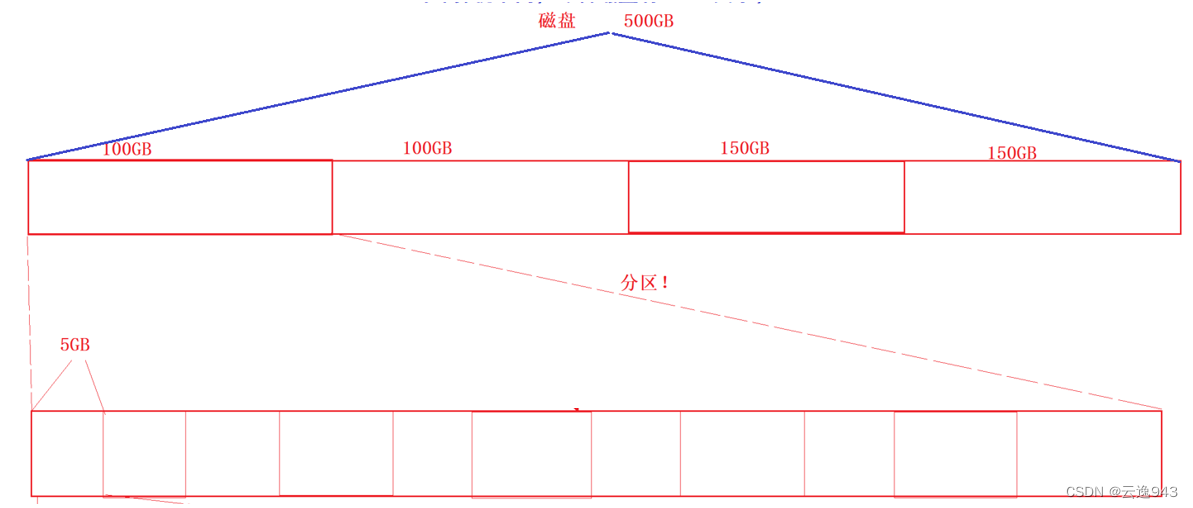
假如磁盘有500GB空间,它的管理方式从上面内存的管理就知道了——分而治之
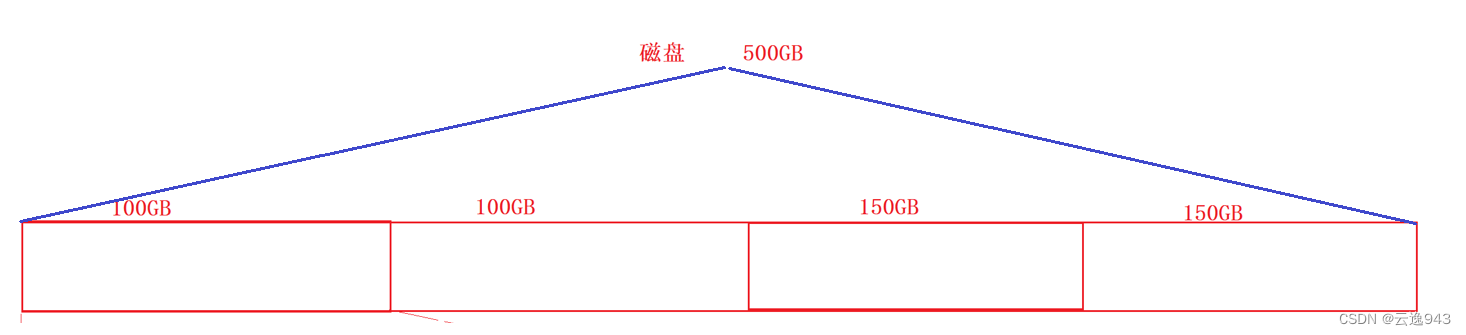
如上图:假如我们将磁盘分成2个100GB,2个150GB。
举个例子:中国有14亿多的人口、数十个省市,想要管理的话,得根据经济状况、风土人情、环境等因素去管理,方式要有针对性;而计算机不同,尽管磁盘有500GB大小,但是数据都是二进制的,没有任何不同,那么管理500GB就和管理100GB一样简单,而管理5GB空间就和管理100GB也一样简单!这就是分区管理——参考电脑中的C、D、E、F盘
到这里,磁盘的相关知识就讲完了。接下来就要进入文件系统了。
二.Linux文件系统
通过磁盘对数据的管理方式,我们也能够体会到文件系统对文件的管理也是如此——分治思想。文件系统就是一个数组,数组的每一个元素都包含着相应数量大小的文件数据和文件属性,治理一个数组方式就和治理数组中的一个元素一样。文件系统中包括磁盘。
2.1系统结构
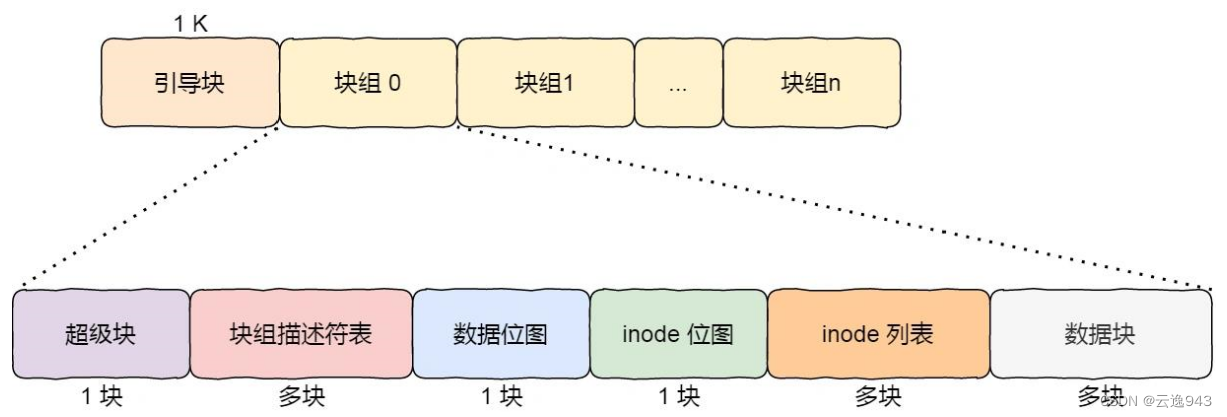
在Linux文件系统中,N个块组形成了一整个文件系统,块组中的每一个小块(相当于一个小型的文件系统)又有其多个小块属性
2.2属性解析:
1.超级块:包含的是当前文件系统中的重要信息:比如文件系统中inode的总个数,整个文件系统的类型大小,文件系统的空间占用度、空闲的块个数、已使用块的字节大小、文件系统的最近一次访问的时间......
2.块组描述符:每个块组都对应一个块组描述符,用来描述块组的相关信息。
3.inode列表:该列表中存放了该组内部所有使用过的和没使用过的inode。inode表示的是每个文件的编号,就像进程的PID一样。
4.inode位图:该位图结构是由N个比特位组成。用于显示在当前文件系统中各个位置比特位的值,能够查看在该位置的空间块是否已经被使用了。
5.数据块:数据块内有若干个小块,每个小块中存放的就是各个文件的数据。所以数据块存放着分组内的所有文件数据。
6.数据位图:该位图作用与inode位图的原理一样,都是用比特位去表示,能够显示在当前文件系统中各个数据块的使用情况。
一个文件=文件的属性+内容。inode块代表的就是文件属性,数据块代表的就是文件内容。所以证明了文件属性和内容是分批存储的。
一个文件中只有一个inode,而inode列表中有多个inode,它的大小是固定的。我们在创建文件时,需要定义文件名,而文件名并不在inode块中存储着。
文件内容存放在数据块中,文件内容会根据文件的类型变化而变化,它的大小是不固定的,会随着文件内容的增多而为其增添多个小数据块。
2.3inode相关块的解析:
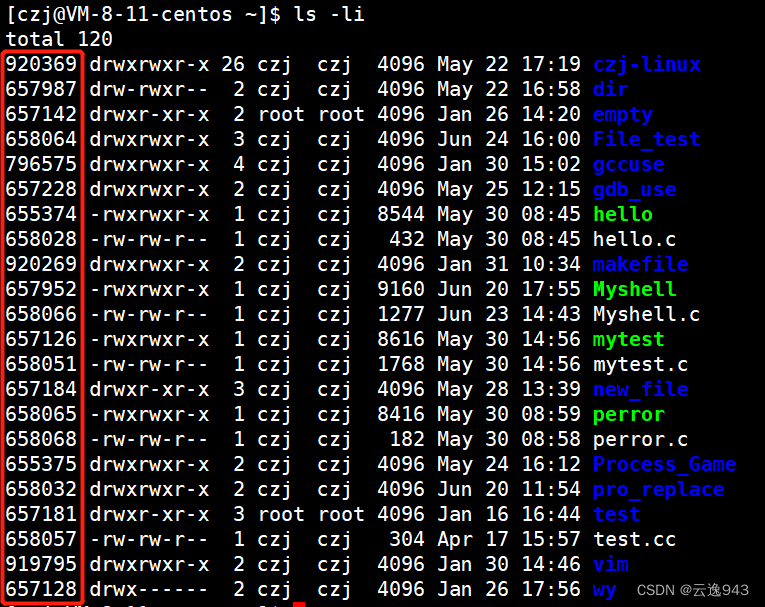
如上图:红框框住的就是各个文件的inode编号。
inode位图的创建原理:因为inode代表的是各个文件,它们都需要一个特有的编号去被系统识别。那么这么多的inode是如何去管理的?于是inode位图诞生了,inode位图是由N个比特位组成的,每个比特位代表着一个inode,假如inode列表中共有1000个inode,那么inode位图中便有1000个比特位,这些比特位初值为0,表示没有被使用。现有200个文件被创建出来,那么系统需要给其分配200个空闲的inode,此时这200个inode所对应的比特位就会从0置为1。于是从位图中我们就能很好的查看整个inode列表中的使用情况。
数据位图的原理也是如此!
总结inode:
1.当我们新建文件的时候,是在inode 位图中的位图结构中找一个未被使用的inode,将该比特位从0置为1,这样该文件就有了一个独有的inode编号了,而正是这个编号,论证了在一目录下不能有两个相同名字的文件,但该文件名并不在inode中存储着! 之后该文件几乎所有的属性就都放在了inode 列表中,该文件也有了其对应的数据块,在向文件中写数据时,第一次分给文件的空间大小大约有4KB,若写入的数据超过4KB,数据块会继续再给其分配一个数据块供其使用。
2.若想要将该文件删除时,直接将inode 位图结构中的该inode号比特位从1置为0,将数据位图结构中的也置为0即可,这样文件就删除成功了! 但是删除的并不彻底,因为我们可以恢复删除的数据,方法就是寻找之前删除过的inode 列表中该文件的编号,找到后,该inode中还存有指向该文件的数据位图结构的比特位,将其0-->1,再根据该inode结构体中的数据块数组成员,便能找到文件相应的数据块及里面的内容,这样就能恢复删除的文件了!

这样就可以解释通:当我们在电脑上下载一个文件的时间要花上十几二十分钟之久:而对于删除文件,系统只需要将inode 位图中相应的比特位从1-->0,数据位图中相应文件的比特位1-->0,就成功删除文件。之后系统若是再于该数据块为新文件添内容时,采用的是堕性管理的方式,将新内容覆盖掉就内容即可——复用数据块!
3.那么我们怎么会知道之前删除过的文件的inode呢?
系统会有相应的日志文件,它会记录在一段时间内新建文件的名字,inode,时间...,删除文件的文件名,inode等信息,我们在寻找的时候可以通过这个快速的找到删除的inode。
2.4数据块的解析:
因为数据块中存放的是当前文件系统中所有文件的数据,那么它肯定会采用分治的思想去管理数据。数据块的底层相当于是一个有15个元素的数组。其中0-10位置的元素都对应有一个小数据块。这是对一般小型文件的处理方式;若是对于一些数据量在不断增大的文件来说,数据块就得一直给该文件提供小数据块供其存储!
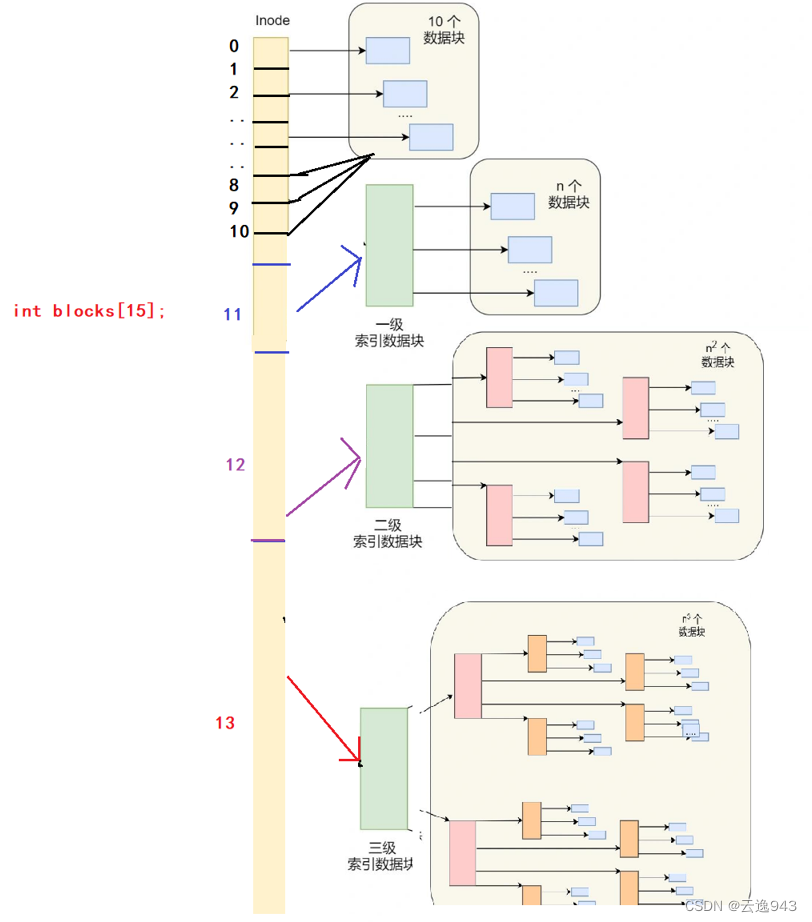
若是该文件一下提供了大约4,5兆的内容,那么索引0-10位置对应的数据块已经放不下了,便会启用二级方案——使用下标第11索引,第11索引管理的小数据块的数量可以有N个了——这是一级索引。这时便会由一级索引给该文件分配数据块空间。
若是文件有几十兆几百兆,连第11索引也放不下,便会开启三级方案——使用下标第12索引,该索引为二级索引——它能够管理的小数据块数量可以有N^2个。
若还不够分配,则会使用第13,14索引为其分配数据块空间,相对应它们能够管理的数据块为N^3,N^4个。