目录
- 1 计算长度 len
- 2 大小写 lower、upper、title、capitalize、swapcase
- 3 字符检索 get、slice
- 4 元素提取 findall、extract
- 5 索引操作 find、index
- 6 字符类型判断,结果一定是True或False
- 7 字符判断 contains、startswith、endswith
- 8 替换 replace
- 9 字符的分割 split、partiton
- 10 去除字符前后特殊字符 strip
- 11 字符填充与对齐center、ljust、rjust、pad、zfill
- 12 拼接 cat
- 13 重复 repeat
- 14 统计 count
pandas提供了一组字符串函数,这些函数忽略NaN值,可以将Series对象转换为String对象,然后使用字符串函数。除此之外panda还有一些功能强大的字符串方法。
1 计算长度 len
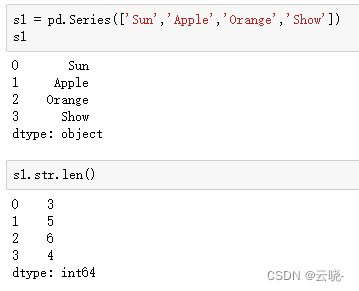
s1.str.len() #字符串长度
2 大小写 lower、upper、title、capitalize、swapcase
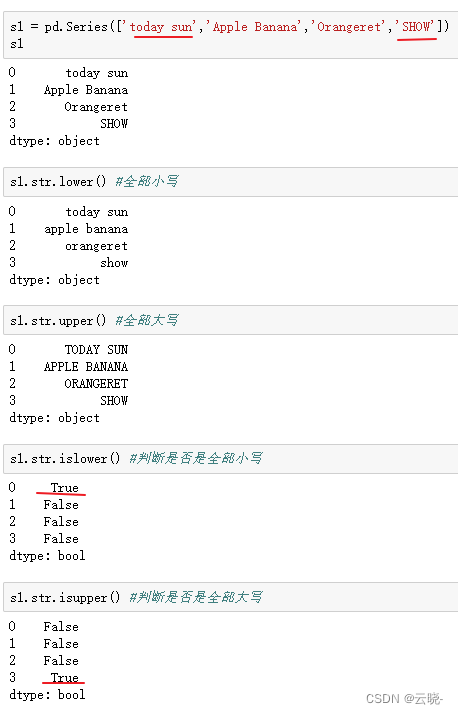
- .str.lower() #小写
- .str.upper() #大写
- .str.islower() #判断是否小写
- .str.isupper() #判断是否大写
- .str.title() #将每个单词的首字母大写,其他的小写
- .str.capitalize() #将整个字符串的首字母大写,其他的小写
- .str.swapcase() #大小写互换

3 字符检索 get、slice
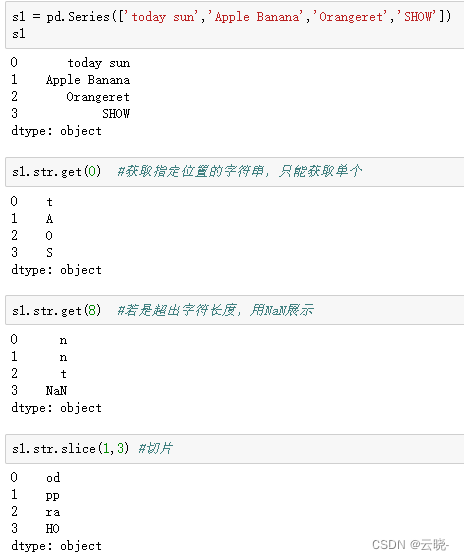
s1.str.get(0) #获取字符串中的单个元素,得到某个位置上到的元素值
s1.str.slice(0,2) #参数和参数之间是逗号分割,参数:起始位置,终止位置和步长
4 元素提取 findall、extract
- .str.extract()
- .str.findall()
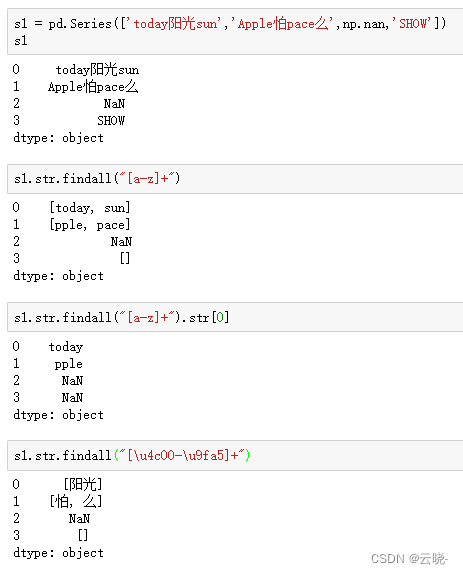
s2.str.extract("([a-z])") #只能提取第一次出现

.str.findall("[\u4e00-\u9fa5]+") #提取中文
5 索引操作 find、index
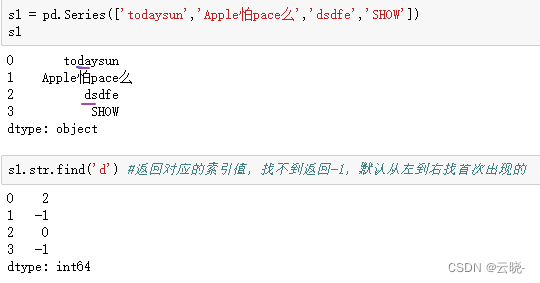
.str.find() #返回对应的索引值,找不到返回-1,默认从左到右找首次出现的
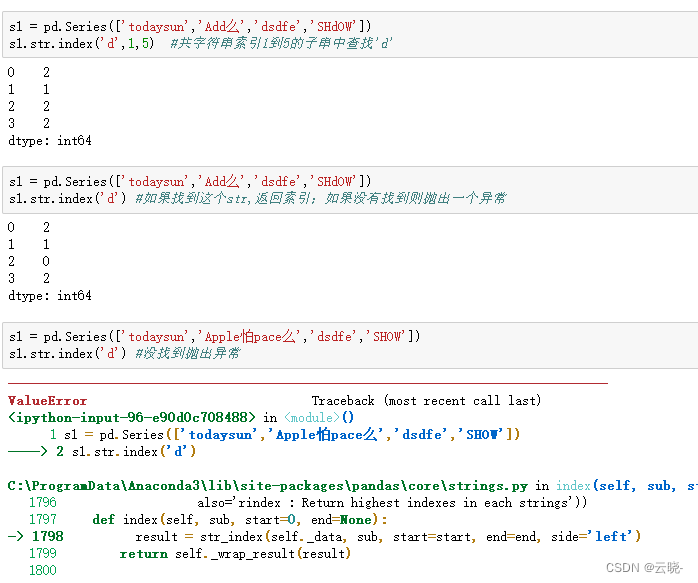
.str.index(str, beg=0 end=len(string))#如果找到这个str,返回索引;如果没有找到则抛出一个异常
'''
str -- 此选项指定要搜索的字符串。
beg -- 这是开始索引,默认情况下是 0。
end -- 这是结束索引,默认情况下它等于该字符串的长度。
'''
6 字符类型判断,结果一定是True或False
- .str.islower() #是否是小写 和 .str.isupper() #是否是大写
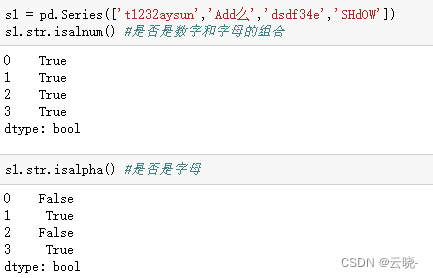
- .str.isnumeric() #是否是数字、.str.isalnum() #是否是数字和字母的组合、.str.isdecimal() #是否是十进制数字、.str.isalpha() #是否是字母
- .str.isspace() #是否是空格
- .str.istitle() #判断字符串的的所有单词是否首字母(开头)是大写其他为小写。
7 字符判断 contains、startswith、endswith
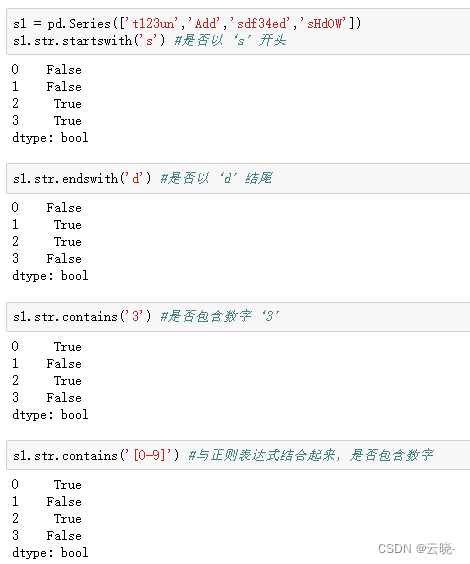
contains 包含 : 判断字符串中是否包含某个自字符
startswith :判断是否以子串开始
endswith : 判断是否以子串结束
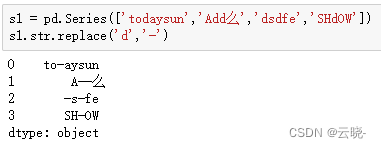
8 替换 replace
.str.replace() #可以实现单个字符串的替换
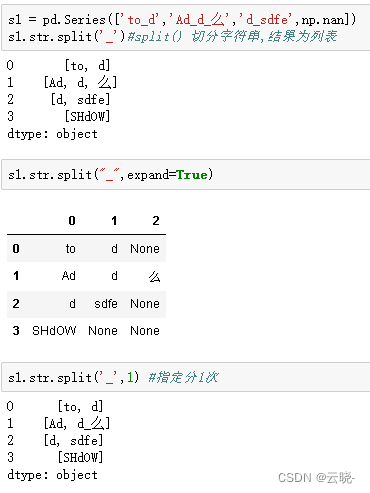
9 字符的分割 split、partiton
.str.split() #结果的数据类型,每个单元格里的都是列表
.str.split(,expand=True) #结果的数据类型,每个单元格里的都是列表
s1.str.partition() # 切割为三部分,分隔符前,分隔符,分隔符后

10 去除字符前后特殊字符 strip
.str.strip() #首尾字符交替去除

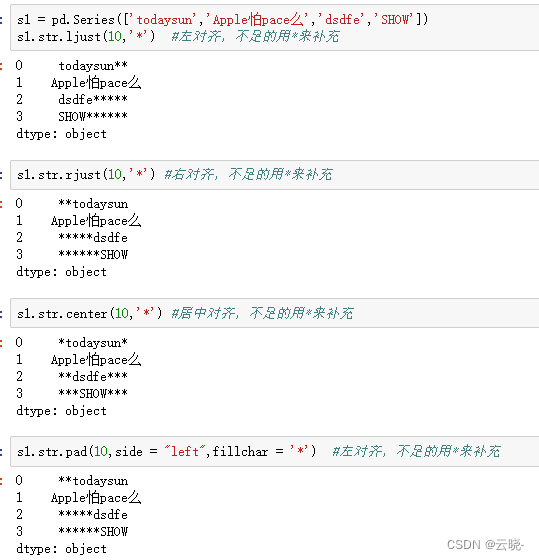
11 字符填充与对齐center、ljust、rjust、pad、zfill
- .str.center()
- .str.ljust() 和 .str.rjust()
- .str.pad()
- .str.zfill()

12 拼接 cat
.str.cat(sep = ' ')

13 重复 repeat
.str.repeat(repeats = 1) #repeats 设置重复次数

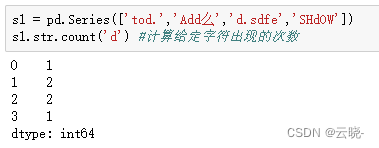
14 统计 count
.str.count() #计算给定字符出现的次数


![[230608] 阅读TPO58汇总|7:30-9:00+17:05](https://img-blog.csdnimg.cn/cba0e007d19c40d48231d90ce59106c6.png)