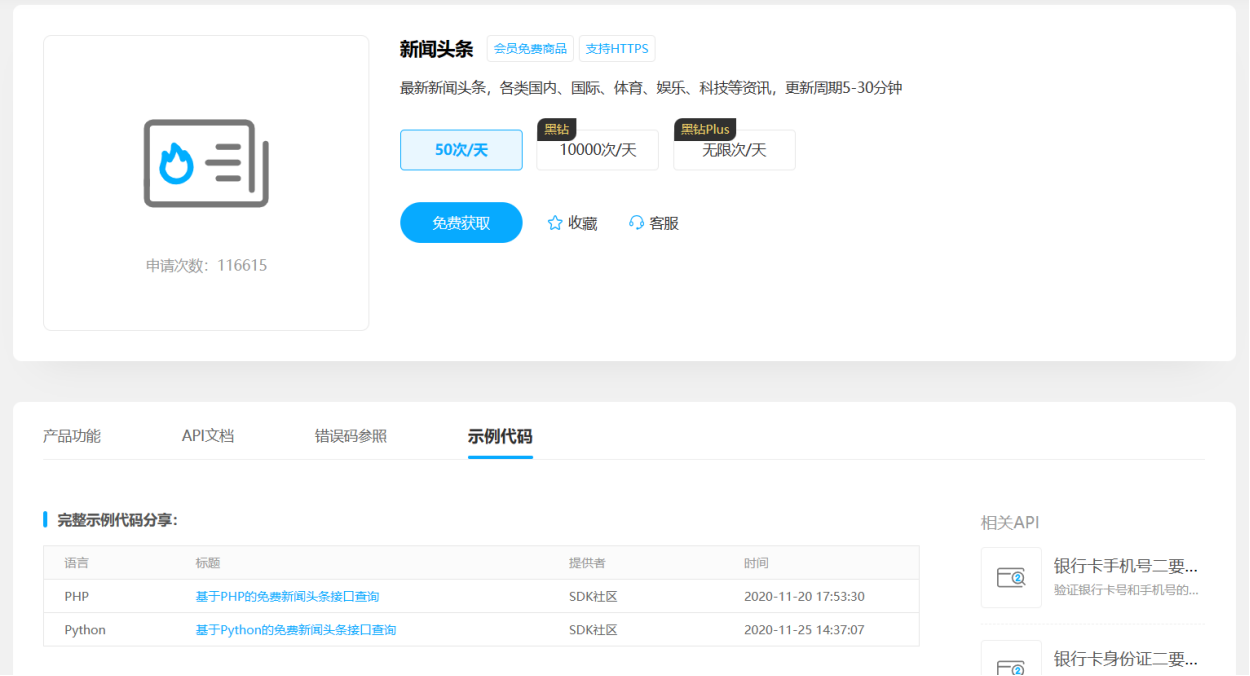
调用聚合数据API获取新闻头条
- 1.作者介绍
- 2.API和聚合数据API的介绍
- 2.1 API简介
- 2.2 聚合数据API
- 3.实验过程介绍,完整实验代码,测试结果
- 3.1参数说明
- 3.2获取代码
- 3.3代码实现
- 3.4问题与分析
1.作者介绍
姚嘉欣,男,西安工程大学电子信息学院,2022级研究生
研究方向:机器视觉与人工智能
电子邮件:2390410432@qq.com
张思怡,女,西安工程大学电子信息学院,2022级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:981664791@qq.com
2.API和聚合数据API的介绍
2.1 API简介
API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
API就是接口,就是通道,负责一个程序和其他软件的沟通,本质是预先定义的函数
2.2 聚合数据API
第一步,创建账号

第二步,进入个人中心

第三步,从数据中心进入我的API

第四步,申请新数据
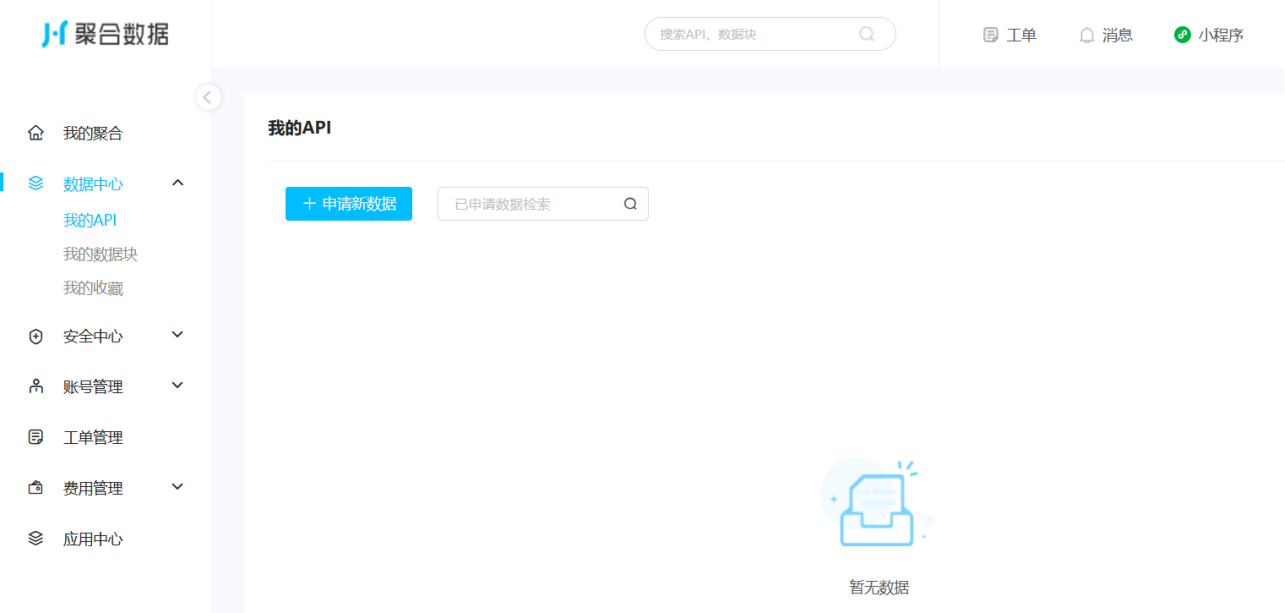
第五步,搜索新闻头条
第六步,申请使用新闻头条
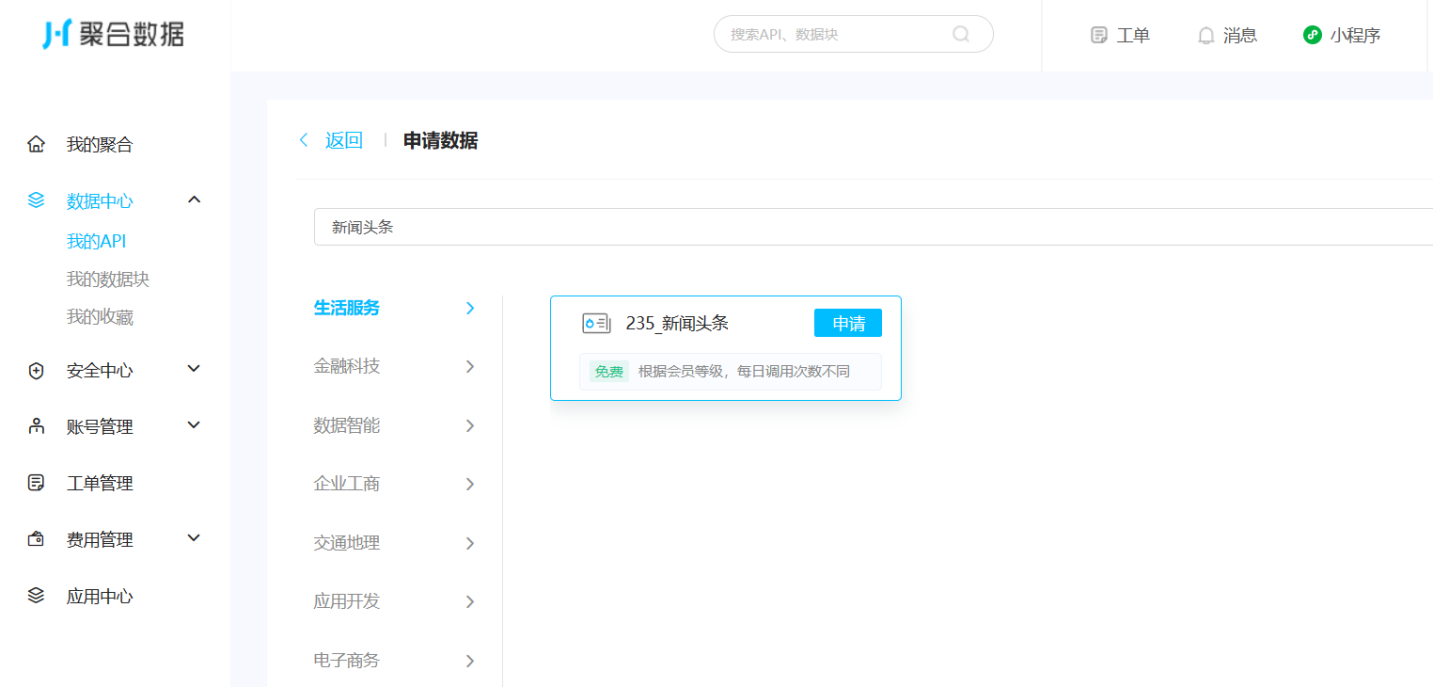
第七步,获取自己的key
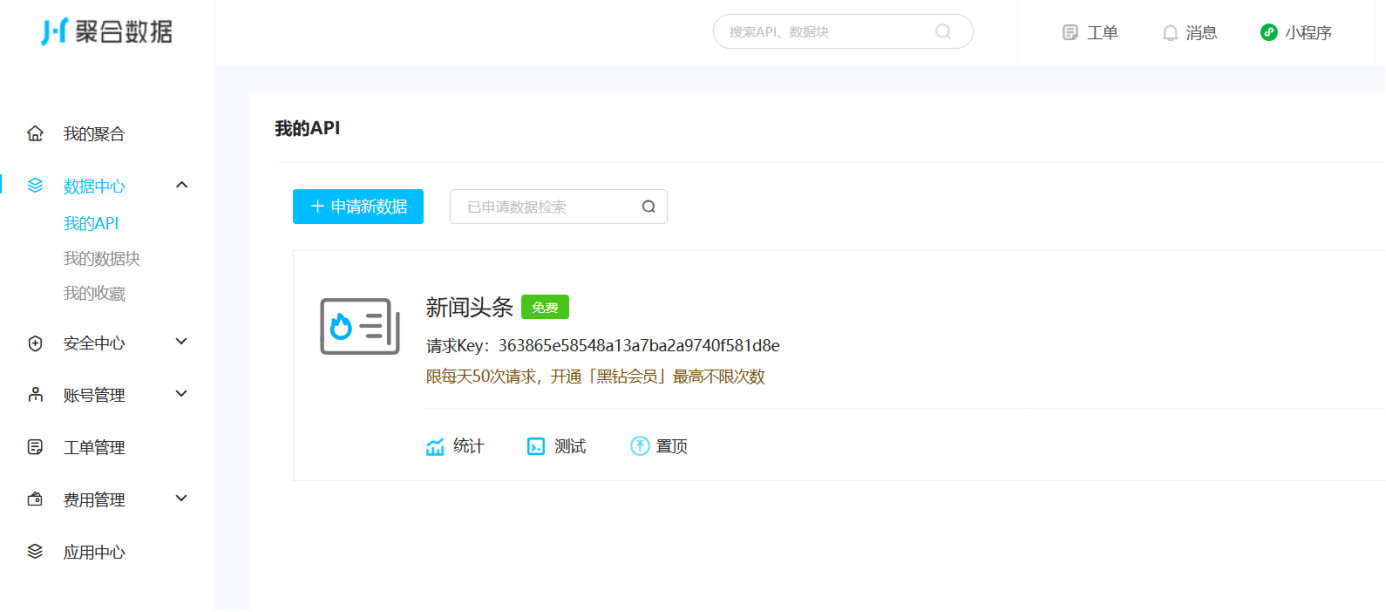
3.实验过程介绍,完整实验代码,测试结果
3.1参数说明
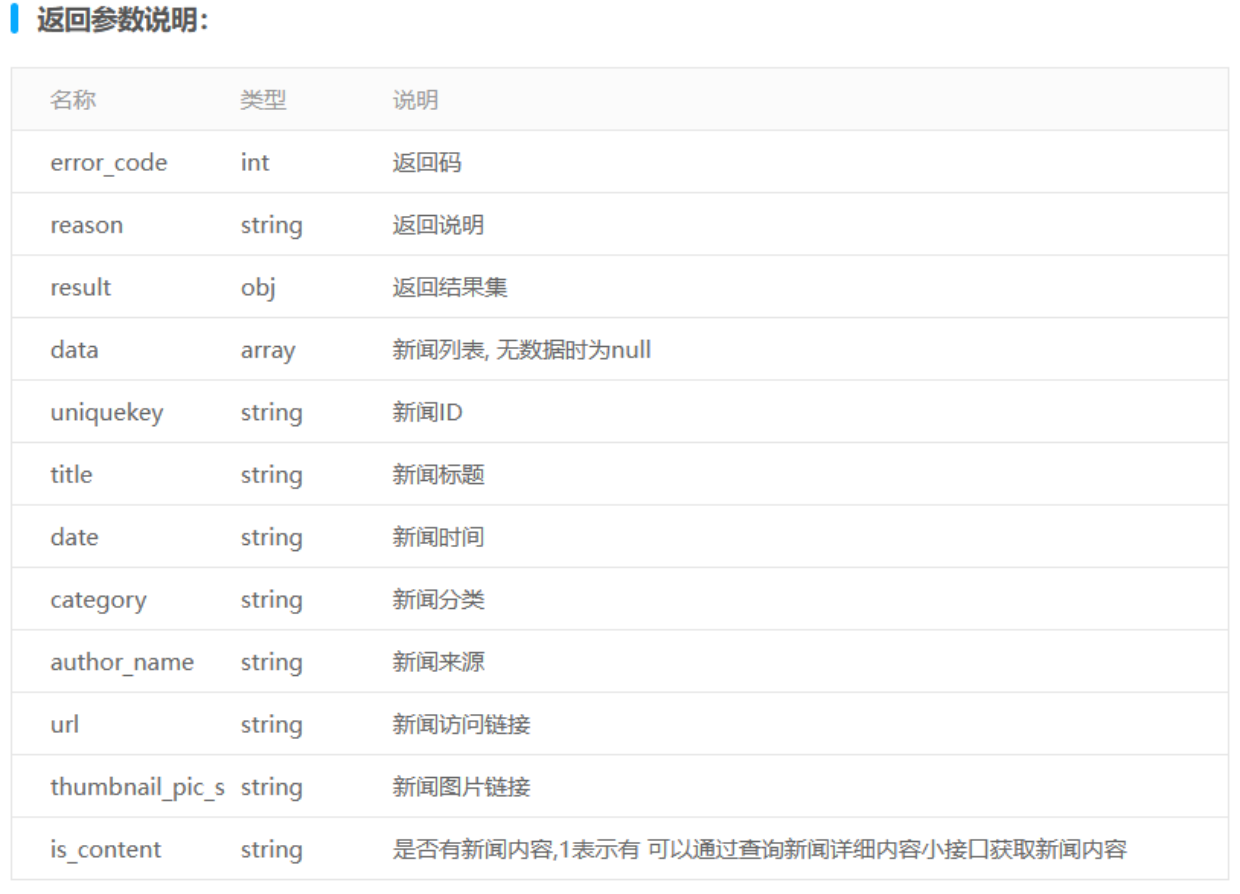
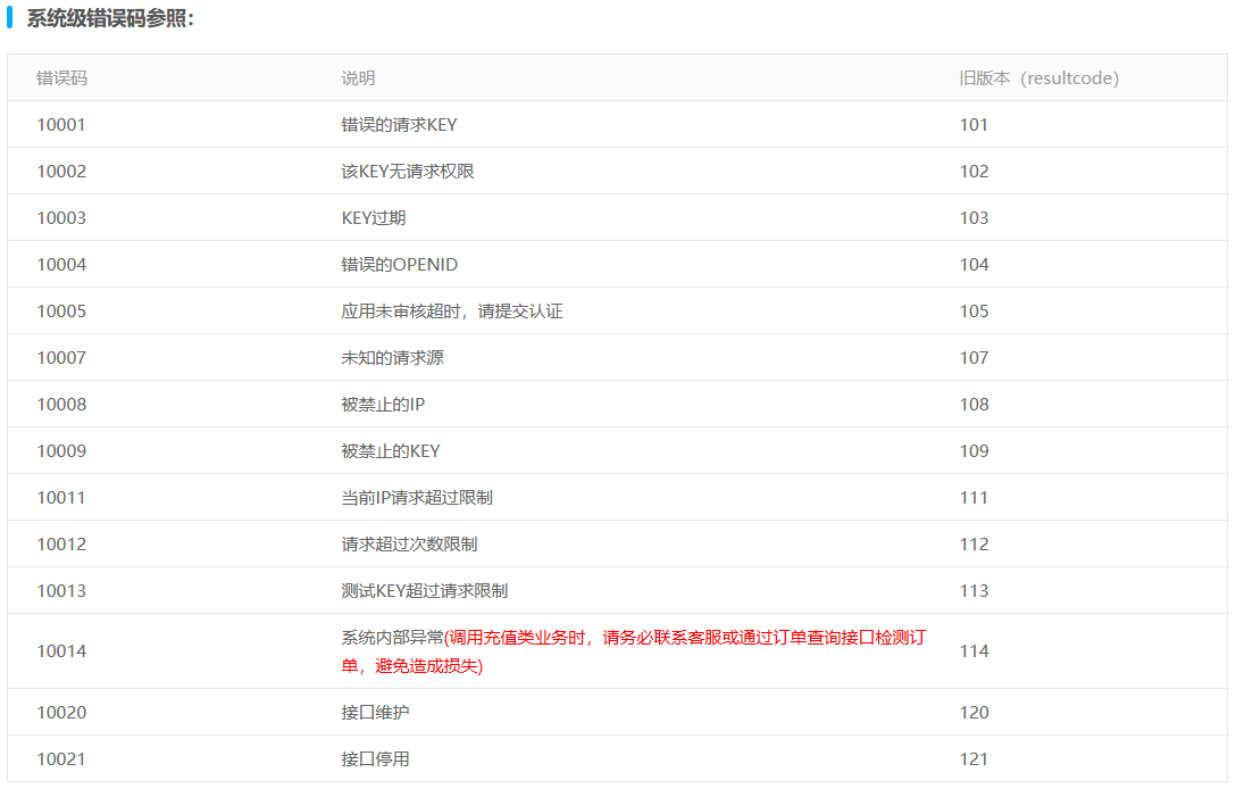
3.2获取代码
3.3代码实现
#导入 urllib.parse、urllib.request 和 json 模块,这些模块分别提供了 URL 解析、HTTP 请求和 JSON 解析的功能。
import urllib.parse, urllib.request, json
#定义了一个变量 url,表示要访问的 API 接口的 URL 地址
url = 'http://v.juhe.cn/toutiao/index'
#定义了一个字典类型的变量 params,包含了请求参数 type 和 key,type 表示要获取的新闻类型,key 是需要申请的接口API接口请求Key。
params = {
"type": "keji", # 头条类型,top(头条,默认),shehui(社会),guonei(国内),guoji(国际),yule(娱乐),tiyu(体育)junshi(军事),keji(科技),caijing(财经),shishang(时尚)
"key": "363865e58548a13a7ba2a9740f581d8e", # 您申请的接口API接口请求Key
"page": "5", #当前页数, 默认1, 最大50
"page_size": "5", #每页返回条数, 默认30 , 最大30
"is_filter": "0", # 是否只返回有内容详情的新闻, 1:是, 默认0
}
#使用 urlencode 方法将请求参数编码为 URL 查询字符串,并使用 encode 方法将其编码为 bytes。
querys = urllib.parse.urlencode(params).encode('utf-8')
#创建一个 urllib.request.Request 对象,其中 data 属性设置为编码后的查询字符串。这样就创建了一个 POST 请求,请求的内容就是查询字符串。
request = urllib.request.Request(url, data=querys)
#发送请求并读取响应,response 变量保存了响应对象,read 方法读取出响应的内容并赋值给 content 变量。
response = urllib.request.urlopen(request)
content = response.read()
#判断 content 是否为空,如果不为空则尝试将其解析为 JSON 格式。如果解析成功,则从结果中获取 error_code 字段,如果值为 0,则说明请求成功,解析出其中的新闻标题、时间和链接信息并输出;否则输出请求失败的原因。
if (content):
try:
result = json.loads(content.decode('utf-8'))
error_code = result['error_code']
if (error_code == 0):
data = result['result']['data']
for i in data:
# 更多字段可参考接口文档
print("新闻标题:%s\n新闻时间:%s\n新闻链接:%s\n\n" % (i['title'], i['date'], i['url']))
else:
print("请求失败:%s %s" % (result['error_code'], result['reason']))
except Exception as e:
print("解析结果异常:%s" % e)
else:
# 可能网络异常等问题,无法获取返回内容,请求异常
print("请求异常")
#如果解析过程中发生异常,则输出异常信息。
#如果 content 为空,则说明请求过程中出现了异常,输出请求异常。
3.4问题与分析
问题一
原始代码是使用Python 2.x的urllib和urllib2库来访问一个头条新闻API,并打印出返回的结果。在Python 3.x中,这些库已经被合并为一个名为"urllib.request"的库,所以需要稍作修改才能在Python 3.x中运行


问题二
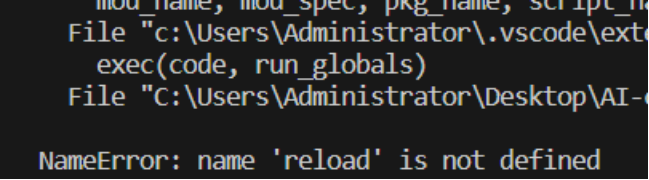
在Python 3.x中,也不需要再使用"reload"函数来设置默认编码了,因为所有字符串都默认使用Unicode编码。


问题三

在Python 3.x中,urllib.urlencode()已经被移除,取而代之的是urllib.parse.urlencode()函数。如果你的代码运行环境是Python 3.x版本,那么需要将代码中的urllib.urlencode()替换为urllib.parse.urlencode()。
问题四
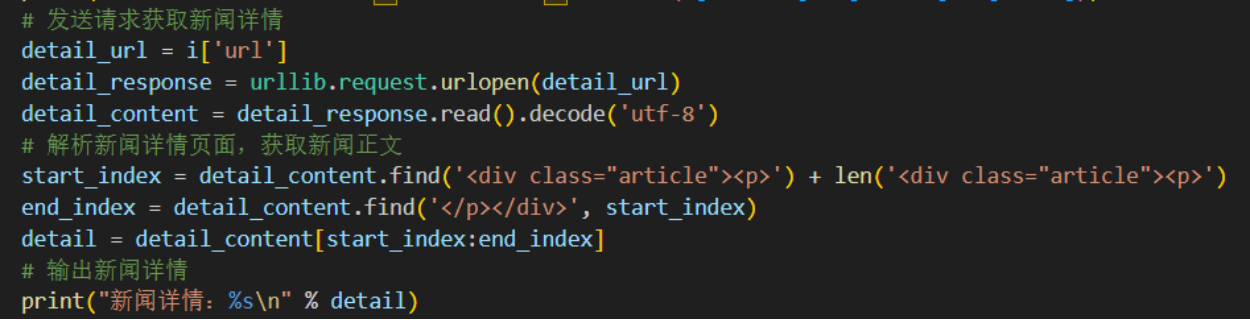
代码查看的只有新闻的标题和时间,以及网页,只能通过点击网页去查看新闻的详细内容。修改代码,使其显示新闻详细内容。
import urllib.parse, urllib.request, json
#定义了一个变量 url,表示要访问的 API 接口的 URL 地址
url = 'http://v.juhe.cn/toutiao/index'
#定义了一个字典类型的变量 params,包含了请求参数 type 和 key,type 表示要获取的新闻类型,key 是需要申请的接口API接口请求Key。
params = {
"type": "top", # 头条类型,top(头条,默认),shehui(社会),guonei(国内),guoji(国际),yule(娱乐),tiyu(体育)junshi(军事),keji(科技),caijing(财经),shishang(时尚)
"key": "363865e58548a13a7ba2a9740f581d8e", # 您申请的接口API接口请求Key
"page": "1", #当前页数, 默认1, 最大50
"page_size": "3", #每页返回条数, 默认30 , 最大30
"is_filter": "0", # 是否只返回有内容详情的新闻, 1:是, 0:否,默认为0,返回所有新闻的详情信息。
}
#使用 urlencode 方法将请求参数编码为 URL 查询字符串,并使用 encode 方法将其编码为 bytes。
querys = urllib.parse.urlencode(params).encode('utf-8')
#创建一个 urllib.request.Request 对象,其中 data 属性设置为编码后的查询字符串。这样就创建了一个 POST 请求,请求的内容就是查询字符串。
request = urllib.request.Request(url, data=querys)
#发送请求并读取响应,response 变量保存了响应对象,read 方法读取出响应的内容并赋值给 content 变量。
response = urllib.request.urlopen(request)
content = response.read()
#判断 content 是否为空,如果不为空则尝试将其解析为 JSON 格式。
if (content):
try:
result = json.loads(content.decode('utf-8'))
error_code = result['error_code']
if (error_code == 0):
data = result['result']['data']
for i in data:
# 更多字段可参考接口文档
print("新闻标题:%s\n新闻时间:%s\n新闻链接:%s\n" % (i['title'], i['date'], i['url']))
# 发送请求获取新闻详情
detail_url = i['url']
detail_response = urllib.request.urlopen(detail_url)
detail_content = detail_response.read().decode('utf-8')
# 解析新闻详情页面,获取新闻正文
start_index = detail_content.find('<div class="article"><p>') + len('<div class="article"><p>')
end_index = detail_content.find('</p></div>', start_index)
detail = detail_content[start_index:end_index]
# 输出新闻详情
print("新闻详情:%s\n" % detail)
else:
print("请求失败:%s %s" % (result['error_code'], result['reason']))
except Exception as e:
print("解析结果异常:%s" % e)
else:
# 可能网络异常等问题,无法获取返回内容,请求异常
print("请求异常")





![[Web程序设计]实验: Web基础](https://img-blog.csdnimg.cn/b99ce50c3aa548509edc657e14be2860.jpeg)