1.flink入门
官方定义:Apache Flink是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算,Flink能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
简言之,Flink是一个分布式的计算处理引擎
-
分布式:「它的存储或者计算交由多台服务器上完成,最后汇总起来达到最终的效果」;
-
实时:处理速度是毫秒级或者秒级的;
-
计算:可以简单理解为对数据进行处理,比如清洗数据(对数据进行规整,取出有用的数据);

a.有边界和无边界
学到Flink了,想必消息队列大家肯定有用过吧?那我们是怎么用消息队列的呢?Producer生产数据,发给Broker,Consumer消费,完事。
在消费的时候,我们需要管什么Producer什么时候发消息吗?不需要吧。反正来一条,我就处理一条,没毛病吧。
这种没有做任何处理的消息,默认就是无边界的。
那有边界就很好理解了:无边界的基础上加上条件,那就是有边界的。加什么条件呢?比如我要加个时间:我要消费从8月8号到8月9号的数据,那就是有边界的。
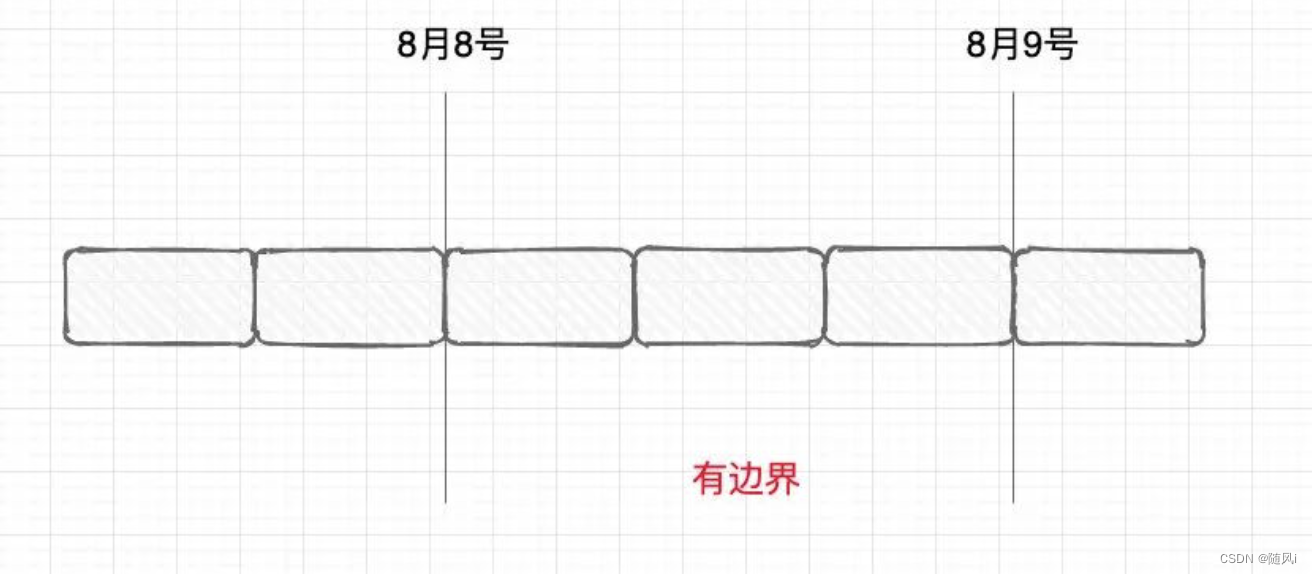
什么时候用无边界,什么时候用有边界?那也很好理解。我做数据清洗:来一条,我处理一条,这种无边界的就好了。我要做数据统计:每个小时的pv(page view)是多少,那我就设置1小时的边界,攒着一小时的数据来处理一次。
在Flink上,设置“边界”这种操作叫做开窗口(Windows),窗口可简单分为两种类型:
- 时间窗口(
TimeWindows):按照时间窗口进行聚合,比如上面所讲得攥着一个小时的数据处理一次。 - 计数窗口(
CountWindows):按照指定的条数来进行聚合,比如每来了10条数据处理一次。
不仅如此,在Flink使用窗口聚合的时候,还考虑到了数据的准确性问题。比如说:现在我在11:06分产生了5条数据,在11:07分 产生了4条数据,我现在是按每分钟的维度来进行聚合计算。
理论上来讲:Flink应该是在06分聚合了5条数据,在07分聚合了4条数据。但是,可能由于网络的延迟性等原因,导致06分的3条数据在07分时Flink才接收到。如果不做任何处理,那07分有可能处理了7条条数据。
某些需要准确结果的场景来说,这就不太合理了。所以Flink可以给我们指定”时间语义“,不指定默认是「数据到Flink的时间」Processing Time来进行聚合处理,可以给我们指定聚合的时间以「事件发生的时间」Event Time来进行处理。
事件发生的时间指的就是:日志真正记录的时间
虽然指定了聚合的时间为「事件发生的时间」Event Time,但还是没解决数据乱序的问题(06分产生了5条数据,实际上06分只收到了3条,而剩下的两条在07分才收到,那此时怎么办呢?在06分时该不该聚合,07分收到的两条06分数据怎么办?)
Flink又可以给我们设置水位线(waterMarks),Flink意思就是:存在网络延迟等情况导致数据接收不是有序,这种情况我都能理解。你这样吧,根据自身的情况,你可以设置一个「延迟时间」,等延迟的时间到了,我再聚合统一聚合。
比如说:现在我知道数据有可能会延迟一分钟,那我将水位线waterMarks设置延迟一分钟。
解读:因为设置了「事件发生的时间」Event Time,所以Flink可以检测到每一条记录发生的时间,而设置了水位线waterMarks设置延迟一分钟,等到Flink发现07分:59秒的数据来到了Flink,那就确信06分的数据都来了(因为设置了1分钟延迟),此时才聚合06分的窗口数据。
b.有状态
什么是有状态,什么是无状态?
无状态我们可以简单认为:每次的执行都不依赖上一次或上N次的执行结果,每次的执行都是独立的。
有状态我们可以简单认为:执行需要依赖上一次或上N次的执行结果,某次的执行需要依赖前面事件的处理结果。
比如,我们现在要统计文章的阅读PV(page view),现在只要有一个点击了文章,在Kafka就会有一条消息。现在我要在流式处理平台上进行统计,那此时是有状态的还是无状态的?
假设我们要在Storm做,那我们可能将每次的处理结果放到一个“外部存储”中,然后基于这个“外部存储”进行计算(这里我们不用Storm Trident),那此时Storm是无状态的。
比如说:我存储将每次得到的数据存储到 Redis中,来一条数据,我就先查一下Redis目前的值是多少,跟Redis的值和现在的值做一次累加就完事了。
假设要在Flink做,Flink本身就提供了这种功能给我们使用,我们可以依赖Flink的“存储”,将每次的处理结果交由Flink管理,执行计算的逻辑。
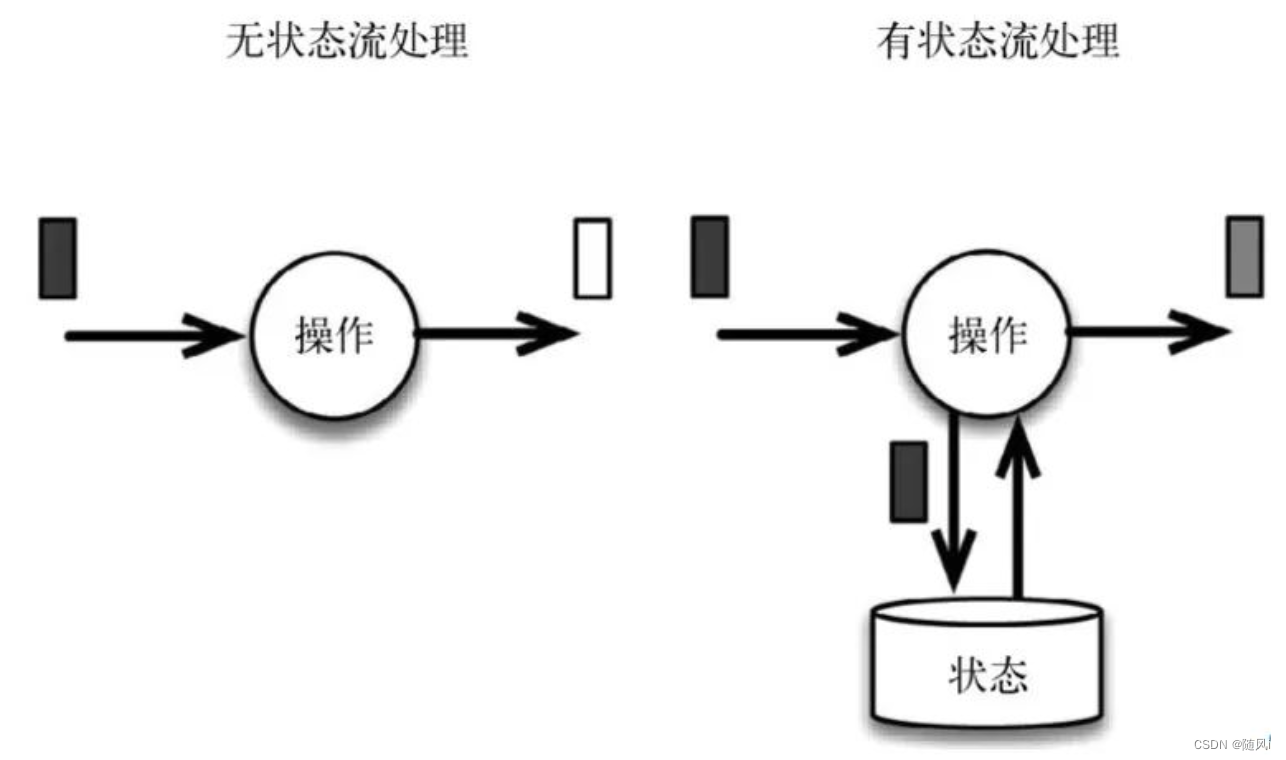
可以简单的认为:Flink本身就给我们提供了”存储“的功能,而我们每次执行是可以依赖Flink的”存储”的,所以它是有状态的。
什么是有状态计算
有状态计算指的就是程序在计算过程中,需要将数据(状态)存储在本地存储或者外部存储中,以便下一次进行计算时获取使用,比如统计Nginx某个地址的调用次数,需要在每次计算时 不停的进行累加,并且将结果进行存储以便下次累加获取使用。
使用状态的场景
- 去重:上游系统数据会重复,落到下游系统时根据主键进行去重,需要将所有主键都记录下来,新的数据到来时需要判断主键是否已经存在;
- 窗口计算:每分钟Nginx的访问次数,09:00~09:01这个窗口的数据需要先存入内存,等到09:01到来时将数据进行输出;
- 机器学习/深度学习:训练的模型和当前模型的参数也是一种状态;
- 访问历史数据:例如和昨天数据进行对比,如果每次从外部去读消耗资源比较大,所以可以把这些历史数据放入状态中做对比;
为什么需要状态管理?
流式作业一般需要7*24小时不间断的运行,在宕机恢复时需要保证数据不丢失,在计算时要保证计算结果准确,数据不重复,恰好计算1次,为了达到上述这些目的,我们就需要对 程序运行过程中的状态进行管理。
为什么离线计算中不提状态,实时计算老是提到状态这个概念?状态到底在实时计算中解决了什么问题?
其实在实时计算中的状态的功能主要体现在任务可以做到失败重启后没有数据质量、时效问题。还不明白?我们来对比一下一个离线任务和实时任务的在任务失败重启时候的区别;
- 离线任务失败重启:重新读一遍输入数据,然后重新计算一遍,没有啥大问题,大不了产出慢一些;
- 实时任务失败重启:实时任务一般都是 7x24 小时 long run 的,挂了之后,就会有以下两个问题。首先给一个实际场景:一个消费上游 Kafka,使用 Set去重计算 DAU 的实时任务;
- 数据质量问题:当这个实时任务挂了之后恢复,Set空了,这时候任务再继续从上次失败的 Offset 消费 Kafka 产出数据,则产出的数据就是错误数据了。这时候小伙伴可能会提出疑问,计算 DAU 场景的话,这个任务挂了我重新从今天 0 点开始消费 Kafka 不就得了?
- 数据时效问题:你要记得,你一定要记得,你是一个实时任务,产出的指标是有时效性(主要是时延)要求的。你可以从今天 0 点开始重新消费,但是你回溯数据也是需要时间的。举例:中午 12 点挂了,实时任务重新回溯 12 个小时的数据能在 1 分钟之内完成嘛?大多数场景下是不能的!一般都要回溯几个小时,这就是实时场景中的数据时效问题;
Flink状态分类
| Managed State | RawState | RawState |
|---|---|---|
| 状态管理方式 | Flink Runtime自动管理:自动存储、自动恢复、内存优化 | 用户自己管理,需要自己序列化 |
| 状态数据结构 | 已知的数据结构:Value、List、Map等 | 字节数组byte[] |
| 推荐使用场景 | 大多数情况下可以使用 | 自定义Operator时使用 |
Managed State分类
Managed State主要分为两类:
- Keyed State
- Operator State
Keyed State特点
- 只能使用在KeyedStream算子中
- 一个Key对应一个State,一个Operator实例可以处理多个key,访问相应的多个State
- 随着并发改变,State会随着key在多个Operator实例间迁移
- 需要通过RuntimeContext访问,因此Operator必须是一个RickFunction
- 支持多样化的数据结构:ValueState、ListState、ReducingState、AggregatingState、MapState
Operator State特点
- 适用所有的算子,常用于source
- 一个Operator实例对应一个State
- 并发改变时,有两种重新分配方式可以选择:均匀分配或者合并后每个得到全量
- 实现CheckpointedFunction或ListCheckpointed接口
- 支持的数据结构:ListState
Keyed Stated具体分类
- ValueState:存储单个值
- MapState:数据类型为Map,在State上有put和remove等方法
- ListState:数据类型为List
- ReducingState:Reducing的add方法不是将当前元素追加到列表,而是直接更新进Reducing的结果中
- AggregatingState:AggregatingState和ReducingState的区别是在访问接口,Reducing的add和get的元素都是同一个类型,但是Aggregating输入的是IN,输出的是OUT
如何保存状态
保存状态依赖Checkpoint和Savepoint机制,Checkpoint是在程序运行过程中自动触发,Savepoint需要手动触发。
如果从Checkpoint进行恢复,需要保证数据源支持重发,同时Flink提供了两种一致性语义(恰好一次或者至少一次)。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(1000L); CheckpointConfig checkpointConfig = env.getCheckpointConfig(); checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); checkpointConfig.setMinPauseBetweenCheckpoints(500L); checkpointConfig.setCheckpointTimeout(60000L); checkpointConfig.setMaxConcurrentCheckpoints(1); checkpointConfig.setExternalizedCheckpointCleanup(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); |
- enableCheckpointing:设置Checkpoint的间隔时间,单位ms
- setCheckpointingMode:设置Checkpoint的模式,如果设置了EXACTLY_ONCE,则需要保证Barries对齐,保证消息不会丢失也不会重复
- setMinPauseBetweenCheckpoints:设置两次Checkpoint中间的等待时间,通过这个可以防止Checkpoint太过频繁导致业务处理速度下降
- setCheckpointTimeout:设置Checkpoint的最大超时时间,上面代码表示如果Checkpoint超过1min,则超时失败
- setMaxConcurrentCheckpoints:表示同时有多少个Checkpoint在做快照
- setExternalizedCheckpointCleanup:用于设置任务在Cancel时是否需要保留当前的Checkpoint,RETAIN_ON_CANCELLATION当作业取消时保留作业的checkpoint,该情况下需要手动清除该作业 的Checkpoint,DELETE_ON_CANCELLATION作业取消时删除作业的Checkpoint,仅当作业失败时保存Checkpoint
Checkpoint和Savepoint区别
| Checkpoint | Savepoint | |
|---|---|---|
| 触发管理方式 | Flink自动触发管理 | 用户手动触发管理 |
| 用途 | Task发生异常时快速恢复 | 有计划地进行备份,作业停止后可以恢复,比如修改代码、调整并发 |
| 特点 | 轻量;自动从故障恢复;作业停止后默认清除 | 持久;标准格式存储,允许代码或配置发生改变;手动触发从Savepoint的恢复 |
那Flink是把这些有状态的数据存储在哪的呢?
主要有三个地方:
- 内存 (MemoryStateBackend)
- 文件系统(FsStateBackend)
- 本地数据库 (RocksDBStateBackend)
MemoryStateBackend在Checkpoint是基于内存保存状态,该状态存储在TaskManager节点(执行节点)的内存中,因此会受到内存容量的限制(默认5M),同时还要受到akka.framesize的限制 (默认10M)。Checkpoint保存在JobManager内存中,因此总大小不能超过JobManager的内存,只推荐本次测试或无状态的作业使用。
FsStateBackend是基于文件系统保存状态的,状态依旧保存在TaskManager中,因此State不能超过单个TaskManager的内存容量,Checkpoint存储在外部文件系统中(比如HDFS或本地),打破了JobManager内存的限制, 但是总大小不能超过文件系统的容量,推荐状态小的作业使用。
RocksDBStateBackend,首先RocksDB是一个K-V的内存存储系统,当内存快满时,会写入到磁盘,RocksDB也是唯一支持增量Checkpoint的Backend,这说明用户不需要将所有状态都写入进去,可以 只将增量改变的状态写入即可。Checkpoint存储在外部文件系统,因此State不能超过单个TaskManager内存+磁盘总和,单key最大为2GB,总大小不超过文件系统的容量即可,推荐大状态作业使用。
如果假设Flink挂了,可能内存的数据没了,磁盘可能存储了部分的数据,那再重启的时候(比如消息队列会重新拉取),就不怕会丢了或多了数据吗?
看到这里,你可能在会在别的地方看过Flink的另外一个比较出名的特性:精确一次性 (简单来说就是:Flink遇到意外事件挂了以后,有什么机制来尽可能保证处理数据不重复和不丢失的呢)
c.精确一次性
众所周知,流的语义性有三种:
- 精确一次性(exactly once):有且只有一条,不多不少
- 至少一次(at least once):最少会有一条,只多不少
- 最多一次(at most once):最多只有一条,可能会没有
Flink实现了精确一次性,这个精确一次性是什么意思呢?
Flink的精确一次性指的是:状态只持久化一次到最终的存储介质中(本地数据库/HDFS...)
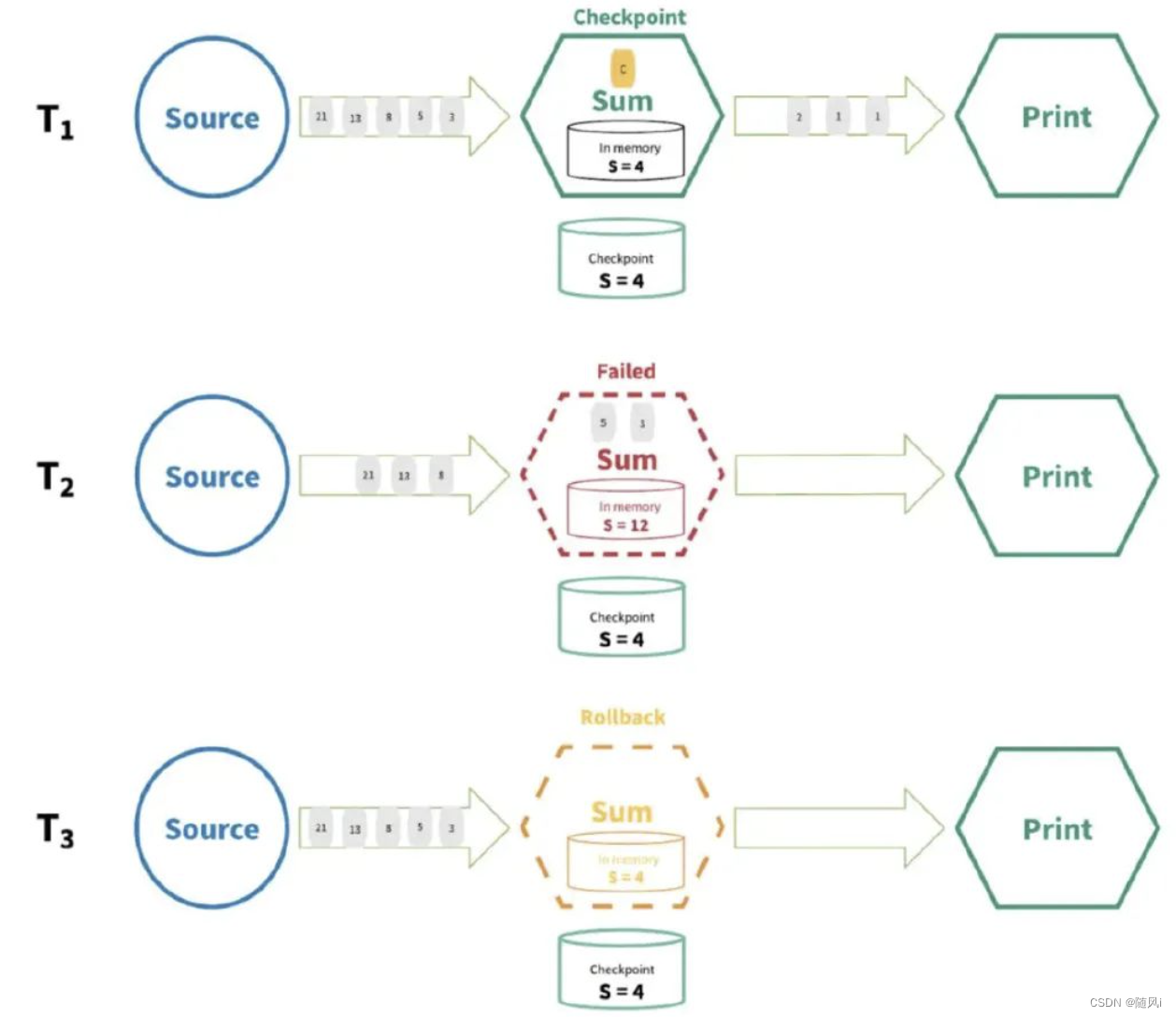 以上面的图为例:
以上面的图为例:Source数据流有以下数字21,13,8,5,3,2,1,1,然后在Flink需要做累加操作(求和)
现在处理完2,1,1了,所以累加的值是4,现在Flink把累积后的状态4已经存储起来了(认为前面2,1,1这几个数字已经完全处理过了)。
程序一直往下走,处理了5,3,现在累加的值是12,但现在Flink还没来得及把12存储到最终的介质,此时系统挂掉了。
Flink重启后会重新把系统恢复到累加的值是4的状态,所以5,3得继续计算一遍,程序继续往下走。
看文章有的同学可能会认为:精确一次性指的不是某一段代码只会执行一次,不会执行多次或不执行。这5和3这两个数,你不是重复计算了吗?怎么就精确一次了?
显然,代码只执行一次肯定是不可能的嘛。我们无法控制系统在哪一行代码挂掉的,你要是在挂的时候,当前方法还没执行完,你还是得重新执行该方法的。
所以,状态只持久化一次到最终的存储介质中(本地数据库/HDFS),在Flink下就叫做exactly once(计算的数据可能会重复(无法避免),但状态在存储介质上只会存储一次)。
那么Flink是在多长时间存储一次的呢?这个是我们自己手动配置的。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.getCheckpointConfig().setCheckpointInterval(20000); //20s一次 |
所谓的CheckPoint其实就是Flink会在指定的时间段上保存状态的信息,假设Flink挂了可以将上一次状态信息再捞出来,重放还没保存的数据来执行计算,最终实现exactly once。
那CheckPonit是怎么办到的呢?想想我们在Kafka在业务上实现「至少一次」是怎么做的?我们从Kafka把数据拉下来,处理完业务了以后,手动提交offset (告诉Kafka我已经处理完了)
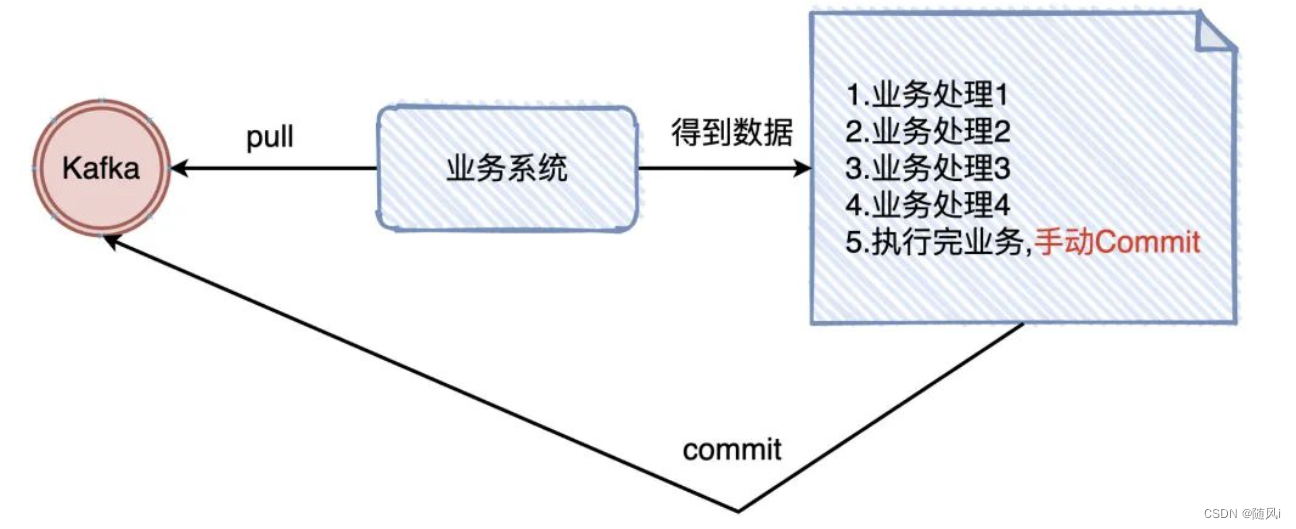
我们是做完了业务规则才将offset进行commit的,checkponit其实也是一样的(等拉下来该条数据所有的流程走完,才进行真正的checkponit)。
问题又来了,那checkpoint是怎么知道拉下来的数据已经走完了呢?Flink在流处理过程中插入了barrier,每个环节处理到barrier都会上报,等到sink都上报了barrier就说明这次checkpoint已经走完了。
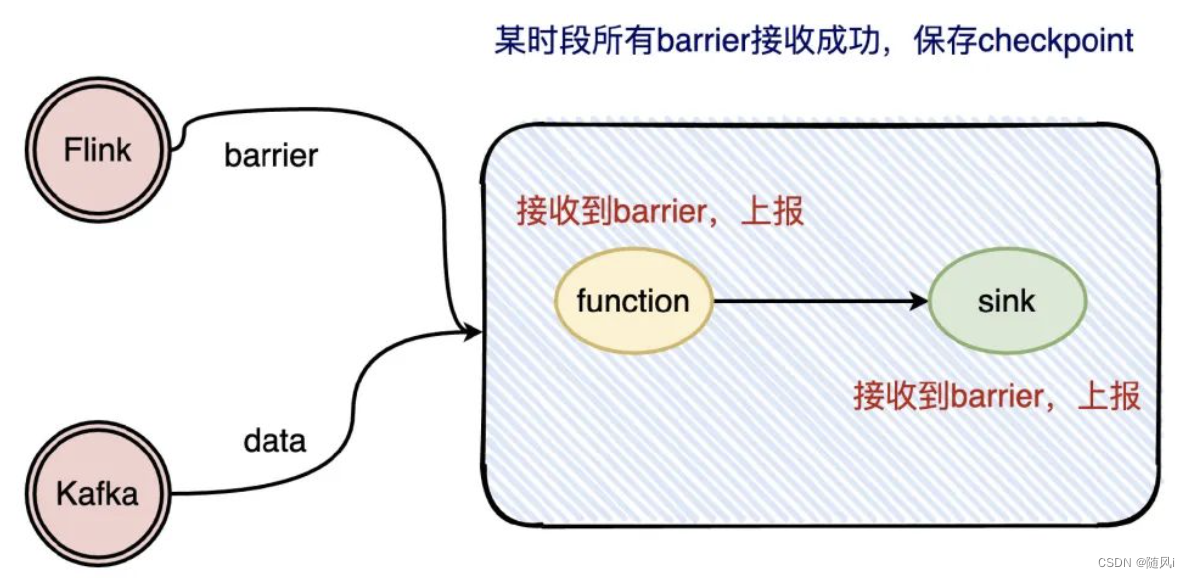
要注意的是,Flink实现的精确一次性只是保证内部的状态是精确一次的,如果想要端到端精确一次,需要端的支持
- 数据源需要可回放,发证故障可以重新读取未确认的数据
Flink需要把数据存到磁盘介质(不能用内存),发生故障可以恢复- 发送源需要支持事务(从读到写需要事务的支持保证中途不失败)

2.flink CheckPoint机制
简介:Flink 的 Checkpoint 机制是其可靠性的基石。当一个任务在运行过程中出现故障时,可以根据 Checkpoint 的信息恢复到故障之前的某一状态,然后从该状态恢复任务的运行。 在 Flink 中,Checkpoint 机制采用的是 chandy-lamport(分布式快照)算法,通过 Checkpoint 机制,保证了 Flink 程序内部的 Exactly Once 语义。
流程详解:
a. 任务启动
我们假设任务从 Kafka 的某个 Topic 中读取数据,该Topic 有 2 个 Partition,故任务的并行度为 2。根据读取到数据的奇偶性,将数据分发到两个 task 进行求和。
某一时刻,状态如下:
-
Source1的偏移量为 3,即读取到了 1,2,3 三条数据。数据1已经发送到 sum_odd。
-
Source2的偏移量为 4,即读取到了1,2,3,4 四条数据。数据1,3已经发送到sum_odd,数据2已经发送到sum_even
-
此时 sum_even 的状态为 2,sum_odd 的状态为 5

b. 启动Checkpoint
JobManager 根据 Checkpoint 间隔时间,启动 Checkpoint。此时会给每个 Source 发送一个 barrier 消息,消息中的数值表示 Checkpoint 的序号,每次启动新的 Checkpoint 该值都会递增。
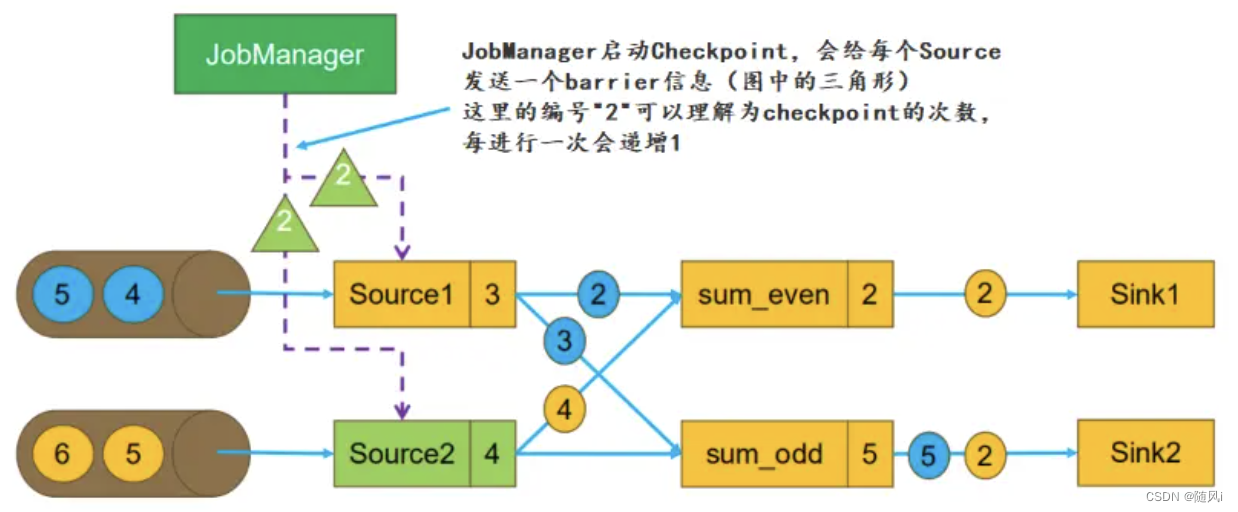
c. Source启动Checkpoint
当Source接收到barrier消息,会将当前的状态(Partition、Offset)保存到 StateBackend,然后向 JobManager 报告Checkpoint 完成。之后Source会将barrier消息广播给下游的每一个 task:
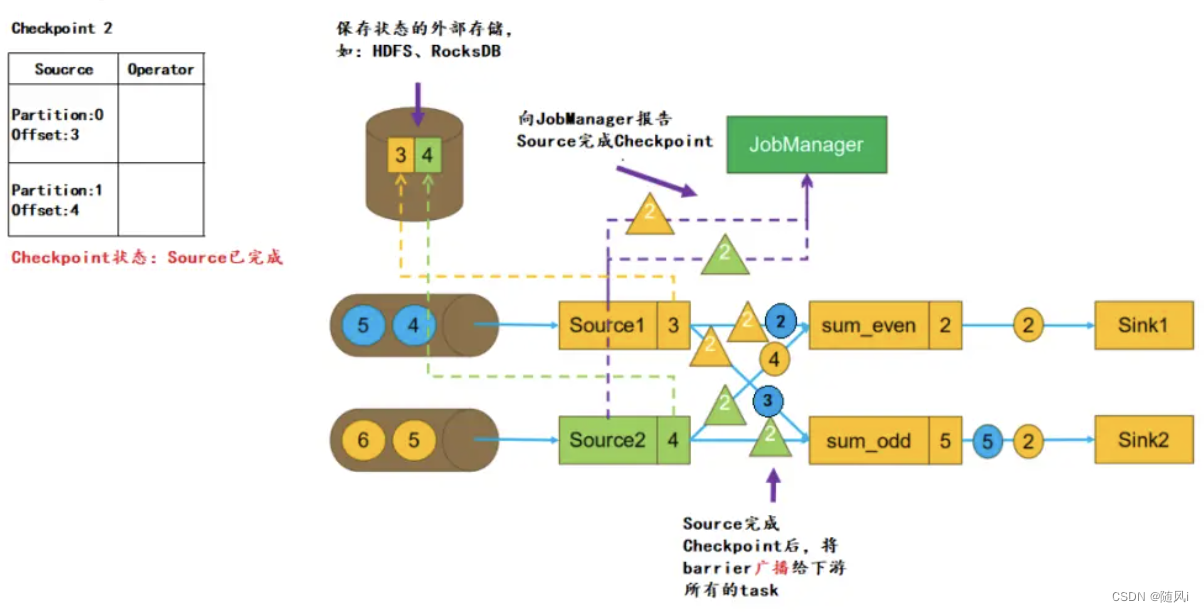
d. task 接收 barrier
当task接收到某个上游(如这里的Source1)发送来的barrier,会将该上游barrier之前的数据继续进行处理,而barrier之后发送来的消息不会进行处理,会被缓存起来,用于区分流中的数据属于哪一个 Checkpoint。
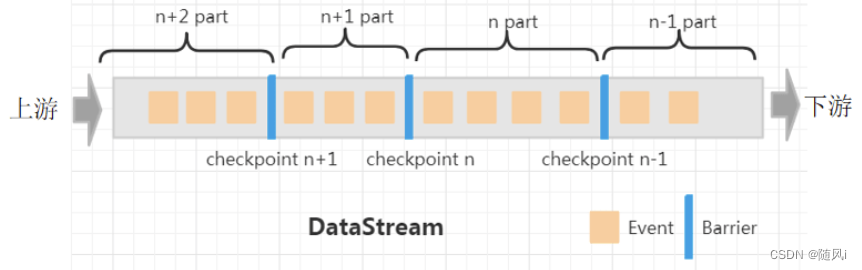
e. barrier对齐
如果某个task有多个上游输入,如这里的 sum_even 有两个 Source 源,当接收到其中一个 Source 的barrier后,会等待其他 Source 的 barrier 到来。在此期间,接收到 barrier 的 Source 发来的数据不会处理,只会缓存(如下图中的数据4)。而未接收到 barrier 的 Source 发来的数据依然会进行处理,直到接收到该Source 发来的 barrier,这个过程称为 barrier的对齐 。
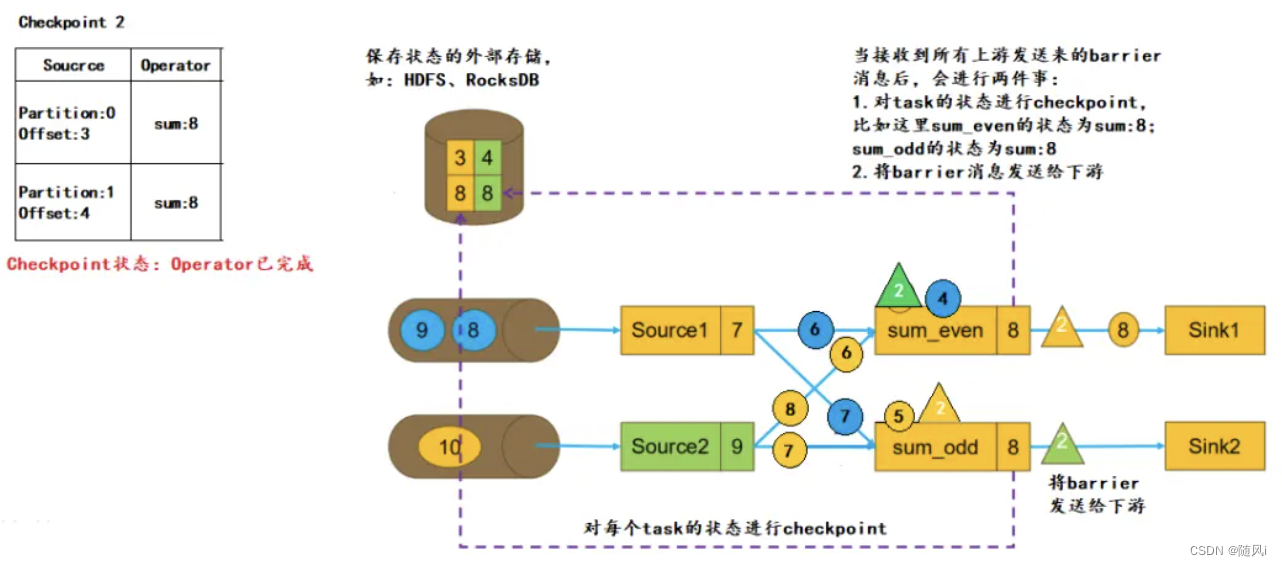
barrier是否对齐决定了程序实现的是 Exactly Once 还是 At Least Once:
如果不进行barrier对齐,那么这里 sum_even 在接收 Source2 的 barrier 之前,对于接收到 Source1的数据4,不会进行缓存,而是直接进行计算,sum_even 的状态改为12,当接收到 Source2 的barrier,会将 sum_even 的状态 sum=12 进行持久化。如果本次Checkpoint成功,在进行下次 Checkpoint 前任务崩溃,会根据本次Checkpoint进行恢复。此时状态如下:
-
Source1的 offset 为3,从数据4开始读。
-
Source2 的 offset 为4,从数据5开始读。
-
sum_even 的状态为 12(Souce1的数据2,数据4;Source2的数据2,数据4),后续接收Source1的数据4,数据6...;接收Source2的数据6,数据8...
从这里我们就可以看出,Source1的数据4被计算了两次。因此,Exactly Once语义下,必须进行barrier的对齐,而 At Least Once语义下 barrier 可以不对齐。
注意:barrier对齐只会发生在多对一的Operator(如 join)或者一对多的Operator(如 reparation/shuffle)。如果是一对一的Operator,如map、flatMap 或 filter 等,则没有对齐这个概念,都会实现Exactly Once语义,即使程序中配置了At Least Once 。
f. 处理缓存数据
当task接收到所有上游发送来的barrier,即可以认为当前task收到了本次 Checkpoint 的所有数据。之后 task 会将 barrier 继续发送给下游,然后处理缓存的数据,比如这里 sum_even 会处理 Source1 发送来的数据4. 而且,在这个过程中 Source 会继续读取数据发送给下游,并不会中断。
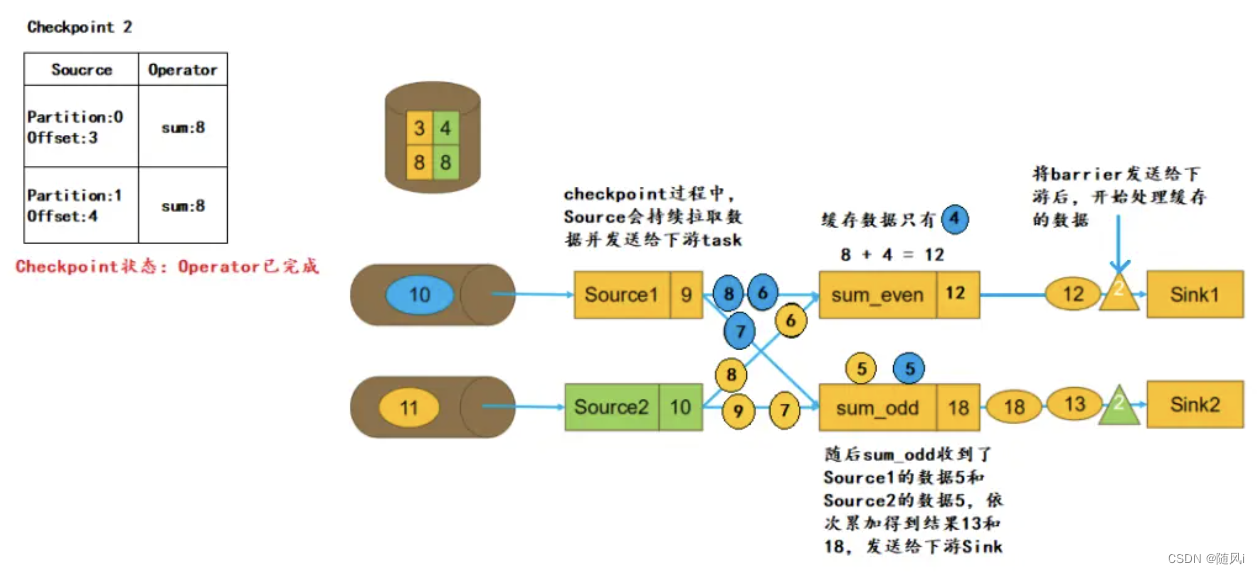
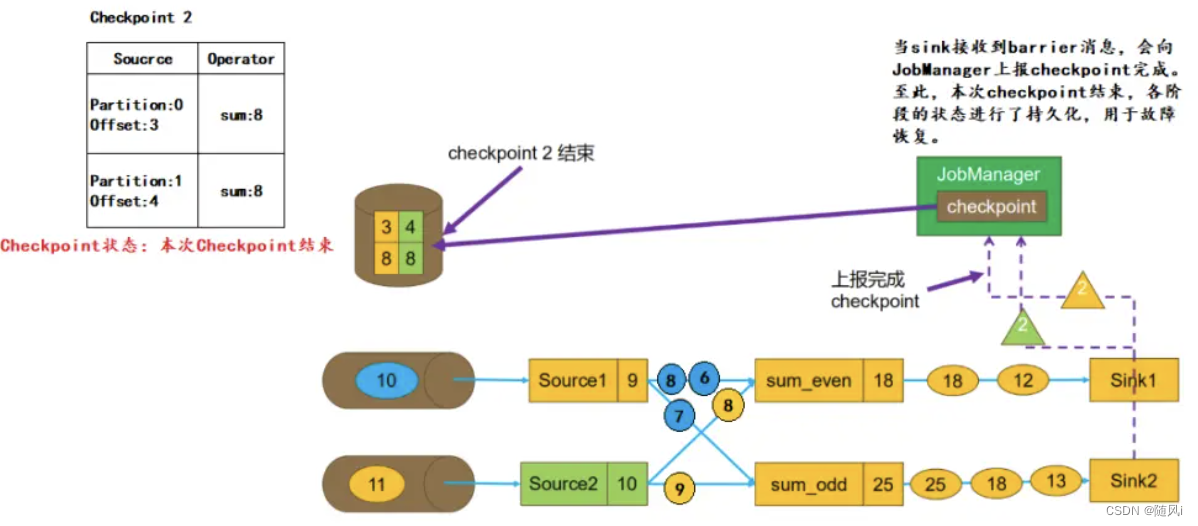
g. 上报Checkpoint完成
当sink收到barrier后,会向JobManager上报本次Checkpoint完成。至此,本次Checkpoint结束,各阶段的状态均进行了持久化,可以用于后续的故障恢复。
3.flink反压(背压)
a. 产生原因
下游消费的速度跟不上上游产生数据的速度,可能原因如下:
- 节点有性能瓶颈,可能是该节点所在的机器有网络,磁盘等等故障,机器的网络延迟和磁盘不足,频繁GC,数据热点等原因;
- 数据源生产的数据过快,计算框架处理不及时;
- flink算子间并行度不同,下游算子相比上游算子过小;
b. 过程
它意味着数据管道中某个节点成为瓶颈,处理速率跟不上「上游」发送数据的速率,上游需要进行限速。
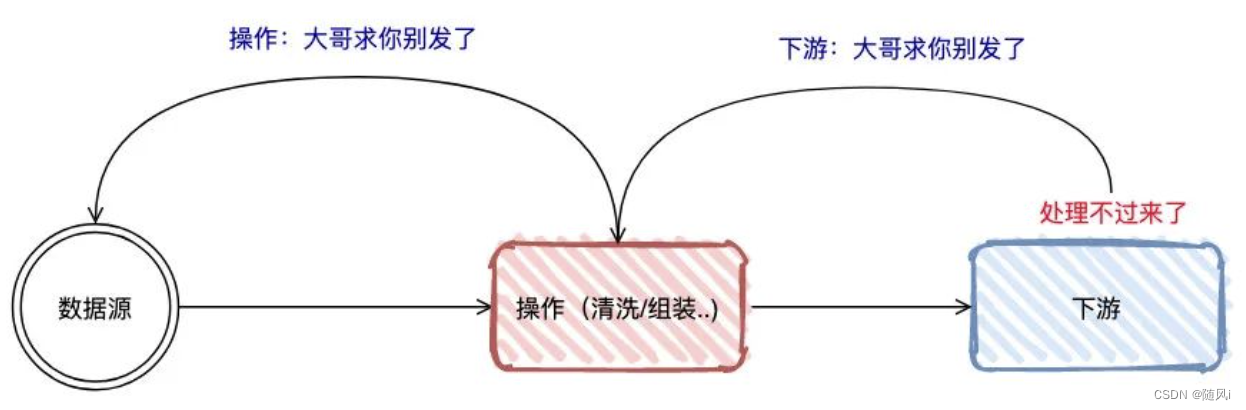
上面的图代表了是反压极简的状态,说白了就是:下游处理不过来了,上游得慢点,要堵了!
最令人好奇的是:“下游是怎么通知上游要发慢点的呢?”
在前面Flink的基础知识讲解,我们可以看到ResultPartition用来发送数据,InputGate用来接收数据。
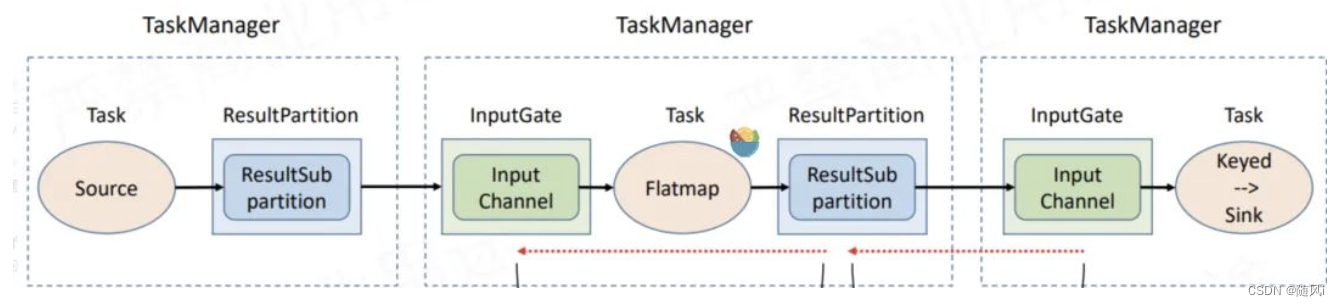
而Flink在一个TaskManager内部读写数据的时候,会有一个BufferPool(缓冲池)供该TaskManager读写使用(一个TaskManager共用一个BufferPool),每个读写ResultPartition/InputGate都会去申请自己的LocalBuffer。

以上图为例,假设下游处理不过来,那InputGate的LocalBuffer是不是被填满了?填满了以后,ResultPartition是不是没办法往InputGate发了?而ResultPartition没法发的话,它自己本身的LocalBuffer 也迟早被填满,那是不是依照这个逻辑,一直到Source就不会拉数据了...
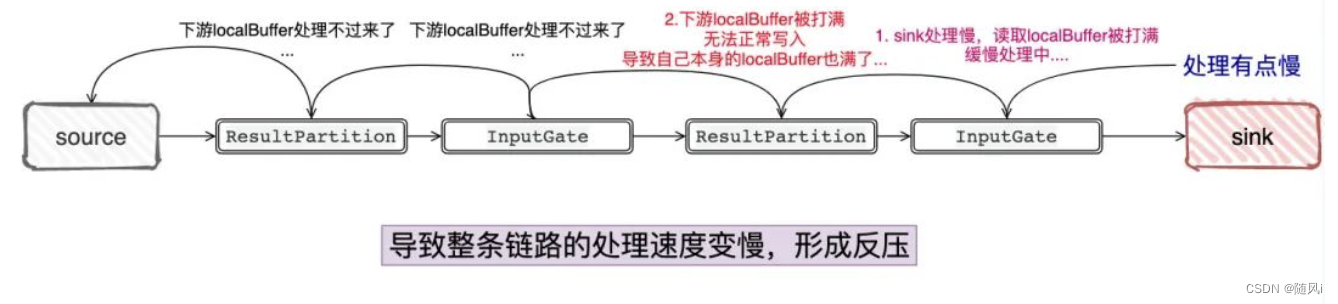
这个过程就犹如InputGate/ResultPartition都开了自己的有界阻塞队列,反正“我”就只能处理这么多,往我这里发,我满了就堵住呗,形成连锁反应一直堵到源头上...
c. 影响
- 背压会导致流处理作业数据延迟的增加
- 影响到Checkpoint,导致失败,导致状态数据保存不了,如果上游是Kafka数据源,在一致性的要求下,可能会导致offset的提交不上
原因: 由于Flink的Checkpoing机制需要进行Barrier对齐,如果此时某个Task出现了背压,Barrier流动的速度就会变慢,导致Checkpoing整体时间变长,如果背压很严重,还有可能导致Checkpoing超时失败
3. 影响state的大小,还是因为checkpoing barrier对齐要求。导致state变大
原理: 接受到较快的输入管道的barrier后,他后面数据会被缓存起来但不处理,直到较慢的输入管道的barrier也到达,这些被缓存的数据会被放到state里面,导致state变大;
参考资料:
官方文档
flink checkpoint
flink反压详解
flink反压机制与处理