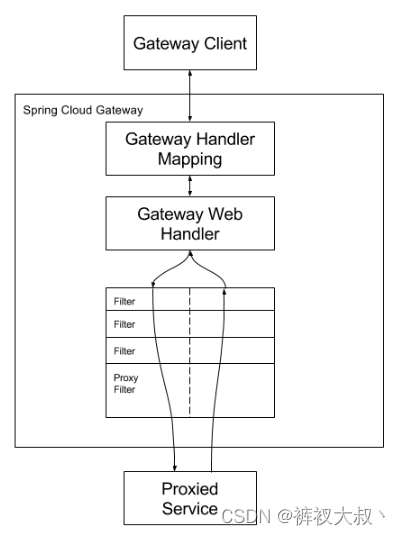
目录
1.官方文档解释
1.1原文参照
1.2中文解释
2.参考代码
3.一些参考使用
3.1生成网络
3.2 感知机的实现
3.3组装网络层
1.官方文档解释
1.1原文参照
A sequential container. Modules will be added to it in the order they are passed in the constructor. Alternatively, an of modules can be passed in. The method of accepts any input and forwards it to the first module it contains. It then “chains” outputs to inputs sequentially for each subsequent module, finally returning the output of the last module.
OrderedDictforward()SequentialThe value a provides over manually calling a sequence of modules is that it allows treating the whole container as a single module, such that performing a transformation on the applies to each of the modules it stores (which are each a registered submodule of the ).
SequentialSequentialSequentialWhat’s the difference between a and a torch.nn.ModuleList? A is exactly what it sounds like–a list for storing s! On the other hand, the layers in a are connected in a cascading way.
SequentialModuleListModuleSequential
1.2中文解释
即是说
这是顺序容器。 模块将按照它们在构造函数。或者,模块可以是传入。接受任何的方法输入并将其转发到它包含的第一个模块。然后它 “链”输出到每个后续模块的顺序输入,最后返回最后一个模块的输出。 通过手动调用序列提供的值模块是它允许将整个容器视为 单个模块,这样对执行转换适用于它存储的每个模块(这些模块每个的注册子模块)。
简单说来就是:
Sequential 本质是一个模块,模块中可以继续添加模块。这意味着我们可以在 Sequential 中添加其它的模块。添加完成后,Sequential 会将这些模块组成一个流水线,输入将依次通过这些模块得到一个输出。
2.参考代码
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))3.一些参考使用
3.1生成网络
生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层, 然后是一个具有10个隐藏单元且不带激活函数的全连接输出层。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
net(X)
3.2 感知机的实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);训练过程的实现与softmax回归完全相同, 这种模块化设计使我们能够将与模型架构有关的内容独立出来。
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
3.3组装网络层
两个参数, 一个用于表示权重,另一个用于表示偏置项。 在此实现中,使用修正线性单元作为激活函数。 该层需要输入参数:in_units和units,分别表示输入数和输出数。
class MyLinear(nn.Module):
def __init__(self, in_units, units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, units))
self.bias = nn.Parameter(torch.randn(units,))
def forward(self, X):
linear = torch.matmul(X, self.weight.data) + self.bias.data
return F.relu(linear)linear = MyLinear(5, 3)
linear.weight
linear(torch.rand(2, 5))
net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1))
net(torch.rand(2, 64))