文章目录
- 前言
- SharedFlow之创建
- SharedFlow之缓存系统
- buffer&Slots
- SharedFlow源码
- 发送数据
- 接收数据
- SharedFlow存在的bug
前言
Kotlin中Flow被分为冷流 热流 两大类。比如经常被使用的flow{}函数就可以创建一个冷流。而本文的主角SharedFlow就是一个热流。冷流需要调用Flow的collect函数才会触发Flow的emit。热流不需要调用Flow的colelct也可以emit。
网络上有很多人把热流(SharedFlow)比作是一个广播。想象一下现实中的广播,比如开车听的交通广播, 比如以前村里的大喇叭广播,不管有没有听众在听,它都会播它想要播的内容。在广播期间,新来的听众就会错过前面已经播出的内容,而且广播不会因为某些听众消化内容比较慢而等他们。因此如果对于一个初学者来说,你一开始学习SharedFlow的时候就把它当做现实中广播的行为方式去理解的话就会让你后面的学习造成困扰。
严格的来说,SharedFlow有好几种行为,只是其中一种行为几乎可以完全模拟现实中广播的行为方式。先记住”几乎“这两字,表明了不能百分百,只能是接近。所以我们在后面的学习过程中,千万不要一开始就把SharedFlow当做一个广播去思考。
还有的朋友学习SharedFlow的时候会去对照冷流。这也不利于你继续学习SharedFlow。冷流相对于热流来说,虽然都叫流,都是调用emit发送数据,调用collect接收数据,实际上它们内部的实现方式可以说完全是天差地别。SharedFlow再实现方式和行为上更像Channel。官方的说法是SharedFlow是用来替代BroadcastChannel的。
如果你还不了解
Channel,可以看:Kotlin Channel系列(一)之读懂Channel每一行源码看完这篇文章后再去学习
BroadcastChannel就简单了。
以共享之名成就热流之实。看一下官方对其的解释:
A hot [Flow] that shares emitted values among all its collectors in a broadcast fashion, so that all collectors get all emitted values. A shared flow is called hot because its active instance exists independently of the presence of collectors. This is opposed to a regular [Flow], such as defined by the
flow { ... }function,which is cold and is started separately for each collector.它是一个热流,以广播的方式在其所有收集器之间共享发出的值,以便所有收集器获得所有发出的值。共享流被称为_hot_,因为它的活动实例独立于收集器的存在而存在。这与常规的[Flow]相反,例如由
Flow{…]}函数创建的流,它是_cold_,为每个收集器单独启动。
冷流
冷流分为上游和下游,上游负责生产数据,下游负责消费数据。只有把下游和上游对接上,这个流才开始工作,简而言之就是上游再没有下游的情况下是不能独立运行的。上游为每一个下游单独启动,比如:
//创建一个上游,负责生产数据
val coldFlow = flow<Int> {
//在没有把上游和下游对接上时,这里面的代码是不会执行的
emit(1)
emit(2)
}
//创建一个下游,负责消费数据。
val collector1 = FlowCollector<Int> { value ->
println(value)
}
//再创建一个下游,两个下游将收到的同样的数据。
val collector2 = FlowCollector<Int> { value ->
println(value)
}
//再没有把上游和下游对接上的时候,上游是不会工作的。
//也没法调用coldFlow.emit
//把上游和下游对接上,上游开始发送数据,下游接收到数据。上游为每一个下游单独启动
launch {
coldFlow.collect(collector1)
}
launch {
coldFlow.collect(collector2)
}
热流
热流更像订阅模式,称之为发布者和订阅者,发布者在没有订阅者的情况下可以独立运行,简而言之就是在没有订阅者的情况下依然可以发送数据。
//创建一个发布者
val hotFlow = MutableSharedFlow<Int>()
//再没有订阅者的情况下也可以独立运行发送数据。
launch {
hotFlow.emit(1)
}
launch {
hotFlow.emit(2)
}
val subscriber = FlowCollector<Int> {
println(it)
}
//订阅者订阅到发布者
launch {
hotFlow.collect(subscriber)
}
SharedFlow之创建
最简单的创建一个SharedFlow:
val sharedFlow = MutableSharedFlow<T>()
创建一个SharedFlow需要用到MutableSharedFlow函数:
public fun <T> MutableSharedFlow(
replay: Int = 0, //可回放个数
extraBufferCapacity: Int = 0,//buffer额外的缓存容量
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND //缓存溢出策略
): MutableSharedFlow<T> {
//对参数replay做校验,必须是大于等于0的,否则抛出异常
require(replay >= 0) { "replay cannot be negative, but was $replay" }
//对参数extraBufferCapacity做校验,必须是大于等于0,的否则抛出异常
require(extraBufferCapacity >= 0) { "extraBufferCapacity cannot be negative, but was $extraBufferCapacity" }
//确保当replay 和 extraBufferCapacity 都为0 的时候,onBufferOverflow 必须是SUSPEND.
//换句话说当 onBufferOverflow 不是suspend的时候,replay 和 extraBufferCapacity 必须有一个不为0。
require(replay > 0 || extraBufferCapacity > 0 || onBufferOverflow == BufferOverflow.SUSPEND) {
"replay or extraBufferCapacity must be positive with non-default onBufferOverflow strategy $onBufferOverflow"
}
// replay 和 extraBufferCapacity之和共同组成了buffer的容量
val bufferCapacity0 = replay + extraBufferCapacity
//如果计算出buffer的容量为负数,就给buffer容量设置为Int.MAX_VALUE。其实这一步就是多余
//在前面已经对两个参数做了校验,bufferCapacity0 不可能小于0。
val bufferCapacity = if (bufferCapacity0 < 0) Int.MAX_VALUE else bufferCapacity0
//实例化一个SharedFlow的实例对象。
return SharedFlowImpl(replay, bufferCapacity, onBufferOverflow)
}
从创建SharedFlow的函数源码中可以看出创建一个SharedFlow有三个关键参数决定了SharedFlow的行为:
replay
简称可回放个数,当一个新的订阅者开始订阅后,能收到之前(在它订阅之前)已经发送过的最新数据个数。简而言之就是SharedFlow至少会保留最近发送的replay这么多个数据在其缓存中。以供新的订阅者接收之前已经发送过的数据。比如有一个SharedFlowd的replay = 4,发送了[1~10个]数据。那么新的订阅者来了就能收到[7 ~10]。
extraBufferCapacity
简称额外的缓存容量,SharedFlow的缓存buffer总容量大小由 replay 和 extraBufferCapacity 共同决定。bufferCapacity = replay + extraBufferCapacity。意思就buffer中在原有replay的基础上能多保留extraBufferCapacity个。比如有一个SharedFlow,它的replay = 4,extraBufferCapacity = 2。那么SharedFlow就能保留6个最近发送的数据,其中最近的4个支持新的订阅者回放。但是需要注意一点的就是额外缓存需要再有订阅自的情况下才会采用。没有订阅者的情况下是不会采用额外缓存的,没有订阅者的时候任然只在buffre中保留最近发送色replay个数据。
onBufferOverflow
简称缓存溢出策略,意思就是当SharedFlow中buffer的数量超过其容量bufferCapacity后,在继续发送数据时应该如何处理。这你这种情况溢出策略一共有三种:
SUSPEND:挂起emit
DROP_OLDEST:把buffer中存在久的数据溢出,把新的数据放进去。不会挂起emit。
DROP_LATEST:把新的数据丢弃,不会挂起emit。
需要注意的是在没有订阅者的情况下,buffer中只会保留最近发送的replay个数据,不会采用额外缓存容量,不会才用任何缓存策略,如果buffer中已经够了replay个,那就把本次的数据放入buffer中,把最早的那一个数据从buffer中删除。这么说其实也和DROP_OLDEST策略比较类似。
Example:
Step1:创建一个replay = 2,extraBufferCapacity = 2,onBufferOverflow = suspend的ShareFlow。
val flow = MutableSharedFlow<Int>(replay =2, extraBufferCapacity = 2 ,onBufferOverflow = BufferOverflow.SUSPEND)
Step2:那么该SharedFlow的buffer容量bufferCapacity就等于4,在没有订阅者的情况下,先发送4条数据:
repeat(4){
flow.emit(it+1)
}
这时候由于没有订阅者,不会采用额外缓存,因此buffer中只有数据3和4。其实想想的确是怎么回事,虽然bufferCapacity=4。有必要缓存最近的四条数据1,2,3,4吗?由于replay = 2,当订阅者来了后,也只能接收最近的两条3和4。1和2也接收不到,缓存了也是浪费空间。
Step3:增加一个订阅者:
launch {
flow.collect{
log("接收到:$it")
delay(3000) //模拟处理数据速度比较慢
}
}
Step4:延迟一秒继续发送数据:
delay(1000)//之所以延迟一秒是为确保订阅者已经取到第一个数据3.
repeat(6){
(5 + it).apply {
log("---> 开始发送 $this")
flow.emit(this) //加5接上面,使其连续
log("发送完成 $this <----")
}
}
Step5:当订阅者取到数据3后,buffer中就只剩数据4。由于订阅者接收到数据3后,处理速度比较慢,发布者继续发送数据5,buffer中变成4和5。在继续发送数据6的时候就会采用额外缓存,因此buffer中又多了6。继续发送7,buffer中又多了数据7。现在buffer中就有了4,5,6,7四个数据,这时候如果有新的订阅者进来,新的订阅者只会收到最新的6和7两个数据。
Step6:继续发送数据8,这个时候buffer已经满了,根据设置的溢出策略,emit(8)这一次发送就会被挂起。当订阅者处理完数据4后,从buffer中取走数据4,给buffer腾出空间了,就会唤醒挂起的emit(8),把数据8放入buffer中,buffer就变成了5,6,7,8。发布者继续发送9,又会被挂起,以此往复。
完整代码:
fun main() = runBlocking {
val flow = MutableSharedFlow<Int>(
replay = 2,
extraBufferCapacity = 2,
onBufferOverflow = BufferOverflow.SUSPEND
)
repeat(4) {
flow.emit(it+1)
}
launch { //这里单独开一个协成,是因为collect函数会被挂起。
flow.collect{
log("接收到:$it")
delay(3000)
}
}
delay(1000)//之所以延迟一秒是为确保订阅者已经取到第一个数据3.
repeat(6){
(5 + it).apply {
log("---> 开始发送 $this")
flow.emit(this) //加5是为了接上面,使其连续
log("发送完成 $this <----")
}
}
Unit
}
//输出结果:
13:20:38:266[ main ] 接收到:3
13:20:39:214[ main ] ---> 开始发送 5
13:20:39:215[ main ] 发送完成 5 <----
13:20:39:215[ main ] ---> 开始发送 6
13:20:39:215[ main ] 发送完成 6 <----
13:20:39:215[ main ] ---> 开始发送 7
13:20:39:215[ main ] 发送完成 7 <----
13:20:39:215[ main ] ---> 开始发送 8 //这里被第一次挂起
13:20:41:289[ main ] 接收到:4 //由于中间我们延迟了一秒,第一次挂起了2秒
13:20:41:289[ main ] 发送完成 8 <---- //取出数据4腾出空间后emit被唤醒,继续发送9
13:20:41:289[ main ] ---> 开始发送 9 //第二次被挂起
13:20:44:294[ main ] 接收到:5
13:20:44:295[ main ] 发送完成 9 <---- //第二次被挂起了3秒。
13:20:44:295[ main ] ---> 开始发送 10//第三次被挂起
13:20:47:297[ main ] 接收到:6
13:20:47:297[ main ] 发送完成 10 <----
13:20:50:301[ main ] 接收到:7
13:20:53:303[ main ] 接收到:8
13:20:56:304[ main ] 接收到:9
13:20:59:309[ main ] 接收到:10
假如我们onBufferOverflow设置成DROP_OLDEST其他都不变会发生什么呢?
前面step1,step2,step3,step4,step5,buffer中都一样为4,5,6,7。当继续发送数据8的时候buffer满了,根据溢出策略会把buffer存在最久的数据也就是数据4移除。把数据8放进去,buffer中变成了5,6,7,8。发布者继续发布9,又把数据5移除,buffer中变成6,7,8,9。继续发送数据10,buffer中变成7,8,9,10。当订阅者出路完数据3后,继续接收数据时接收到下一个数据为7。以下为输DROP_OLDEST出结果:
13:41:59:240[ main ] 接收到:3
13:42:00:123[ main ] ---> 开始发送 5
13:42:00:124[ main ] 发送完成 5 <----
13:42:00:124[ main ] ---> 开始发送 6
13:42:00:124[ main ] 发送完成 6 <----
13:42:00:124[ main ] ---> 开始发送 7
13:42:00:124[ main ] 发送完成 7 <----
13:42:00:125[ main ] ---> 开始发送 8
13:42:00:126[ main ] 发送完成 8 <----
13:42:00:126[ main ] ---> 开始发送 9
13:42:00:126[ main ] 发送完成 9 <----
13:42:00:126[ main ] ---> 开始发送 10
13:42:00:126[ main ] 发送完成 10 <----
13:42:02:280[ main ] 接收到:7
13:42:05:280[ main ] 接收到:8
13:42:08:282[ main ] 接收到:9
13:42:11:283[ main ] 接收到:10
假如我们onBufferOverflow设置成DROP_LATEST其他都不变会发生什么呢?
前面step1,step2,step3,step4,step5,buffer中都一样为4,5,6,7。当继续发送数据8的时候buffer满了,根据溢出策略会丢掉本次发送的数据,因此数据8,9,10都会丢掉。以下为DROP_LATEST的输出结果:
13:52:14:631[ main ] 接收到:3
13:52:15:562[ main ] ---> 开始发送 5
13:52:15:562[ main ] 发送完成 5 <----
13:52:15:562[ main ] ---> 开始发送 6
13:52:15:562[ main ] 发送完成 6 <----
13:52:15:562[ main ] ---> 开始发送 7
13:52:15:562[ main ] 发送完成 7 <----
13:52:15:563[ main ] ---> 开始发送 8
13:52:15:563[ main ] 发送完成 8 <----
13:52:15:563[ main ] ---> 开始发送 9
13:52:15:563[ main ] 发送完成 9 <----
13:52:15:563[ main ] ---> 开始发送 10
13:52:15:563[ main ] 发送完成 10 <----
13:52:17:655[ main ] 接收到:4
13:52:20:659[ main ] 接收到:5
13:52:23:663[ main ] 接收到:6
13:52:26:669[ main ] 接收到:7
SharedFlow之缓存系统
对于冷流来说它为每一个它的下游单独启动。就好比你们村的村长去乡里开会了,得到了一些新的政策(数据),回到村里后,如果有谁想要知道新政策就去找村长,村长一个一个服务,单独把政策告诉每一个人。那如果换做是热流呢?村长就会用村里的大广播,开始宣读新的政策,谁想听的就找个能听的地方站着听就行了。每个想听的人只能听见他开始听以后得数据,如果之前它在屋内(假如屋内听不见),没出屋之前村长已经讲过的内容他就没法听见了,只能听见之后的内容,而且村长用这种广播的方式是同时服务于全村想听的人。不是单独针对每一个人。
就像官方解释所说的,SharedFlow是一个热流,以广播的方式在其所有收集器之间共享发出的值。SharedFlow它只是以广播的形式,不代表它和广播完全一样,SharedFlow支持回放,支持等待接收慢的订阅者,回放的意思就是可以让新来的订阅者可以接收到订阅之前已经发送过的数据。现实中的广播就不可以,其实Android中的粘性广播也可以,只是粘性广播只能接收到最后发送的那一次广播。等待接收慢的订阅者的意思就是当有的订阅者取到数据后处理数据的数据比较慢时(buffer已经满了,新发的数据没地方放),SharedFlow会把emit函数挂起等待。
SharedFlow为了实现这种目的,在它内部设计了两套缓存以系统。一套(buffer)是用来缓存发送的数据,用于支持数据回放,一套(slots)是用来缓存订阅者,当订阅者订阅的时候SharedFlow没有数据可消费时把订阅者挂起,等待有数据后唤醒订阅者接收数据。
buffer&Slots
buffer
SharedFlow发送的数据都不是直接交给订阅者的,都是先放进缓存中,buffer这个缓存内部采用的数据结构为数组,可以用来存两种类型的数据,第一种为我们发送的数据,第二种为挂起的emit。当一次emit需要挂起的时候会把要发送的数据和emit函数所在的协成包装成一个Emitter对象存入buffer中(这点和Channel中的Send很像)。两种数据类型是分开存放的,数据在前,Emitter存在数据的后面。
buffer是动态的,初始状态下buffer = null。第一次创建的时候会创建一个长度为2的数组。每次扩容为原有数组长度的2倍。
我们经常所说的buffer容量bufferCapacity不是指数组的长度,而是指能能存放发送的数据的最大个数(不包括Emitter,Emitter存入个数不受限制)。bufferCapacity由replay和extraBufferCapacity两个参数共同决定。当存放数据超过了bufferCapacity就需要把emit挂起,把数据包装成Emitter对象存入Buffer中,数组的长度是以2的倍数递增。理论上来说素组的长度可以增长到Int.MAX_VALUE。
我们来看一个简单buffer内存示意图:

slots
slots 是用来存放订阅者的,在SharedFlow中,每一个订阅者订阅后是不支持取消的(要想取消只能取消订阅者所在的协成),所以订阅者会一直存在,即使没有数据可消费了也会挂起等待。所以SharedFlow在每一个订阅者订阅的时候创建一个Slot对象,这个对象有两个属性:index Int类型 记录了每一个订阅者将要取数据在buffer中的下标,cont 是一个Continuation。当一个订阅自需要挂起的时候,cont记录了挂起的协成对象。
创建好Slot对象后会把Slot放入一个Array<Slot>的数组了里面,该数组初始情况下为null。第一次创建的时候创建一个长度为2的数组,以后每次扩容为原来的2倍,理论上来说数组最大可以扩容到Int.MAX_VALUE。在实际使用中不太可能会发生这样的情况,因为不太可能有这么多订阅者。
当一个订阅者取消后,并不会把Slot从数组中移除,只会把其index = -1,cont = null。当有新的订阅者来的时候可以复用这个Slot。有点像Handler中复用Message。
SharedFlow为开发者提供了一个subscriptionCount可以观察订阅者的数量,当有新订阅者订阅或者已有订阅者取消时可以收到回调。subscriptionCount是SharedFlow中的一个属性,其类型为StateFlow(如果你还不理解StateFlow,展示可以把他当做Android中的LiveData)。subscriptionCount里面存了订阅者的数量,每来一个订阅者就加一,每减少一个订阅者就减一。
这里主要讲buffer这个缓存系统,至于slots会顺带讲一下:
为了维持好buffer这个缓存系统的正确运作,在SharedFlow中定义了几个关键属性:

Example1:
我们以一个例子来说明一下buffer是如何工作的:
Step1:创建一个replay = 2,extraBufferCapacity = 2,onBufferOverflow = suspend的ShareFlow。
val flow = MutableSharedFlow<Char>(replay =2, extraBufferCapacity = 2 ,onBufferOverflow = BufferOverflow.SUSPEND)
那么这个buffer的bufferCapacity = 4,在还没有发送数据的时候,buffer = null。
Step2:在没有订阅者的情况下,先给他发送四条数据:
for(data in 'A' ..'D'){
debug("---------> 开始发送数据 $data")
flow.emit(data) //连续发送数据A,B,C,D
debug("把$data 放入了buffer中 <------------")
}
–> 发送第一条数据‘A’的时候,replay = 2,支持回放两个数据,所以即使在没有订阅者的情况下数据“A”不能丢掉(如果丢掉了订阅者来了怎么回放呢?),为了保存数据“A”,开始启动缓存buffer。第一次创建一个长度为2的数组,然后把“A”存入进去,存入一个数据后bufferSize加一。replayIndex代表了订阅者来了后回放的起始下标,由于目前只有一个数据,replayIndex = 0,指向数据“A”

因为此时还没有订阅者,所以minCollectorIndex默认为最大值(head + bufferSize)= 1,即和bufferEndIndex相等。
–> 继续发送数据"B",buffer中有空间,会把"B"放入buffer中,计算存入"B"的index 是通过 (head + totalSize) and (buffer.size -1) = (0 + 1) and (2 -1) = 1,and 是一个与运算符号。replayIndex保持不变,新来的订阅者需要从index = 0 的位置开始取数据,minCollectorIndex为默认最大值,此时最大致变为了2:

–> 发送数据"C"的时候,totalSize >=2(数组的长度),需要扩容,扩容到4,具体的做法就是创建一个长度为4的新数组,然后再把原来数组中的数据拷贝到新数组里面。这里由于数组还处于一种比较简单的情况下,拷贝数据转移这个操作比较简单,大家一眼就能看明白,因此此次就先不讲细节,留在后面情况复杂的时候再讲。
把原来的数据都拷贝到新数组后,需要把数据"C"放入新数组中,放入的位置index = (head + totalSize) and (buffer.size -1) =( 0 + 2 ) and (4 -1) = 2 and 3 = 2。放入数据"C"后,bufferSize++,buffer中就有3个数据了。但是replay = 2,最多能回放之前发送的最近的两个数据B和C。这个时候数据"A"还留在buffer中就没有意义了,新来的订阅者也不会消费他,因此把数据“A”移除,把存A的地方存一个null,bufferSize--。移除数据“A”后,replayIndex需要加一,让新来的订阅者从数据“B”开始取。buffer中增加了数据“C”,移除了数据“A”,一加一减,因此bufferSize 不变。

minCollectorIndex为默认最大值,此时最大致变为了3。
–>继续发送数据"D",数组长度为4,里面只存了两个元素,因此数据"D"可以直接放入buffer中。存入index = 3的位置,数据"B"就没有存在的意义了,因此也需要移除,replayIndex加一。

这时候如果在继续发送数据,会发生什么?会继续扩容吗?扩容的前提条件是totalSize >= buffer.size。目前totalSize = 2。buffer.size = 4。不满足扩容的条件,本来也不满足,数组中只装了C和D两个数据,再扩容就有点浪费了。假如是你来设置这个buffer。你会怎么做。比如把数据C和数据D向前移动两格,然后更新相应的index。这样的确是可以,但是移动数组中的元素这种做法不是最优的。就比如ArrayList的增删比LinkedList要慢。正确的做法是把这个数组当做一个无限循环来使用。就好比Android中的RecycleView一样,用有限的Item可以展现无限多个数据一样。此处的思想差不多。
Ok 我们在继续发送数据E:
debug("---------> 开始发送数据 E")
flow.emit('E') //发送数据 E
debug("把E 放入了buffer中 <------------")
往一个buffer中存入数据的时候,计算存入的index = (head+ totalSize) and (buffer.size -1) = (2 + 2) and (4-1) = 4 and 3 = 0。。那么数据E存放的index = 0的位置。因为把数据E存入了,数据C就变成没有意义的数据了,可以被移除了。修改replayIndex 指向了数据D。

在继续来发送一个数组F吧:
debug("---------> 开始发送数据 F")
flow.emit('F') //发送数据 E
debug("把F 放入了buffer中 <------------")
数据F会放入到数据E的后面,即index = 1的位置。放入数据F后,数据D就可以移除了。想必不用说,大家都知道replayIndex应该指向数据E。这样新来的订阅者可以从数据E开始回放。那replayIndex = 0 吗?NO NO,回放的起始数据是数据E没错。但是replayIndex 和 minCollectorIndex的值是永远正向递增的。在取数据的时候用 replayIndex 或者 minCollectorIndex 和 (buffer.size -1) 进行与运算,一样可以取到正确的数据。看图吧:

如果有新的订阅者进来取数据的时候通过replayIndex and (buffer.size -1)计算出真实的位置:4 and 3 = 0,因此也可以取到数据E。经过6次数据发送已经形成了一个大循环了。在继续发送数据,逻辑都是一样的。
**Step3:**经过了前面6次emit。是时候搞一个订阅者了,先假设这个叫订阅者A:
//单独开一个子协成来接收数据,因为collect是一个suspend函数。不单独开一个协成被挂起后导致后面代码没法执行
launch {
flow.collect{
debug("订阅者 A 取到数据 :$it")
delay(6000)
debug("订阅者 A 处理完数据 :$it")
}
}
调用collect函数后会为每一个订阅者创建一个Slot对象,然后把Slot对象存在缓存slots中,Slot中有一个index属性,记录他每次要取的数据的index。这时候第二套缓存系统开始启动了。同样的在没有订阅者的时候slots = null。第一次创建一个长度为2的数组,以后每次扩容2倍。
订阅者来了后,由于我们的SharedFlow是支持回放的,就算你不知道代码细节,也能想到订阅者第一次取到的数据应该是E。目前buffer中就两个数据E和F。replay = 2,所以刚好是E这个数据。E这个数据就是replayIndex指向的数据,因此把订阅者A的Slot.index = replayIndex。在前面说过,minCollectorIndex代表了最慢的这个订阅者下一次将要取数据的index。之前由于没有订阅者minCollectorIndex为默认最大值,现在订阅者来了,由于目前订阅者A是唯一一个订阅者,所以我们可以认为它就是最慢的这一个订阅者,因为不存在其他订阅者。那订阅者A的刚创建的时候,它下一次(第一次)要取的数据是replayIndex指向的数据,于是让minCollectorIndex = replayIndex,即minCollectorIndex = 4(注意这里不是0)。

在此之前,先声明一个问题:我们把订阅者消费数据分为两步:第一步从buffer中取到数据,第二步处理数据。第一步取数据是在SharedFlow内部完成的,第二部处理数据就是我们自己写的代码,即对应上面调用collect函数收到数据后的代码。
订阅者A取到数据E后,会把其Slot的index++ 指向下一个它要去的数据,订阅者A取到数据E后,它下一次要去的数据是不是数据F,因此需要把minCollectorIndex修改为指向F。数据E被订阅者A消费了,数据E能被移除吗?这里是不能的,如果把数据E移除了,有新的订阅者来了,就只能回放一个数据了。在SharedFlow中buffer最少都会保留replay个数据用于回放。所以replayIndex和其他index,size 属性都不会变。

Step4:在订阅者A在处理数据时,我们又开始发送数:
delay(1000)//延迟一秒确保订阅A已经取到数据,
launch {// 这时候有订阅者A了,订阅者A处理数据比较慢,会导致emit挂起,因此单独开子一个协成。
for(data in 'G' ..'K'){
debug("---------> 开始发送数据 $data")
flow.emit(data) //连续发送数据G,H,I,J,K
debug("把$data 放入了buffer中 <------------")
}
}
–> 时间来的第一秒,发送数据G的时候,订阅者A处于正在处理数据的过程中,目前buffre中只有数据E和F,totalSize < buffer.size。不需扩容,直接把数据G放入buffer中。放入的位置为index =(head + bufferSize)and (buffer.size - 1) = 6 and 3 = 2。刚好在数据F的后面。放入数据G后buffer中就有E,F,G三个数据,根据前面讲的规则,replayIndex 需要加一指向数据F。数据E变成没有意义的无效数据了,可以被移除。这时候由于有订阅者的存在,minCollectorIndex就不能是默认最大值了,minCollectorIndex保持不变指向最慢的订阅者下一次将要取的数据F,

—>发送数据H的时候,订阅者A仍然处于处理数据的过程中,bufferSize < bufferCapacity,buffer中还有足够空间,可以直接把数据H放进去(不需要挂起)。数据H放入的位置为(head + bufferSize)and (buffer.size - 1) = 7 and 3 = 3,因此把数据H放入了数组中index=3的位置,即数据G的后面。放入数据H后,新来的订阅者回放的数据变成了G和H,因此replayIndex需要加一变成6指向G。minCollectorIndex不能变,继续等于5,依然指向订阅者A下一次要取的数据F。数据F不能被移除,因为订阅者A还没有消费。这时候replayIndex > minCollectorIndex,因此head = minCollectorIndex。buffer中有了三个数据,因此bufferSize = 3。

–> 继续发送数据I,订阅者A仍处于处理数据的过程中,bufferSize < bufferCapacity,buffer中还有足够空间,buffer中还有一个空间可以容纳数据I,数据I放入的位置为(head + bufferSize)and (buffer.size -1) = 8 and 3 = 0,因此把数据I放入了数组中index=0的位置。放入数据I后,replayIndex需要加一变成7,以便让新来的订阅者能正确的回放数据H和数据I,buffer中存入了四个数据,bufferSize = 4。

–> 继续发送数据J,订阅者A仍处于处理数据的过程中,这时候bufferSize >= bufferCapacity,buffer中没有可用空间了,需要扩容存放数据J吗?答案是不。因为bufferCapacity = 4,意思就是buffer中最多只能缓存4个数据,按照溢出策略需要把这一次emit挂起,因此把数据J和协成对象包装成一个Emitter对象存入Buffer中,为了存这个Emitter对象buffer需要扩容,扩容的原来的2倍变成8。
扩容的步骤是先创建一个长度为8的数组,转移数据的时候注意了。是从原来数组中head指向的位置开始转移,一共转移totalSize个。源码这是这样的:
private fun Array<Any?>.getBufferAt(index: Long) = get(index.toInt() and (size - 1))
private fun Array<Any?>.setBufferAt(index: Long, item: Any?) = set(index.toInt() and (size - 1), item)
for (i in 0 until totalSize) {
newBuffer.setBufferAt(head + i, oldBuffer.getBufferAt(head + i))
}
因此第一个数据F转移到新数组中index为5的位置,数据G转移到index=6的位置,数据H转移到index = 7的位置,数据I转移到index = 0的位置。

扩容完成后,把Emitter(J,con)放入buffer中。需要放入的位置为(head+ bufferSize) and (buffer.size -1) = (5 + 4) and (7) = 1。因此最终把Emitter(J,con)放入了新数组中的index = 1的位置:

之所以扩容后用这样的方式转移数据,就刚好使得replayIndex和minCollectorIndex的值就是数组下标index的值。
把Emitter对象存入Buffer中后,queueSize加一。queueEndIndex = head + bufferSize + queueSize = 5 + 4 + 1 = 10。其他都保持不变。
数据J被挂起后,数据K就没法发送了,因为emit函数被挂起了。如果这时候还想往SharedFlow中发送数据,就只能再开一个协成来发送。比如:
delay(1000) //延迟一秒是确保发送数据J被挂起了。
debug("---------> 开始发送数据 L")
flow.emit('L') //发送数据 L
debug("把L 放入了buffer中 <------------")
–>这时候时间来到第二秒,发送数据L的时候,由于bufferSize >= bufferCapacity,不能直接缓存数据L,并且minCollectorIndex <= replayIndex说明buffer中已有的数据都是有效的不能被清除。因此数据L和它所在的协成会被包装成一个Emitter对象放入buffer中,现在buffer.size = 8。里面只存了5个元素,不需要扩容。

queueSize加一变成2。queueEndIndex变成11,其他都不变。
Step5: 发送完数据L后,订阅者A仍处于处理数据E的过程中。这时候我们在给他增加一个处理数据速度比较快的订阅者B,每一个新的订阅者来了后都会闯将一个Slot对象,存入slots数组中。订阅者B取数从replayIndex开始取数据,因此订阅者B的Slot.index = replayIndex = 7。
delay(1000) //延迟一秒确保发送数据L被挂起了。
launch {
flow.collect{
debug("订阅者 B 取到数据 :$it")
delay(2000)
debug("订阅者 B 处理完数据 :$it")
}
}

时间来到第3秒,订阅者B从replayIndex开始取数据,取完数据H后,它不会对buffer做任何修改(它想改也改不了)。只是每次取完数据后对自己Slot.index++。2秒后,也就是第5秒开始取数据I。任然不会对bufer做任何修改,buffer维持原样。

时间来到第6秒,订阅者A处理完成数据E,订阅者B,此时正在处理数据I。订阅者A处理完成后开始取是数据F。
订阅者A取到数据F后。数据F就成为了无效数据了。因为没有人会消费它,因此订阅者A在取完数据(还未开始处理前)后会把数据F从buffer中移除,订阅者A的Slot.idex也要加一指向数据G,订阅者A作为慢的订阅者,minCollectorIndex代表了慢的订阅者下一次将要取数据的index,因此minCollectorIndex指向数据G。移除数据F后,bufferSize就减一变成了3,存在bufferSize < bufferCapacity。说明腾出空间了,可以用来放之前被挂起的Emitter。于是乎就把第一个挂起的Emitter从buffer中移除(把Emitter原来的位置存一个N0_VALUE),把Emitter中的数据放入buffer中。放入数据的index和之前emit发送数据的计算方式一样(head + bufferSize)and (buffer.size -1)=(6+3) and 7 = 1。移除了一个Emitter那么queueSize就要减一。把Emitter中的J放入了Buffer中。buffSize加一,这样一加一减,bufferSzie不变。
把数据J存入buffer中后,replayIndex需要加一变成8,指向数据I。最后唤醒被移除的emitter对应的协成,继续发送数据K。

–> 第6秒的时候订阅者A取到了数据F开始处理数据F。被唤醒的协成继续发送数据K。根据目前的buffer的情况,数据K也要包装成Emitter对象放入buffer中,buffer中新增了一个Emitter。因此queueSize加一。其他不变。

当时间来到第7秒的是时候,订阅者B处理完数据后I,开始取下一个数据,下一个数据是J。订阅者B取走数据J后,不会对buffer做任何修改,只会对自己Slot.index++。buffer里面的数据订阅者B一个都不能移除,因为订阅者A还需要消费,也不能唤醒挂起的Emitter,因为没有多余的空间来存放Emitter中的数据。因此订阅者B取完数据后,不会对buffer做任何修改。
在SharedFlow中,执行速度快的订阅者不会对buffer做任何修改。有一句话这么说的,先吃完的不管,后吃完的洗碗。

—>当时间来到第9秒的时候,订阅者B处理完成数据J后,再想取数的时候它取不到了,Buffer中没有数据了,只有两个挂起的Emitter。订阅者在bufferCapacity > 0 的情况下是不能直接从Emitter中拿数据的,因此订阅者B会被挂起。把订阅者B所在的协成存入Slot_B中。

—>当时间来到第12秒的时候,订阅自A处理完数据F,就开始取数据G。取到数据G后,对Slot_A.index加一等于7指向H。两个订阅者中A是最慢的,修改minCollectorIndex = Slot_A.index = 7。取出数据G后,数据G就变得无效了,会被订阅者A移除。移除后bufferSize减一变成了3。bufferSize < bufferCapacity。有新的空间可以用来唤醒挂起的Emitter。于是乎就把Emitter(L,con2) 从buffer中移除。把数据L放入index =(head + bufferSize) and (buffer.Size -1) = (7 + 3) and (8 -1) = 10 and 7 = 3的位置。存入了新的L,buffeSize加一。又是一加一减,bufferSize不变。但是少了一个Emitter。queueSize减一。存入数据L后,replayIndex加一等于9指向数据J。
订阅者A取完数据G后,因为把G移除,新加入了L。这时候如果有挂起的订阅者就可以被唤醒用来消费数据L了,于是乎订阅者A会把订阅自B唤醒。订阅者B唤醒后取Slot_B.index = 10的数据,刚好就是L。订阅者B被唤醒后会把Slot_B中的协成对象删除,
在12秒的时订阅者A取到数据G,

在第12秒的时候,订阅者B被唤醒后取到数据L后,把Slot_B.index加一变成11。buffer中其他都不变,订阅在A处理数据G,订阅在B处理数据L。
—>在第14秒的时候,订阅者B处理完成数据L。再想取Slot_B.index = 11的数据时,没有数据了,取不到了,于是乎订阅者B又被挂起了。把协成对象再存入Slot_B中。

—>时间来到第18秒,订阅者A处理完成G。开启取数据H。取到数据H后,Slot_A.index加一等于8指向数据I。minCollectorIndex= Slot_A.index = 8。数据H被订阅者A移除。移除数据H后,挂起的Emitter(K,con)就可以被移除,对应的协成被唤醒。协成被唤醒后在本例中就没有继续发送了。把Emitter从buffer中移除,把数据K放入buffer中,放入的位置为L的后面,replayIndex加一指向数据L
新放入了数据L。于是订阅者A又把订阅者B唤醒了。订阅者B被唤醒后去数据K。

在第18s,订阅者A取到数据H,开始处理数据H。订阅者B被唤醒后,取到数据K,把Slot_B.index加一变成了12。
在第20秒的时候,订阅者B处理完数据K后,开始取index = 12的数据,取不到buffer中最后一个数据就是K,没有数据了,于是订阅者B又被挂起了。

—>时间来到第24秒,订阅者A处理完数据H后,开始取数据I。取到数据I后Slot_A.Index加一,minCollectorIndex加一。数据I失效,将不再有订阅者会消费他了,因此数据I从Buffer中移除,bufferSzie减一。

这时候虽然订阅自B被挂起了,但是订阅者A不会唤醒订阅者B,因为没有新的数据可供订阅者B消费。
—>经过了6秒,时间来到30秒,订阅者A处理完数据I后,开始取数据J,取到数据J后,Slot_A.Index加一,minCollectorIndex加一。数据J失效,将不再有订阅者会消费他了,因此数据J从Buffer中移除,bufferSzie减一。同样不会唤醒订阅B

—>经过了6秒,时间来到36秒,订阅者A处理完数据J后,开始取数据L,取到数据L后,Slot_A.Index加一,minCollectorIndex加一。由于replayIndex指向了数据L,此时buffer中只有L和K两个数据,为了保证新的订阅者来了后能回放两个数据,所以数据L不会失效。同样不会唤醒订阅B

—>经过了6秒,时间来到42秒,订阅者A处理完数据L后,开始取数据K,取到数据K后,Slot_A.Index加一变成了12,minCollectorIndex加一也变成了12。同样的未来保证新的订阅者能回放两个数据,replayIndex不变。同样不会唤醒订阅B

----经过6秒,时间来到48秒,订阅者A处理数据K后,在想取数据的时候,buffer中没有新的数据供它消费了,于是订阅者A被挂起,把协成保存在Slot_A中,到此,两个订阅者都被挂起了。

至此,两个订阅者都被挂起了,如果这时候在往SharedFlow中发送一条数据,两个订阅者都会被唤醒。
完整源码:
val currentTime = System.currentTimeMillis()
fun main() = runBlocking {
val flow = MutableSharedFlow<Char>(
replay = 2,
extraBufferCapacity = 2,
onBufferOverflow = BufferOverflow.SUSPEND
)
for(data in 'A' ..'D'){
debug("---------> 开始发送数据 $data")
flow.emit(data) //连续发送数据A,B,C,D
debug("把$data 放入了buffer中 <------------")
}
debug("---------> 开始发送数据 E")
flow.emit('E') //发送数据 E
debug("把E 放入了buffer中 <------------")
debug("---------> 开始发送数据 F")
flow.emit('F') //发送数据 E
debug("把F 放入了buffer中 <------------")
//单独开一个子协成来接收数据,因为collect是一个suspend函数。不单独开一个协成被挂起后导致后面代码没法执行
launch {
flow.collect{
debug("订阅者 A 取到数据 :$it")
delay(6000)
debug("订阅者 A 处理完数据 :$it")
}
}
delay(1000)
launch {
for(data in 'G' ..'K'){
debug("---------> 开始发送数据 $data")
flow.emit(data) //连续发送数据G,H,I,J,K
debug("把$data 放入了buffer中 <------------")
}
}
delay(1000)
launch {
debug("---------> 开始发送数据 L")
flow.emit('L') //发送数据 L
debug("把L 放入了buffer中 <------------")
}
delay(1000)
launch {
flow.collect{
debug("订阅者 B 取到数据 :$it")
delay(2000)
debug("订阅者 B 处理完数据 :$it")
}
}
Unit
}
fun debug(mes : String){
val pre = (System.currentTimeMillis() - currentTime) / 1000
println("在第${pre}秒的时候 $mes")
}
//输出结果:
在第0秒的时候 ---------> 开始发送数据 A
在第0秒的时候 把A 放入了buffer中 <------------
在第0秒的时候 ---------> 开始发送数据 B
在第0秒的时候 把B 放入了buffer中 <------------
在第0秒的时候 ---------> 开始发送数据 C
在第0秒的时候 把C 放入了buffer中 <------------
在第0秒的时候 ---------> 开始发送数据 D
在第0秒的时候 把D 放入了buffer中 <------------
在第0秒的时候 ---------> 开始发送数据 E
在第0秒的时候 把E 放入了buffer中 <------------
在第0秒的时候 ---------> 开始发送数据 F
在第0秒的时候 把F 放入了buffer中 <------------
在第0秒的时候 订阅者 A 取到数据 :E
在第1秒的时候 ---------> 开始发送数据 G
在第1秒的时候 把G 放入了buffer中 <------------
在第1秒的时候 ---------> 开始发送数据 H
在第1秒的时候 把H 放入了buffer中 <------------
在第1秒的时候 ---------> 开始发送数据 I
在第1秒的时候 把I 放入了buffer中 <------------
在第1秒的时候 ---------> 开始发送数据 J
在第2秒的时候 ---------> 开始发送数据 L
在第3秒的时候 订阅者 B 取到数据 :H
在第5秒的时候 订阅者 B 处理完数据 :H
在第5秒的时候 订阅者 B 取到数据 :I
在第6秒的时候 订阅者 A 处理完数据 :E
在第6秒的时候 订阅者 A 取到数据 :F
在第6秒的时候 把J 放入了buffer中 <------------
在第6秒的时候 ---------> 开始发送数据 K
在第7秒的时候 订阅者 B 处理完数据 :I
在第7秒的时候 订阅者 B 取到数据 :J
在第9秒的时候 订阅者 B 处理完数据 :J
在第12秒的时候 订阅者 A 处理完数据 :F
在第12秒的时候 订阅者 A 取到数据 :G
在第12秒的时候 把L 放入了buffer中 <------------
在第12秒的时候 订阅者 B 取到数据 :L
在第14秒的时候 订阅者 B 处理完数据 :L
在第18秒的时候 订阅者 A 处理完数据 :G
在第18秒的时候 订阅者 A 取到数据 :H
在第18秒的时候 把K 放入了buffer中 <------------
在第18秒的时候 订阅者 B 取到数据 :K
在第20秒的时候 订阅者 B 处理完数据 :K
在第24秒的时候 订阅者 A 处理完数据 :H
在第24秒的时候 订阅者 A 取到数据 :I
在第30秒的时候 订阅者 A 处理完数据 :I
在第30秒的时候 订阅者 A 取到数据 :J
在第36秒的时候 订阅者 A 处理完数据 :J
在第36秒的时候 订阅者 A 取到数据 :L
在第42秒的时候 订阅者 A 处理完数据 :L
在第42秒的时候 订阅者 A 取到数据 :K
在第48秒的时候 订阅者 A 处理完数据 :K
buffer能缓存数据的多少有由replay 和 extBufferCapacity两个参数决定的,当缓满了的时候即bufferSize > bafferCapacity的时候的做法由溢出策略决定。在前面的example中我们列举了replay > 0 ,extBufferCapacity >0,onBufferOverflow = SUSPEND时buffer在发送和接收数据时的一个运行情况。当然还有其他情况,每种情况buffer的工作方式有所不同,这三个参数一共可以组合成10中情况:
replay > 0 ,extBufferCapacity > 0,onBufferOverflow = SUSPEND | DROP_OLDEST | DROP_LATEST (3种)
replay > 0 ,extBufferCapacity = 0,onBufferOverflow = SUSPEND | DROP_OLDEST | DROP_LATEST (3种)
replay = 0 ,extBufferCapacity > 0,onBufferOverflow = SUSPEND | DROP_OLDEST | DROP_LATEST (3种)
replay = 0 ,extBufferCapacity = 0,onBufferOverflow = SUSPEND (1种)
在这里我们再具体讲一下replay = 0 ,extBufferCapacity = 0,onBufferOverflow = SUSPEND这种情况,其他8种就不举例讲解了。在后面我会放出一个总结图,感兴趣的可以结合源码和总结图自行学习。
Example2:
**Step1:**创建一个 replay = 0 ,extBufferCapacity = 0,onBufferOverflow = SUSPEN 的SharedFlow。这种情况比较特殊,又称之为“sync case”,也叫同步。意思就是说所有发送的数据都需要包装成Emitter对象放入Buffer中(在有订阅者的情况下),即emit函数会被挂起,每一个挂起的emit函数只有在已有所有订阅者都消费完该数据后才会被唤醒。
val flow = MutableSharedFlow<Char>() //全部采用默认参数
**Step2:**在没有订阅者情况下发送几条数据:
//也不用单独开协成取发送数据,因为不会挂起emit
for(data in 'A' ..'D'){
flow.emit(data) //连续发送数据A,B,C,D
}
在没有订阅者的情况下,发送对的数据依然会被丢弃。想想也是这么个道理,因为replay = 0,意味着不支持回放,那么在没有订阅者的情况下如果把数据放入buffer中有什么意义呢?
**Step3:**先整上一个订阅者:
launch {
flow.collect{
debug(" 订阅者1 收到数据 $it")
delay(3000)
debug("订阅者1 处理完数据 $it ")
}
}
这时候你订阅者1不会收到任何数据,因为buffer中没有任何数据。订阅者1被挂起等待,因此会为订阅者1创建一个Slot对象存入slots数组里面,并把订阅者1所在的协成保存在创建的Slot对象中:

Step4:延迟一秒,开始发送数据,这时候因为有订阅者了,所以会挂起emit。因此需要单独开协成:
delay(1000) //延迟一秒确保订阅者处于挂起等待
repeat(6){ //开启了6个协成,每个协成发送一个数据,分别发送E,F,G,H,I,J
val data = ('E'.code + it).toChar()
launch {
debug(" ---> 协成 $it 开始发送数据 $data")
flow.emit(data)
debug("协成 $it 发送数据完成 <---")
}
}
由于bufferCapacity = 0因此每一次emit发送的数据都需要包装成Emitter对象放入buffer中,并把协成挂起,所以每一次emit都需要单独开一个协成。这里相当于6个协成都会被挂起。发送E的时候会创建一个长度为2的数组,发送G的时候会扩容到4,发送I的时候会扩容到8。

发送数据E的时候,发现slots中有挂起等待的订阅者就回去调用con1.resume把订阅者1唤醒,把Slot_1.con1 = null。由于本例的代码是连续启动6个协成发送数据,因此在6个Emittter都放入了buffer后,订阅自1所在的协成才开始接收数据,如果稍微发送数据的速度慢一点,就会存在6个Emitter还没有全部放入buffer,订阅者1已经取到数据E的情况。这都不重要,至少Emitter(E)已经进去了。
订阅者1被唤醒后,开始取数据,从什么地方开始取呢?以什么依据呢?订阅者取数据的依据是根据Slot.index。不管创建SharedFlow时的参数是什么情况,新订阅者来的时候,每一个Slot被创建(或者被复用)时其index初始值都等于replayIndex。在bufferCapacity = 0时,每次发送数据把emit挂起都不会去更改replayIndex的值(bufferCapacity > 0 时除外),因此replayIndex在第一个订阅者来的时候任然为默认值0。于是订阅者1开始从数组中index = 0 的位置开始取数据。
订阅者1取到数据后(还未开始处理之前) 把Slot_1.index ++。 把relayIndex++, 由于目前只有一个订阅者,因此minCollectorIndex就是订阅者1下一次要取数据的index。于是minCollectorIndex = relayIndex。取完数据E后,也没有其他订阅者了,数据E对应的协成就可以唤醒了。Emitter也可以移除了,移除Emitter后,queueSize–。

在第一秒的时候订阅者1取到数据后开始出路数据,处理数据需要3秒钟。
Step5:继续增加一个订阅者2,订阅者2处理数据速度比订阅者1快只需要1秒。
delay(1000) //继续延迟一秒,确保订阅者1已经开始处理数据。
launch {
flow.collect{
debug("订阅者2 收到数据 $it")
delay(1000)
debug("订阅者2 处理完数据 $it ")
}
}
在第2秒的时候,订阅者2来了,为订阅者2创建一个Slot对象。此时replayIndex = 1,因此订阅者2的Slot.index = 1。订阅者2能取到数据F。订阅者2不会挂起。订阅者2取到数据F后,发现订阅者1还没有取数据F,于是订阅者1就成了最慢的订阅者。订阅者2作为消费速度比较快的订阅者,取到数据后不会对buffer做任何改动(先吃完不管,后吃完洗碗)。订阅者2只会把自己的Slot。index ++。

订阅者2取完数据F后,不会唤醒F对应的协成,因为订阅者1还没有消费数据F,这就是sync case 的SharedFlow。一个挂起的Emitter需要所有订阅者都消费了该数据才会被唤醒,
由于订阅者2处理数据的速度比较快,在第3秒的时候,订阅者2准备取index = 2的数据。这时候对于sync case的情况,是不会让订阅者2继续取数据的。源码中的注释把sync case 叫做 Rendezvous。中文约会的意思,把Slot从Emitter中取数据看着是Slot和Emitter约会,就好比A和B两个人约会,在其中一个还没离开的时候,另一个怎么好意思离开继续下一次约会。
于是乎订阅者2在第三秒的时候被挂起了。

Step5:时间来到第4秒。订阅者1处理完数据E,订阅者1开始取数据F。订阅者1取完数据F后,把自己的index++。把replayIndex++,把minCollectorIndex = Slot_1.index(始终代表最慢的订阅者)。 数据F被订阅者1取到后,就可以被移除了(订阅者2已经消费了)。于是订阅者1把数据F移除,调用数据F对应的协成resume函数唤醒协成。queueSize减一,totalSize减一。

订阅者1取完数据F,移除数据F后,发现订阅者2被挂起了,因此会去尝试唤醒订阅者的协成(能不能唤醒要看订阅者2唤醒后能不能取到数据,如果能取到数据就会被唤醒)。
在这里订阅者2是能够被唤醒的,因为Emitter(F,con1)已经被移除了,相当于说Slot_2可以开始和下一个人约会了。所以在第4秒时,订阅者1取到数据F,在处理F期间,订阅者2开始取数据G。订阅者2取到数据G后,同样它作为快的订阅者不会对buffer做任何修改,只会把自己的slot.index加一。
在第5秒的时候订阅者2处理完数据G后,想取数据H的时候又被挂起了。和之前取完数据F想取数据G挂起是一样的。
**Step6:**在第7秒的时候,订阅者1处理完成数据F后,开始取数据G,订阅者1取完数据G后,把自己的index++,把replayIndex++。把minCollectorIndex = Slot_1.index(始终代表最慢的订阅者)。 数据G被订阅者1取到后,就可以被移除了(订阅者2已经消费了)。于是订阅者1把数据G移除,调用数据G对应的协成resume函数唤醒协成。queueSize减一,totalSize减一。

订阅者1取完数据G,移除数据G后,发现订阅者2被挂起了,因此会尝试唤醒订阅者2,这里是能唤醒的。于是乎订阅者1在处理数据G的时候,订阅者2开始取数据H。
往后的流程都这样。就不在继续讲了。最终直到订阅者1和订阅者2把所有数据都取到,把所有挂起的发送方协成都唤醒,最后订阅者1和订阅者2没数据可取,订阅者1和订阅者2自己挂起。
在第14秒的时候订阅者2被挂起,在第19秒的时候订阅者1被挂起。

Step7:这时候如果再发送一个数据L。同样会把数据L和协成对象包装成一个Emitter对象存入数组中index = 6的位置,然后唤醒订阅者1和订阅者2。
delay(20000) //延迟20秒,之前已经有两次延迟一秒,也就是说在第22秒的时候发送数据L
debug(" --->开始发送数据 L")
flow.emit('k')
debug("发送数据 L 完成 <---")
在订阅者还没开始取数据前,buffer 情况如下:

订阅者1和订阅者2都取完数据后L后,订阅者1和订阅者2又被挂起了。细节就不在赘述了。
这里再强调一点,如果继续发送数据,只要totalSize < buffer.size(数组实际长度)就不会扩容,会循环利用前面的空间。
在这里已经列举了两种情况,限于篇幅有限,其他八种情况就不列举了。可以通过后面的源码自行了解,这里给出了一个简单的总结图:

SharedFlow源码
源码基于协成版本1.6.1
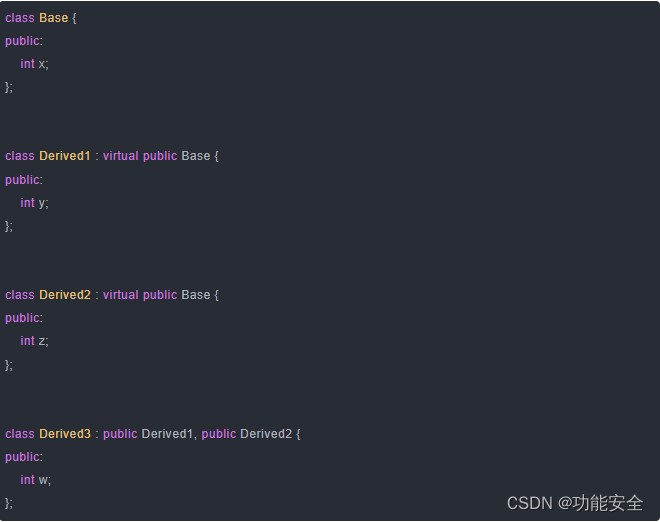
关于源码的介绍,从发送,接收,连个方面来讲,在这之前,先介绍一个SharedFlow类继承关系。

这里面涉及的类不是很多,大部分都是接口。其中四个比较重要的类(也是唯一4个class):
SharedFlowSlot
代表了一个订阅者,每一个订阅者来了后都要为其分配一个Slot对象,Slot里面有两个属性,index记录了订阅者需要取的数据在buffer中的下标。cont属性记录了订阅者需要挂起时的协成对象。
Emitter
当调用emit函数发送数据时,需要把emit函数挂起时,会把要发送的数据,和挂起的协成封装成一个Emitter对象存入Buffer中。
AbstractSharedFlow
作为SharedFlowImpl的父类,里面的代码比较简单,在它里面定义了slots这个缓存,这个类里面就两个有用的函数,主要为slots这个缓存服务,比如创建slots数组,给数组扩容,有订阅者来了后为订阅分配Slot对象(创建新的或者复用之前的)并放入slots数组里面,当有订阅者取消后,把对应的Slot重置(以后复用)。
SharedFlowImpl
这个就是今天的主角,基本上所有的逻辑都写在这个里面了,负责处理发送,接收,维护buffer整个缓存系统等几乎又有工作。
关于SharedFlowImpe中定义的各种index和size属性在前面已经说了,这里就不在赘述了。
发送数据
调用emit函数发送一个数据,emit函数是一个挂起函数。当有订阅者存在,buffer不能存放数据(bufferSize > bufferCapacity 或者 bufferCapacity = 0) ,并且缓存溢出策略为SUSPEND时,emit函数就会挂起。
override suspend fun emit(value: T) {
//先调用tryEmit发送数据,
if (tryEmit(value)) return
//tryEmit返回false,就需要把emit挂起。emitSuspend中创建Emitter对象,并将其放入buffer中,
//然后返回一个挂起表示,让协成挂起。
emitSuspend(value)
}
所以调用emit发送数据可以分为两步:第一步先tryEmit,试试能不能按照规则发送成功,如果能就直接返回,不需要挂起,第二步:在第一步失败的情况下创建Emitter对象把emit函数挂起。
–> tryEmitt()
override fun tryEmit(value: T): Boolean {
//一个空数组
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
//枷锁,SharedFlow里面大量使用了synchronized来保证线程安全。
val emitted = synchronized(this) {
//继续调用tryEmitLocked函数发送数据,在SharedFlow中有大量函数命名是以"locked"结尾,这说明该函数
//是调用在synchronized里面的,是线程安全的。
if (tryEmitLocked(value)) {
//如果tryEmitLocked发送成功了,就去找找有没有挂起的订阅者满足条件能被唤醒。有就把满足条件的
//的协成放入resumes这个数组中。
resumes = findSlotsToResumeLocked(resumes)
//返回true 代表了这次发送成功了(成功不一定能会放入buffer,有可能丢掉了,比如溢出策略为DROP_LATEST)
true
} else {
//返回fase 代表了这次发送失败,需要走第二步把emit挂起。
false
}
}
//只有发送成功了 resumes里面才有可能有数据,因此如果发送成功了,有满足挂起的订阅者就唤醒他们来取数据。
for (cont in resumes) cont?.resume(Unit)
//返回结果,true,表示发送成功不需要挂起,false,表示失败,需要挂起。
return emitted
}
//该函数要做的事情就是去已有的所有订阅者去找,找满足条件并且被挂起的订阅者,可能存在多个,因此找到了就
//把对应的协成放入一个数组中,然后返回出去集中唤醒。让这些挂起的订阅者醒来取数据。
private fun findSlotsToResumeLocked(resumesIn: Array<Continuation<Unit>?>): Array<Continuation<Unit>?> {
var resumes: Array<Continuation<Unit>?> = resumesIn
var resumeCount = resumesIn.size
forEachSlotLocked loop@{ slot ->
val cont = slot.cont ?: return@loop //cont 为空说明该订阅者没有被挂起,跳过
//tryPeedk意思就是去尝试一下假如该订阅者被唤醒后能不能满足取数据的条件。
//比如有的订阅者已取完buffer中最后一个数据后被挂起了,buffer中没有新数据,那唤醒后也取不到数据,
//因此就没必要唤醒,tryPeek中有很多种判断情况,具体查看该函数
if (tryPeekLocked(slot) < 0) return@loop
//如果该订阅者满足唤醒,那就把该订阅者对应的协成放入resumes这个数组中。如果数组中没有空间
//放不下协成对象,就对数据扩容,也是扩容2倍,扩容或在把协成对象加入进去。
if (resumeCount >= resumes.size) resumes = resumes.copyOf(maxOf(2, 2 * resumes.size))
resumes[resumeCount++] = cont //把挂起的订阅者的协成放入resumes中
//把slot.con = null 意思就是该订阅者即将要被唤醒了,不需要挂起等待了。con是否为null就是判断
//一个订阅者是否被挂起的依据。
slot.cont = null // not waiting anymore
}
return resumes
}
// 该函数就是校验一个订阅者下一次是否能取导数据。返回-1说明取不到,否则能取到
private fun tryPeekLocked(slot: SharedFlowSlot): Long {
//index 是该订阅者下一次要取数据的index.
val index = slot.index
//如果下一次要取的数据index <= buffer中最后一个数据的index。那就说明有数据供它取
if (index < bufferEndIndex) return index
/**
* bufferCapacity > 0 说明buffer是支持缓存的,在这种情况下 index > bufferEndIndex 说明
* 该订阅者已经消费完了buffer中已有的数据,这时候再唤醒它也没有新数据供他消费,因此没有必要唤醒。
* 即使这时候有挂起的Emitter,也不能去取挂起的Emitter中的数据,挂起的emitter需要等订阅者把buffer中
* 数据消费了后,这个数据变成无效数据被删除后,给buffer腾出空间了,才能把Emitter中的数据拿出来放入buffer中,
* 然后移除Emitter,把Emitter对应的协成唤醒。
*/
if (bufferCapacity > 0) return -1L
//以下的情况是针对 sync case ,即bufferCapacity= 0 的处理。
//针对bufferCapacity = 0 ,即 sync case 的情况。index > head。说明该订阅者要取的数据的前面任然是一个
//Emitter对象,即该订阅者将要取的数据的前面的Emitter还有订阅者没有消费。因为是sync case,因此这个订阅者
//不能继续取数据,得等前面对Emitter被所有订阅者消费完成后,移除后,该订阅者才能继续取数据,
//这种情况在前面缓存系统example里面就遇到过。
if (index > head) return -1L
// 同样是针对sync case。如果此时没有挂起的Emitter。那你把它唤醒起来取什么呢?因此也没必要。sync case 时
//订阅者都是从挂起的Emitter中取数据。
if (queueSize == 0) return -1L
// 经过以上层层筛选都没有返回-1。说明index 现在就指向了buffer中第一个Emitter。并且index前面
//没有Emittter了,该订阅者可以被唤醒。去取buffer中第一个Emitter中的数据。
return index //
}
–> tryEmitLocked()
@Suppress("UNCHECKED_CAST")
private fun tryEmitLocked(value: T): Boolean {
//如果没有订阅者,就走tryEmitNoCollectorsLocked,该函数永远return true。
//这就是在前面讲的,没有订阅者时永远不会挂起emit。
//tryEmitNoCollectorsLocked做的事情就是如果replay > 0 就把数据放入buffer中,否则丢弃直接return true。
if (nCollectors == 0) return tryEmitNoCollectorsLocked(value) // always returns true
/**
* 有订阅者时:
* 1.检查buffer中已经缓存的数据是否大于等于bufferCapacity
* 2.minCollectorIndex <= replayIndex 那就说明head = minCollectorIndex,也就是说
* buffer中目前第一个数据虽然不在回放范围之类,但是目前有订阅者还没消费该数据,同时也说明了
* replayIndex前面的数据是不能被清除的,还有订阅者为消费。
* 两个条件都满足就说明buffer满了并且buffer中的数据都是有效的,不能清除。这就导致本次发送的数据
* 不能放入buffer中,那就根据溢出策略来执行。
*/
if (bufferSize >= bufferCapacity && minCollectorIndex <= replayIndex) {
when (onBufferOverflow) {
//溢出策略为Suspend,那么需要把本次发送挂起
BufferOverflow.SUSPEND -> return false
//溢出策略为DROP_LATEST,丢掉本次发送的数据,直接return true。表明本次发送数据是成功的。
BufferOverflow.DROP_LATEST -> return true
//溢出策略为DROP_OLDEST,那就继续往下走,把本次数据加入buffer中,删除buffer中最久的(head指向)
BufferOverflow.DROP_OLDEST -> {} // force enqueue & drop oldest instead
}
}
//把本次数据加入Buffer中
enqueueLocked(value)
bufferSize++ //buffer中增加了一个数据,因此bufferSize++
// 加入本次数据后,如果出现bufferSize > bufferCapacity。那么就需要删除buffer中最久的那一个数据
if (bufferSize > bufferCapacity) dropOldestLocked()
//此时relayIndex还指向原来的,buffer中加入一个新数据后,如果还按照原来的replayIndex计算,那么就可能
//出现可回放的数据超出了规定的个数(replay)。如果是这种情况,就需要把replayIndex向前移动一个,加一。
//始终让可回放的个数小于等于replay。
/**
* 比如raply = 4,extBufferCapacity = 2
* buffer中又6个数据,
* [a,b,c,d,e,f]
* replayIndex =2.指向了c,minCollectorIndex = 0。
* 此时发送了g,溢出策略DROP_OLDEST。把g加入进去了后,把a删除了。
* 在dropOldestLocked中会把minCollectorIndex指向b。
* [g,b,c,d,e,f]
* replayIndex依然等于2,就存在了(replaySize = 5) > (replay = 4)的情况。
* 因此需要把replayIndex改为3,指向数据d。这样可回放的数据就是d,e,f,g,就没有问题了
*/
if (replaySize > replay) { // increment replayIndex by one
//updateBuffer就是去更新各种index 和size属性,
updateBufferLocked(replayIndex + 1, minCollectorIndex, bufferEndIndex, queueEndIndex)
}
//返回treu,表示本次发送成功,不需要挂起。
return true
}
–>–> tryEmitNoCollectorsLocked
该方法就是针对没有订阅者的时候发送数据。
private fun tryEmitNoCollectorsLocked(value: T): Boolean {
assert { nCollectors == 0 } //再次确认没有订阅者,如果有就抛出异常
//如果不支持回放,在没有订阅者的情况下直接丢掉本次数据,因此直接返回true。不需要挂起本次emit
if (replay == 0) return true
//支持回放,那就把数据直接加入到buffer中。
enqueueLocked(value)
bufferSize++ //增加了数据,那对应的size也需要加一
//在没有订阅者的情况下是不需要采用extBufferCapacity的。所以当buffer中数据超过replay后,就需要把最久
//的那个数据删除了。始终让buffer中保持不超过replay个最新数据,用于支持回放。
if (bufferSize > replay) dropOldestLocked()
//没有订阅者的情况下,minCollectorIndex保持默认最大值。指向了buffer中最后一个数据的下一个位置。
//也就是指向了bufferEndIndex。
minCollectorIndex = head + bufferSize
//在没有订阅者的情况下永远return true。
return true
}
–>–> enqueueLocked
该函数的作用就是把数据加入buffer中。
private fun enqueueLocked(item: Any?) {
//目前buffer中已经缓存的元素总的个数(缓存数据+ 缓存的Emitter)
val curSize = totalSize
val buffer = when (val curBuffer = buffer) {
//如果是第一次,在growBuffer中会创建一个长度为2的数组。
null -> growBuffer(null, 0, 2)
//buffer的数组已经有了,如果buffer中已经没有剩余空间放本次数据,那就需要扩容2倍。扩容后
//把原来的数据转移到新的buffer中。
//如果buffer有剩余空间,那就什么都不用管,直接把本次数据加入buffer中。
else -> if (curSize >= curBuffer.size) growBuffer(curBuffer, curSize,curBuffer.size * 2) else curBuffer
}
//把本次发送的数据,放入buffer中,放入的位置为原来已有元素的最后一个数据后面,
buffer.setBufferAt(head + curSize, item)
}
//扩容buffer。
private fun growBuffer(curBuffer: Array<Any?>?, curSize: Int, newSize: Int): Array<Any?> {
//如果扩容2倍后尺寸超过了Int.MAX_VALUE,那么newSize就成了负数,因此抛出异常
check(newSize > 0) { "Buffer size overflow" }
//创建一个newSize的新数组
val newBuffer = arrayOfNulls<Any?>(newSize).also { buffer = it }
//curBuffer = null,说明是第一次,直接把创建长度为2的数组返回出去,不需要做数据拷贝
if (curBuffer == null) return newBuffer
//下面开始数据拷贝。
val head = head //从原来数组中head指向的数据开始拷贝。
//curSize代表了buffer中已经存了的元素的总的个数,一个一个的拷贝,因此需要拷贝curSize次
for (i in 0 until curSize) {
//从原来数组中取出数据,拷贝到新数组中,这里拷贝到新数组中的位置和原来数组中的位置一致。
//比如原来数组中第一个数据head =3,那么把这个数据拷贝到新数组中的位置也是3。
newBuffer.setBufferAt(head + i, curBuffer.getBufferAt(head + i))
}
//把处理好的新数组返回出去。
return newBuffer
}
//从buffer中指定位置取出一个数据,把index 和 (size-1)做与运算,这样能让数组形成一个循环。
private fun Array<Any?>.getBufferAt(index: Long) = get(index.toInt() and (size - 1))
//把数据放入buffer中指定的位置,同样 index 和 (size-1)做与运算,这样能让数组形成一个循环。
private fun Array<Any?>.setBufferAt(index: Long, item: Any?) = set(index.toInt() and (size - 1), item)
–>–> dropOldestLocked
该函数就是把buffer中存在最久的数据从buffer中删除。
private fun dropOldestLocked() {
//存在最久的肯定是buffer中第一个数据,因此直接把head指向的位置设置成null。
buffer!!.setBufferAt(head, null)
bufferSize-- //少了一个数据,size减一
//原来head指向的数据被删除了,那head就要指向下一个数据。
val newHead = head + 1
//replayIndex < newHead,那就说明replayIndex和原来的head相等。原来的数据被删除了,删除之前已经新进来一个了
//那就让replayIndex和newHead相等。
if (replayIndex < newHead) replayIndex = newHead
//minCollectorIndex < newHead说明已有订阅者中速度最慢的订阅者下一次将要取的数据就是被删除的这个数据。
//所以需要把minCollectorIndex指向newHead,同时还要让已有订阅者中,将要取被删除数据的订阅者跳过被删除的数据,
//直接取newHead这个数据。correctCollectorIndexesOnDropOldest就是干这事情。
if (minCollectorIndex < newHead) correctCollectorIndexesOnDropOldest(newHead)
//head = minOf(minCollectorIndex, replayIndex),head == newHead,说明前面俩个if处理是正确的。
assert { head == newHead }
}
private fun correctCollectorIndexesOnDropOldest(newHead: Long) {
//便利slots中左右的订阅者
forEachSlotLocked { slot ->
//slot.index > 0 说明这个slot是有效的,和订阅自绑定了(index = -1 说明是一个无效的,是用来复用的)。
// slot.index < newHead 说明该订阅者下一次将要取的数据是刚被删那个数据。
if (slot.index >= 0 && slot.index < newHead) {
//因此就把订阅者下一次将要去的数据跳过被删除的,直接取newHead指向的数据。
slot.index = newHead
}
}
//让inCollectorIndex指向newHead
minCollectorIndex = newHead
}
–>–>updateBufferLocked
该函数就是去更新buffer的各种index和size属性。
private fun updateBufferLocked(
newReplayIndex: Long,
newMinCollectorIndex: Long,
newBufferEndIndex: Long,
newQueueEndIndex: Long
) {
// 计算新的head
val newHead = minOf(newMinCollectorIndex, newReplayIndex)
assert { newHead >= head } //head只会递增,因此如果出现newHead < head,比如是某个地方逻辑不对,直接抛异常
//如果newHead > head。那就需要把newHead前面的数据都移除。没有任何用处了。
for (index in head until newHead) buffer!!.setBufferAt(index, null)
//更新各种index和size
replayIndex = newReplayIndex
minCollectorIndex = newMinCollectorIndex
bufferSize = (newBufferEndIndex - newHead).toInt()
queueSize = (newQueueEndIndex - newBufferEndIndex).toInt()
//对更新后的size和index做校验,如果不满足那就是某个地方逻辑不对,直接抛出异常
assert { bufferSize >= 0 }
assert { queueSize >= 0 }
assert { replayIndex <= this.head + bufferSize }
}
至此tryEmit涉及到的源码都讲完了。如果tryEmit返回false。那就需要把本次emit挂起,根据前面的分析,只有当有订阅者存在,并且bufferSize > bufferCapacity ,并且buffer中已有的数据都不能删除,并且溢出策略为suspend时才会返回false(简单的来说就是本次发送的数据不能放入buffer中,buffer已经满了,腾不出空间了)。那就走emitSuspend
–> emitSuspend
该函数做事情就是创建一个Emitter对象,包含了要发送的数据和需要挂起的协成,把Emitter放入buffer中。返回一个挂起标识让协成挂起。在里面还做了一件事情就是,去检查一下有没有挂起的订阅者,有的话就去唤醒订阅者让其醒来取本次挂起的数据。
如果你还不了解suspendCancellableCoroutine的原理可以点击 你真的了解kotlin中协程的suspendCoroutine原理吗?
private suspend fun emitSuspend(value: T) = suspendCancellableCoroutine<Unit> sc@{ cont ->
//整一个空数组,在需要的时候扩容用来装可被唤醒的订阅者
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
val emitter = synchronized(this) lock@{
//该函数在前面讲过,在这里就是再次tryEmiit。因为有可能在调用emitSuspend之前有订阅者消费了buffer中的数据
//并把该数据移除了,为buffer腾出空间了,可以容纳本次要发送的数据。
if (tryEmitLocked(value)) { //再次尝试如果成功了,则不需要挂起
cont.resume(Unit) //调用resume。 emitSuspend就会返回一个Unit。最终emit返回Unit就不会挂起了。
//跟前面的逻辑一样,找找有没没有满足唤醒条件的订阅者,有的话就找出来,一会统一唤醒。
resumes = findSlotsToResumeLocked(resumes)
return@lock null //返回出 synchronized。继续执行后面的代码
}
// 上面调用tryEmitLocked任然失败了,那就创建一个Emitter对象,把本次emit挂起。
//Emitter中包含了SharedFlow,还有它所在buffer中对应的index,本次要发送的数据,需要挂起的协成。
Emitter(this, head + totalSize, value, cont).also {
//把Emitter加入buffer中
enqueueLocked(it)
queueSize++ //buffer中存入的Emitter数量加一
//如果是sync case。新的Emitter被加入了buffer,那就去找找有没有满足条件被挂起的订阅者
//如果有,找出来,然后一统一唤醒,让他们来取Emitter中的数据,
if (bufferCapacity == 0) resumes = findSlotsToResumeLocked(resumes)
}
}
// 如果把本次发送挂起了,那么注册一个协成取消的回调。Emitter这个类实现了DisposableHandle这个接口。
//当挂起的协成被取消时,就会回调Emitter的dispose函数。在dispose函数中会把该Emitter从buffer中移除。
emitter?.let { cont.disposeOnCancellation(it) }
//统一唤醒满足唤醒条件被挂起的订阅者。
for (r in resumes) r?.resume(Unit)
}
private class Emitter(
@JvmField val flow: SharedFlowImpl<*>,
@JvmField var index: Long,
@JvmField val value: Any?,
@JvmField val cont: Continuation<Unit>
) : DisposableHandle {
//当对应的协成被取消时,从buffer中移除自己
override fun dispose() = flow.cancelEmitter(this)
}
}
private fun cancelEmitter(emitter: Emitter) = synchronized(this) {
if (emitter.index < head) return // 说明emitter已经被移除了。不在buffer中了
val buffer = buffer!!
//说明emitter已经被订阅者消费了,已经唤醒过了。即emitter也不在buffer中了。
if (buffer.getBufferAt(emitter.index) !== emitter) return
//把emitter从buffer中移除。移除的方式是在原来的位置存入NO_VALUE来代替,并不会
//改变queueSize.
buffer.setBufferAt(emitter.index, NO_VALUE)
//该函数相当于对buffer进行一个整理操作。
//意思就是如果buffer的尾部是NO_VALUE,那就把NO_VALUE移除,存入null,对queueSize--。
cleanupTailLocked()
}
/**
* 该函数是对buffer中存Emitter那部分区域做回收,在前面缓存的时候我们就讲过,如果bufferCapacity > 0 ,
* buffer就会被分为两个区域,一个用来存发送的数据,当emit需要挂起时另一个区域用来存Emitter。
* 存数据的区域会在每次存入或者取走数据时会对这个区域里面无效的数据进行移除,会对bufferSize
* 进行相应的加一或者减一,但是另外一个存Emitter的区域在挂起emit的协成被取消导致Emitter对象移除时,
* 只是在其原来的位置存入了一个NO_VALUE,queueSize并没有减一。为什么SharedFlow没有在对移除一个Emitter的时候
* 对queueSize减一呢?你试想一下,如果移除的Emitter是处于中间(前后还有其他Emitter)。如果要把queueSize减一
* 那么就需要把被移除的这个Emitter后面的所有Emitter都向前移动。这对性能上来说是有一定的影响的。
*
* 所以为了保证性能不受印象,又能让buffer正常工作,就把移除的Emitter用NO_VALU代替,但是如果移除的Emitter是
* 数组中最后一个Emitter,那就可以做到真正移除(不需要添加一个NO_VALUE,并且让queueSize减一),因为不涉及到
* 对数组中其他Emitter移位。
* 因此cleanupTailLocked干的事情就是从Buffer中存Emitter区域的尾部开始遍历,如果是N0_VALUE,就可以存入
* 一个null,让queueSize减一
*
* 这样做还有一个好处就是,当buffer中存Emitter的部分全是NO_VALUE的时候,可以把全部NO_VALUE都清除,
* 让这部分缓存重复利用起来。
*/
private fun cleanupTailLocked() {
//如果是sync case, 并且buffer中只有一个Emiiter。不需要清理
if (bufferCapacity == 0 && queueSize <= 1) return // return, don't clear it
val buffer = buffer!!
//从尾部开始遍历,如果尾部最后一个是NO_VALUE。那就queuesize --.并把NO_VALUE移除,存入一个null。
while (queueSize > 0 && buffer.getBufferAt(head + totalSize - 1) === NO_VALUE) {
queueSize--
buffer.setBufferAt(head + totalSize, null)
}
}
发送相关的源码到此就结束了。没有什么难度,结合前面的example,或者自己写个demo。多看两遍,或者debug跟一下,基本上就没有什么问题了。
接收数据
订阅是从collect函数开始。collect函数是一个挂起函数,当订阅者取不到数据的时候就会把collect函数挂起。简而言之collect函数永远不会结束,除非把collect所在的协成取消。当让也有例外,可以通过操作符take or takeWhile 让 collect函数在执行完预期后自动结束,这个结束的原理就是抛出一个协成的取消异常。
collect
override suspend fun collect(collector: FlowCollector<T>): Nothing {
//为订阅者分配一个Slot对象,allocateSlot函数定义在父类AbstractSharedFlow中
val slot = allocateSlot()
try {
//这种情况对我们开发者来说不会发生,因为SubscribedFlowCollector是Internal类型,开发者使用不到
if (collector is SubscribedFlowCollector) collector.onSubscription()
//拿到协成的Job对象。
val collectorJob = currentCoroutineContext()[Job]
//开启一个死循环,这就是为什么collect函数不会结束的原因,
while (true) {
var newValue: Any?
while (true) {
// 调用tryTakevValue尝试从buffer中取一个数据,
newValue = tryTakeValue(slot)
//如果取出来有值(不是NO_VALUE)就把值交给collector。
//NO_VALUE说明没有值,没有值有两种情况:
//第一种是已经把最后一个数据取完了,后面没有数据了
//第二周是取到的是一个被取消的emit,一个挂起的Emitter被移除后会存入一个NO_VALUE
if (newValue !== NO_VALUE) break //如果有值就跳出第一个while,把数据交给collector
//如果是NO_VALUE,调用awaitValue函数把collect挂起,但是在awaitValue函数里面
//会去判断,只有是第一种NO_VALUE才会真正挂起,如果是第二种不会挂起。又回到whil循环里面继续
//取下一个数据,相当于跳过被移除的Emitter,继续下一个
awaitValue(slot)
}
//确保协成是活着的(意思就是协成还没有被取消),如果已经取消了就会抛出取消异常,
//这个取消异常如果外部协成里面不对collect函数进行try catch 的话是看不到的。
//这里为什么要加一个这个呢?是因为协成的取消就和调用线程的interrupt一样,如果不对其做出回应
//就没法取消,协成和线程的取消都只是一个标识,并不能真正让协成取消,真正让协成取消的是收到取消
//后得做出回应。
//比如一个订阅者每取到一个数据处理时间需要1秒钟,在订阅者处理数据时,调用协成的cancel把订阅者
//所在的协成取消了,如果不对cancel做出任何回应,订阅者仍然会继续执行while循环继续取数据。
collectorJob?.ensureActive()
//取的值不是NO_VALUE就会把取到值交给collector取处理数据。
collector.emit(newValue as T)
}
} finally {
/**
* finally 会在两种情况下执行:
* 第一种: 协成被取消了,上面try里面collectorJob?.ensureActive()抛出协成取消异常,try里面抛出
* 异常,跳出whilex循环,执行finally,然后collect抛出异常结束。
*
* 第二种:try里面awaitValue(slot) 把协成挂起了,在协成被挂起的的时候调用协成的取消也会导致
* collec函数抛出协成取消异常。这种情况内部原理比较复杂一点,在collect函数中会创建一个
* 协成对象,为了好称呼,我们暂且把他叫做C2。把调用collect的协成叫做C1。C2里面包含了C1。
* 调用awaitValue时,又会创建一个协成CancellableContinuationImpl,把它叫做C3。C3包含了
* C2。 当我们通过C1的job的cancel函数把C1取消的时候,C3会收到回调,在C3中会调用C2的resumeWith
* 函数,传入一个取消异常给C2。C2的resumeWith函数里面会调用C2的invokeSuspend函数,并把取消
* 异常传入进去(C2的invokeSuspend里面的代码就是collect函数里面的代码),C2的invokeSuspend
* 接收到一个异常后就会执行finally里面的逻辑。当C2的invokeSuspend执行完成后,会把异常通过
* C1的resumeWiht函数把异常传给C1。因此如果我们在调用collect的时候加一个try catch的话就能
* 捕获到该取消异常。
*
* 也就是说这两种情况都会导致collect函数抛出异常终止,finally被执行
*
* freeSlot函数被定在父类中,里面做的事情就是释放Slot对象,让Slot变成可复用。
*/
freeSlot(slot)
}
}
protected fun freeSlot(slot: S) {
// Release slot under lock
var subscriptionCount: SubscriptionCountStateFlow? = null
val resumes = synchronized(this) {
nCollectors-- //有订阅者取消了,让订阅者数量减一
subscriptionCount = _subscriptionCount
//如果订阅者数量为0了,把nextIndex = 0,让以后为新来的订阅者分配Slot对象时,从slots中第0个开始找
//其实也就是把nextIndex恢复了没有订阅者时的默认值。
if (nCollectors == 0) nextIndex = 0
//订阅者被取消后,调用freeLocked把Slot对象变成可复用的,把其index和con恢复成默认值。
//当一个订阅者被取消后,如果这个订阅者是目前已存的唯一一个订阅自,或者是执行最慢的订阅者。
//那么该订阅者被取消后,buffer中已缓存的某些数据就就可能失效了,就会被移除,所以在
//freeLocked中还会调用其他函数去对buffer中的数据做处理。具体是哪些数据呢?
// index范围在[head ~ minOf(minCollectIndex,replayIndex)的数据都需要被移除,因为已经
//没有存在的必要了。
(slot as AbstractSharedFlowSlot<Any>).freeLocked(this)
}
//freeLocked中会调用其他函数去对buffer做处理,如果是执行最慢的订阅者或者唯一一个订阅者被移除时,
//那就很有可能移除buffer中某些失效的数据,移除数据了,buffer腾出空间了,如果有挂起的Emitter,那就会
//把Emitter移除,把Emitter中的数据放入buffer中,把Emitter对应的协成返回出来,然后统一唤醒。
for (cont in resumes) cont?.resume(Unit)
// 通知外部,订阅者数量发生了改变。
subscriptionCount?.increment(-1)
}
//SharedFlowSlot.freeLocked
override fun freeLocked(flow: SharedFlowImpl<*>): Array<Continuation<Unit>?> {
assert { index >= 0 }
val oldIndex = index
//把inde 和 cont恢复成默认值
index = -1L
cont = null
//updateCollectorIndexLocked就上面说的,要对buffer进行处理,可能会移除buffer中某些数据,
//可能会唤醒挂起的Emitter。该函数会在后面详细讲解。
return flow.updateCollectorIndexLocked(oldIndex)
}
整个collect函数里面的代码不复杂,反而涉及到协成相关的知识比较多,比如协成的取消原理这一块。kotlin里面最难的也就是协成了,只有理解协成的工作原理才能算是真正学会了kotlin这么语言。如果对协成原理不是很了解的建议好好学学习。
–>allocateSlot
该函数为新来的订阅者分配一个Slot对象,如果有现成的直接复用,没有的话创建一个新的,分配好Slot对象后,需要把订阅者和这个Slot对象绑定在一起,啥意思呢?就是为Slot对象的index属性赋值,index代表了新订阅者将要从buffer中取数据的位置。
在同一时刻一个订阅者只能对应一个Slot对象,订阅者每取完一个数据后其index属性会加一,指向下一个要取的数据位置。当订阅者需要挂起的时候就把协成存入Slot的cont属性。
订阅者所在协成取消后,就把订阅者和Slot对象解绑,解绑就是把index = -1,cont = null。让这个Slot对象将来可以被复用。
protected fun allocateSlot(): S {
var subscriptionCount: SubscriptionCountStateFlow? = null
val slot = synchronized(this) {
val slots = when (val curSlots = slots) {
//第一次创建一个长度为2的数组
null -> createSlotArray(2).also { slots = it }
//如果slot中已经存满了有效的Slot对象(已经被释放掉的Slot不算),那就扩容2倍
else -> if (nCollectors >= curSlots.size) {
curSlots.copyOf(2 * curSlots.size).also { slots = it }
} else {
curSlots
}
}
//nextIndex用来记录新的订阅者来了后,应该在slots中从什么位置开始找可复用的Slot对象。
//nextIndex 的值增长到大于slots.size后,又回重置为0。使其能够循环查找。
var index = nextIndex
var slot: S
while (true) {
//先看看index位置是否有Slot对象,有的话取出来复用,没有的话创建一个Slot放入该位置
slot = slots[index] ?: createSlot().also { slots[index] = it }
index++
//index超出了数组的边界,把index指向数组第第一个,循环起来
if (index >= slots.size) index = 0
/**
*
* allocateLocked函数中会去判断这个slot是否为一个未被其他订阅者正在使用的Slot对象,
* 如果slot是新创建的,那肯定是未被使用的,如果是从slot数组中取出来的,那取出的这个slot
* 很有可能正在被某个订阅自使用,判断一个slot对象是否处于被订阅者使用中,就看slot的index是否
* 大于0。新创建的Slot或者被不在被使用已经释放的Slot对象其index = -1。
*
* 在allocateLocked函数中如果这个Slot对象正处于被别的订阅者正在使用就会返回false。返回false后
* while循环就会继续从slots数组找一下个,最终要么找到一个被释放的Slot对象(可复用),
* 要么找遍了都没找到一个可复用的,那就创建一个新的,并把创建的新的Slot对象放入slots数组中。
*
*
* allocateLocked返回true,说明这个slot是一个新创建的或者是一个可复用的,那就为其index 设置
* 一个值,把replayIndex赋值给slot.index。新订阅者从replayIndex指向的数据开始取。
*/
if ((slot as AbstractSharedFlowSlot<Any>).allocateLocked(this)) break
}
nextIndex = index
nCollectors++ //nCollectors记录了订阅者的数量
subscriptionCount = _subscriptionCount
}
// subscriptionCount是一个StateFlow。用来提供给外界观察订阅者的数量用的。新增订阅者或者减少订阅者
// 外界都可以通过对subscriptionCount进行订阅来获取。
subscriptionCount?.increment(1)
return slot //把分配的slot对方返回出去
}
//创建一个长度为size的slot数组
override fun createSlotArray(size: Int): Array<SharedFlowSlot?> = arrayOfNulls(size)
//创建一个Slot对象,直接new 的一个实例对象
override fun createSlot() = SharedFlowSlot()
//Slot类完整源码
internal class SharedFlowSlot : AbstractSharedFlowSlot<SharedFlowImpl<*>>() {
// 用来记录订阅者要取的数据在buffer中的位置,
// 初始值为-1 说明这个Slot对象还没有和订阅者绑定,订阅者被取消后,释放Slot对象
//时也会把index 设置成 -1。
@JvmField
var index = -1L
//当一个订阅者需要挂起等待数据的的时候,把协成对象存入该属性,方便后期唤醒协成
@JvmField
var cont: Continuation<Unit>? = null
//订阅者和Slot绑定的时候,给index 设置值,只有新创建的或者可复用的Slot才能给其index设置值。
override fun allocateLocked(flow: SharedFlowImpl<*>): Boolean {
//index >=0 说明该Slot对象正在被别的订阅者使用,返回false。表示失败,
//告知调用者,该Slot对象不可用,需要重新找一个可复用的或者创建一个新的
if (index >= 0) return false // not free
// updateNewCollectorIndexLocked返回replayIndex值
index = flow.updateNewCollectorIndexLocked()
return true
}
//解绑订阅者和Slot
override fun freeLocked(flow: SharedFlowImpl<*>): Array<Continuation<Unit>?> {
assert { index >= 0 }
val oldIndex = index
index = -1L //恢复成默认值,表示该Slot是一个可被复用的
cont = null
/**
* 当一个订阅者所在协成被取消后,对buffer可能造成很大的改动。
* updateCollectorIndexLocked函数里面比较复杂,可以说是SharedFlow里面
* 最难理解一个函数了,在后面详细讲解。这里简单举一个例子:
* 比如buffer情况如下:replay = 3,extBufferCapaciyt = 3
* 【nul,b,c,d,e,f】
* replayIndex 目前指向数据d。被取消的这个订阅者的Slot的index 指向了数据b。并且被取消的这个订阅者
* 是最慢的订阅者,或者是唯一的一个订阅者。buffer中的b和c 就变成无效数据了,即使新订阅者来了也取不到它两
* 因此在updateCollectorIndexLocked函数中会把b和c删除,然后更新minCollectorIndex起其他size属性。
*/
return flow.updateCollectorIndexLocked(oldIndex)
}
}
//SharedFlowImpl.updateNewCollectorIndexLocked
internal fun updateNewCollectorIndexLocked(): Long {
val index = replayIndex
//replayIndex < minCollectorIndex。说明新来的订阅者成为了最慢的订阅者,
//因此让minCollectorIndex指向这个最慢的订阅将要取数据的位置。
if (index < minCollectorIndex) minCollectorIndex = index
return index //把replayIndex返回出去给Slot.index赋值
}
–>tryTakeValue
尝试从buffer中取数据,能取到就返回正确的数据,取不到就返回NO_VALUE
private fun tryTakeValue(slot: SharedFlowSlot): Any? {
//创建一个空数组,在需要的时候用来装可被唤醒的Emitter里面的协成对象,
//因为一般来所,从buffer中取出一个数据后,如果这个数据已经被所有订阅者都消费了(无效了)
//并且这个数据也不再回放数据范围内,因此这个数据就会被移除,移除后buffer就有空间了,如果这时候
//存在挂起的Emitter,就会把Emitter移除,把Emitter中的数据放入buffer中,把Emitter中的协成放入
//resumes这个数组中,然后统一唤醒这些协成。
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
val value = synchronized(this) {
//tryPeekLocked在前面”发送数据“已经讲过,意思就计算一下slot.index(将要取数据的在buffer中的位置)
//是否能取到数据,如果能取到就返回slot.index,后续就去取slot.index指向的数据,如果取不到,就返回-1。
val index = tryPeekLocked(slot)
if (index < 0) { //小于0 说明取不到,
NO_VALUE //返回NO_VALUE
} else {
val oldIndex = slot.index //能取到,那就取index指向buffer中的数据。
//getPeekedValueLockedAt函数比较简就是取出buffer中index指向位置的数据
val newValue = getPeekedValueLockedAt(index)
//slot.index加一,指向该订阅者下一次将从buffer中取数据的位置
slot.index = index + 1 //
//取出一个数据后,有可能被取出的这个数据就会成为无效数据,意思就是可以被删除了。
//buffer中数据被删除后,腾出空间了,如果有挂起的Emitter就需要把Emitter中的数据放入buffer中。
//因此就会涉及到replayIndex的改动。
//如果是作为最慢的订阅者取完数据后,还需要更新minCollectorIndex的值,
//updateCollectorIndexLocked里面就是做这些事情。
resumes = updateCollectorIndexLocked(oldIndex)
newValue
}
}
//如果有能被唤醒的emit(发送数据时被挂起的协成),那就挨个唤醒。
for (resume in resumes) resume?.resume(Unit)
return value //把取到的数据返回出去
}
private fun getPeekedValueLockedAt(index: Long): Any? =
//取出index指向的数据
when (val item = buffer!!.getBufferAt(index)) {
is Emitter -> item.value //如果数据是一个Emitter类型,就返回Emitter里面的数据
else -> item //如果不是Emitter,那就是我们想要的数据类型,直接返回。
}
—> updateCollectorIndexLocked
在该函数中,是用的collector代替订阅自的称呼,是因为我在看SharedFlow源码的时候,第一个看的函数就是该函数,根据该函数连的代码逻辑去一步一步反推其他的逻辑,先把该函数中的源码注释写完了后才决定写这一篇文章的。
/**
* 这个函数只有两个地方会被调用:
* (1)订阅者从Buffer获取到数据之后,还未交给FlowCollertor之前,oldInext = 被取到的那个数据在Buffer中的[index]
* (2)在一个订阅者被取消后。SharedFlow没有提供让订阅者取消订阅的函数,一个订阅者想要取消只能通过把它所在的
* 协程取消。
*
* 该函数内部涉及到的逻辑极其复杂,简单的来说就是当一个collector取到数据后,或者collector被取消后
* 需要去更新Buffer,因为collector从Buffer中取到数据后,这个数据有可能就不需要继续留在Buffer中了(比如
* 该数据已经被所有collector都消费了,并且该数据也不在replay范围内了)。再或者当最慢的colelctor被取消后
* 在Buffer中某些数据(最慢的collector还未消费,其他colelctor已经消费)并且这些数据有可能是部分也有可能是
* 全部已经不在replay范围了,是不是也需要把这些数据清除。
* 数据被清除了,腾出了空间,如果这时候有挂起的emittter,就可以用腾出的空间来放挂起Emitter发送的数据。
* 不管是清除数据,还是放入新的数据,对Buffer来说都涉及到了数据的进出,那么replayIndex,minCollectorIndex,
* bufferSize,queueSize是不是都有可能发生变化了,所以就需要更新这些index。
*
* 对于学习该函数的的一些建议:最好在idea中对照源码,写一些满足情况的案例,一边调试一边分析。否则会看的
* 云里雾里的
*/
internal fun updateCollectorIndexLocked(oldIndex: Long): Array<Continuation<Unit>?> {
/**
* minCollectorIndex 代表了执行最慢的订阅者将要从Buffer中取数据的index(注意这里还未取,是将要取,)。
* 所以对于执行最慢的订阅者进入该函数oldIndex = minCollectorIndex。对于执行快的订阅者
* oldIndex > minCollectorIndex。
*
* 比如说:
* step1 : SharedFlow的replay = 4,在发送数据之前,先给他整两个订阅者 c1 和 c2
* 这时候 minCollectorIndex = 0,假设c1处理数据比c2慢。
*
* step2: emit(1)发送第一个数据,这时候会把数据放入Buffer中【1】,然后依次唤醒c1,c2
* 至于c1 和 c2 所在的协程谁先真正开始执行(取决于cpu线程调度),都无所谓。
* 紧接着又连续发了3条数据,Buffer为【1,,2,,3,,4】
*
* step3: 假如c1先取数据,c1取到数据"1"后,进入该函数,oldIndex = 0,minCollectorIndex = 0;
* 这时候,c2还未开始取就成了慢的的那一个,c2将要去的数据是Buffer中index = 0 ,即c2.slot.index = 0
* 因此c1在该函数中更新 minCollectorIndex = c2.slot.index,
* 即c1执行完该函数后 minCollectorIndex = 0 。
* c1取到数据后,开始处理数据,由于c1处理数据非常的慢....
*
*step4 : c2开始取数据,取到数据"1"后进入该函数,oldIndex =0 ,minCollectorIndex = 0,这时候
* c1 和 c2下一次将要取的数据都是index = 1。因此c2在该函数中更新 minCollectorIndex = 1.
*
*step5 : c2继续下一次取数据,取到数据"2"后进入该函数,oldIndex =1 ,minCollectorIndex = 1,这时候
* c1还在处理它第一取到的数据,因此c1成了慢的那一个了。因此c2在该函数中更新
* minCollectorIndex为c1将要取的数据的index(也就是1),最终minCollectorIndex = 1。
* c2继续以比C1速度快的方式取数据,c2每次进来时oldIndex 都是大于 minCollectorIndex
*
*step6: c1终于处理完数据,开始取下一个数据"2",取完后进入该函数,oldIndex =1, minCollectorIndex = 1。
* 由于c1处理数据比c2慢,在该函数去更新minCollectorIndex的时候,依然以c1为准,为c1下一次
* 将要取的数据的index。所以c1执行完该函数后,minCollectorIndex = 2.
*
*
* 因此assert在这里就是为了确保逻辑是按照预期的执行,出现oldIndex < minCollectorIndex
* 说明代码不是按照设定的逻辑在执行,抛出异常。
*/
assert { oldIndex >= minCollectorIndex }
//oldIndex > minCollectorIndex 说明是执行较快的订阅者,因此不需要去最什么,比如唤醒等待的发送者(Emitter)
//和更新Buffer(包括各种index),更新Buffer需要根据最慢的那个colletor执行的情况,
//更新Buffer由最慢的collector来做。
//俗话说,先吃完不管,后吃完洗碗,就是这个道理,执行的快的到这里直接返回一个empty list
if (oldIndex > minCollectorIndex) return EMPTY_RESUMES
//能走到这里,说明是执行最慢的那个订阅者。(oldIndex = minCollectorIndex),所以一下的代码都是针对
//最慢的collector来讲的,不管是因为取到数据后进入该函数,还是协成取消进入到该函数。
val head = head //head 为 min(minCollectorIndex,replayIndex)
/**
* ok。现在开始做第一件事情就是重新计算minCollectorInedex的新值。也就是说最慢的这个collector取完数据后,
* minCollectorIndex应该指向buffer中那个数据(目前minCollectorIndex指向刚取到这个数据)。
*
* 计算这个minCollectorInex新值的规则就是,最慢的这个订阅者下一个要取的数据的index。
* 虽然代码执行到此处的collector是正在取数据中的最慢的collector(如果不是上面return出去了),
* 但是这并不妨碍collector在它取本次数据之前(调用tryTakeValue之前)有新的collector加入进来(还未开始取数据),
* 如果有那么新的collector有可能会成为最慢的collector。为什么是有可能呢?因为新的collector
* 取的第一个数据是replayIndex。所以如果本次colletor取到数据的index(oldIndex) >= replayIndex。那么新的这个
* collector就变成最慢的collector了。
*
* 如果没有新的collector加入进来,在执行此处的
* 代码的collector 就是最慢的。所以最简单的办法就是去所有collector中找,谁最慢,minCollectorInedex
* 的新值就是这个collector对应的slot.index(代表了将要取数据的index)。
* 遍历collector的集合,找出最慢的那一个,就相当于给你一个Int的数组,让你找出里面最小的值。
* 这就是一个最简单的查找算法。这里采用的简单的遍历查找。
*
* 先整个临时变量newMinCollectorIndex 代表minCollectorIndex的新值,给这个变量的初值
* 为head + bufferSize。head + bufferSize 代表了Buffer中最后一个数据的index + 1。 就算
* 执行最快的collector,他的slot.index 也最多是等于head + bufferSize。从而也就变相说明collector
* 所在集合中,执行最快的哪一个collector的slot.index也最多和 head + bufferSize 相等,不可能大于。
* 所以一开始就把newMinCollectorIndex就赋值了一个在collector集合中可能存在的最大值,这样遍历的时候
* 就能确保找出执行最慢的那一个。
*
* 把newMinCollectorInde赋值为head + bufferSize除了上面所说的作用以外,还有一个作用就是
* 在flow的 bufferCapacity = 0 的时候,这时候buffersize 永远为0。
* 那么就相当于 newMinCollectorInde = head =min(minCollectorInex,replayIndex).
* 对于这种情况 minCollectorInex == replayIndex,所以也就相当于让新值的默认值为原来的旧值,
* 即newMinCollectorIndex = minCollectorInex。而 minCollectorInex 又等于 oldIndex。
* 又可以推断出 newMinCollectorIndex == oldIndex,这样的好处就是在后面直接对
* newMinCollectorIndex加一就可以。
*
* 还有一个作用就是该函数是在collector被取消时调用的,代码能走到这里来,说明被取消的这个collector
* 肯定是最慢的这一个。至于还有有么有其他的collector这个不一定要,如果没有其他它的了,那这个被取消
* 的colelctor就是唯一的一个collector。
* 如果被取消的这个collector是目前已存的唯一个collector,唯一个的一个就被取消了,
,就相当于回到没有collector的状态,没有collector时,
* minCollectorIndex值默认为最大值也就是 head + bufferSize。所以
* 把newMinCollectorInde = head + bufferSize 就相当于把minCollectorIndex更新到没有collector
* 时的默状态。
* 如果被取消的的colector并不是唯一的collector,还有其他collector存在,但是肯定是最慢的这个,
* 最慢的被取消了,把newMinCollectorInde = head + bufferSize设置为这样坑定是不对,这个会在后面修正。
*
* 为什么在flow没有collector时minCollectorIndex的默认值为head + bufferSize呢?这样可以变相认为Buffer中
* minCollectorIndex之前的所有的数据都有可能可以被清除在需要的时候(buffer满了用来放新数据)。
* 把newMinCollectorIndex恢复到最大值,在该函数中后面updateBuffer的时候就可以清除
* min(replayIndex,newMinCollectorIndex)之前的所有数据,把这些即使是新的collector来了也不会消费数据
* 从Buffer中清除。
*
* 综上所述:
* (1)如果 bufferCapacity > 0时,newMinCollectorIndex的初值为 Buffer中被
* 缓存最后一个数据的index +1。
* (2)如果bufferCapacity = 0时,newMinCollectorIndex的初值为 oldIndex,代表了
* 最慢的collector正在处理的这个数据的index。
* (3)对与collector被取消时,newMinCollectorIndex的初值在 bufferCapacity > 0时
* 为Buffer中被缓存最后一个数据的index +1,在bufferCapacity = 0时为head,代表了所有挂起的
* emitter中的第一个emitter。
*
* 说的有点复杂了,如果对flow不是特别熟悉的朋友,可能真想不明白为什么要给newMinCollectorIndex赋这样
* 一个初值。
* 对于初学者来说,想不明白就先不管,只需要记住最终是为了让最慢的collector取到数据后或者被取消后,计算出
* 正确的新的 minCollectorIndex。
*/
var newMinCollectorIndex = head + bufferSize
/**
* 考虑同步共享流(sync shared flow )的特殊情况。何为同步?意思就是
* 不能缓存发送的数据,不支持回放(replay),但是 onBufferOverflow = Suspend。
* 意思就是bufferCapacity = 0,这种流在有collector的时候,每次发送数据都只能把发送协程挂起,即
* 这种就叫同步共享流。
*
* if 里面的意思就是,如果是一个同步共享流,并且至少一个emitter(发送的协程)被挂起了。
* 满足情况就给 newMinCollectorIndex 加一。为什要加一呢?在上一步中 bufferCapacity = 0时
* newMinCollectorIndex的初值为oldIndex,加一就正好,加一过后的值刚好就是当前collector(最慢)
* 下一次需要取数据的index。
*
*/
if (bufferCapacity == 0 && queueSize > 0) newMinCollectorIndex++
/**
*
* 针对 bufferCapacity > 0 的情况,newMinCollectorIndex的初值显然不能作为最终
* minCollectorIndex的新值,需要遍历collector的集合,找到执行最慢的那一个collector.
*
* 针对bufferCapacity == 0 && queueSize > 0的情况,newMinCollectorIndex的值为
* 当前collector下一次要取数据的index。正常情况下newMinCollectorIndex的值就是minCollectorIndex
* 新值,前面不是也说了,有可能在再本次collector取数据前有新的collector进来了,
* 所以newMinCollectorIndex的值也是不正确的。也需要遍历collector的集合,如果没有新的collector
* 加入进来,newMinCollectorIndex不会做出修改。如果有新的collector加入进来
* newMinCollectorIndex的值为新的collector的 slot.index。
*
* 所以下面这个遍历就是对newMinCollectorIndex的一个修正。找出最慢的这个collector,
* 使newMinCollectorIndex的值等于最慢的collector下一次要取的数据的index。
*/
forEachSlotLocked { slot ->
@Suppress("ConvertTwoComparisonsToRangeCheck") // Bug in JS backend
if (slot.index >= 0 && slot.index < newMinCollectorIndex) newMinCollectorIndex = slot.index
}
//执行到这里,minCollectorInedex的新值newMinCollectorIndex就确定了。
//确保minCollectorIndex是正向递增的。
//这个和android中的recyecleView很像,用有限的item可以展示个数据,重复利用item。
//当我们滑动item展示更多数据的时候,postion是正向增长,并不会因为item的复用导致position的值在一个
//范围类循环。
//在sharedFlow中也是重复利用Buffer的每一个空间,minCollectorIndex,replayIndex的值都是随着
//不断发送数据不断递增的。
assert { newMinCollectorIndex >= minCollectorIndex } // can only grow
/**
* 如果 newMinCollectorIndex < minCollectorIndex 上面assert就抛异常了。
* 因此 newMinCollectorIndex最次就等于 minCollectorIndex。
* 什么时候newMinCollectorIndex会等于minCollectorIndex呢?
*
* 我举例说明一下,假如一个buffer中有4个数据,该flow的reply = 4。extBufferCapacity = 2.
* 在发送数据之前先开两个子协成整两个订阅者(collector),暂且称之为C1 和 C2.
这时候C1和C2对应的Slot对象的index都等于replayIndex = 0。
* 连续发送6个数据,这6个数据都会存入buffer中,relayIndex最终指向了数据c
*
* 0 1 2 3 4 5 ----> index
* +---------+---------+---------+---------+---------+---------+
* | a | b | c | d | e | f |
* +---------+---------+---------+---------+---------+---------+
* ^ ^
* minCollectorIndex replyIndex
*
*
* 加入C1先调用tryTakeValue函数,于是C1进入到该函数,C1已经取到了数据a。假如没有C2,C1在该函数中
* 计算出来newMinCollectorIndex = 1,在该函数后面会把数据a移除。但是现在有了C2的存在,并且C2还没开始
* 取数据a,C1在该函数中计算出来的newMinCollectorIndex 仍然等于0。此时minCollectorIndex仍然等于0,
* 指向了数据a。所以就出现了newMinCollectorIndex == minCollectorIndex的情况。
*
* 对于这种情况,C1就不要再做任何处理了,直接返回出去。
* 其实还是那句话,执行较快的collector取完数据后不需要对buffer做任何处理,
*
*/
if (newMinCollectorIndex <= minCollectorIndex) return EMPTY_RESUMES
/**
*
* 经过前面的一顿计算,确定了newMinCollectorIndex的值,代码执行到这里,同时也确定了本次collector
* 就是最慢的那一个。那接下来应该做点什么呢?
*
*
* 先回顾一下该函数只有两个地方会被调用,第一个就是collector从Buffer中拿到数据后(还未处理之前)。
* 第二个就是一个collector所在协程被取消后。
*
* 如果是第一种情况:collector从buffer中获取收据后,而且还是作为最慢的那一个collector,应该做点什么呢?
* 想象一下,如果collector取出的这一次数据的index < replayIndex。那个这个数据就不用再继续留在buffer中了,
* 因为即使是新来的collector也取不到这个数据,新来的取数据都是从replayIndex开始取。本来本次的collector
* 就是最慢的这个collecotor了,也没有别的collector来消费这个数据了,因此需要把这个数据删除。
* 既然删除了数据,buffer就腾出空间了,如果之前有挂起的emitter,那是不是也应该把emitter的数据放到buffer中来,
* 在把emitter对应的协程唤醒。
*
* 如果是第二种情况:即collector被取消了调用进来的,只有被取消的是最慢的那个collector才有机会执行到这里来 ,
* 不然在前面就已经被return 了。为什么不是最慢的那一个collector被取消后在前面要被返回,
* 因为执行的快的被取消后,它也不能去动
* 它前面的数据,因为还有慢的collector还需要消费。因此在一开始被返回出去。
*
* 对于最慢的这个collector被取消后,那倒数第二慢的那个collector就替代它成为最慢的那一个
* (假入有多个Collector的情况)。那么是不是意味着倒数第二慢的collector前面已经消费过的数据是不是也有可能
* 没啥用了需要被移除,同样移除了数据就是腾出了空间,是不是也要看看有没有挂起的emitter.
*
*
* 总结下来就是:不管是那一种情况调用的该函数,在接下来要做的事情:
* (1)清除newMinCollectorIndex之前的数据,但是不一定是全部清楚,能清楚的范围的index为:
* head ~ min(newMinCollectorIndex,newReplayIndex)。
* 想想也对,你不能把replayindex之后的数据给清除了,不然新的collector怎么回放之前的数据。
* (2)计算出需要唤醒的emitter对应的协程,返回出去统一唤醒。把这些即将要被唤醒的emitter发送的数据
* 转移到Buffer中存起来。
*
* (3)Buffer发了变化,就需要重新更新Buffer相关的各种index和size 属性。
*/
//假设 newBufferEndIndex 等于原来的 bufferEndIndex
var newBufferEndIndex = bufferEndIndex
//计算最多可以唤醒多少个挂起emitter.(当然如果没有挂起的emmitter时 maxResumeCount = 0)
val maxResumeCount = if (nCollectors > 0) {
/**
* (1)newBufferEndIndex - newMinCollectorIndex 得出的数量就是Buffer有效的数据,这些数据
* 对于最慢的collector来说是还没有消费的。这些数据也是不能被清除的。
* (2)bufferCapacity - newBufferSize0 用Buffer总的可缓存数据的容量减去不能被清除的数据个数
* 就得出可以有多少个可用空间可以容纳唤醒后的emitter的数据。
* (3)在可用空间数量和挂起的emiter数量取最小值。就是最大可唤醒的emitter数量。
*
* 举个例子:比如有一个数组,这个数组的容量为5,你不用管数组中装满了没有,你只需要知道数组里面有多少个数据
* 是不能移除的就行。不能被移除的数据个数最少是0,最多是5。所以用总的容量减去不能被移除的数量的结果
* 最多是5,最少是0。如果还不够形象,假入你有一个衣柜,衣柜容量是可以装10件衣服,现在里面有3件是新的,
* 是不能扔的。这个三件衣服新衣服你是知道的,至于还有没有其他已经穿过的,可以扔的。你不用具体知道。
* 这时候你妈给你说儿子我要给你买新衣服了,你衣柜能装多少,你掐指一算,最多还能容纳7件新衣服。
* 也就是说你衣柜里面最多可以还能放7件新衣服进来。不管原来衣柜里面具体有多少件(至少是3件)。
* 大不了就把其他的扔了用来放新衣服,只留三件不能扔的。所以最终能放进来的新衣服数量取决于买的新衣服的数量
* 和“7”谁最小。如果买了10件新衣服也只能放进来7件,如果你买了5件新衣服那就全部能放进来
*/
val newBufferSize0 = (newBufferEndIndex - newMinCollectorIndex).toInt()
minOf(queueSize, bufferCapacity - newBufferSize0)
} else {
/**
* 如果flow中此时没有collector了,比如原来的都被取消了(包括本次collector)。
* flow针对没有collector的处理逻辑
* 就是让挂起的emitter全部唤醒,这就跟flow发送数据时,在没有collector时发送数据如果replay = 0
* 就全部丢掉,如果replay > 0 就放入Buffer中是一样的。总的来说就是在没哟collector时是不会让发送方
* 协程挂起的。
*
*/
queueSize
}
//先定义一个empty arry.
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
/**
*
* newBufferEndIndex = (head + bufferSize) 代表了Buufer中最后一个缓存的数据的index + 1。
* 同样也代表了第一个挂起的emitter的index。
*
* queueSize 是挂起emitter的总数。
*
* 因此: newQueueEndIndex 代表了挂起的最后一个emitter所在数组中的index + 1。
*/
val newQueueEndIndex = newBufferEndIndex + queueSize
// maxResumeCount 大于0 说明有maxResumeCount个emitter可以唤醒,把其对应的数据放入Buffer中。
if (maxResumeCount > 0) {
//创建一个容量为maxResumeCount的 array 赋值给 resumes
resumes = arrayOfNulls(maxResumeCount)
var resumeCount = 0 //计数器,
val buffer = buffer!! // buffer里面存了emmiter。
/**
* 从第一个挂起的emitter到最后一个挂起的emmiter进行遍历。为什么要遍历所有emitter呢?
* 而不是从第一个开始,到maxResumeCount结束?因为可能中间某些emitter所在协程被取消了。
* 比如现在有[emiiter1,emitter2,emitter3,emitter4]这么多个emitter在挂起。
* 如果emitter3被取消,将会变成[emiiter1,emitter2,NO_VALUE,emitter4]。只是把Array中
* emitter3所在的位置存了一个NO_VALUE。newQueueEndIndex和queueSize是不会变的。所以
* 遍历的的结束位置只能是newQueueEndIndex。
*/
for (curEmitterIndex in newBufferEndIndex until newQueueEndIndex) {
val emitter = buffer.getBufferAt(curEmitterIndex)
//判断取出的是不是NO_VALUE,是意味着这个位置原来的emiter被取消了。
//注意这里会导致同步流的一个bug(在后面会专门讲)
if (emitter !== NO_VALUE) {
emitter as Emitter
//把取出的emitter对应协程存放在resume这个Array中。
resumes[resumeCount++] = emitter.cont
//把取出这个emitter对应的位置存入NO_VALUE。相当于把emitter移除了。
buffer.setBufferAt(curEmitterIndex, NO_VALUE)
//取出的这个emiiter即将要被唤醒,那么就把emitter里面数据存入Buffer中。
//存入的位置就是原来Buffer中原有数中最后一个数据的后面。
//(curEmitterIndex >= newBufferEndIndex)
buffer.setBufferAt(newBufferEndIndex, emitter.value)
newBufferEndIndex++ //加一,下一个取出的emitter对应的数据存入的位置。
//当取出的数量等于curEmitterIndex的时候就可以不用再取了,在继续取Buffer中放不下了。
if (resumeCount >= maxResumeCount) break
}
}
}
//Buffer中现在(当前)实际存储的有效数据个数。
val newBufferSize1 = (newBufferEndIndex - head).toInt()
/**
* 针对没有collector的情况(最后一个colelctor被取消调用进来),会把所有挂起的emitter都唤醒,
* 那就会存在Buffer的容量不够装下所有emitter。
* 举个例子,bufferCapacity = 4,挂起的emitter数量为10,所以最终只有只有emitter7,emitter8,emitter9,
* emitter10,这四个数据会被存入Buffer中,Buffer里面原来的数据都被顶替了,那上面计算的newMinCollectorIndex
* 就无效了。
* 就算Buffer中剩余的空间能装下所有emitter的数据,上面计算的newMinCollectorIndex的值也无效了,
* newMinCollectorIndex 在nCollectors = 0 时在上面被计算为 head + bufferSize。唤醒emitter,把
* 其数据放入buffer中后,buffersize发生改变了,因此newMinCollectorIndex就无效了。
*
* 针对这种newMinCollectorIndex之前计算的结果会实现的情况,最简单的办法,就是让newMinCollectorIndex
* 指向newBufferEndIndex。
*/
if (nCollectors == 0) newMinCollectorIndex = newBufferEndIndex
/**
* Buffer中放入了被唤醒emitter的数据后,重新计算replayIndex。
*
* step1 : 先计算Buffer中可用于回放的数据的个数,期望的值是replay个,光期望是不够的,还得看buffer中
* 有没有这多个,所以在期望的个数和实际个数两个之间取最小的。比如我期望10个,实际只有4个,那最
* 终是不是只能回放4个,因此minOf(replay, newBufferSize1)
* step2:在step1中计算出了可回放的个数。用newBufferEndIndex减去可回放的个数,就能算出新的replayIndex。
* 就算没有挂起的eimtter,Buffer中的没有增加新的数据,新的replayIndex 就和原来的replayeIndex相等
* ,不可能存在新的replayIndex小于原来的replayIndex。只能是大于等于。
* stpe3: 在新的replayIndex和原来的replayIndex中取最大的那一个。replayIndex只能是递增,不可能变小。
*/
var newReplayIndex = maxOf(replayIndex, newBufferEndIndex - minOf(replay, newBufferSize1))
/**
* 针对 同步流的情况,如果发现newReplayIndex的位置是一个NO_VALUE,说明这个位置
* 原来的Emitter因为协成取消被移除了,让newReplayIndex 和 newBufferEndIndex加一
* 就相当于是跳过这个位置。
*/
if (bufferCapacity == 0 && newReplayIndex < newQueueEndIndex && buffer!!.getBufferAt(newReplayIndex) == NO_VALUE) {
newBufferEndIndex++
newReplayIndex++
}
/**
* 经过前面的继续,Buffer可能发生了改变。各种index也发生了改变。需要更新buffer。该函数在前面已经讲过
*/
updateBufferLocked(newReplayIndex, newMinCollectorIndex, newBufferEndIndex, newQueueEndIndex)
/**
* 当我们取消一个挂起的emitter对应的协程后,eimtter会被从array中移除,把对应在数组中的位置设置成NO_VALUE。
* 如果我们取消的这个emitter不是最后一个时,是不会对queueSize进行减一的。
*
* 比如有这种情况:
* [null,emitter2,emiiter3,emitter4,emitter5]
*
* 此时collector拿到index = 0 的数据正在处理,还未处理完成。这时候取消了emitter2,emitter3,emitter4变成:
* 【null,NO_VALUE,NO_VALUE,NO_VALUE,emitter5】
* 虽然emitter被移除了,但是queueSize 任然等于4。
*
* 过来一会儿,collector处理完成后,继续取index = 1的数据,取出是NO_VALUE,进入到该函数后。在前面的计算过程中
* 会把array变成如下:
* 【null,null,NO_VALUE,NO_VALUE,NO_VALUE】
* queueSize = 2;
* 有没有发现emitter5的数据(5)被丢掉了。是怎么被丢掉的呢?是在上线for循环里面,先把aray变成这样:
* 【null,5,NO_VALUE,NO_VALUE,NO_VALUE】。即先把index = 4的地方设成了NO_VALUE,在把emitter5的数据“5”
* 放到了index = 1的位置。但是执行完updateBufferLocked 后,index = 1位置的5又被设置成了null。
*
* 调用 cleanupTailLocked后:
* 【null,null,NO_VALUE,null,null】
* queueSize = 0。
*
* collector 执行完完该函数后,由于取到的是NO_VALUE, 又由于queueSize = 0,出去后会被挂起。
*
* 就在举这个例子过程中又发现了一个bug.emitter5的数据被丢掉了。为了证明bug的存在,我写了一个demo
* 测试后,的确发现collector只打印了index = 0的数据后,就被挂起了,我也debug看了array的变化情况,完全
* 符合上面说的情况。
*
*
* cleanupTailLocked 里面的代码比较简单,就是当queueSize > 0 和 array中最后一个数据为NO_VALUE时
* 从尾部开始逐一清除为NO_VALUE的值,设置成null,然后让queueSiez 减一。
*
*
*/
cleanupTailLocked()
//resumes 不为空时,说明有挂起的emitter会被唤醒,已经把需要唤醒的emitter对应的数据放入array中了,
//相当于flow中有新的数据了,这时候如果有被挂起的collector就可以唤醒他们让他们继续消费数据。
//把满足条件能够被唤醒的collector也放入resumes这个Array里面。一起返回去。
if (resumes.isNotEmpty()) resumes = findSlotsToResumeLocked(resumes)
return resumes
}
SharedFlow存在的bug
fun main() = runBlocking(){
//创建一个同步流,即bufferCapacity = 0 ,异常策略为suspned。
val flow = MutableSharedFlow<Int>()
//先安排一个订阅者A,否则在没有订阅自的情况下,发的数据都会被丢弃
launch {
flow.collect{
println("A received $it")
delay(6000)
}
}
//延迟一秒,确保订阅者已经被挂起了
delay(1000)
// 开启了6个协成
val job1 = launch {
flow.emit(1)
}
val job2 = launch {
flow.emit(2)
}
val job3 = launch {
flow.emit(3)
}
val job4 = launch {
flow.emit(4)
}
val job5 = launch {
flow.emit(5)
}
val job6 = launch {
flow.emit(6)
}
//延迟一秒,确保六次发送全部完成,即Emitter对象已经存入Buffer中了。
delay(1000)
//只把2,3,4 job 取消。
job2.cancel()
job3.cancel()
job4.cancel()
delay(1000)
延迟一秒,确保job2,3,4已经被取消了,再安排一个订阅者B
launch {
flow.collect{
println("B received $it")
}
}
}
这个Bug导致的结果就是只有订阅者A取到了数据1,打印了”A received 1“。然后程序就被挂起了,后续再也没有其他打印输出了。如果是正常情况,即使job2,3,4被取消了,至少数据5,和数据6会被订阅者A和订阅者B消费吧。实际情况却是没有。
这个bug我已经在kotlin官网的issue中提交了,地址:Coroutines: job cancel prevents MutableSharedFlow from showing the results of other jobs。在github上也有人向官方提交了类似的bug,都是因为协成取消导致的。
经过对ShareFlow的源码分析,发现在bufferCapacity = 0的情况下,只要最慢的那个订阅者下一次将要取数据的Emitter对应的协成被取消了这个Bug就会发生。就比如我们这个例子中,订阅者A去掉数据1后,开始处理数据1,这时候把订阅者A下一个要取的数据index = 1的Emitter移除了(协成取消)。就会导致bug发生。
即使我们在这个例子中最后不给整订阅者B。其他代码都不变,也会有bug。这个bug的现象就是,订阅者A只会打印数据1和数据6,数据5任然给整丢了。
经过测试,在协成版本1.7.1(包括)之前这个bug都存在。
下面我们来具体分析一下bug 是如何一步一步导致的:
在订阅者A还没开始取数据之前:

订阅者A取到数据a后,开始处理数据,

在第2秒的时候订阅者A还在处理数据,这时候把Emitter2,Emitter3,Emitter4 给取消了:

在第三秒的时候又整了一个订阅者B。订阅者B从replayIndex = 1的位置开始取,取出数据为NO_VALUE,订阅者B进入updateCollectorIndexLocked函数后,发现订阅者A比订阅者B慢,因此订阅者B在updateCollectorIndexLocked中什么也没有做返回了一个空的Array。由于订阅自B取出的数据时NO_VALUE,因此会走awaitValue函数,在awaitValue函数中调用tryPeekLocked时返回了-1。因为此时订阅者B对应的Slot.index = 2,而head = 1,在tryPeekLocked中 index > head 所以返回了-1。于是就把订阅者B挂起了。

在第7秒的时候,订阅者A处理完数据a后,开始取index = 1位置的数据,同样取到NO_VALUE,然后进入updateCollectorIndexLocked。在updateCollectorIndexLocked中,首先计算出newMinCollectorIndex = 2。然后又计算出maxResumeCount = 1,说明需要唤醒一个挂起的Emitter,问题就是这开始出现的:
if (maxResumeCount > 0) {
resumes = arrayOfNulls(maxResumeCount)
var resumeCount = 0
val buffer = buffer!!
for (curEmitterIndex in newBufferEndIndex until newQueueEndIndex) {
val emitter = buffer.getBufferAt(curEmitterIndex)
if (emitter !== NO_VALUE) {
emitter as Emitter
resumes[resumeCount++] = emitter.cont
buffer.setBufferAt(curEmitterIndex, NO_VALUE) ahead
buffer.setBufferAt(newBufferEndIndex, emitter.value)
newBufferEndIndex++
if (resumeCount >= maxResumeCount) break
}
}
}
for循环的额时候,newBufferEndIndex = bufferEndIndex = 1,newQueueEndIndex = 6。相当于从index =1 开始,遍历后面所有元素,对照上面的图,前面三个都是NO_VALUE。当便利到Emitter5的时候,把Emitter5对应的协成放入resumes中,把NO_VALUE存入Emitter5所在的位置,把Emitter5中的数据f,存入了index = 1的位置,让newBufferEndIndex++。

在updateCollectorIndexLocked中继续执行:
if (bufferCapacity == 0 && newReplayIndex < newQueueEndIndex && buffer!!.getBufferAt(newReplayIndex) == NO_VALUE) {
newBufferEndIndex++
newReplayIndex++
}
又变成了这样:

在updateCollectorIndexLocked中继续执行:
//(3,2,3,6) 四个参数分别对应的值
updateBufferLocked(newReplayIndex, newMinCollectorIndex, newBufferEndIndex, newQueueEndIndex)
经过updateBufferLocked函数后,buffer变成如下:

有没有发现Emitter5的数据f,就这么没了(bug出现了)。订阅者A执行完updateBufferLocked后,发现订阅订阅者B挂起的,这时候订阅者B满足唤醒了(在tryPeekLocked中返回了2),订阅者A执行完updateCollectorIndexLocked函数后回去调用订阅者B协成的resume函数唤醒订阅者B。由于订阅者A取的数据也是NO_VALUE,于是也会走awaitValue函数去挂起订阅者A。订阅者A在awaitValue中调用tryPeekLocked返回的结果为2,因此订阅自A不会被挂起,订阅者A会继续取index = 2的数据。
在这里订阅者A和订阅者B谁先取index = 2的数据不好说,这和两个订阅者协成调度器选择有关。不管谁先执行,都没关系。
就假如订阅者A先取数据2。订阅者A取完数据2后,订阅者A的Slot的index变为3,订阅者A进入updateCollectorIndexLocked后,订阅者A就走到订阅者B前面,因此订阅者B成了慢的那一个,订阅者A在updateCollectorIndexLocked中什么也不会做。订阅者A从index = 2的位置取到的数据时NO_VALUE。于是订阅者A进入到awaitValue函数,调用tryPeekLocked的时候,index > head(3 > 2)于是订阅自A被挂起了。订阅者B开始取数据2。订阅者B取到index = 2的数据为NO_VALUE。订阅者B的Slot.index变为3。订阅者B进入到updateCollectorIndexLocked函数,计算出newMinCollectorIndex = 3,maxResumeCount = 0,由于maxResumeCount = 0,所以订阅者B不会去唤醒挂起的Emitter。订阅者B在updateCollectorIndexLocked中继续,开始计算newReplayIndex的值,依然得出newReplayIndex =3,但是经过下面代码:
if (bufferCapacity == 0 && newReplayIndex < newQueueEndIndex && buffer!!.getBufferAt(newReplayIndex) == NO_VALUE) {
newBufferEndIndex++
newReplayIndex++
}
所以最终newBufferEndIndex = 4,newReplayIndex = 4。然后继续调用updateBufferLocked:
//(4,3,4,6) 四个参数分别对应的值
updateBufferLocked(newReplayIndex, newMinCollectorIndex, newBufferEndIndex, newQueueEndIndex)
执行完updateBufferLocked后,buffer情况如下:

订阅者B从从index = 2的位置取到的数据为NO_VALUE,于是订阅者B进入到awaitValue函数中,调用tryPeekLocked时返回3。不会被挂起,于是订阅者B又继续取数据,取index = 3位置的数据,取出的数据又是NO_VALUE,取完数据后,让订阅自B的Slot的index加一,变为4。订阅者进入到updateCollectorIndexLocked后,计算出newCollectIndex = 3,出现了newMinCollectorIndex = minCollectorIndex,因为订阅者A现在是最慢的了。所以订阅者B在updateCollectorIndexLocked中直接被返回了。订阅者B从updateCollectorIndexLocked函数中退出后,因为取到的数据为NO_VALUE。所以订阅者B又进入到awaitValue函数中,这一次在调用tryPeekLocked时出现了index(4) > head(3)的情况,tryPeekLocked 返回-1,因此这一次订阅者B被挂起了。

订阅者A和订阅者B都被挂起了,如果没有新的发送者发送数据,订阅者A和订阅者B会一直被挂起,直到协成取消,或者程序退出,这就导致了之前被挂起的Emitter6的数据没办法被消费了。