做了几年Power BI 开发人员,微软最近上发布了Microsoft Fabric, 对它的研究安排起来!
从微软官方中文文档入手
Microsoft Fabric 中的端到端教程 - Microsoft Fabric | Microsoft Learn
Microsoft Fabric 是将 Power BI、Azure Synapse 和 Azure 数据资源管理器中的新组件和现有组件汇集到单个集成环境中.
Fabric 将如下几项集成体验集成到共享的 SaaS 中。
1. 数据工程: Lakehouse、Notebook和Spark Job Definition
2. 数据工厂(Azure Data factory):Lakehouse、Notebook和Spark Job Definition
3. 数据仓库(Data Warehouse): DataWarehouse
4. 数据科学(Data Science): 模型、实验和Notebook
5. Real-Time分析
6. Power BI
从应用场景的角度:Fabric是一个试图用一套交互承接数据工程师、数据科学家以及业务分析师工作流的平台级产品。
2 跟着官方文档将数据工程的操作流程走了一遍,但是有些概念的定义,能读懂文字,但是串不起来。比如: Lakehouse 和Warehouse 的区别,Lakehouse 的 SQL 终结点和Data warehouse 有何不同.
目录
2.1. Lakehouse vs Warehouse(Lakehouse 在官方文档里被翻译为湖屋)
2.2. Lakehouse 的 SQL 终结点和Data warehouse 有何不同?
2.1. Lakehouse vs Warehouse(Lakehouse 在官方文档里被翻译为湖屋)
网上看到如下文章的解释比较好理解 Lakehouse 和warehouse
微软Fabric: AI时代的数据平台 - 知乎 (zhihu.com)
Lakehouse和Warehouse是Fabric中最基本的两个概念。在Fabric中,无论您选择使用Lakehouse还是Warehouse,最终的数据都将以Delta格式的Parquet形式存储在Lake中。这意味着无论您选择哪种方式,最终的数据都将以相同的方式存储。
虽然这些工件在Lake中都是以Delta格式的Parquet存储的,但在您的工作空间中,它们会被标记为不同类型的对象,两者的图标不同,一个是Warehouse表,一个是Lakehouse表。刚开始使用的时候多少有一些理解的门槛。
其次Lakehouse和Warehouse在处理数据的方式上存在一些差异。Lakehouse基于Spark,您可以在notebook中编写代码,支持Python、R、Scala和SparkSQL等语言。而Warehouse则更传统,主要使用SQL查询和存储过程,支持完整的T-SQL。 也是通过上一级的产品分类进行分流。
选择使用Lakehouse还是Warehouse主要取决于您的需求和团队的技能。如果您需要动态、元数据驱动的代码,或者需要处理复杂的数据转换和大数据问题,那么Spark的Lakehouse可能是更好的选择。如果您已经有了大量的T-SQL代码,或者需要复杂的事务支持,那么Warehouse可能更适合您。无论您选择哪种方式,都需要使用相应的方式来维护和更新表。也就是说,如果您创建了一个Lakehouse对象,那么您就不能使用T-SQLWarehouse对象来插入数据到Lakehouse对象中,反之亦然。
微软官方的技术文档也给出了详细的技术指标,帮助团队选择时做参考:
| Warehouse | Lakehouse | Power BI Data Mart | |
|---|---|---|---|
| 数据量 | 无限 | 无限 | 100GB |
| 数据类型 | 结构化 | 无结构、半结构、结构化 | 结构化 |
| 主要开发人员角色 | 数据仓库开发者、SQL工程师 | 数据工程师、数据科学家 | 非开发者 |
| 主要开发人员技能集 | SQL | Spark (Scala, PySpark, Spark SQL, R) | 无代码, SQL |
| 数据由...组织 | 数据库、模式和表 | 文件夹和文件、数据库和表 | 数据库、表、查询 |
| 读操作 | Spark、T-SQL | Spark、T-SQL | Spark、T-SQL、Power BI |
| 写操作 | T-SQL | Spark (Scala, PySpark, Spark SQL, R) | Dataflow、T-SQL |
| 多表事务 | 是 | 否 | 否 |
| 主要开发接口 | SQL脚本 | Spark笔记本、Spark作业定义 | Power BI |
| 安全性 | 对象级别(表、视图、函数、存储过程等)、列级别、行级别、DDL/DML | 行级别、表级别(使用T-SQL时)、Spark无 | 内置RLS编辑器 |
| 可通过快捷方式访问数据 | 是(间接通过湖仓库) | 是 | 否 |
| 可作为快捷方式的来源 | 是(表) | 是(文件和表) | 否 |
| 可跨项查询 | 是,跨湖仓库和仓库表查询 | 是,跨湖仓库和仓库表查询;跨湖仓库查询(包括使用Spark的快捷方式) | 否 |
2.2. Lakehouse 的 SQL 终结点和Data warehouse 有何不同?
两者在 Microsoft Fabric 工作区中的名称不同:
SQL 终结点在 “类型 ”列下标记为“SQL 终结点”,
Synapse Data Warehouse或 Warehouse 在“类型”列下标记为“仓库”。
每个 Lakehouse 都有一个自动生成的 SQL 终结点,可通过熟悉的 SQL 工具(如 SQL Server Management Studio、Azure Data Studio、Microsoft Fabric SQL 查询编辑器)利用。而Data warehouse支持事务、DDL 和 DML 查询。

下图介绍 Microsoft Fabric 中仓库和 SQL 终结点之间的差异。
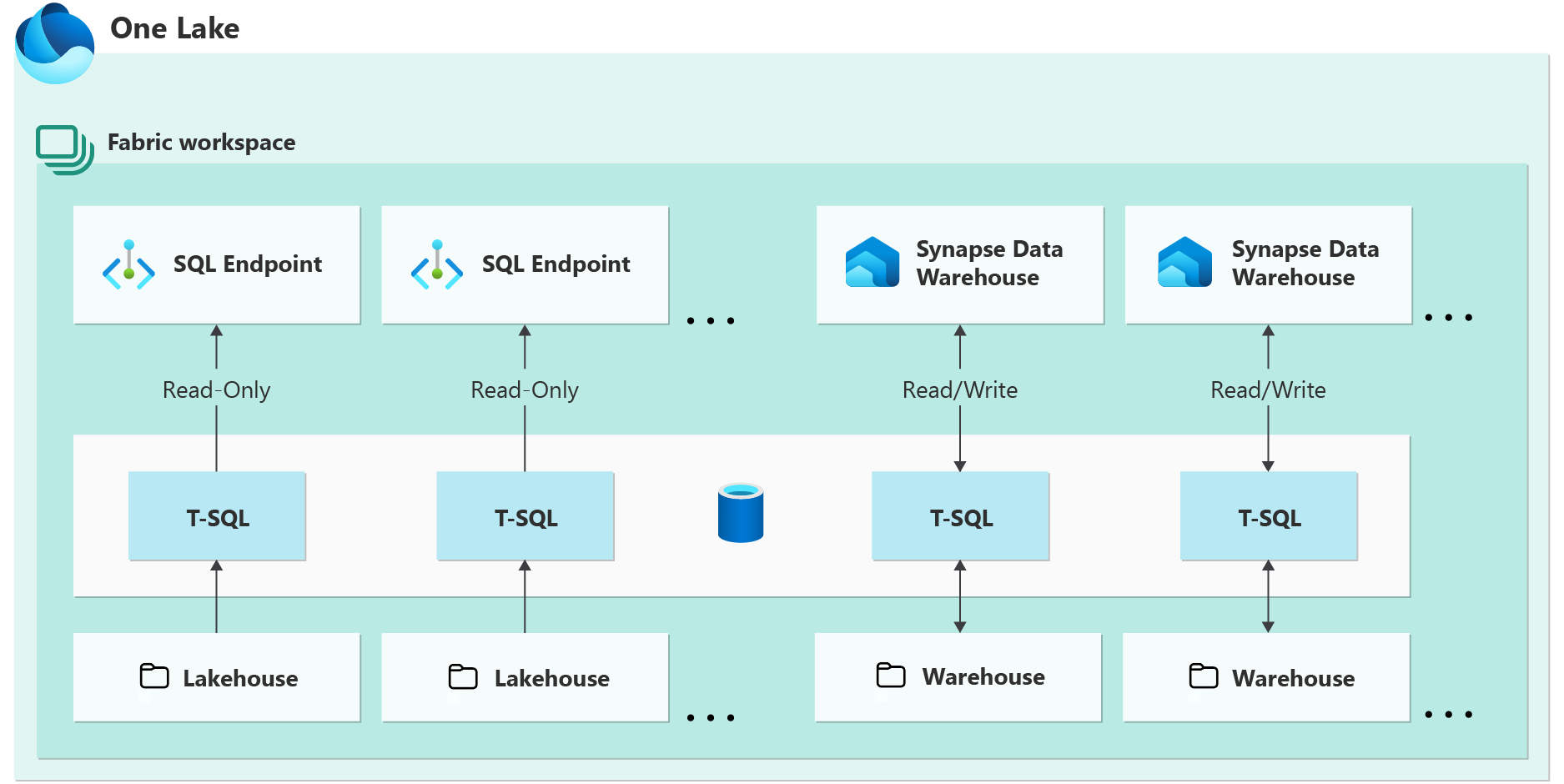
SQL 终结点是从 Microsoft Fabric 中的 Lakehouse 创建时自动生成的只读仓库。 在 Lakehouse 中通过 Spark 创建的 Delta 表可自动在 SQL 终结点中发现为表。 SQL 终结点使数据工程师能够基于 Lakehouse 中的物理数据构建关系层,并使用 SQL 连接字符串将其公开给分析和报告工具。 然后,数据分析师可以使用 T-SQL 通过仓库体验访问 Lakehouse 数据。 使用 SQL 终结点设计仓库以满足 BI 需求和提供数据。
Synapse Data Warehouse 或 Warehouse 是“传统”数据仓库,支持企业数据仓库等完整事务性 T-SQL 功能。 与自动创建表和数据的 SQL 终结点不同,可以使用 Microsoft Fabric 门户或 T-SQL 命令完全控制在数据仓库中创建 表、加载、转换和查询数据。
参考如下文章查看如何在SQL 终结点和 数据仓库中查询SQL 查询 SQL 终结点或仓库 - Microsoft Fabric | Microsoft Learn
今天就到这里,后面慢慢研究,慢慢更新,Stay tuned.