写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:zhuyc@vip.163.com。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
Mac系统安装Kafka 3.x及可视化工具
本文关键字:MacOS、Kafka、Eagle、brew、console测试
文章目录
- Mac系统安装Kafka 3.x及可视化工具
- 一、Kafka介绍
- 1. 应用场景
- 2. 版本对比
- 二、Kafka安装
- 1. 软件安装
- 2. 服务启动
- (1)启动Zookeeper
- (2)启动Kafka
- 3. 话题创建
- 三、Eagle安装
- 1. 下载安装
- 2. 配置修改
- 3. 项目启动
- 四、console测试
- 1. 启动生产者
- 2. 启动消费者
- 3. 验证流程
- 3. 可视化查询
- (1)Kafka总览
- (2)查看Topic列表
- (3)KSQL查询
一、Kafka介绍
来自维基百科:Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。

1. 应用场景
Kafka可以看作是一个能够处理消息队列的中间件,适用于实时的流数据处理,主要用于平衡好生产者和消费者之间的关系。
- 生产者
生产者可以看作是数据源,可以来自于日志采集框架,如Flume,也可以来自于其它的流数据服务。当接收到数据后,将根据预设的Topic暂存在Kafka中等待消费。对于接收到的数据将会有额外的标记,用于记录数据的被消费【使用】情况。
- 消费者
消费者即数据的使用端,可以是一个持久化的存储结构,如Hadoop,也可以直接接入支持流数据计算的各种框架,如Spark - Streaming。消费者可以有多个,通过订阅不同的Topic来获取数据。
2. 版本对比
Kafka的0.x和1.x可以看作是上古版本了,最近的更新也是几年以前,从目前的场景需求来看,也没有什么特别的理由需要使用到这两个版本了。
- 2.x
在进行版本选择时,通常需要综合考虑整个数据流所设计到的计算框架和存储结构,来确定开发成本以及兼容性。目前2.x版本同样是一个可以用于生产环境的版本,并且保持着对Scala最新版本的编译更新。
- 3.x
3.x是目前最新的稳定版,需要注意的是,Kafka的每个大版本之间的差异较大,包括命令参数以及API调用,所以在更换版本前需要做好详细的调查与准备,本文以3.x的安装为例。
二、Kafka安装
在Mac上使用brew安装Kafka十分简单,在此列出依赖关系,如果想要自己指定某些软件的版本,可以提前手动安装:
- Java8【Scala的依赖】
- Scala【Kafka的依赖】
- Zookeeper【Kafka的依赖】
1. 软件安装
如果使用brew安装,一般直接使用以下命令就可以直接安装各种依赖:
brew install kafka
安装完成后可以使用以下命令确认版本信息:
brew info kafka
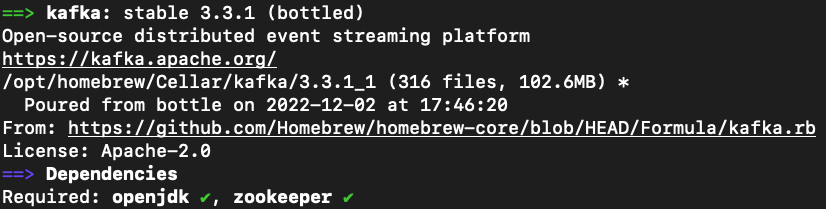
- Tips:如果你以前已经手动安装过Java环境,需要配置好JAVA_HOME的环境变量,如:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_331.jdk/Contents/Home
默认的安装路径将在**/Library/Java/JavaVirtualMachines/**,大家可以自行寻找。
2. 服务启动
(1)启动Zookeeper
- 常驻后台启动【brew方式】
brew services restart zookeeper
启动后可以使用以下命令验证:
brew services info zookeeper

- 脚本自定义启动
如果需要通过指定的配置文件启动,可以在以下位置找到Zookeeper的命令文件路径以及配置文件样例:
# 命令所在路径
/opt/homebrew/opt/zookeeper/bin/

# 配置文件样例
/opt/homebrew/opt/zookeeper/share/zookeeper/examples

(2)启动Kafka
- 常驻后台启动【brew方式】
brew services restart kafka
启动后可以使用以下命令验证:
brew services info kafka

- 脚本自定义启动
如果需要通过指定的配置文件启动,可以在以下位置找到Kafka的命令文件路径以及配置文件样例:
# 命令所在路径
/opt/homebrew/opt/kafka/bin/
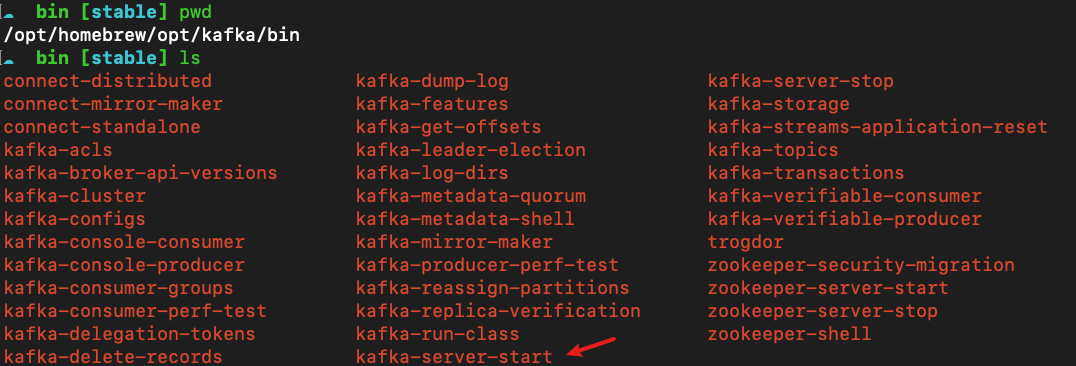
# 配置文件样例
/opt/homebrew/etc/kafka

3. 话题创建
以下命令适用于Kafka 3.x版本:
- 创建话题
kafka-topics --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test_kafka

- 查看列表
kafka-topics --list --bootstrap-server localhost:9092

三、Eagle安装
Kafka Eagle是一个基于Web的可视化界面,可以方便的查看到当前Kafka的运行状态以及进行数据查询,十分方便。
1. 下载安装
- 官网地址:https://www.kafka-eagle.org/
- Github:https://github.com/smartloli/EFAK
进入官网Download页面,点击下载按钮得到软件包,直接解压缩到某一个目录:
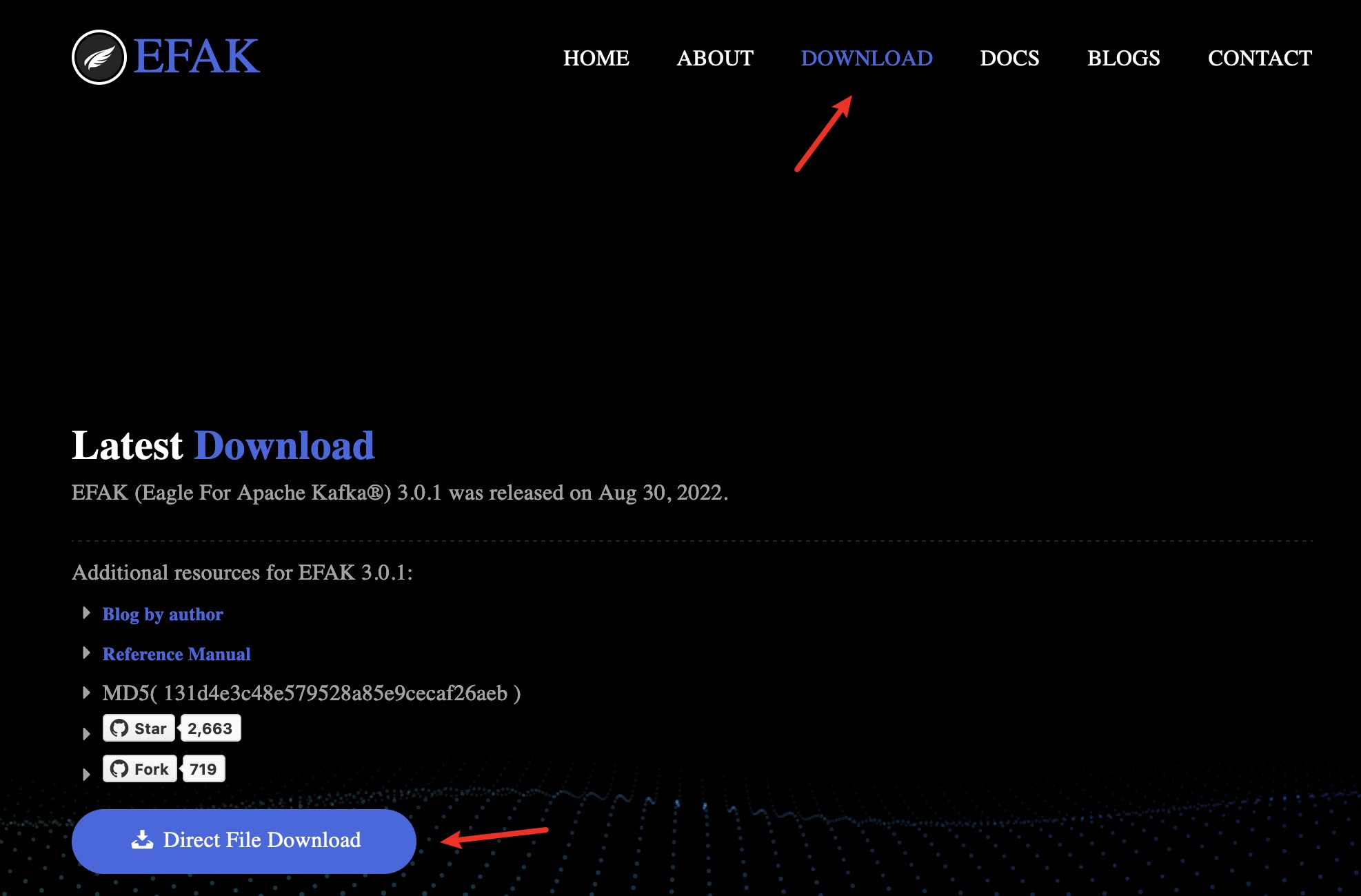
2. 配置修改
- 配置环境变量
需要确保已经配置了JAVA_HOME,同时添加EFAK的解压路径作为KE_HOME:
# 在环境变量配置文件中
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_331.jdk/Contents/Home
export KE_HOME=/Users/xxx/Software/efak-web-3.0.1
export PATH=$JAVA_HOME/bin:$EK_HOME/bin:$PATH
- EFAK配置文件修改($EK_HOME/conf/system-config.properties)
需要在MySQL数据库中新建一个名为ke的数据库,编码使用utf8mb4,也可以使用sqlite方式配置。
efak.zk.cluster.alias=cluster1
cluster1.zk.list=localhost:2181
# 注释cluster2.zk.list
# 修改结尾的jdbc连接参数
# 确认efak.username
# 确认efak.password
3. 项目启动
- 启动命令
进入到命令文件所在路径:$KE_HOME/bin,执行以下命令:
# 启动
ke.sh start
# 停止
ke.sh stop
# 重启
ke.sh restart
# 状态
ks.sh status
- 登录页面
成功启动后根据提供的用户名密码进行访问和登录:

- 注意事项
当机器的网络环境发生变化后【如从办公室回到家】,需要重启Kafka服务与Eagle项目,因为hostname绑定的是具体的局域网IP,当更换后,需要使用新的ip进行访问。
四、console测试
当Kafka服务成功安装启动后,测试的最好方法就是使用最简单的生产者与消费者脚本来进行测试,前文中已经创建了话题test-kafka,则相关命令如下:
1. 启动生产者
kafka-console-producer --bootstrap-server localhost:9092 --topic test_kafka

启动成功后即可在交互环境中直接输入数据来模拟数据的流入,当消费者启动后即可看到被消费的数据。
2. 启动消费者
添加from-beginning参数以从头消费数据。
kafka-console-consumer --bootstrap-server localhost:9092 --topic test_kafka --from-beginning

3. 验证流程
在生产者控制台中随意输入数据,同时查看消费者控制台的数据输出【消费】情况。

3. 可视化查询
(1)Kafka总览
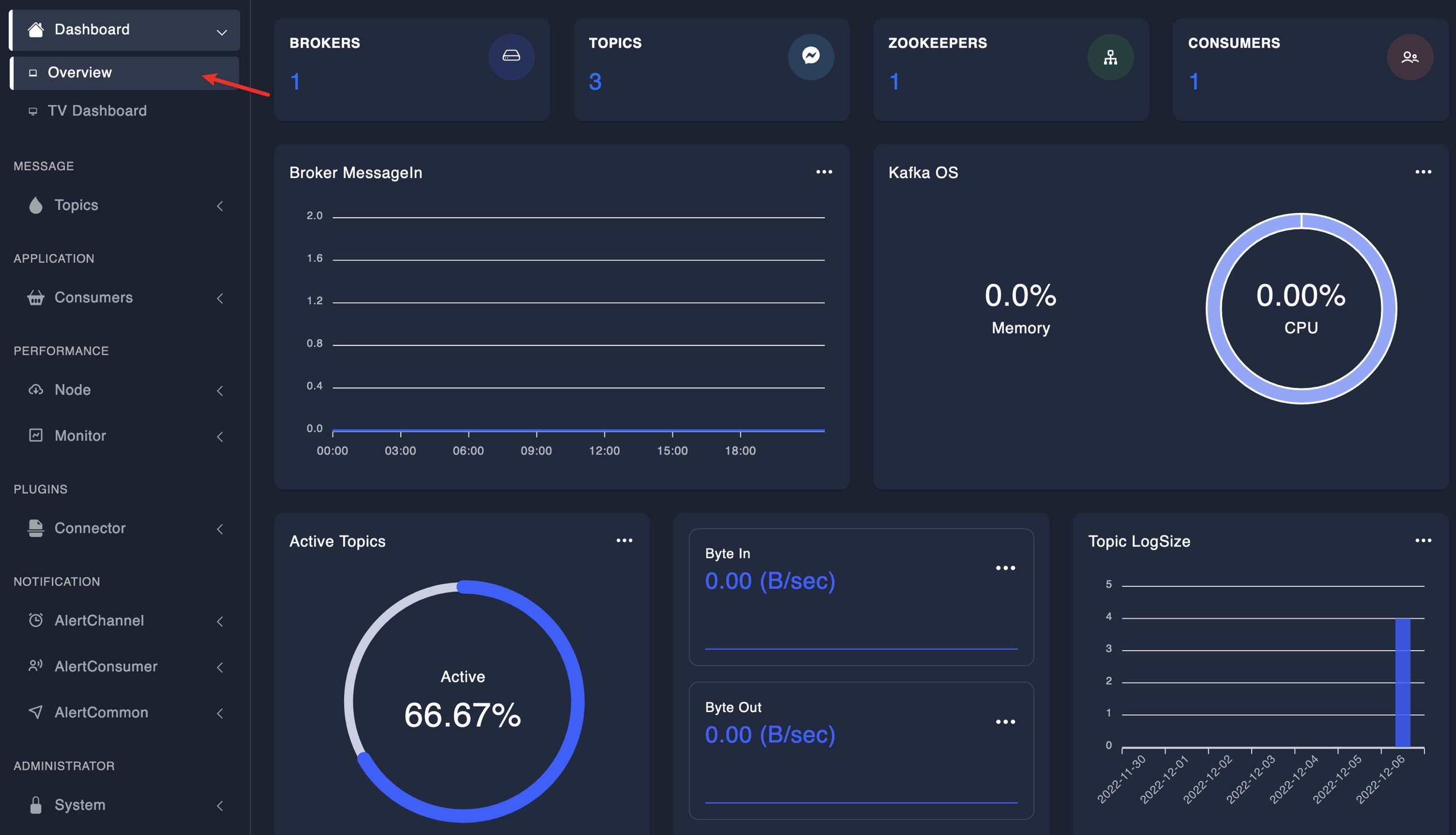
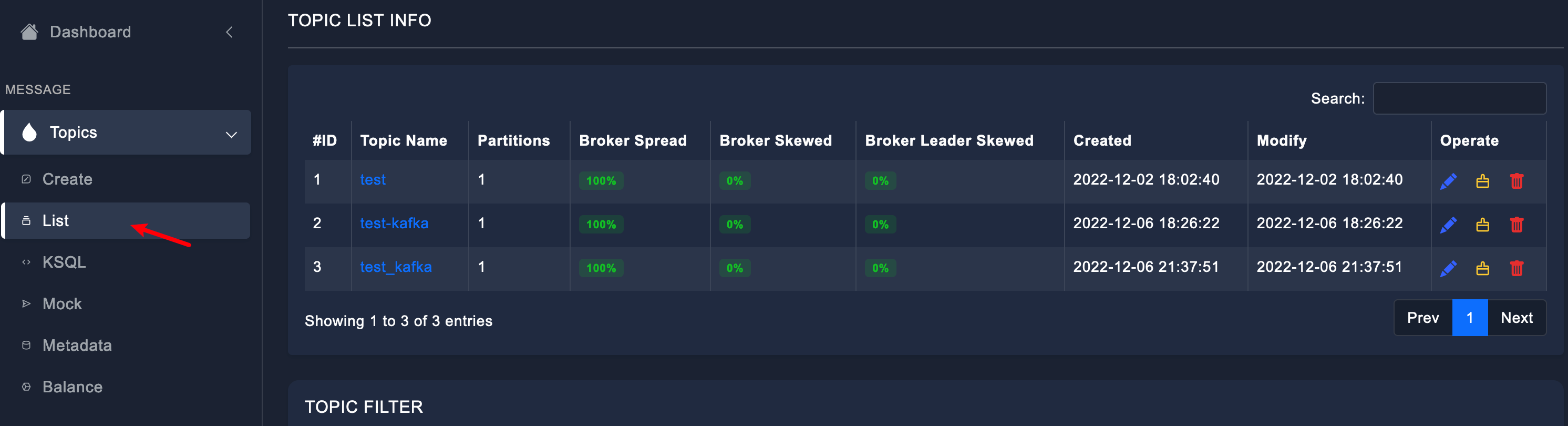
(2)查看Topic列表
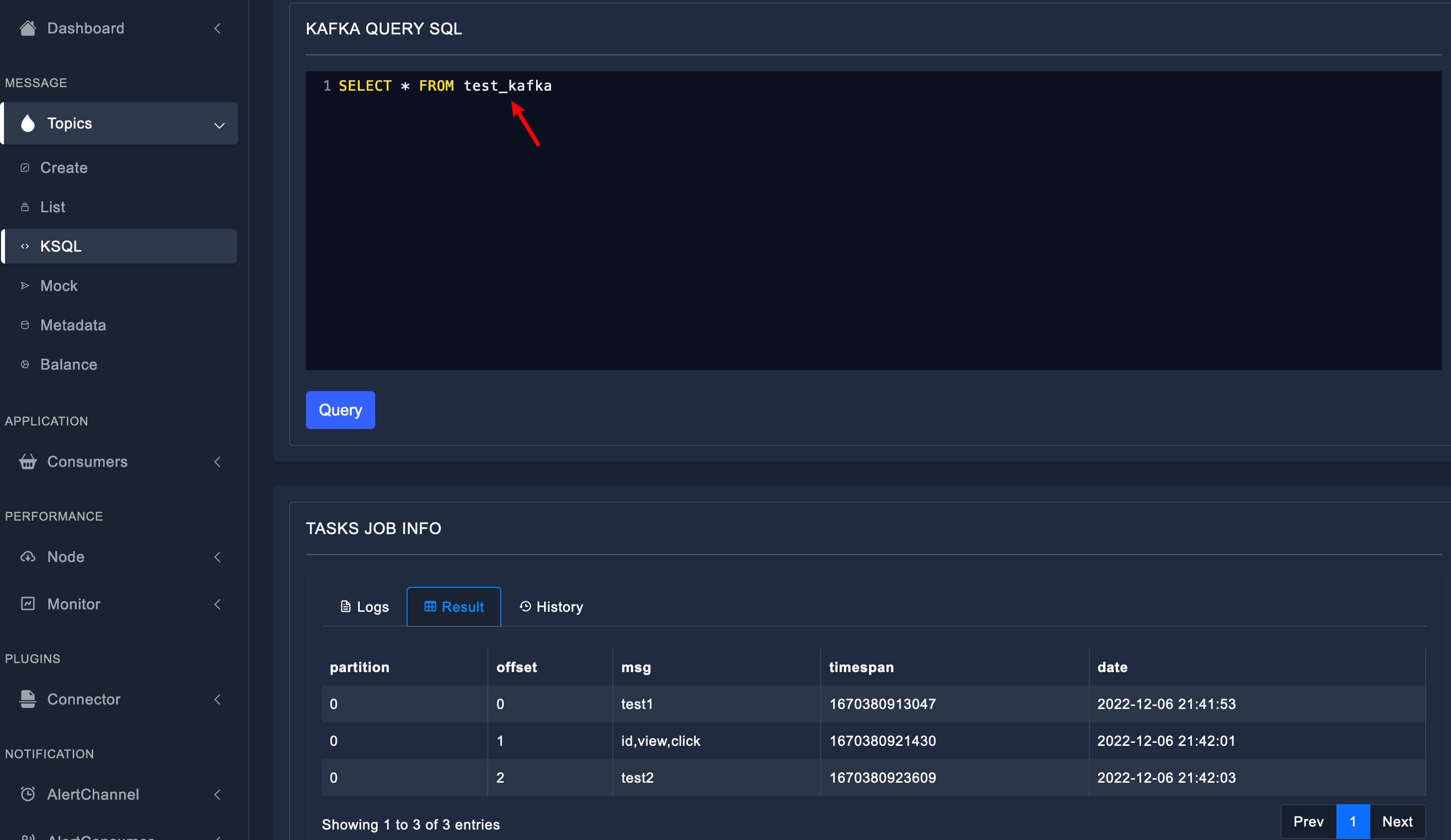
(3)KSQL查询

![[附源码]Python计算机毕业设计Django学生综合数据分析系统](https://img-blog.csdnimg.cn/a2ad5a21d26b4813989bc961f42e780a.png)