一、信息熵
其中:
:样本属于第i个类别的概率
:总样本数
:集合
中属于第
个类别的样本个数
二、条件熵
其中:
:属性
的取值个数
:选出属性
取值等于
的样本集合
三、信息增益
信息增益指的是在划分数据集前后,类别标签的混乱程度发生的减少的程度,信息增益越大,说明使用该属性进行划分可以获得更多的信息,可以更好地区分不同的类别。
信息增益 = 信息熵 - 条件熵
四、示例
假设我们有一个关于动物的数据集,其中包含7个样本,每个样本有4个属性:是否有翅膀、是否有爪子、是否会游泳和是否有鳞片,以及一个类别标签,表示该动物属于哪一类别(例如,鱼类、鸟类、哺乳类等)。数据集如下:
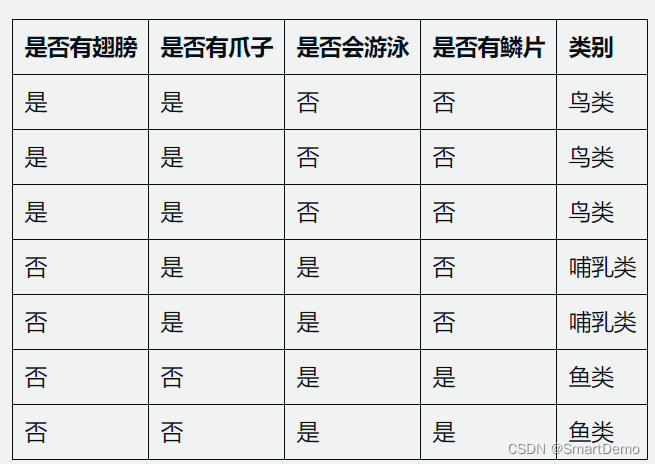
使用ID3算法来构建决策树。
1、计算整个数据集的信息熵,公式为:
2、其中,表示类别的个数,
表示样本属于第
个类别的概率。
在本例中
因此,整个数据集的信息熵为
3、接下来,计算每个属性的信息增益。以是否有翅膀为例,计算其信息增益的公式为:
其中:
表示属性
表示属性
的取值个数
表示选出属性
取值等于
的样本集合
在本例中,是否有翅膀有两个取值,即是和否,因此 。我们可以根据数据集中是否有翅膀的取值,将数据集划分为两个子集:
- 子集1:是否有翅膀=是。该子集有3个样本,其中2个属于鸟类,1个属于哺乳类。
- 子集2:是否有翅膀=否。该子集有4个样本,其中2个属于哺乳类,2个属于鱼类。
计算子集1和子集2的信息熵
因此,计算是否有翅膀的信息增益为: