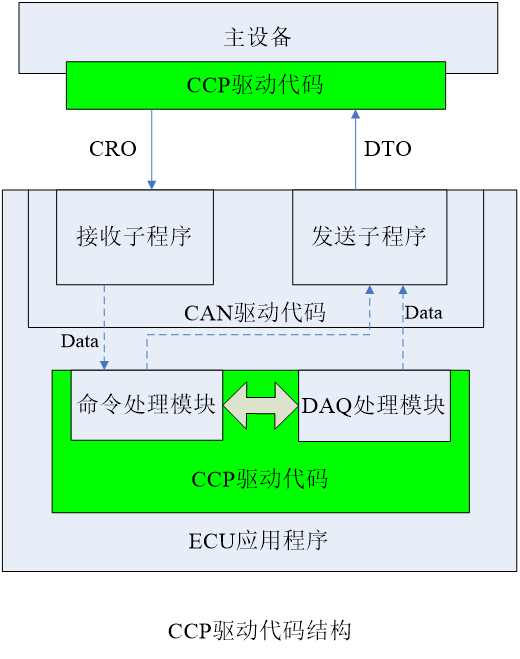
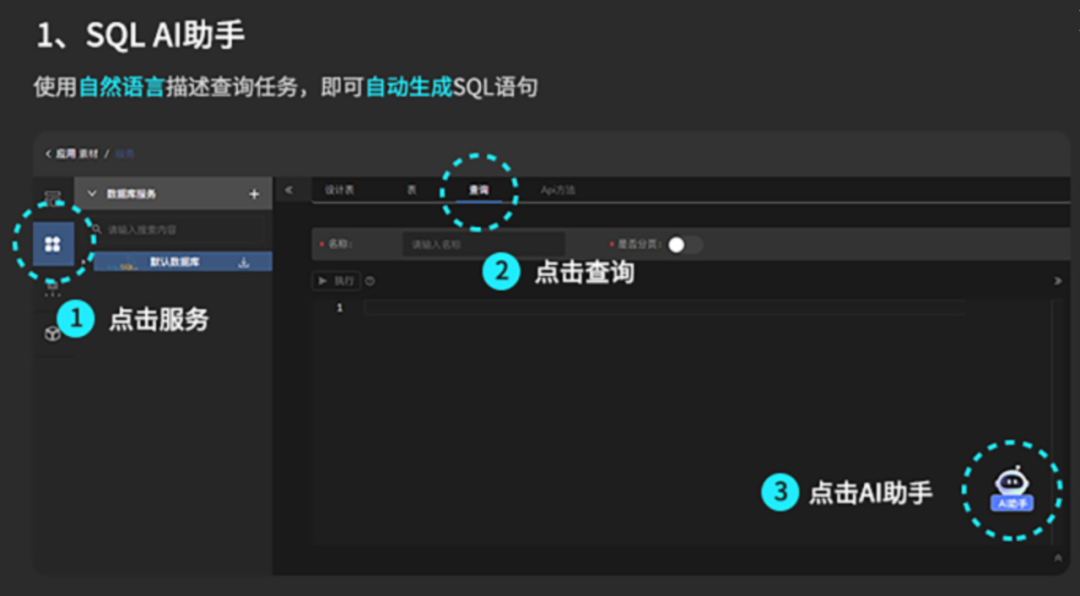
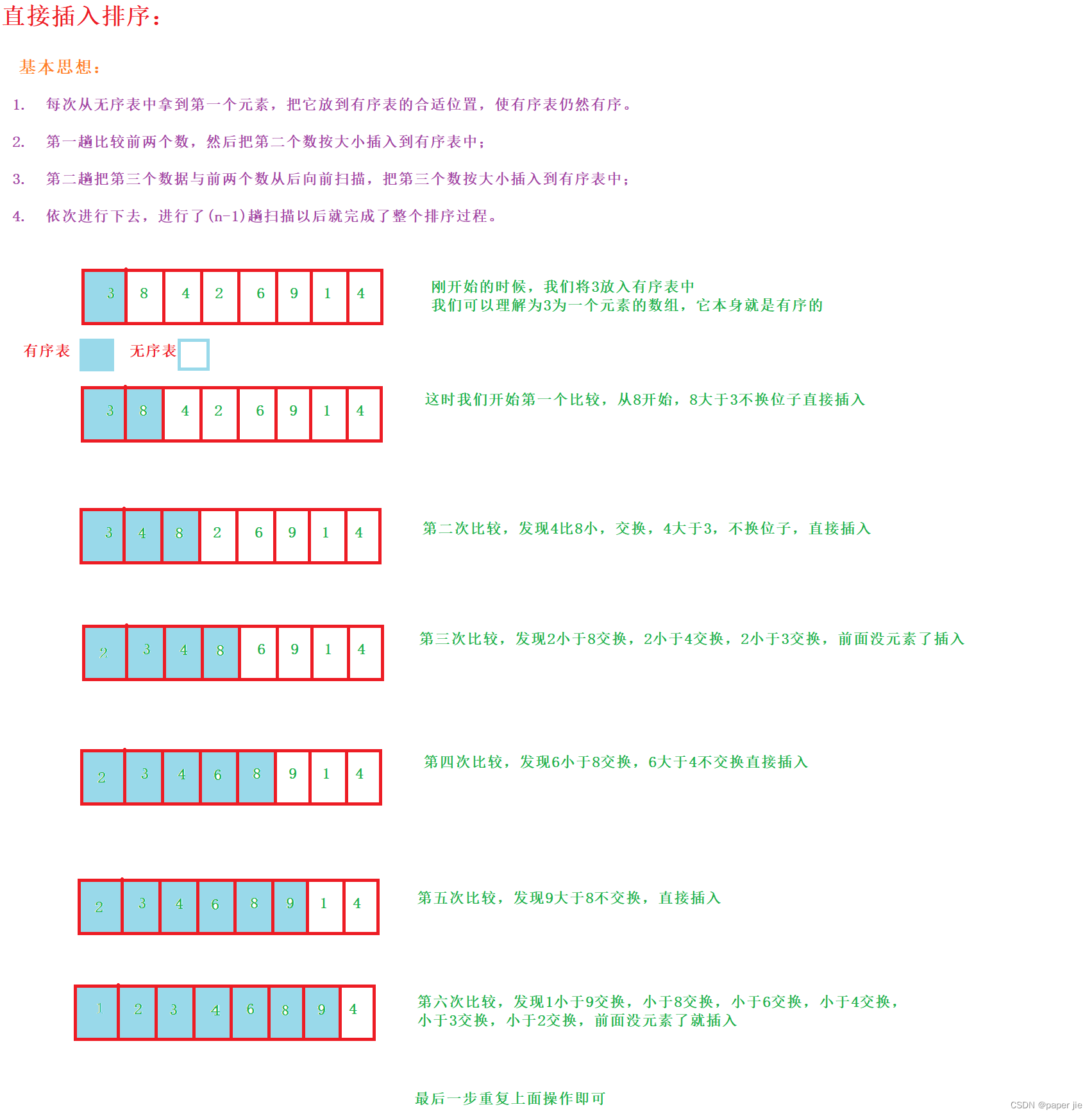
SpringCloud
- 一:微服务架构
- 1.1 ESB
- 1.2 微服务与微服务
- 二 :编写SpringCloud代码
- 2.1 父模块SpringCloudDemo项目
- 2.2 公共类模块SpringCloud-api项目
- 2.3 消费模块SpringCloud-user-8001项目
- 2.4 RestTemplate
- 三:注册中心:Eureka
- 3.1 eureka的服务端代码实现
- 3.2 注册服务到eureka上
- 3.3 eureka的自我保护机制
- 3.4 Eureka的健壮性和容错性的三大保障
- 3.5 Eureka完善监控信息
- 3.6 Eureka 服务的发现
- 3.7 修改Eureka上的默认的状态名字
- 3.8 Eureka的集群
- 3.9 将8001服务注册到集群中
- 3.10 分布式系统的CAP原则
- 四: 负载均衡:Ribbon
- 4.1 将80客户端实现负载均衡
- 4.2 Ribbon 实现随机负载均衡
- 五:客户端调用:Fegin
- 5.1 Fegin与RestTemplate的区别
- 六:服务熔断:Hystrix
- 6.1 服务的雪崩
- 6.2 Hystrix概念:
- 6.3 服务降级
- 6.4 Fegin客户端与服务端都实现双侧服务降级
- 6.5 服务端的峰值调用
- 6.5 Hystrix的代码拢余
- 6.6 服务熔断
- 6.6.1 服务熔断重要参数
- 6.6.2 服务熔断小结
- 6.7 Hystrix的监控
- 七:Zuul (网关)
- 7.1 Zuul的概念
- 7.2 Zuul的代码实现
- 7.3 服务前缀
- 7.3 Zuul的执行流程
- 7.4 Zuul自定义过滤器
- 八:Config
- 8.1 git的环境准备
- 8.2 Config的准备
- 8.3 设置超时时间
- 8.4 对原有项目进行操作
- 8.5 动态刷新Config的客户端
- 九: 微服务网关 GateWay
- 9.1: GateWay路由实现
- 9.2 gateway实现负载均衡
- 9.3 GateWay之Predicates的使用
- 9.4 GateWay过滤器的使用
- 9.5 自定义过滤器
- 十:Springcloud-Bus
- 10.1:Springcloud-Bus代码实现
- 10.2 :Springcloud-Bus的定点刷新
- 10.3 SpringCloud-Bus的执行流程
- 十一:SpringCloud-sleuth
- 11.1 zipkin
- 11.2 代码实现
- 11.3 zipkin数据的持久化到Mysql中
- 十二 :SpringCloud Stream--消息驱动
- 12.1代码实现数据推送
- 12.2 代码实现接受数据
- 12.3 消息的分组
- 12.3 消息的持久化
- 十三:SpringcloudAlibaba
- 13.1 SpringCloudAlibaba环境搭建
- 13.2 SpringCloudAlibaba组件Nacos组件
- 13.2 Nacos核心功能
- 13.3 nacos的安装和服务端的配置
- 13.4 Nacos客户端的配置
- 13.5 Nacos管理界面
- 13.5 Nacos的配置
- 13.5 Nacos Linux下集群的搭建
- 13.6 openFegin
- 13.6.1 openFegin的日志配置
- 13.6.2 openFegin的超时时间配置
- 13.6.3 openFegin自定义拦截器
- 13.7 nacos的config配置
- 13.7.1 nacos-config的配置管理界面
- 13.7.1 nacos-config的权限控制
- 13.7.2 nacos-config读取配置
- 13.7.2 nacos-config的其他配置
- 13.8 sentinel (服务熔断)
- 13.8.1 sentinel 流控规则的使用
- 13.8.2 @ SentinelResource 的使用
- 13.8.3 控制台的方式进行部署
- 13.8.4 整合Springcloud-alibaba
- 13.8.4 Qps- 服务熔断
- 13.8.4 线程流控
- 13.8.4 BlockException的统一返回数据
- 13.8.5 链路流控规则
- 13.8.5 流控效果介绍
- 13.8.6 Warm Up和排队等待
- 13.8.7 熔断降级
- 13.8.8 热点数据处理
- 13.8.9 规则持久化
- 13.9 Seata (分布式事务)
- 13.9.1 二阶段提交协议(2pc)
- 13.9.2 分布式解决方案:AT模式
- 13.9.3 分布式解决方案:TCC模式
- 13.9.4 MQ的可靠消息最终一致性
- 13.9.5 Srate DB服务搭建
- 13.9.6 Srate db+nacos服务搭建
- 13.9.7 代码和环境搭建
- 13.9.8 Seata解决分布式事务
- 13.9.9 Seate的分布式生命周期和原理
- 13.10 getway
- 13.10.1 getway整合nacos
- 13.10.1 请求日志配置
- 13.10.2 Sentinel 整合getway
- 13.10.3 Sentinel 整合getway自定义异常
- 13.11 SkyWalking 链路追踪
- 13.11.1 SkyWalking 接入多个微服务
- 13.11.2 SkyWalking 持久化数据
- 13.11.3 SkyWalking 自定义
- 13.11.4 SkyWalking 的性能监控
一:微服务架构
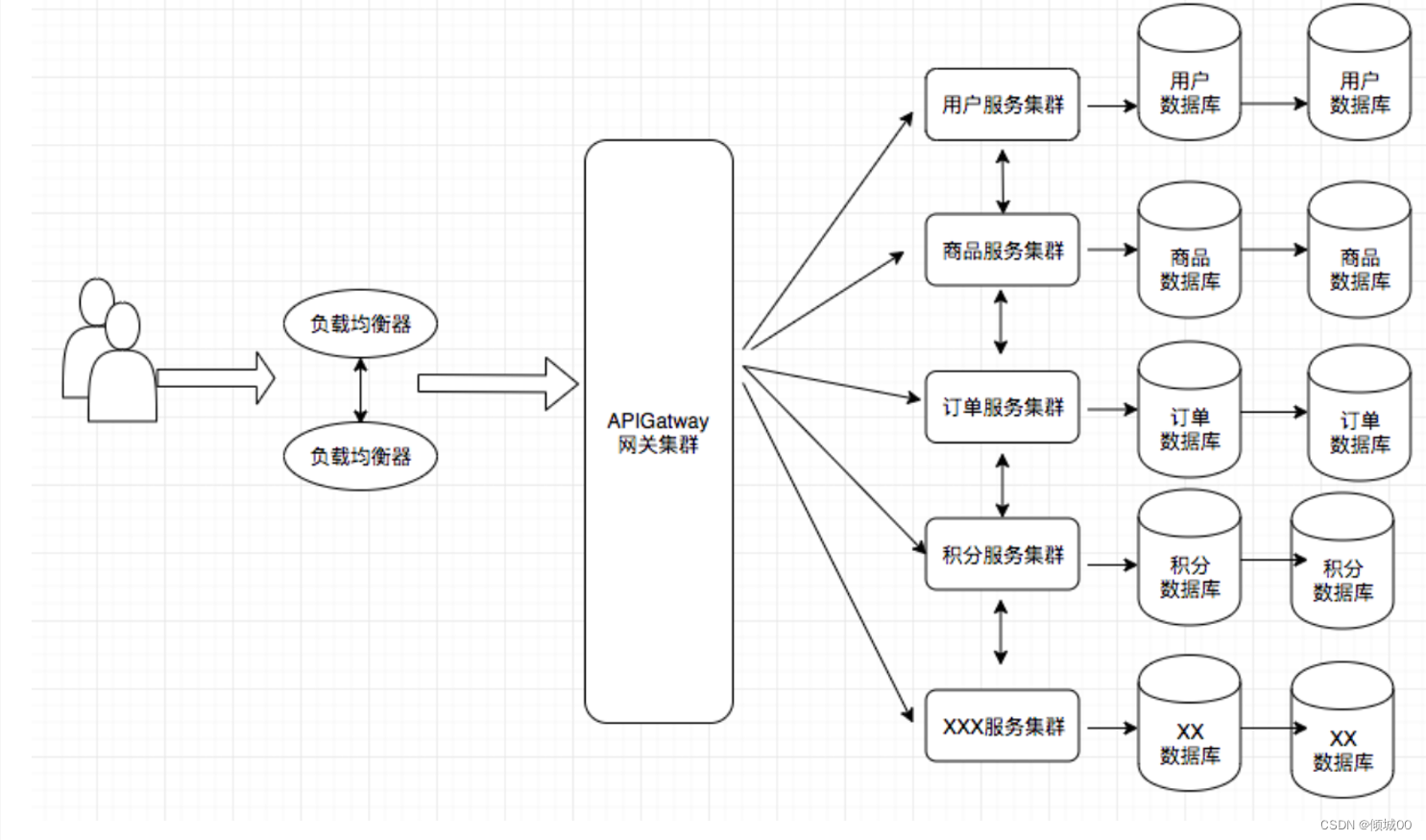
- 特点:
- 将系统服务层完全独立出来,抽成一个个的微服务
- 微服务遵循单一的原则
- 微服务之间采用RESTful等清凉传输协议
- 优点
- 服务拆分粒度更细,有利于资源的重复利用,提高开发效率
- 可以更加精准的定制每个服务的优化方案,提高系统的可维护性
- 微服务架构采用中心化思想服务之间采用RESTful轻量级通信,比ESB更轻量
- 适用于互联网时间,产品迭代周期更短
- 缺点
- 微服务过多服务治理成本高,不利于维护
- 分布式开发的质数成本高,(容错,分布式事务等),对团队挑战大
1.1 ESB
-
ESB是企业服务总线,既全程是:Enterprise Service Bus,是指传统中间件与XML,WEB服务等技术结合的产物, ESB提供了网络中最基本的连接中枢,是构建企业神经系统的必要元素,
-
理解: 它的核心功能就是兼容各个企业的协议接口,可以将数据在各个协议之中进行流转,并且可以根据数据格式对数据进行编排转换,格式转换(A系统是用java写的支持JSON,B系统是用C++写的支持xml,那么ESB就会吧这两种格式的数据转化为同一种)、协议转换(A系统是Http协议,B系统是Https系统,那么ESB也会吧他们转为相同的协议)、代理(A系统想要获取B系统中的数据,不是直接获取,而是由ESB作为代理,A系统从ESB中获取)、安全控制(数据交互的时候有身份验证机制)、监控(监控各个子系统是否运行正常)、不支持高并发,类似于路由器维护着一张路由表进行路由转发。
1.2 微服务与微服务
- 分布式:一个业务被拆分为多个子模块,部署在不同的服务器上
- 分布式的项目架构:根据业务需求拆分为N多个 子系统,多个子系统相互协作才能完成业务流程子系统之间通讯使用Rpc远程调用技术
优点:
(1)把模块拆分,使用接口通信,降低模块之间的耦和度
(2)把项目拆分为多个子模块,不同的团队负责不同的子项目
(3)增加模块只需要在增加一个子项目,调用其他系统的接口
- RPC远程调用:
RPC 的全称是 Remote Procedure Call 是一种进程间通信方式。
它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即无论是调用本地接口/服务的还是远程的接口/服务,本质上编写的调用代码基本相同。
比如两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数或者方法,由于不在一个内存空间,不能直接调用,这时候需要通过就可以应用RPC框架的实现来解决 - RPC远程调用框架/技术
几种比较典型的RPC的实现和调用框架。
(1)RMI实现,利用java.rmi包实现,基于Java远程方法协议(Java Remote Method Protocol)
和java的原生序列化。
(2)Hessian,是一个轻量级的remoting onhttp工具,使用简单的方法提供了RMI的功能。 基于HTTP协议,采用二进制编解码。
(3)thrift是一种可伸缩的跨语言服务的软件框架。thrift允许你定义一个描述文件,描述数据类型和服务接口。依据该文件,编译器方便地生成RPC客户端和服务器通信代码。
(4)SpringCloud 为开发人员提供了快速构建分布式系统的一些工具,包括配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等。
(5) Dubbo是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架很容易集成。
二 :编写SpringCloud代码
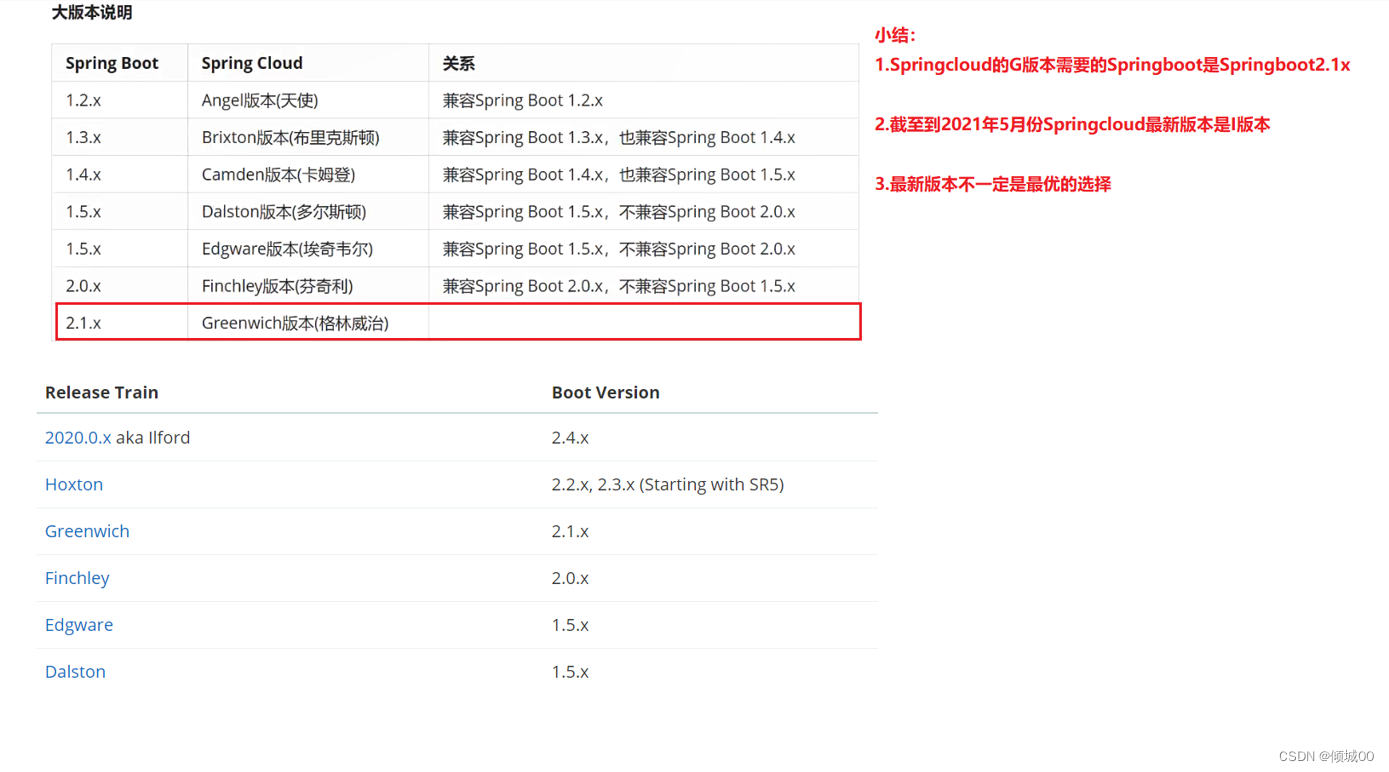
- 首先创建SpringCloudDemo项目,为父模块,里面在pom中约束了maven依赖的版本还有springboot和springcloud的版本
- 然后编写SpringCloud-api项目,为公共的实体类,既任何子模块通过引入都可以调用这个类
- 编写SpringCloud-user-8001项目为一个模块的消费者,引入SpringCloud-api使用User实体类对数据进行增删改查
- 下面是架构图,都是父模块的子项目
2.1 父模块SpringCloudDemo项目
pom文件
<!--用来管理有可能会用到的jar包-->
<dependencyManagement>
<dependencies>
<!--1.springcloud的依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Greenwich.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--2.springBoot依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.1.4.RELEASE</version>
<type>pom</type>
<scope>import </scope>
</dependency>
<!--3.数据库-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.8</version>
</dependency>
<!--4.数据库连接池:druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
<!--5.SpringBoot启动器(mybatis整合springboot)-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.1</version>
</dependency>
<!--6.junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!--7.lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
<!--8.日志测试-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>
</dependencyManagement>
2.2 公共类模块SpringCloud-api项目
- pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>SpringCloudDemo</artifactId>
<groupId>com.bj.sh</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<groupId>com.bj.sh.pojo.User</groupId>
<artifactId>SpringCloud-api</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!--当前这个模块是当前微服务项目中的其中一个,其作用是对实体类添加上做处理的,因为父项目中已经做了dependencyManagement,且还配置了版本信息
所以我们在这里只是需要引入具体需要用的lombok.jar,连版本都可以不写-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
</project>
- 实体类User
package com.rj.bd.prop;
import lombok.Data;
import lombok.experimental.Accessors;
/**
* @author WYH
* @desc
* @time 2021-05-02-16:05
*/
@Data
@Accessors(chain = true)// 可以实现链式调用的编写,即:user.setId("001").setName("杨过");
public class User {
private String id;
private String name;
private int age;
private String dbname;
}
2.3 消费模块SpringCloud-user-8001项目
1.pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>SpringCloudDemo</artifactId>
<groupId>com.bj.sh</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>SpringCloud-user-8001</artifactId>
<dependencies>
<dependency>
<groupId>com.bj.sh.pojo.User</groupId>
<artifactId>SpringCloud-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<!--test-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
<!--热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
</dependencies>
</project>
- application.yml 文件
# 服务启动的端口8001
server:
port: 8001
spring:
application:
name: springCloud-user
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/springcloud001?userSSL=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
- dao层 (实体类引用的是SpringCloud-api的User)
package com.bj.sh.Dao;
import com.rj.bd.prop.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* @author LXY
* @desc
* @time 2022--12--03--17:11
*/
@Mapper
public interface UserDao {
@Select("select * from user where 1=1")
List<User>queryAllUser();
@Select("select * from user where id=#{id}")
User qeryAllUserById(String id);
}
- Service层
package com.bj.sh.Service;
import com.rj.bd.prop.User;
import java.util.List;
/**
* @author LXY
* @desc
* @time 2022--12--03--17:37
*/
public interface UserService {
public List<User>qeryAllUser();
User qeryAllUserById(String id);
}
5.SeviceImple
package com.bj.sh.Service.ServiceImple;
import com.bj.sh.Dao.UserDao;
import com.bj.sh.Service.UserService;
import com.rj.bd.prop.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* @author LXY
* @desc
* @time 2022--12--03--17:37
*/
@Service
public class UserServiceImple implements UserService {
@Autowired
UserDao dao;
@Override
public List<User> qeryAllUser() {
return dao.queryAllUser();
}
@Override
public User qeryAllUserById(String id) {
return dao.qeryAllUserById(id);
}
}
- Controller层
package com.bj.sh.controller;
import com.bj.sh.Service.UserService;
import com.rj.bd.prop.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* @author LXYa
* @desc 8001项目的C层
* @time 2021-05-02-16:26
*/
@RestController
public class UserController {
@Autowired
UserService service;
//查询全部
@GetMapping("list/user")
public List<User>qeryAllUser(){
return service.qeryAllUser();
}
//查询一条
@GetMapping("list/ById/{id}")
public User qeryAllUserById(@PathVariable("id") String id){
return service.qeryAllUserById(id);
}
}
- 启动类
package com.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author LXY
* @desc
* @time 2022--12--03--17:11
*/
@SpringBootApplication
public class SpringCloud_8001 {
public static void main(String[] args) {
SpringApplication.run(SpringCloud_8001.class,args);
}
}
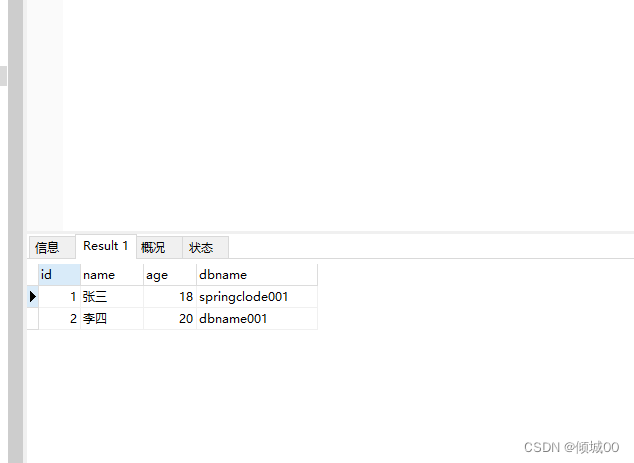
8 数据库
2.4 RestTemplate
RestTemplate: RestTemplate是Spring3.x之后提供的用于发送HTTP请求的客户端工具,它遵循Restful原则,RestTemplate默认依赖JDK的Http连接工具HttpUrlConnection
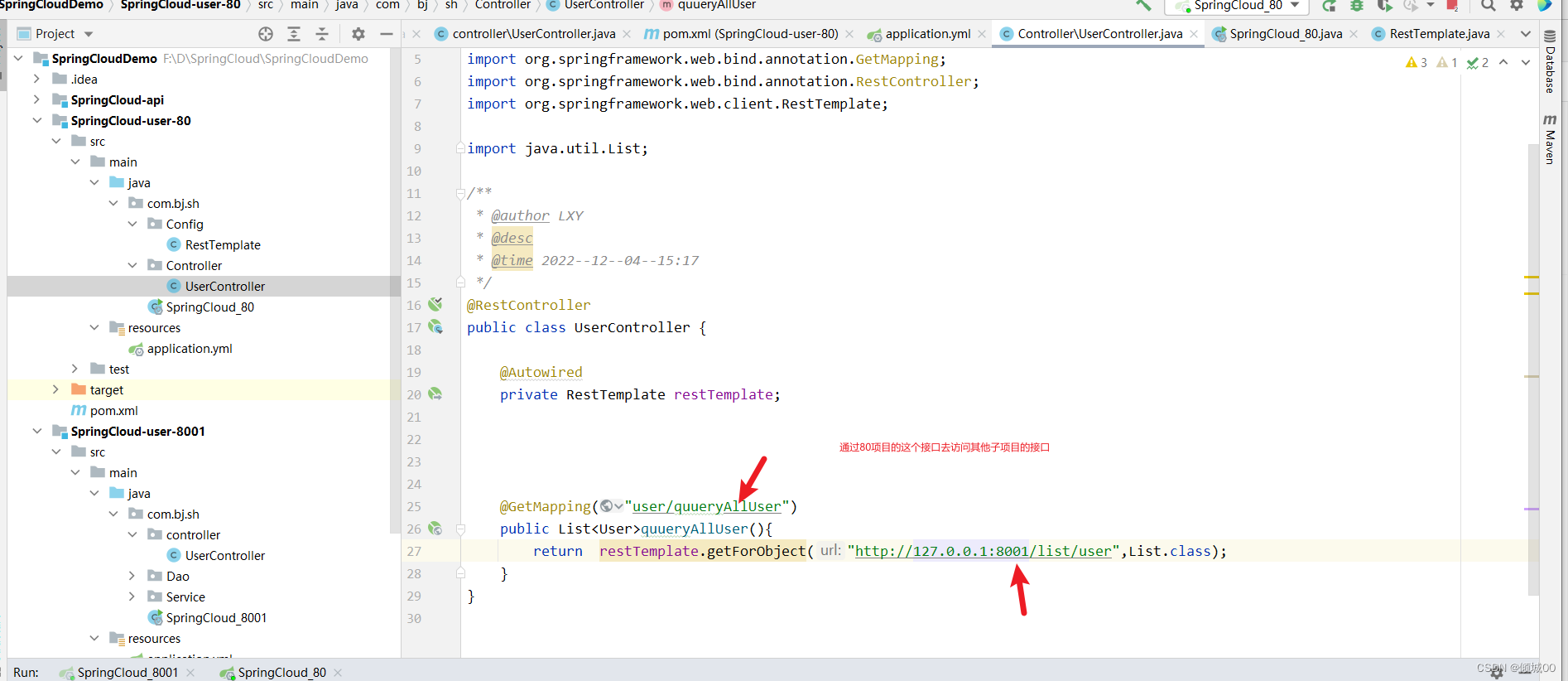
- 创建SpringCloud-user-80项目,也是消费端,但是意义不同的是80这个项目通过RestTemplate类去调用8001这个项目的接口
- pom
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.bj.sh.pojo.User</groupId>
<artifactId>SpringCloud-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
- c层
package com.bj.sh.Controller;
import com.rj.bd.prop.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import java.util.List;
/**
* @author LXY
* @desc
* @time 2022--12--04--15:17
*/
@RestController
public class UserController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("user/quueryAllUser")
public List<User>quueryAllUser(){
return restTemplate.getForObject("http://127.0.0.1:8001/list/user",List.class);
}
}
- 启动类
package com.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author LXY
* @desc
* @time 2022--12--04--15:20
*/
@SpringBootApplication
public class SpringCloud_80 {
public static void main(String[] args) {
SpringApplication.run(SpringCloud_80.class,args);
}
}
- config配置文件
package com.bj.sh.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author LXY
* @desc
* @time 2022--12--04--15:22
*/
@Configuration
public class RestTemplate {
@Bean
public org.springframework.web.client.RestTemplate getRestTemplate(){
return new org.springframework.web.client.RestTemplate();
}
}
三:注册中心:Eureka
- Eureka 是“活动中心”,Eureka的2.x停止更新了,但是后面会有替代的办法
- Eureka是Netflix开源的一个RESTful服务,主要用于服务的注册发现。Eureka由两个组件组成:Eureka服务器/端和Eureka客户端。Eureka服务器用作服务注册服务器
- 我们可以将8001的这个项目注册到eureka上,然后让80通过服务名去调用8001的接口
- 创建springcloud-eureka-7001项目,作为Eureka的服务端
3.1 eureka的服务端代码实现
- pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
- application.yml
server:
port: 7001
eureka:
instance:
hostname: 127.0.0 # Eureka服务端的主机,
client:
register-with-eureka: false #是否要向Eureka注册中心注册自己,自己是服务端,所以设定为false意味着不需要
fetch-registry: false #true表示客户端,false是注册中心服务端,单注册中心的时候就为false,集群注册中心的时候就要为true
service-url: #注册中心监控页面的网址
defaultZone: http://127.0.0.1:7001/eureka/
- 启动类
package com.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
/**
* @author LXY
* @desc
* @time 2022--12--04--16:04
*/
@SpringBootApplication
@EnableEurekaServer //启动Eureka-server,即开启注册中心的功能
public class SpringCloud_eureka7001 {
public static void main(String[] args) {
SpringApplication.run(SpringCloud_eureka7001.class,args);
}
}
-启动服务端 浏览器输入127.0.0.1:7001
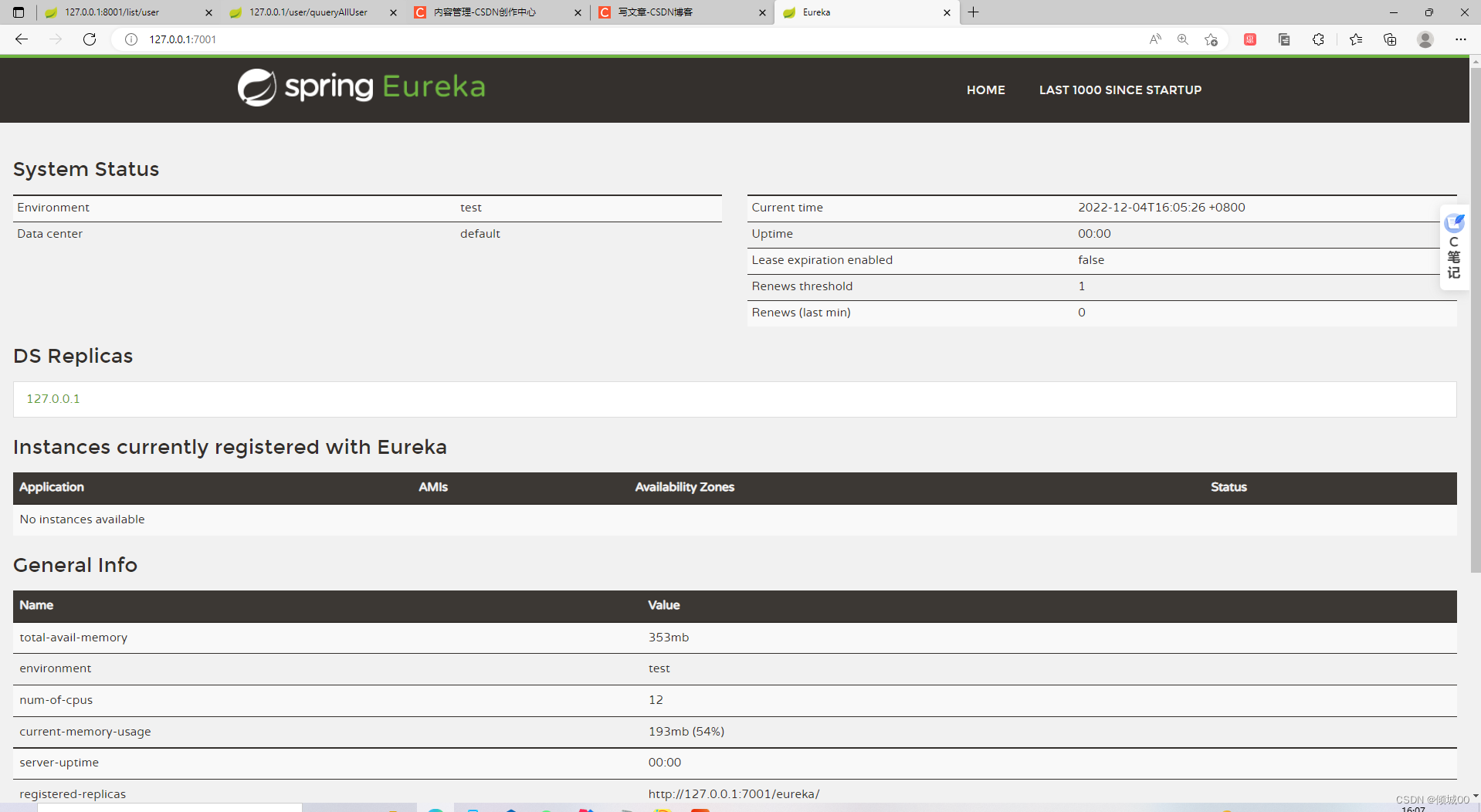
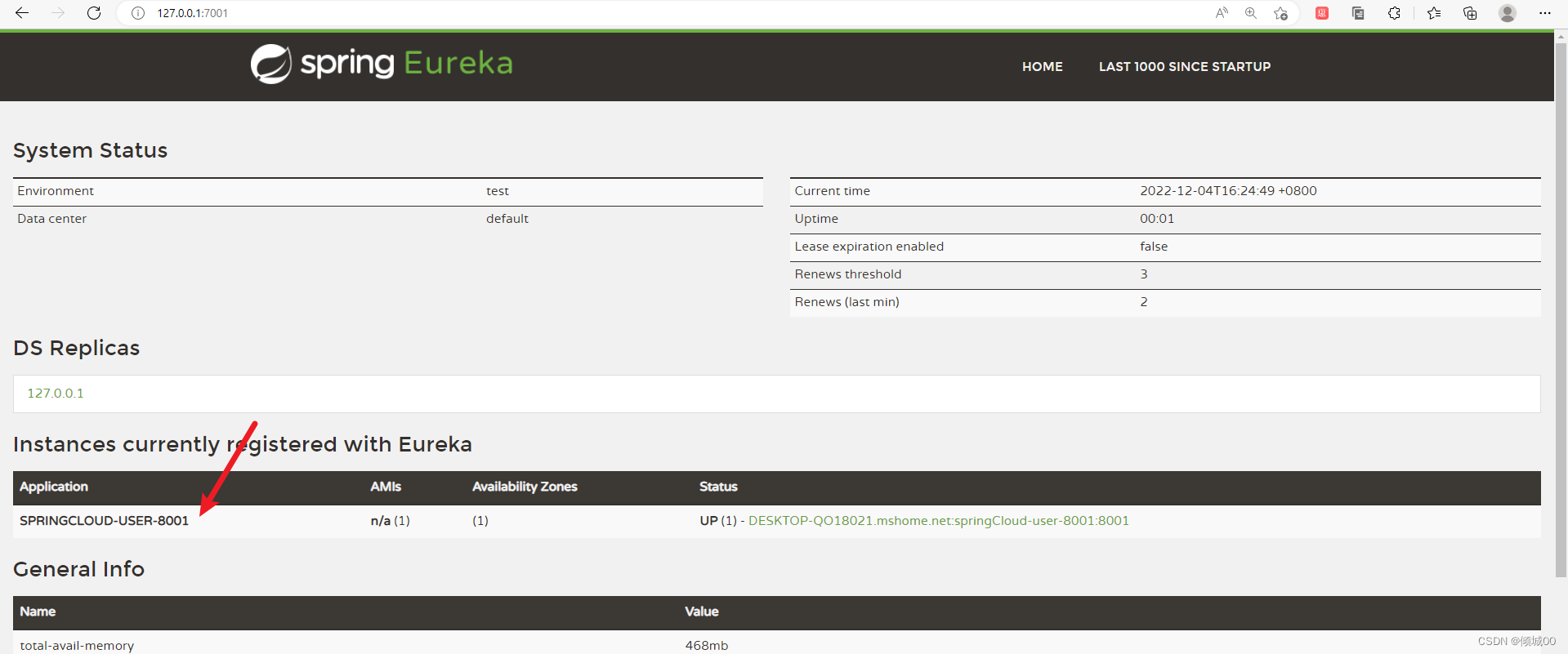
3.2 注册服务到eureka上
- 将8001项目注册到eureake上
- 8001 pom文件新增
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
- application.yml 上新增
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:7001/eureka/
- 在启动类上新增
@EnableEurekaClient//启动eureka的客户端,目的是将当前这个8001的子项目以服务的方式注入到”eureka7001“中@EnableEurekaClient//启动eureka的客户端,目的是将当前这个8001的子项目以服务的方式注入到”eureka7001“中
- 访问网页
3.3 eureka的自我保护机制
eureka的自我保护机制:Eureka有自我保护机制,在默认的情况下,如果Eureka server 在一定的时候内,没有接受到某个微服务的心跳,就会注销该实例,默认时间是90秒。但是当网络发生故障的情况下,
微服务和EurekaServer就无法通讯,这样就很危险,因为微服务本身是健康的,此时不应该注销该服务,而EurekaServer通过注销该服务来达到自我保护机制,
当网络健康的时候,EurekaServer就会自动退出自我保护机制。在自我保护模式中,eurekaserver服务端会保护服务注册表中的信息,不再注销任何服务实例,
当它收到的心跳数重新恢复到阈值以上时,eurekaserver就会自动的退出自我保护模式。它的设计哲学就是宁可留着错误的服务注册信息,也不盲目草率的销毁
- eureka的自我保护机制的目的:使用自我保护模式,可以让eureka(集群)更加的健壮和稳定(不用频繁的停止和重启erueka server服务端)
- 关闭eureka的自我保护机制:我们可以在springcloud-eureka-7001的配置文件application.yml中,通过eureka.server.enable-self-preservation: false ,但是不推荐这样使用
3.4 Eureka的健壮性和容错性的三大保障
- Eureka的健壮性和容错性的三大保障:服务下线,失效剔除,自我保护
- 服务下线
- 我们在正常关闭服务节点的情况下,Eureka Client会通过PUT请求方式调用Eureka Server的REST访问节点/eureka/apps/{appID}/{instanceID}/status?value=DOWN请求地址,
- 告知Eureka Server我要下线了,Eureka Server收到请求后会将该服务实例的运行状态由UP修改为DOWN,这样我们在管理平台服务列表内看到的就是DOWN状态的服务实例
自我保护机制:当服务没有按每30S按时发请求时,Eureka将会统计15分钟内心跳的请求成功概率,如果低于85%则可能服务提供方有延迟问题或者网络故障,这样会将服务提供方保护起来不会剔除。 - 剔除服务机制:Eureka Server在启动完成后会创建一个定时器每隔60秒检查一次服务健康状况,如果其中一个服务节点超过90秒未检查到心跳,那么Eureka Server会自动从服务实例列表内将该服务剔除
3.5 Eureka完善监控信息
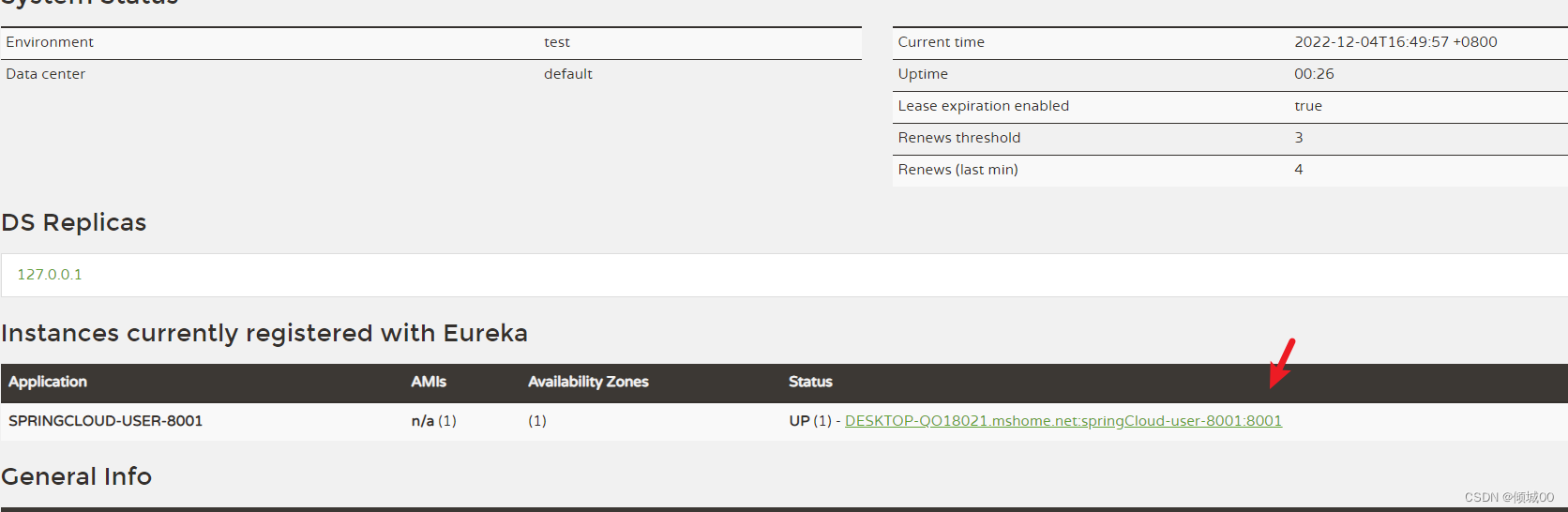
- 微服务项目可能会有很多的子模块,每个子模块有可能都是不同的人来写的,所以我们需要知道这个模块的是哪个人写的
- 在8001上新增pom
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
-在8001的application.yml上新增
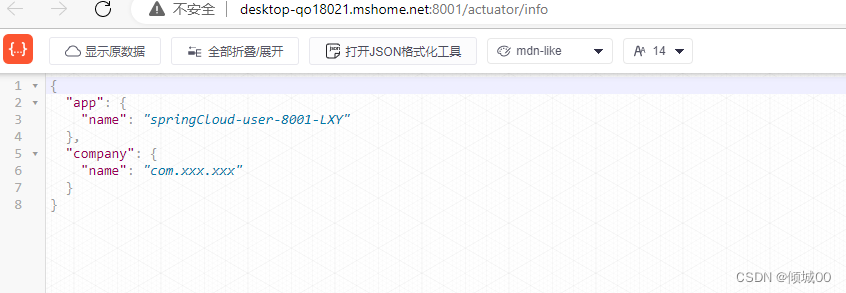
info:
app.name: springCloud-user-8001-LXY #显示的应用的名字
company.name: com.xxx.xxx #公司的名字
- 再次点击就会显示出信息
3.6 Eureka 服务的发现
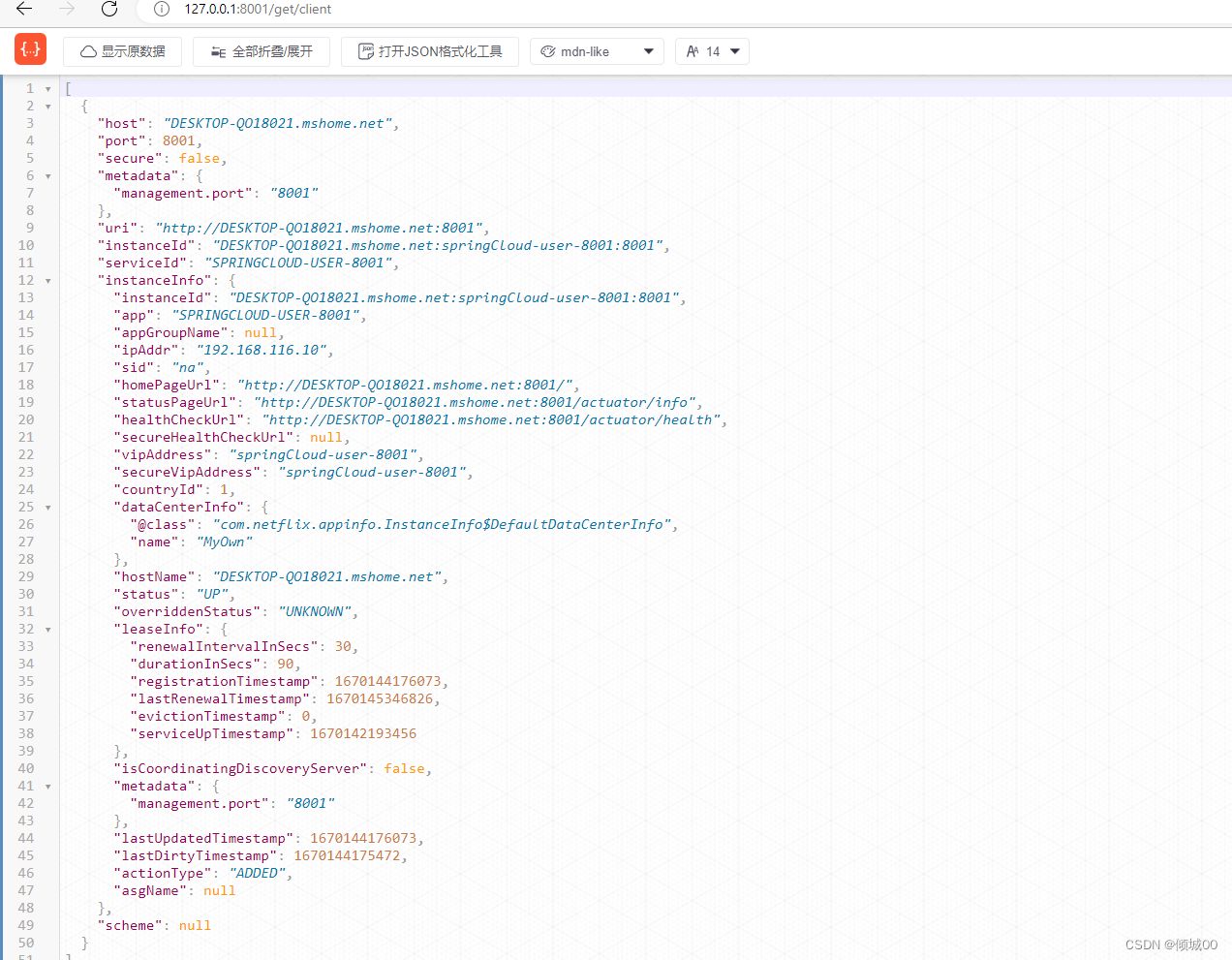
那么我们此时已经注册到eureka server注册中心的服务该怎么发现呢?其实是将来依靠ribbon+fegin来实现注册的服务的发现,除了这两种方式还有一种方式可以
- 在8001的UserController上
@Autowired
DiscoveryClient client;
@GetMapping("get/client")
public Object queryDiscoveryClient(){
List<ServiceInstance> instances = client.getInstances("SPRINGCLOUD-USER-8001");
return instances;
}
- 在8001的启动类上添加注解
@EnableDiscoveryClient //服务的发现
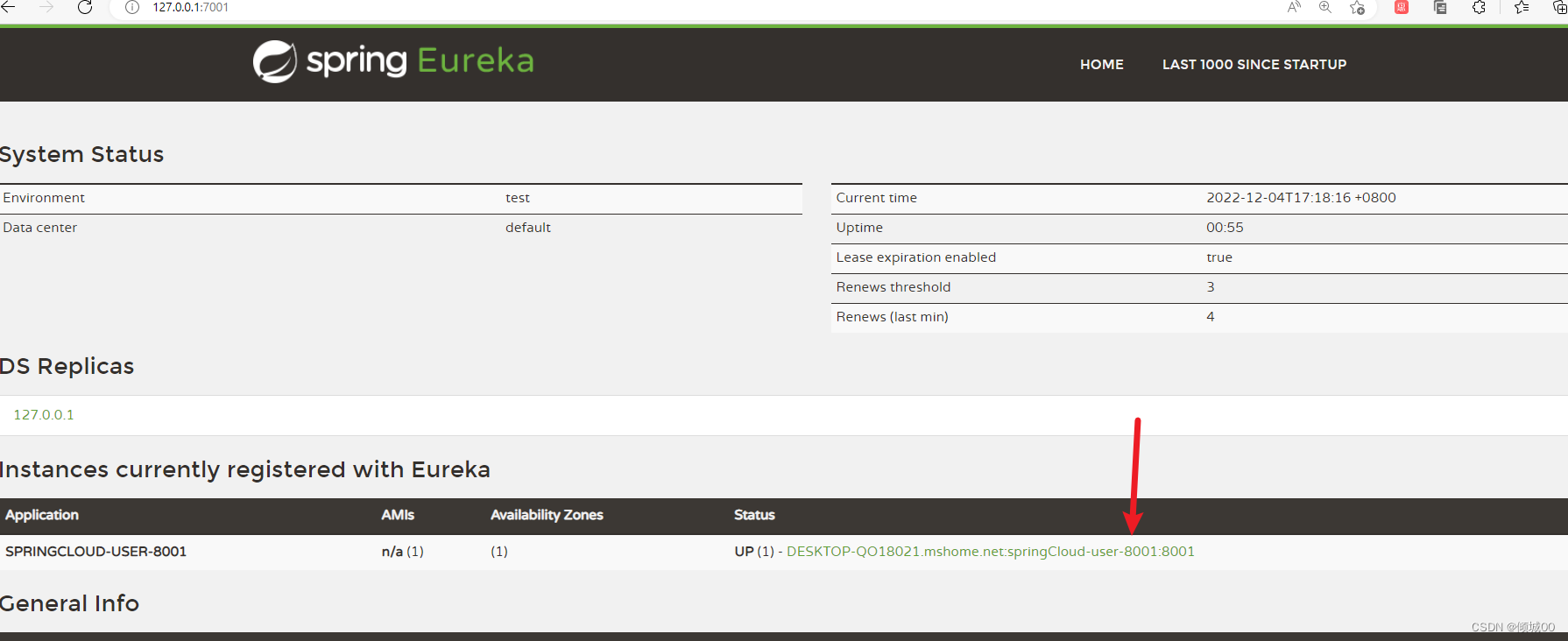
3.7 修改Eureka上的默认的状态名字
- 在8001上新增
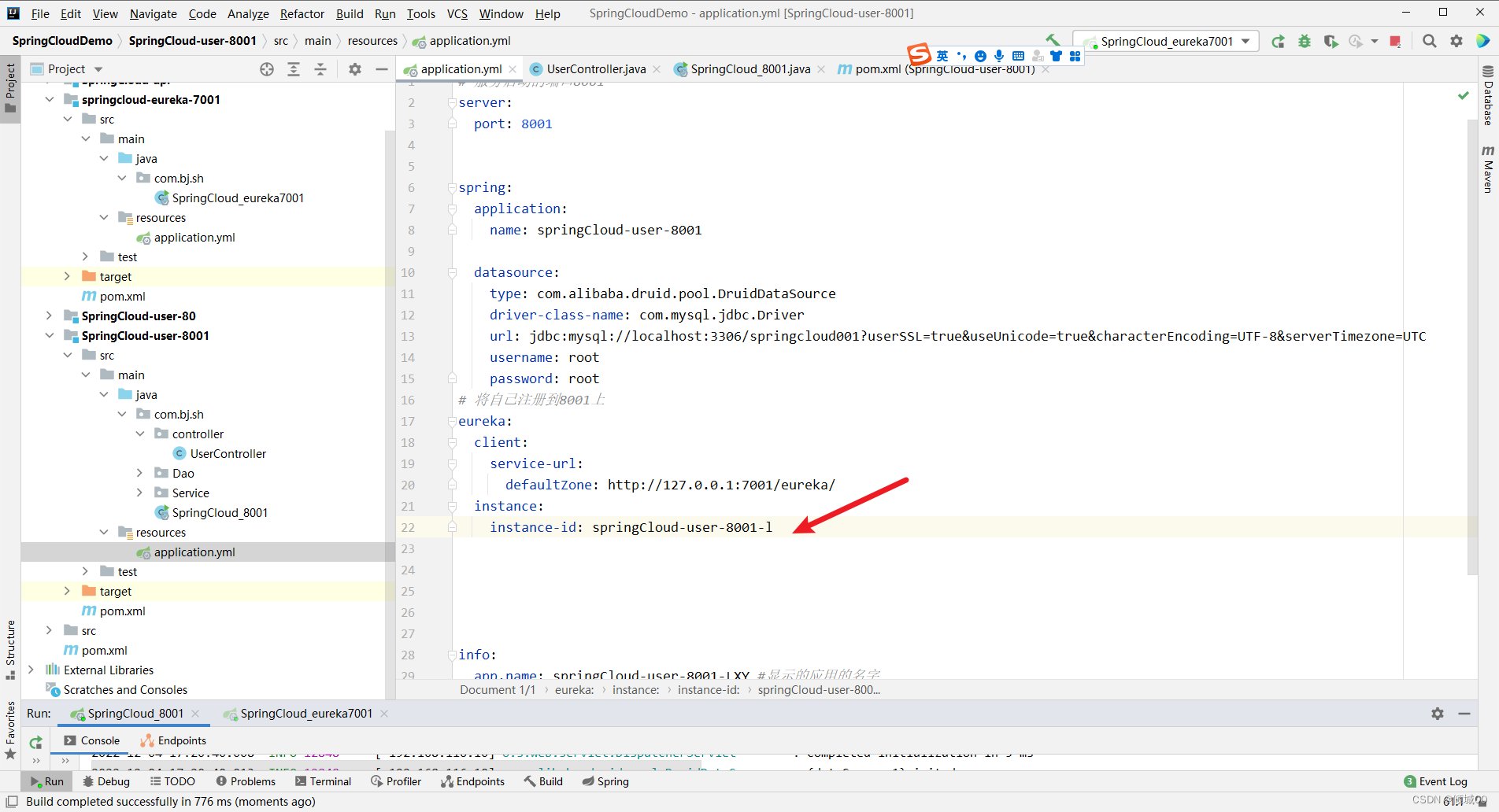
instance:
instance-id: springCloud-user-8001-l
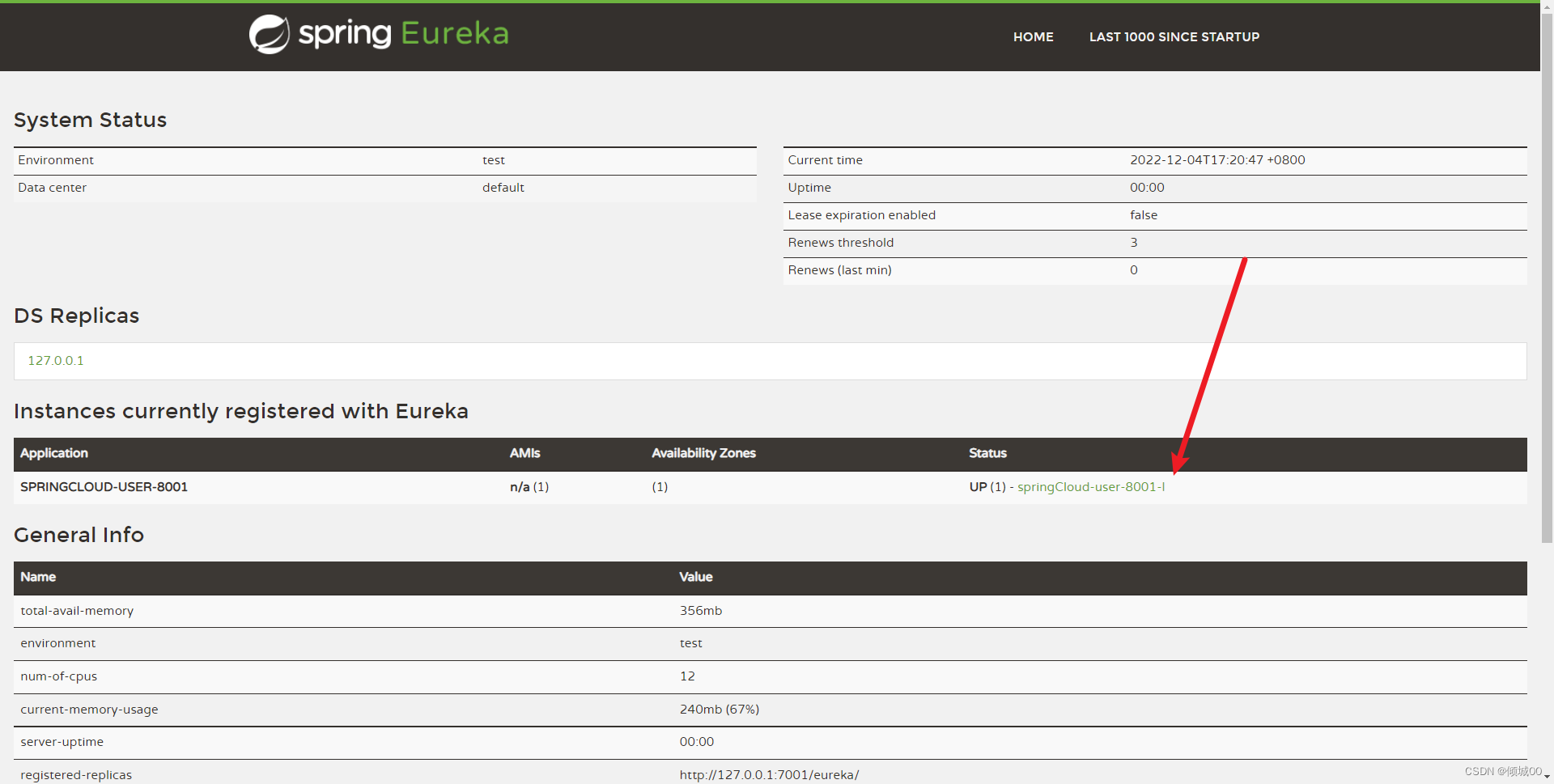
3.8 Eureka的集群
- 集群前提时不时一个电脑,因为我在一个电脑上跑的,所以在
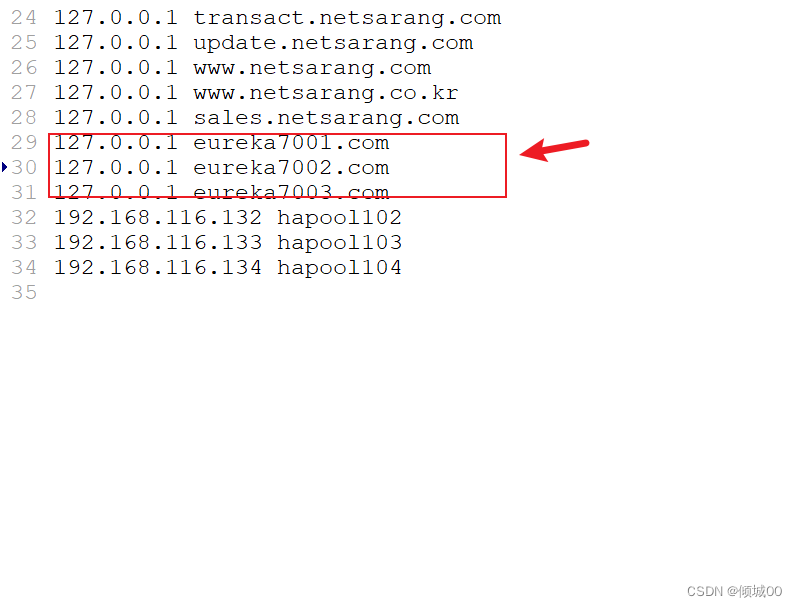
C:\Windows\System32\drivers\etc里面修改hosts文件,在文件的末尾添加下面几行 - 模拟这是3台电脑
127.0.0.1 eureka7001.com
127.0.0.1 eureka7002.com
127.0.0.1 eureka7003.com
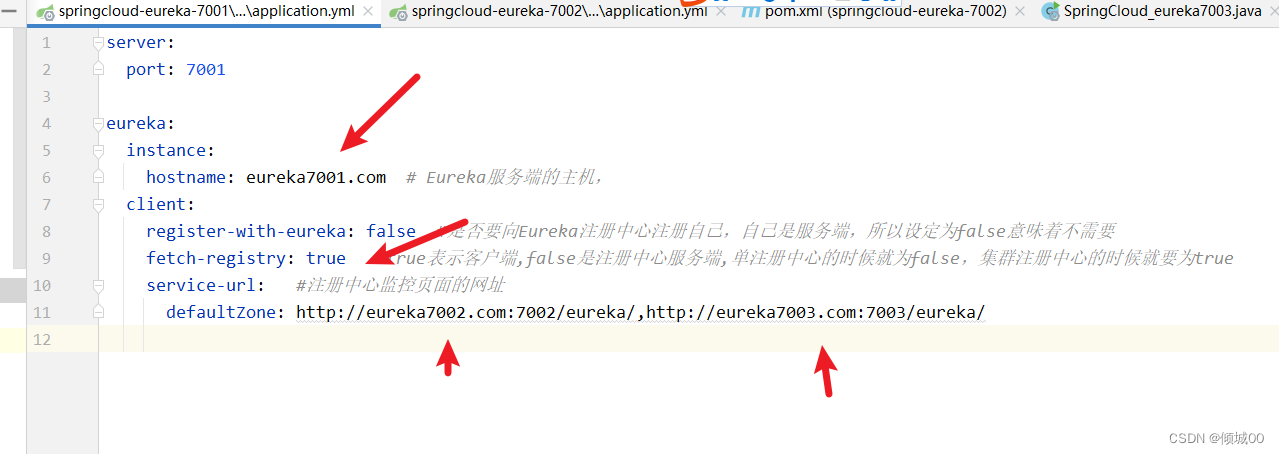
- 在7001上修改配置文件
server:
port: 7001
eureka:
instance:
hostname: eureka7001.com # Eureka服务端的主机,
client:
register-with-eureka: false #是否要向Eureka注册中心注册自己,自己是服务端,所以设定为false意味着不需要
fetch-registry: true #true表示客户端,false是注册中心服务端,单注册中心的时候就为false,集群注册中心的时候就要为true
service-url: #注册中心监控页面的网址
defaultZone: http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
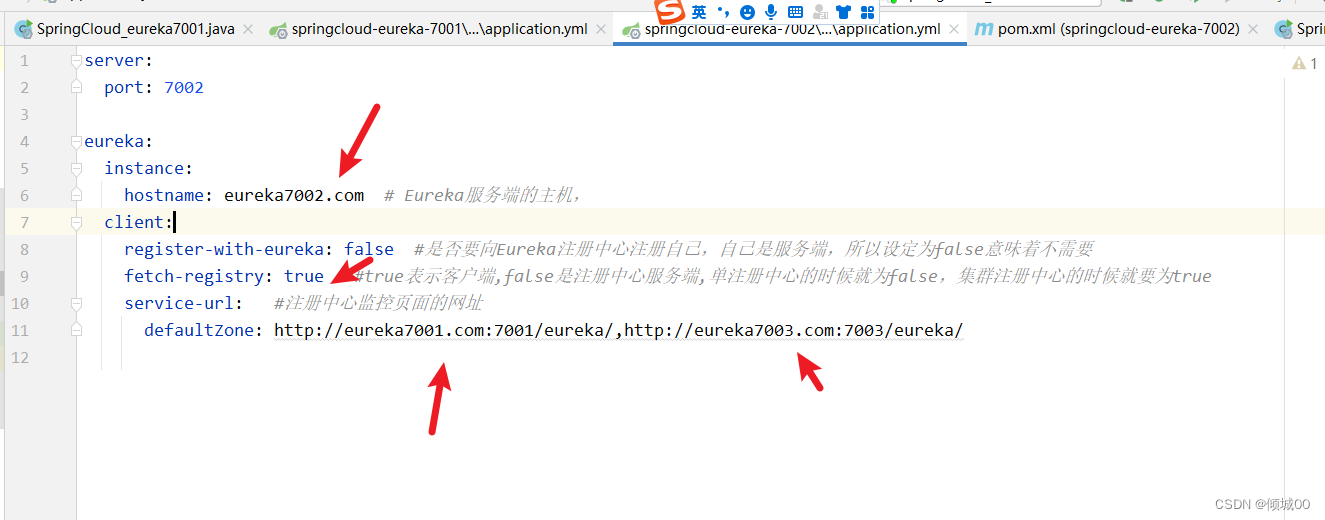
- 新建SpringCloud_eureka7002子项目,就是我们集群的第二个eureka
- pom
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
</dependencies>
- yml文件中
server:
port: 7002
eureka:
instance:
hostname: eureka7002.com # Eureka服务端的主机,
client:
register-with-eureka: false #是否要向Eureka注册中心注册自己,自己是服务端,所以设定为false意味着不需要
fetch-registry: true #true表示客户端,false是注册中心服务端,单注册中心的时候就为false,集群注册中心的时候就要为true
service-url: #注册中心监控页面的网址
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7003.com:7003/eureka/
- 启动类
package com.bd.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
/**
* @author LXY
* @desc
* @time 2022--12--04--16:04
*/
@SpringBootApplication
@EnableEurekaServer //启动Eureka-server,即开启注册中心的功能
public class SpringCloud_eureka7002 {
public static void main(String[] args) {
SpringApplication.run(SpringCloud_eureka7002.class,args);
}
}
- 新建SpringCloud_eureka7003子项目,就是我们集群的第三个eureka
- pom
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
</dependencies>
- yml文件中
server:
port: 7003
eureka:
instance:
hostname: eureka7003.com # Eureka服务端的主机,
client:
register-with-eureka: false #是否要向Eureka注册中心注册自己,自己是服务端,所以设定为false意味着不需要
fetch-registry: true #true表示客户端,false是注册中心服务端,单注册中心的时候就为false,集群注册中心的时候就要为true
service-url: #注册中心监控页面的网址
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/
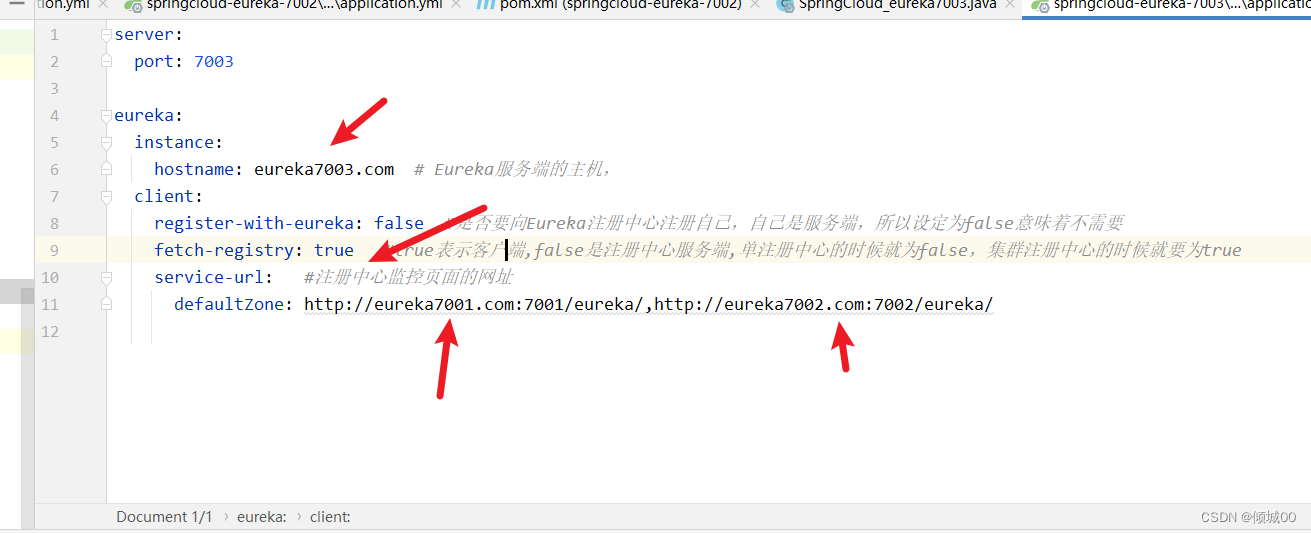
- 启动类
package com.bd.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
/**
* @author LXY
* @desc
* @time 2022--12--04--16:04
*/
@SpringBootApplication
@EnableEurekaServer //启动Eureka-server,即开启注册中心的功能
public class SpringCloud_eureka7003 {
public static void main(String[] args) {
SpringApplication.run(SpringCloud_eureka7003.class,args);
}
}
- 然后访问三个浏览器的页面
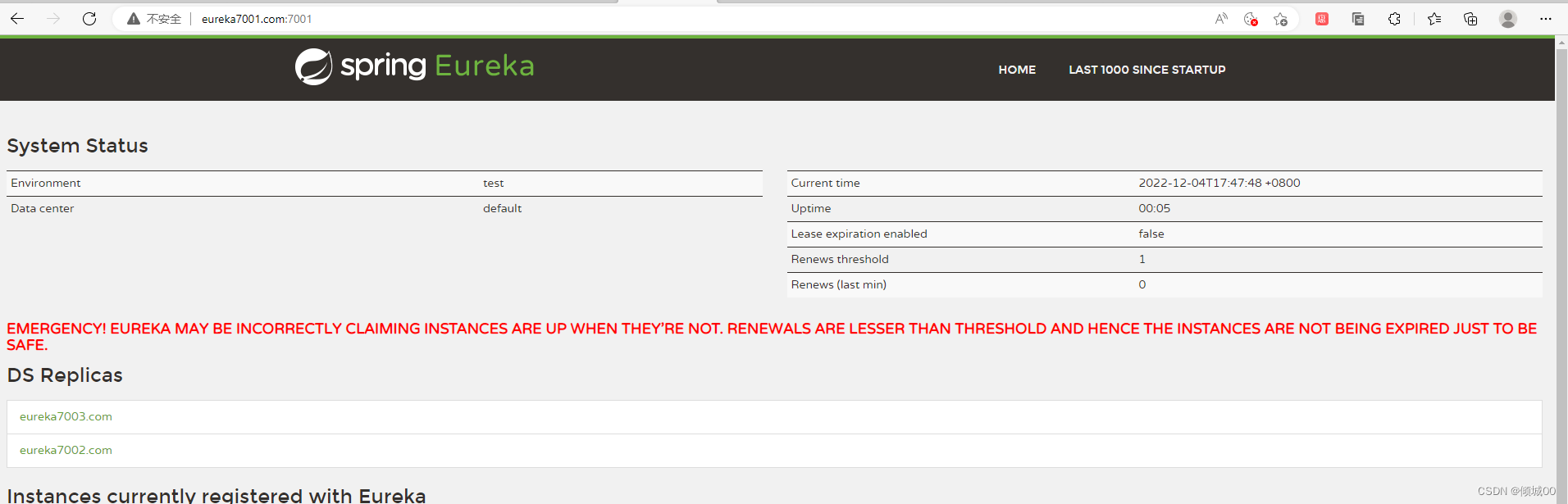
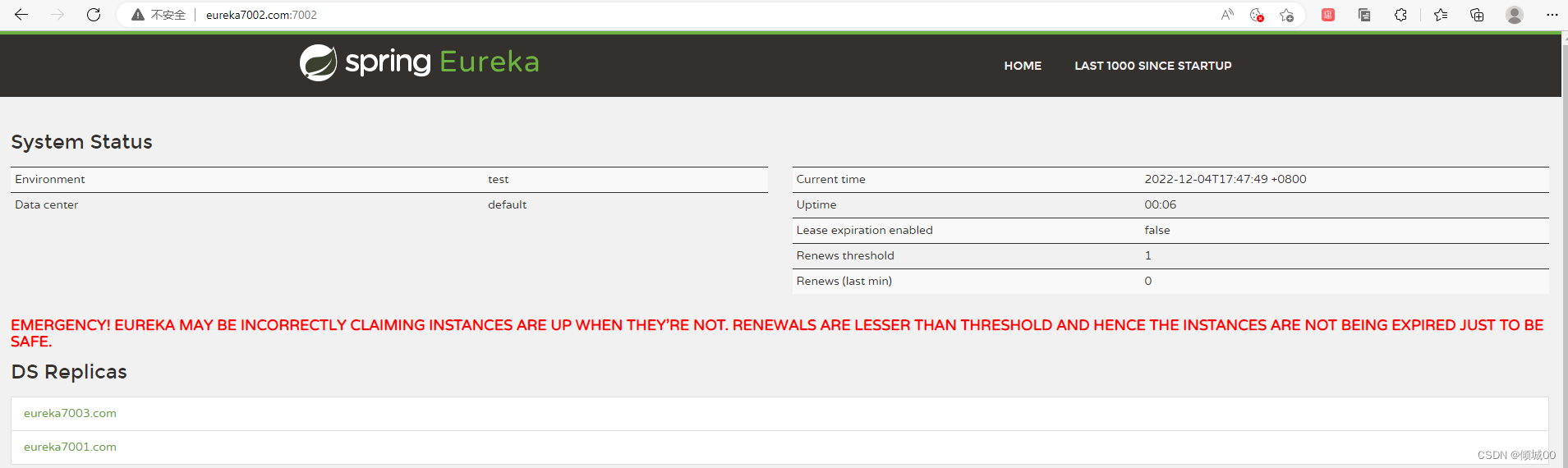
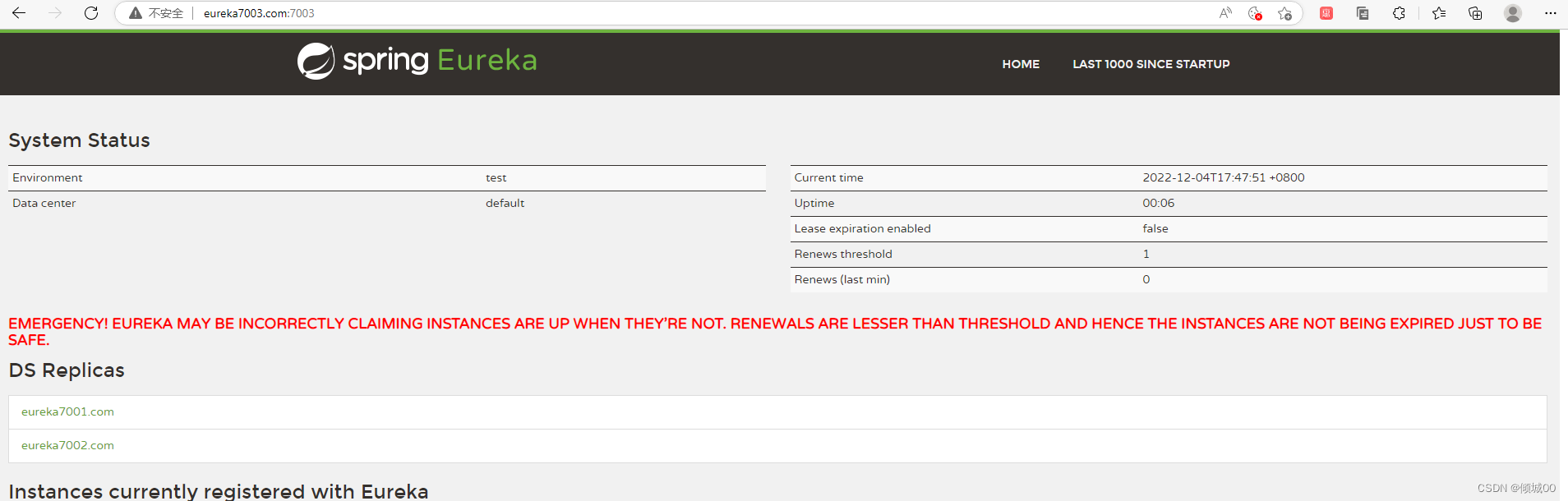
- 这个红色的就是上面说的eureka的自我保护机制,可以再yml中取消自我保护机制
3.9 将8001服务注册到集群中
-
在8001的yml文件修改
-
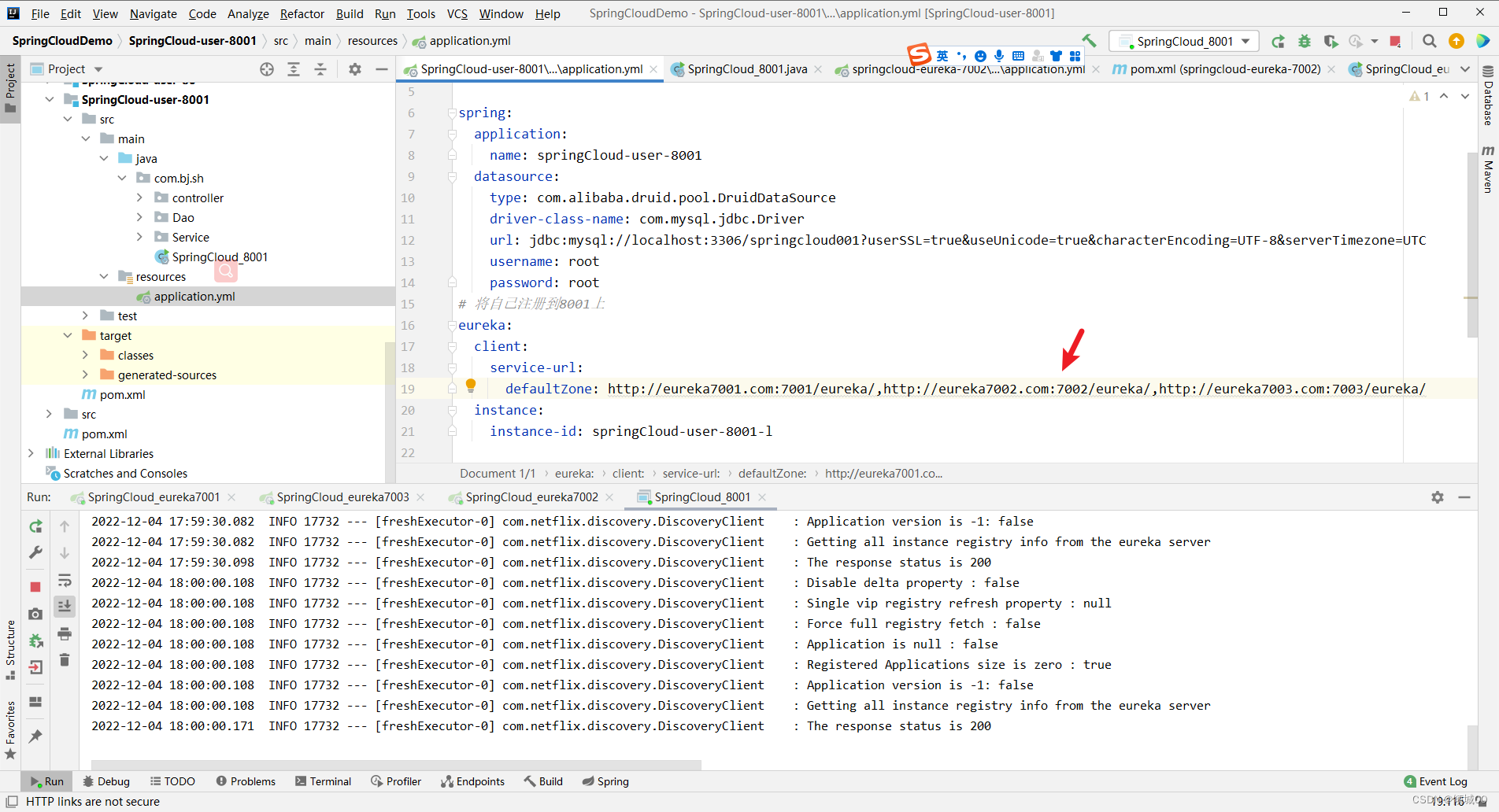
-
刷新网页就会注册上去

3.10 分布式系统的CAP原则
在分布式系统中有这样一个CAP原则,而这个又和eureka又有什么关系呢?
1.CAP原则:又称CAP定理,指的是在一个分布式系统中,强一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾
所以最终的结果就是:CP,AP,CA 这三种结果,那么这三种结果的组合又代表是什么意思呢
2.CAP三种组合结果的讲解:
1)CA:单点集群,满足一致性,可用性的系统,但是扩展性差(容错性差)
2)CP: 满足一致性,分区容错性,但是可用性差(也就是性能不是特别高)
3)AP: 满足可用性,分区容错性,但是强一致性差
3.正式有了CAP理论,在这样的一个背景下,我们的Eureka才诞生了,Eureka保证的AP(可用性+分区容错性)
4.Eureka是怎样保证/实现AP的呢?
Eureka各个节点都是平等的,任何一个节点挂掉是不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册时,如果
发现连接失败,则会自动切换至其他节点,只要有一台Eureka还在,就能保证注册服务的可用性,只不过查到的信息可能不是最新的,除此之外,Eureka还有一种自我保护机制,
踢出服务机制,服务下线等三大功能一起保证了Eureka的AP实现
5.扩展:Zookeeper是保证的Cp,那么ZK是怎么实现的呢?
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。
但是zk会出现这样-种情况, 当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30~120s,且选举期间整个zk集群都是不可用的,
这就导致在选举期间注册服务瘫痪。在云部署的环境下,因为网络问题使得zk集群失去master节点是较大概率会发生的事件,虽然服务最终能够恢复,但是漫长的选举时间导致
的注册长期不可用是不能容忍的。
6.ZK与Eureka的对比小结:
Eureka可以很好的应对网络故障导致的部分节点(可以7002,7003都宕机了,但是7001还可以正常工作)失去联系的情况,
而不会像ZK那样使得整个注册中心集群瘫痪(因为ZK是靠选举机制的,ZK集群中的节点是不平等的)
四: 负载均衡:Ribbon
- Ribbon是Netflix发布的开源项目, 主要功能是提供客户端的软件负载均衡算法(例如轮询,加权,随机等),将NetFlix的中间层服务连接在一起。Ribbon的客户端组件提供一系列完整的配置项如: 连接超时、重试等等。简单的说,就
是在配置文件中列出LoadBalancer (简称LB:负载均衡)后面所有的机器,Ribbon会 自动的帮助你基于某种规则(如简单轮询,随机连接等等)去连接这些机器。我们也很容易使用Ribbon实现自定义的负载均衡算法!
4.1 将80客户端实现负载均衡
- (1)需要将80客户端添加上eureak的依赖,将其注册到注册中心上
- (2)需要将80客户端添加上Ribbon的依赖,实现负载均衡
- 80 pom文件新增
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
<!--5.导入Ribbon的同时要导入erueka,因为它要发现服务从那里来(也就是需要将自己也注册到注册中心上)-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
- yml文件添加(将80注册到eureak中)
spring:
application:
name: SpringCloud-user-80
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: SpringCloud-user-80
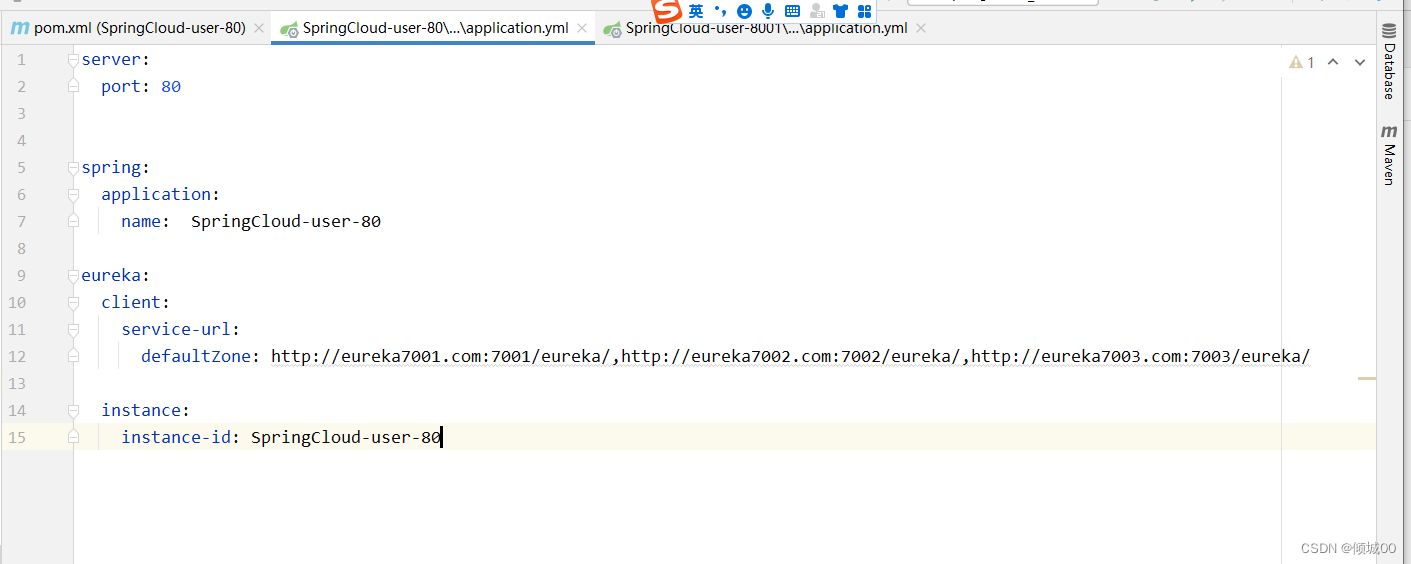
- 启动类添加@EnableEurekaClient
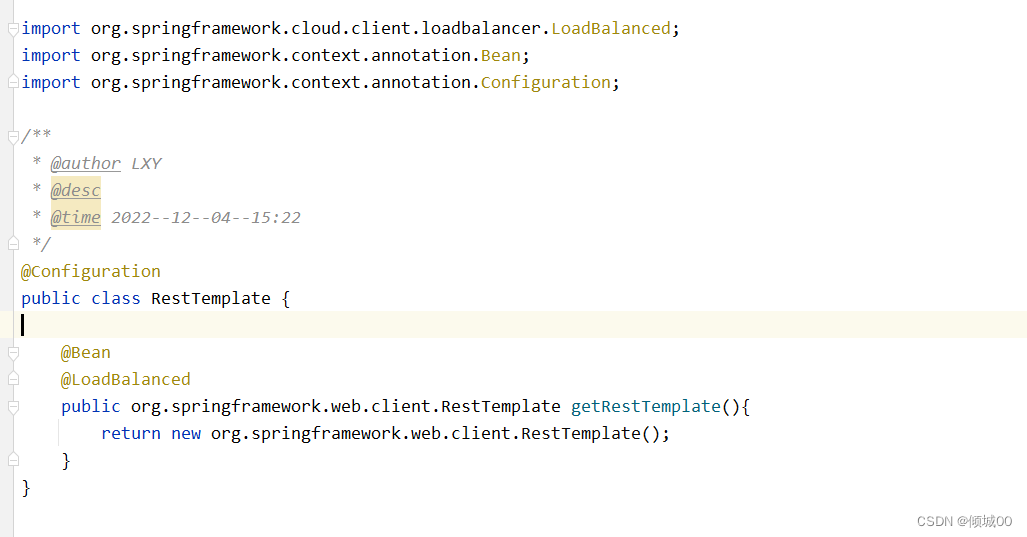
- 在config添加@LoadBalanced注解,这个是负载均衡的注解,如果不加的话是无法通过服务名去识别的
- 其实是因为我们当前客户端是通过RestTemplate实现的调用服务端,所以添加上@LoadBalanced就是可以实现RestTemplate的负载均衡。
- 改造一下c层
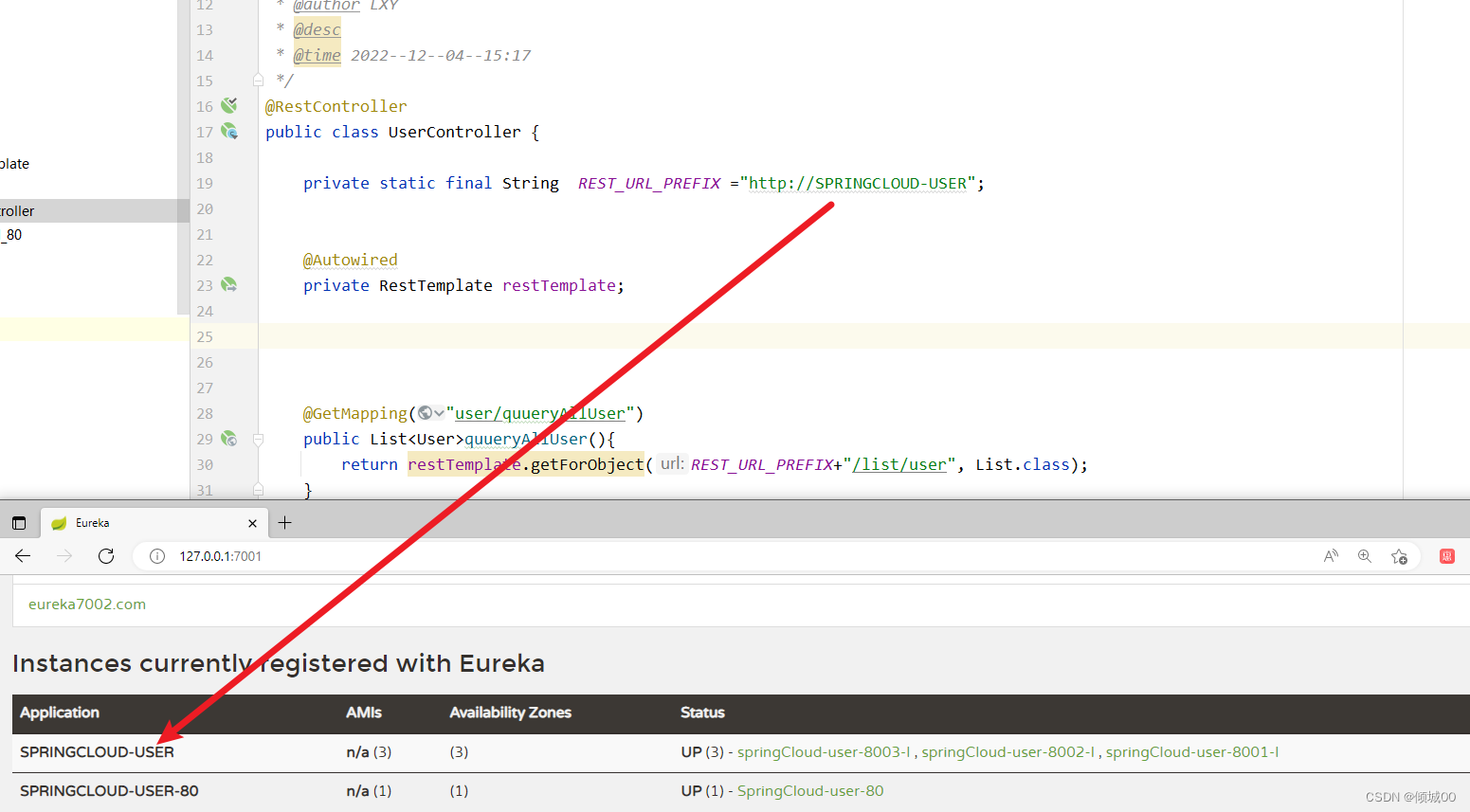
这样就实现了负载均衡了,但是一个8001的子项目体现不出来,所以需要在新增8002和8003两个相同的子项目
-
需要新增两个数据库
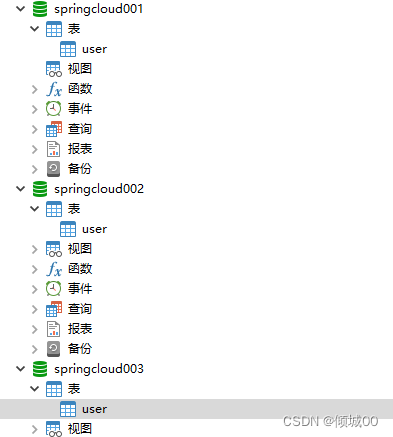
-8001 8002 8003连接不同的数据库 -
首先创建8002 项目名springCloud-user-8002
-
pom一样,其他的启动类啥的都一样
-
yml文件-端口不一样-数据库不一样,注册到euraker的id不一样
# 服务启动的端口8002
server:
port: 8002
spring:
application:
name: springCloud-user
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/springcloud002?userSSL=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
# 将自己注册到8001上
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: springCloud-user-8002-l
info:
app.name: springCloud-user-8002-LXY #显示的应用的名字
company.name: com.xxx.xxx #公司的名字
- 然后创建8003 项目名springCloud-user-8003
- pom一样,其他的启动类啥的都一样
- yml文件-端口不一样-数据库不一样,注册到euraker的id不一样
# 服务启动的端口8003
server:
port: 8003
spring:
application:
name: springCloud-user
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/springcloud003?userSSL=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
# 将自己注册到8001上
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: springCloud-user-8003-l
info:
app.name: springCloud-user-8003-LXY #显示的应用的名字
company.name: com.xxx.xxx #公司的名字
- 然后启动7001,7002,7003,8001,8002,8003,80这几个项目,然后访问浏览器
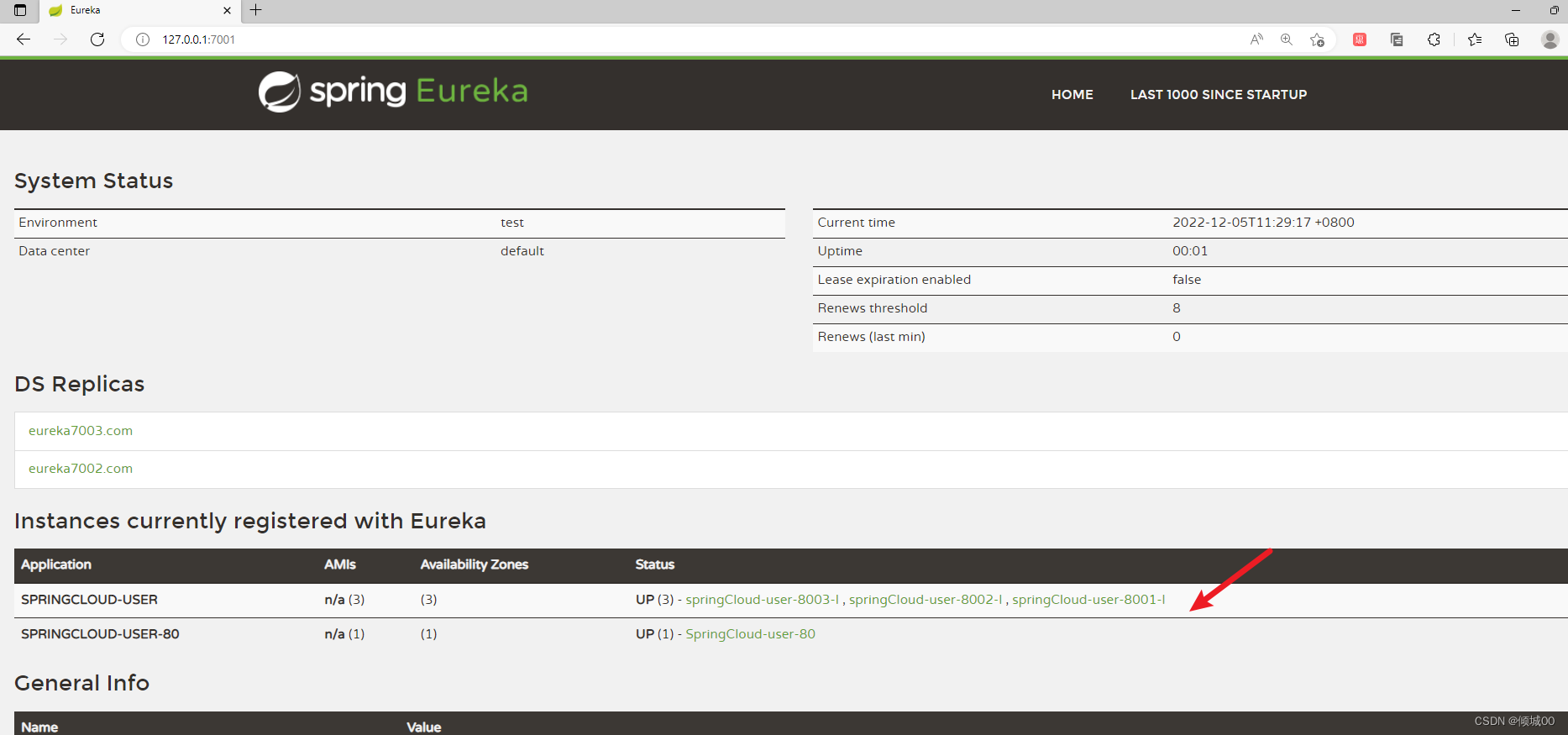
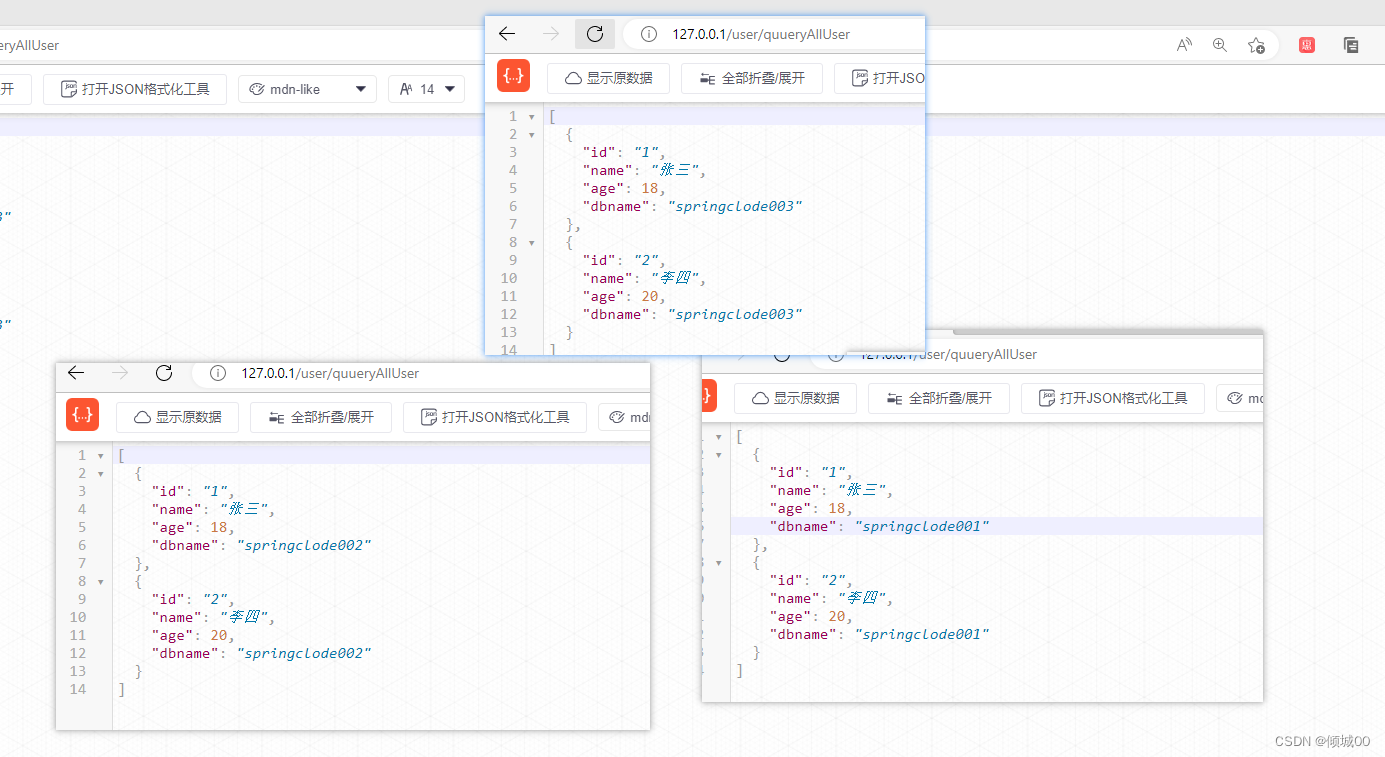
- 然后访问http://127.0.0.1/user/quueryAllUser
- 这是80通过restTemplate去负载均衡的调用8001-8002-8003这三个接口
- 每次刷新数据,都是轮训的访问这三个,这就实现了负载均衡
4.2 Ribbon 实现随机负载均衡
- IRule接口,是实现负载均衡的接口
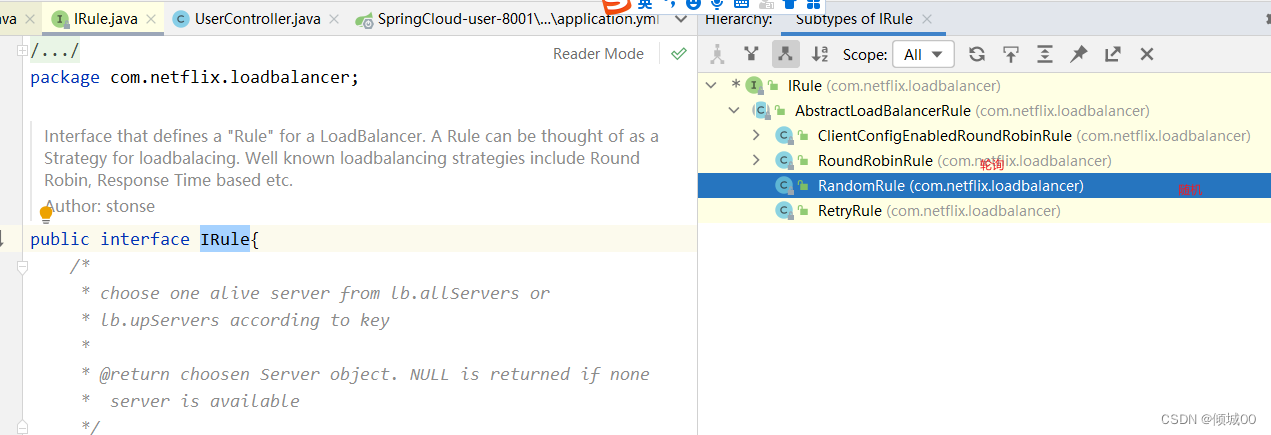
- 在配置文件新增,负载均衡的策略就变成了随机
五:客户端调用:Fegin
-
是一个声明式的伪Http客户端,它使得写Http客户端变得更简单。使用Feign,只需要创建一个接口并注解。
它具有可插拔的注解特性,可使用Feign 注解和JAX-RS注解。Feign支持可插拔的编码器和解码器。Feign默认集成了Ribbon,并和Eureka结合,默认实现了负载均衡的效果。 -
前面在使用Ribbon + RestTemplate时,利用RestTemplate对Http请求的封装处理, 形成了一套模板化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往一个接口会被多处调用,所以通常都会
针对每个微服务自行封装一些客户端类来包装这些依赖服务的调用。 所以, Feign在此基础上做了进一步封装,由他来帮助我们定义和实现依赖服务接口的定义,在Feign的实现下, 我们只需要创建一个接口并使用注解的方式
来配置它(类似于以前Dao接口上标注Mapper注解,现在是一个微服务接口上面标注一-个Feign注解即可。)即可完成对服务提供方的接口绑定,简化了使用Spring Cloud Ribbon时,自动封装服务调用客户端的开发量。 -
创建一个 Springcloud-user-fegin-8008 项目
-
pom
<dependencies>
<!--1.web处理的(Spring+springmvc)-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--2.热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
</dependency>
<!--3.实体类-->
<dependency>
<groupId>com.bj.sh.pojo.User</groupId>
<artifactId>SpringCloud-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<!--4.eureka(ribbon要是使用必须要有eureka环境)-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
<!--5.ribbon(fegin要想使用必须要有ribbon)-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
<!--6.feign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-feign</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
</dependencies>
- UserService 通过服务名+请求的URL去调用接口
package com.bj.sh.Service;
import com.rj.bd.prop.User;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import java.util.List;
/**
* @author LXY
* @desc
* @time 2022--12--05--12:50
*/
@FeignClient("SPRINGCLOUD-USER")
public interface UserService {
@GetMapping("list/user")
List<User> qeryAllUser();
//查询一条
@GetMapping("list/ById/{id}")
User qeryAllUserById(@PathVariable("id") String id);
}
- c层
package com.bj.sh.Controller;
import com.bj.sh.Service.UserService;
import com.rj.bd.prop.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import java.util.List;
/**
* @author LXY
* @desc
* @time 2022--12--04--15:17
*/
@RestController
public class UserController {
@Autowired
private UserService service;
@GetMapping("user/quueryAllUser")
public List<User>quueryAllUser(){
return service.qeryAllUser();
}
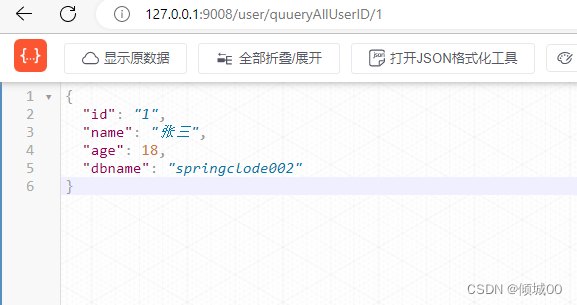
@GetMapping("user/quueryAllUserID/{id}")
public User quueryAllUser(@PathVariable ("id") String id){
return service.qeryAllUserById(id);
}
}
- 启动类
package com.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
/**
* @author LXY
* @desc
* @time 2022--12--04--15:20
*/
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
public class SpringCloud_8008 {
public static void main(String[] args) {
SpringApplication.run(SpringCloud_8008.class,args);
}
}
- yml文件
server:
port: 8008
spring:
application:
name: SpringCloud-user-fegin8008
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: SpringCloud-user-fegin8008
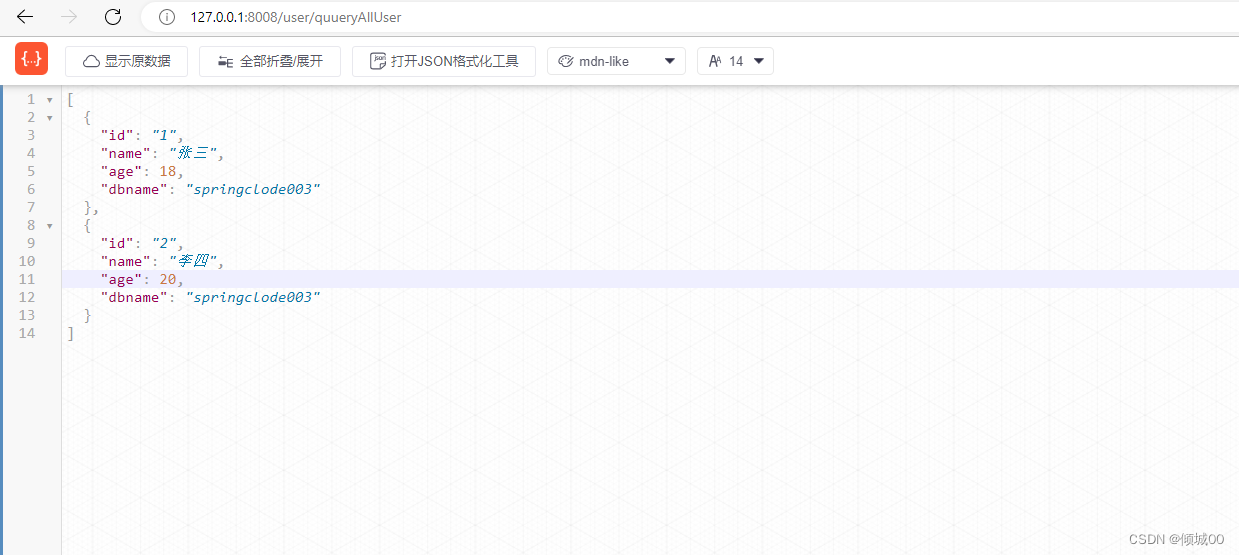
- 通过访问fegin的接口去通过服务名调用8001-8002-8003的接口,默认是轮训调用的
5.1 Fegin与RestTemplate的区别
-
RestTemplate的的使用方式:
直接只用RestTemplate 方式调用,url写死,例如:String msg =restTemplate.getForObject(“http://localhost:8080/server/msg”,String.class);
RestTemplate t 通过应用名方式调用 例如:restTemplate.getForObject(REST_URL_PREFIX+“/user/list”, List.class); private static final String REST_URL_PREFIX = “http://SPRINGCLOUD-PROVIDER-USER”; -
Fegin的使用方式:
直接在M层接口上添加上@FeginClient即可: 例如:@FeignClient(“SPRINGCLOUD-PROVIDER-USER”) -
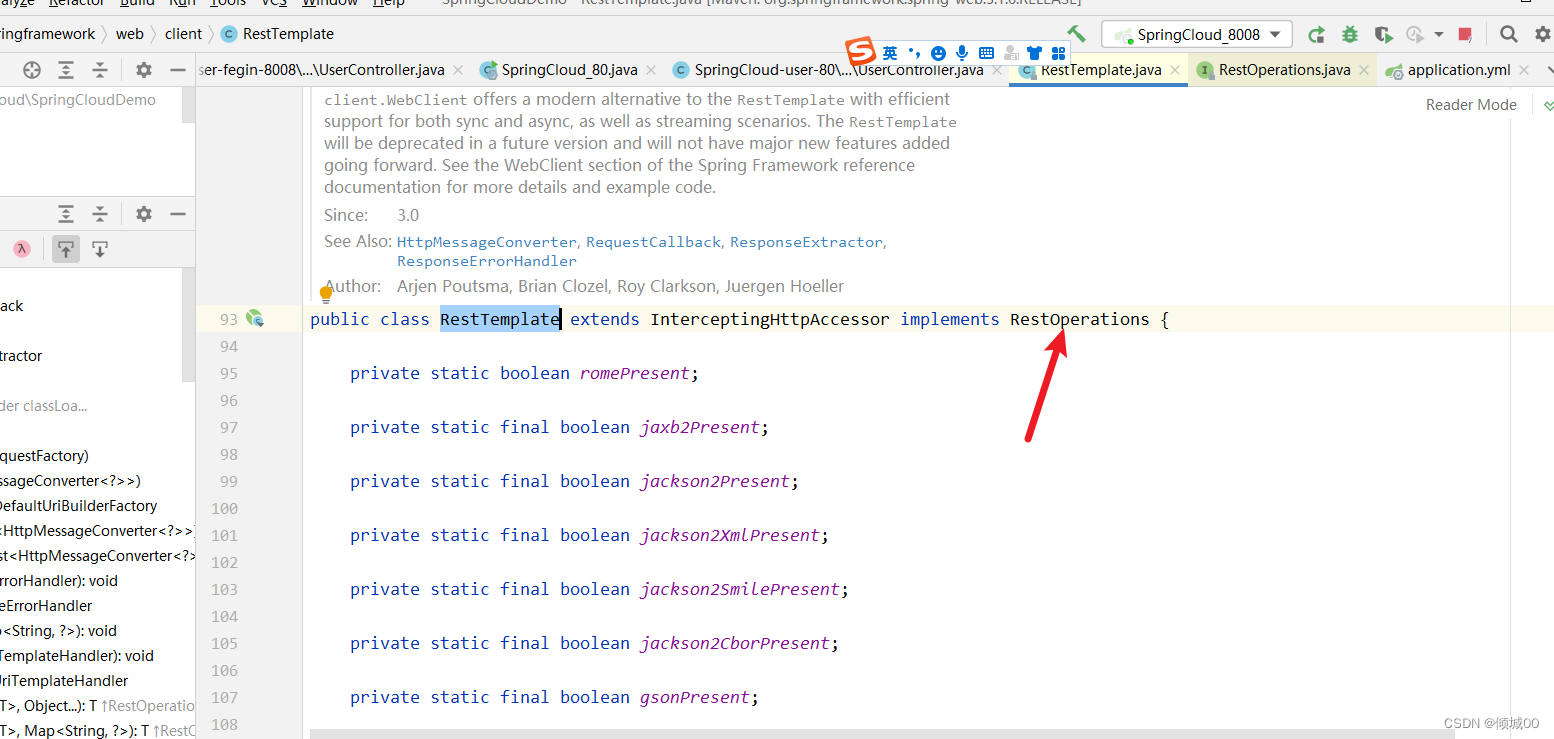
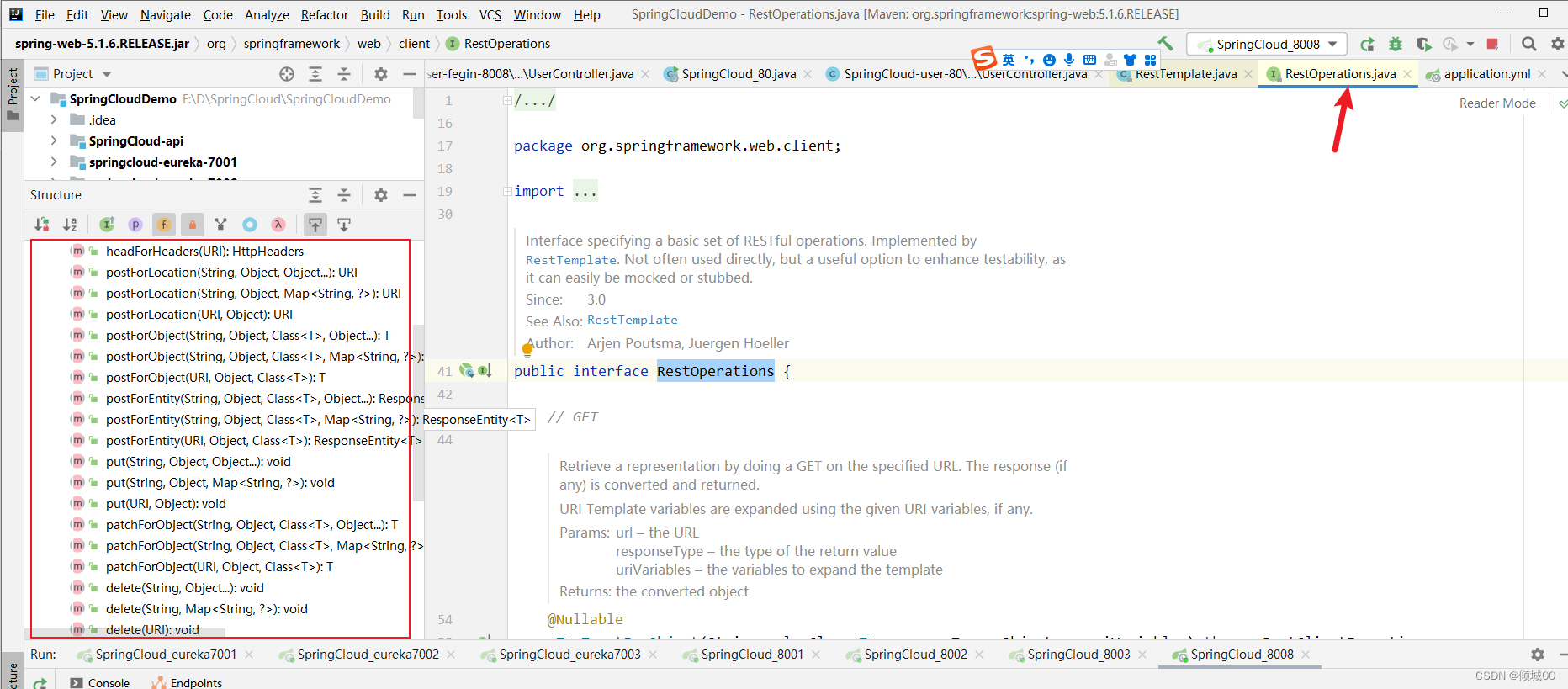
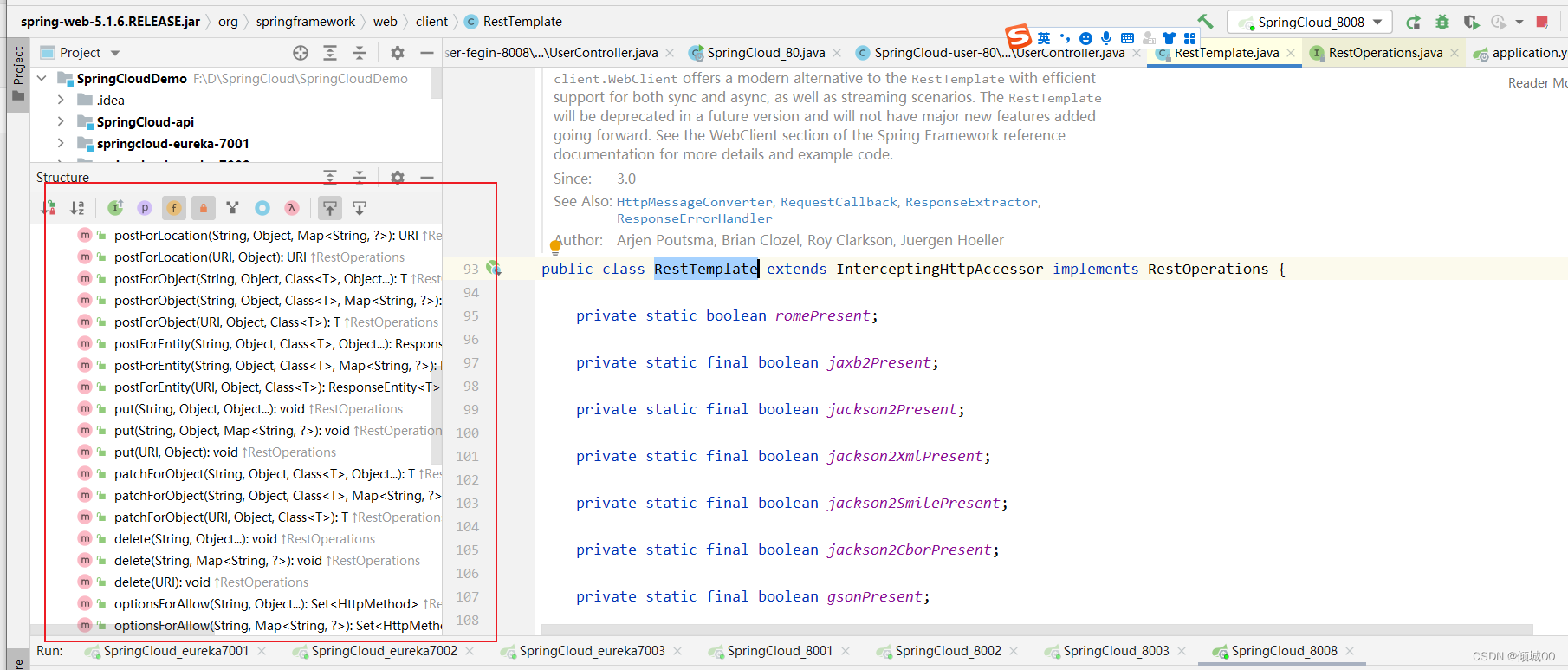
RestTemplate
-
RestTemplate的底层实现是继承自 InterceptingHttpAccessor 并且实现了 RestOperations 接口,其中 RestOperations 接口定义了基本的 RESTful 操作,这些操作在 RestTemplate 中都得到了实现
-
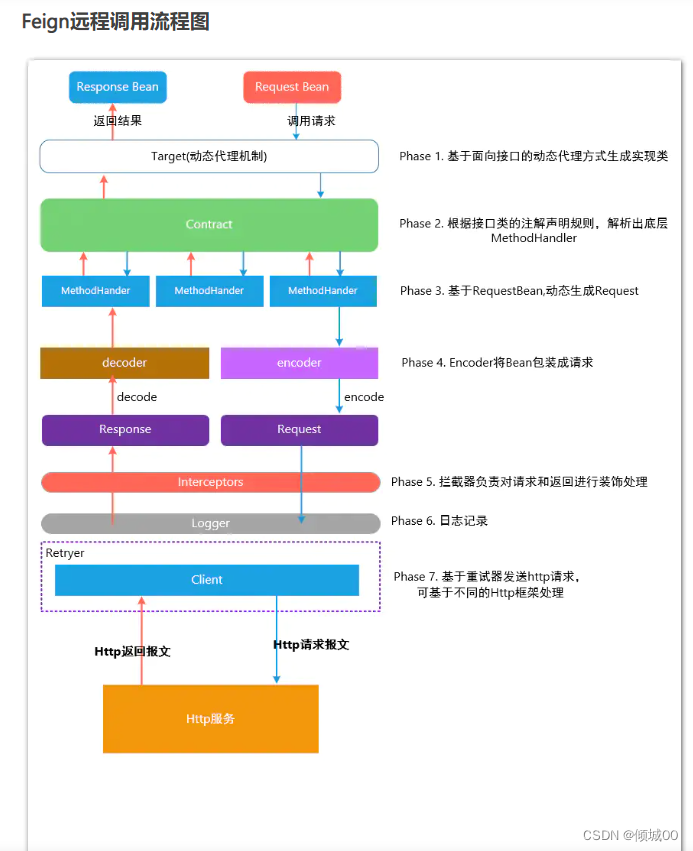
Fegin的底层实现是依靠JDK动态代理实现的
好文章推荐 -
RestTemplate可以直接通过URL访问到服务提供者,而Fegin是依靠接口注解的方式调用Http请求而这个过程需要中间经历很多步(例如先JDK动态代理–>调用处理器 InvocationHandler–>Encoder—>Request—>…),所以前者效率高
-
虽然在效率上RestTemplate是更胜一筹,但是在开发效率上,Fegin实在是特别友好,通过M层接口上的注解我们可以很优雅的去实现在客户端调用服务端的方法,进而获取到数据
-
追求效率用RestTemplate 追求优雅用Fegin,还是Fegin比较推荐
六:服务熔断:Hystrix
在微服务架构的应用程序中经常会有几个甚至几十个子系统,而每个子系统之间的可能会有相互依赖的关系,但是如果有一个宕机了,那么与他相关的会怎么办?这时候就会出现服务雪崩的现象。
6.1 服务的雪崩
假设有A-B-C这三个服务,是链式调用的,突然A这个服务流量很大,这种情况下,就算A扛得住,B或者C有可能扛不住
假设B不可用了,那么C的请求也会阻塞,直到资源耗尽,紧接着A也会不可用
一个服务失败,导致整条链路都失败的情况下我们称之为服务的雪崩
- 服务的雪崩原因
| 服务不可用: | 程序故障 | 缓存击穿 | 用户大量请求 |
| 重试加大流量: | 用户重试 | 代码重试 | |
| 服务调用者不可用: | 同步等待导致资源耗尽 |
- 应对策略
| 用户扩容: | 增加机器数量 | 升级硬件规格 | ||
| 流控: | 限流 | 关闭重试 | ||
| 缓存: | 缓存预加载 | |||
| 服务降级: | 服务页面拒绝服务 | 页面拒绝服务 | 延迟持久化 | 拒绝随机服务 |
6.2 Hystrix概念:
- Hystrix是一个处理分布式系统延迟和容错的开源库,在分布式系统中,许多依赖避免不了调用失败,比如超时异常等等,Hystrix能够保证在一 个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,
- Hystrix就是一个组件(一些jar包)能够帮我们便捷的实现服务熔断,服务降级
ps:Hystrix除了能实现服务熔断,服务降级之外,还能实现服务的监控(也就是他有一个类似于solr的管理页面的面板)
6.3 服务降级
-
什么情况下会触发服务降级
(1)换言之就是服务端有直接运行的的exception:
例如:在服务端的某一函数内有这行语句:System.out.print(2/0); 虽然这行代码能够校验通过,但是运行的时候是会产生异常的。
例如:nullPointerException,ArrayIndexOutOfBoundsException等这些都是程序运行异常
(2)超时:当客户端调用服务端的服务的时候,但是此时服务端有一个较为耗时的操作,那么此时就会产生一个超时的错误,就会触发服务降级
(3)服务熔断触发服务降级:这个是比较绕的一个原因,其实就是服务端因为达到了最大负载,不能继续提供服务了,那么此时就要给客户端反馈一个服务降级的信息,例如给客户端的回复是当前服务端已经达到了最大负载,请稍后再尝试。
(4)线程池/信号量打满也会导致服务降级:当服务端提供服务使用的线程池threadPool(例如服务端的数据库连接池),或者信号量达到了最初的设定,且没有继续申请开启更多的时候,那么此时服务端就会触发服务降级 -
服务降级的应对策略
(1)页面降级 —— 可视化界面禁用点击按钮、调整静态页面:在代码实现就是在页面上用js获取jquery实现
(2)调用Fallback处理逻辑------就是执行降级处理的相关函数
- 服务降级和异常处理是有异曲同工之妙的,只不过异常处理是对某一个项目,服务降级更多侧重的是多个服务
- 下面是代码实现,以8003项目的基础增加Hystrix
- pom新增
<!--Hystrix-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
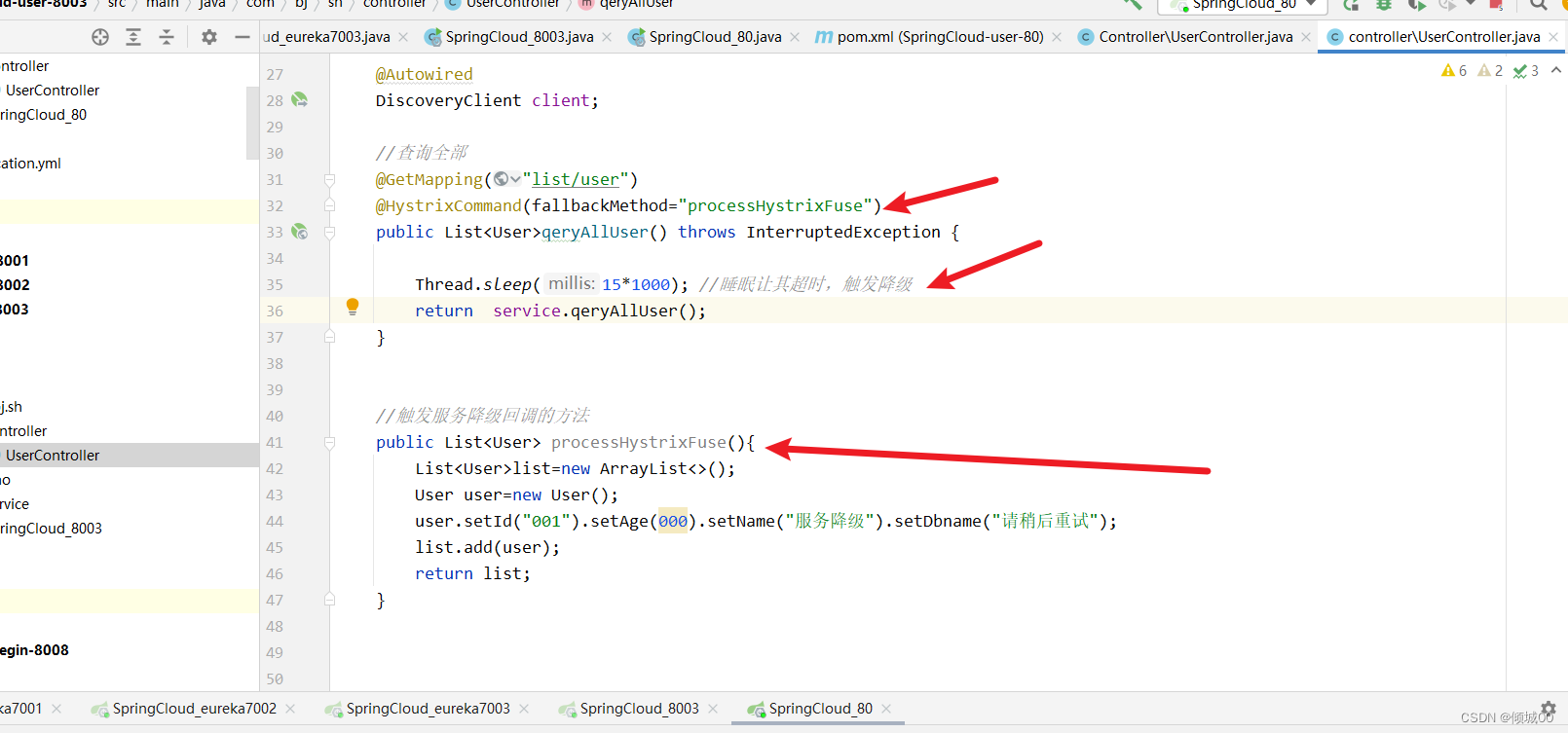
- 在UserController 新增- 通过睡眠触发异常,然后进行服务降级
@HystrixCommand(fallbackMethod="processHystrixFuse")
//触发服务降级回调的方法
public List<User> processHystrixFuse(){
List<User>list=new ArrayList<>();
User user=new User();
user.setId("001").setAge(000).setName("服务降级").setDbname("请稍后重试");
list.add(user);
return list;
}
- 启动类新增对Hystrix的注解支持
@EnableHystrix //r实现对服务熔断的支持
- 启动7001-7002-7003-8003-80
- 通过80去访问8003- 服务降级成功
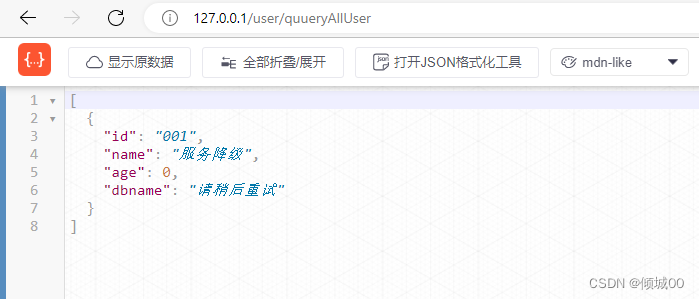
- 然后再启动8008就是通过fegin去调用8003-发现没有成功启动服务降级
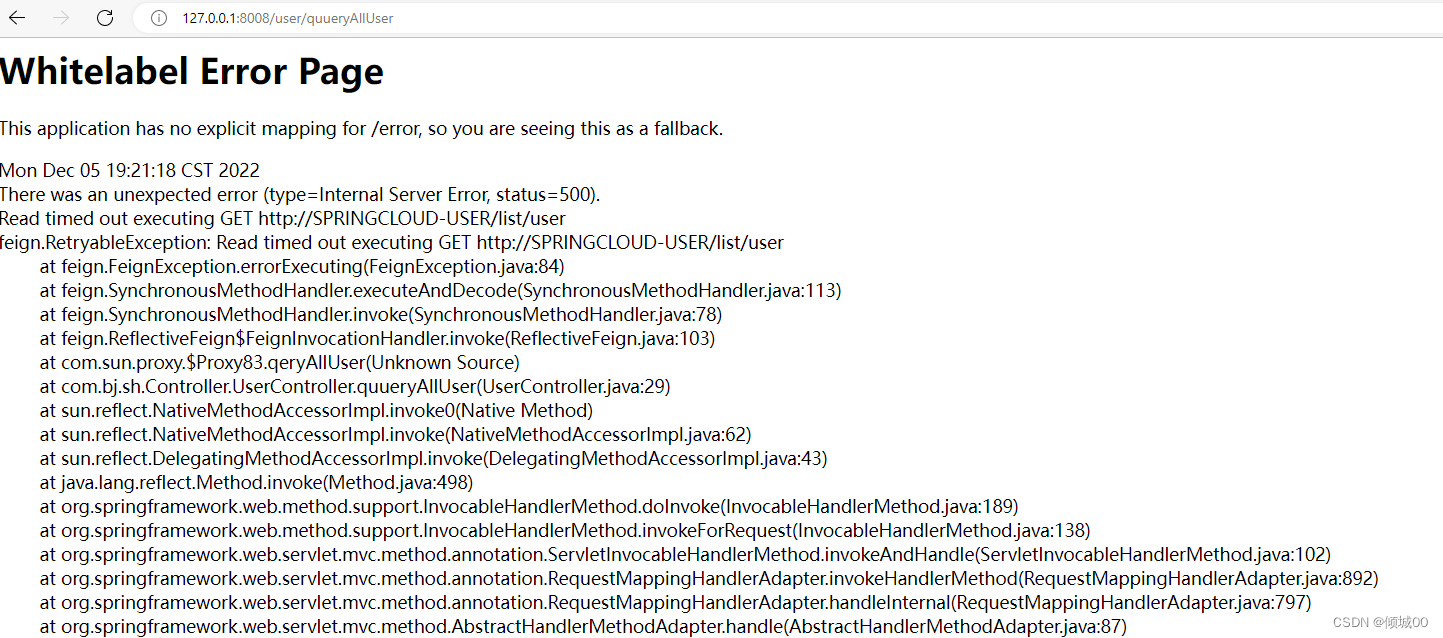
6.4 Fegin客户端与服务端都实现双侧服务降级
- 其实上面这个是因为我们的客户端调用服务端的时候,因为服务端的异常就是超时异常,而我们客户端的Fegin在调用服务端的时候如果遇到服务请求超时异常的时候,就会产生一个属于fegin自己的错误
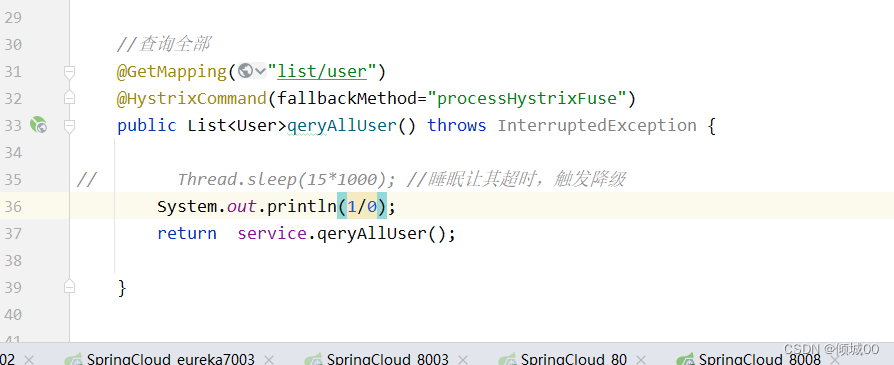
- 将8003的超时异常换为算数异常,在次访问就会访问成功
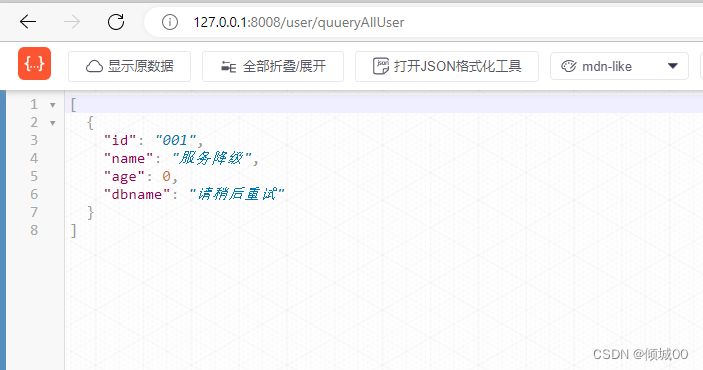
- 但是遇到超时应该怎么办呢
-解决办法1:在fegin的yml文件设置,治标不治本(不推荐)
feign:
client:
config:
default:
connectTimeout: 10000
readTimeout: 600000
- 解决办法二:实现双向降级
- 就是在fegin这块也实现服务降级
-在fegin新增pom
<!--Hystrix-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
- fegin的UserController 中新增
@HystrixCommand(fallbackMethod="processHystrixFuse")
//触发服务降级回调的方法
public List<User> processHystrixFuse(){
List<User>list=new ArrayList<>();
User user=new User();
user.setId("001").setAge(000).setName("fegin服务降级").setDbname("请稍后重试");
list.add(user);
return list;
}

- 在fegin中增加对于降级的支持@EnableHystrix
- 重启8003和fegin,通过fegin去访问8003
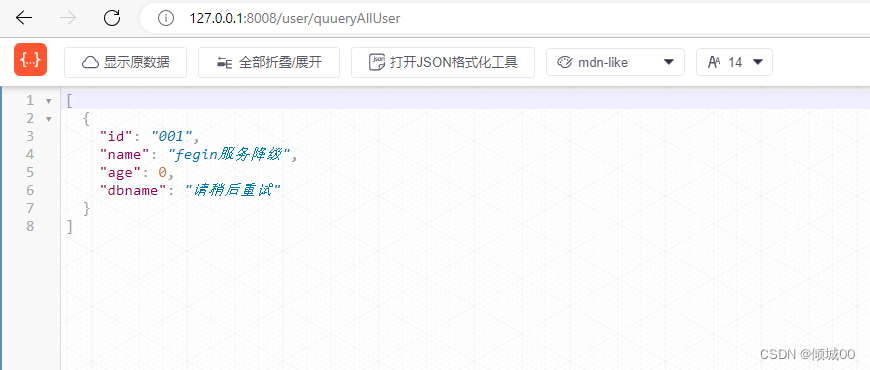
- 效果成功,并且走的是fegin的异常
6.5 服务端的峰值调用
自身服务处理的时候,我们设置更加细粒度的处理,即我们假定当处理的服务是在3秒之内是正常
超过3秒就是要触发异常,这样的操作就叫做服务端的峰值调用
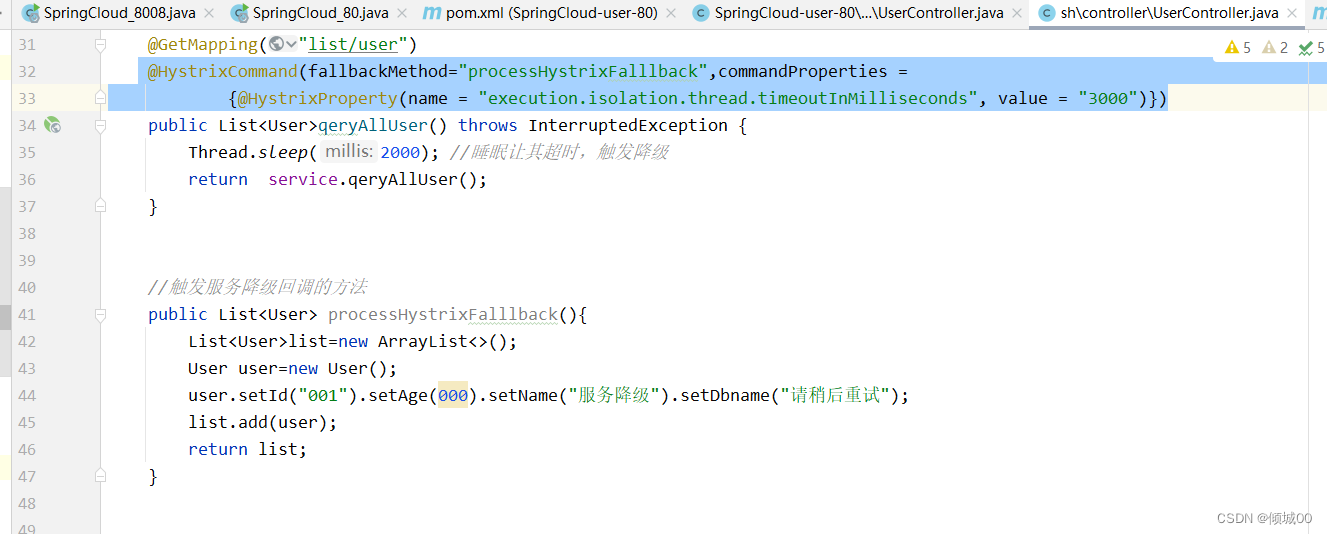
- 在8003的UserController 添加这个
@HystrixCommand(fallbackMethod="processHystrixFalllback",commandProperties =
{@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000")})
- 让自己睡眠2s让其最大时间设置为3s,超过3s就触发服务降级
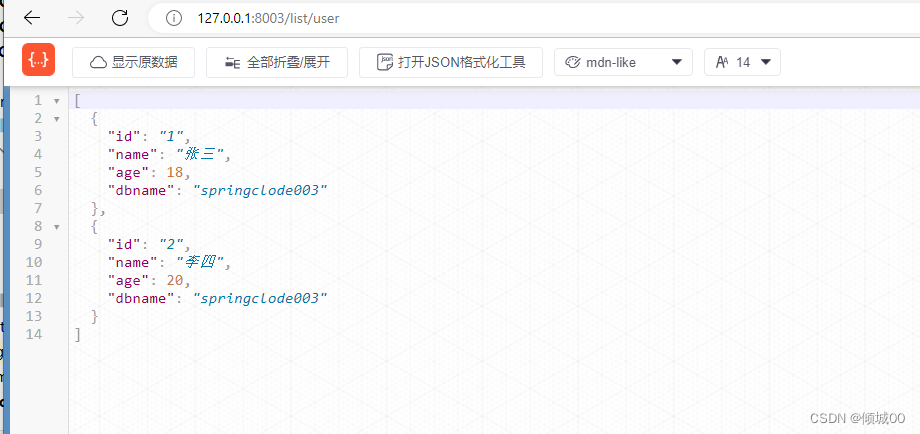
- 通过浏览器访问8003(直接访问)成功
- 通过fegin去访问8003(失败)
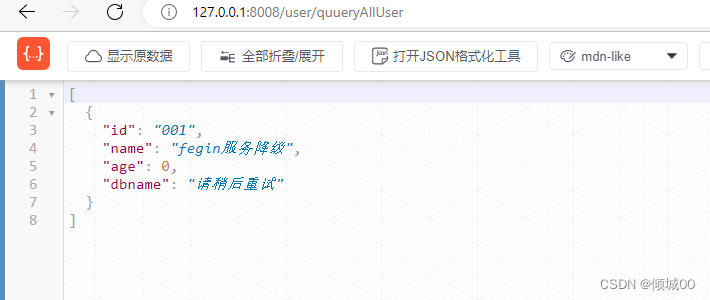
- 原因:我们自己调用自己代码是睡眠2s,设置的是超过3s触发降价,自己访问自己肯定不会超过3s
- 用fegin去调用8003的数据,睡眠2s,时间就超过了3s,这就是有的时候自己本地跑的没问题,但是别人一调就有问题了
- 解决办法:
- (1)优化代码
- (2)优化网络
- (3)在客户端这边的配置文件applcation.yml中设定ribbon的连接时间和读取服务的时间(推荐使用),同时也建议在客户端这块配置上自己的服务降级的属性配置(即客户端执行的时候超过5秒就自动触发客户端降级)
- 在8008也就是fegin的代码进行配置
- yml文件
ribbon: #客户端负载均衡的配置
ReadTimeout: 10000 #读取服务的时间配置
ConnectTimeout: 10000 #客户端连接服务端的时间配置
- fegin的UserController
@HystrixCommand(fallbackMethod="processHystrixFuse",commandProperties =
{@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "5000")})
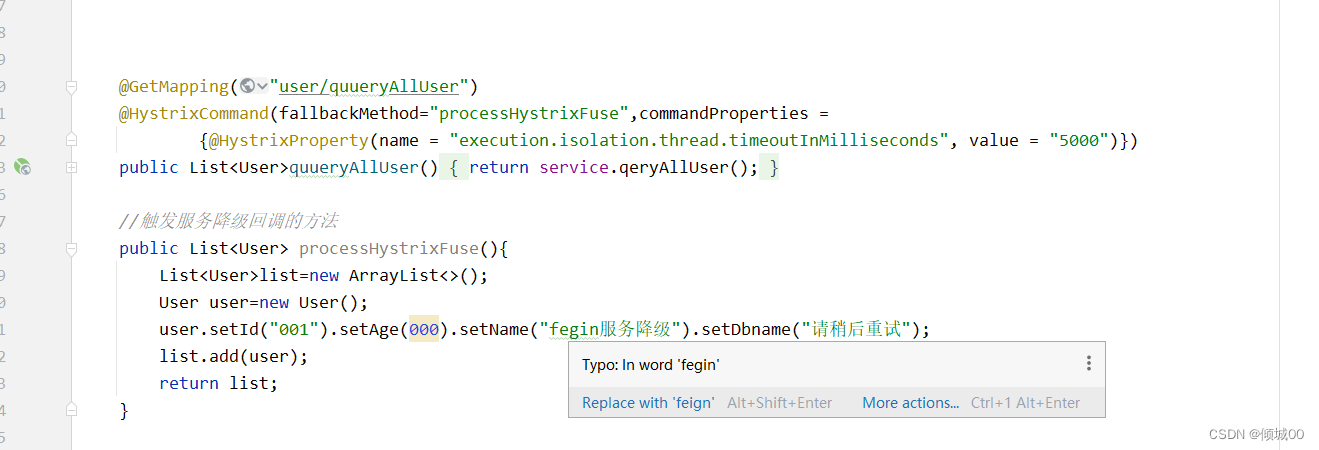
- 这样就不会触发服务降级了
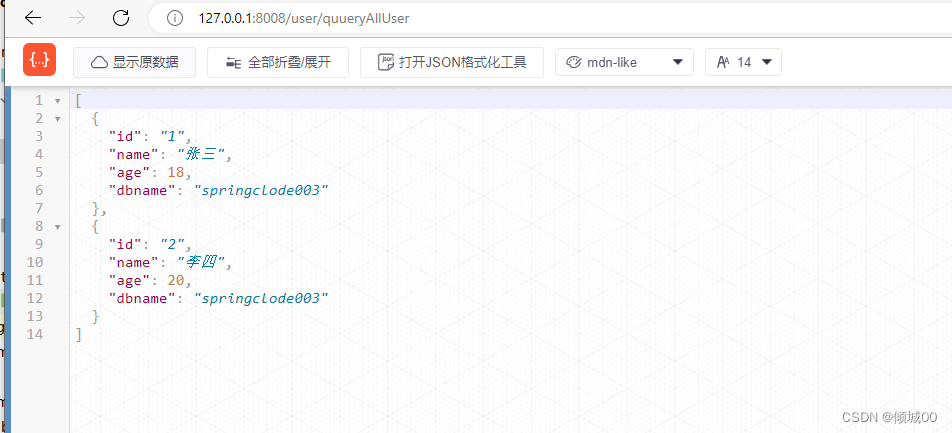
6.5 Hystrix的代码拢余
- @DefaultProperties(defaultFallback = “processHystrixFuse”)
- 全局回调,如果@HystrixCommand 后面什么都不写,那么就会走@DefaultProperties注解的回调方法
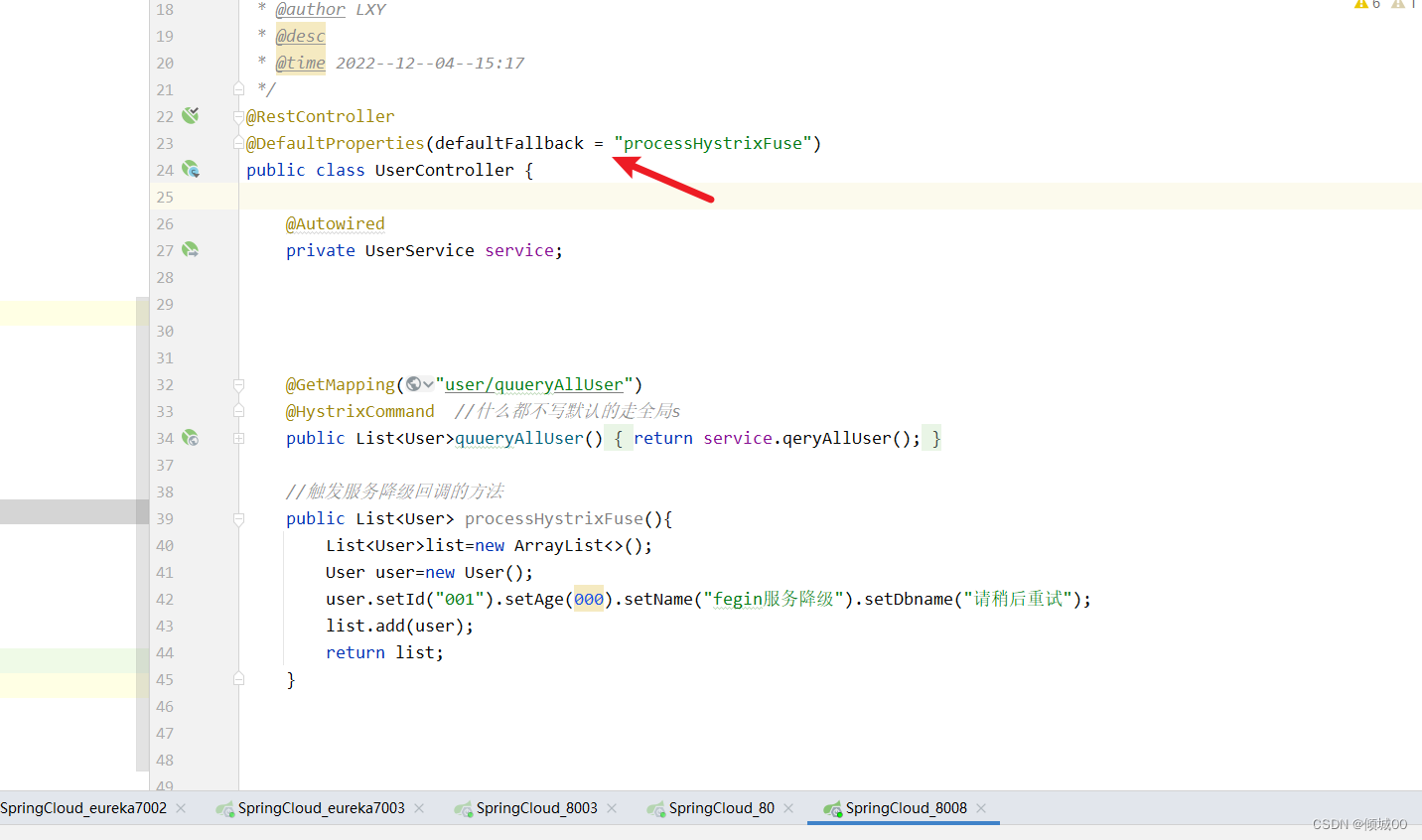
- 结果是正常降级
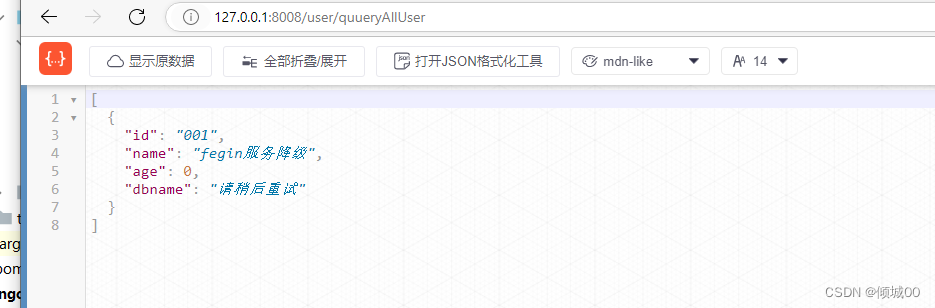
- 解决办法二:
- 新建UserServiceHystrixService 实现UserService
代码 -->这是降级之后返回的数据
package com.bj.sh.Service;
import com.rj.bd.prop.User;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
/**
* @author LXY
* @desc
* @time 2022--12--05--20:11
*/
@Component("feginUserFallBackService") //将当前这个类设定为M层的实现类,feginUserFallBackService,好在C层中能实现自动装配
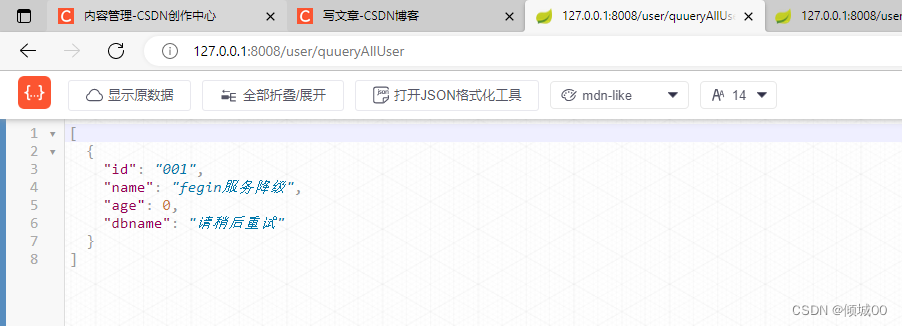
public class UserServiceHystrixService implements UserService{
@Override
public List<User> qeryAllUser() {
List<User>list=new ArrayList<>();
User user=new User();
user.setId("001").setAge(000).setName("fegin服务降级").setDbname("请稍后重试");
list.add(user);
return list;
}
@Override
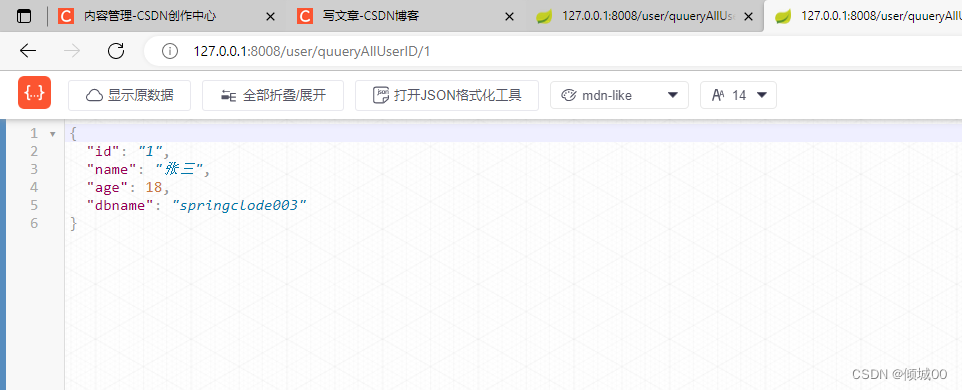
public User qeryAllUserById(String id) {
User user=new User();
user.setId("2").setAge(000).setName("fegin服务降级").setDbname("请稍后重试");
return user;
}
}
-
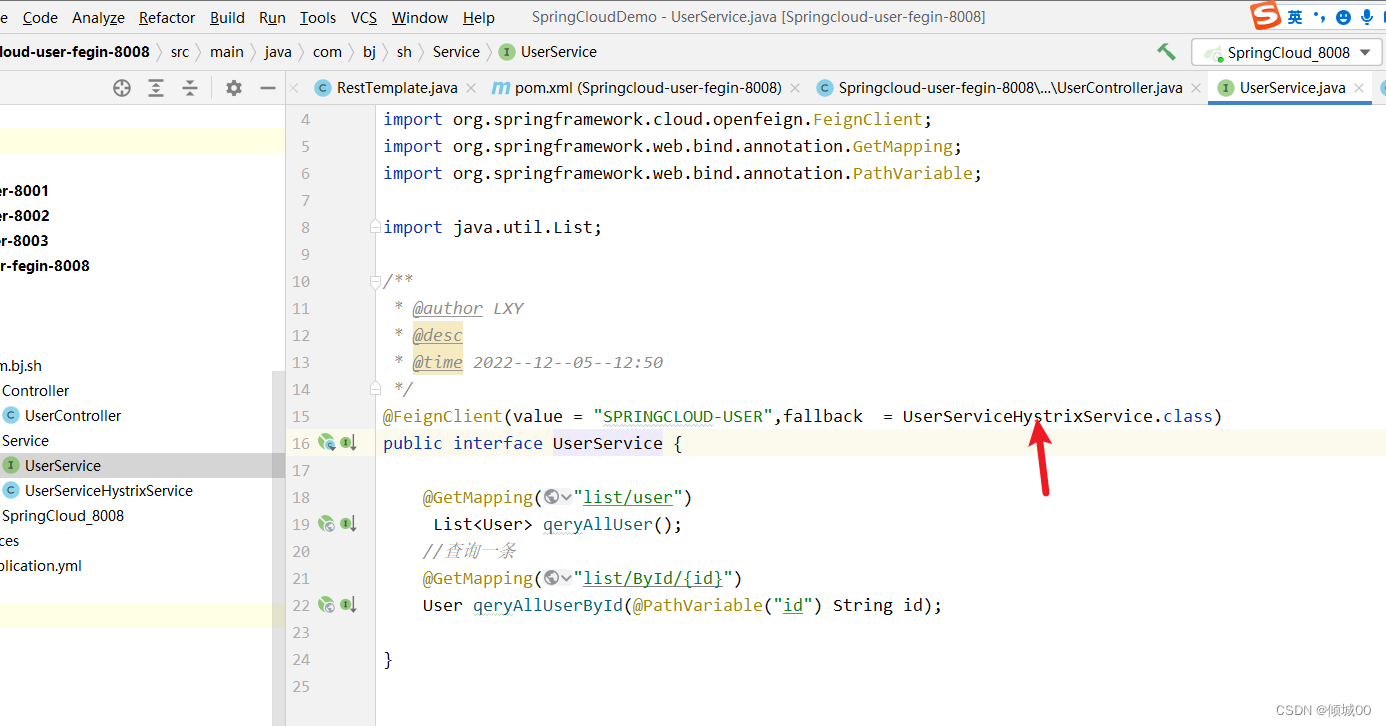
UserService中新增
@FeignClient(value = “SPRINGCLOUD-USER”,fallback = UserServiceHystrixService.class)
回调的接口就是我们新创建的类。如果一切正常则不走,一旦发生异常或者服务端下线,就将数据进行返回
-
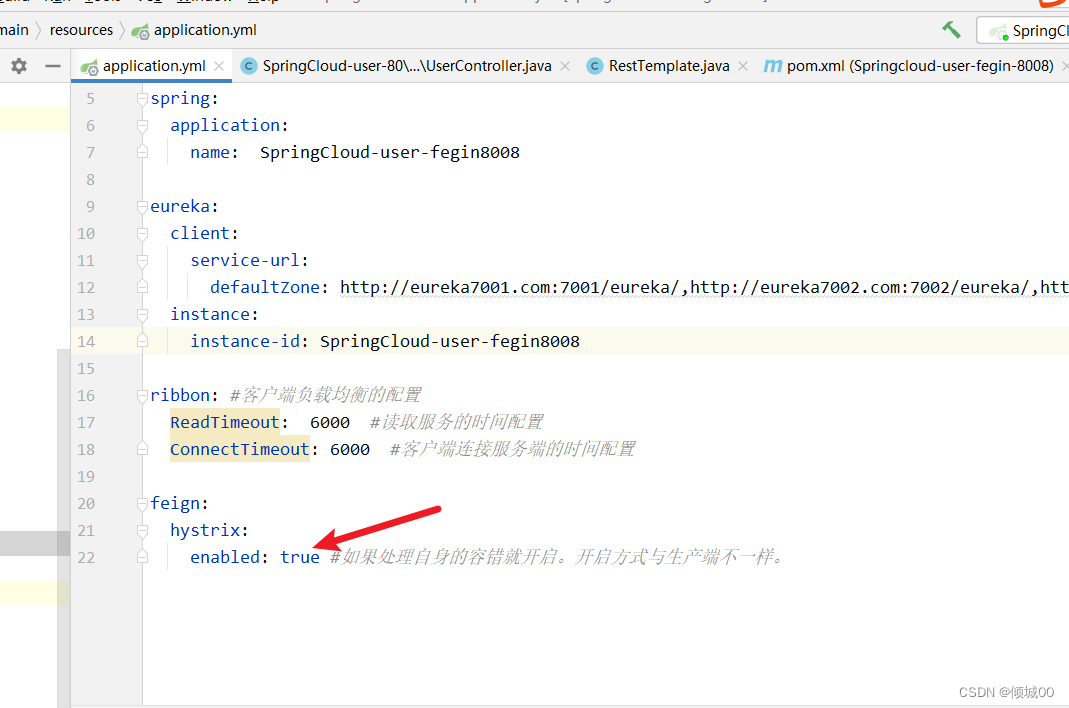
yml中新增
feign:
hystrix:
enabled: true #如果处理自身的容错就开启。开启方式与生产端不一样。
- 然后将UserController中关于一切降级的代码都注释,然后启动浏览器访问,没有问题的时候访问正常,出了问题会发现降级的返回值
6.6 服务熔断
1.服务熔断的状态:
对于熔断机制的实现,Hystrix设计了三种状态:
1.1.熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制。
1.2.熔断开启状态(Open)
在固定时间内(Hystrix默认是10秒),接口调用出错比率达到一个阈值(Hystrix默认为50%),会进入熔断开启状态。
进入熔断状态后, 后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法。
1.3.半熔断状态(Half-Open)
在进入熔断开启状态一段时间之后(Hystrix默认是5秒),熔断器会进入半熔断状态。
所谓半熔断就是尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。
如果成功率达到预期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断开启状态
- 在8003的项目上演示
- 在查询一条这个办法中,添加熔断注解
@HystrixCommand(fallbackMethod = "processHystrixCircuitBreakMethod",commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled",value = "true"), //是否开启断路器
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "10"), //请求次数
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "10000"), //时间范围
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "60"), //失败60%也就是6次的时候就跳闸(触发服务降级)
})
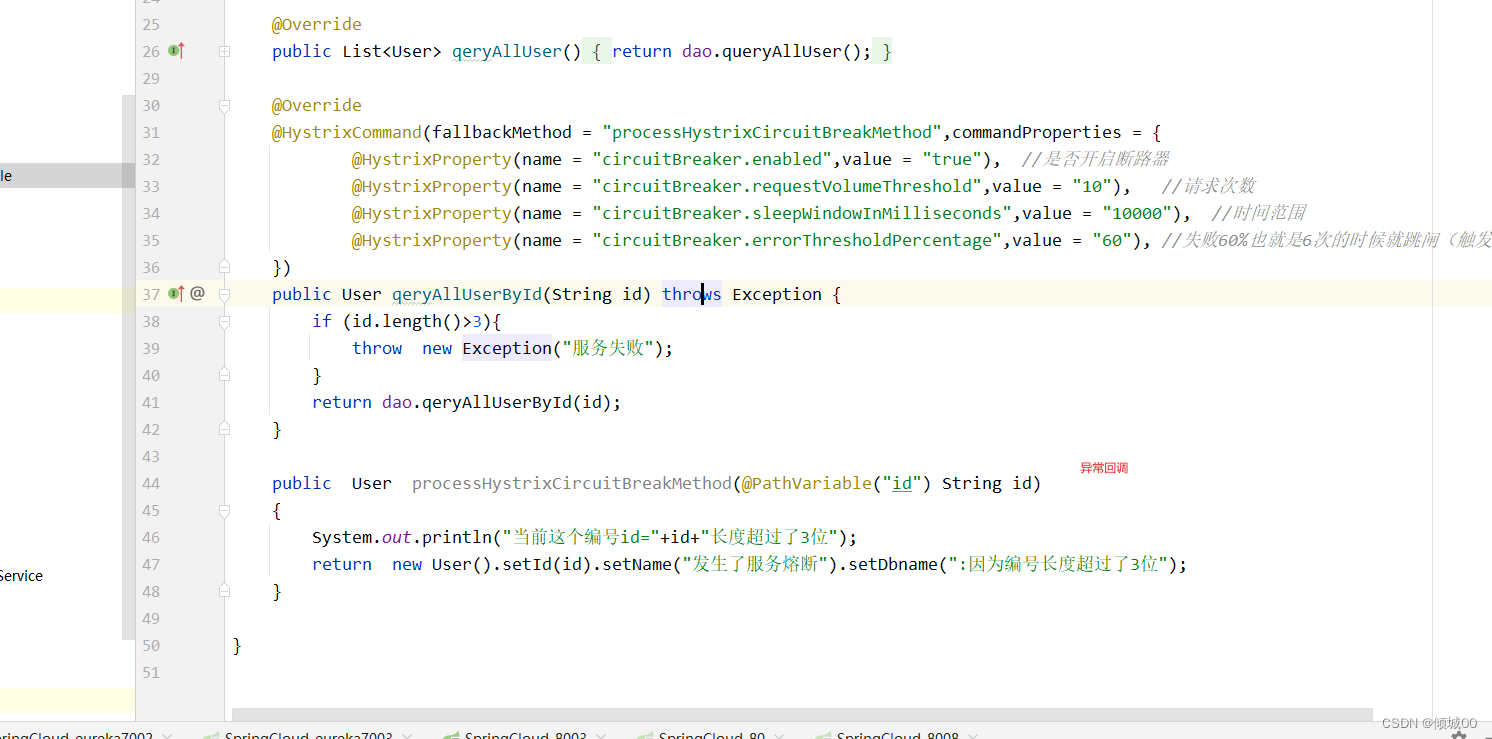
- 如果id的长度>3那么就抛出异常,我们一直刷新正确的看不出来变化
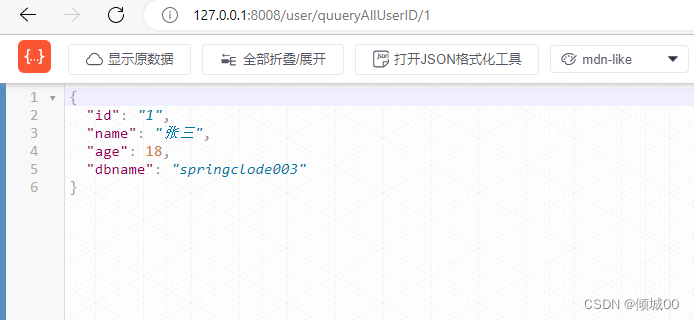
- 我们一直请求错误的,在10s请求10次
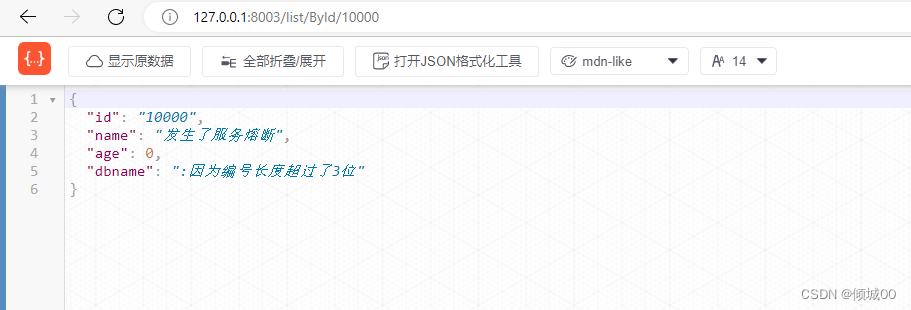
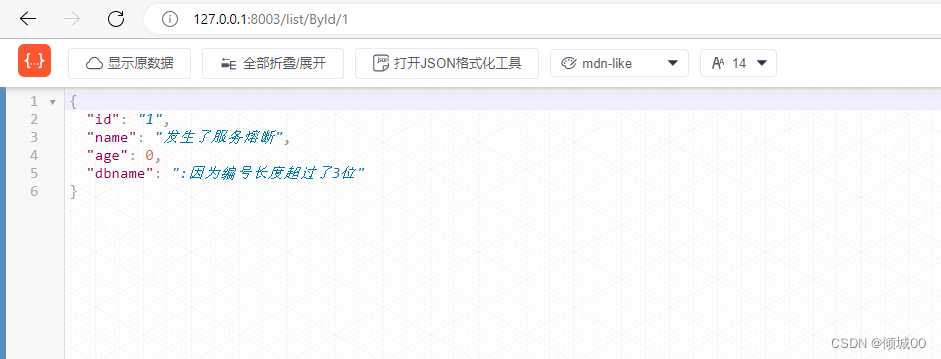
- 然后我们在请求正确的,发现数据还是发生了熔断,这是因为,我们请求错误的在10s内失败的概率,超过了60%那么就进入了熔断状态,然后我们在请求正确的就会进入到半熔断状态,等过了5s在请求正确的就是非熔断状态,这个就可以理解为,因为网络波动等一系列元素,导致一直请求失败,然后突然网络好了,请求到的是正确的,那么等待5s即可恢复正常
6.6.1 服务熔断重要参数
-
1.服务熔断注解中主要三个参数是什么意思:
(1) circuitBreaker.enabled:确定断路器是否用于跟踪运行状况和短路请求(如果跳闸)。默认值为true
(2)circuitBreaker.requestVolumeThreshold(请求总数阈值):请求次数,默认值:10
(3)circuitBreaker.sleepWindowInMilliseconds(快照时间窗):熔断多少秒后去尝试请求,默认值:5000
(4)circuitBreaker.errorThresholdPercentage(错误百分百阈值):失败率达到多少百分比后熔断,默认值:50。主要根据依赖重要性进行调整
小结:断路器开启或者关闭的条件:
1)当满足一定阀值的时候(默认10秒内超过20个请求次数)
2)当失败率达到一定的时候(默认10秒内超过50%请求失败)
3)到达以上阀值,断路器将会开启
4)当开启的时候,所有请求都不会进行转发
5)一段时间之后(默认是5秒),这个时候断路器是半开状态,会让其中一个请求进行转发。如果成功,断路器会关闭,若失败,继续开启。重复4和5
开启就能用,半开是尝试着用,关闭就不能用,阈值可调控 -
在HystrixCommandProperties类中我们就可以看到
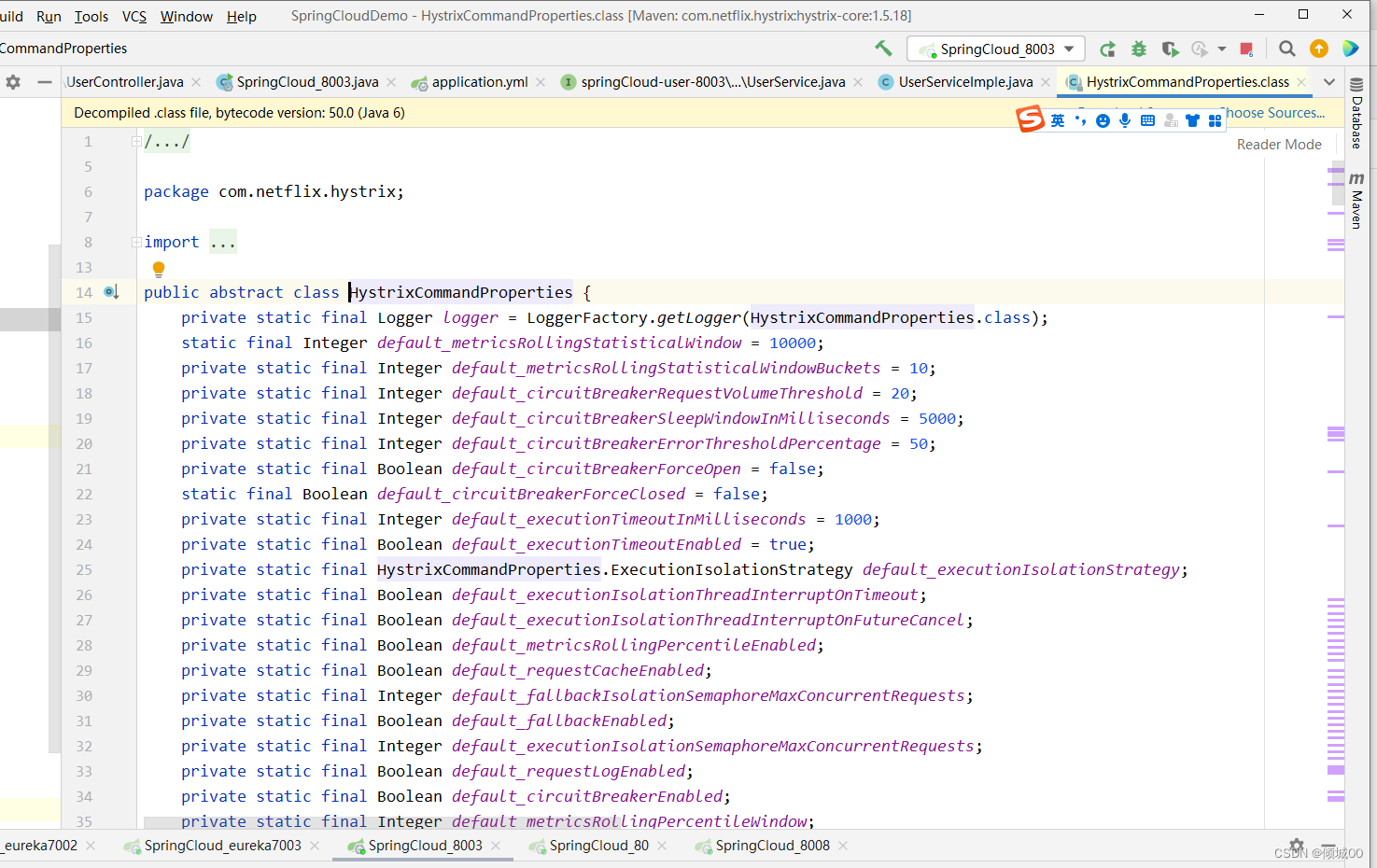
-
其他参数

6.6.2 服务熔断小结
- 当断路器开启之后将不会调用主要逻,将会调回降级逻辑实现了发生错误,自动地将断路器逻辑自动转为主要逻辑
- 那之前的主逻辑要如何恢复呢?
- 当断路器打开之后,对主逻辑进行一个熔断状态会启动一个休眠的时间窗,在这个时间内,降级逻辑将会成为主逻辑,当休眠时间到期,断路器进入到半开状态,释放一次请求到原来的主逻辑上,如果正常,那么断路器将关闭,如果请求有误,断路器会进入到打开状态,休眠时间窗会重新计时
6.7 Hystrix的监控
-
除了服务降级和服务熔断之外,Hystrix还提供 了接近于实时的调用监控(Hystrix Dashboard) , Hystrix会持续地记录所有通过Hystrix发
起的请求的执行信息,以统计报表和图形的形式展示给用户,包括每秒执行多少请求多少成功,多少失败等。Netflix通过hystrix-metrics-event-stream项目
实现了对以上指标的监控。Spring Cloud也提供了Hystrix Dashboard的整合,对监控内容转化成可视化界面。 -
创建子项目 springcloud-user-hystrix-8000
-
pom
<dependencies>
<!--新增hystrix dashboard-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
-启动类
package com.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.hystrix.dashboard.EnableHystrixDashboard;
/**
* @author LXY
* @desc
* @time 2022--12--05--21:39
*/
@SpringBootApplication
@EnableHystrixDashboard //加载HystrixDashboard 的功能
public class springcloud8000 {
public static void main(String[] args) {
SpringApplication.run(springcloud8000.class,args);
}
}
- yml文件
server:
port: 8000
- 浏览器输入http://127.0.0.1:8000/hystrix

- 在被监控者里面的启动类需注入bean
- 并且被监控的子系统中需要有spring-boot-starter-actuator 这个maven
@Bean
public ServletRegistrationBean getServlet(){
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}

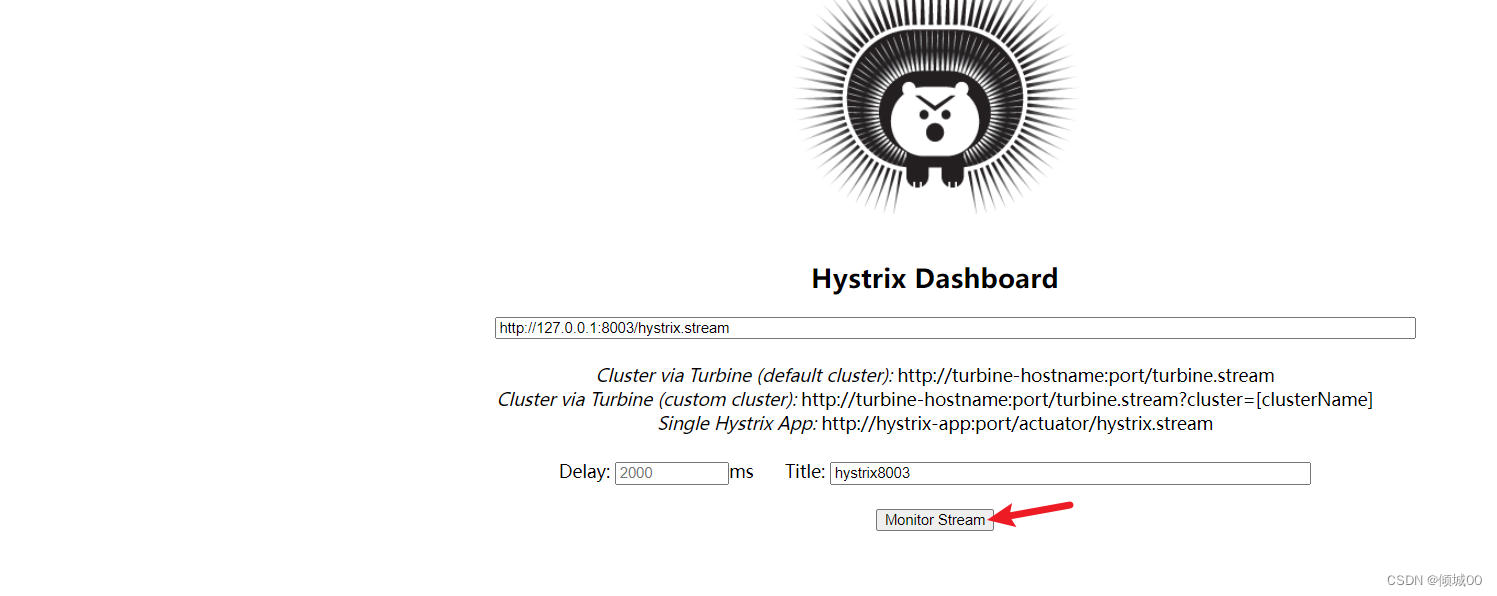
- 通过请求数据,数据就会发生变化
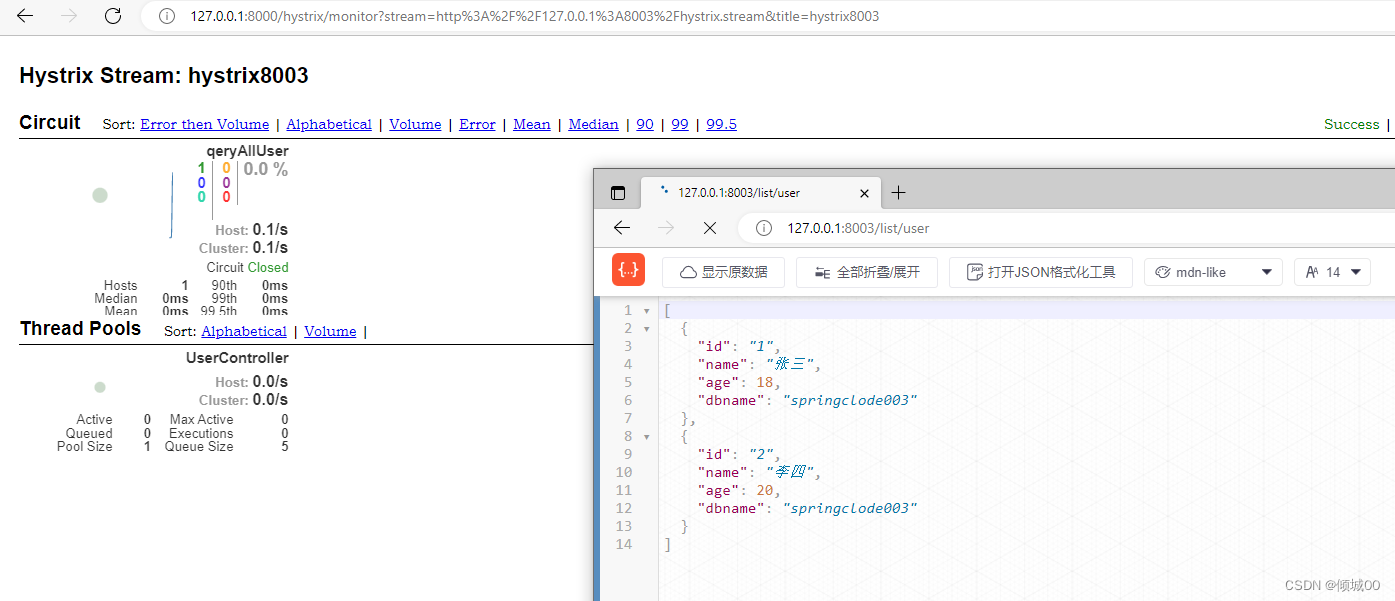
- 监控详情图
七:Zuul (网关)
- 网关的相关知识
(1.1)网关(Gateway) 就是一个网络连接到另一个网络的“关口”。也就是网络关卡
(1.2)网关(Gateway)又称网间连接器、协议转换器。网关在网络层以上实现网络互连,是复杂的网络互连设备,仅用于两个高层协议不同的网络互连 - 网关的分类
(2.1)协议网关:协议网关在两个使用不同协议的网络之间,充当了翻译器的角色。比如生活中常见的路由器,就是协议网关。
(2.2)安全网关:安全网关有独特的保护作用,会对一些目的地址、协议等进行授权
(2.3) 应用网关:应用网关可以在接受一种格式后,将之翻译,并以新的格式发送出去,例如邮件服务 - 为什么要使用网关
(3.1)使用网关可以统一进行鉴权,如果在微服务系统中不使用网关那么在每一个微服务中都需要进行鉴权,不仅增加系统的复杂性,而且也影响用户体验
(3.2)使用网关鉴权可以有效的保护微服务,只暴露自己的网关,将其他的微服务可以隐藏在内网中通过防火墙进行保护(用户访问的时候,直接看到的是网关服务,而并不是后面真正的微服务业务子项目)
(3.3)易于监控,可以在网关中直接统一收集监控数据并将其推送到外部系统进行分析(通过监控网关可以进而实现间接监控业务子系统)
(3.4)减少客户端与各个微服务之间的交互次数 - 实现网关的相关技术
(4.1)Nginx:nginx是一个高性能的HTTP和反向代理web服务器
(4.2) getway:是spring出品,基于spring的网关项目,集成断路器,路劲重写,性能要比zuul好
(4.3)zuul: 是netfix出品的一个基于JVM路由和服务端的负载均衡器
7.1 Zuul的概念
- Zuul是Spring Cloud-全家桶中的微服务API网关,且是Netflix公司出产的
- 所有从设备或网站来的请求都会经过Zuul到达后端的Netflix应用程序。
- 作为一个边界性质的应用程序,Zuul提供了动态路由、监控、弹性负载和安全功能
- 其中路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统-入口的效果,而过滤器功能则
- 负责对请求的处理过程进行干预,是实现请求校验,服务聚合等功能的基础。Zuu和Eureka进行整合, 将Zul自身注册为Eureka服务治理下的应用,同时从Eureka中获得其他微服务的消息,也即以后的访问微服务都是通过 Zuul跳转后获得
- Zuul还有其他的功能
- 1) 认证和安全 识别每个需要认证的资源,拒绝不符合要求的请求。
2)性能监测 在服务边界追踪并统计数据,提供精确的生产视图。
3)动态路由 根据需要将请求动态路由到后端集群。
4)压力测试 逐渐增加对集群的流量以了解其性能。
5)负载卸载 预先为每种类型的请求分配容量,当请求超过容量时自动丢弃。
6)静态资源处理 直接在边界返回某些响应。
7.2 Zuul的代码实现
新建子项目SpringCloud-Zuul-9007
- pom
<!--1.zuul的依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zuul</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
<!--2.将zuul以服务的方式注册到erueka上-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
<!--3.actuator完善监控信息-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
- 启动类
package co.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.zuul.EnableZuulProxy;
import org.springframework.cloud.netflix.zuul.EnableZuulServer;
/**
* @author LXY
* @desc
* @time 2022--12--06--22:35
*/
@SpringBootApplication
@EnableZuulProxy //加上zuul代理注解即可让当前项目启动的时候加载到zuul组件。
public class SpringCloud_zuul_9007 {
public static void main(String[] args) {
SpringApplication.run(SpringCloud_zuul_9007.class,args);
}
}
- yml文件
server:
port: 9007
spring:
application:
name: SpringCloud-zuul
eureka:
instance:
instance-id: SpringCloud-zuul-9007
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
info:
app.name: springcloud-zuul-9007-lxy #当前这个子系统的应用的名字
company.name: com.lxy.com #公司的名字
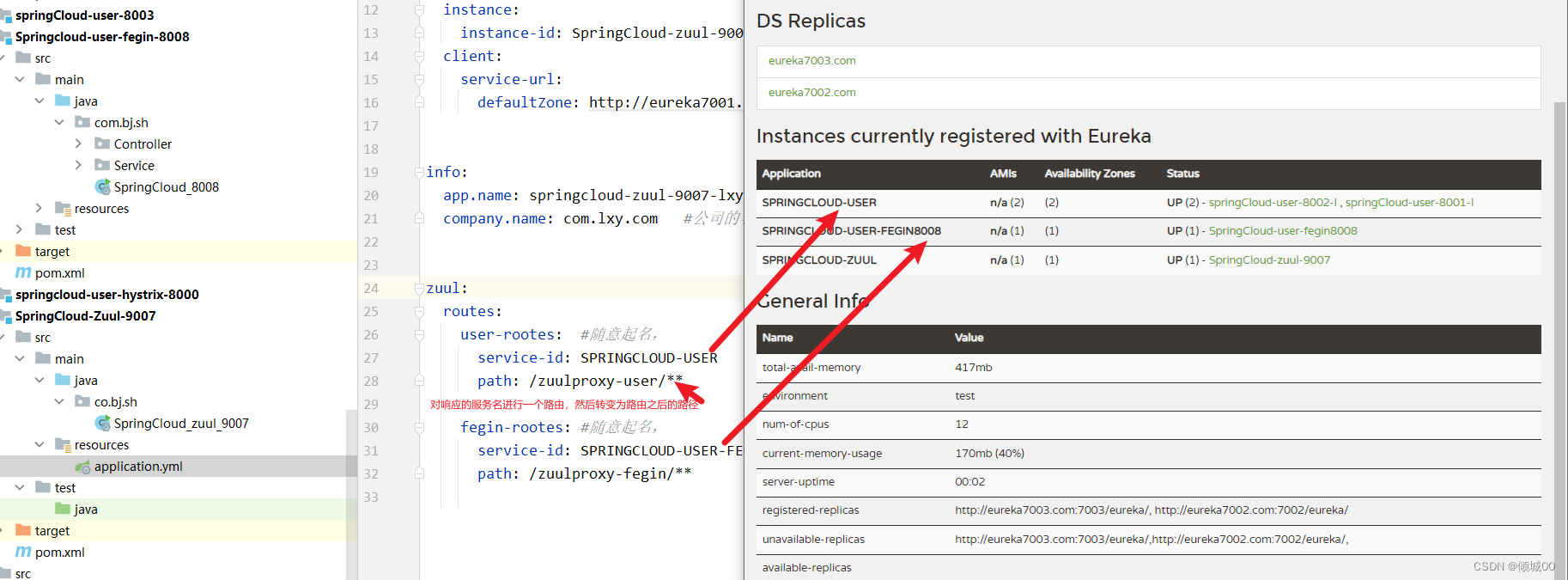
zuul:
routes:
user-rootes: #随意起名,
service-id: SPRINGCLOUD-USER
path: /zuulproxy-user/**
fegin-rootes: #随意起名,
service-id: SPRINGCLOUD-USER-FEGIN8008
path: /zuulproxy-fegin/**
-
启动 7001-7002-7003-8001-8002-9007-8008-这几个项目
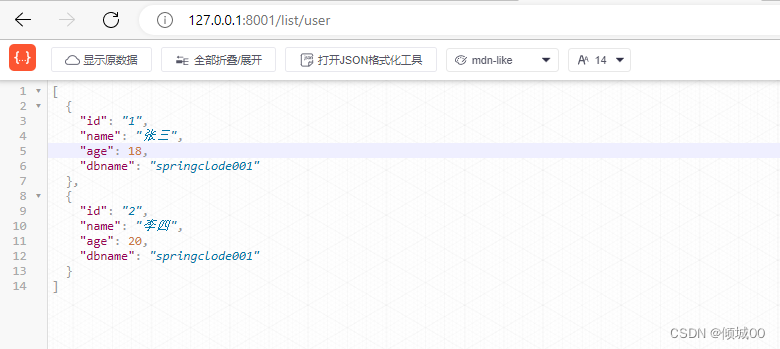
-
先访问http://127.0.0.1:8001/list/user
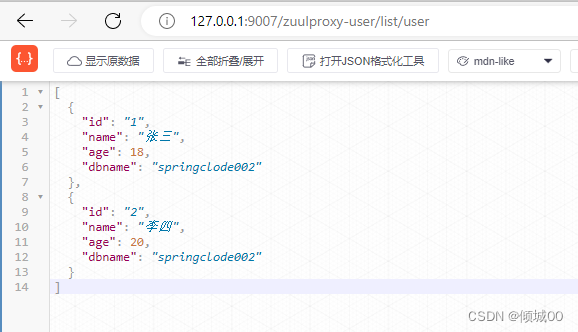
-
然后通过对user的路由再去访问
http://127.0.0.1:9007/zuulproxy-user/list/user
-
在通过fegin去访问user
-
http://127.0.0.1:8008/user/quueryAllUser
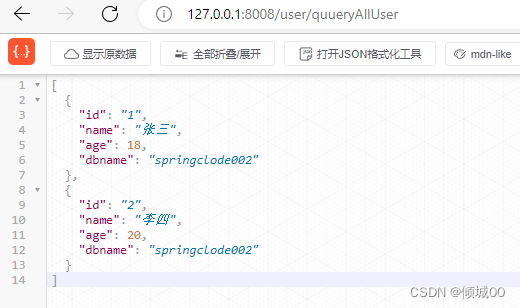
-
在通过zuul,去给fegin路由,去访问
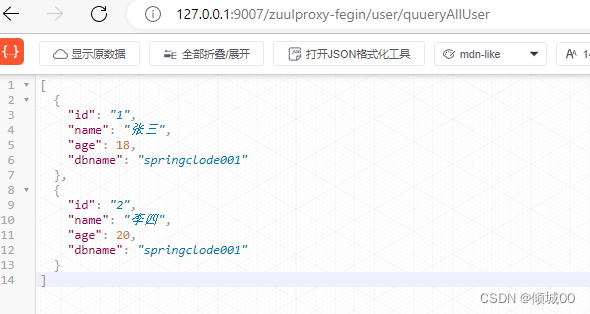
-
由此可见获得的效果是一样的
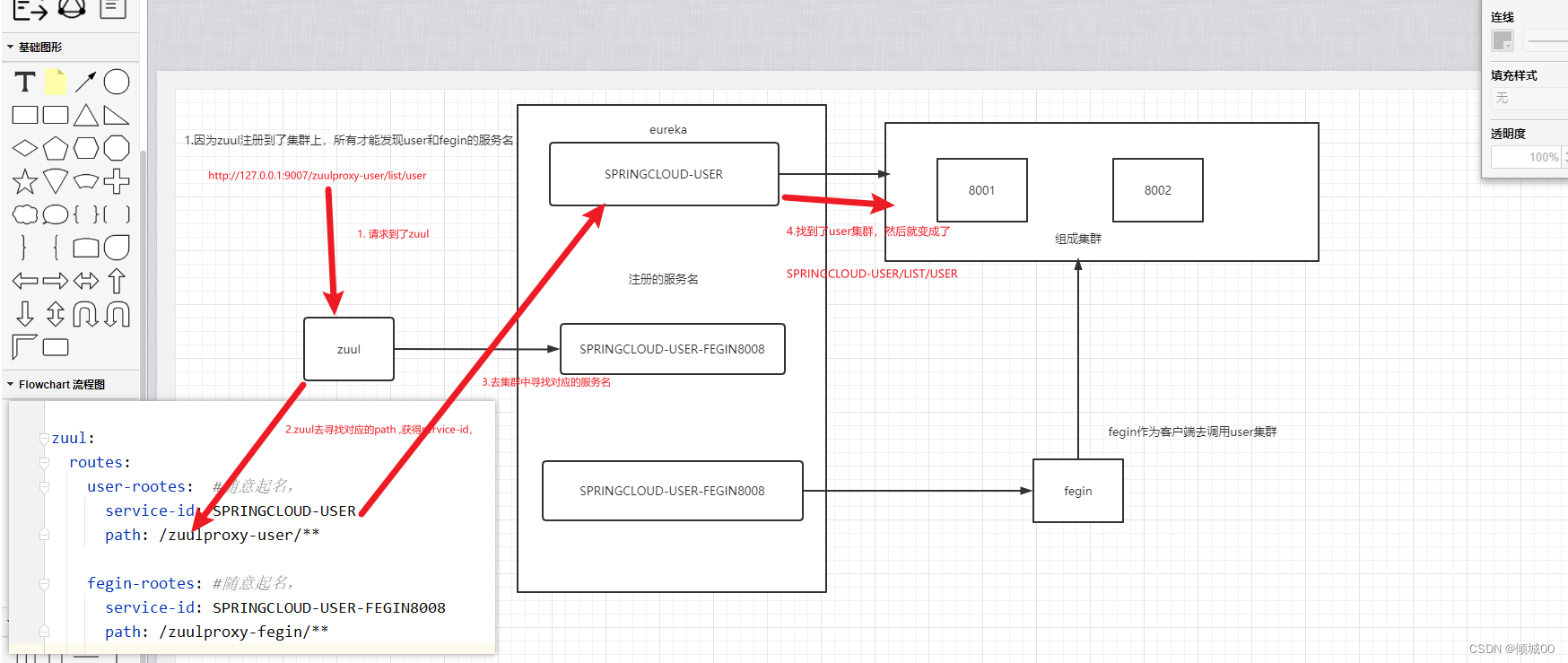
-
原理:将zuul注册到eureak上,然后通过服务的发现,对服务名进行一个路由,最终都是通过9007这个端口和ip+地址去访问的别的子项目
-
实际商业项目中,zuul是不是要为当前微服务项目中的所有子系统配置服务网关呢?
-
现实世界中,我们进入某一栋别墅,肯定是从正门或者后门进入的,那么同样的道理,我们的微服务架构的项目也是这样的,例如在使用淘宝的时候,要先让你登录,然后才能浏览商品,才能下单购买等接下来一系列的操作
那么我们假定此时淘宝用的是zuul作为微服务网关,那么此时zuul中实现代理的路由只是需要配置一个用户子系统的即可,因为其他的业务都是在这之后才展开的,所以zuul并不是要将当前微服务项目中的所有子系统中都给配置
到zuul网关中
7.3 服务前缀
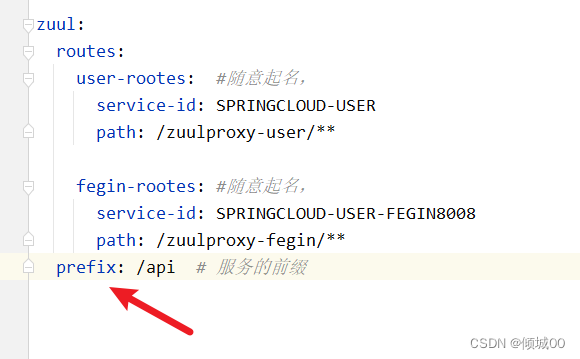
- 配置了服务前缀访问的原网址:
http://127.0.0.1:9007/zuulproxy-user/list/user - 就会变成 http://127.0.0.1:9007/api/zuulproxy-user/list/user
7.3 Zuul的执行流程

- Zuul启动的时候,会对页面记性分发,判断,然后会进入到ZuulController.java
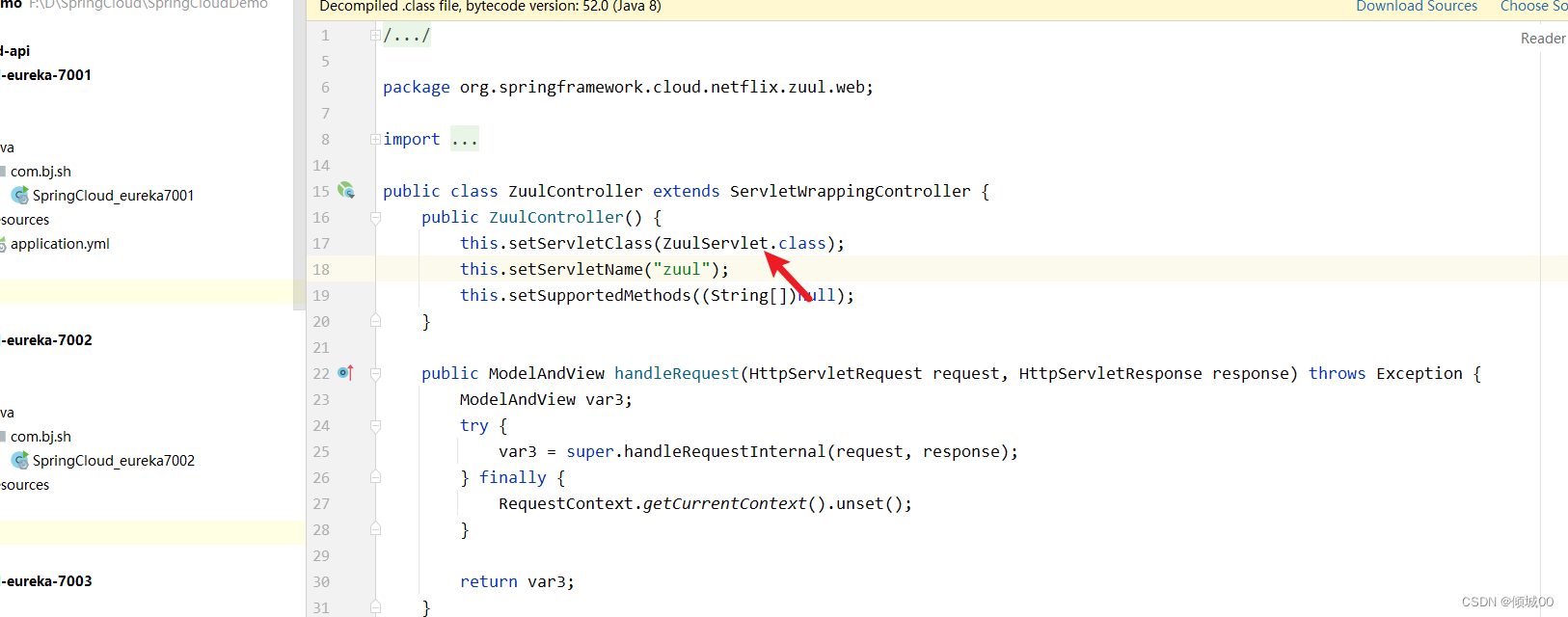
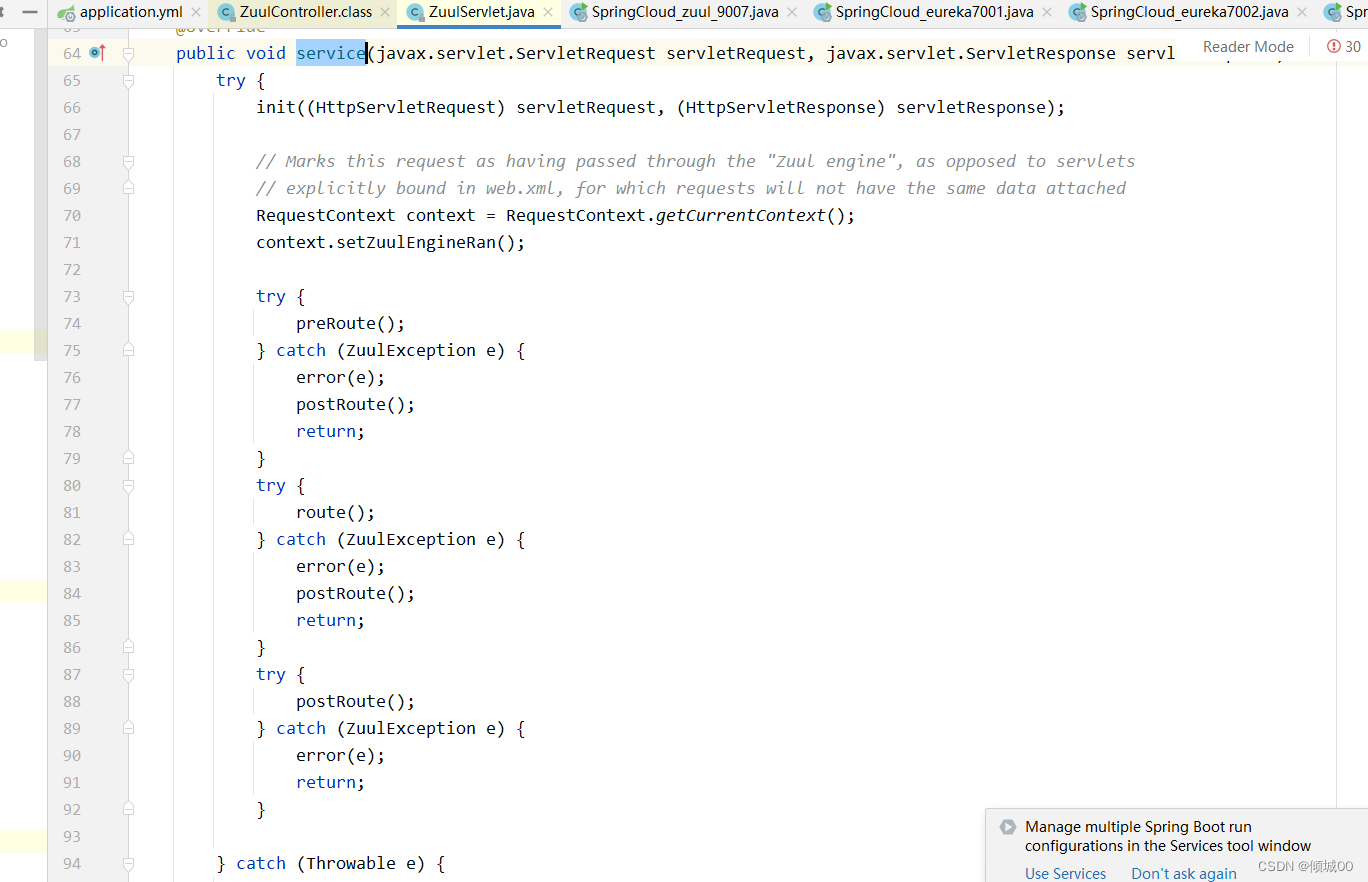
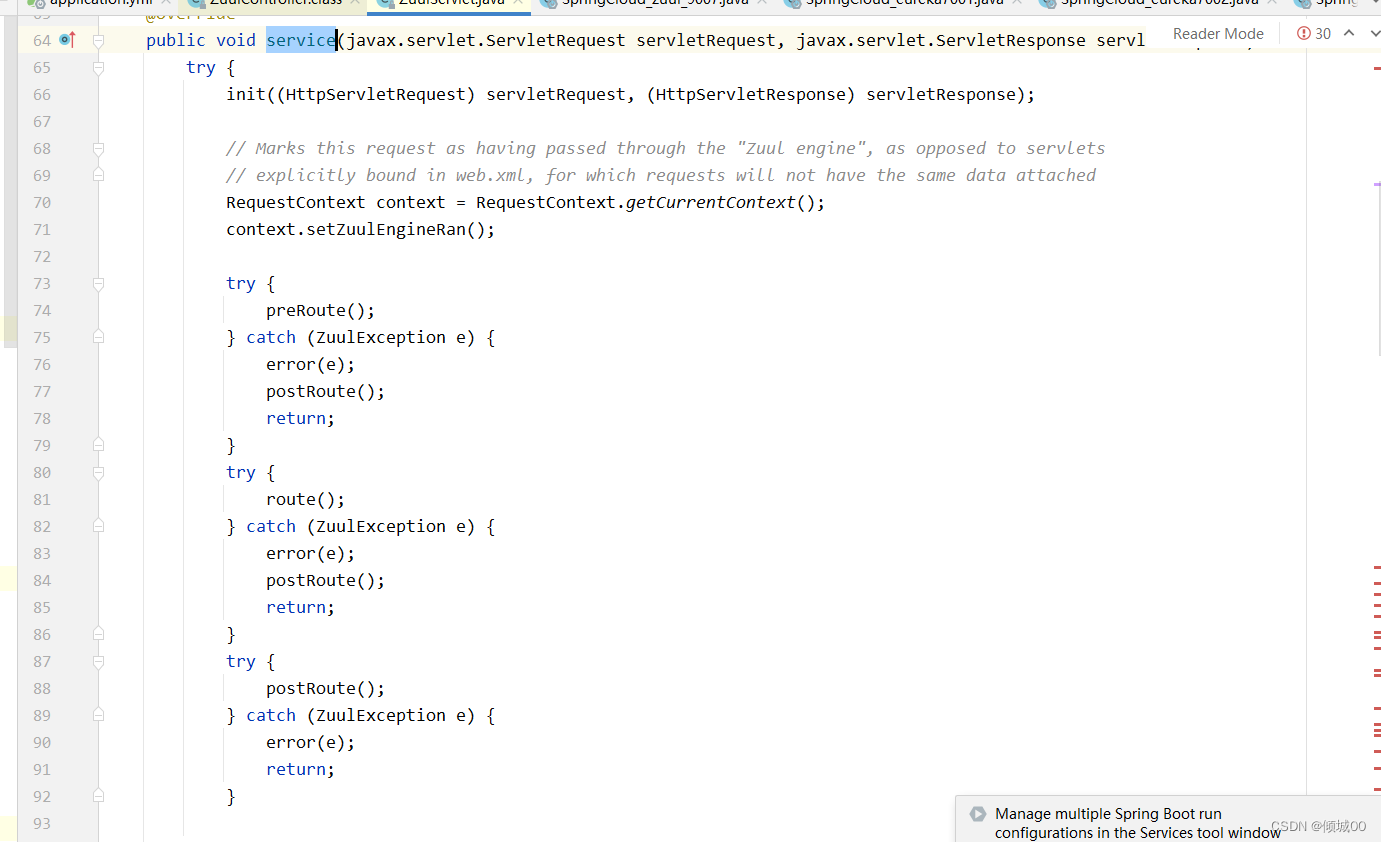

7.4 Zuul自定义过滤器
- 代码中写到,假设传递的token是ABC,但是正确的token是ABCD,对于token不对就不让其访问
- 请求的URL不包含list也不能执行
- 效果(忽视乱码)
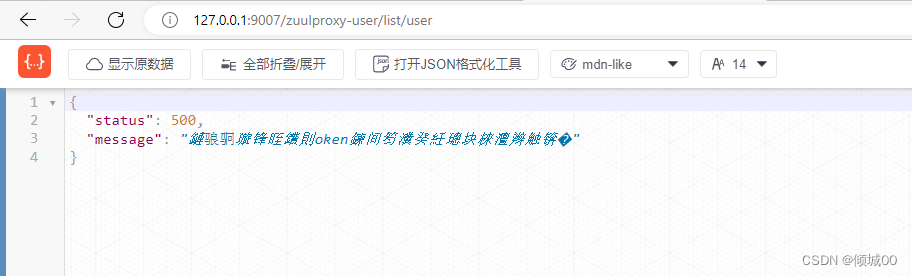
代码 - 创建config文件夹,创建类
package com.bj.sh;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import com.netflix.zuul.exception.ZuulException;
import org.springframework.cloud.netflix.zuul.web.ZuulController;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* @author LXY
* @desc
* @time 2022--12--07--21:39
*/
public class preReqestFilet extends ZuulFilter {
@Override
public String filterType() {
/** * pre类型的Filter总是先执行,它可以做限流,权限控制等。
* * route类型的Filter为Zuul内部转发请求到真正的服务的Filter,一般我们不需要实现这种类型.
* * post为请求转发完成后的后续动作,可以进行日志等的一些添加。
* * error为上述Filter出错后执行的动作,可以进行错误处理等。
* *
*/
return "pre";
}
@Override //filterOrder返回同类型filter执行顺序,数字越大,优先级越低
public int filterOrder() {
return 0;
}
//shouldFilter返回请求是否应该执行run方法
@Override
public boolean shouldFilter() {
//判断是不是执行的list 方法,如果不是的话就拦截了
RequestContext ctx = RequestContext.getCurrentContext();
String url = ctx.getRequest().getRequestURI().toLowerCase();
if (url.contains("/list")){
System.out.println("本次请求的url:"+url+" 满足条件可以执行");
return true;
}
System.out.println("不满足条件");
return false;
}
/**
* run:表示业务逻辑执行过程。
* 处理逻辑过程中如果需要用到HttpServletRequest和HttpServletResponse可以用RequestContext.getCurrentContext()拿出。
*
*/
@Override
public Object run() throws ZuulException {
RequestContext context = RequestContext.getCurrentContext();
HttpServletRequest request = context.getRequest();
HttpServletResponse response = context.getResponse();
System.out.println("启动自定义过滤器");
String token="ABC";
if (token.equals("ABCE")){
return true;
}
response.setCharacterEncoding("UTF-8");
//对该请求禁止路由,也就是禁止访问下游服务
context.setSendZuulResponse(false);
//设定responseBody供本次进行响应返回
context.setResponseBody("{\"status\":500,\"message\":\"本次请求的token值不对,访问失败!\"}");
return false;
}
}
- 在启动类中进行注入
package co.bj.sh;
import com.bj.sh.preReqestFilet;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.zuul.EnableZuulProxy;
import org.springframework.cloud.netflix.zuul.EnableZuulServer;
import org.springframework.context.annotation.Bean;
/**
* @author LXY
* @desc
* @time 2022--12--06--22:35
*/
@SpringBootApplication
@EnableZuulProxy //加上zuul代理注解即可让当前项目启动的时候加载到zuul组件。
public class SpringCloud_zuul_9007 {
public static void main(String[] args) {
SpringApplication.run(SpringCloud_zuul_9007.class,args);
}
@Bean
public preReqestFilet getpreReqestFilet(){
return new preReqestFilet();
}
}
- 也可以实现黑白名单,ip限制等等操作,
- 正常情况,地址正确,且ip地址正确的是可以获取到数据的
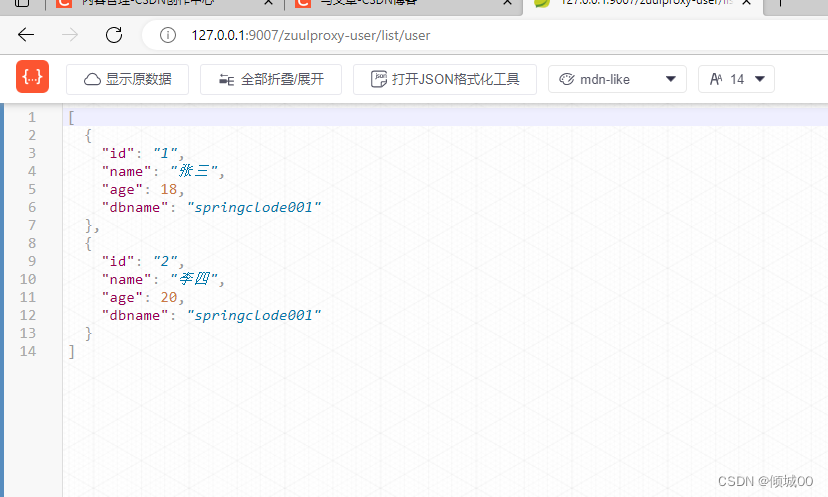
八:Config
-
假定我们的微服务项目中有20个子系统,且各个系统的分布式不同的不服务器上,当项目迭代或者迁移
的时候我们需要更改这20个系统中大部分的application.yml中的配置,例如端口,ip,服务名字等。诚然这些我们修改是没问题的,但是一般项目部署的时候是需要运维人员进行操作,其实如果修改20个配置文件也是一个很大的工作量,
那么能不能找一个集中的地方配置(或者我们可以叫中心化的外部配置),然后分布在不同服务器上的子系统他们分别的动态调用呢?如果可以的话那就太好了,就是在这样的一个愿景下配置中心SpringCloud Config 出现了 -
什么是SpringCloud Config :
SpringCloud Config 是springcloud技术栈中的一个组件,其作用是一个分布式配置中心。
SpringCloud Config 为微服务架构中的微服务提供集中化/中心化的外部配置支持,配置服务器为各个不同微服务应用的所有环境提供了一个中心化的外部配置。 -
SpringCloud Config的组成:
SpringCloud Config 分为服务端和客户端两部分
服务端:服务端也称为分布式配置中心,它是一个独立的微服务应用,来连接配置服务器并为客户端提供获取配置信息、加密/解密信息等访问接口
客户端:客户端则是通过指定的配置中心来管理应用资源,以及与业务相关的配置内容,并在启动的时候从配置中心获取和加载配置信息配置服务器默认采用 git 来存储配置信息,
这样就有助于对环境配置进行版本管理,并且可以通过 git 客户端工具来方便的管理和访问配置内容 -
SpringCloud Config 能干嘛
1) 集中管理配置文件
2)不同环境不同配置,动态化的配置更新,分环境部署比如dev(开发)/test(测试)/prod(生产)/beta(抢先预览版)/release(灰度)
3)运行期间动态调整配置,不再需要在每个服务部署的机器上编写配置文件,服务会向配置中心统一拉取配置自己的信息
4)当配置发生变动时,服务不需要重启即可感知到配置的变化并应用新的配置
5)将配置信息以REST接口的形式暴露
4.SpringCloud Config 怎么用:
由于 SpringCloud Config 默认使用 Git 来存储配置文件(也有其它方式,比如支持 svn 和本地文件,但最推荐的还是 Git,而且使用的是 http/https 访问的形式),所以这里默认是使用 github或者gitee或者gitlab来做配置文件的存放地址
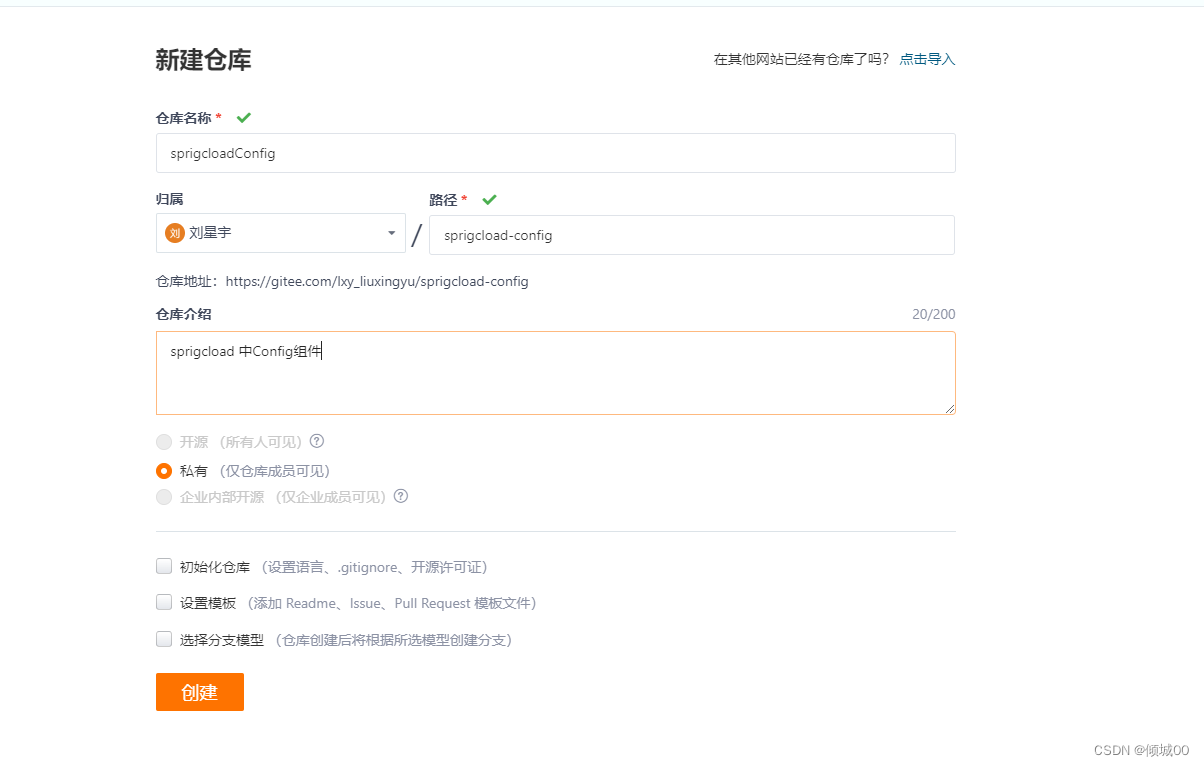
8.1 git的环境准备
- 在gitee上新建仓库
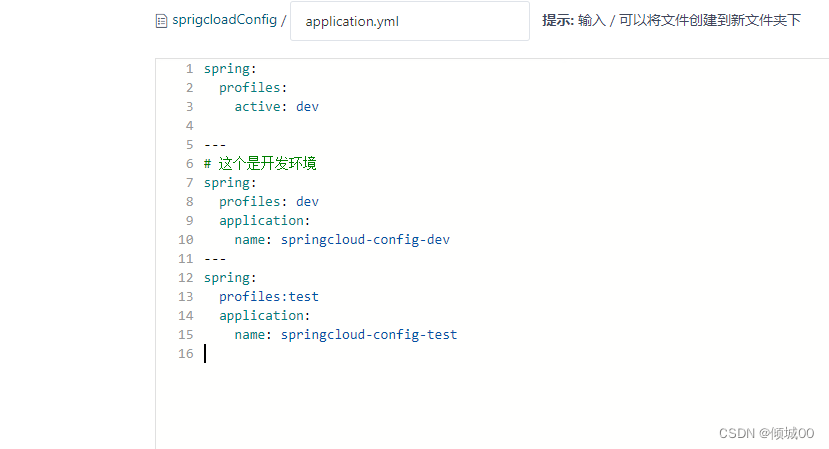
spring:
profiles:
active: dev
---
# 这个是开发环境
spring:
profiles: dev
application:
name: springcloud-config-dev
---
spring:
profiles: test
application:
name: springcloud-config-test
- 这里写了两个环境,默认是启动dev环境
8.2 Config的准备
- 新建项目 SpringCloud-CConfig-3344项目
- pom
<dependencies>
<!--1.config配置中心-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
<version>2.0.5.RELEASE</version>
</dependency>
<!--2.springboot的web模块(Spring+Springmvc)-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--3.actuator完善监控信息-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
- yml 文件
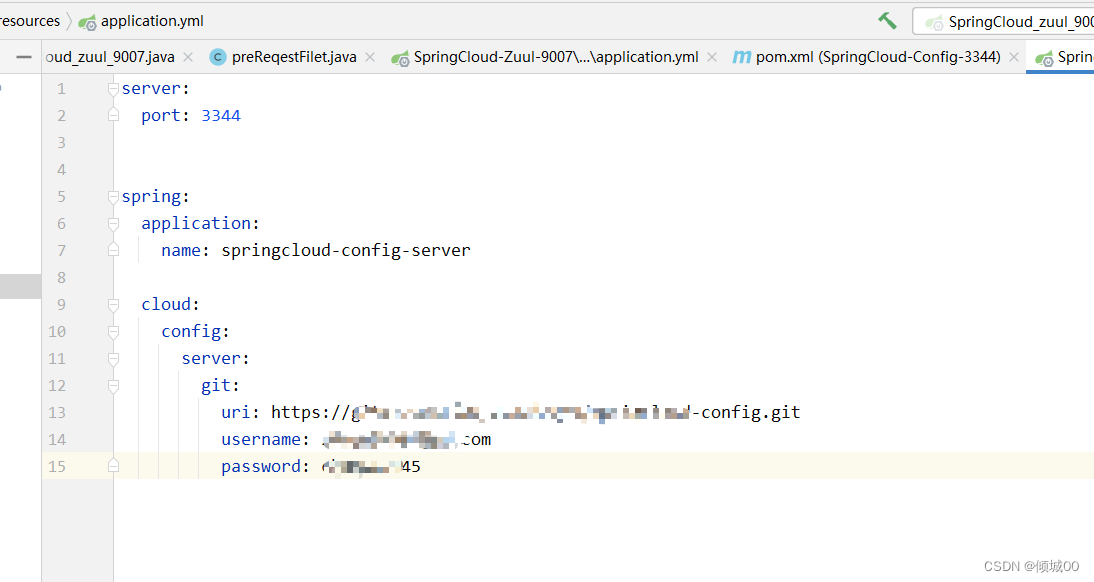
server:
port: 3344
spring:
application:
name: springcloud-config-server
cloud:
config:
server:
git:
uri: xxx
username: xxx
password: xxx
- 启动类
package com.rj.bd;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.config.server.EnableConfigServer;
/**
* @author LXY
* @desc
* @time 2022--12--08--20:14
*/
@SpringBootApplication
@EnableConfigServer
public class SpringCloud_Config {
public static void main(String[] args) {
SpringApplication.run(SpringCloud_Config.class,args);
}
}
- 启动3344项目
- 启动的时候会有一个下载地址
- 这个是自动下载git仓库的文件
浏览器访问
http://localhost:3344/application-dev.yml
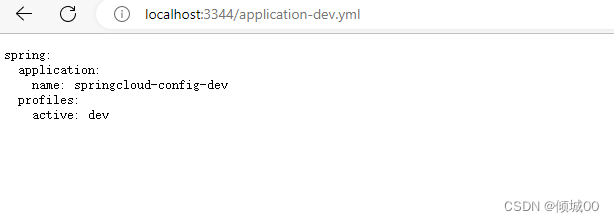
- 可以显示dev环境,并且默认是dev环境
- 在访问 http://localhost:3344/application-test.yml
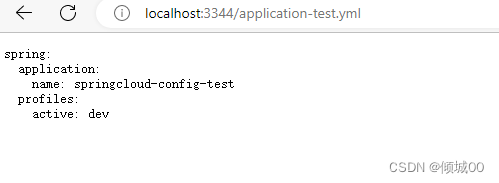
- 可以显示test环境,并且默认是dev环境
http://127.0.0.1:3344/application/dev/master
http://127.0.0.1:3344/application-dev.yml
http://127.0.0.1:3344/master/application-dev.yml
http://127.0.0.1:3344/application-dev.properties
http://127.0.0.1:3344/master/application-dev.properties
- 这几种方式都可以获取,推荐第二种或者第三
8.3 设置超时时间
request-read-timeout: 1000 #配置读取超时
request-connect-timeout: 3000 #配置连接超时
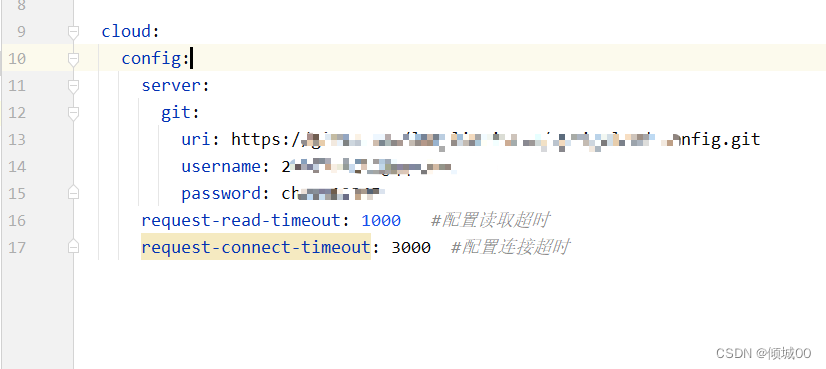
-配置了连接超时,断网了,还可以访问到数据,因为是读取的本地仓库的内容
8.4 对原有项目进行操作
-pom
<!--0.config-client(这个是config客户端使用)-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
<version>2.0.5.RELEASE</version>
</dependency>
- bootstrap.yml
spring:
cloud:
config:
uri: http://127.0.0.1:3344
label: master
name: config-provider-user
profile: dev
- application.yml
- 在git上创建 config-provider-user.yml文件
spring:
profiles:
active: dev
---
# 服务启动的端口8001
server:
port: 8001
spring:
profiles: dev
application:
name: springCloud-user
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/springcloud001?userSSL=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
# 将自己注册到8001上
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: springCloud-user-8001-l
info:
app.name: springCloud-user-8001-LXY #显示的应用的名字
company.name: com.xxx.xxx #公司的名字
---
#1.springcloud-provider-user-hystrix-8001自身的配置
server:
port: 8001 #本次子项目发布的端口
#2.mybatis的配置
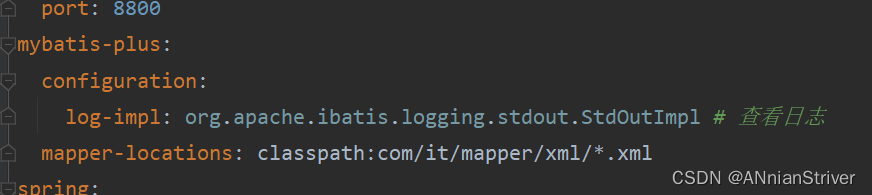
mybatis:
type-aliases-package: com.rj.bd.pojo #mybatis中实体类对应的路径,这样配置了之后,我们在映射文件中就可以不写路径了
config-location: classpath:mybatis/mybatis-config.xml
mapper-locations: classpath:mybatis/mapper/*.xml
#3.spring配置
spring:
profiles: test #且测试环境下连接的是springcloud002这个数据库
application:
name: springcloud-provider-user
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/springcloud002?userSSL=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
#4.eureka在provider-user-hystrix-8001这个子系统使用的配置,目的是将当前项目的服务注册到“注册中心-eureka7001”中
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:7001/eureka/,http://127.0.0.1:7002/eureka/,http://127.0.0.1:7003/eureka/
instance:
instance-id: springcloud-provider-user-hystrix-8001
#5.服务监控的信息配置
info:
app:
name: springcloud-provider-user-hystrix-8001-wyh #显示的应用的名字
company:
name: com.wyh.com #公司的名字
-
启动7001,7002,7003,3344(config),8001项目,我们的8001项目的application.yml 上面是空的
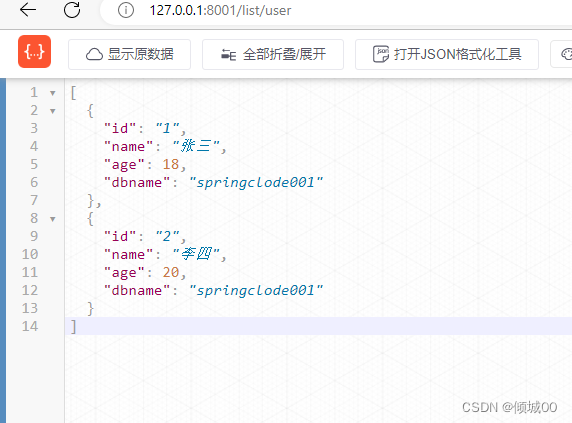
-
然后启动项目,我们虽然没有配置,但是成功的在git上读取了
-
我们创建bootstrap.yml文件之后,我们发现他的图标和application.yml很类似,即被spingcloud框架识别了,那么二者有什么区别呢?
1)角色:application.yml是用户级别的配置文件, bootstrap.yml是系统级别的配置文件,优先级更高
2)功能:application.yml是设定springcloud-config-client-3355子项目内容的。bootstrap.yml在子项目springcloud-config-client-3355启动之前获取config-server-3344中的内容(直白的说就是从本地仓库获取配置文件) -
我们是通过bootstrap.yml文件进行获取文件的
8.5 动态刷新Config的客户端
- 在正常的开发过程中,Gitee上的配置文件肯定会经过更改,那么这样的话也没啥事啊,的确是没什么太大的事,但是如果我们config客户端比较多的时候,假定有20个子config客户端子系统,如果今天中午运维要切换一下数据库的ip地址,这样的话
就会导致20个子系统要重新启动一下,因为Gitee上内容更改,config-server-3344这样的config服务端是不需要重启的,但是我们的20个config客户端需要重新启动,假定启动一个需要1分钟,那么这样的话需要至少20分钟的时候。此时项目就会有20分钟的服务掉线
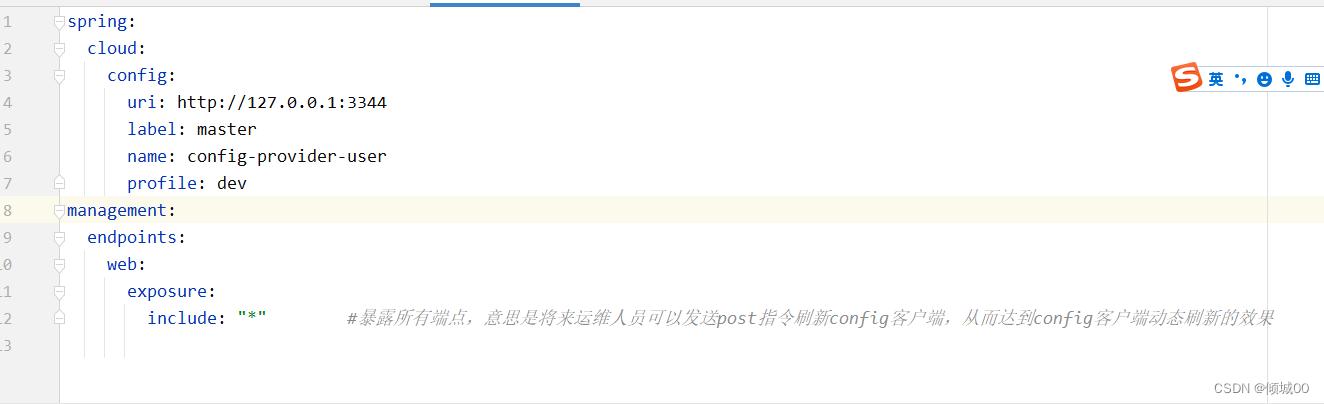
时间,这是非常可怕的。那么有没有什么办法在Gitee切换了数据库ip之后,config客户端尽可能的少的重新启动或者,尽可能耗时短一些的启动呢 - 新增是在客户端8001的项目上做改动
# 系统级别的配置
spring:
cloud:
config:
uri: http://localhost:3344
label: master
name: config-provider-user # 需要从git上读取的资源文件的名称,不需要带上后缀
profile: dev
management:
endpoints:
web:
exposure:
include: "*" #暴露所有端点,意思是将来运维人员可以发送post指令刷新config客户端,从而达到config客户端动态刷新的效果
- 启动类
@RefreshScope
-确保config客户端添加了spring-boot-starter-actuator的组件(服务监控模块)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
- 测试
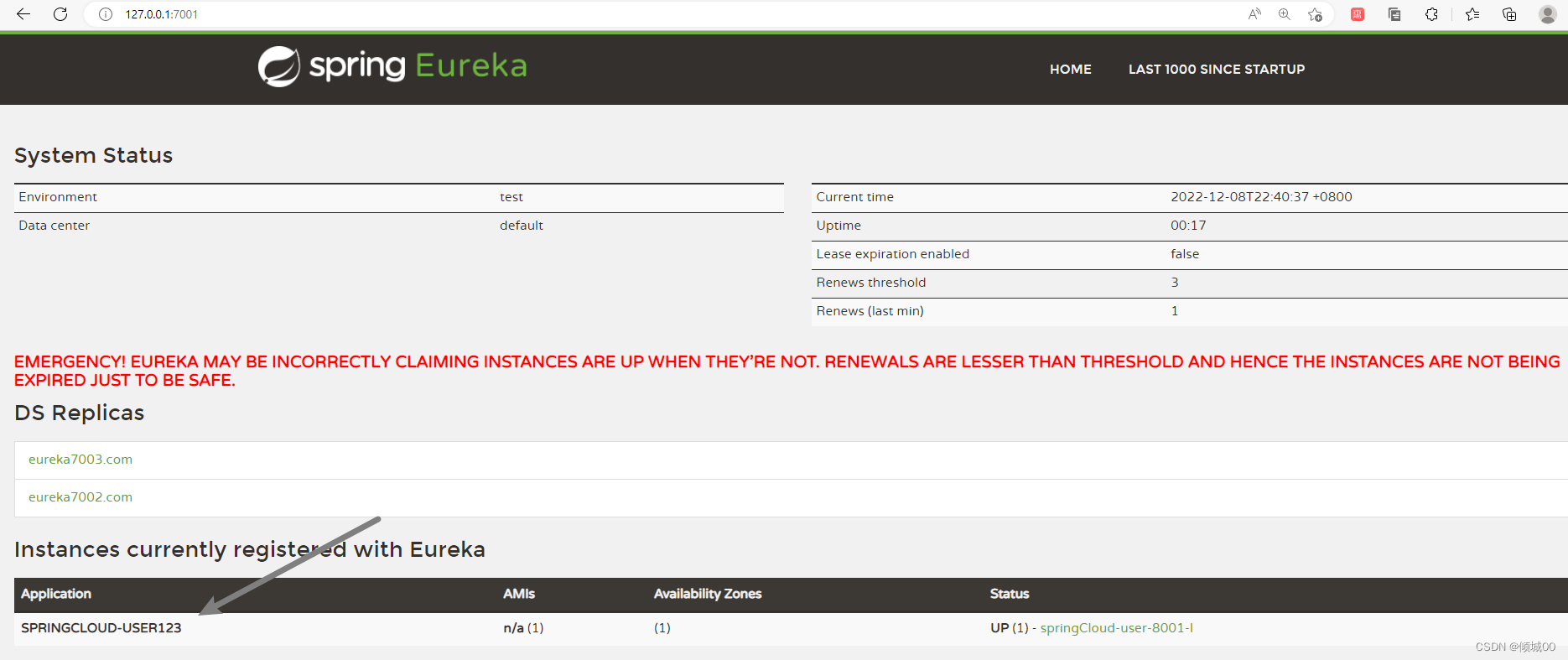
- 修改回来user
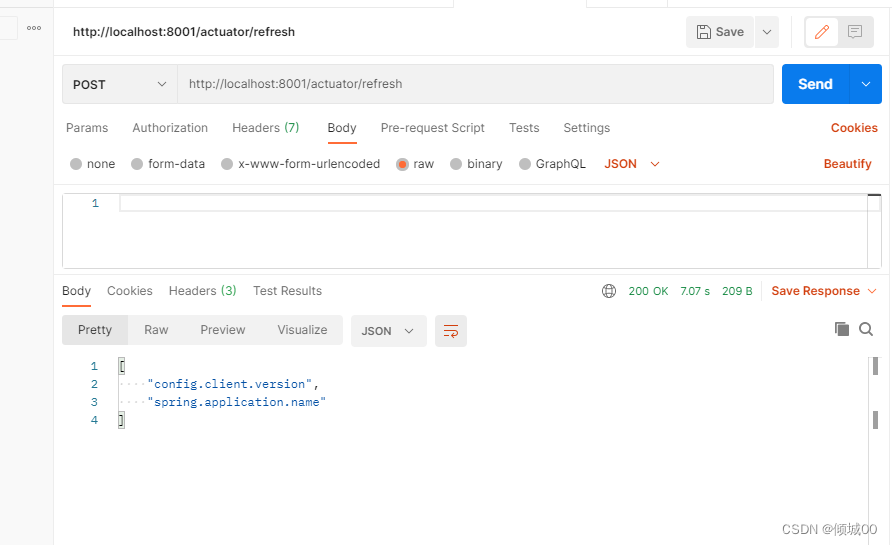
- 发送刷新请求
http://localhost:8001/actuator/refresh (post)
- 总结:需要有监控maven包,
- 需要有
九: 微服务网关 GateWay
- :Spring Cloud GateWay是Spring Cloud的⼀个全新项⽬,⽬标是取代Netflix Zuul,它基于Spring5.0+SpringBoot2.0+WebFlux(基于⾼性能的Reactor模式响应式通信框架Netty,异步⾮阻塞模型(或者最简单的理解为网络通信))等技术开发,
性能⾼于Zuul1.x,官⽅测试,GateWay是Zuul1.x的1.6倍,旨在为微服务架构提供⼀种简单有效的统⼀的API路由管理⽅式 - Spring Cloud GateWay不仅提供统⼀的路由⽅式(反向代理)并且基于 Filter(定义过滤器对请求过滤,完成⼀些功能) 链的⽅式提供了⽹关基本的功能,例如:鉴权、流量控制、熔断、路径重写、⽇志监控等
ps:其实这些功能跟Zuul1.x来对比不算什么新的,因为Zuul1.x通过自定义过滤器也能实现。但是GateWay的强大在于他的网络请求是基于Netty实现的(异步非阻塞)。
GateWay的特点: - 基于 Spring Framework 5,Project Reactor 和 Spring Boot 2.0:使用的时候要注意Springboot的版本,同时也可以使用Spring高版本的新特性
- 动态路由:它也可以像zuul一样实现动态的给路由请求,说白了就是例如动态添加前缀
- Predicates 和 Filters 作用于特定路由:意思就是GateWay中有很多已经写好的Predicates(意思为断言:可以理解为一些功能强大的工具类),和一些已经写好的过滤器Filter
- 易于编写的 Predicates 和 Filters: 意思是我们可以使用它本身带的断言和过滤器,也可以自己根据规则自定义来实现增强。
GateWay的缺点: - SpringCloud-gateway使用的时候需要注意Springboot版本,需要是Springboot2.x
- springcloud-gateway可能会和Springdata-springSecurity不协调(不代表不能在同一个项目中使用,比较费劲),因为getaway是使用Spring Framework 方式作为容器,SpringSecurity是使用Server作为容器,不是无缝衔接的,
- Springcloud-gateway使用的时候需要有netty环境,换言之,就是需要用JAR包的形式才可以运行
9.1: GateWay路由实现
- 创建Springcloud-gateway-9008子项目
- pom
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--2.将gateway以服务的方式注册到erueka上-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
<!--3.actuator完善监控信息
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>-->
<!--4.springboot的web处理模块
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>-->
</dependencies>
- 启动类
package com.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
/**
* @author LXY
* @desc
* @time 2022--12--13--16:51
*/
@EnableEurekaClient //注册到eureka上
@SpringBootApplication
public class gateway9008 {
public static void main(String[] args) {
SpringApplication.run(gateway9008.class,args);
}
}
- yml文件
server:
port: 9008
spring:
application:
name: springcloud-gateway #2.当前项目运行的名字
cloud:
gateway: #3.服务网关gateway的配置
routes:
- id: provider-user-8002 #路由的ID,没有固定规则但要求唯一,建议配合服务名,就是我们当前给哪个子服务配置的路由的意思
uri: http://localhost:8002 #匹配后提供服务的路由地址(就是子服务的地址)
predicates:
- Path=/list/user/** #断言,路径相匹配的进行路由(就是我们当前访问的路径)
- id: customer-user-fegin-8008 #意思为子系统customer-user-fegin-8009配置的路由代理id
uri: http://localhost:8008 #子系统customer-user-fegin-8009的地址
predicates:
- Path=/user/** #断言:通过服务网关访问customer-user-fegin-8008的url
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: springCloud-user-8002-l
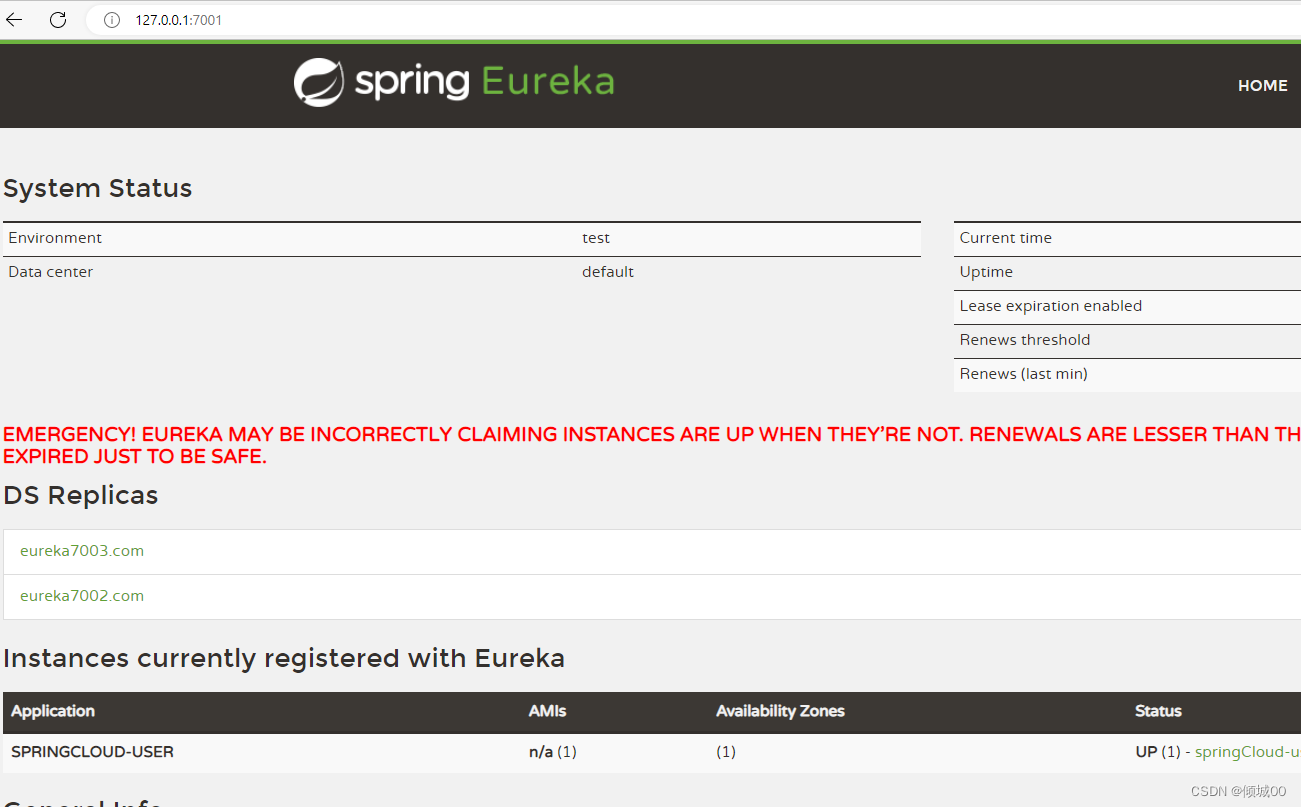
-然后启动7001,7002,7003,8002,8003,8008,9008
访问http://127.0.0.1:7001/
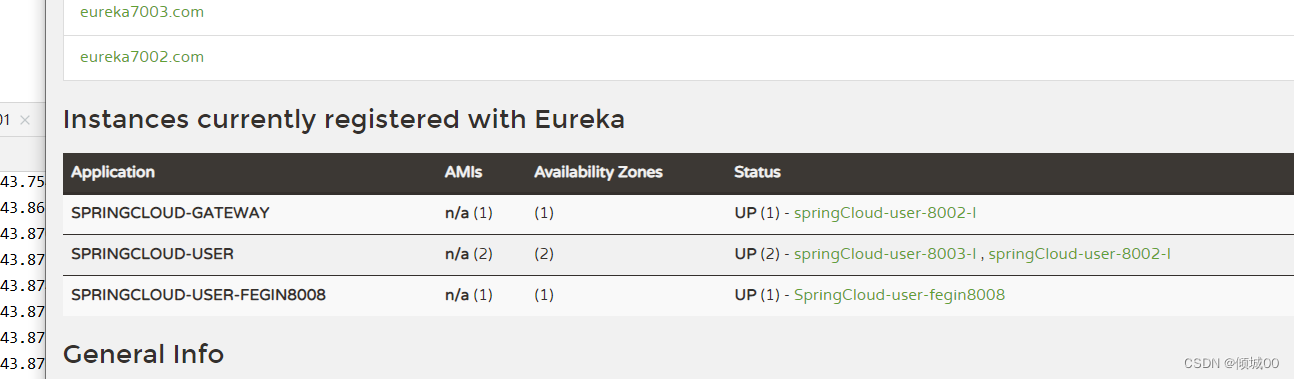
http://127.0.0.1:8008/user/quueryAllUserID/1
http://127.0.0.1:8002/list/user
- 上面两个网址是不使用路由,去获取数据
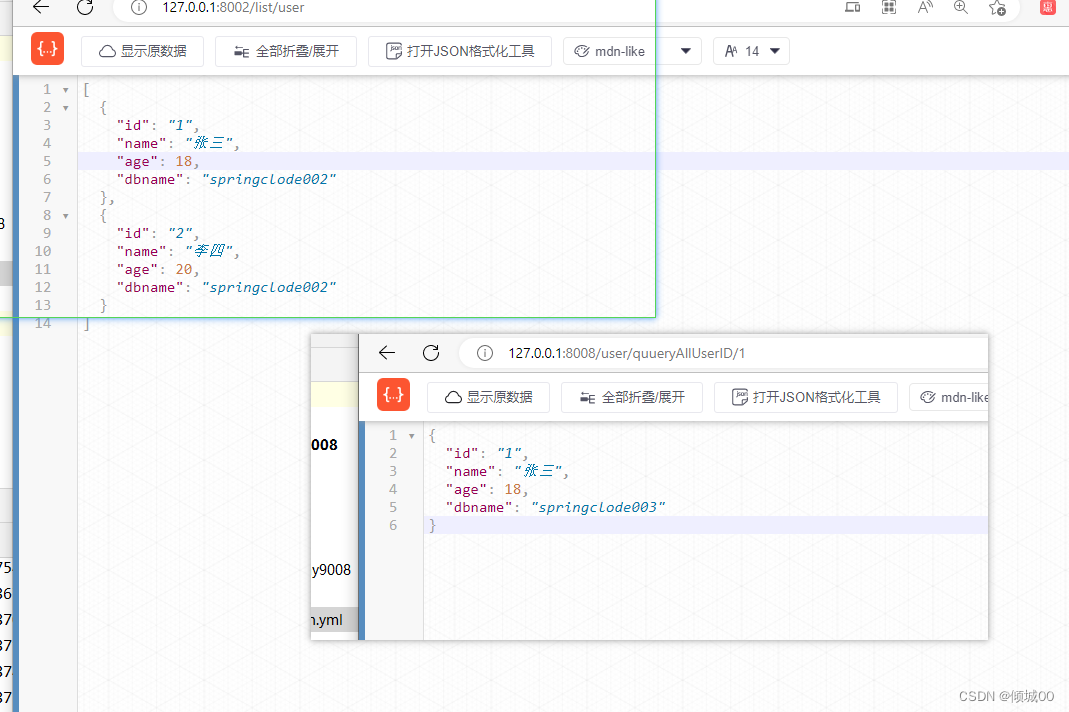
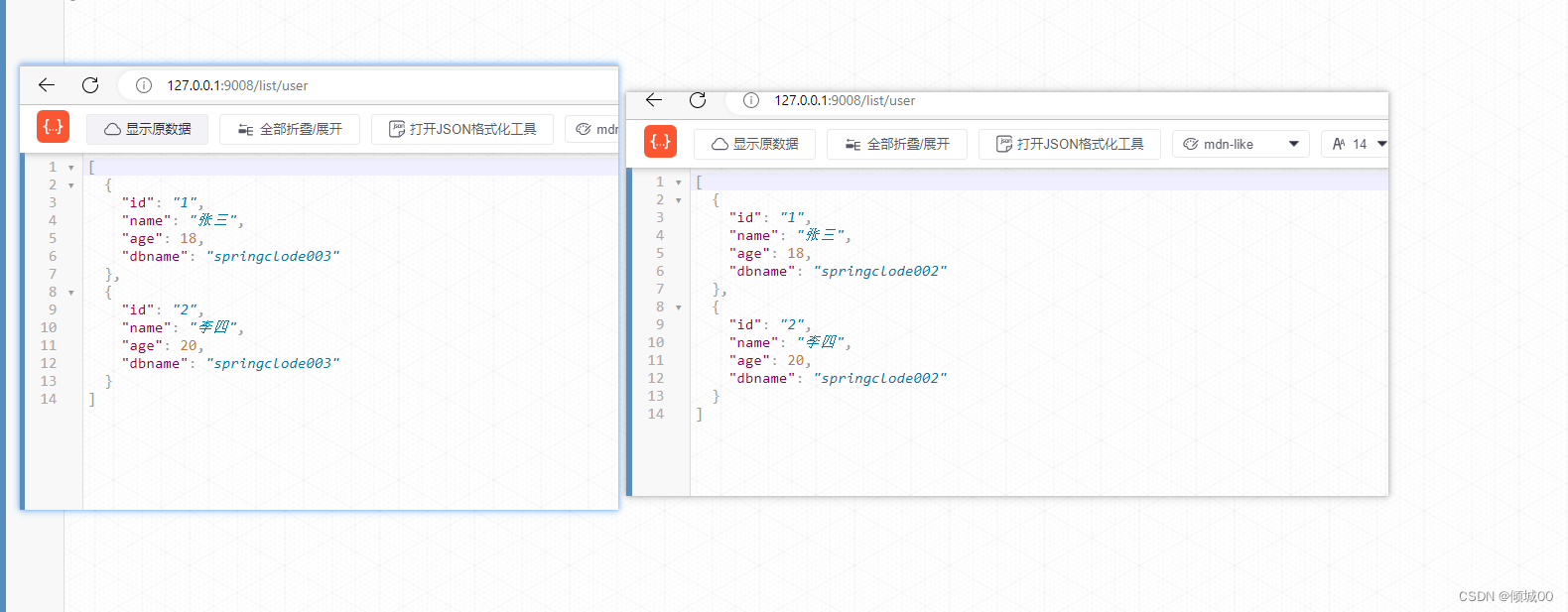
- http://127.0.0.1:9008/list/user
- http://127.0.0.1:9008/user/quueryAllUserID/1
- 以上这两个是通过gateway去路由的网址
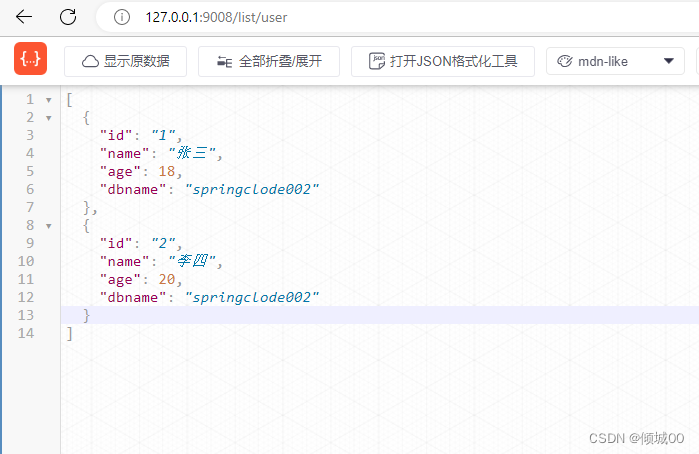
- yml模式路由成功
9.2 gateway实现负载均衡
- 之前路由的是8002一个项目,导致不通过fegin的话8003访问不到
- 修改yml文件,让其通过注册到eureak的名称去路由,就可以实现负载均衡了
- yml文件
server:
port: 9008
spring:
application:
name: springcloud-gateway #2.当前项目运行的名字
cloud:
gateway: #3.服务网关gateway的配置
discovery:
locator:
enabled: true #开启从注册中心动态创建路由的功能,其实就是利用已经注册到eureka上的服务名实现路由
routes:
- id: provider-user-8002 #路由的ID,没有固定规则但要求唯一,建议配合服务名,就是我们当前给哪个子服务配置的路由的意思
# uri: http://localhost:8002 #匹配后提供服务的路由地址(就是子服务的地址)
uri: lb://SPRINGCLOUD-USER
predicates:
- Path=/list/user/** #断言,路径相匹配的进行路由(就是我们当前访问的路径)
# -
# - id: provider-user-8002 #路由的ID,没有固定规则但要求唯一,建议配合服务名,就是我们当前给哪个子服务配置的路由的意思
## uri: http://localhost:8002 #匹配后提供服务的路由地址(就是子服务的地址)
#
# predicates:
# - Path=/list/user/** #断言,路径相匹配的进行路由(就是我们当前访问的路径)
- id: customer-user-fegin-8008 #意思为子系统customer-user-fegin-8009配置的路由代理id
uri: http://localhost:8008 #子系统customer-user-fegin-8009的地址
predicates:
- Path=/user/** #断言:通过服务网关访问customer-user-fegin-8008的url
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: springCloud-user-8002-l
9.3 GateWay之Predicates的使用
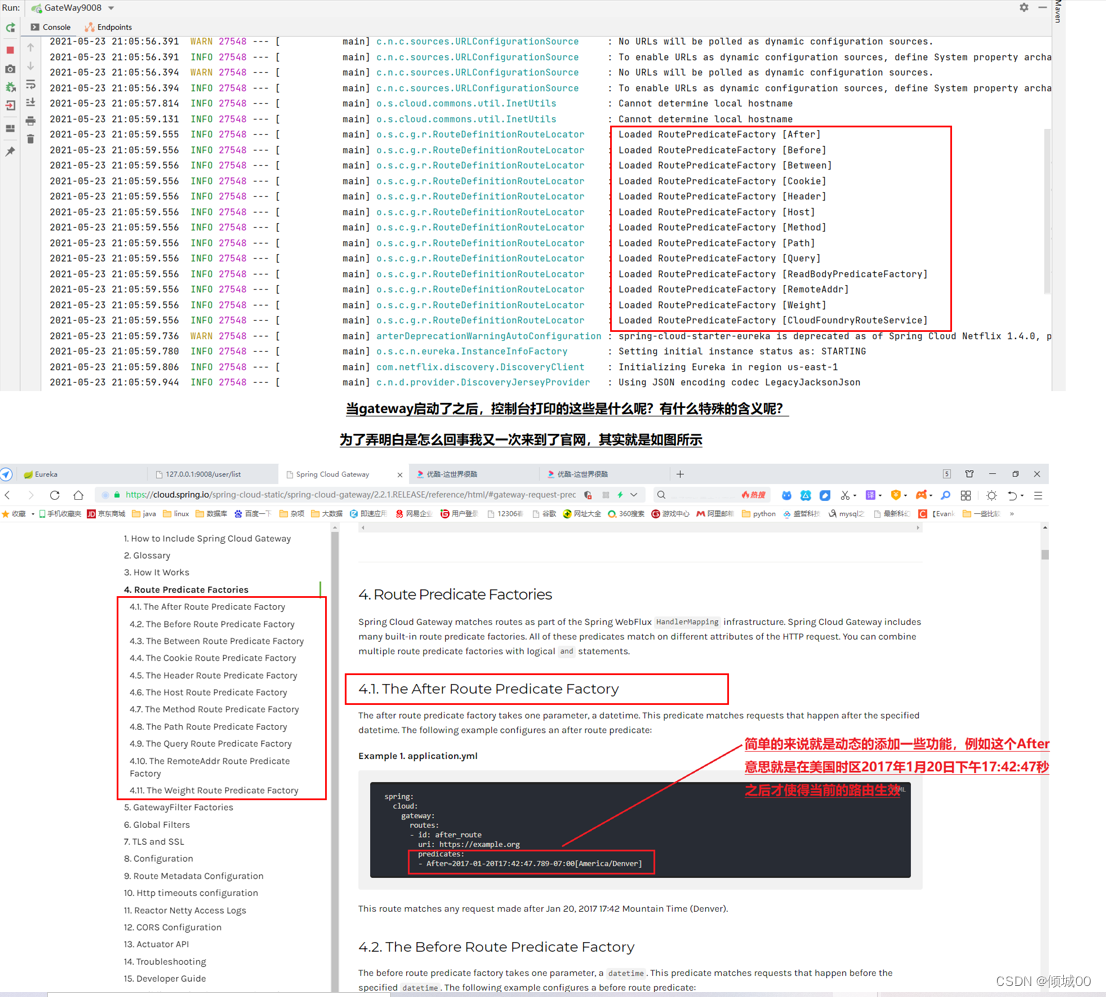
- 官网: https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/
- 演示效果图
修改yml
server:
port: 9008
spring:
application:
name: springcloud-gateway #2.当前项目运行的名字
cloud:
gateway: #3.服务网关gateway的配置
discovery:
locator:
enabled: true #开启从注册中心动态创建路由的功能,其实就是利用已经注册到eureka上的服务名实现路由
routes:
- id: provider-user-8002 #路由的ID,没有固定规则但要求唯一,建议配合服务名,就是我们当前给哪个子服务配置的路由的意思
# uri: http://localhost:8002 #匹配后提供服务的路由地址(就是子服务的地址)
uri: lb://SPRINGCLOUD-USER
predicates:
- Path=/list/user/** #断言,路径相匹配的进行路由(就是我们当前访问的路径)
- After=2022-12-14T23:26:17.458+08:00[Asia/Shanghai] #跟Before相反
# - Between=2022-12-14T23:26:17.458+08:00[Asia/Shanghai], 2022-12-14T23:26:17.458+08:00[Asia/Shanghai] #在这个范围之后是可以访问的
- id: customer-user-fegin-8008 #意思为子系统customer-user-fegin-8009配置的路由代理id
uri: http://localhost:8008 #子系统customer-user-fegin-8009的地址
predicates:
- Path=/user/** #断言:通过服务网关访问customer-user-fegin-8008的url
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: springCloud-user-8002-l
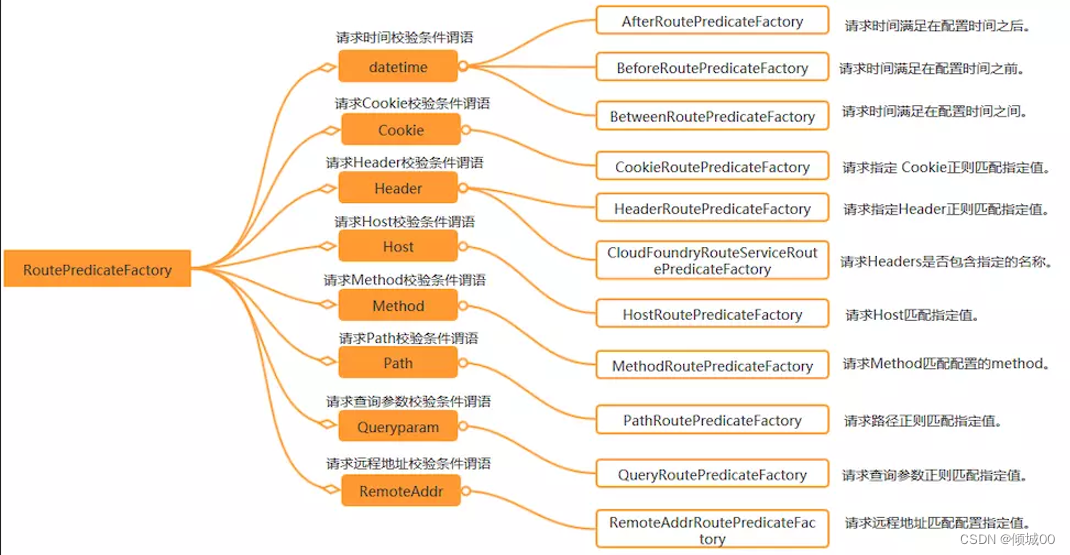
- 其他使用方式:

9.4 GateWay过滤器的使用
-
1.1Spring Cloud Gateway 的 Filter 的生命周期不像 Zuul 的那么丰富,它只有两个:“pre” 和 “post”。
1)PRE: 这种过滤器在请求被路由之前调用。我们可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。
2)POST:这种过滤器在路由到微服务以后执行。这种过滤器可用来为响应添加标准的 HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
1.2 Spring Cloud Gateway 的 Filter 分为两种:GatewayFilter 与 GlobalFilter。
1)GlobalFilter :会应用到所有的路由上,
2) GatewayFilter:将应用到单个路由或者一个分组的路由上
2.接下来我们就利用 GatewayFilter 可以修改Http 的请求或者响应为例子,,例如我们可以使用AddRequestParameter在请求中添加指定参数。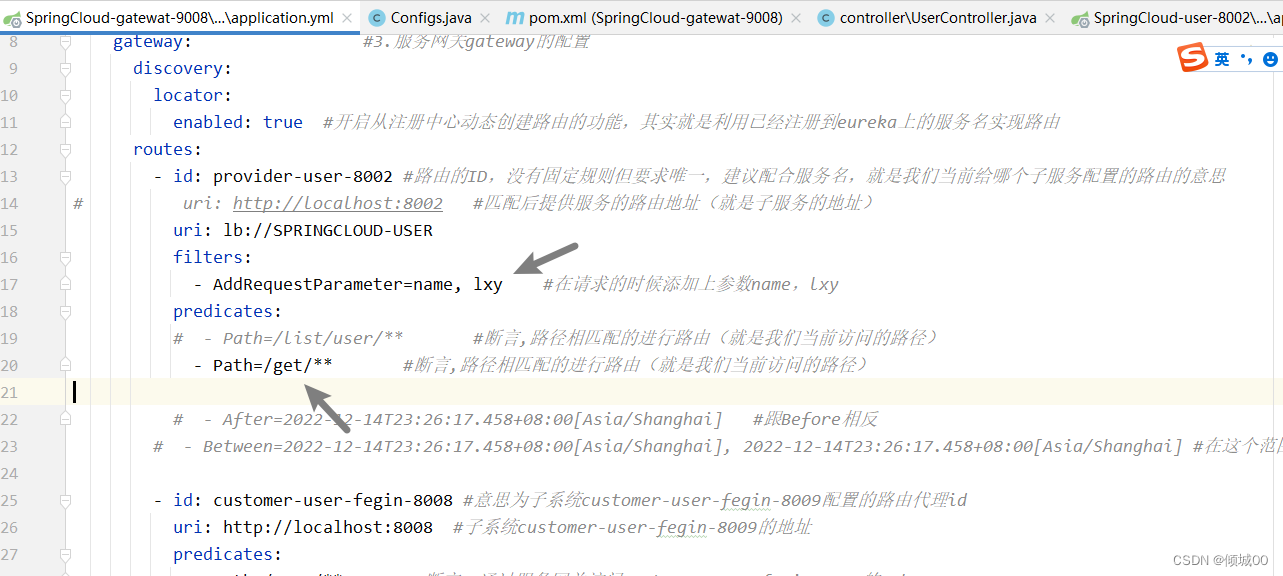
-
访问的时候发送一个name=lxy的http请求
-
在8002添加一个请求
@GetMapping("get/name")
public Object getname(String name){
return "name="+name;
}
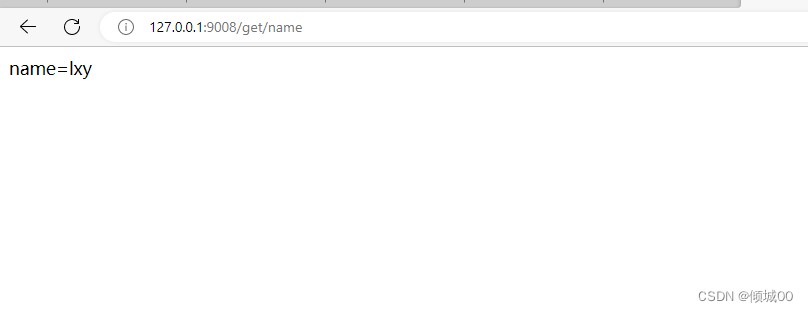
- 这样即使我们没传递,通过gateway路由过去的也会给我们自动添加请求参数
https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/#gatewayfilter-factories - 其他的过滤器地址
- 全局过滤器https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/#global-filters
- 这种的应用很少,都是用自定义的过滤器
9.5 自定义过滤器
- config文件
package com.ba.sh.filter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.Ordered;
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.nio.charset.StandardCharsets;
/**
* @author WYH
* @desc 自定义过滤器增强GateWay的功能
* @time 2021-05-24-1:25
*/
/**
* Ordered:是控制过滤器使用的顺序的
* GlobalFilter:是全局过滤器接口,实现它的目的是将来可以将MyRoutesFilter作用域全局
*/
@Component
@Slf4j
public class MyRoutesFilter implements GlobalFilter , Ordered {
/**
* 参考 GlobalFilter接口的实现类
*
* @param exchange
* @param chain
* @return
*/
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
log.info("---------执行全局过滤器-----------");
// 请求头或者请求参数中获取token
String token = exchange.getRequest().getHeaders().getFirst("token");
//String token = exchange.getRequest().getQueryParams().getFirst("token");
if (token.isEmpty()&& token==null) {
log.info("token is null");
ServerHttpResponse response = exchange.getResponse();
response.getHeaders().add("Content-Type", "application/json;charset=UTF-8");
// 401 用户没有访问权限
response.setStatusCode(HttpStatus.UNAUTHORIZED);
byte[] bytes = HttpStatus.UNAUTHORIZED.getReasonPhrase().getBytes();
DataBuffer buffer = response.bufferFactory().wrap(bytes);
// 请求结束,不继续向下请求
return response.writeWith(Mono.just(buffer));
}
// TODO 校验token进行身份认证
log.info("开始校验token,token={}", token);
return chain.filter(exchange);
}
/**
* 当有多个过滤器时, order值越小,越优先先执行
*
* @return
*/
@Override
public int getOrder() {
return 100;
}
}
十:Springcloud-Bus
- 我们只能是实现手动化的Config配置中心动态化,那么有没有自动化的Config配置中心动态化,其实是有的,即就是我们的Springcloud-Bus
- 什么是总线
(1)微服务架构的系统中,通常会使用轻量级的消息代理来构建一个共用的消息主题,并让系统中所有微服务实例都链接上来。由于该主题中产生的消息都会被所有实例监听和消费,所以称它为消息总线。
在总线上的各个实例,都可以方便地广播一些需要让其他连接在该主题上的实例都知道的消息 - Springcloud-Bus:它是Springcloud技术栈中实现消息总线的一个组件(你可以理解为是一个框架),使用轻量级的消息代理来连接微服务架构中的各个服务,可以将其用于广播状态更改(例如配置中心配置更改)或其他管理指令。
- Spring Cloud Bus是用来将分布式/微服务系统的节点与轻量级消息系统链接起来的框架, 它整合了Java的事件处理机制和消息中间件的功能。
- Springcloud-Bus的作用:
(1)SpringCloud Bus 能管理和传播分布式系统间的消息,就像一个分布式执行器,可用于广播状态更改、事件推送等,也可以当做微服务间的通信通道 - Springcloud-Bus的支持与实现
1) Springcloud-Bus现在只是支持RabbitMQ, kafka这两种MQ消息中间件。
2) SpringCloud-Bus经常是与Springcloud-Config一起使用。
- 使用springcloud bus之前需要有rabbitmq的环境
- Rabbitmq连接
- 原理就是利用Rabbitmq的广播交换机进行动态刷新
10.1:Springcloud-Bus代码实现
- 在3344上,就是我们的Config的服务端
- 添加pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>
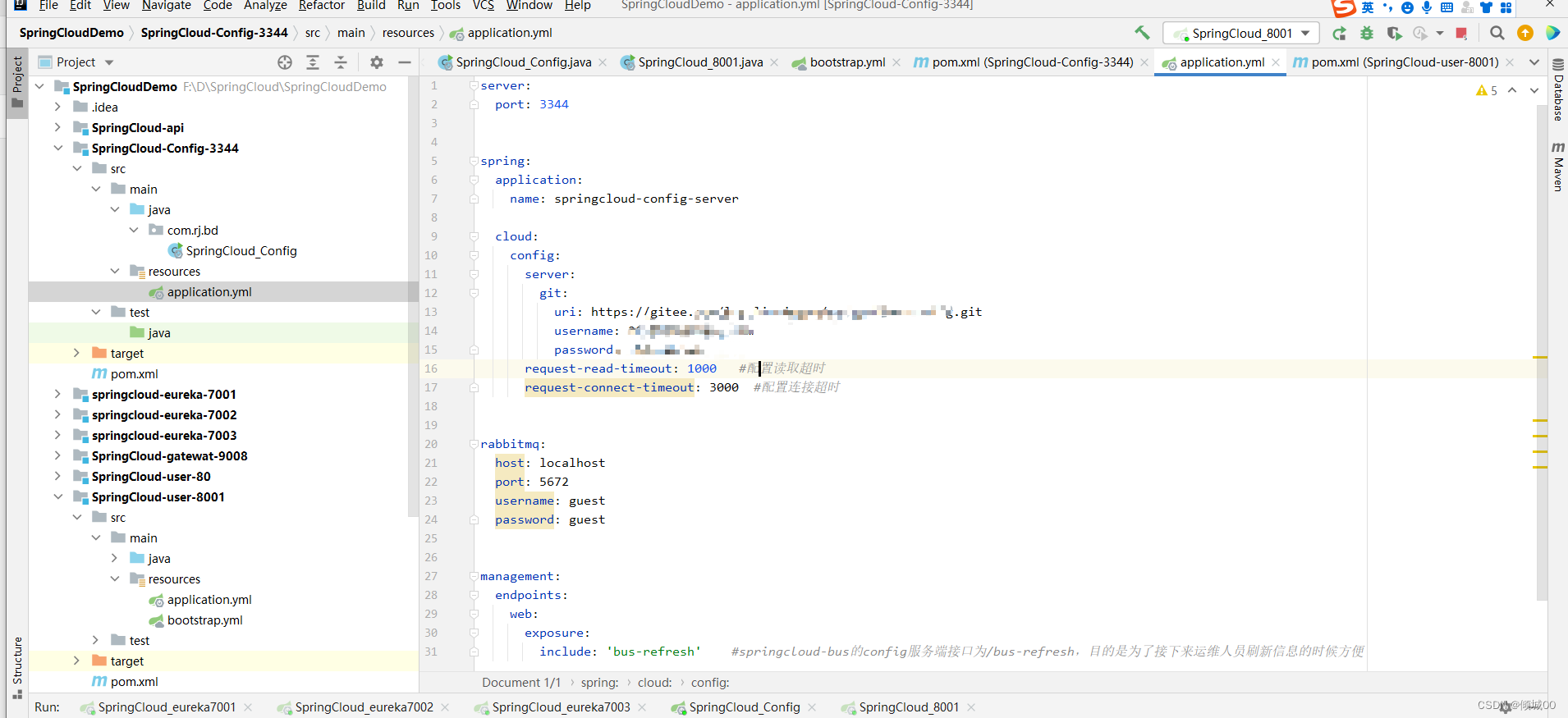
- yml文件
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
management:
endpoints:
web:
exposure:
include: 'bus-refresh' #springcloud-bus的config服务端接口为/bus-refresh,目的是为了接下来运维人员刷新信息的时候方便
- 在8001上,也就是config的客户端
- pom新增
<!--springcloud-bus的依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>
-bootstrap.yml文件
# 系统级别的配置
spring:
cloud:
config:
uri: http://localhost:3344
label: master
name: config-provider-user # 需要从git上读取的资源文件的名称,不需要带上后缀
profile: dev
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
management:
endpoints:
web:
exposure:
include: "*" #暴露所有端点,意思是将来运维人员可以发送post指令刷新config客户端,从而达到config客户端动态刷新的效果
- 启动7001,7002,7003,3344,8001
- 访问7001
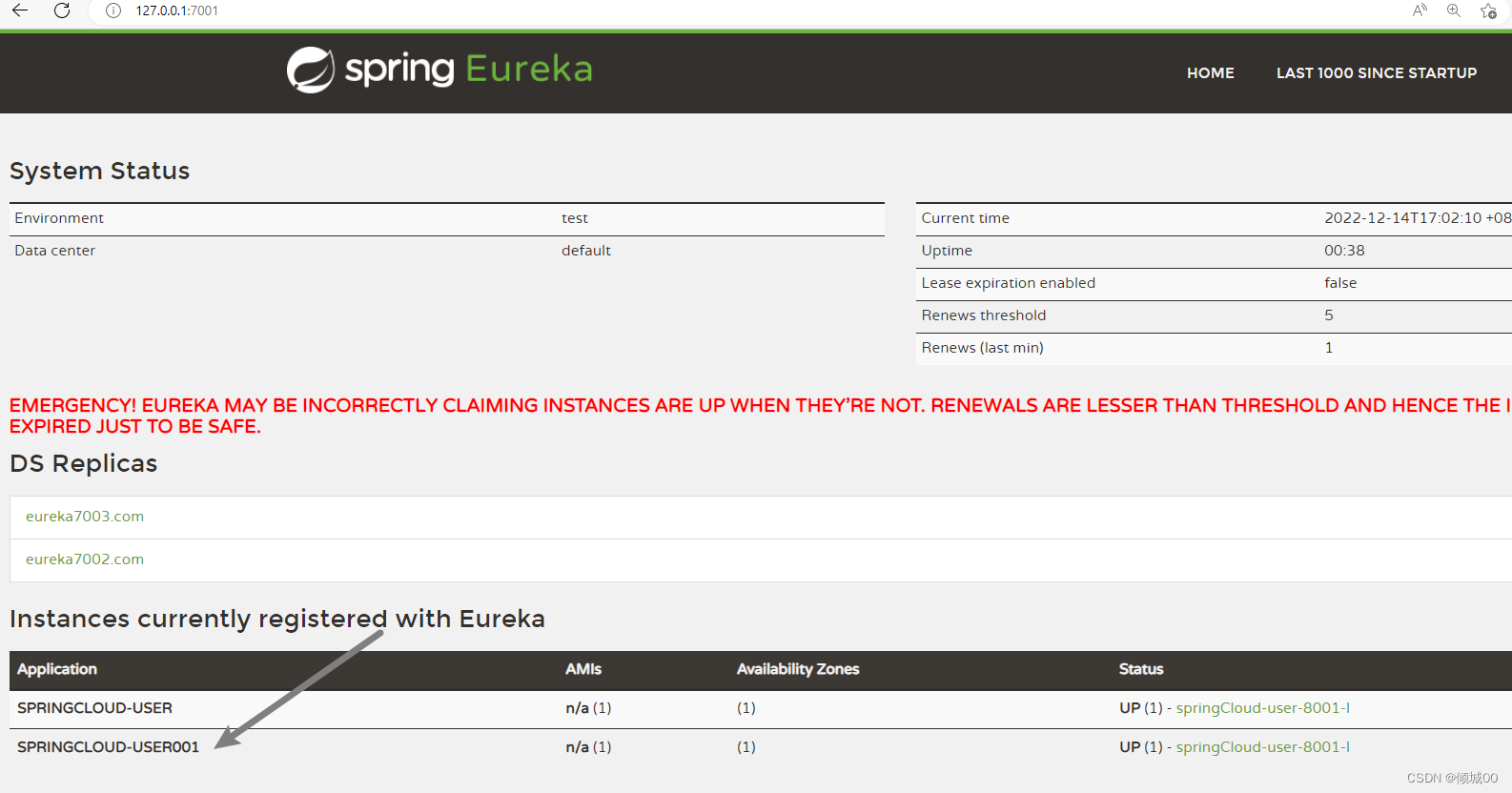
- 然后修改一下git的名字
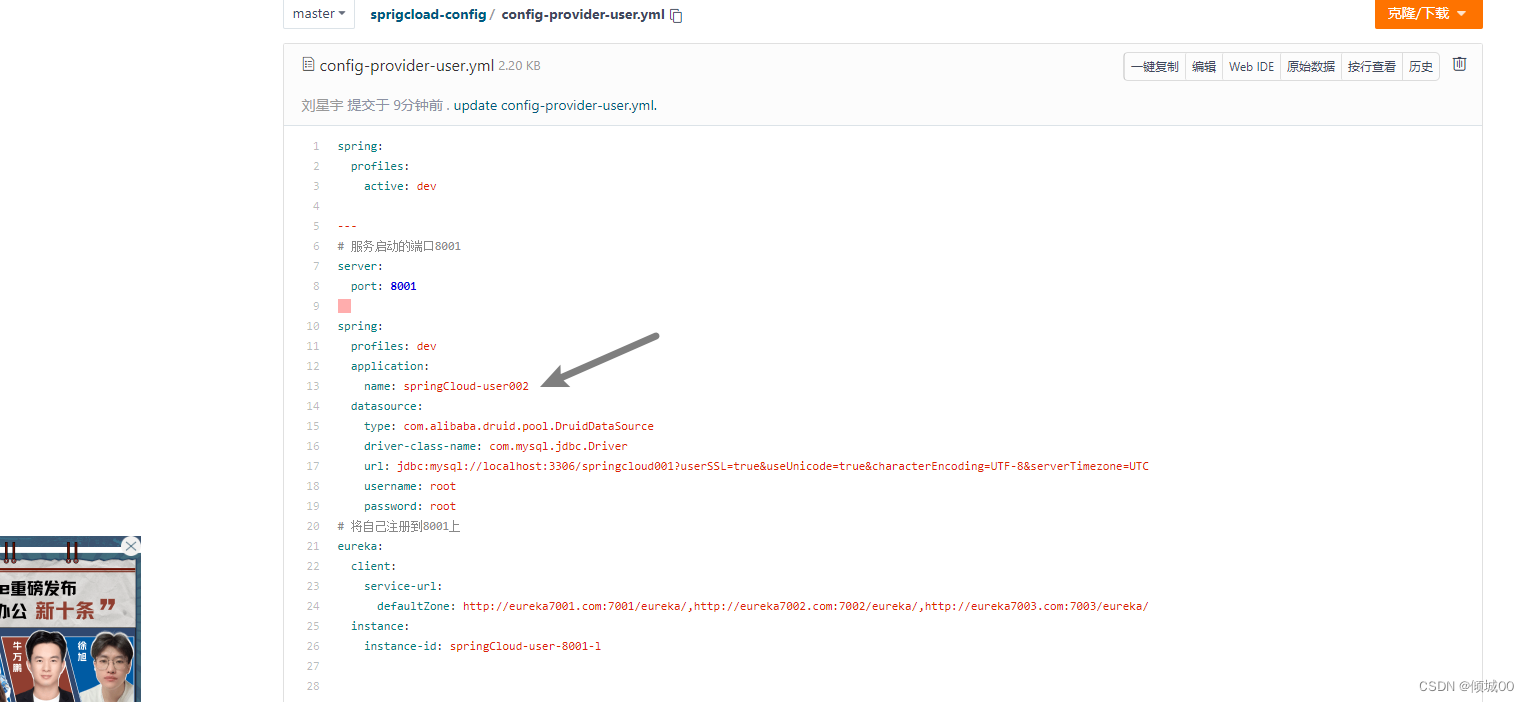
- 发送 http://localhost:3344/actuator/bus-refresh的一个post请求,执行刷新
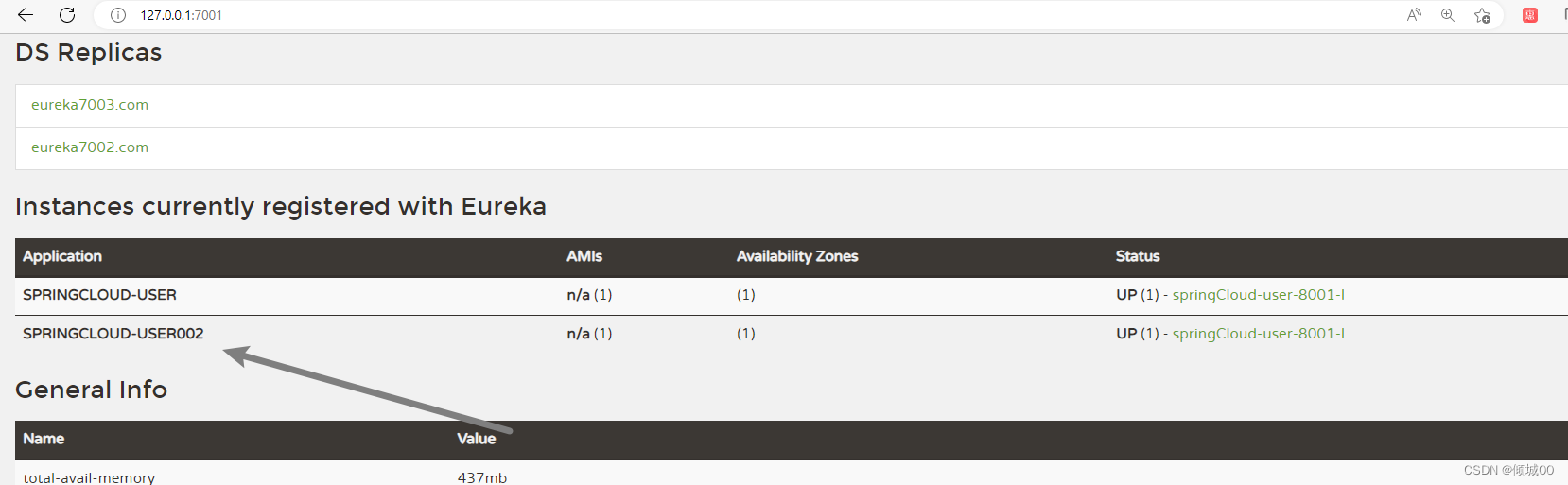
- 动态刷新成功,以后可以只需要刷新一次3344,所有的config的客户端就都可以刷新了
10.2 :Springcloud-Bus的定点刷新
- 说人话就是:想让哪个刷新就让哪个刷新
- 3344注册到eureak上
3344的pom
<!--将当前的config服务端注册到eureka集群中的依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
- yml文件
bus:
ack:
enabled: true
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: springCloud-user-8002-l
- 8001不用动,已经注册到eureak上了
- 首先访问7001
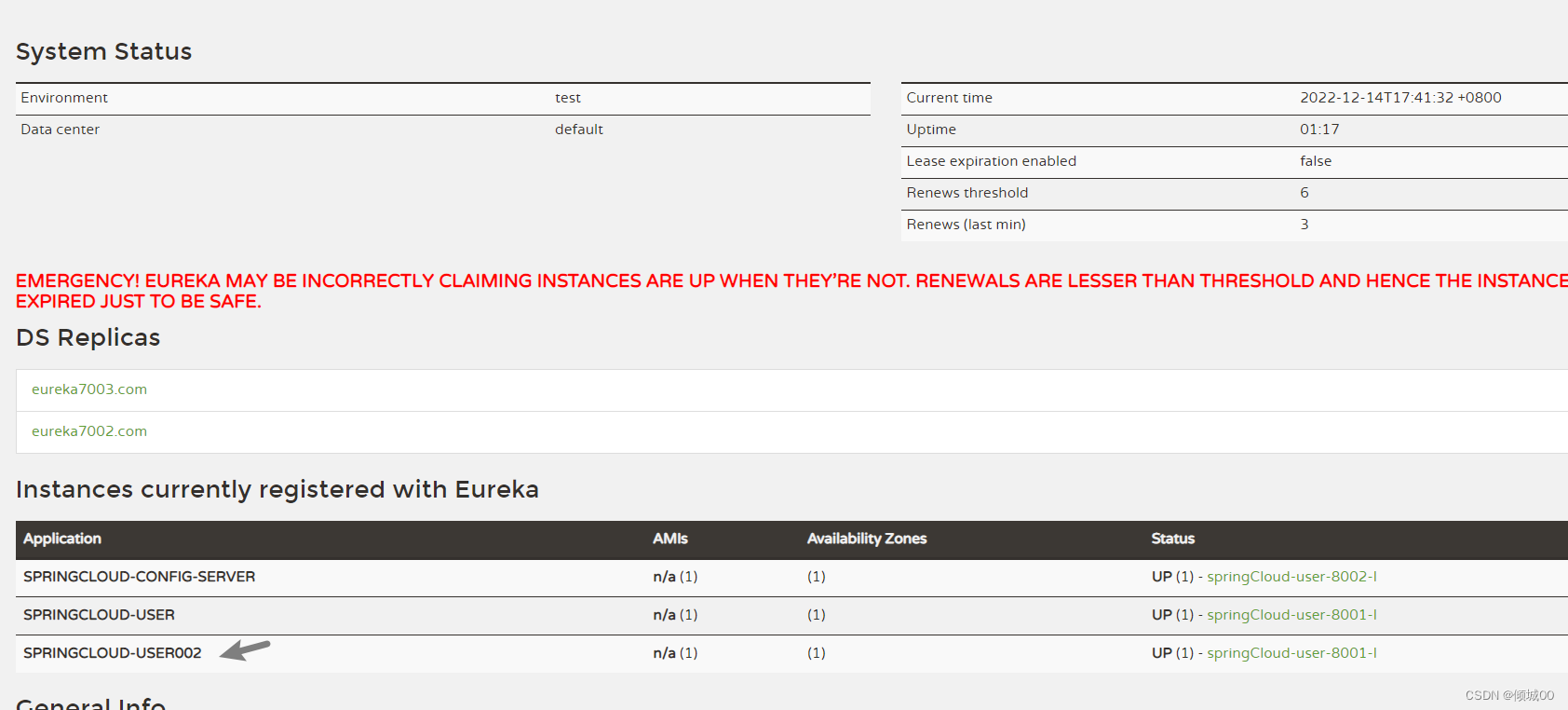
- 8001的名字是user002
- 然后再git上修改
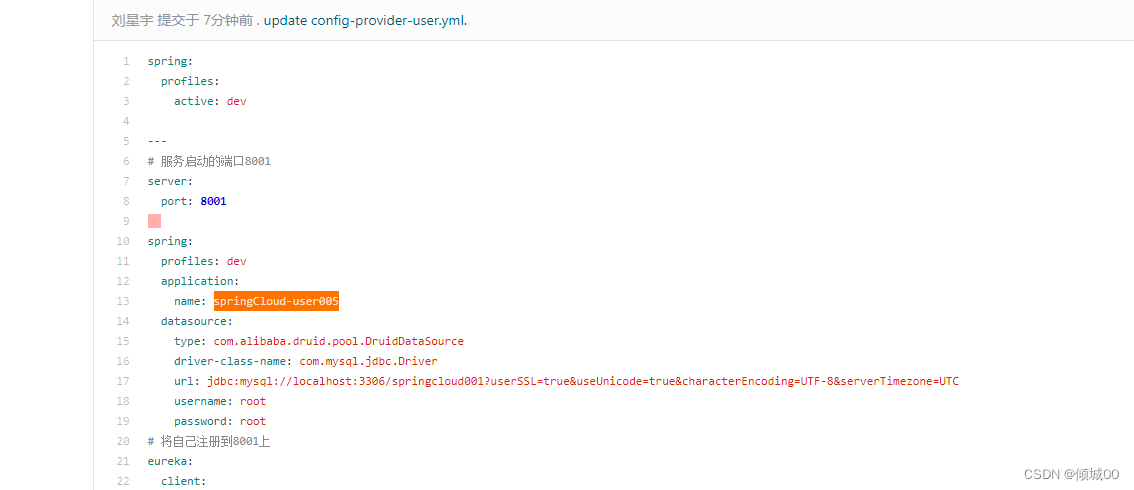
- 发送post指令 http://localhost:3344/actuator/bus-refresh/springCloud-user002:8001
- 只让8001修改,服务名字是springCloud-user002
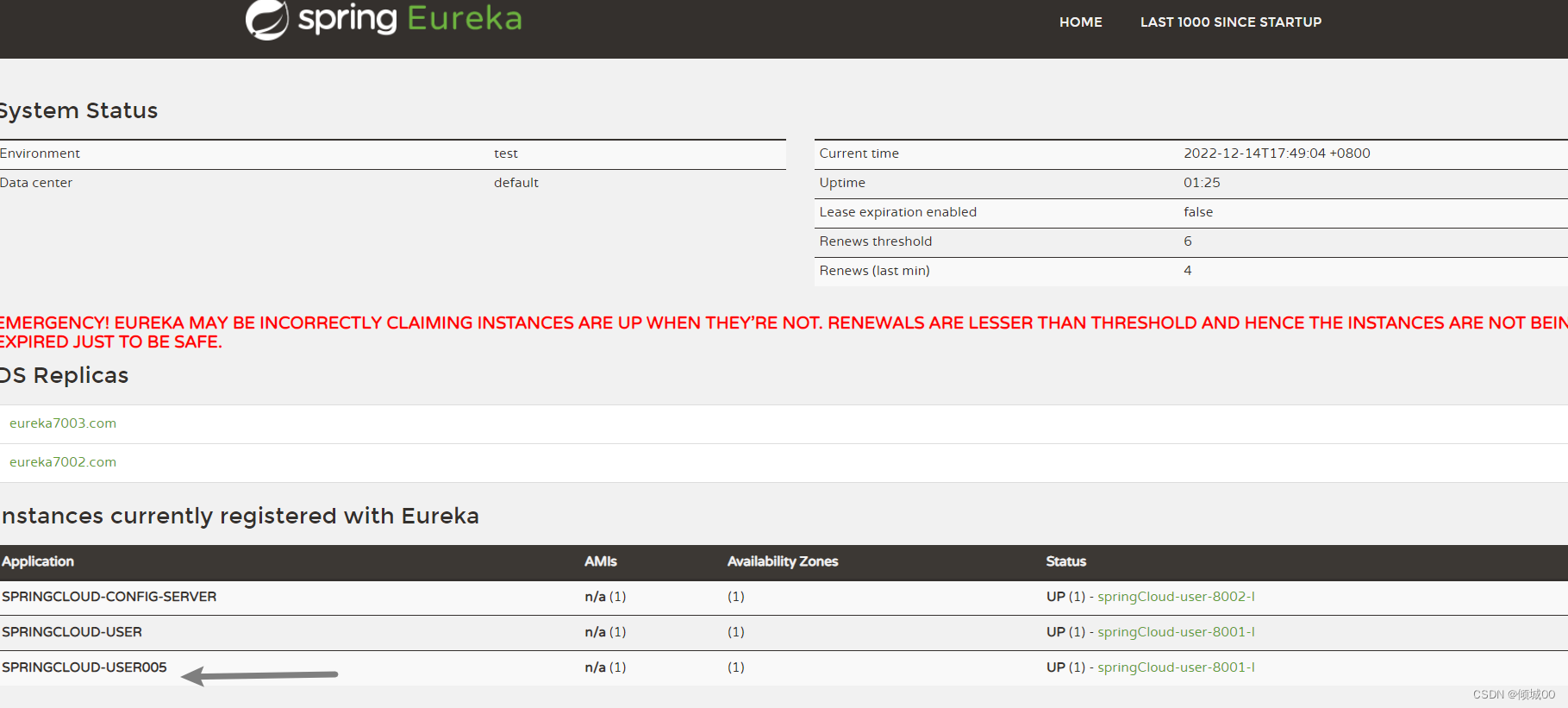
- 上面的post请求是刷新服务名:springCloud-user002端口是8001的
- 前提是3344和8001相互都注册到eureak上才能用服务名发现
10.3 SpringCloud-Bus的执行流程

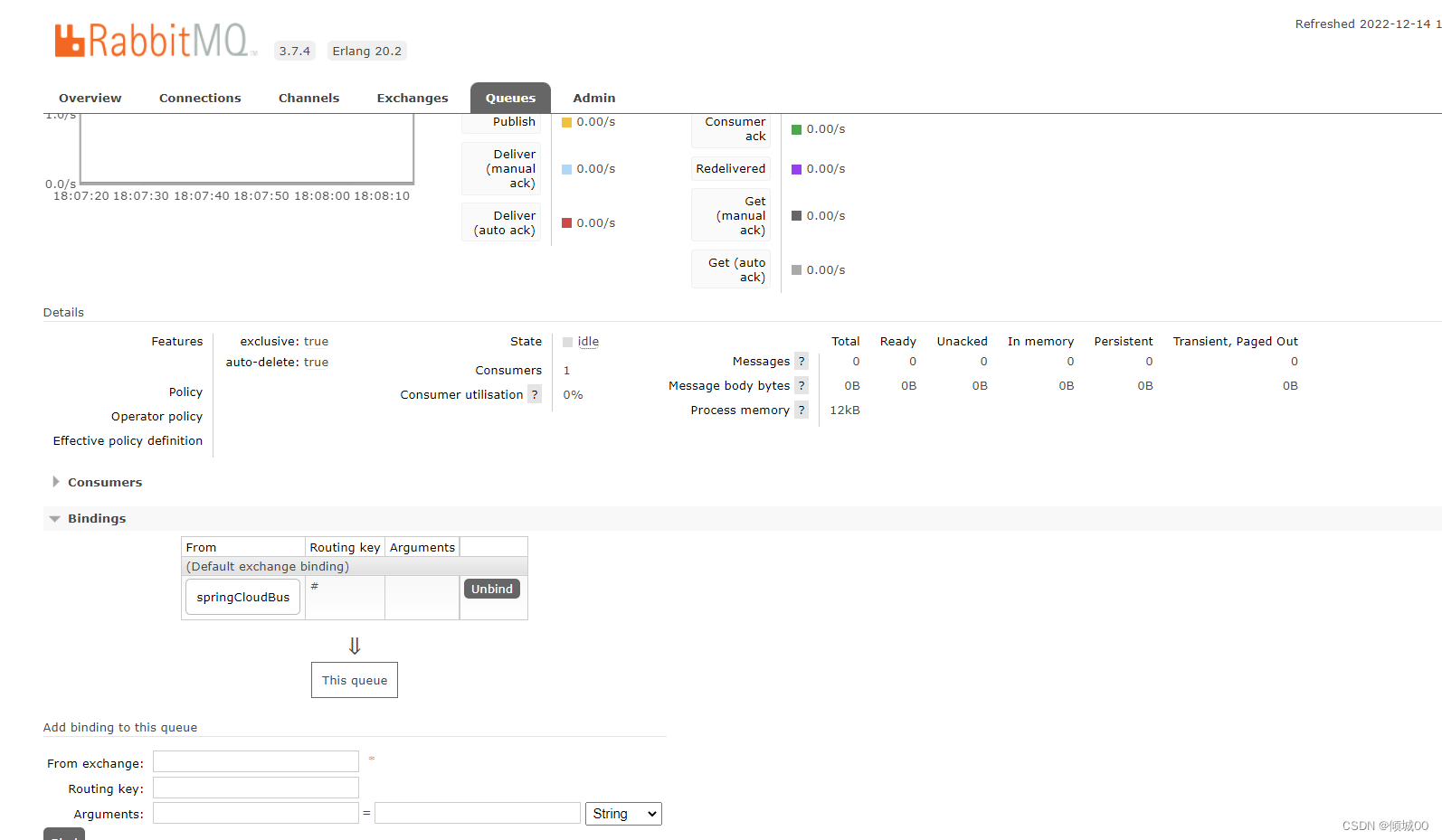
十一:SpringCloud-sleuth
-
在微服务框架中,-个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。
这样的话就会导致服务雪崩,相信看到这里肯定会有人说我们用Hystrix实现服务降级或者熔断不就行了嘛,诚然这样做是绝对可以的,但是这些是相当于bug的处理,对于复杂的请求调用链路中具体是因为哪一个环节出错误了,我们要给定位
该怎么定位,那么就需要你去对请求的链路实现监控追踪,那么就引出了主角springcloud-sleuth分布式请求链路追踪 -
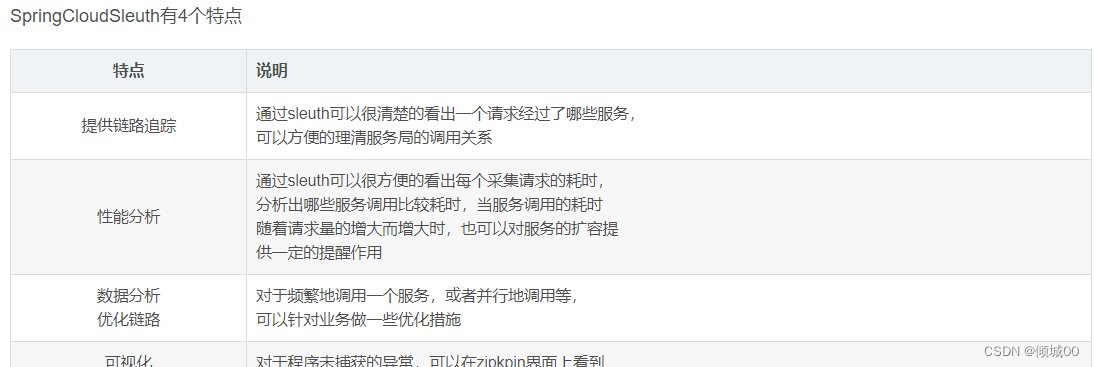
SpringCloud-Sleuth是什么:
-
是Spring Cloud提供的分布式系统服务链追踪组件,它大量借用了Google的Dapper,Twitter的Zipkin。微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪
一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具 -
Springcloud-sleuth和zipkin的区别是SpringCloud-sleuth是对ziplkin的一个封装
-
Springcloiud-Sleuth要想使用成功,需要依靠zipkin(你可以理解为是一个第三方的组件,而且从Springcloud的F版之后,就是以jar包的形式存在,那就意味着我们今天要用的ZipLink其实就是一个jar包)
11.1 zipkin
- 我们要先了解一个概念就是APM-应用性能管理,通过各种探针采集微服务系统中各个子系统的运行和调用的情况并上报数据,收集关键指标,同时搭配数据展示以实现对应用程序性能管理和故障管理的系统化解决方案
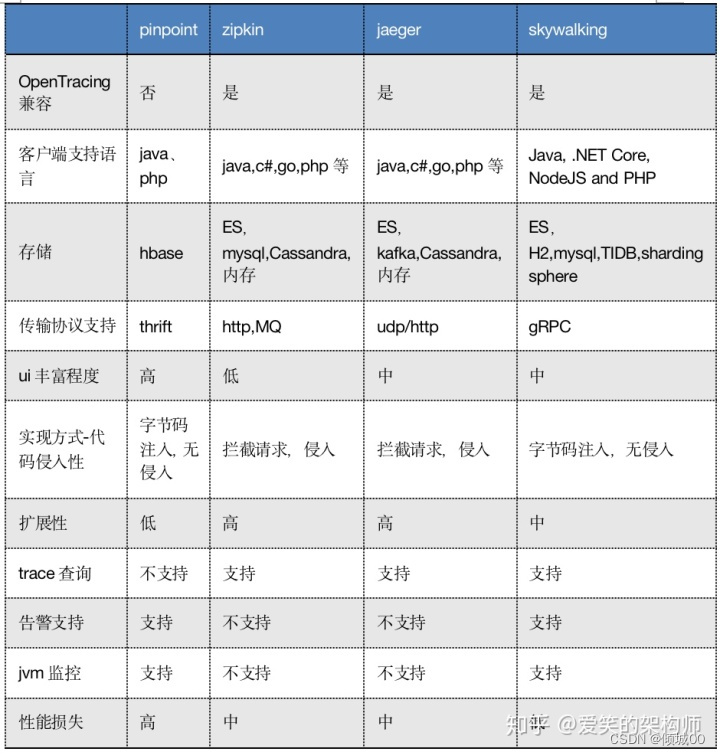
- 1.应用性能管理APM的分类:
- 1.1监控APM软件性能管理的软件:有美团Cat、Zipkin、Pinpoint、SkyWalking(华为)。
- 1.2监APM硬件性能管理的软件:Zabbix、Premetheus、open-falcon等监控系统主要关注服务器硬件指标与系统服务运行状态 (可以理解为监控软件的软件)
- zipkin是什么
- 是 Twitter 的一个开源项目,它基于 Google Dapper论文作为理论支撑的 ,通过收集分布式服务执行时间的信息来达到追踪服务调用链路、以及分析服务执行延迟等目的。
- Zipkin核心组件有
- Collector:收集器组件,作用是接收或收集各应用传输的数据,而我们要想在java语言中使用ZipLink实现收集数据,需要借助Springcloud-sleuth这个分布式请求链路追踪的配置才能实现。
- 存储组件,作用是存储接受或收集过来的数据,当前支持Memory,MySQL,Cassandra,ElasticSearch等,默认存储在内存中,我们也可以修改默认的存储策略,搭配上MySql实现数据的持久化存储。
- 负责查询Storage中存储的数据,提供简单的JSON API获取数据,主要提供给web UI使用(这也就是为什么有人称之为Query)
- WebUI:其实就是指Zipkin运行之后可以在浏览器上访问到的页面: http://127.0.0.1:9411/
- 输入指令: java -jar zipkin-server-2.12.9-exec.jar
11.2 代码实现
-
先运行zipKin
访问:http://127.0.0.1:9411/ -
在fegin的子系统添加pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
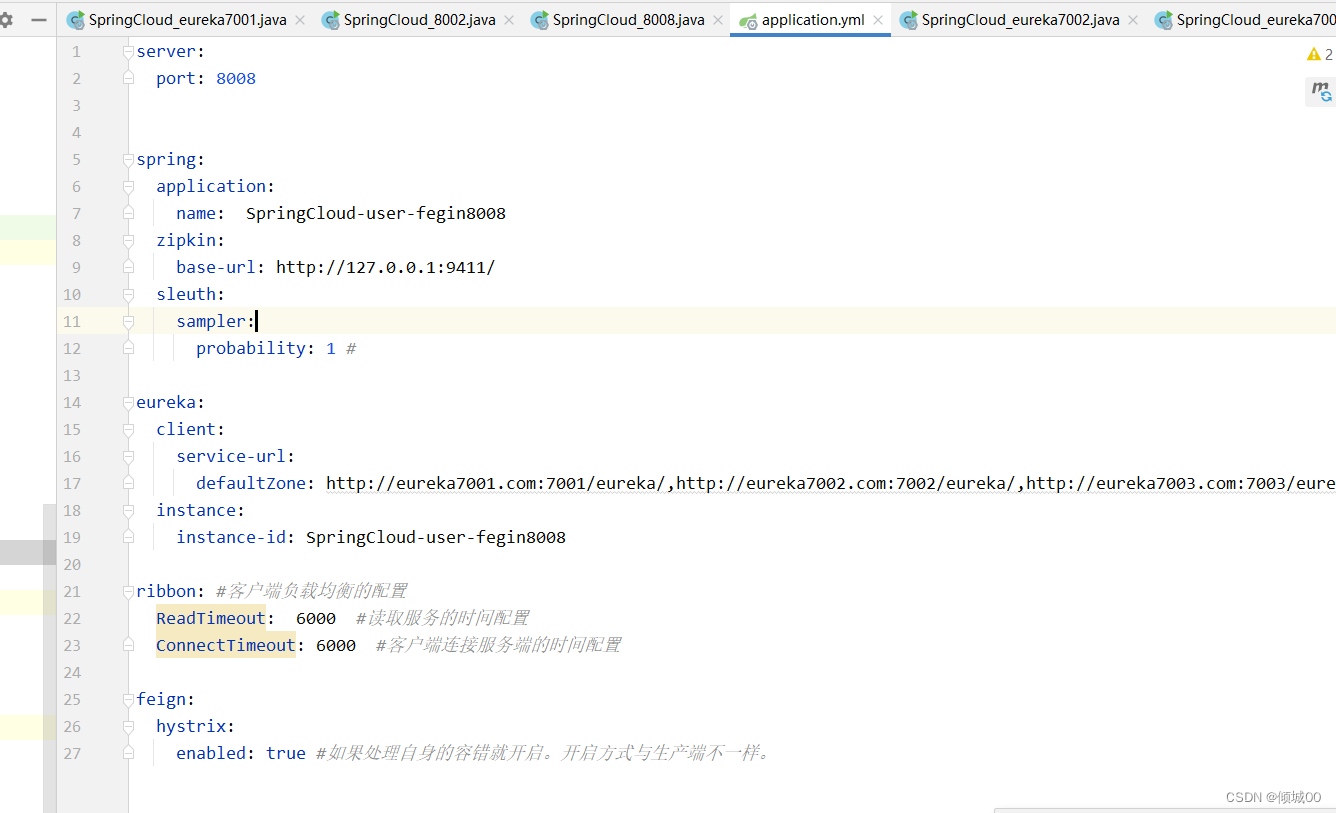
- yml文件新增
zipkin:
base-url: http://127.0.0.1:9411/
sleuth:
sampler:
probability: 1 # 这个是采集率,就是比如是10个人采集,1是100%,如果只想采集一半就是50%也就是0.5
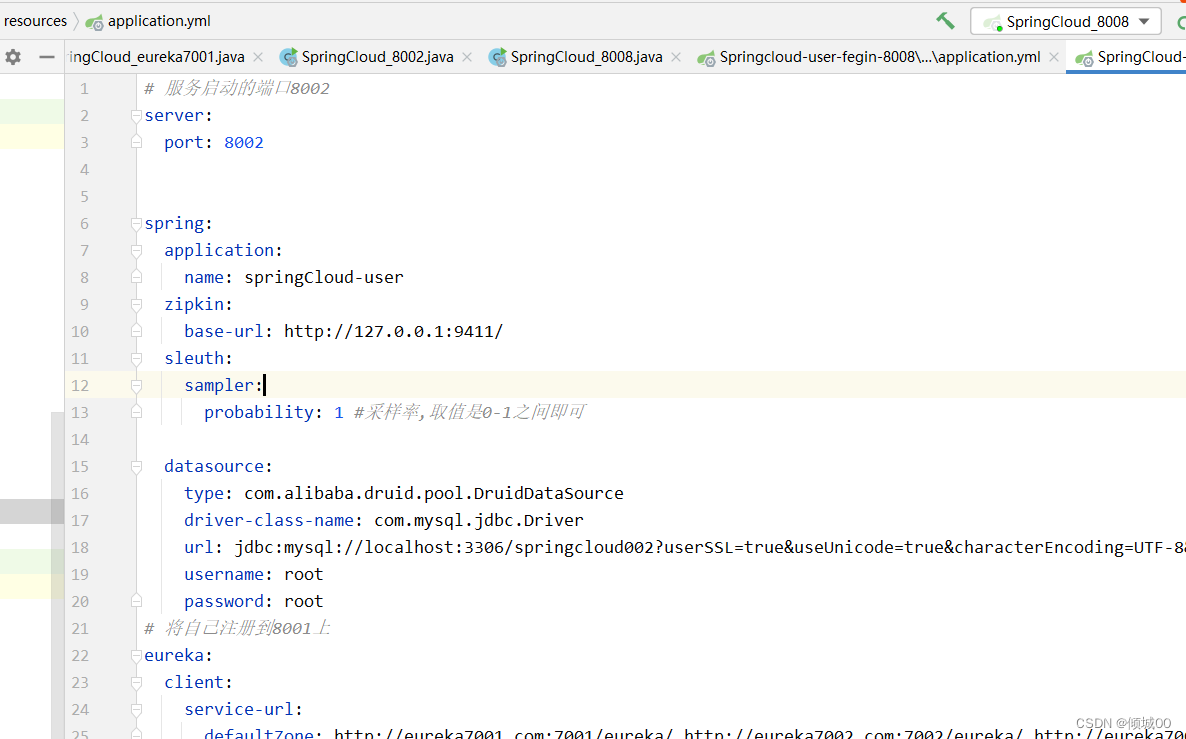
- 在8002的子系统添加pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
- yml文件
zipkin:
base-url: http://127.0.0.1:9411/
sleuth:
sampler:
probability: 1 #采样率,取值是0-1之间即可
- 启动7001-7002-7003-8002-8008
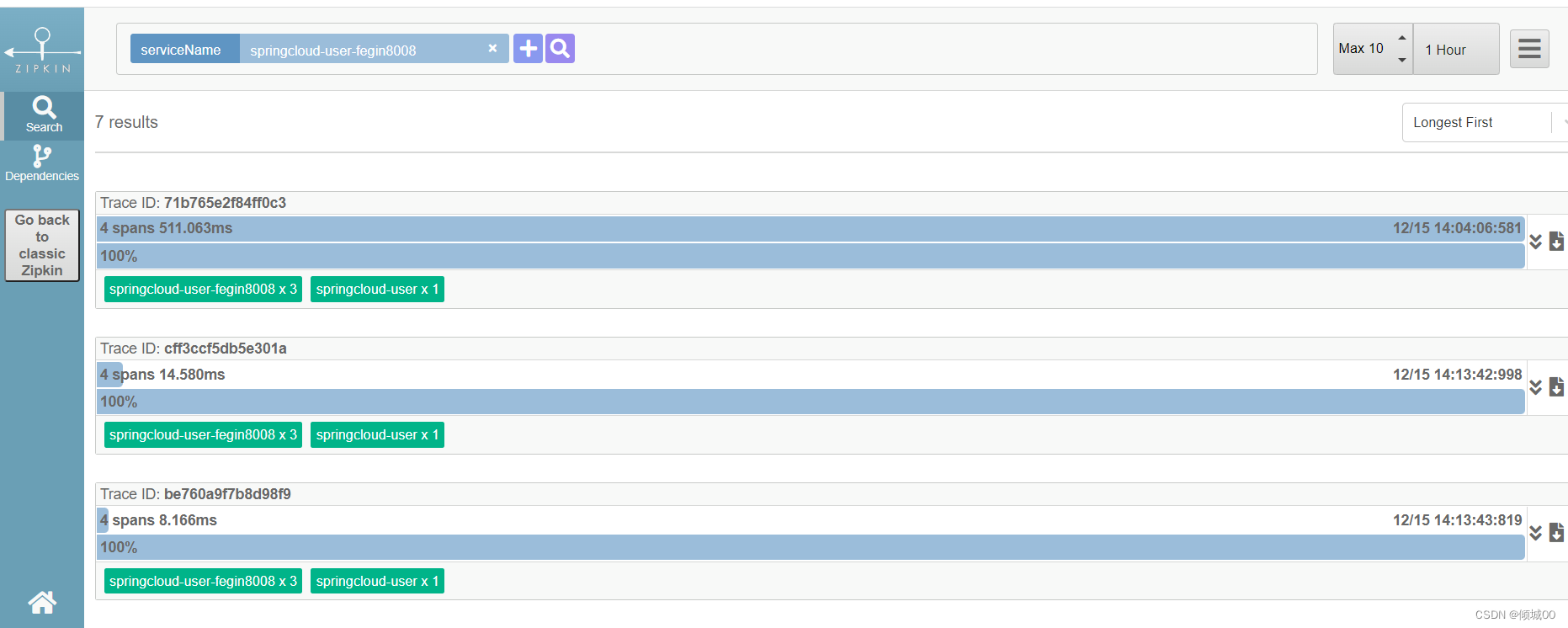
- 通过fegin去发送请求
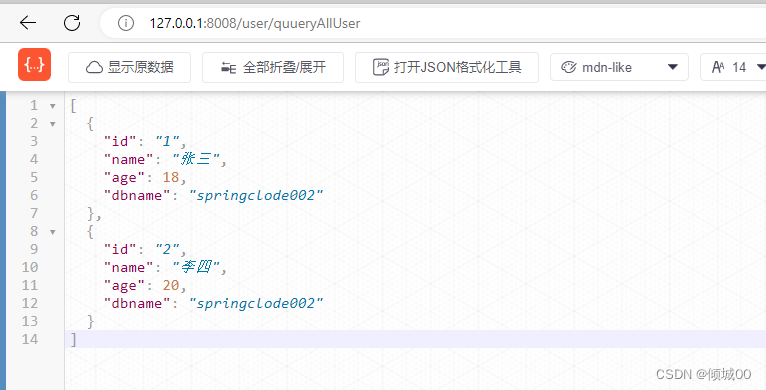
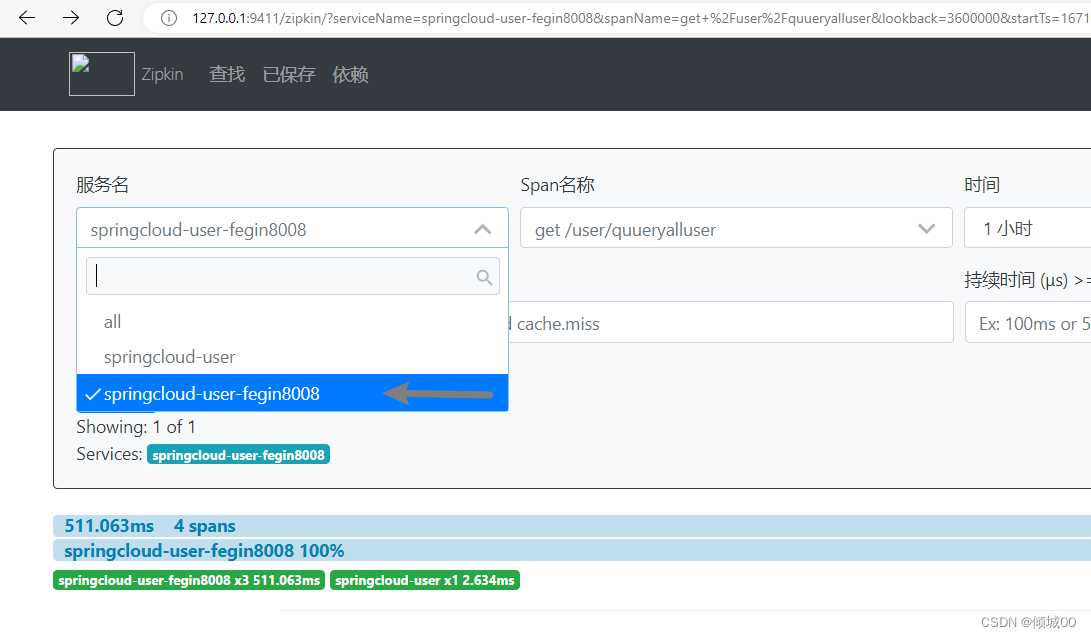
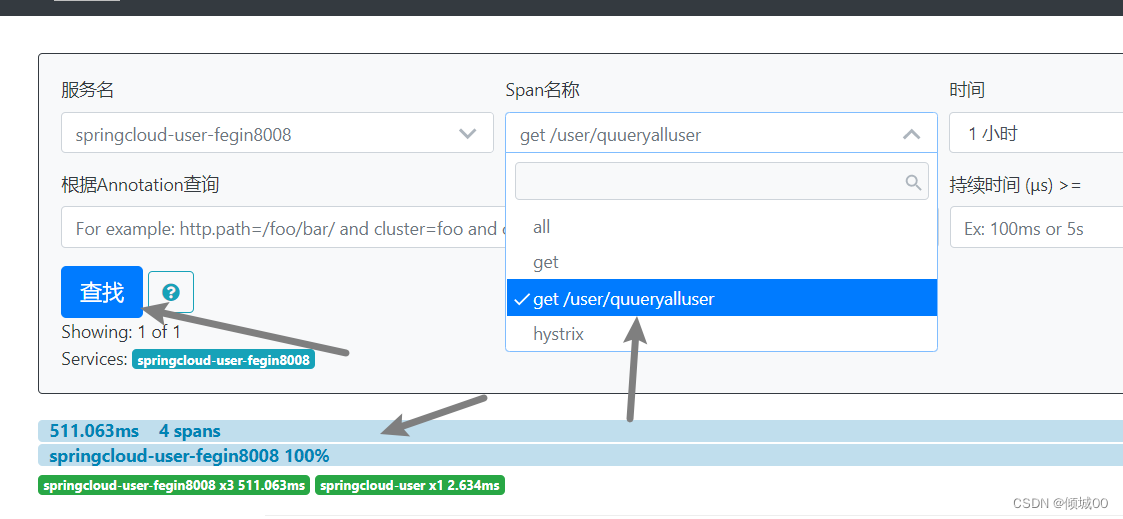
点击查询就可以看到数据了
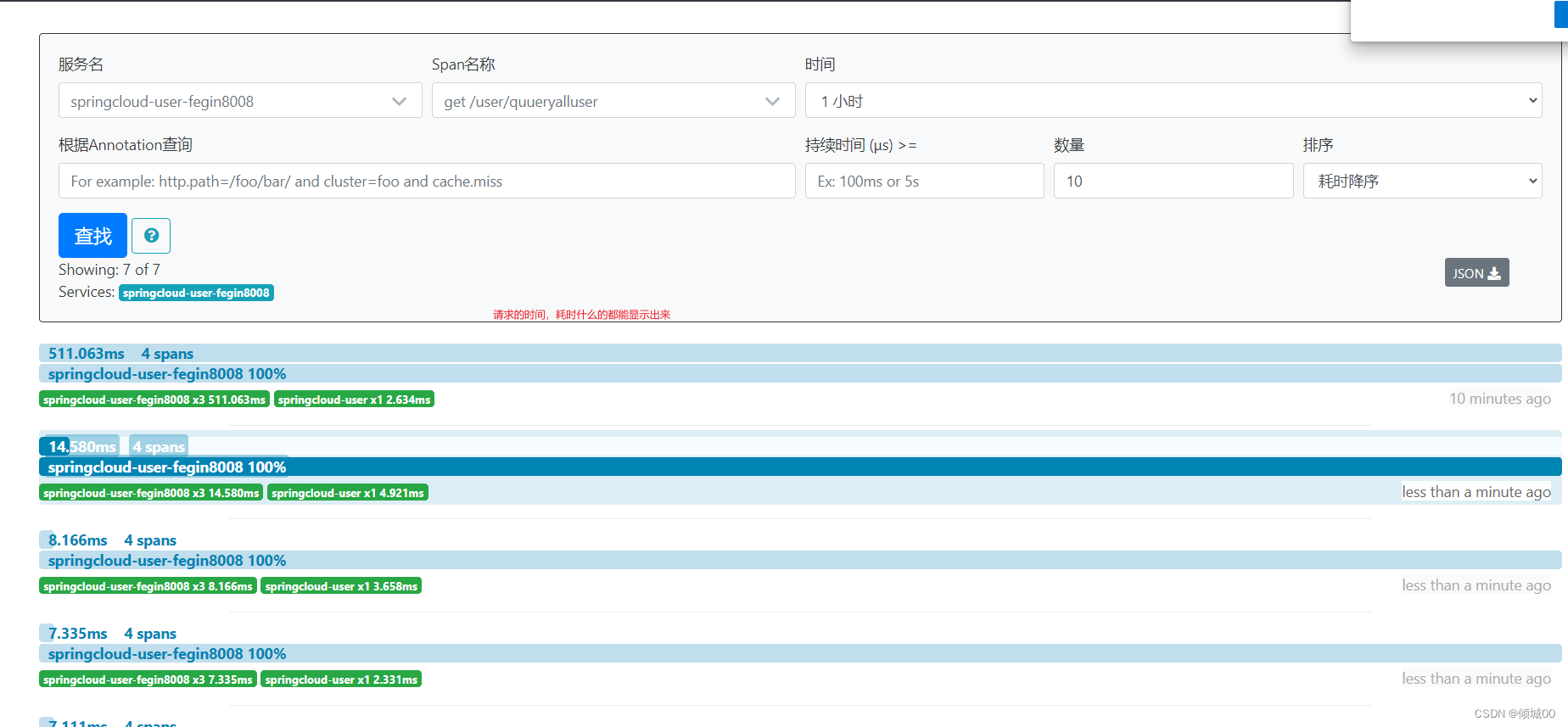
- 随表找一个点进去
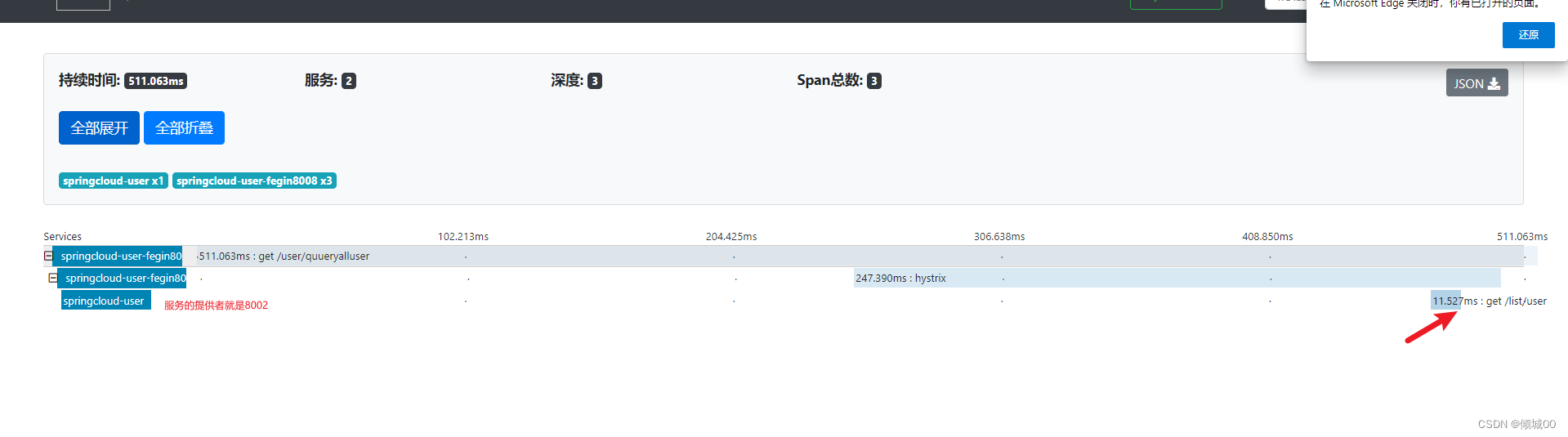
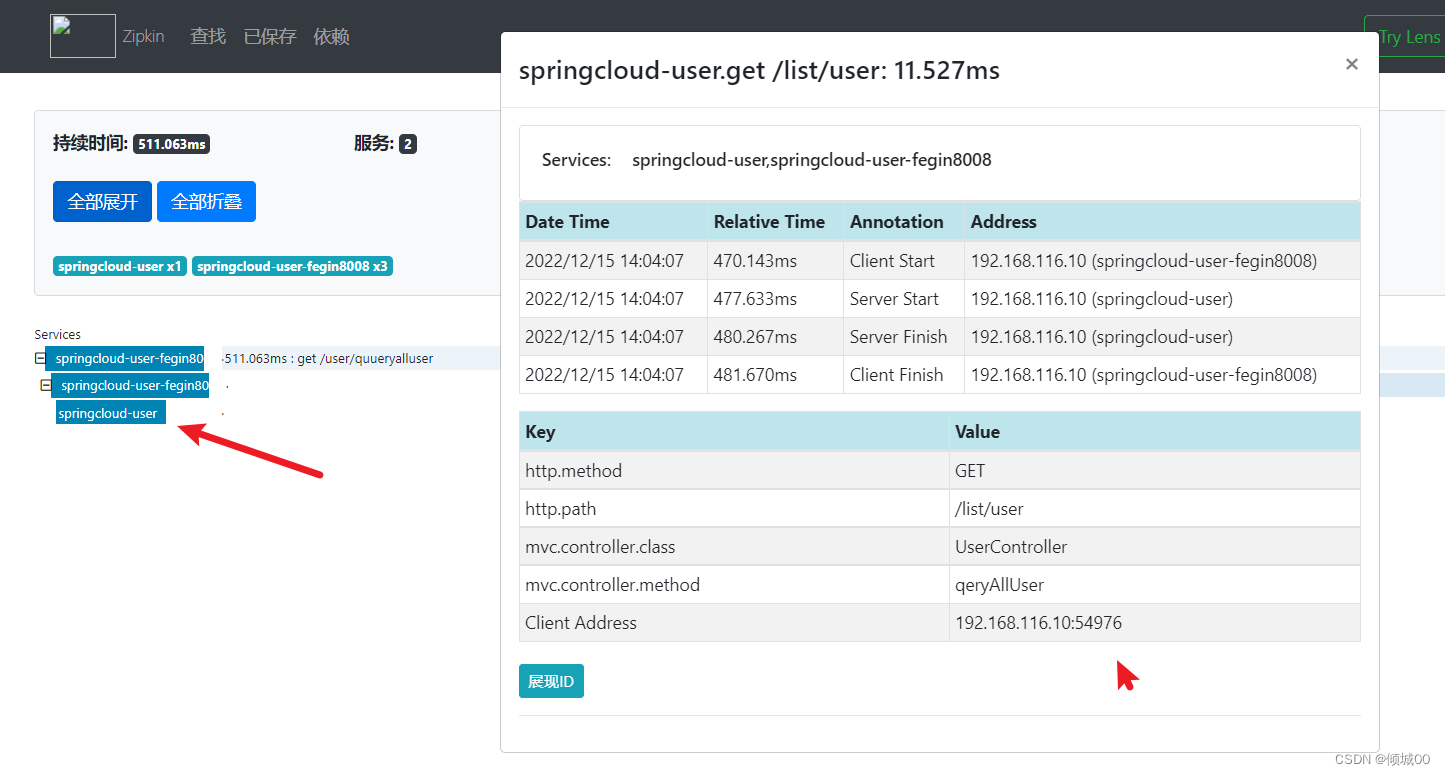
- 点进去可以再看详情,什么ip地址,请求方式,类等等,都可以看到
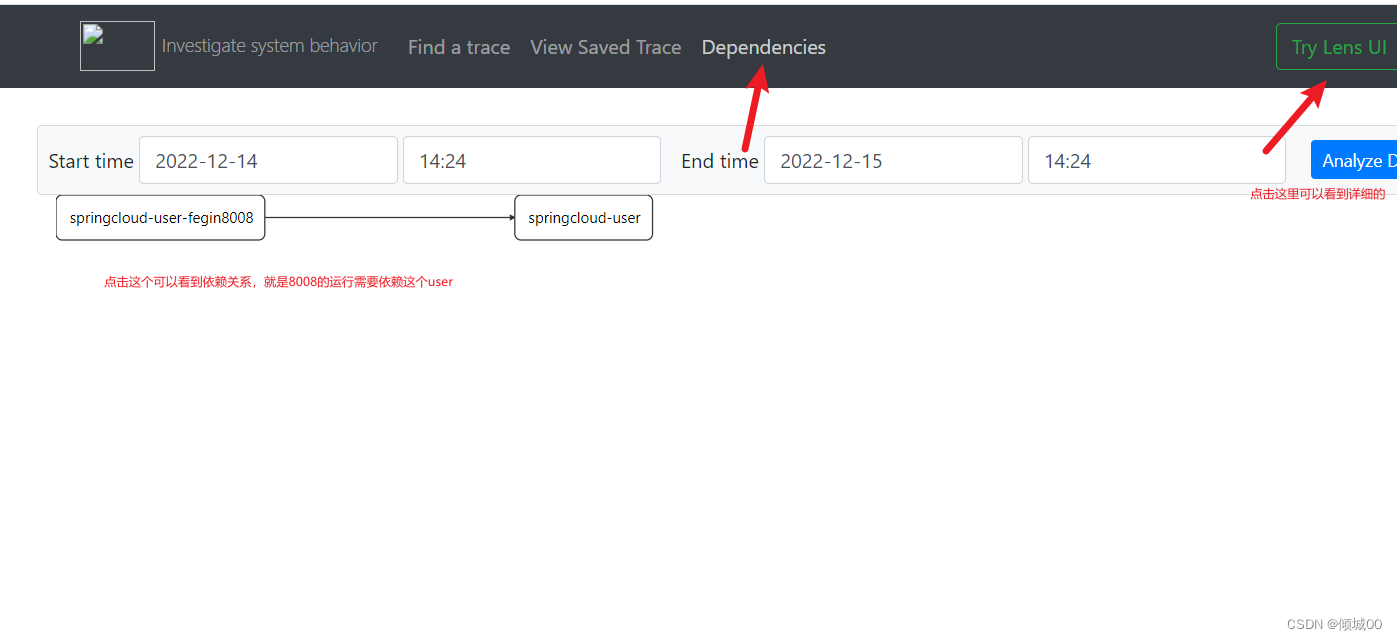
11.3 zipkin数据的持久化到Mysql中
Zipkin Server默认会将链路追踪数据保存到内存中,但这种方式不适合生产环境。一旦Zipkin Server重启,数据就丢失了。Zipkin支持将追踪数据持久化到mysql或者elasticsearch中
具体实现的步骤:
1.创建mysql数据库名字叫zipkin,然后执行ziplink.sql这个库表文件
ps:可以使用官网给的.sql库表文件,但是这个官方给的库表文件要求的mysql是5.6+,网址为:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
你仔细看了之后会发现其实就是三张表,且其中的zipkin_annotations这张表没有主键,不是错了,而是因为这张表添加了好几个索引,至于原因作者没写,我猜测可能是用不上,因为有些时候主键索引可能会与
它自身设计的索引有冲突。
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`remote_service_name` VARCHAR(255),
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',
PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT,
PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;

打开黑窗体,输入指令:
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root
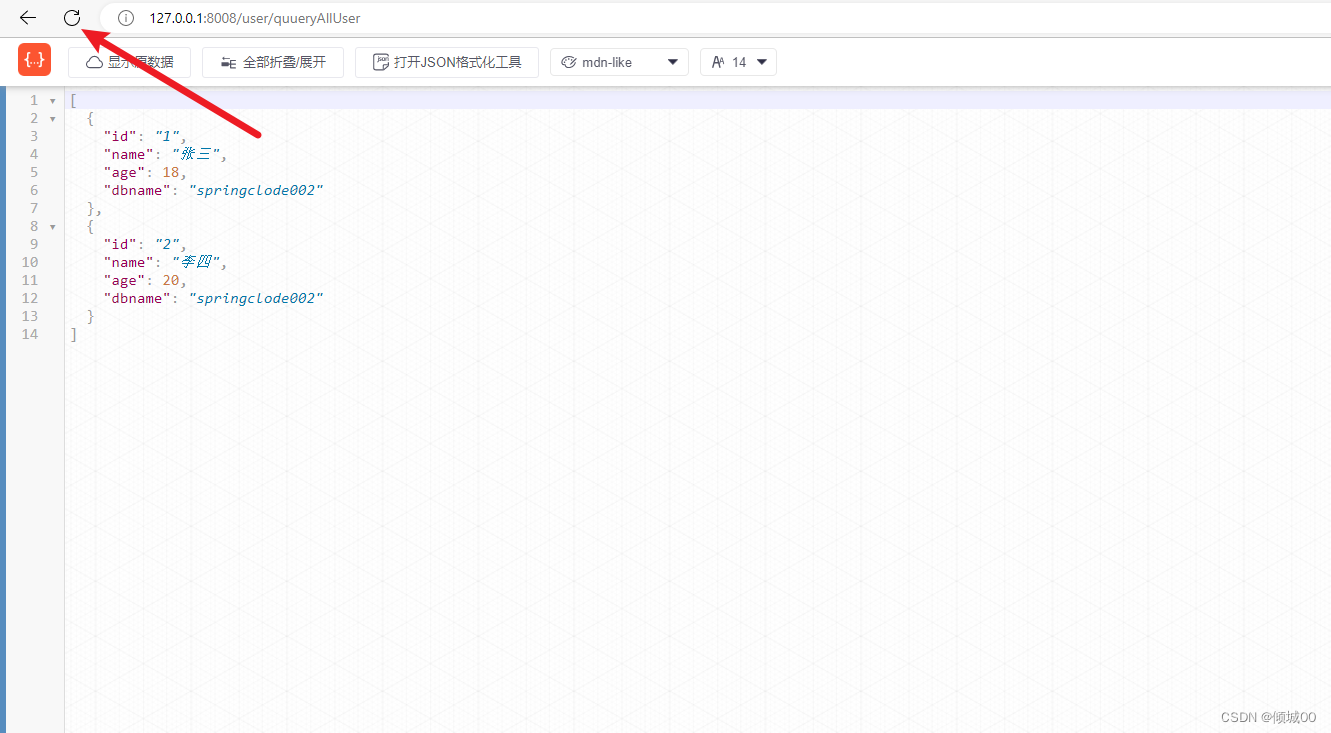
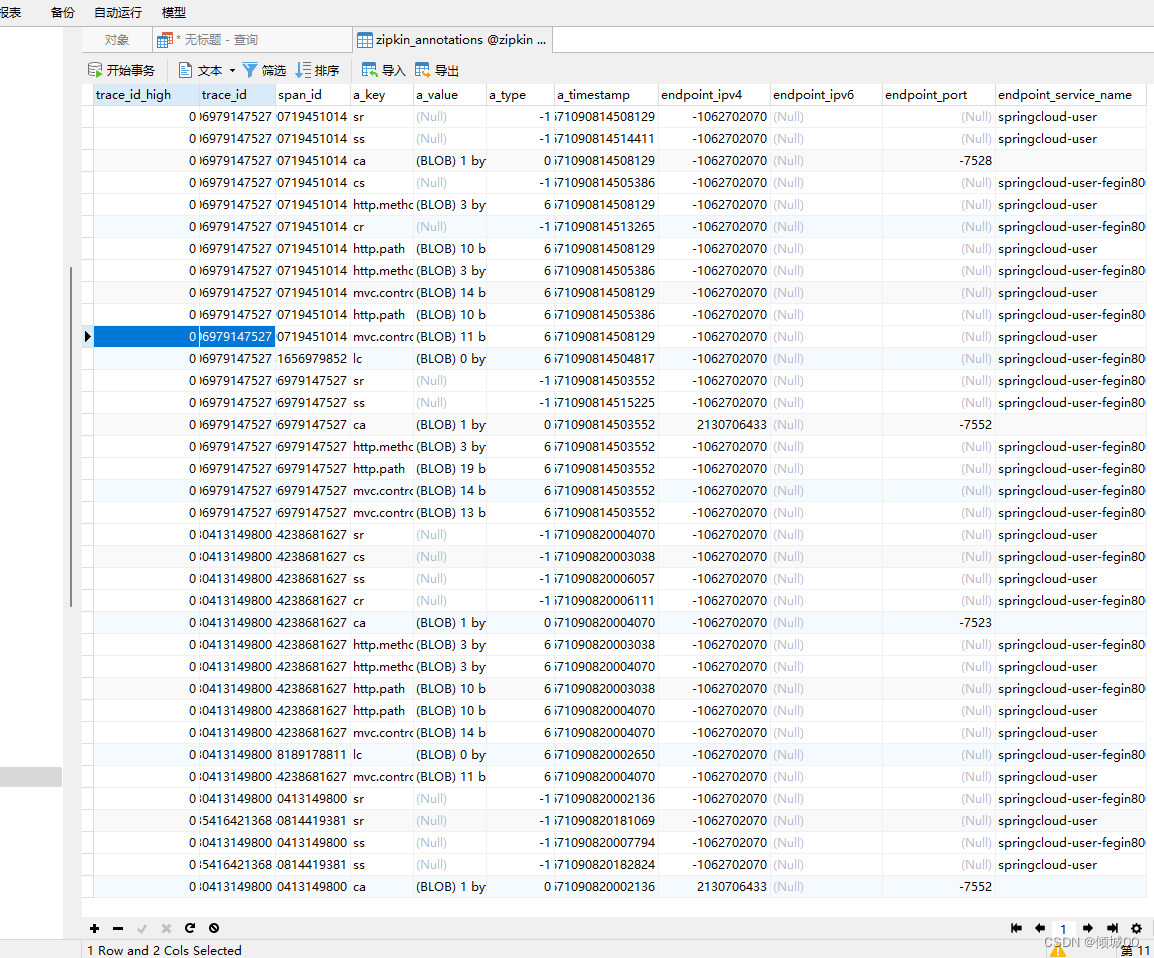
- 现在就有数据了
十二 :SpringCloud Stream–消息驱动
- Springclou-stream诞生的背景原因:
- 众所周知消息中间件有多种,例如,Rabbitmq,Rocketmq,Activemq,Kafka等(其中最流行的就是这个四个),不同的消息中间件具体使用和实现细节也不一样,假如我们是一个超级大的项目,除了我们的java开发组之外
还有大数据组,但是他们使用的MQ的实现不一样。例如前者使用Rabbitmq,后者使用kafka,那么这时候该怎么办?肯定会有人说那简单啊:方案一:所有的开发人员都去把这两个MQ中间件学了(有学习时间成本),
方案二:改为同一种MQ(项目就有可能是延误工期),方案三:我们编写工具类进行消息格式和发送接收方式的转换(这种方式肯定是可以的,但是要求你们项目组的人员技术能力是超牛才行),那么有没有方案四呢?肯定是
有的,我们springcloud-stream就是这样的(引入一个spingcloud-stream组件,少量的编写代码,不用管MQ的实现到底是rabbitmq还是kafka还是什么,作为程序员只是需要关注output,input即可)
- Springcloud-stream是什么:
- pring Cloud Stream 是一个用来为微服务应用构建消息驱动能力的框架。它可以基于 Spring Boot 来创建独立的、可用于生产的 Spring 应用程序。Spring Cloud Stream 为一些供应商的消息中间件产品提供了个性化的自动化
配置实现,并引入了发布-订阅、消费组、分区这三个核心概念。通过使用 Spring Cloud Stream,可以有效简化开发人员对消息中间件的使用复杂度,让系统开发人员可以有更多的精力关注于核心业务逻辑的处理。但是目前
Spring Cloud Stream 只支持 RabbitMQ 和 Kafka 的自动化配置 - 简而言之:屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型
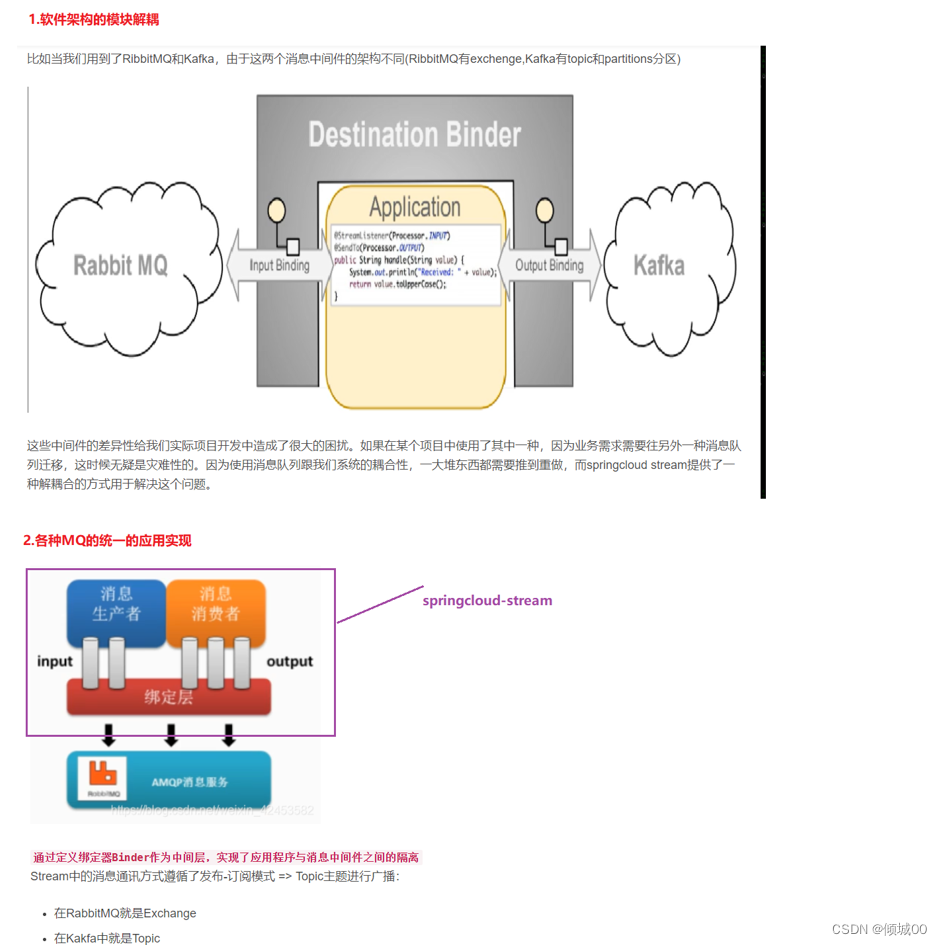
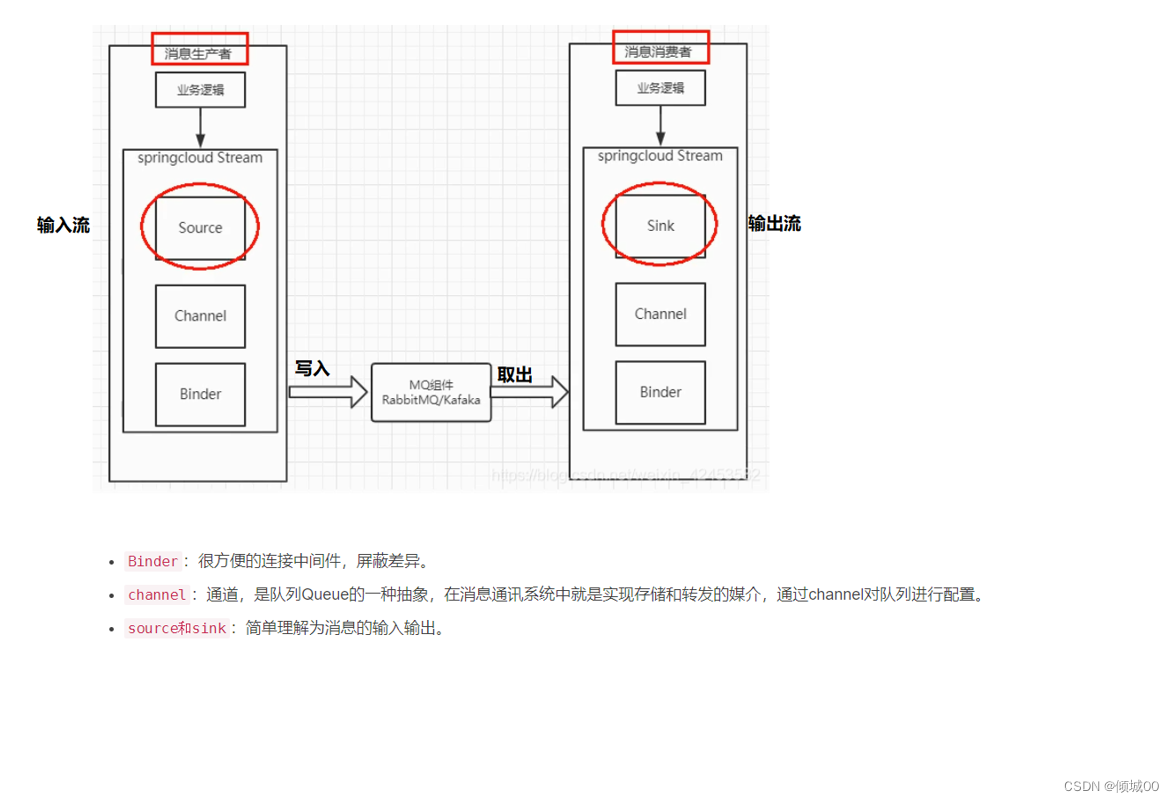
12.1代码实现数据推送
- 创建springcloud-stream-rabbitmq-provider-8901项目,充当发送者
- pom
<dependencies>
<!--1.引入springcloud-stream的rabbit实现-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<!--2.eureka客户端组件(目的是将当前子系统注册到eureka集群中)-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--3.web处理的模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--4.引入web监控模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--5.引入热部署模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<!--6.实体类-->
<dependency>
<groupId>com.bj.sh.pojo.User</groupId>
<artifactId>SpringCloud-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
- yml文件
server:
port: 8901
spring:
application:
name: springcloud-stream-rabbitmq-provider #2.Spring应用的名字
cloud: #springcloud-stream的配置
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于与bindings整合
type: rabbit # 当前springcloud-stream使用的MQ的类型:RabbitMQ
environment: # 配置rabbitmq的相关信息
spring:
rabbitmq:
host: localhost #rabbitmq的主机
port: 5672 #rabbitmq的端口
username: guest #rabbitmq的用户名
password: guest #rabbitmq的密码
bindings: # 服务的整合处理
output: #这个名字是一个通道的名称,就是本次消息的写入的名字
destination: LXYExchange # 表示要使用的Exchange名称定义(在rabbitMQ上要生成一个wyhExchange交换器)
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
# 将自己注册到8001上
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: springCloud-user-8003-l
info:
app.name: springCloud-user-8003-LXY #显示的应用的名字
company.name: com.xxx.xxx #公司的名字
- MsgController
package com.rj.bd.controller;
import com.rj.bd.Service.IMsgService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.UUID;
/**
* @author LXY
* @desc
* @time 2022--12--15--17:18
*/
@RestController
public class MsgController {
@Autowired
public IMsgService msgService;
@GetMapping("/getmessage")
public String getmess(){
String uuid= UUID.randomUUID().toString();
String getmess = msgService.getmess(uuid);
return "发送成功订单号为:"+uuid;
}
}
- IMsgService
package com.rj.bd.Service;
/**
* @author LXY
* @desc
* @time 2022--12--15--17:18
*/
public interface IMsgService {
public String getmess(String messID);
}
- IMsgServiceImple
package com.rj.bd.ServiceImple;
import com.rj.bd.Service.IMsgService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.support.MessageBuilder;
/**
* @author LXY
* @desc
* @time 2022--12--15--17:19
*/
@EnableBinding(Source.class) //绑定输入流对象
public class IMsgServiceImple implements IMsgService {
@Autowired
private MessageChannel output;
@Override
public String getmess(String messID) {
return output.send(MessageBuilder.withPayload(messID).build())+"";
}
}
- 执行
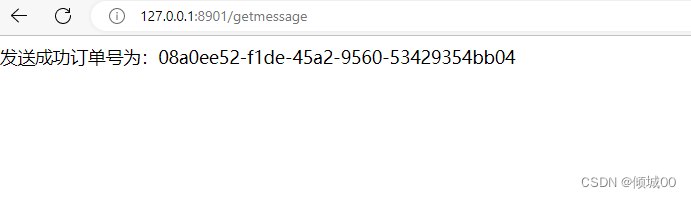
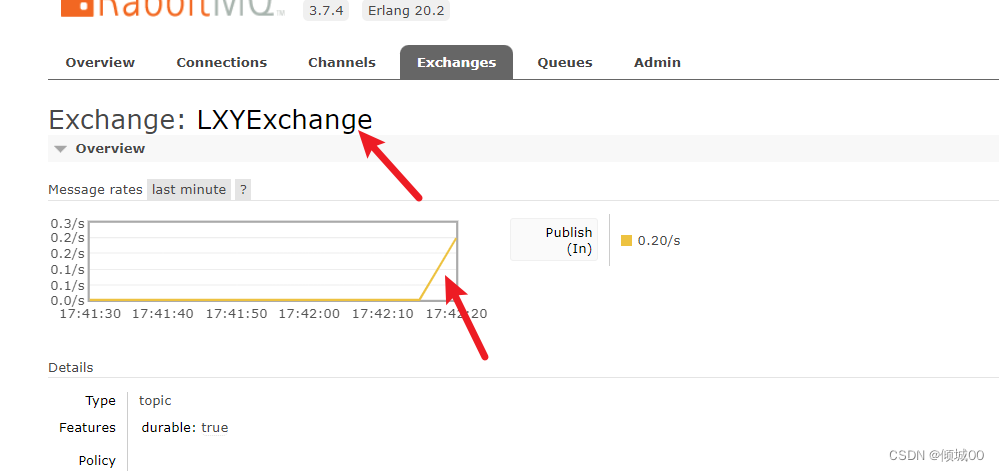
- 数据发送成功
- 通过EnableBindinh直接去绑定输出流,进行数据的写入
- 通过MessageChannel去发送数据
- output.send(MessageBuilder.withPayload(messID).build())+“”;
12.2 代码实现接受数据
- 创建springcloud-stream-rabbitmq-concumer-8902项目
- pom
<dependencies>
<!--1.引入springcloud-stream的rabbit实现-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<!--2.eureka客户端组件(目的是将当前子系统注册到eureka集群中)-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--3.web处理的模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--4.引入web监控模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--5.引入热部署模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
</dependencies>
- yml
server:
port: 8902 #当前子项目启动的端口
#将当前子项目注册到eureka集群上
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
instance:
instance-id: springcloud-stream-rabbitmq-concumer-8902 # 在信息列表时显示主机名称
spring:
application:
name: springcloud-stream-rabbitmq-concumer
cloud:
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称,即是“input”,在Sink.java这个接口中已经定义好的
destination: LXYExchange # 表示要使用名字叫wyhExchange的这个交换器
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
- 启动类
package com.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
/**
* @author LXY
* @desc
* @time 2022--12--15--17:59
*/
@EnableEurekaClient
@SpringBootApplication
public class RabbitmqConcumer8902 {
public static void main(String[] args) {
SpringApplication.run(RabbitmqConcumer8902.class,args);
}
}
- 接受消息的类
package com.bj.sh.Config;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Sink;
import org.springframework.messaging.Message;
import org.springframework.stereotype.Component;
/**
* @author LXY
* @desc
* @time 2022--12--15--18:02
*/
@Component
@EnableBinding(Sink.class)
public class RabbitmqConf {
/**
* @desc 当前这个方法就是用来从rabbitMq中获取消息的,但是此时37行爆出一个警告,意思为“未找到绑定消息处理程序”
* 但是这个不应该我们使用,至于爆出这个异常的原因是因为我们目前接收者这块用的是默认的Sink.INPUT,你可以可以单独的
* 新一个接口类似于是Sink.java(但是这块改,那就意味着8901也要改,而且application.yml中也要改,比较麻烦)。
* 我们此时因为没有自己新建,所以就报警告了,没事的(建议使用Stream内置的默认的即可)
* @param message
*/
@StreamListener(Sink.INPUT)
public void getMsg(Message<String> message) {
System.out.println("8902接受的消息-->"+message.getPayload());
}
}
- 我们再次发送数据


12.3 消息的分组
- 在创建一个springcloud-stream-rabbitmq-concumer-8903 项目,内容和8902一样
- 然后两边都修改yml文件
group: LXY-groupA #消息分组:实现避免消息被重复消费
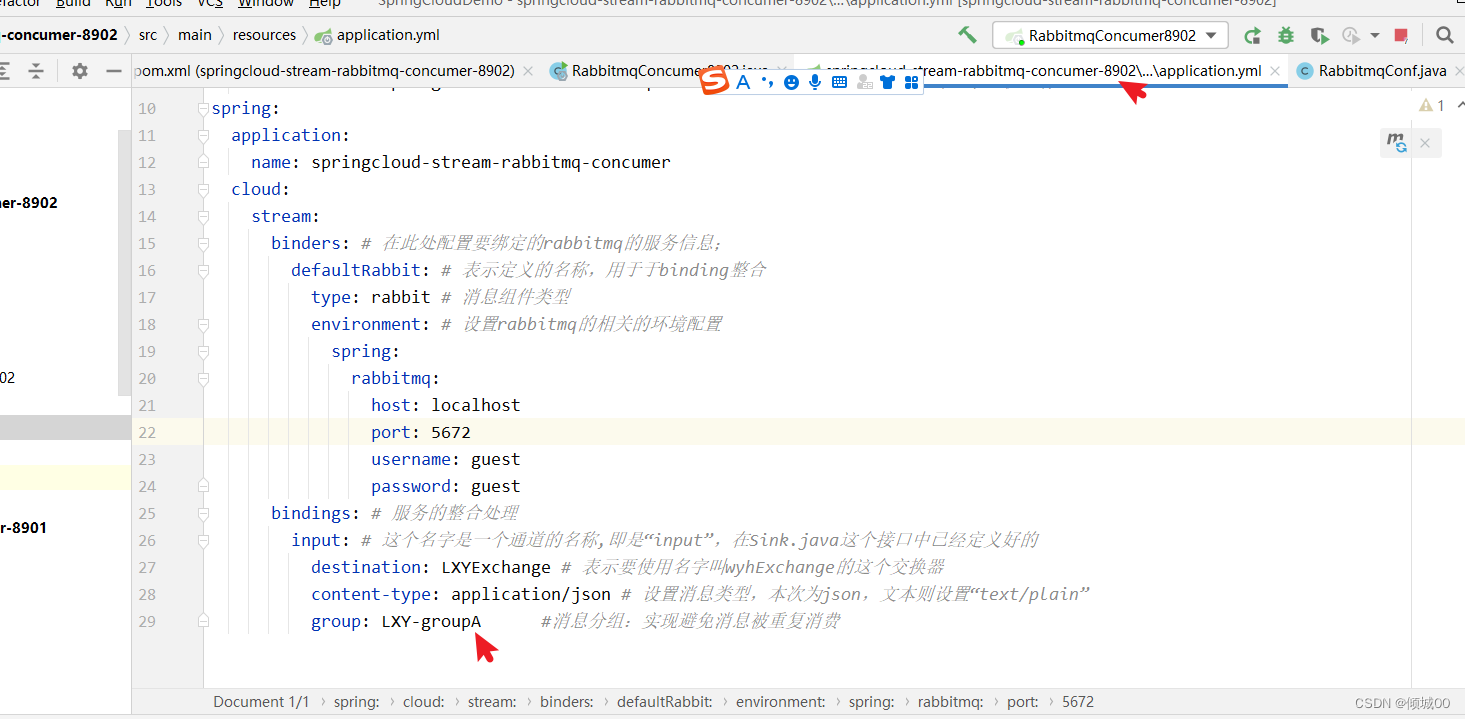
- 进行一个分组,这样消息就8901发送消息,8902和8903就会出现竞争关系,只有一个能接受到数据
12.3 消息的持久化
-
和上面一样,对消息进行分组之后,将接受消息的关掉,然后发送消息,
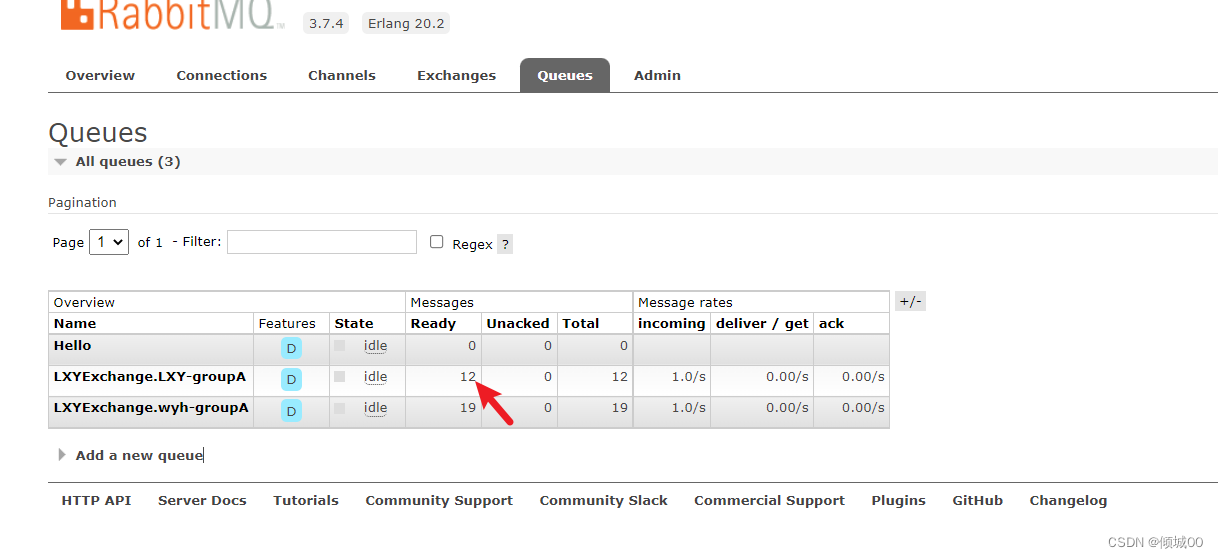
-
消息就会有没有被消费的,然后把消费者启动
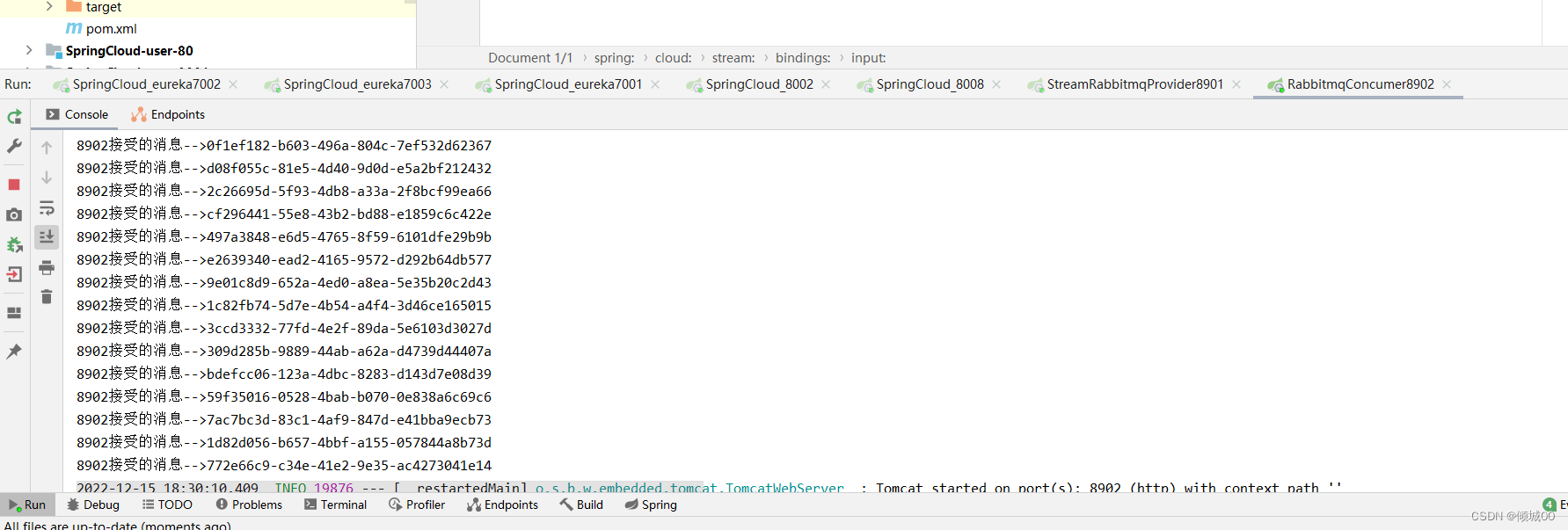
-
可以接受到数据,这样就实现了消息的持久化操作
十三:SpringcloudAlibaba
- 首先搭建一个微服务的环境,父项目(订单和库存模块)
- 父pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<modules>
<module>Order</module>
<module>Stock</module>
</modules>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.11.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<packaging>pom</packaging>
<groupId>com.bj.sh</groupId>
<artifactId>SpringCloudAlibaba</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringCloudAlibaba</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<!-- <build>-->
<!-- <plugins>-->
<!-- <plugin>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-maven-plugin</artifactId>-->
<!-- </plugin>-->
<!-- </plugins>-->
<!-- </build>-->
</project>
Order-pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>SpringCloudAlibaba</artifactId>
<groupId>com.bj.sh</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>Order</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
</project>
c层
package com.bj.sh.Controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
/**
* @author LXY
* @desc
* @time 2023--02--20--21:54
*/
@RestController
@RequestMapping("/api")
public class OrderController {
@Autowired
RestTemplate restTemplate;
@GetMapping("/add")
public String add(){
String mess = restTemplate.getForObject("http://127.0.0.1:8011/api/reduces", String.class);
System.out.println("下单成功");
return "下单成功"+mess;
}
}
- 启动类
package com.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.web.client.RestTemplateBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
/**
* @author LXY
* @desc
* @time 2023--02--20--22:03
*/
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class,args);
}
//注入模板类
@Bean
public RestTemplate getrestTemplate(RestTemplateBuilder restTemplateBuilder){
return restTemplateBuilder.build();
}
}
- yml
server:
port: 8010
- Stock-pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>SpringCloudAlibaba</artifactId>
<groupId>com.bj.sh</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>Stock</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
</project>
- c层
package com.bj.sh.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
/**
* @author LXY
* @desc
* @time 2023--02--20--22:07
*/
@RestController
@RequestMapping("/api")
public class StockController {
@RequestMapping(value = "/reduces",method = RequestMethod.GET)
public String add(){
System.out.println("购买成功,库存-1");
return "购买成功,库存-1";
}
}
- 启动类
package com.bj.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author LXY
* @desc
* @time 2023--02--20--22:08
*/
@SpringBootApplication
public class StockApplication {
public static void main(String[] args) {
SpringApplication.run(StockApplication.class,args);
}
}
- yml
server:
port: 8011
- 最后的效果是通过订单去购买,调用库存然后-1
13.1 SpringCloudAlibaba环境搭建
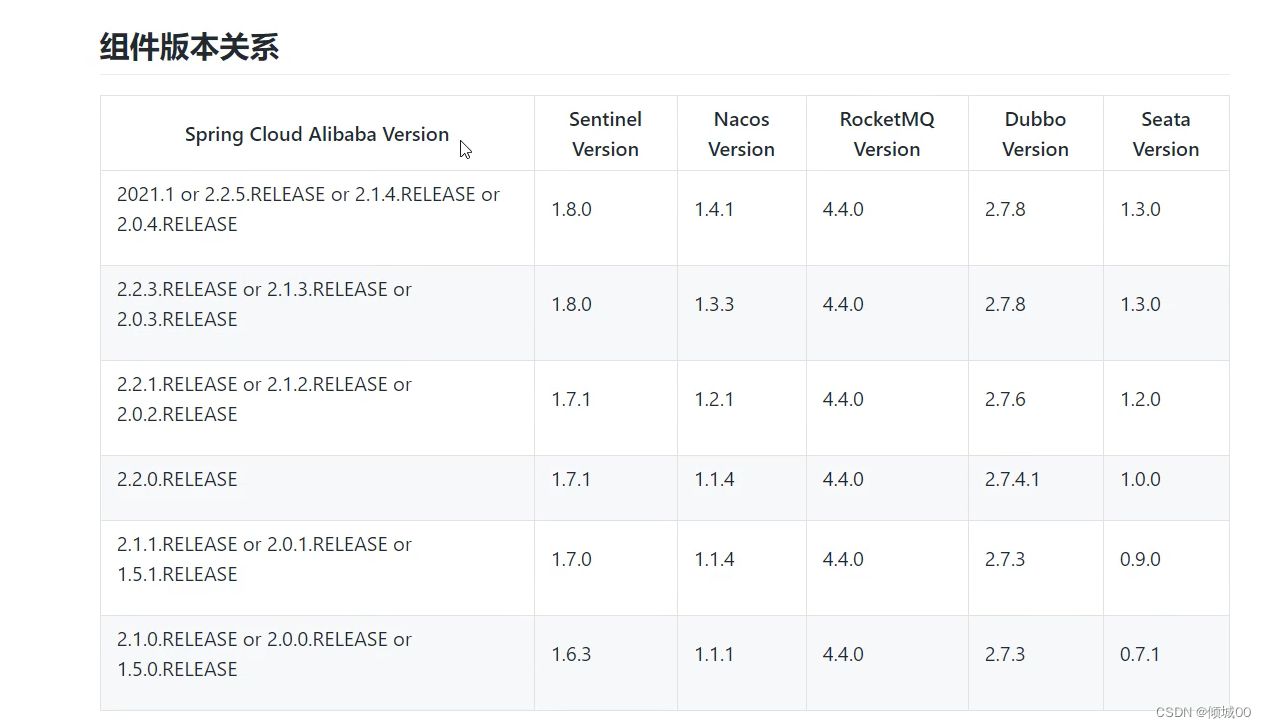

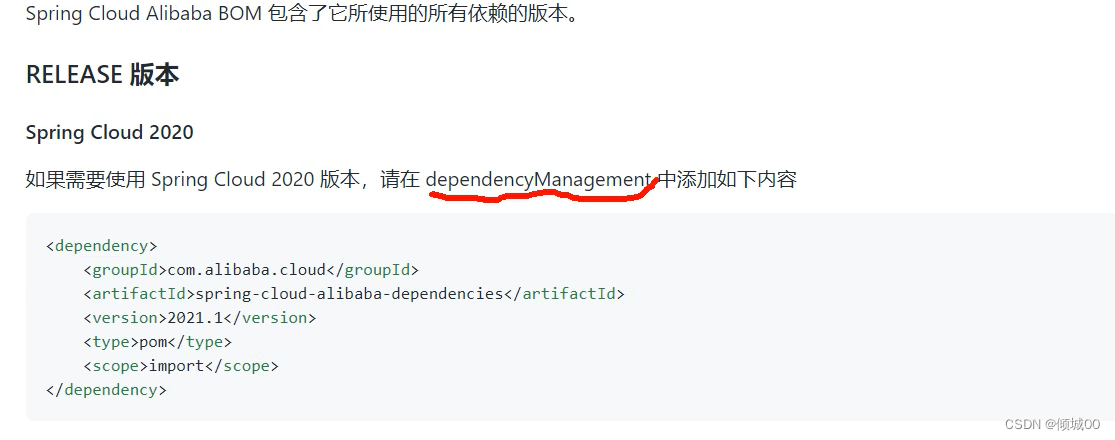
- 父项目已经有了Springboot了,但是还想用SpringcloudAlibba,maven有一个新特性,如上就可以实现

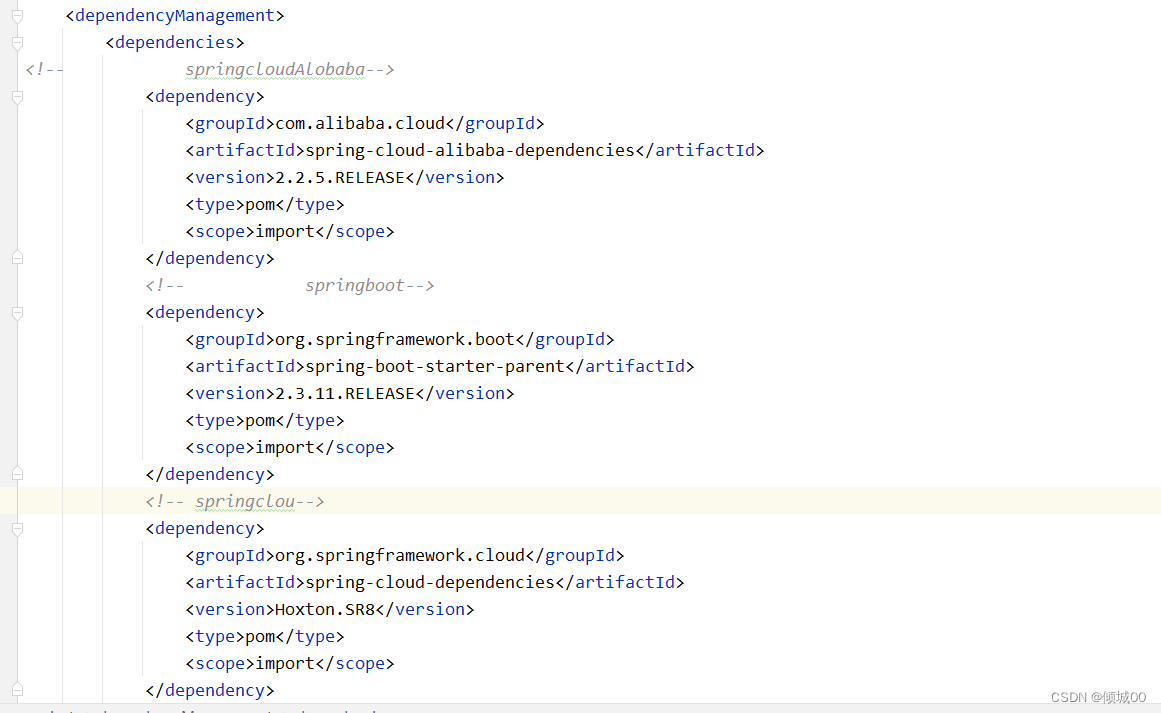
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<modules>
<module>Order</module>
<module>Stock</module>
</modules>
<packaging>pom</packaging>
<groupId>com.bj.sh</groupId>
<artifactId>SpringCloudAlibaba</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringCloudAlibaba</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!-- springcloudAlobaba-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- springboot-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.11.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- springclou-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR8</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<!-- <build>-->
<!-- <plugins>-->
<!-- <plugin>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-maven-plugin</artifactId>-->
<!-- </plugin>-->
<!-- </plugins>-->
<!-- </build>-->
</project>
- 这样maven的新特性就可以让我们的子项目同时继承alibaba-springboot-springcloud这三个了,子项目引入组件不需要进行版本号指定了,因为父项目引入的Springalibaba项目里面包含了各个组件的版本
13.2 SpringCloudAlibaba组件Nacos组件
- 是一个更易于构建云原生应用的动态
服务发现(Nacos Discovery),服务配置(Nacos Config)和服务管理平台 - Nacos的特性包括
-
- 服务的发现和服务的健康检测
-
- 动态配置服务
-
- 动态DNS服务
-
- 服务以及其元数据的管理
13.2 Nacos核心功能
- 服务注册: Nacos Client 会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址,端口等信息,Nacos Server收到注册请求之后,会把这些元数据存储在一个双层的map中
- 服务心跳:在服务注册之后,Nacos Cient会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止为剔除,默认每5s发送一次请求
- 服务同步:Nacos Server集群之间会相互同步服务实例,用来保证服务信息的一致性,leader raft
- 服务发现:服务消费者在调用服务提供者的服务时,会发送一个Rest请求给Nacos Server,获取上面注册的服务清单,并且缓存在Nacos Client本地,同时会在Nacos Client本地开启一个定时任务定时拉取服务器端的最新注册表信息更新到本地缓存
- 服务健康检查:Nacos Server会开启一个定时任务,用来检查服务实例的健康情况,对于超过15s没有收到客户端心跳的实例,会将它的healthy属性值设置false(客户端服务发现时不会发现)如果某个实例超过30s没有收到心跳,直接剔除该实例(被剔除的实例如果恢复发送心跳则会重新注册)
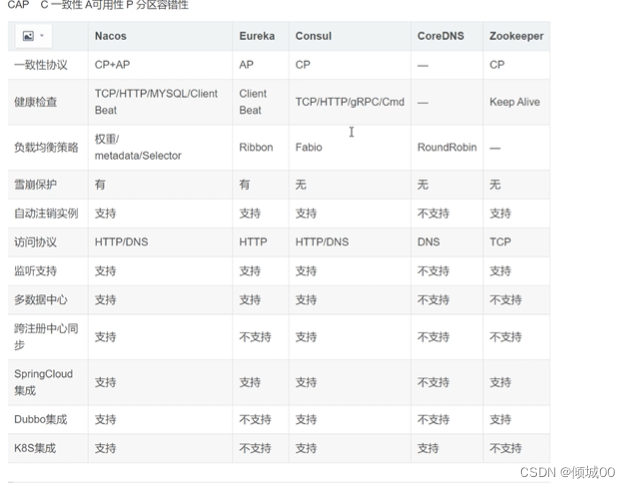
13.3 nacos的安装和服务端的配置
按照最上面的图,下载对应alibaba的版本
- 用本地电脑演示我下的是zpi的
- 加压之后是在Bin目录中国,这个是在win10启动的,下面的是在linux启动的
- 需要编辑一下,默认是集群打开的
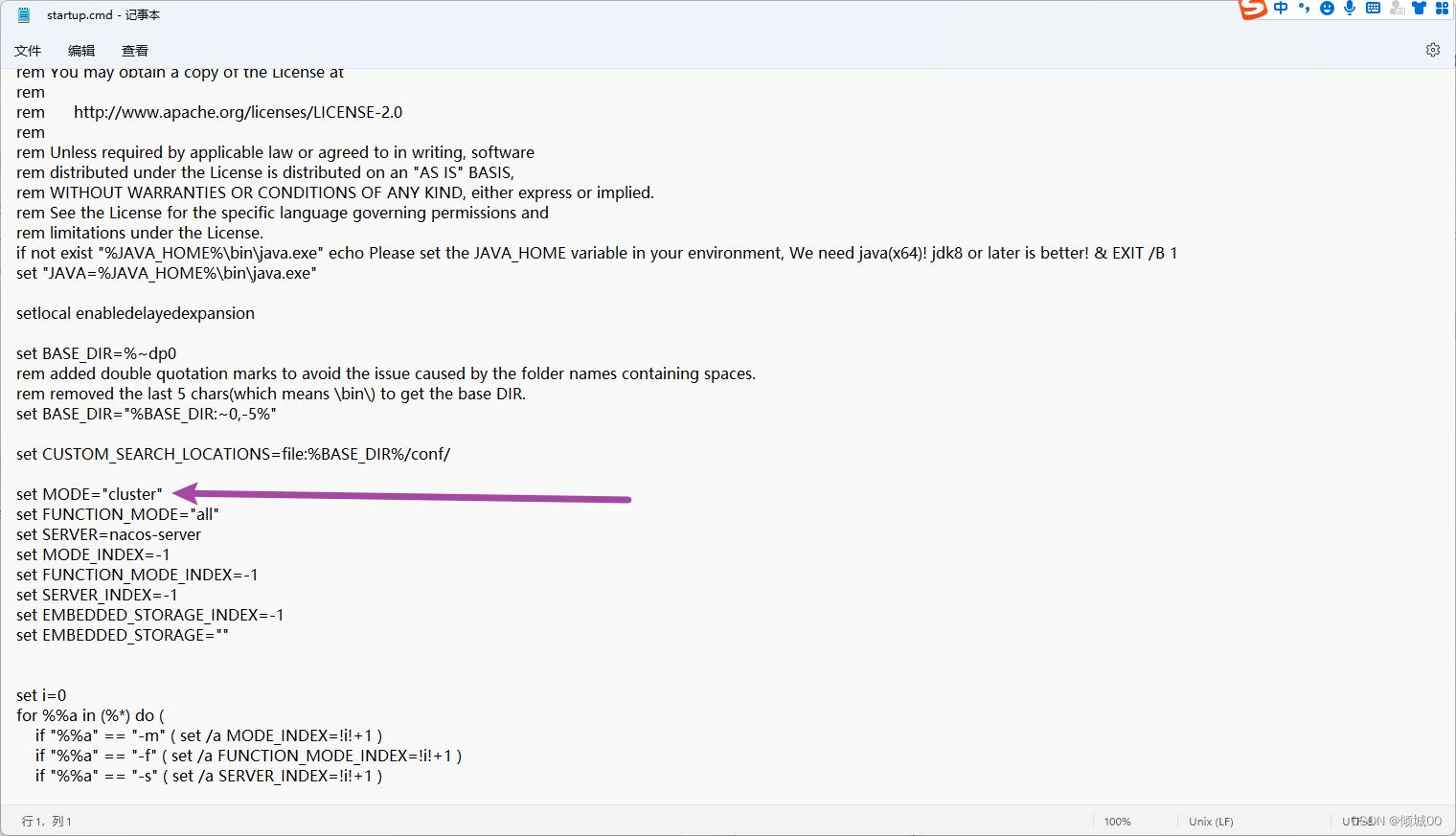
- 因为下面有判断,需要进行更改
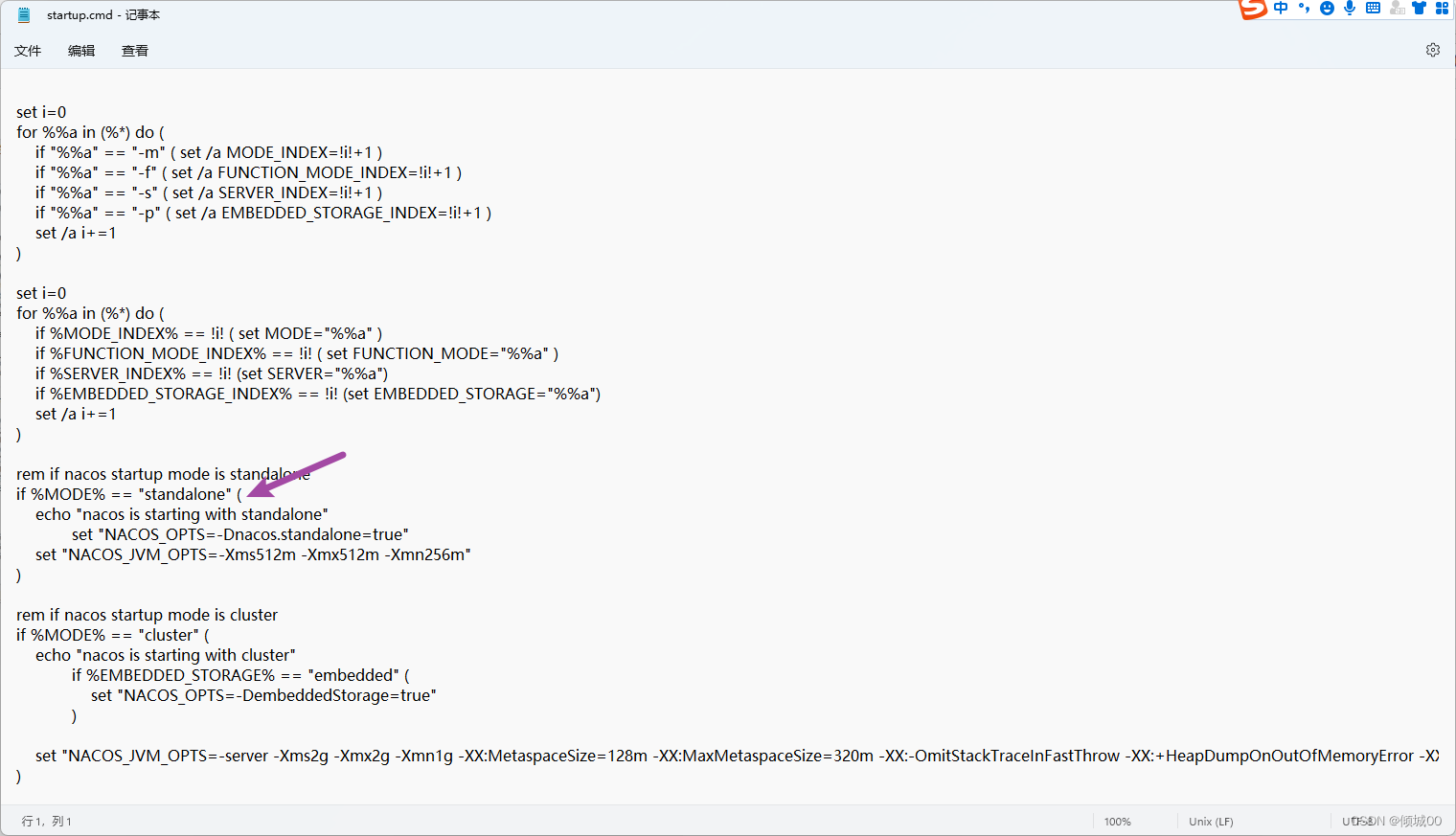
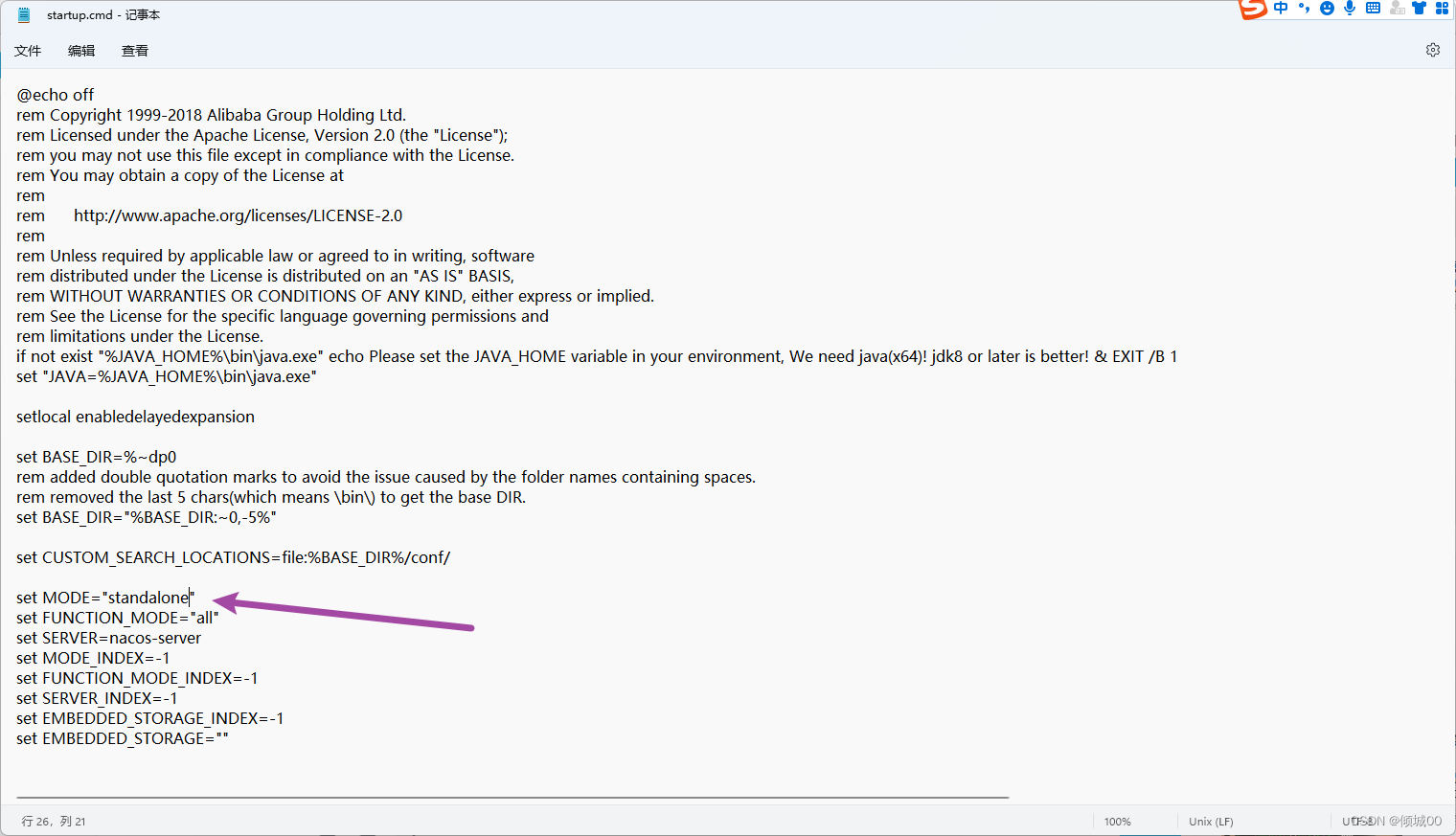
- 可以进行配置
- 可以配置虚拟目录,连接超时,数据源等(数据源不配置的话默认是在内存中也可以把他保存在mysql中),单击模式下没有做任何的修改
,
- 双击启动文件就会启动
- 通过这个地址去访问
- 默认账号是nacos,密码时nacos
13.4 Nacos客户端的配置
<!-- nacos-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
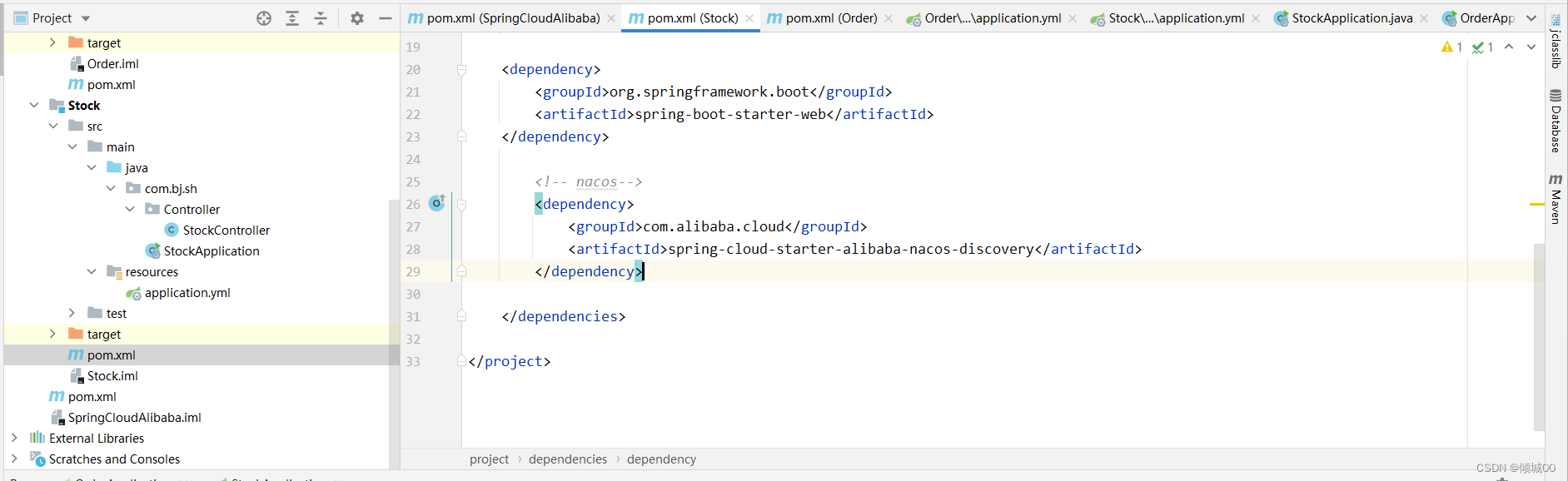
server:
port: 8011
# nacos的服务的名字
spring:
application:
name: stock-server
cloud:
nacos:
server-addr: 127.0.0.1:8848 #地址
discovery:
username: nacos # 用户名和密码,下面的是命名空间
password: nacos
namespace: public
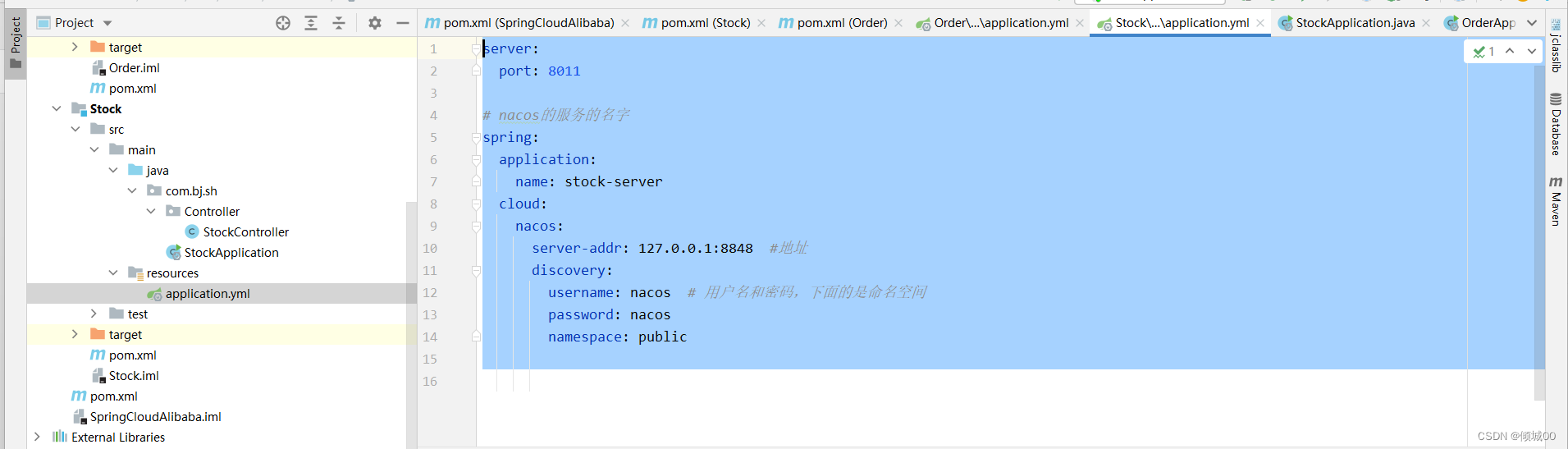
- 订单和库存都需要进行配置
- 健康实例:如果停止的一个项目大概15s,就会发生如下图,超过30s就会剔除
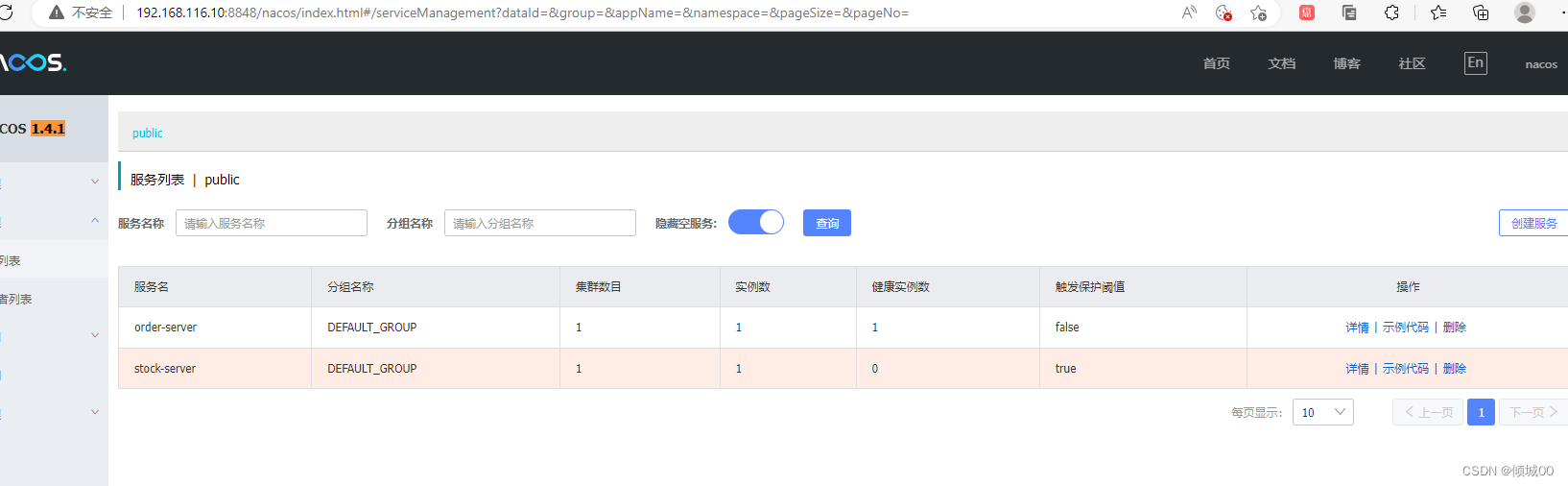
- 通过服务名去下单
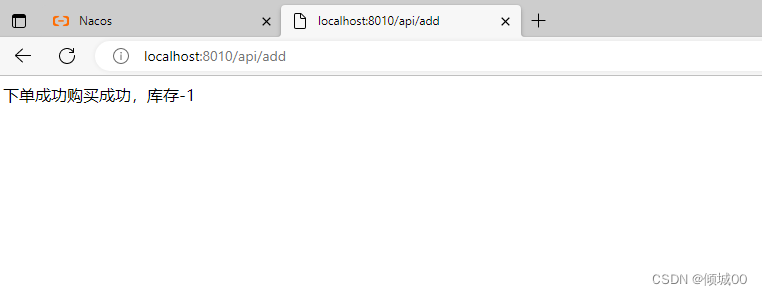
- 和上面的springcloud的restTemplate请求是一样的
13.5 Nacos管理界面
- 可以在这里配置命名空间,可以让多个项目通过命名空间来区分,也可以通过环境来配置(没有决定的配置标准)
- 如果设置雪崩保护的话介意设置0-1的数值,就是一个百分比,
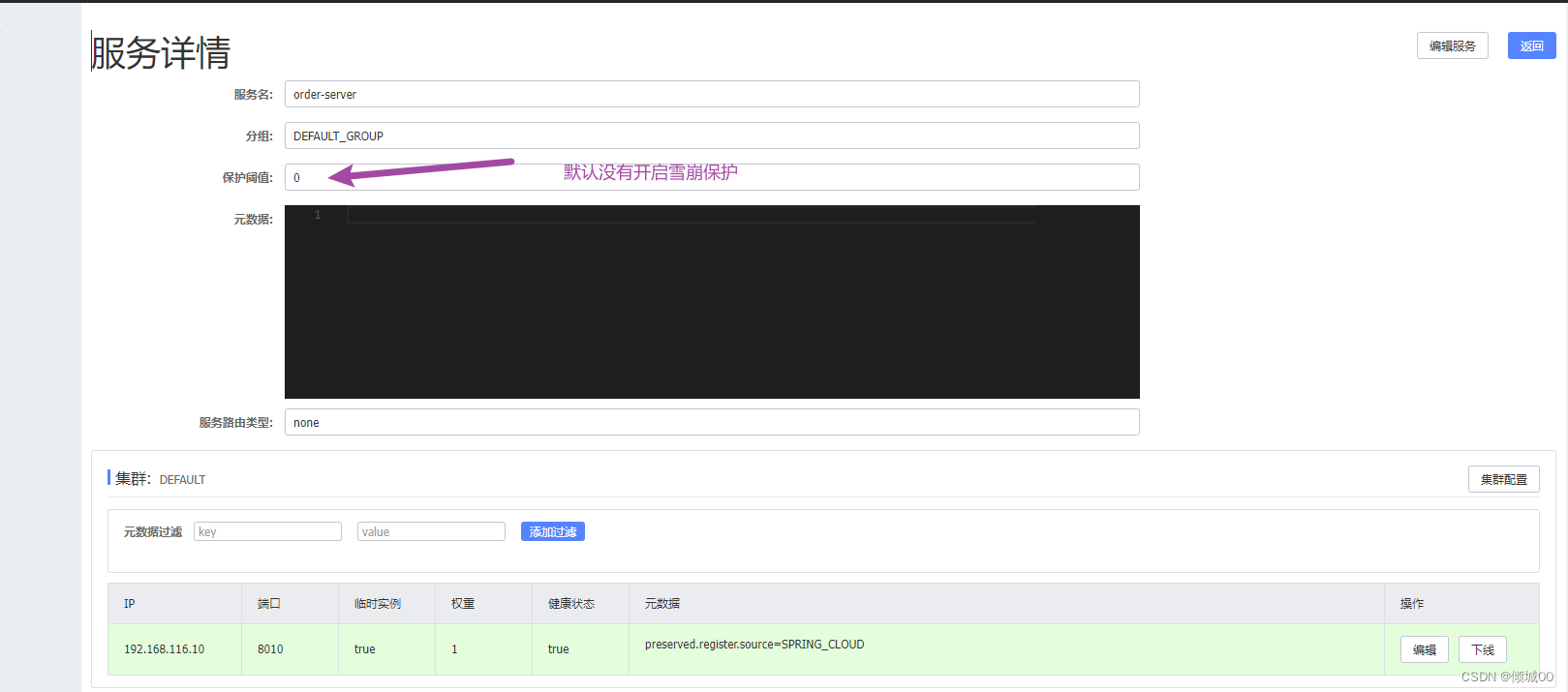
- 这个实例变量时ture就是临时的,如果服务挂了,15s之后就会变成不健康30s就会剔除服务
- 可以在配置文件当中进行设置,false为永久实例,就是服务挂了,但是不会下线
- 学等的配置,如果咱们一共有两个实例,一个健康实例,一个非健康的实例,设置的雪崩是0.6
- 那么就是 健康实例/总实例<雪崩
- 现在的健康实例是1,总实例是2,雪崩是0.6 1/2=0.5 0.5<0.6 就会触发学等机制,就会将已经不健康的拿给你用,防止大流量到来,导致宕机

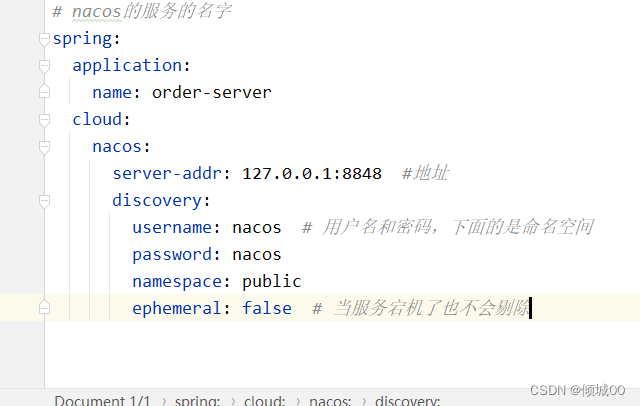
13.5 Nacos的配置
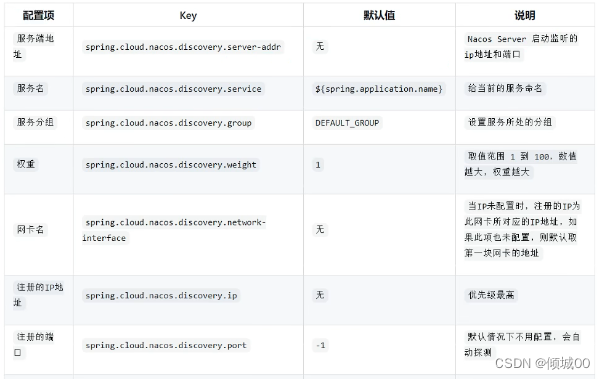
13.5 Nacos Linux下集群的搭建
- 所需环境 nginx
- jdk8
- nacos
-
- 首先下载Nacos
- 首先下载Nacos
- 下载好,传递进来,然后解压

- 一台虚拟机配置集群,所以解压三分

-
- 配置8849的application.properties
- 配置数据源,因为如果不配置的就是默认存在于内存中的,3个进程就是三个内存,配置一台mysqll,会实现数据的统一(mysql需要使用5.7+)
- 在mysql中执行这个mysql文件
-
- 修改文件改成对应的nacos的ip
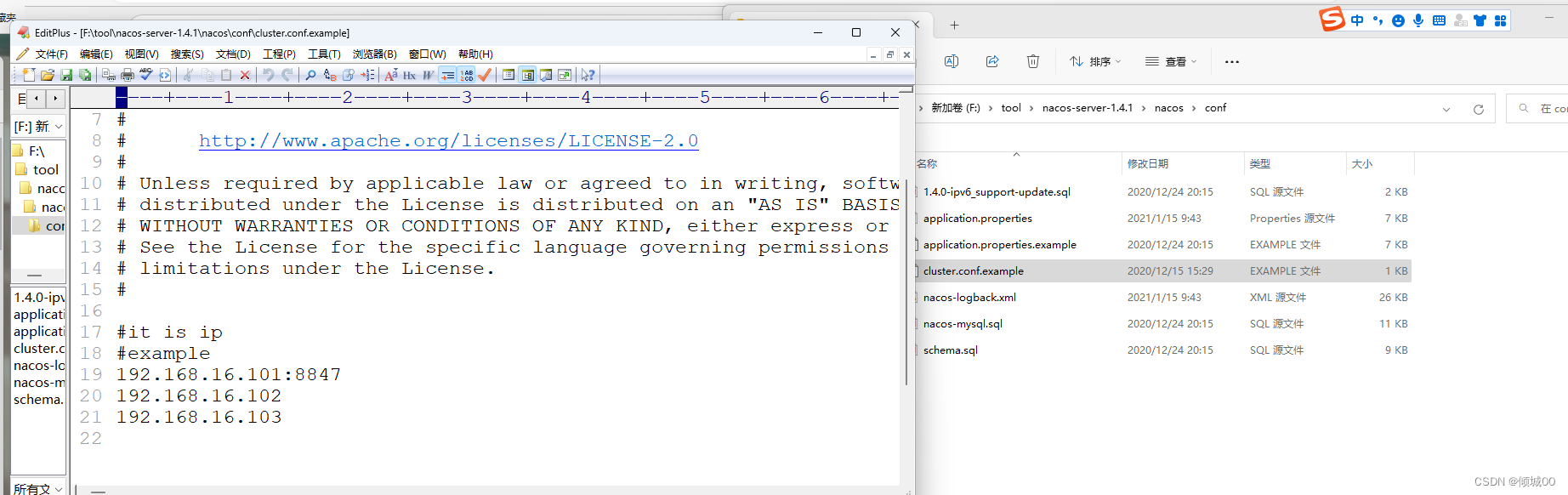
- 修改文件改成对应的nacos的ip
-
- 修改启动文件(如果虚拟机的内存不是很富裕,需要更改这个,将jvm的参数调小避免内存不足)
-
- 修改nginx文件,让其可以负载均衡的到对应的naos上
- 修改8849的application.properties文件,修改端口,打开mysql连接(我设置的是连接的我本地的mysql)

-
- 在本地的mysql中创建数据库,执行sql文件

- 在本地的mysql中创建数据库,执行sql文件
-
从user表就能看出来,是用nacos这个账户去登录对应的管理平台。就是将数据维护到了对应的数据库中
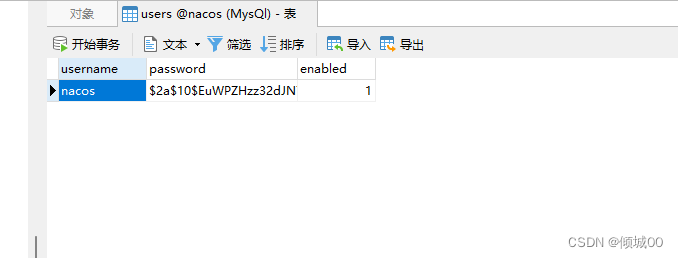
-
拷贝一份文件,修改ip地址
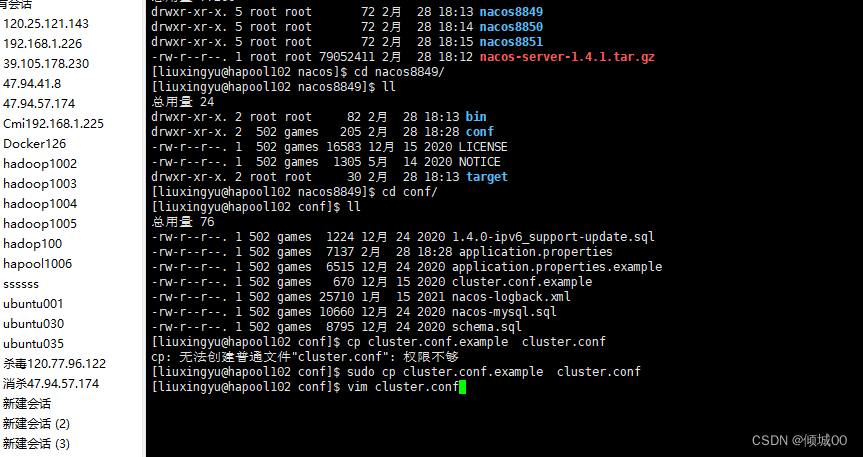
-
修改集群的ip和端口
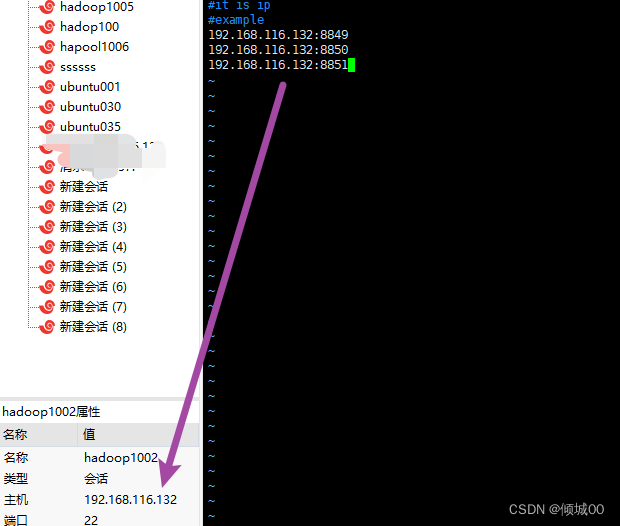
-
修改启动文件,现在就是单节点集群装填,所以不用修改类型
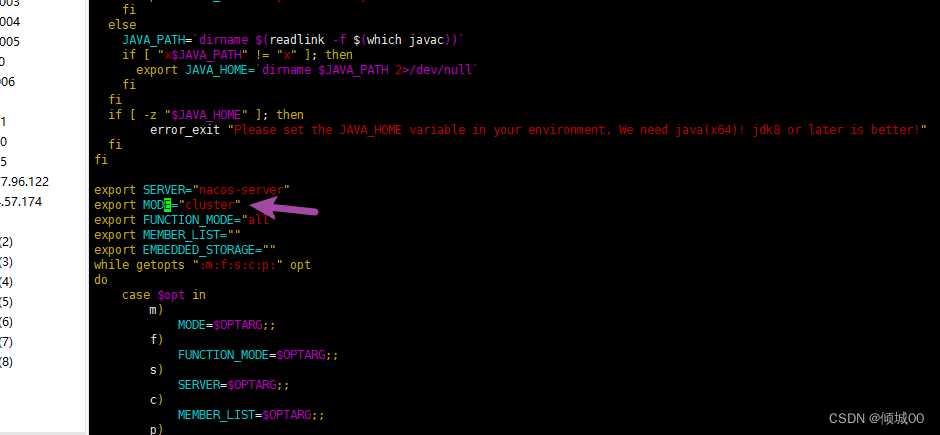
-
因为我的这个虚拟机内存小,所以参数调小点
-
启动查看日志,发现启动成功
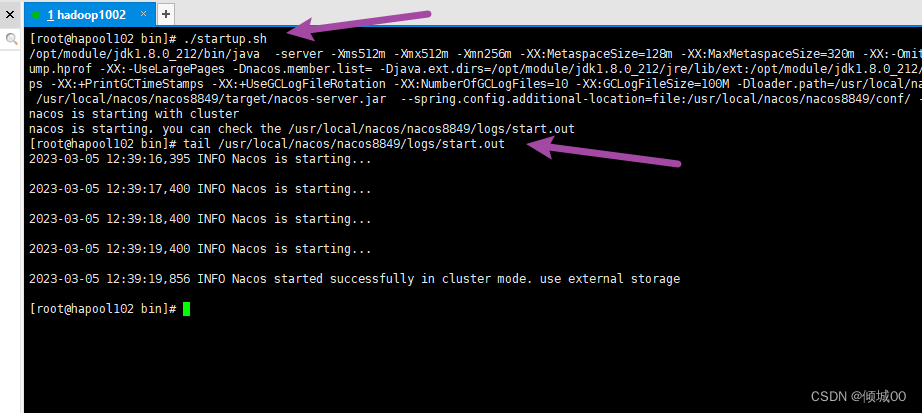
-
打开浏览器可以访问成功

- 在这个地方就可以看到配置的节点
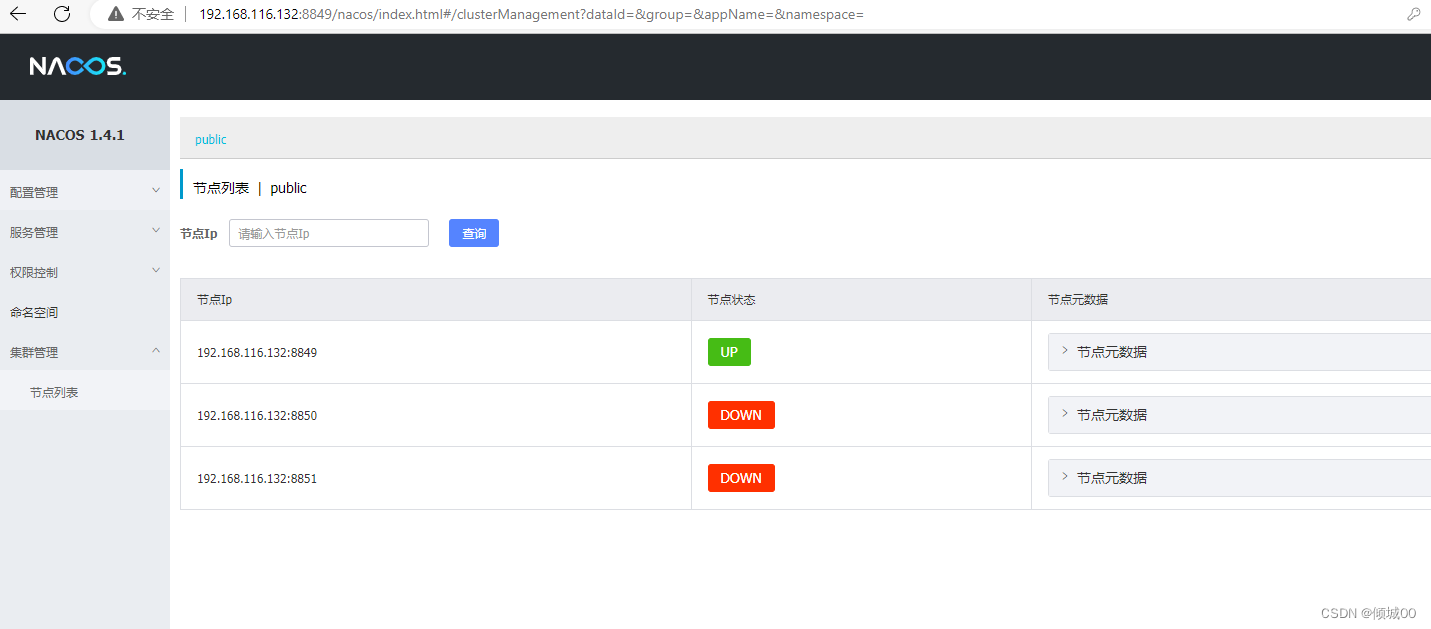
- 加下来将8849的文件拷贝到另外的两台机器上,修改两个文件的application.properties文件,修改称为对应的端口
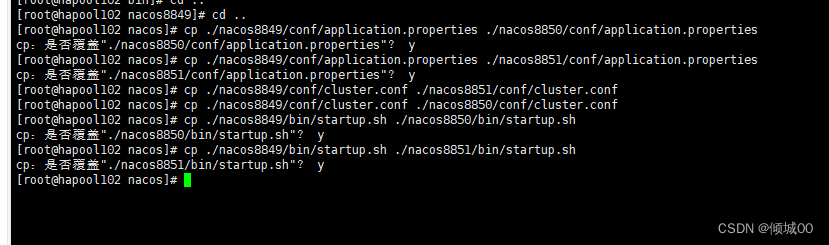
- 启动另外的两台服务器

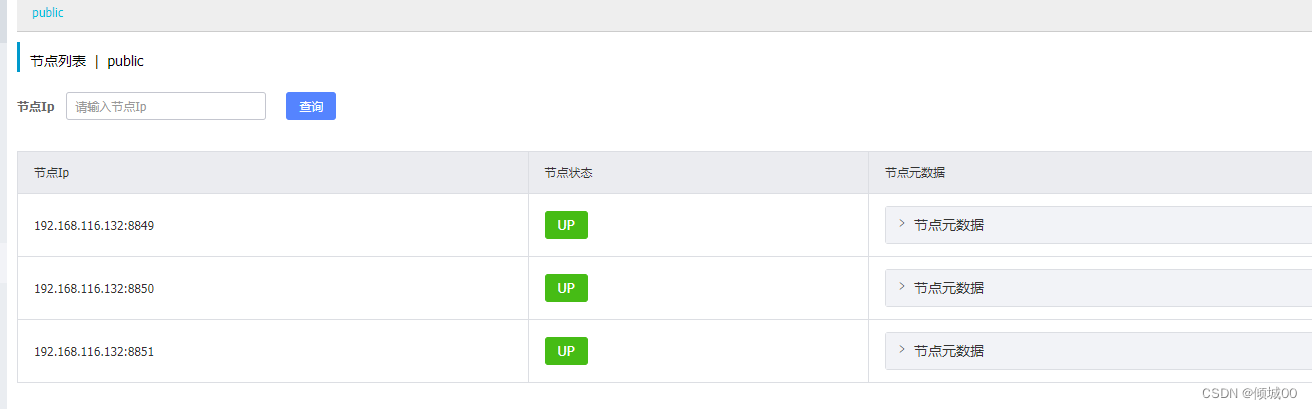
集群全部启动成功了 - 然后安装nginx
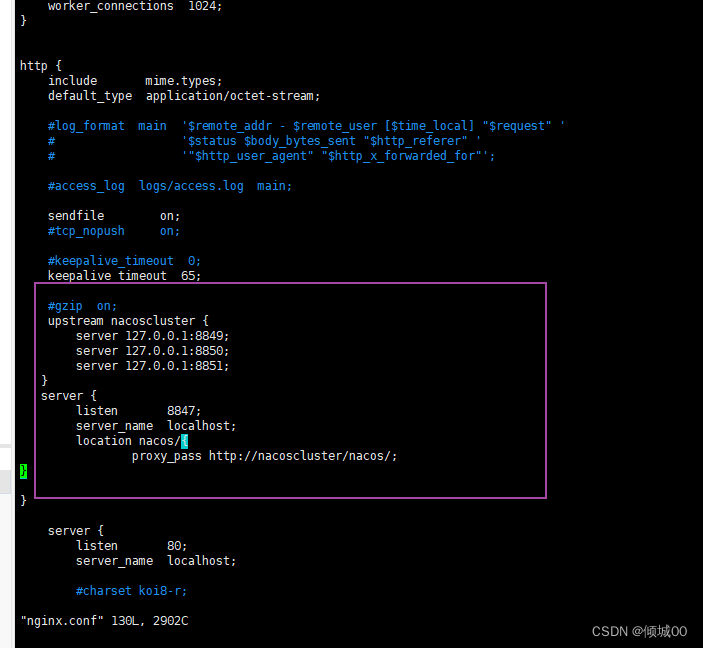
upstream nacoscluster {
server 192.168.116.132:8849;
server 192.168.116.132:8850;
server 192.168.116.132:8851;
}
server {
listen 8847;
server_name localhost;
location / {
proxy_pass http://nacoscluster;
root /nacos/;
}
}
- nginx监听的端口号是8847,访问这个端口会负载均衡的转发到8849,8850,8851,就是集群模式的均衡
- 浏览器输入http://192.168.116.132:8847/nacos/
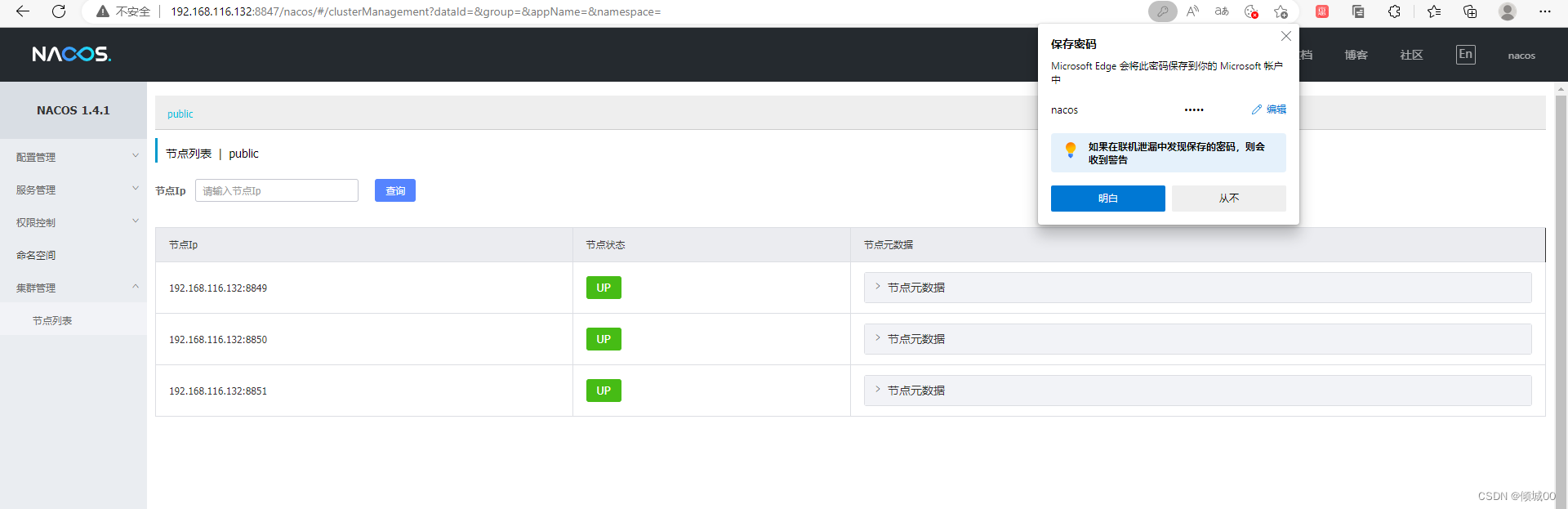
- 代码的nacos地址变为nginx地址,通过nginx的地址去负载均衡到三台集群
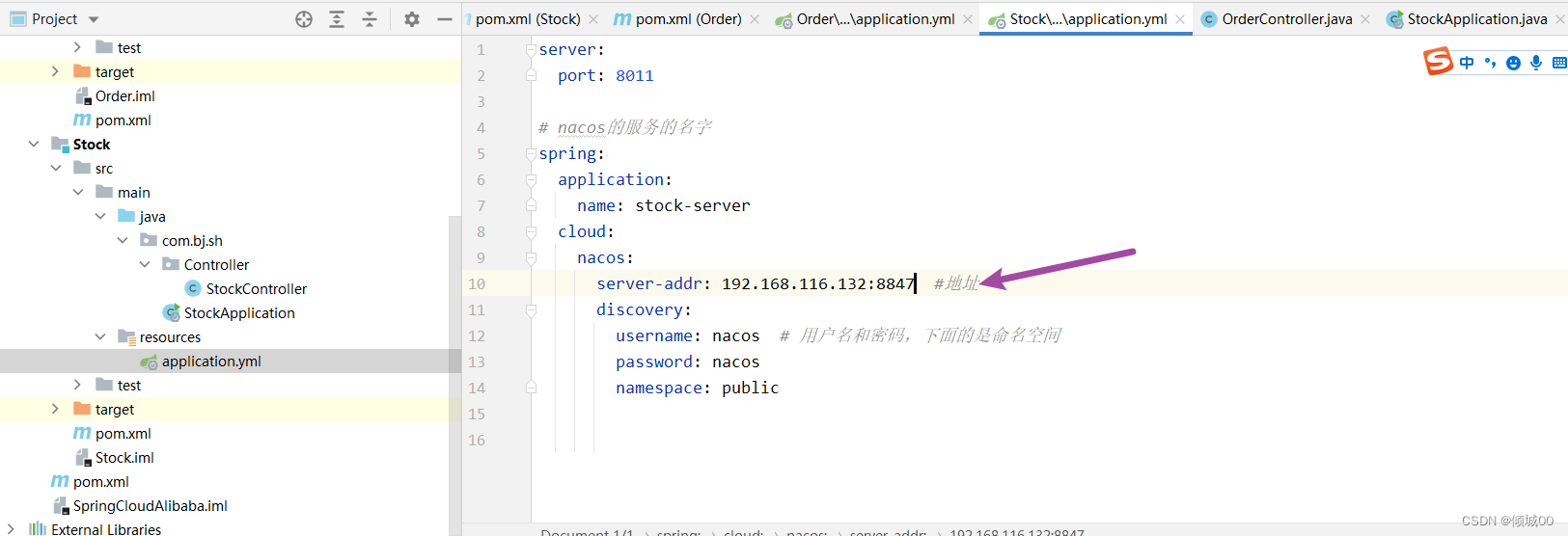
- 这样集群就部署完成了,
13.6 openFegin
- 复制一份订单模块修改端口
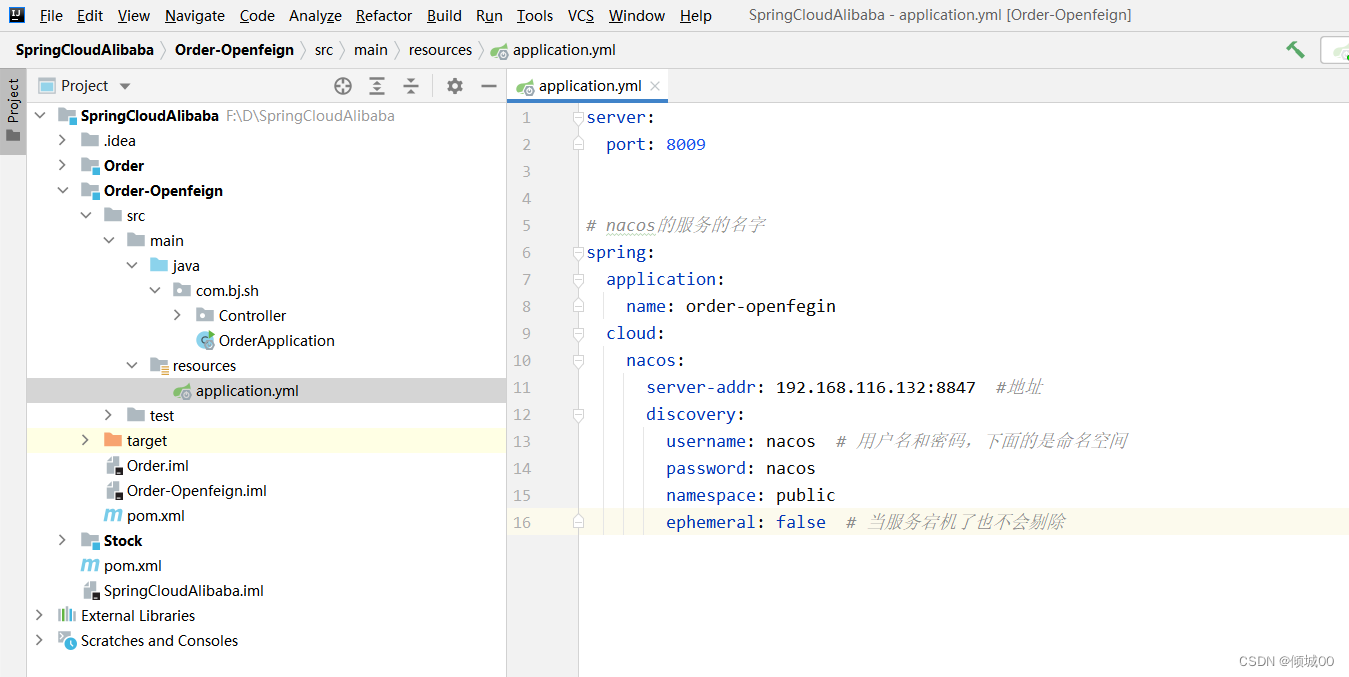
- 父po记得添加springcloud的依赖,因为他是依赖于springcloud的
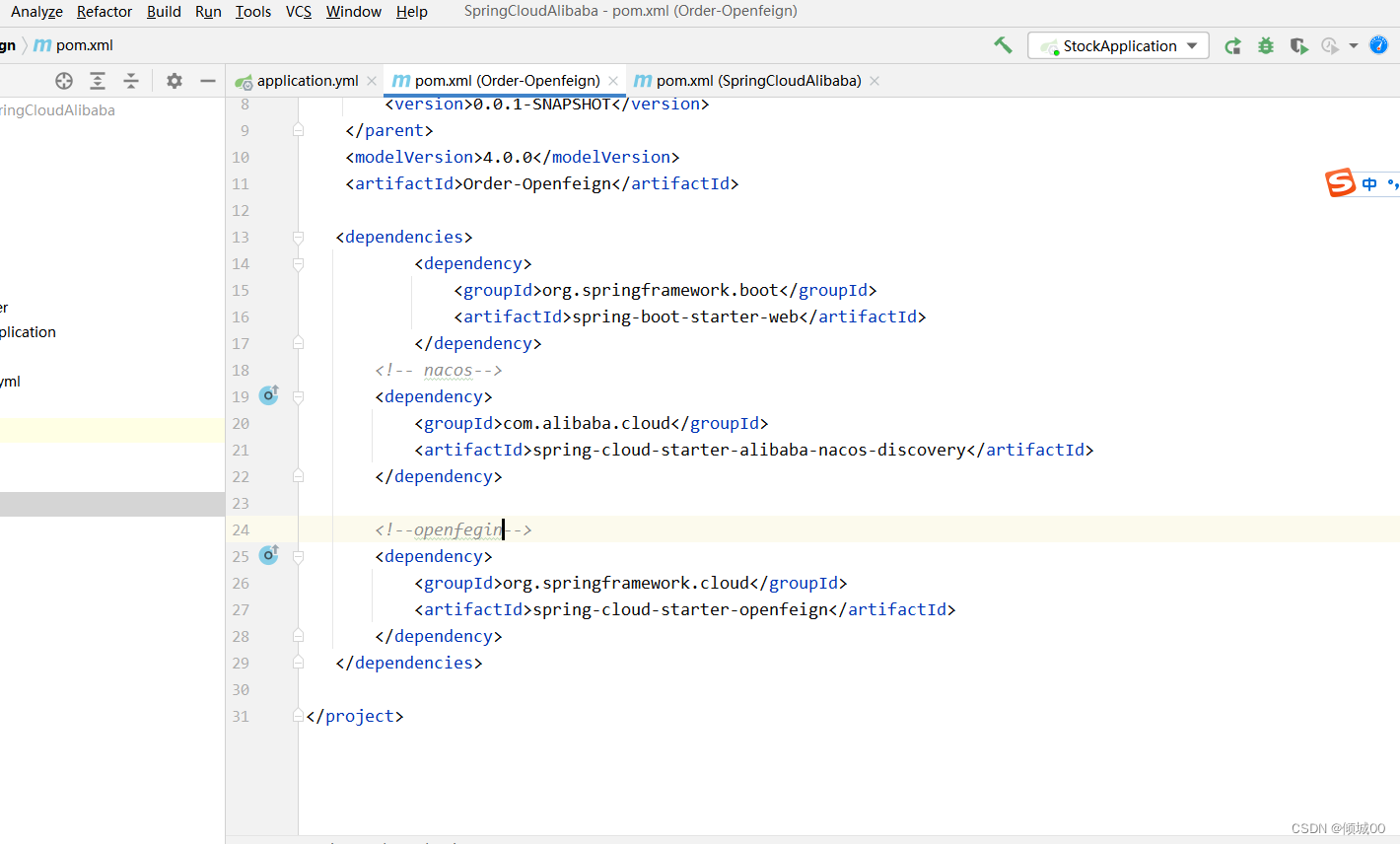
# 不需要指定版本,因为他所依赖的父pom中springcloud中已经指明了版本
<!--openfegin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>

- @FeignClient注解填写被调用的服务名字,通过服务区访问对应的路径
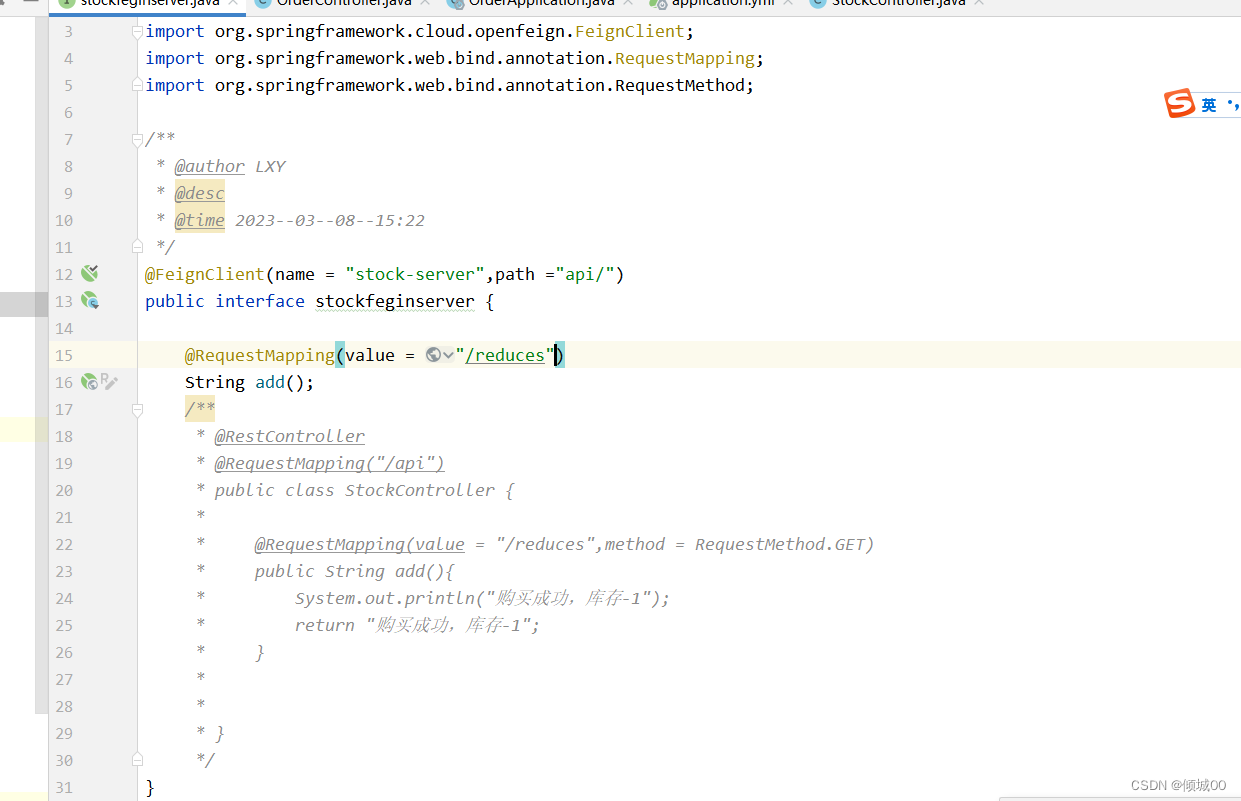
- c层注入进来,调用方法
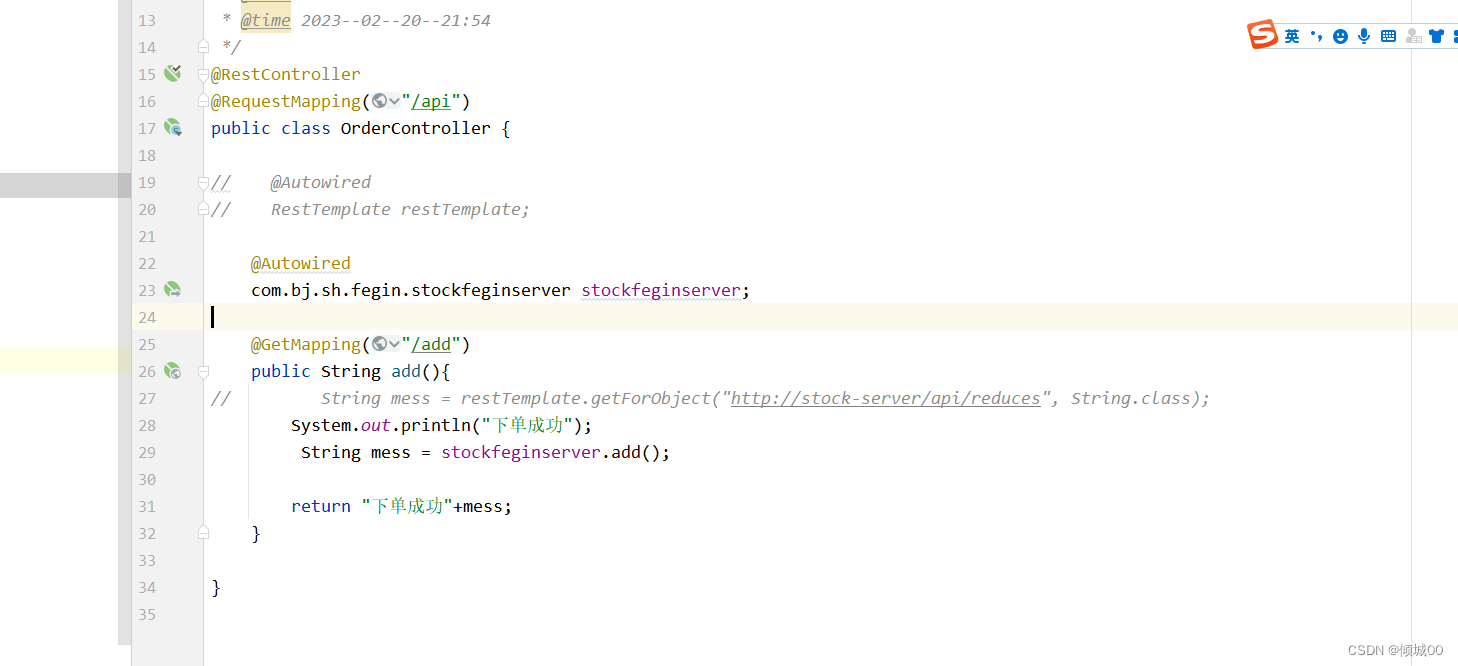
- 启动类添加上发现openfegin的注解
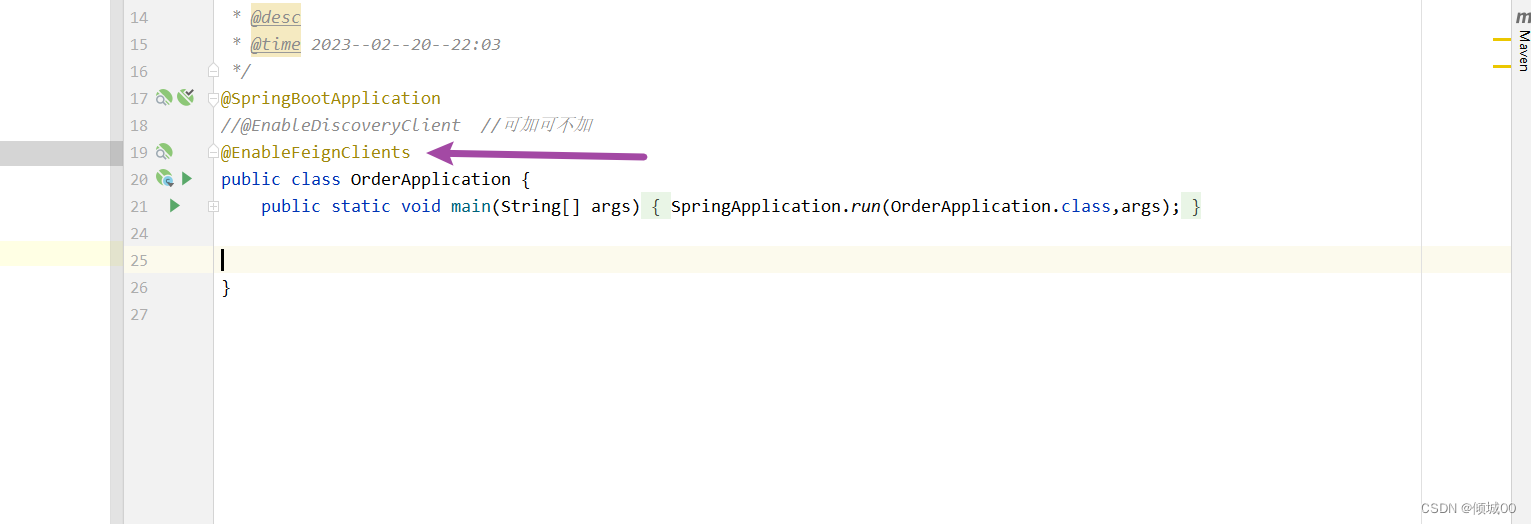
- 浏览器访问c层接口就会通过openfegin去访问库存接口

13.6.1 openFegin的日志配置
- fegin提供了很多扩展机制,可以让用户更加灵活的使用
- openfegin有4种日志级别,分别是
-
- NONE(性能最佳,适合生产)不记录任何日志
-
- BASIC(适用于生产环境追踪问题)仅记录请求方法,URL,响应状态以及代码的执行时间
-
- HEADRS 记录HEADRS级别的基础上,请求记录和响应的header
-
- Full(比较适用于开发以测试环境定位问题)记录请求和响应的head,body和元数据
- 首先在新建一个调用的接口
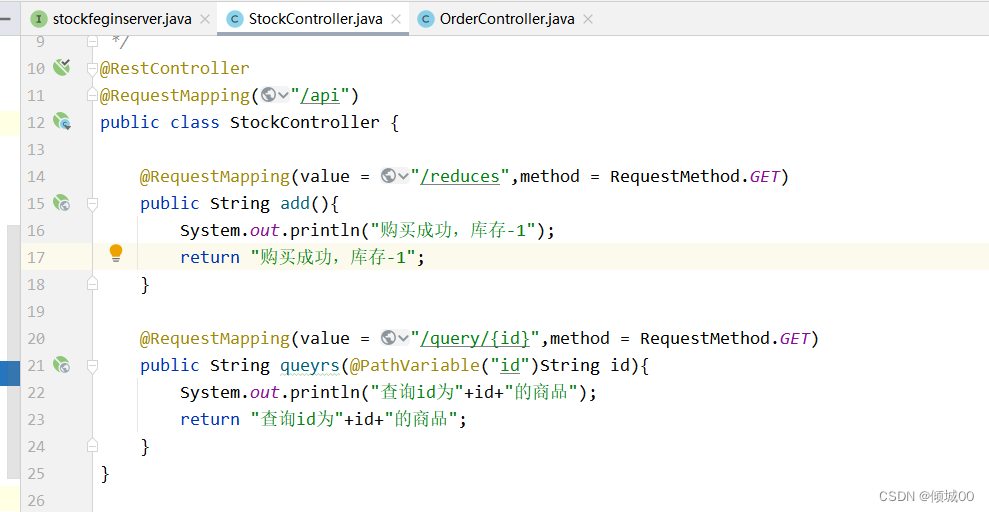
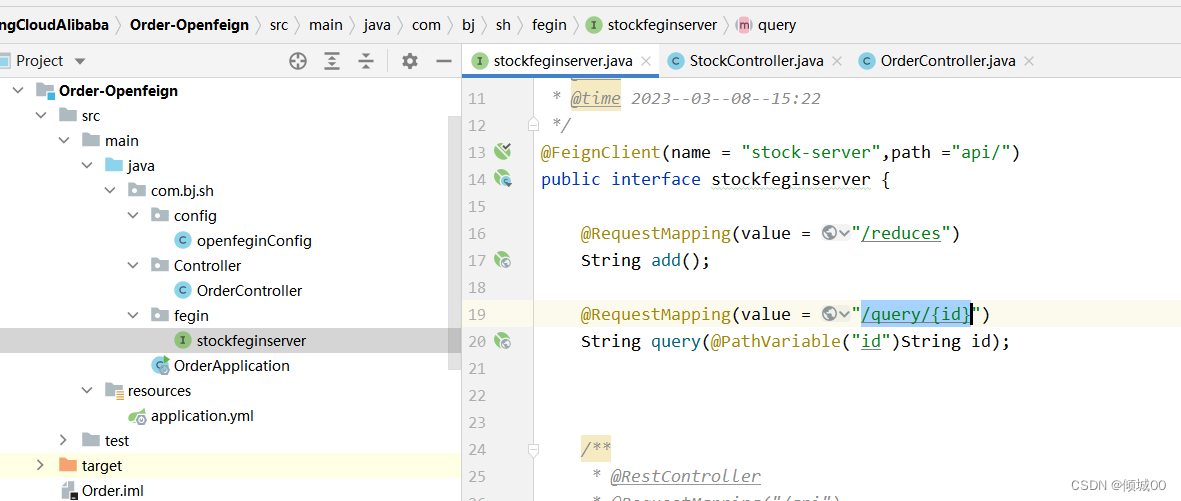
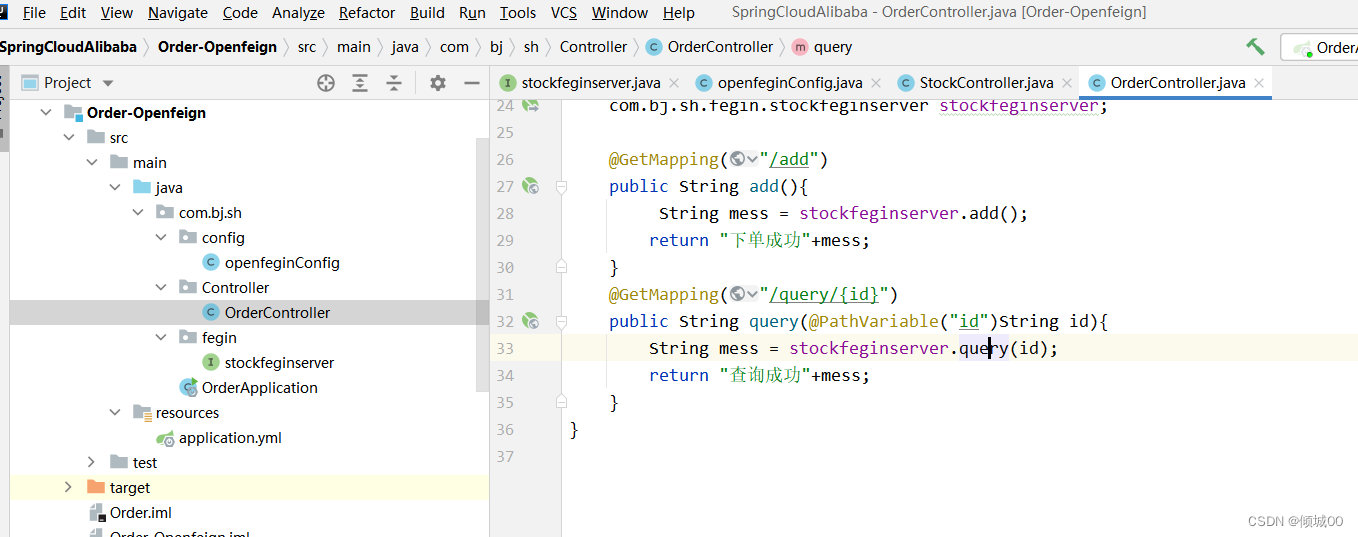
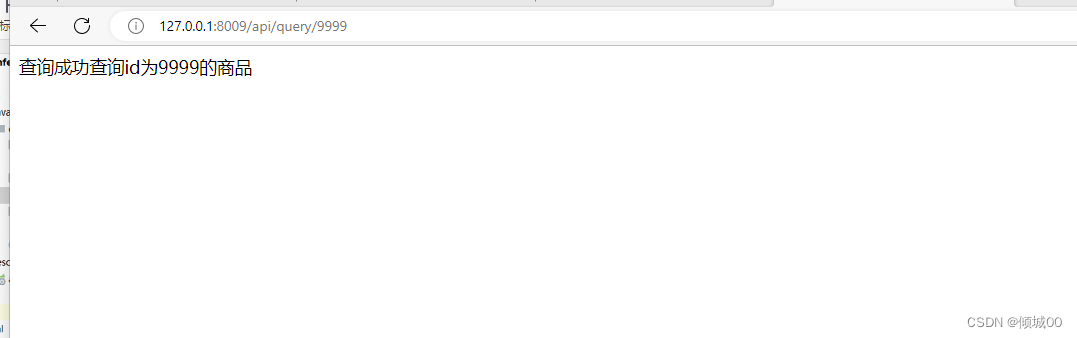
- 开始配置日志
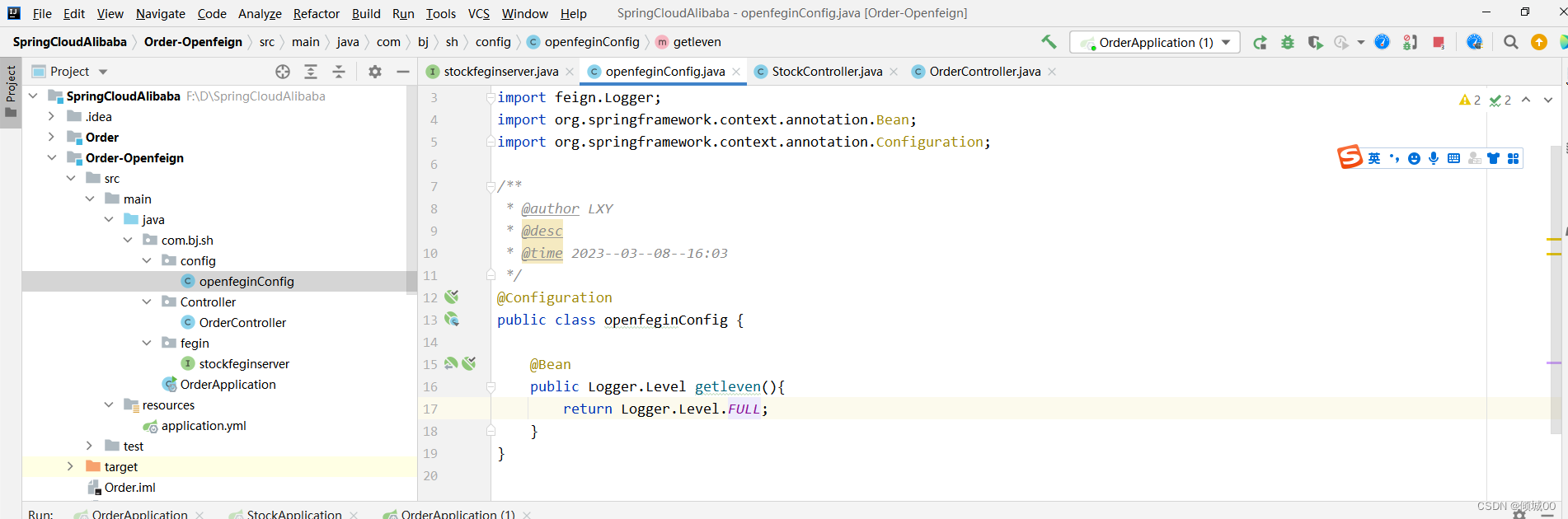
package com.bj.sh.config;
import feign.Logger;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author LXY
* @desc
* @time 2023--03--08--16:03
*/
@Configuration
public class openfeginConfig {
@Bean
public Logger.Level getleven(){
return Logger.Level.FULL;
}
}
- 设置的是FULL类型的
- 需要在applicationyml中配置,因为openfegin是以debug的形式打印的,springboot是info日志
- 对指定的路径进行debug的日志输出
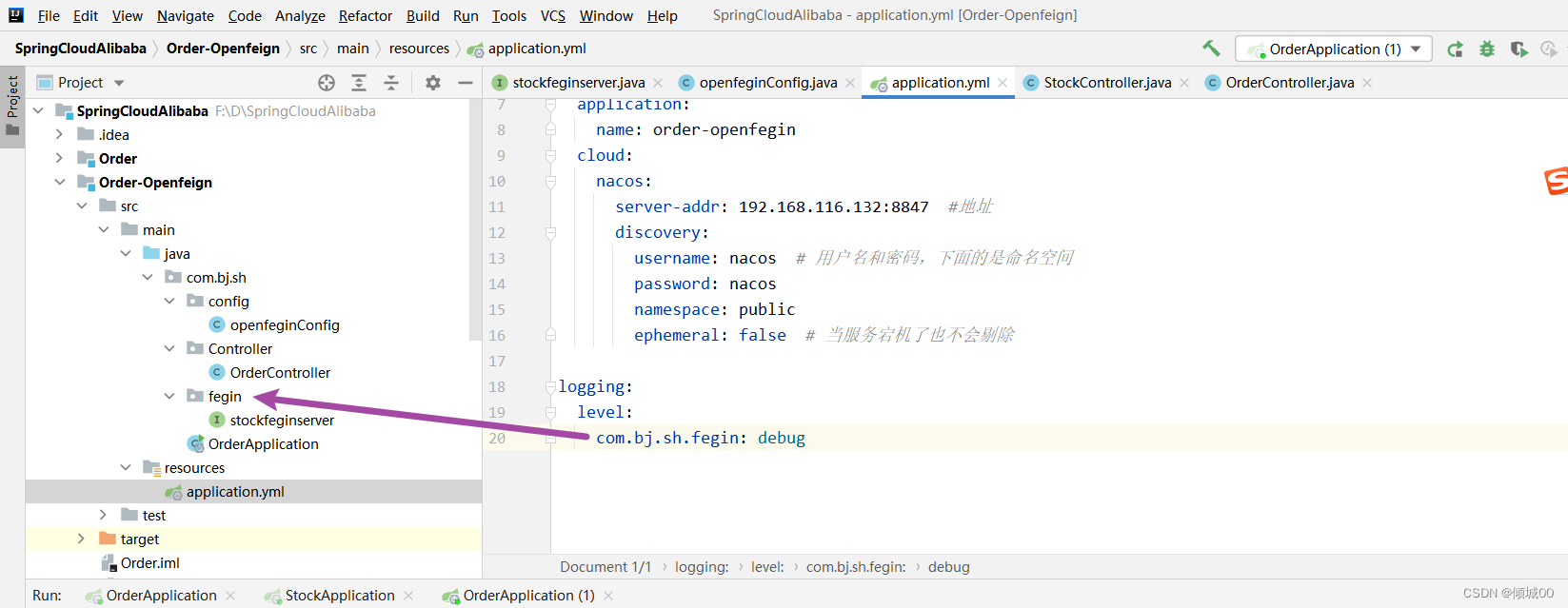
- 可以再控制台看到请求路径,请求头等信息
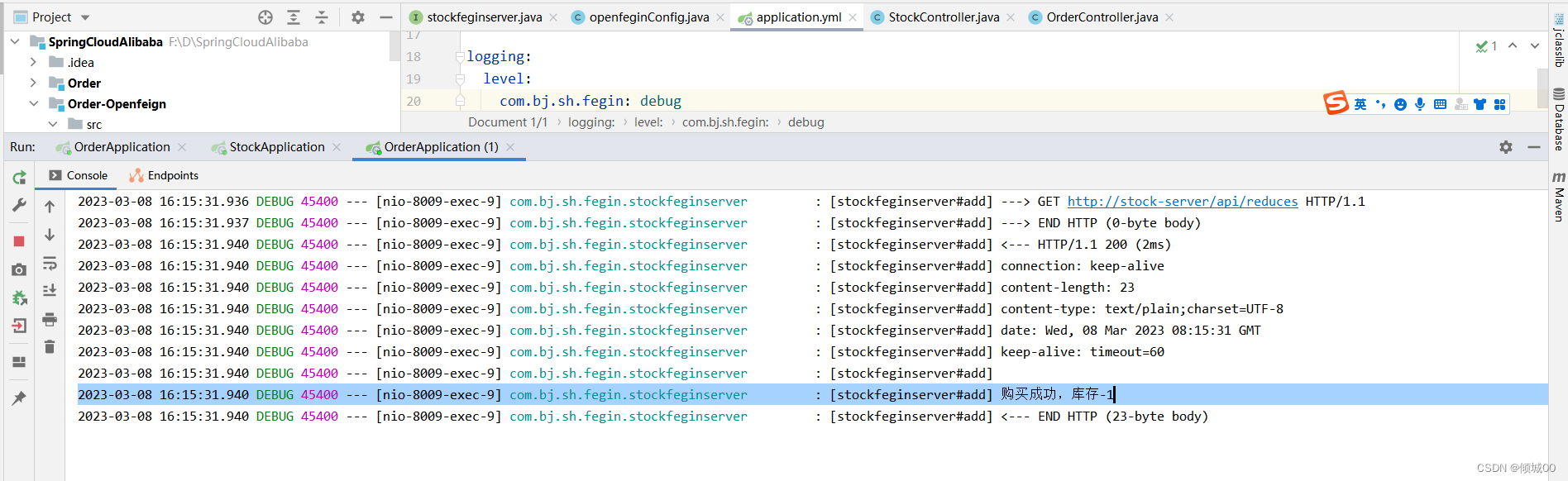
- 上面是配置的全局的,如果是配置局部的将注解注释掉
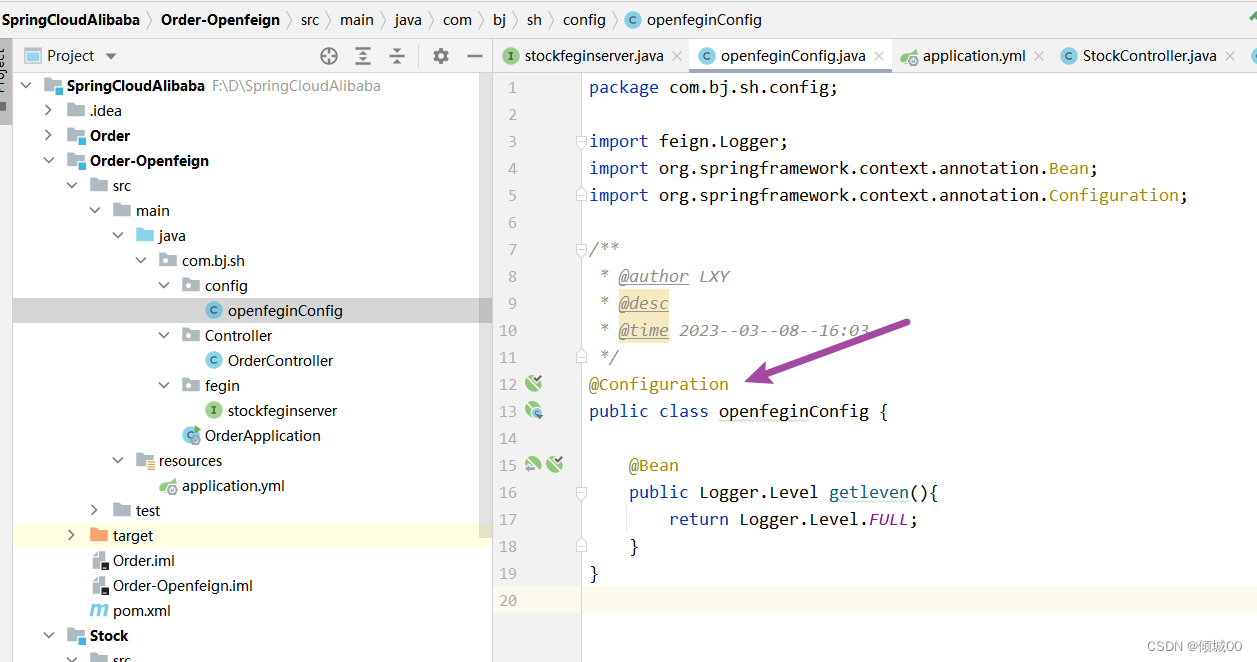
- 然后再你需要配置的接口中添加
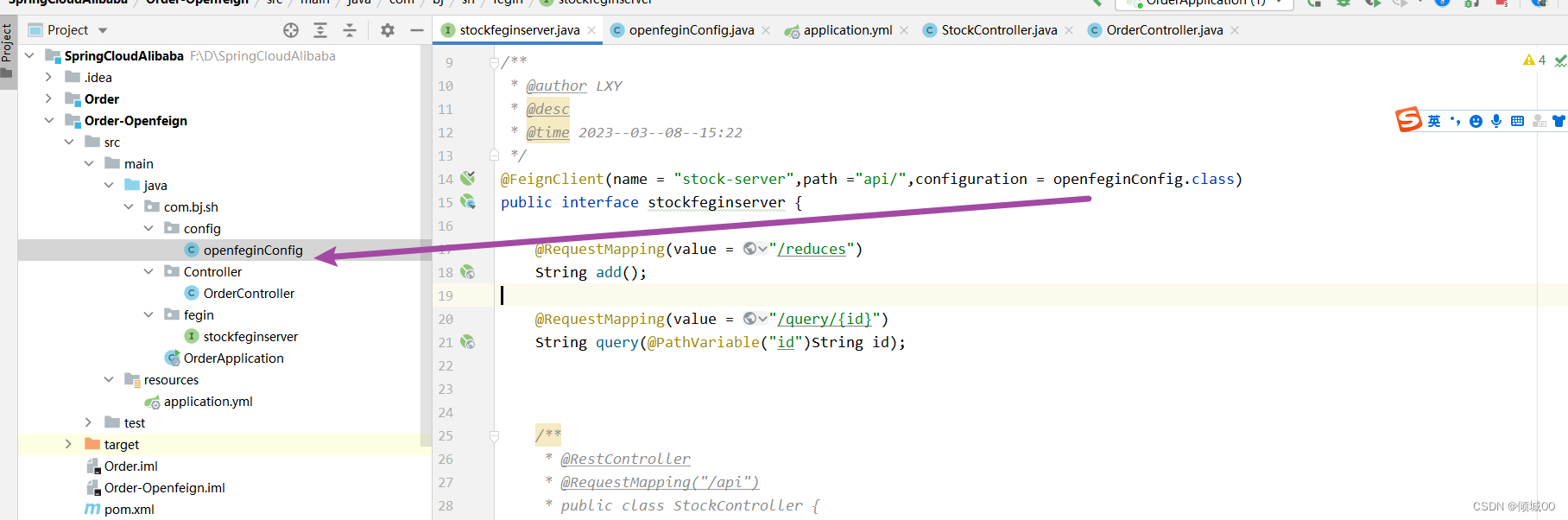
- 也可以通过配置文件的方式去对对应的服务名的数据配置日志
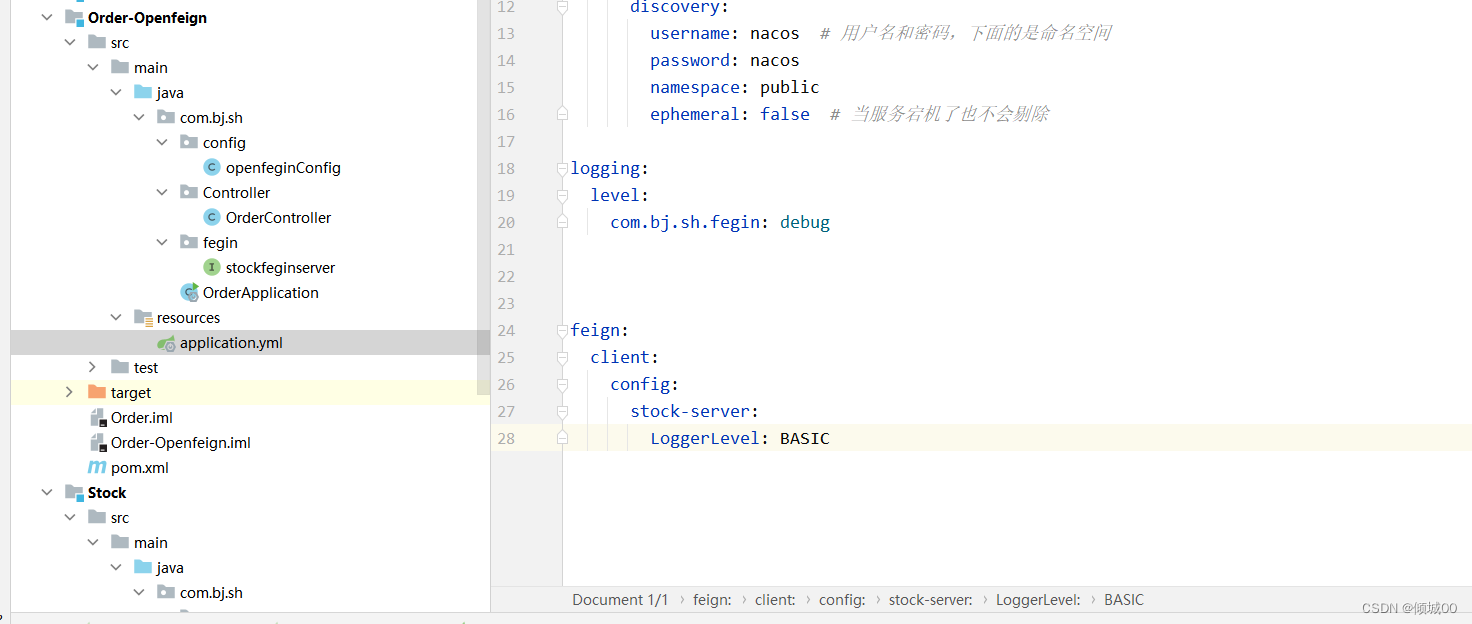
- 效果如下
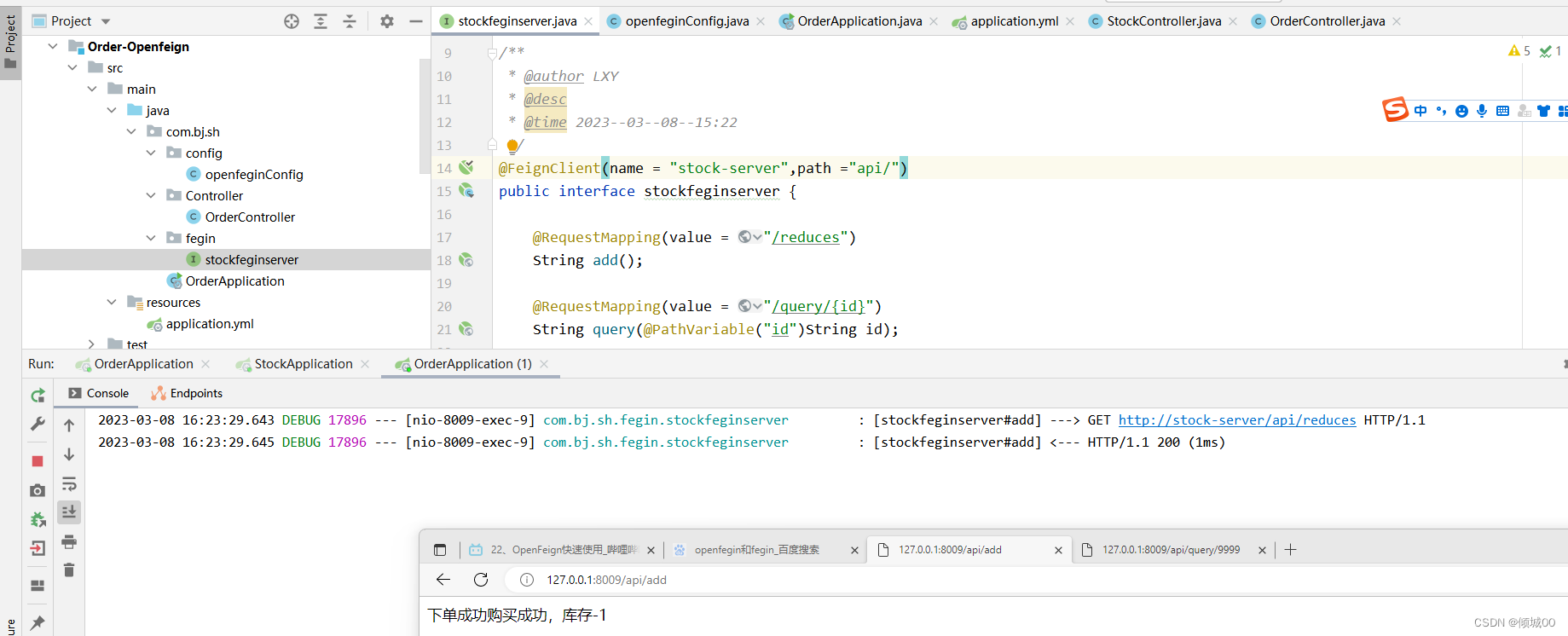

13.6.2 openFegin的超时时间配置
- 这个是全局的配置
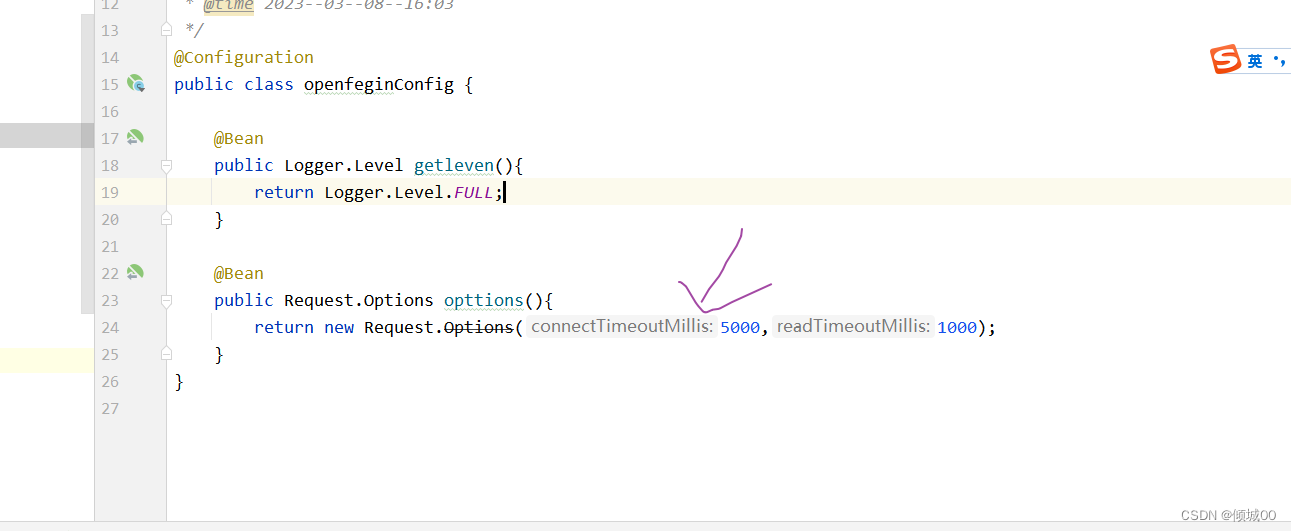
- 局部配置
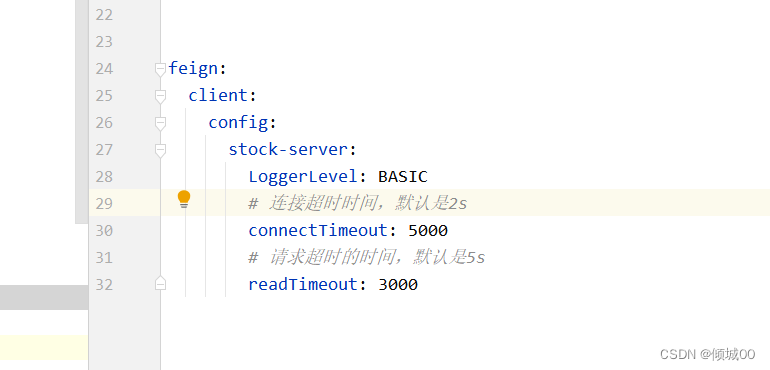
feign:
client:
config:
stock-server:
LoggerLevel: BASIC
# 连接超时时间,默认是2s
connectTimeout: 5000
# 请求超时的时间,默认是5s
readTimeout: 3000
- 设置的请求超时是3s,睡4s就直接超时了
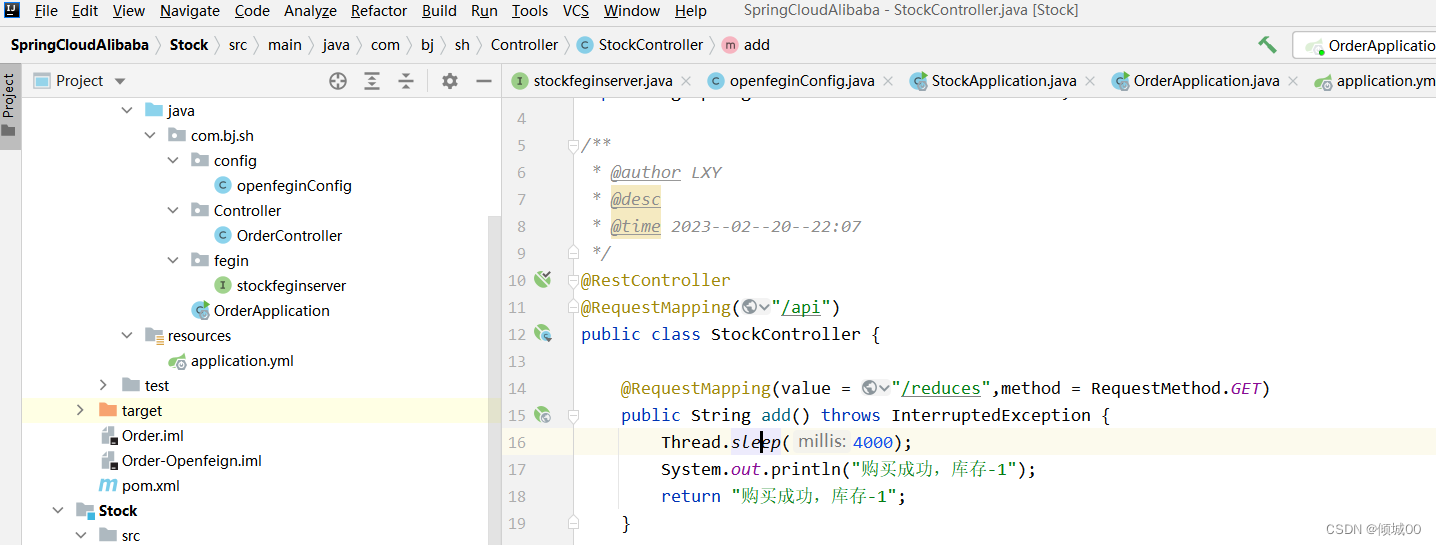
13.6.3 openFegin自定义拦截器

package com.bj.sh.config;
import feign.RequestInterceptor;
import feign.RequestTemplate;
/**
* @author LXY
* @desc
* @time 2023--03--08--17:06
*/
public class openfegininner implements RequestInterceptor {
public void apply(RequestTemplate requestTemplate) {
requestTemplate.header("token","456");
}
}
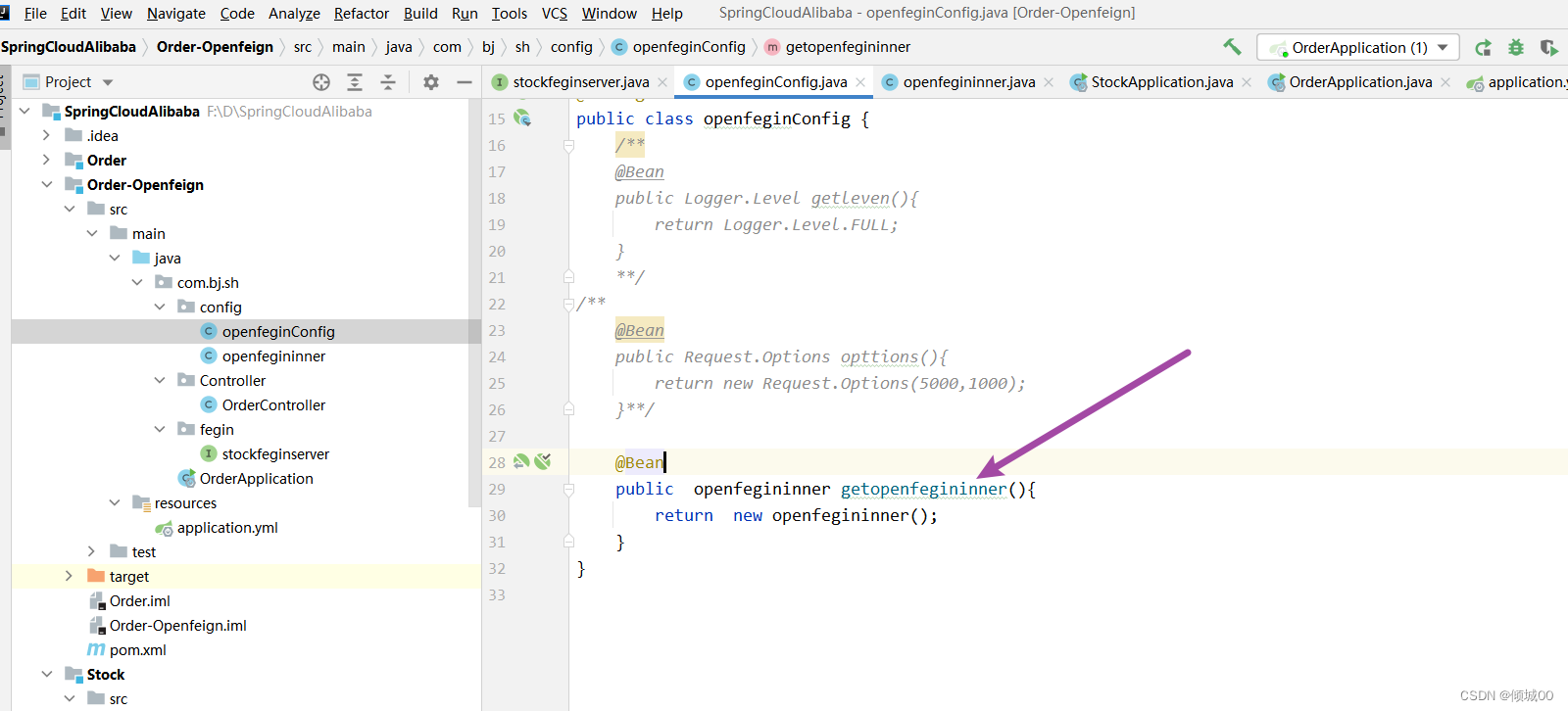
- 局部配置的方法
feign:
client:
config:
stock-server:
LoggerLevel: BASIC
# 连接超时时间,默认是2s
connectTimeout: 5000
# 请求超时的时间,默认是5s
readTimeout: 3000
requestInterceptors[0]:
com.bj.sh.config.openfegininner
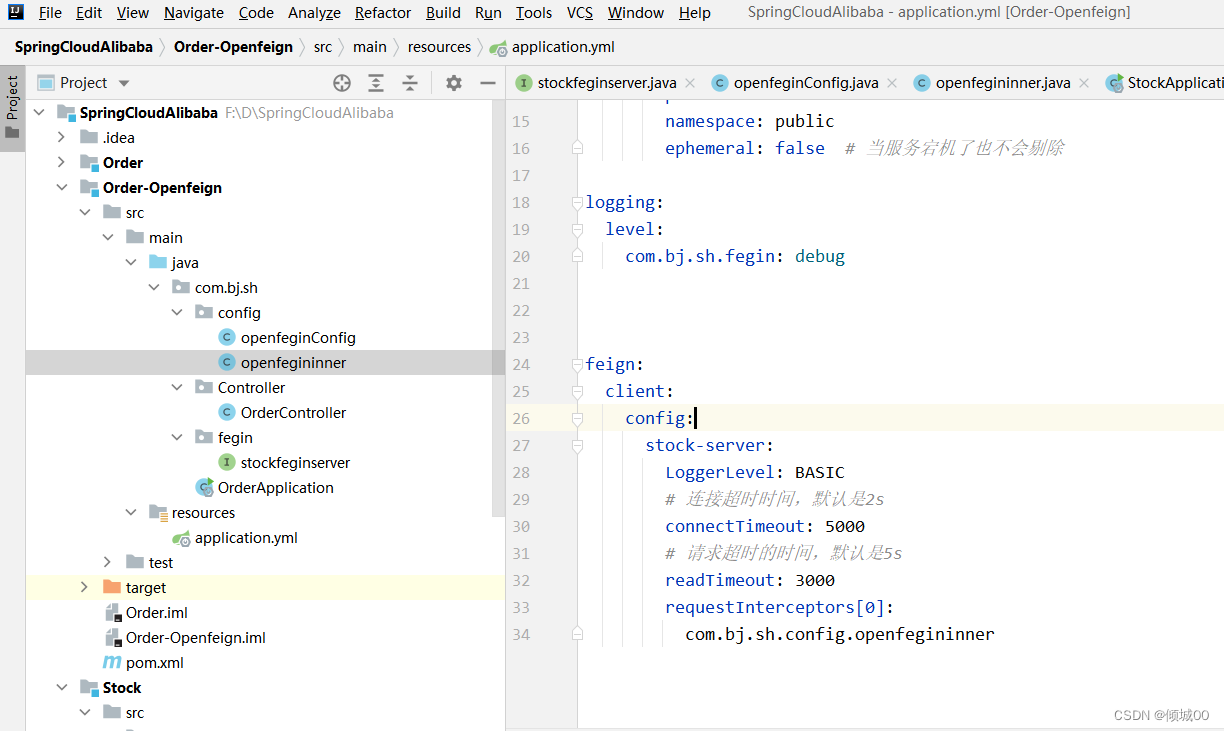
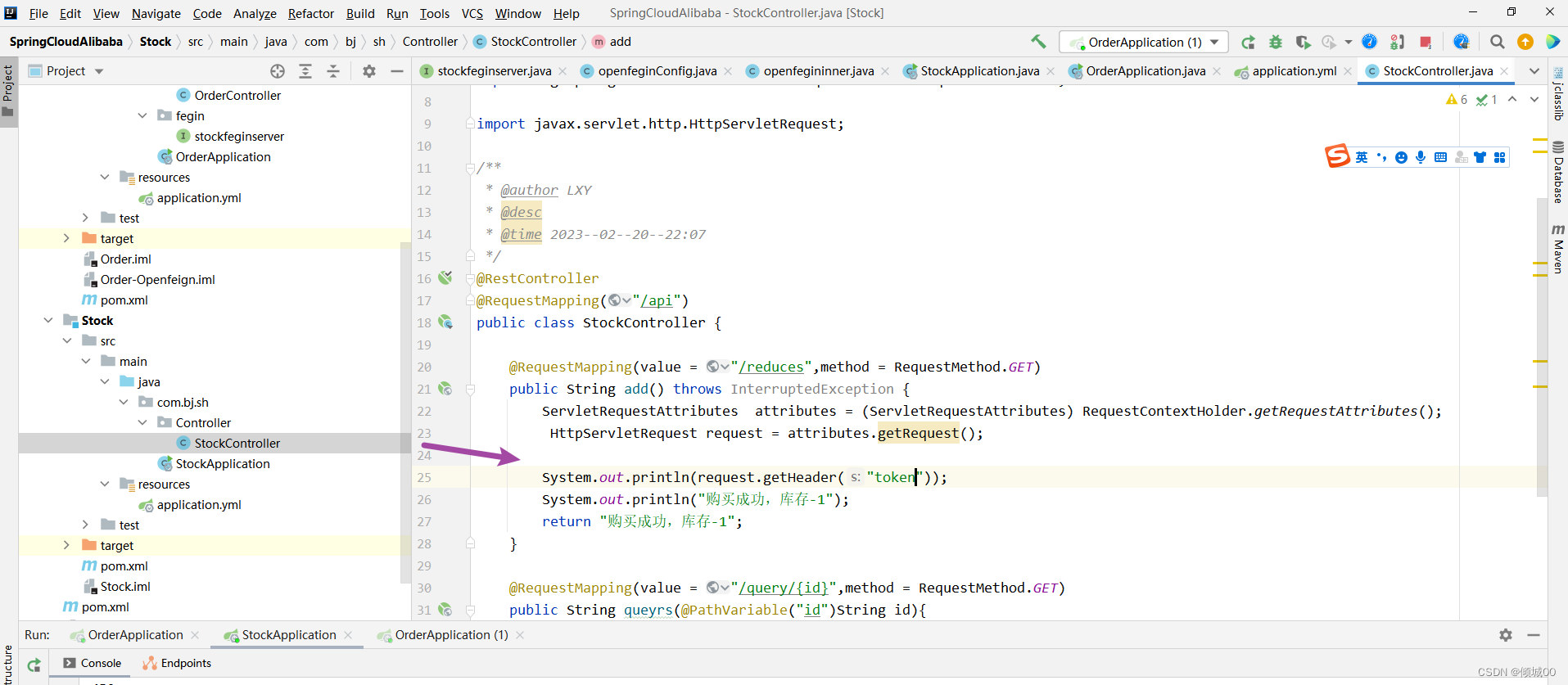
- 最后的效果截图,最后可以得到传递的token
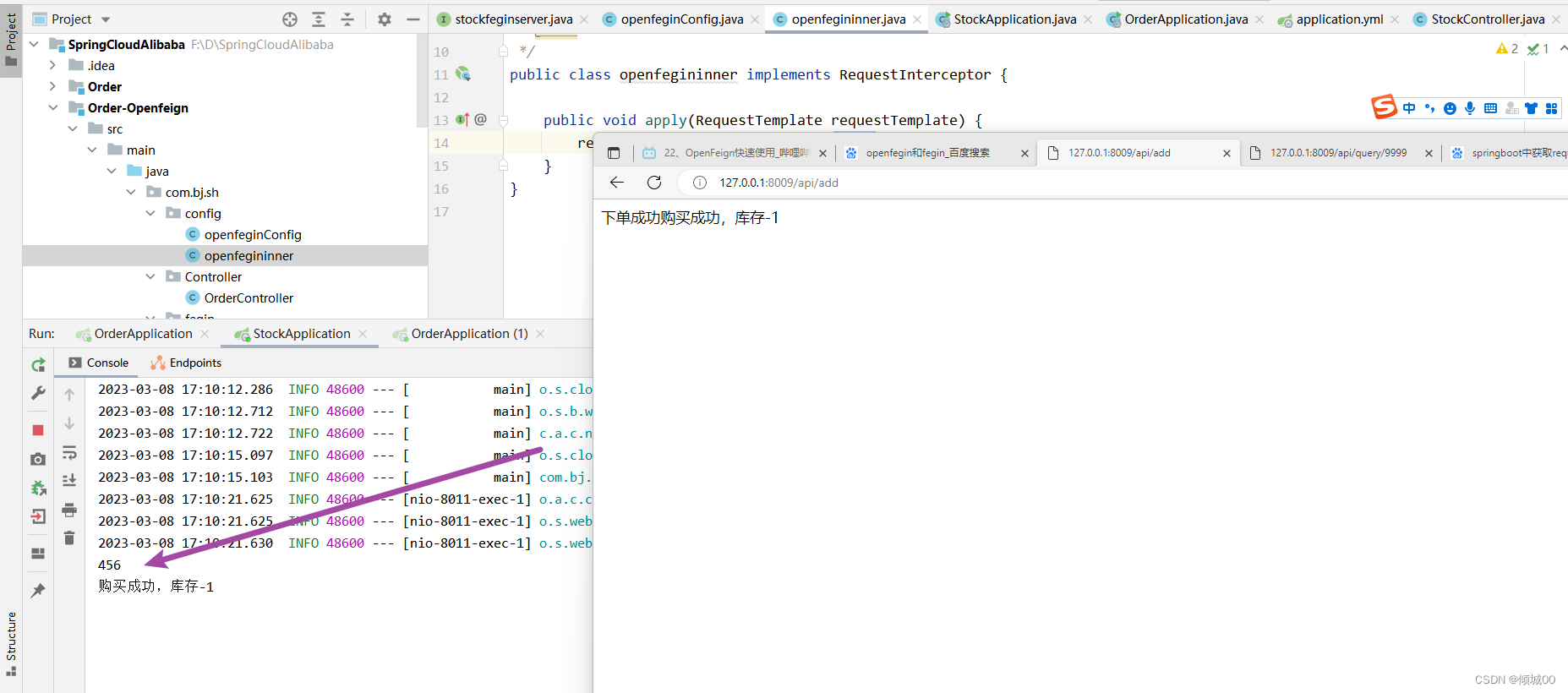
13.7 nacos的config配置
- 提起微服务,离不了配置文件(参看springcloud的config组件)
- nacos提供用于存储配置其他元数据的存储,为分布式系统中的外部化配置提供服务器端和客户端的支持,使用springclood-alibaba nacos config可以再nacos server中集中管理springcloud的外部属性配置
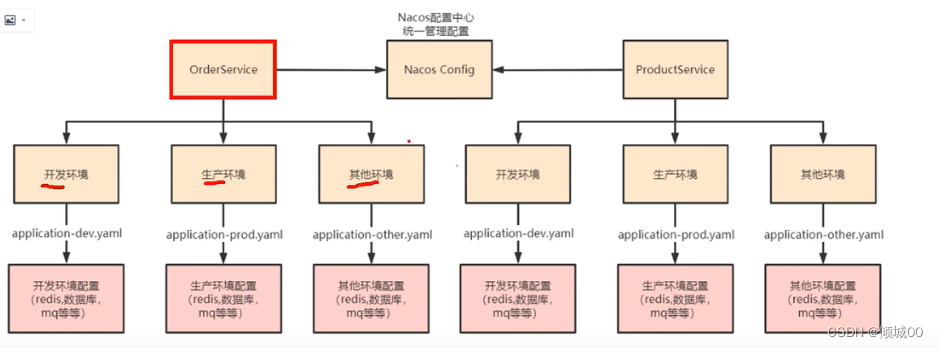
13.7.1 nacos-config的配置管理界面
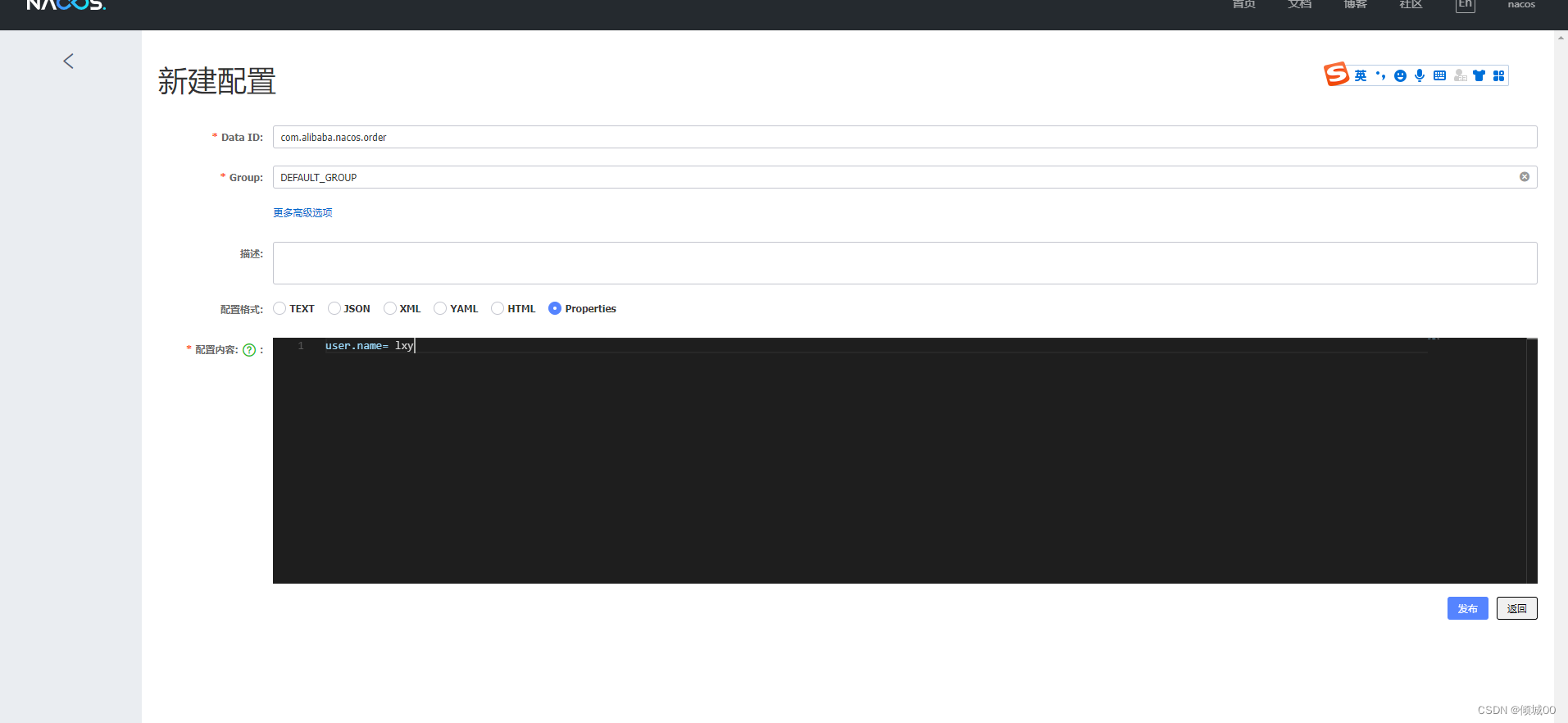

- 在数据库中是存在这里的
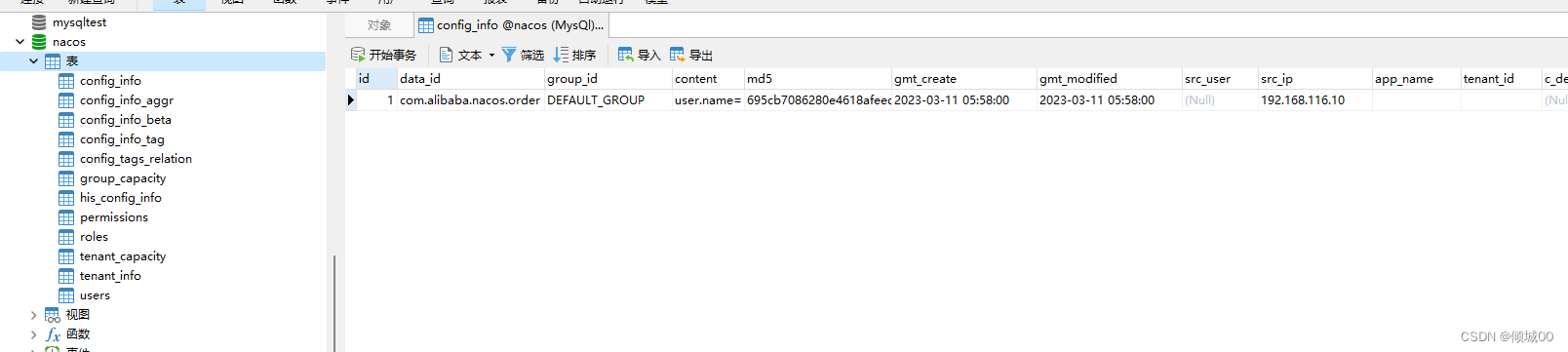
-修改完成之后,可以查看历史
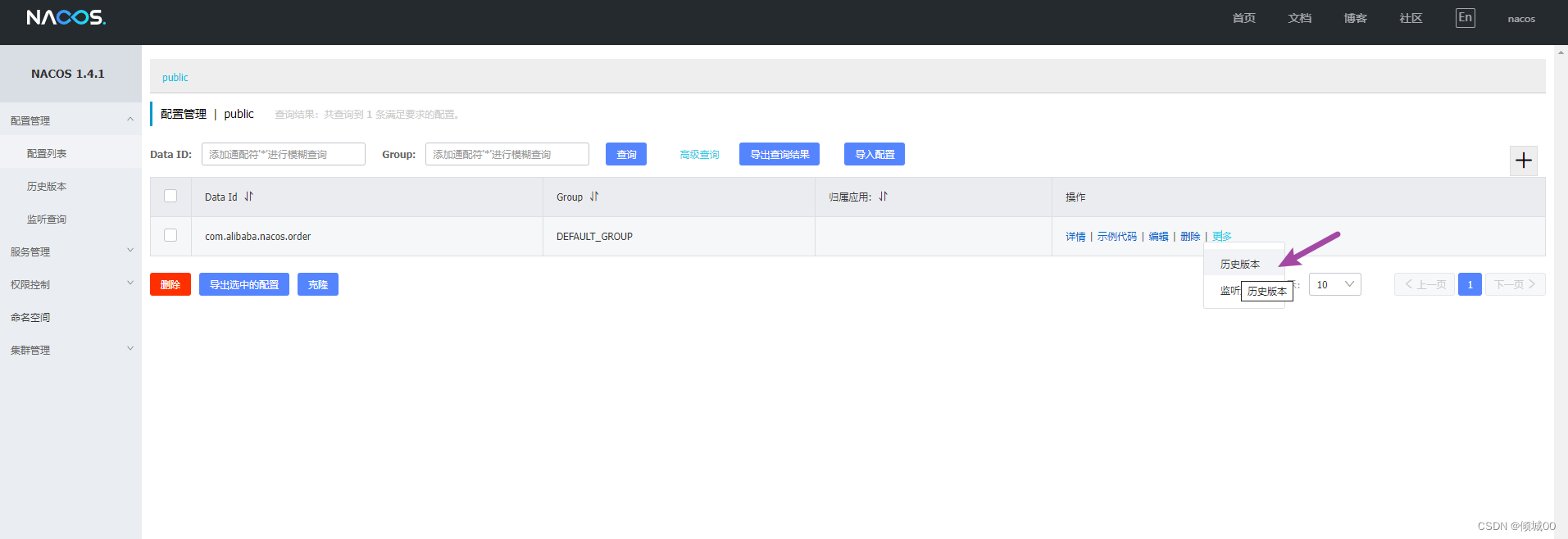
- 还可以对数据进行回滚操作
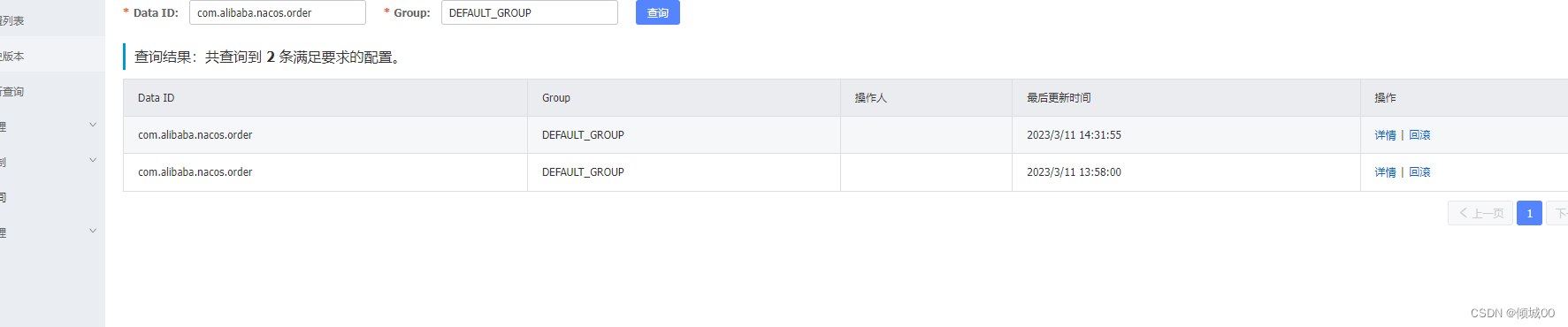
13.7.1 nacos-config的权限控制
- 权限控制需要修改配置文件
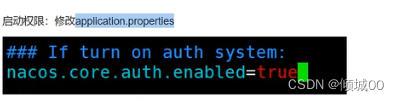
- 新建一个dev环境
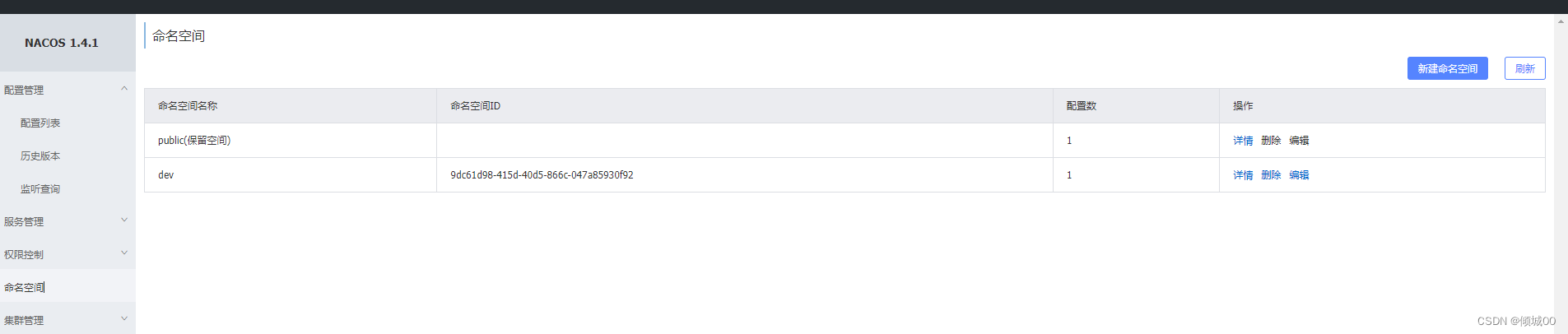
- 创建一个用户

- 绑定该账号的角色
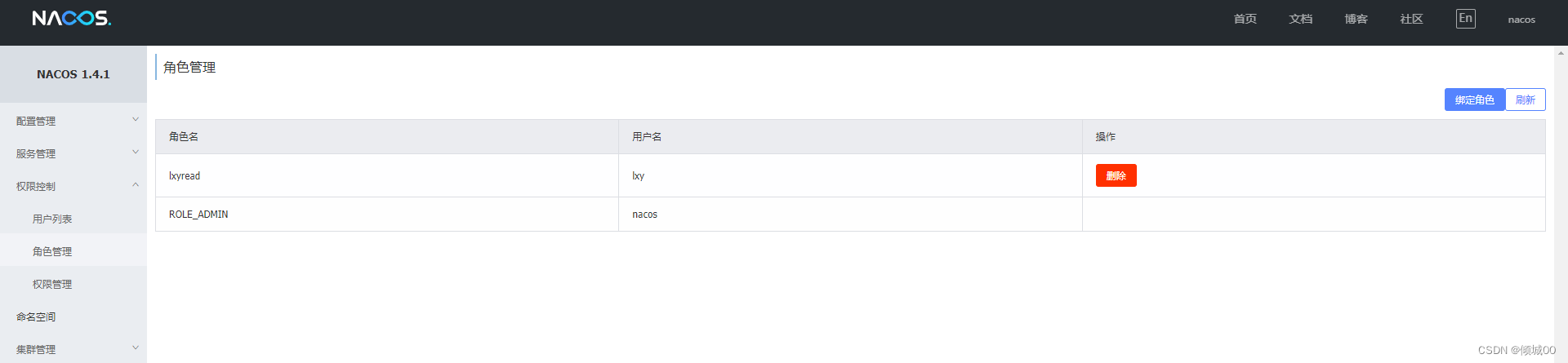
- 然后给这个角色设置称为dev只读的权限
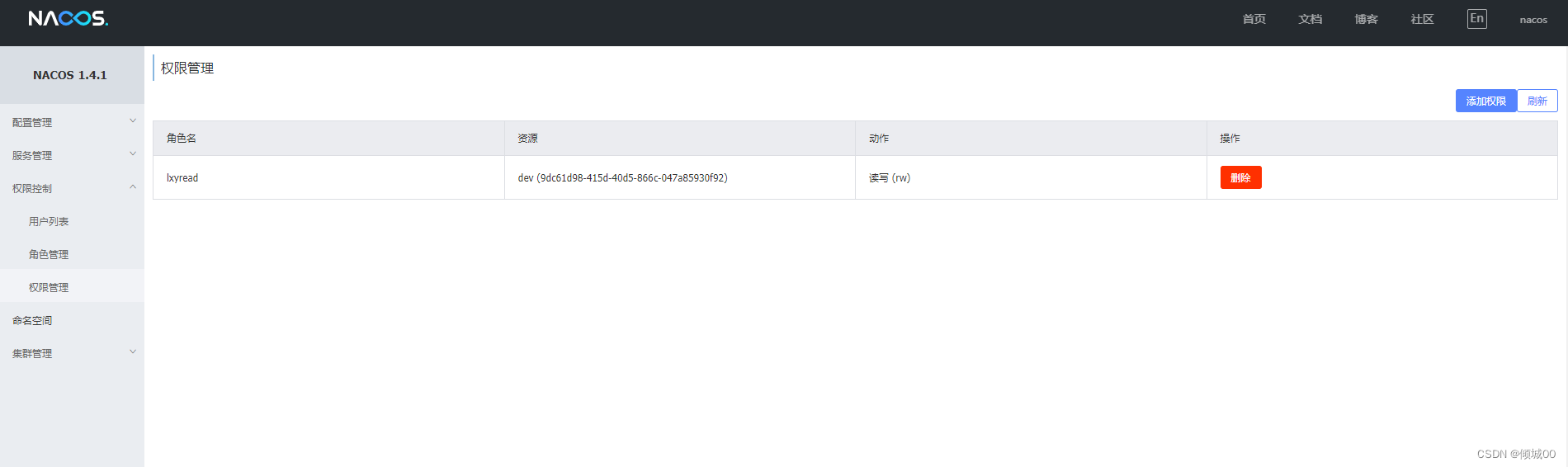
- 这个账号是dev读写的,所以看不了public的
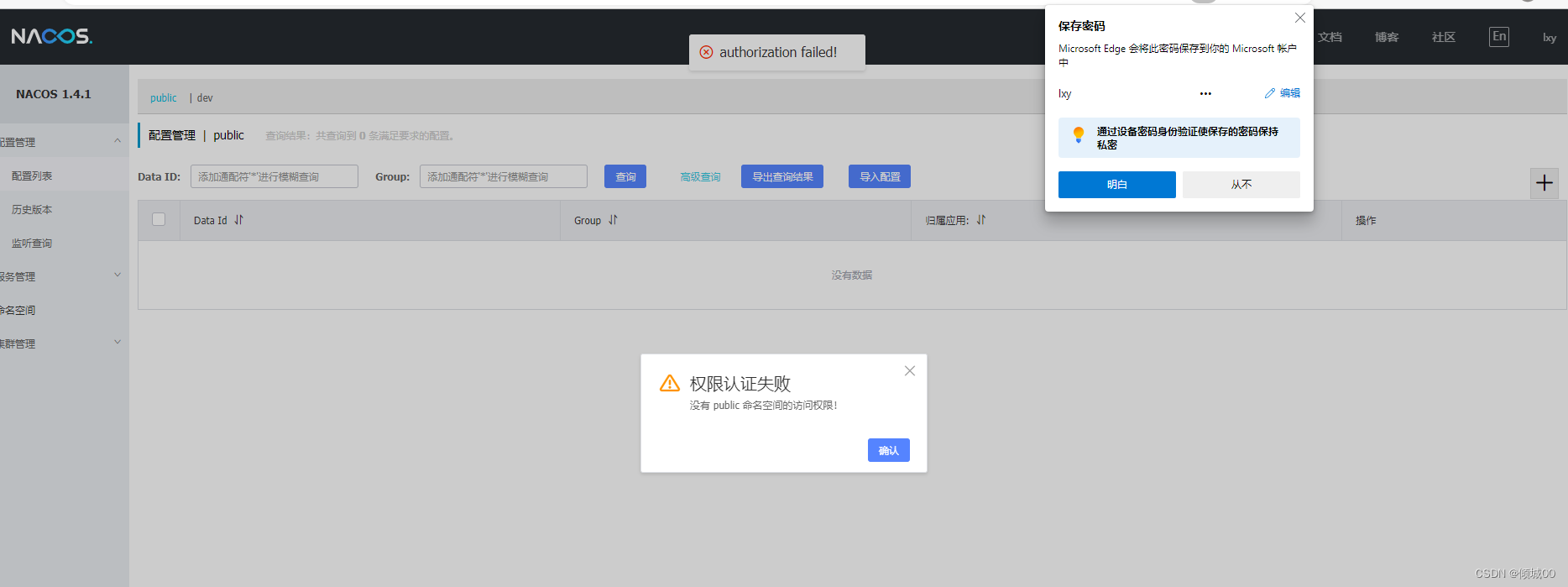
13.7.2 nacos-config读取配置
- 首先是要添加pom的
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>SpringCloudAlibaba</artifactId>
<groupId>com.bj.sh</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>nacos-config</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- nacos-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
</dependencies>
</project>
- 新建一个项目 nacos-config
package com.bd.sh.contorller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
/**
* @author LXY
* @desc
* @time 2023--03--11--14:47
*/
@RestController
@RequestMapping("/api")
public class UserContorller {
@Value("${user.name}")
String name;
@GetMapping("/queryvalues")
public String queryvalues(){
return name;
}
}
package com.bd.sh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author LXY
* @desc
* @time 2023--03--11--14:47
*/
@SpringBootApplication
public class configserver {
public static void main(String[] args) {
SpringApplication.run(configserver.class,args);
}
}
- application.yml文件
server:
port: 8050
- nacos-config要想使用在nacos中配置的文件,需要依赖于bootstrap.yml文件
bootstrap.yml
spring:
application:
name: com.alibaba.nacos.order
cloud:
nacos:
server-addr: 192.168.116.10:8848
username: nacos
password: nacos
# config:
# namespace: public
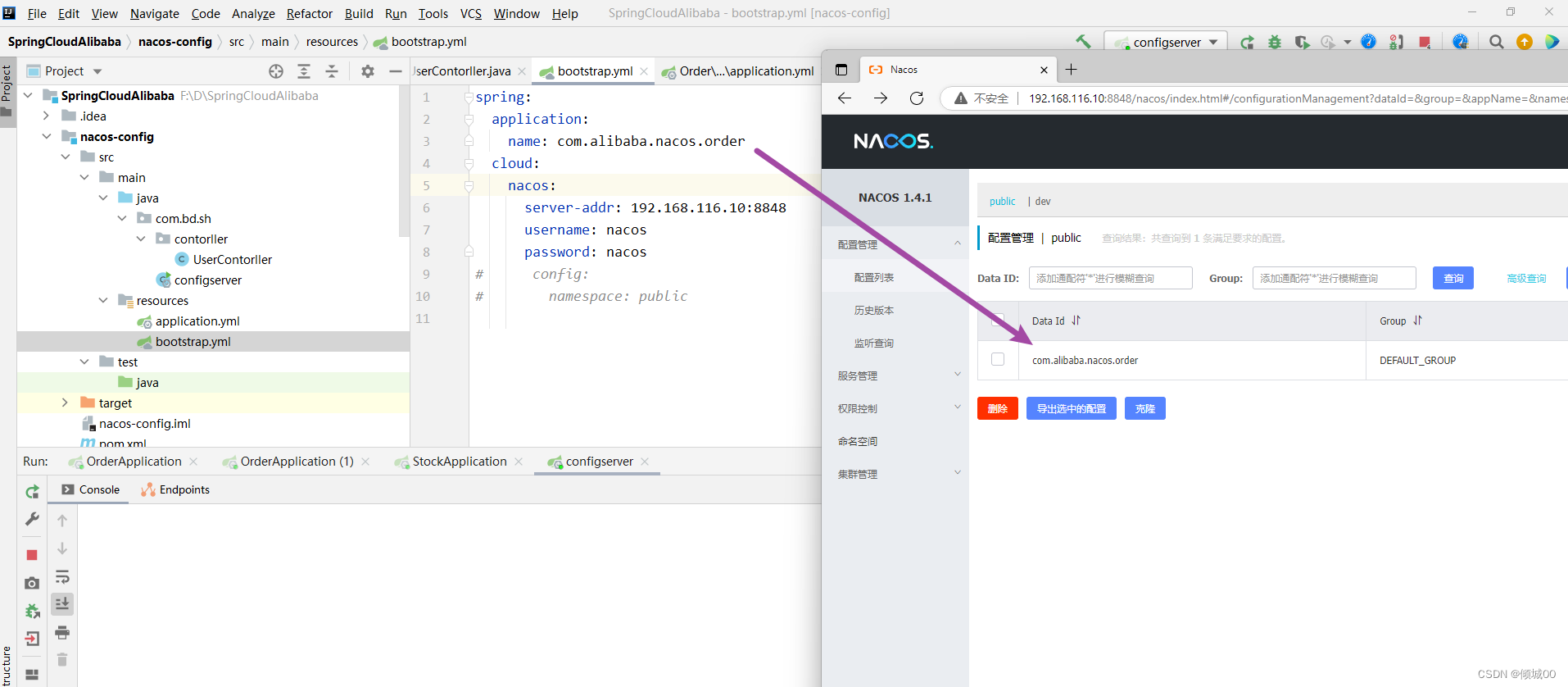
- 浏览器访问,可以拿到之前配置的值
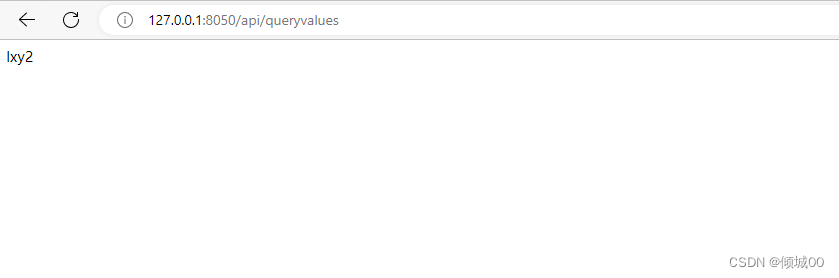
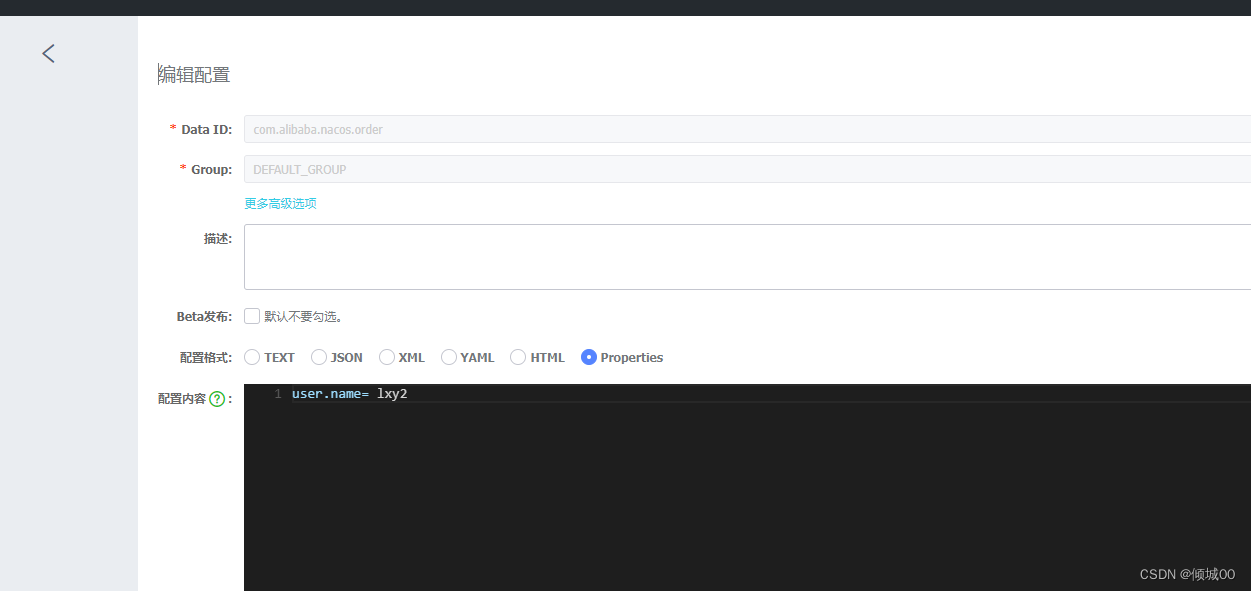
- 因为使用的value注解,然后需要加上这个注解,不然不回动态的刷新
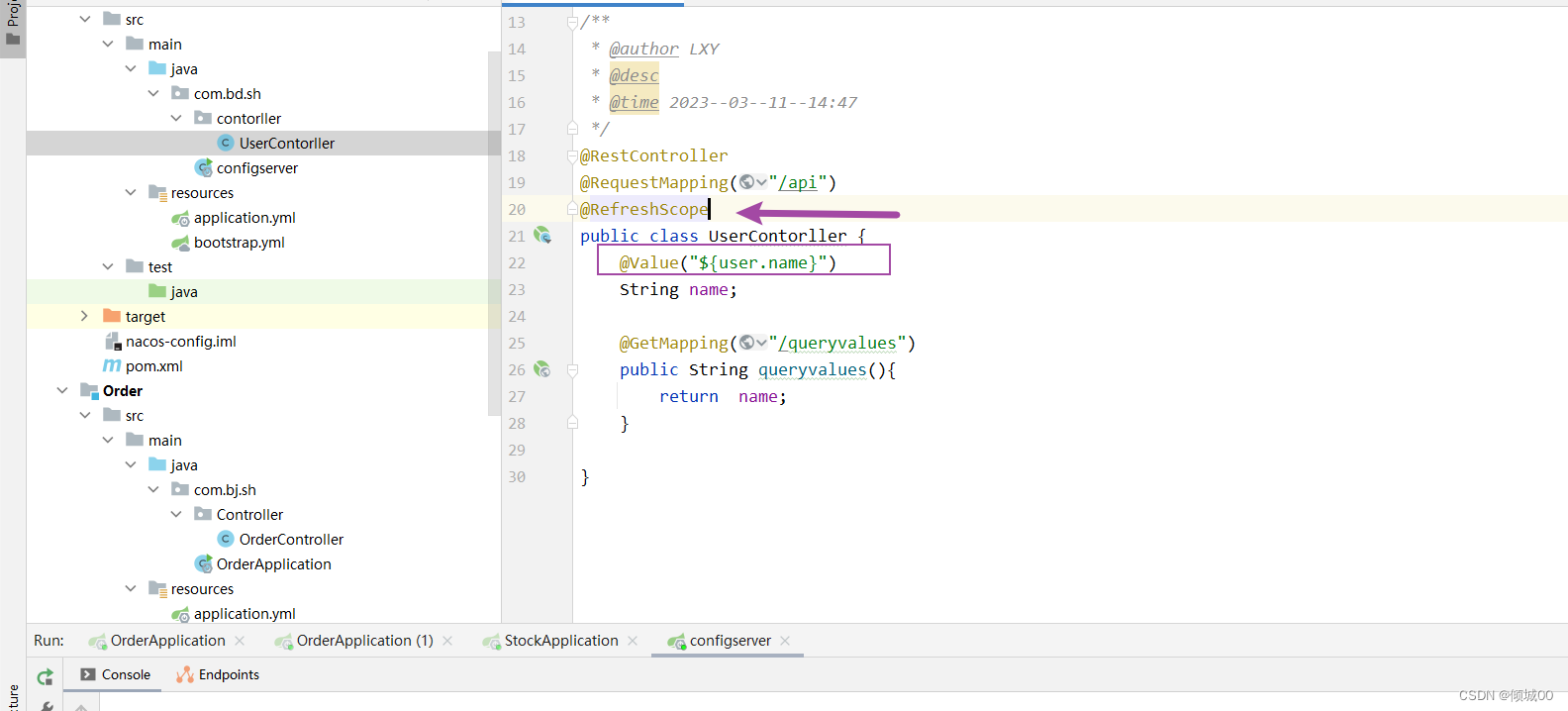
- 修改完成之后在刷新就可以动态的获取到信息了(不用重启)
- 每次修改之后会生成一个新的md5,拿这个md5去作比较,不同的话就重新加载
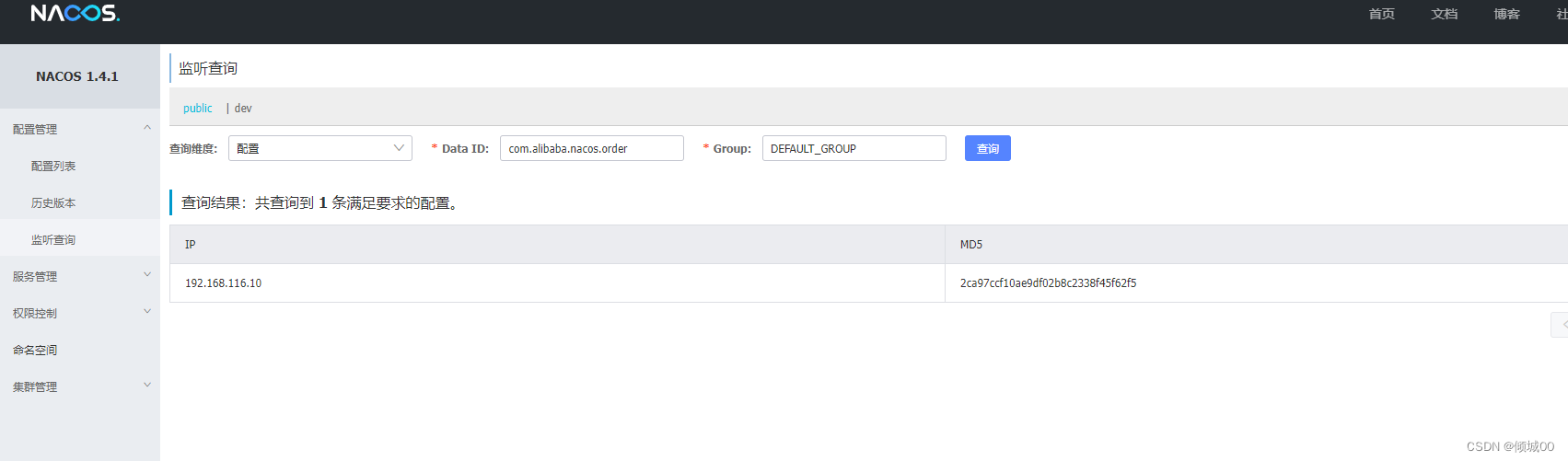
13.7.2 nacos-config的其他配置
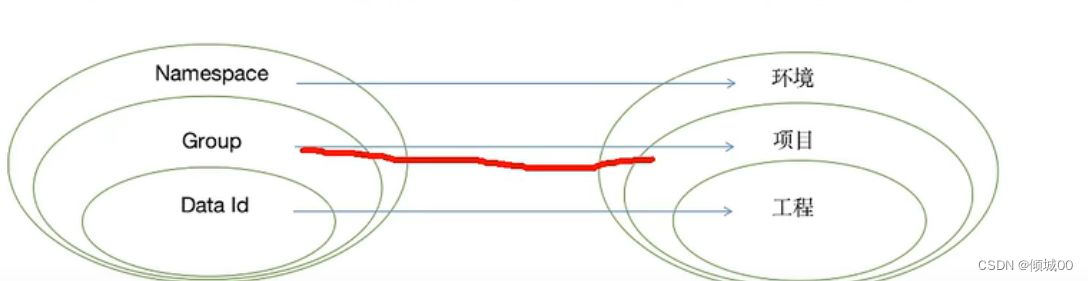
-
不设置的话默认是Properties的
-
设置命名空间
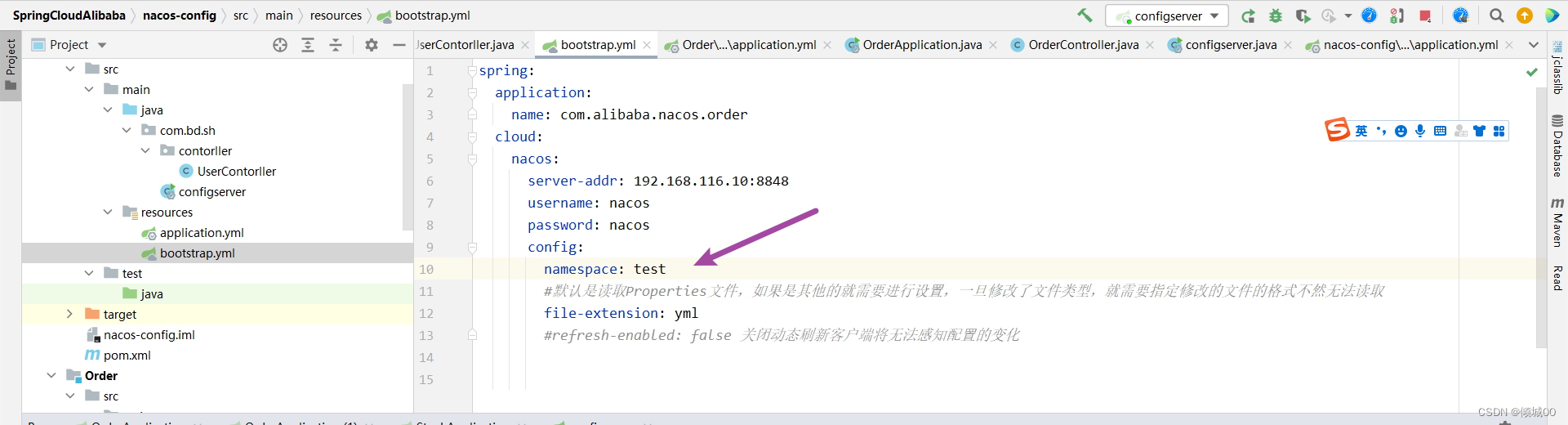
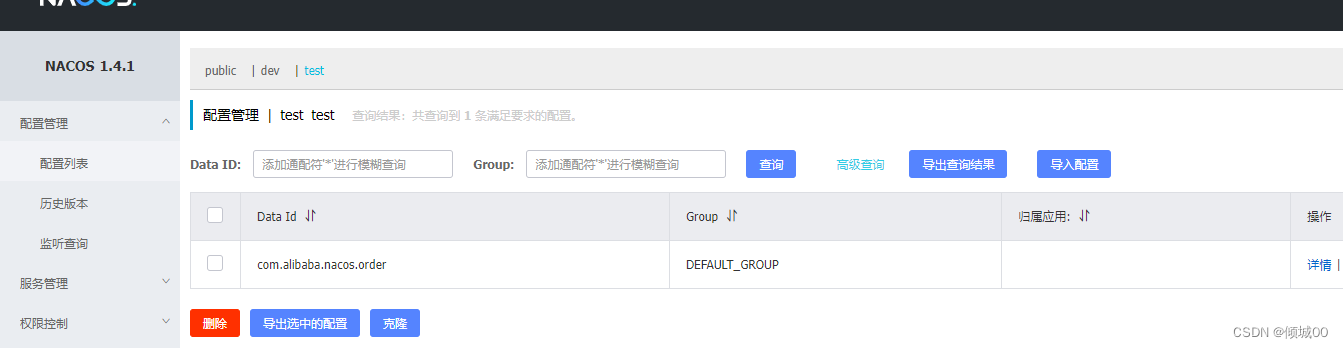
-
配置组
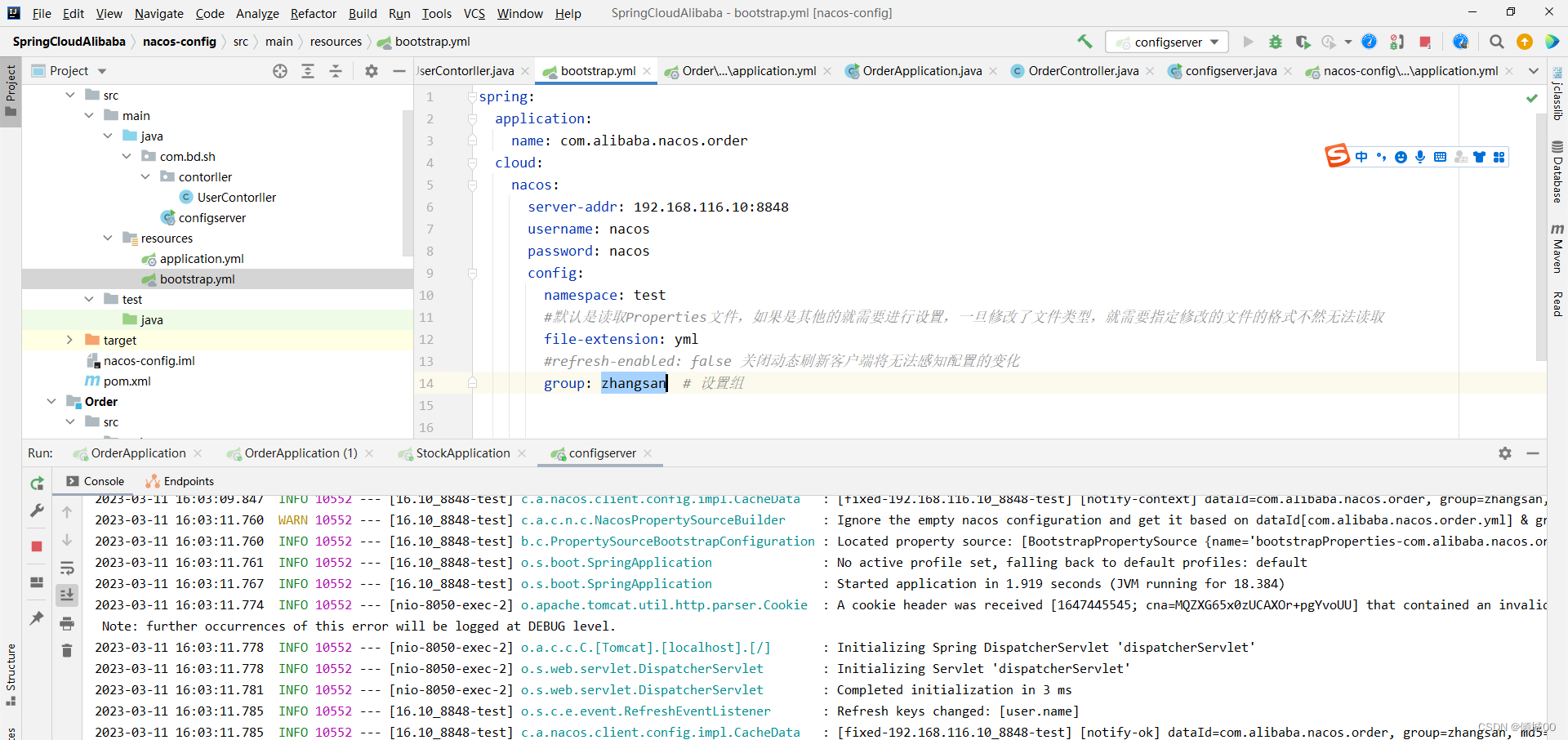
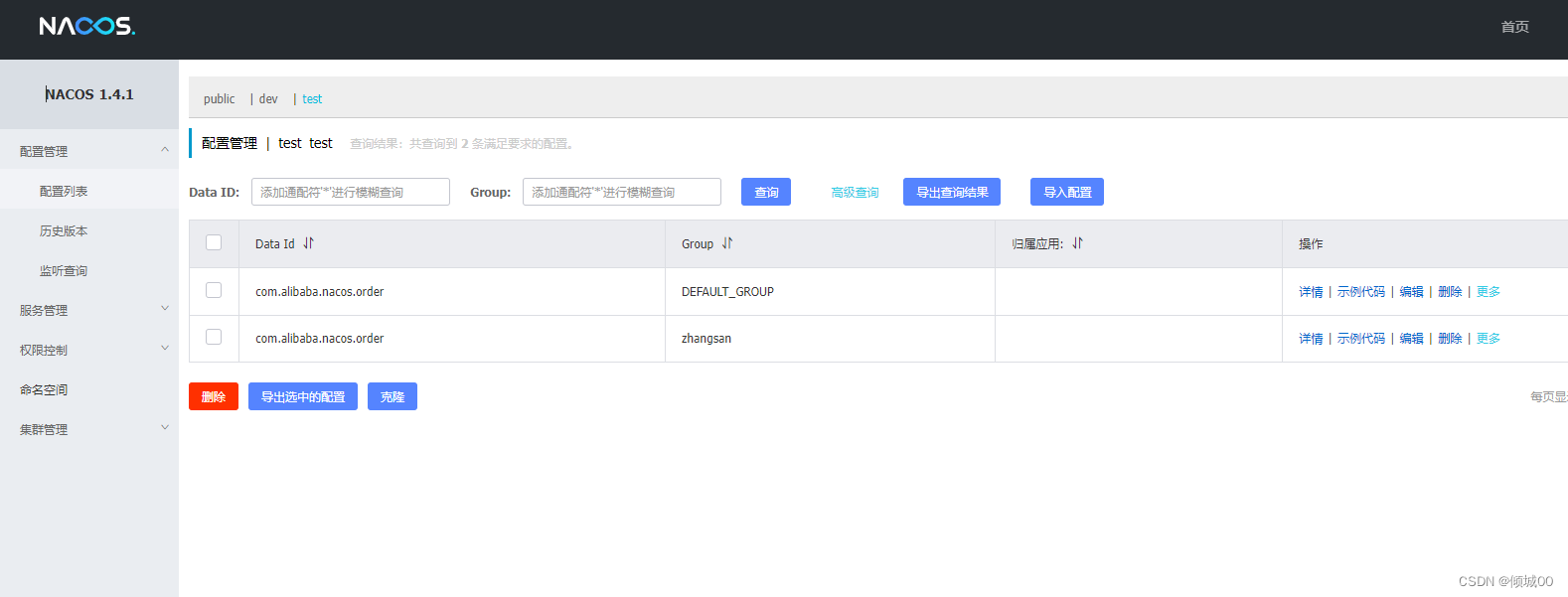
-
shared-configs
- 上面是载入了一个配置文件,如果我们想载入多个配置文件或者是引用公共的配置文件呢,那么就使用了shared-configs是一个list可以加载多个文件
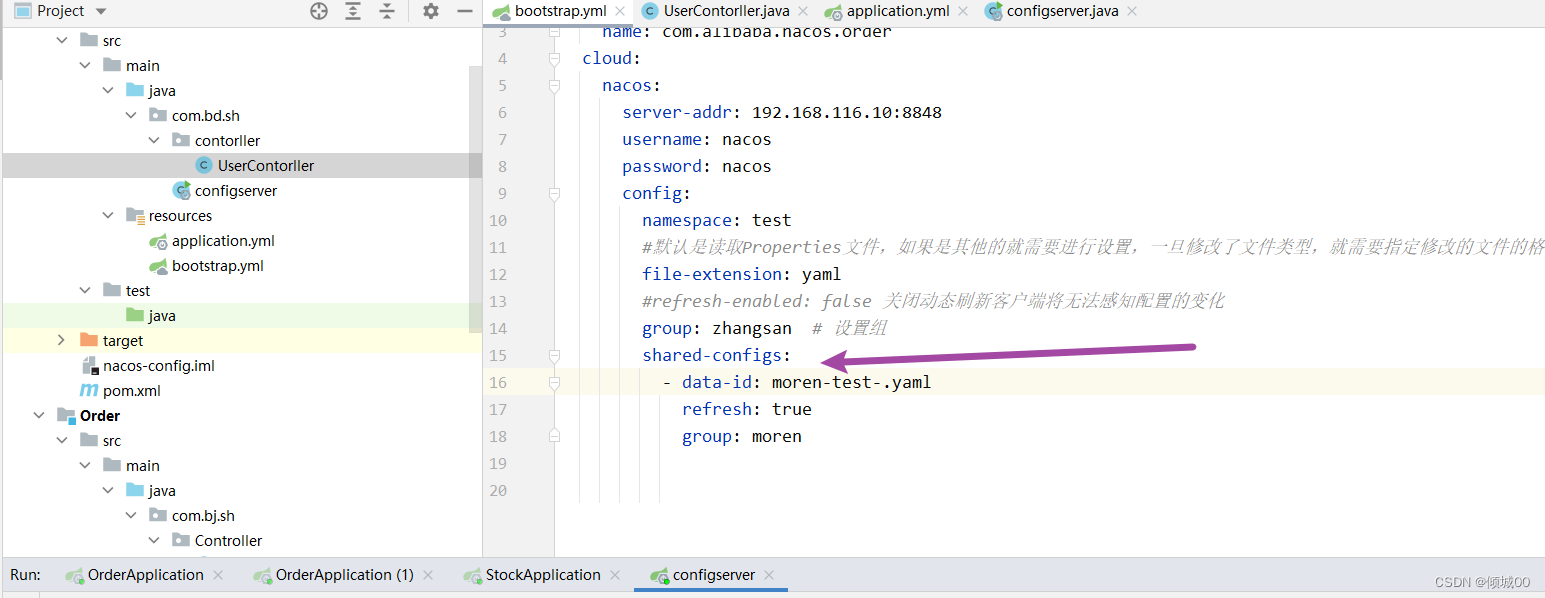
- extension-configs[0] 也是加载多个配置文件,是下标方式的和4的用法是一样的,用于加载公共配置文件
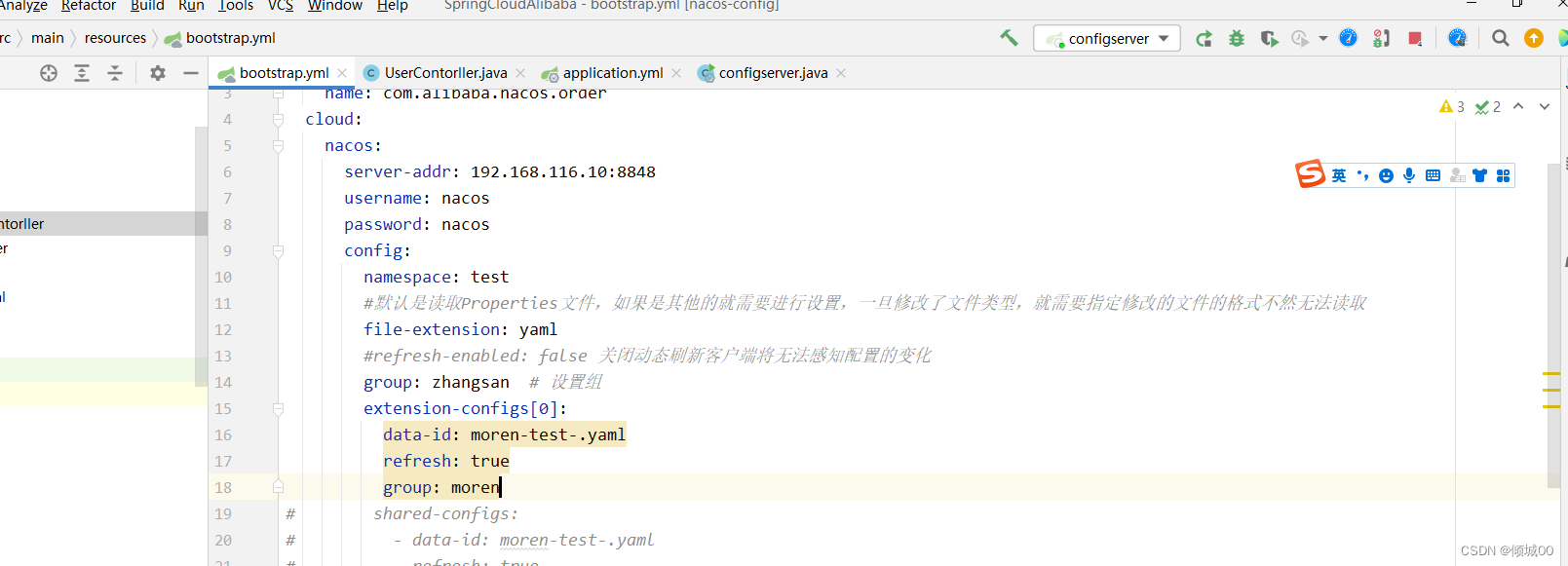
- 配置文件的优先级

13.8 sentinel (服务熔断)

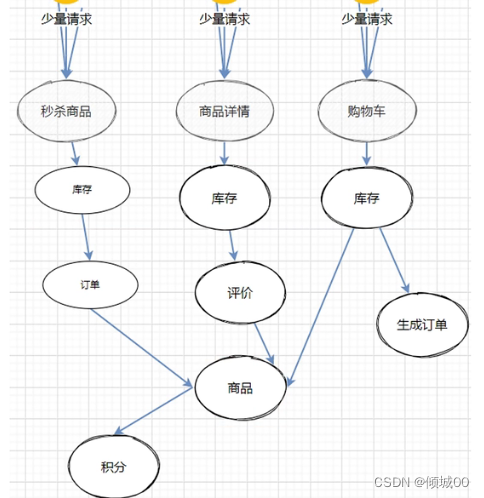
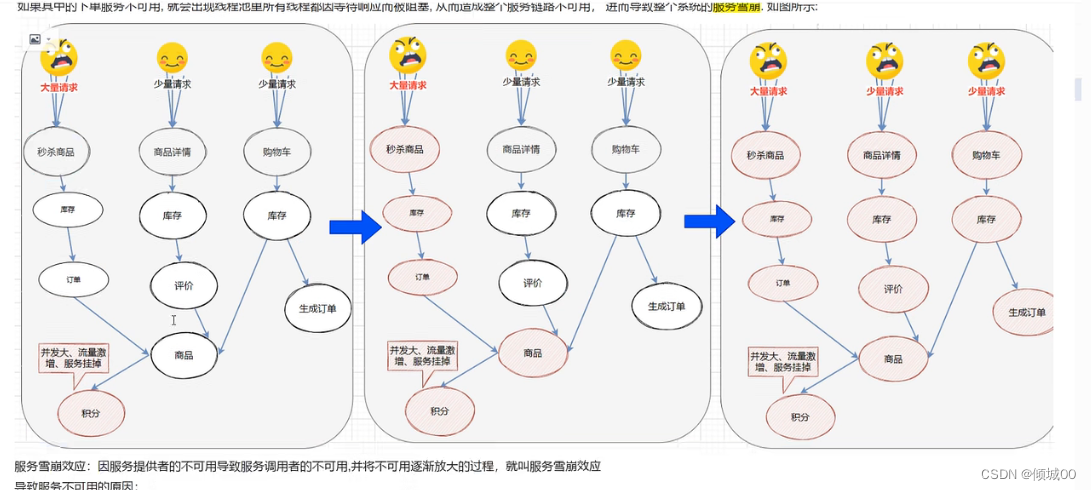

- sentinel 是alibaba开源的面向分布式的高可用防护组件
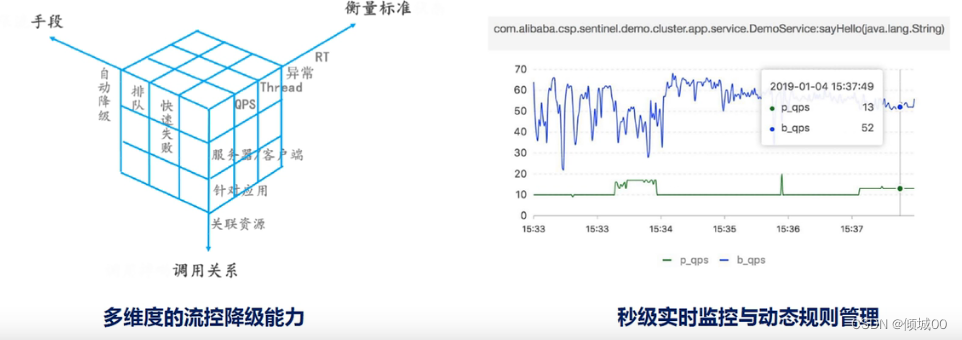
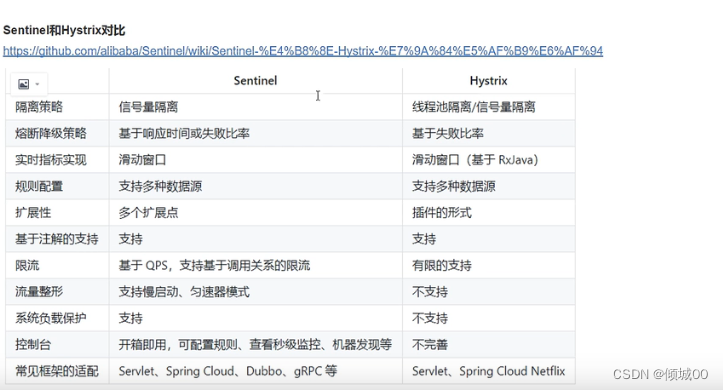
13.8.1 sentinel 流控规则的使用
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>SpringCloudAlibaba</artifactId>
<groupId>com.bj.sh</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>Sentinel_demon</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-annotation-aspectj</artifactId>
<version>1.8.0</version>
</dependency>
</dependencies>
</project>
server:
port: 8086
package com.rj.bd.connction;
import com.alibaba.csp.sentinel.Entry;
import com.alibaba.csp.sentinel.SphU;
import com.alibaba.csp.sentinel.Tracer;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
/**
* @author LXY
* @desc
* @time 2023--03--11--18:29
*/
@RestController
@RequestMapping("/api")
public class Userconnction {
private static final String RESOURCE_NAME="hello";
private static final String USER_RESOURCE_NAME="user";
private static final String DEGRADE_RESOURCE_NAME="degrand";
@GetMapping("/hello")
public String add(){
Entry entry=null;
try {
//定义资源名称
entry = SphU.entry(RESOURCE_NAME);
//收保护的业务逻辑
return "hello word";
}catch (BlockException e){
//资源访问阻止,被限流或者降级
//进行相对应的操作
return "被流控了";
}catch (Exception e){
//如果需要配置降级规则,则需通过这种方式记录
Tracer.traceEntry(e,entry);
}finally {
if (entry!=null)
{
System.out.println("entry is not null");
entry.exit();
}
}
return null;
}
//项目启动就加载
@PostConstruct
private void initFlowRule(){
System.out.println("initFlowRule start");
//创建一个规则的集合,里面可以添加多个规则
List<FlowRule>rules=new ArrayList<FlowRule>();
FlowRule rule=new FlowRule();
/**
* 为hello这个资源设置一个qbs的流控规则,
*/
rule.setResource(RESOURCE_NAME);
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
//设置了阈值,1秒钟超过1次访问就收保护
rule.setCount(1);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
}
- 上述代码是对hello就行一个流控,超过设定的阈值就触发保护
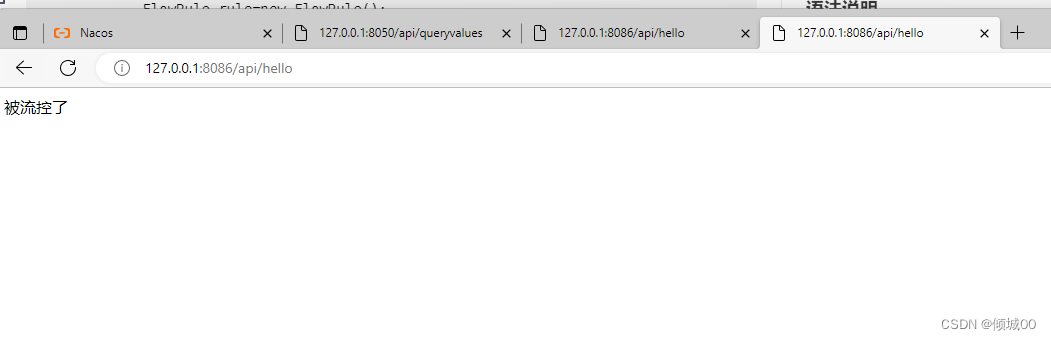
13.8.2 @ SentinelResource 的使用
- 和springcloud-Histy的注解使用方法相似,就不过多介绍了,有注释
package com.rj.bd.connction;
import com.alibaba.csp.sentinel.Entry;
import com.alibaba.csp.sentinel.SphU;
import com.alibaba.csp.sentinel.Tracer;
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
/**
* @author LXY
* @desc
* @time 2023--03--11--18:29
*/
@RestController
@RequestMapping("/api")
public class Userconnction {
private static final String RESOURCE_NAME="hello";
private static final String USER_RESOURCE_NAME="user";
private static final String DEGRADE_RESOURCE_NAME="degrand";
/**
* @SentinelResource
* value 定义资源
* blockHandler 设置控流降级的处理方法(默认需要声明同一个类)
* 如果没在同一个类中需要添加属性blockHandlerClass = xxx(所在的类).class ,这个类的方法需要是静态的
* fallback 是发生异常的时候执行该方法
* @return
*/
@GetMapping("/user")
@SentinelResource(value = USER_RESOURCE_NAME ,fallback = "getblockHandlerforgetUser",blockHandler = "blockHandlerforgetUser")
public Object getuser(){
int i=1/0;
return "new object";
}
/**
* 1.一定是public 的
* 2. 返回值一定要和原方法保持一致,包含源方法的参数
* 3. 可以在参数最后添加BlockException可以区分是什么规则的处理方法
* @param e
* @return
*/
public Object blockHandlerforgetUser(BlockException e){
e.printStackTrace();
return "is error";
}
public Object getblockHandlerforgetUser(Throwable e){
e.printStackTrace();
return "发生异常";
}
@GetMapping("/hello")
public String add(){
Entry entry=null;
try {
//定义资源名称
entry = SphU.entry(RESOURCE_NAME);
//收保护的业务逻辑
return "hello word";
}catch (BlockException e){
//资源访问阻止,被限流或者降级
//进行相对应的操作
return "被流控了";
}catch (Exception e){
//如果需要配置降级规则,则需通过这种方式记录
Tracer.traceEntry(e,entry);
}finally {
if (entry!=null)
{
System.out.println("entry is not null");
entry.exit();
}
}
return null;
}
//项目启动就加载
@PostConstruct
private void initFlowRule(){
System.out.println("initFlowRule start");
//创建一个规则的集合,里面可以添加多个规则
List<FlowRule>rules=new ArrayList<FlowRule>();
FlowRule rule=new FlowRule();
/**
* 为hello这个资源设置一个qbs的流控规则,
*/
rule.setResource(USER_RESOURCE_NAME);
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
//设置了阈值,1秒钟超过1次访问就收保护
rule.setCount(1);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
}
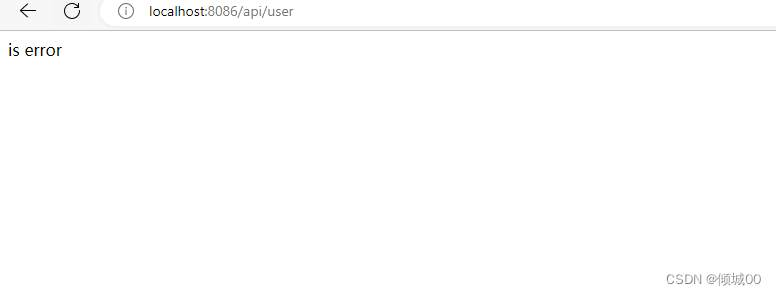

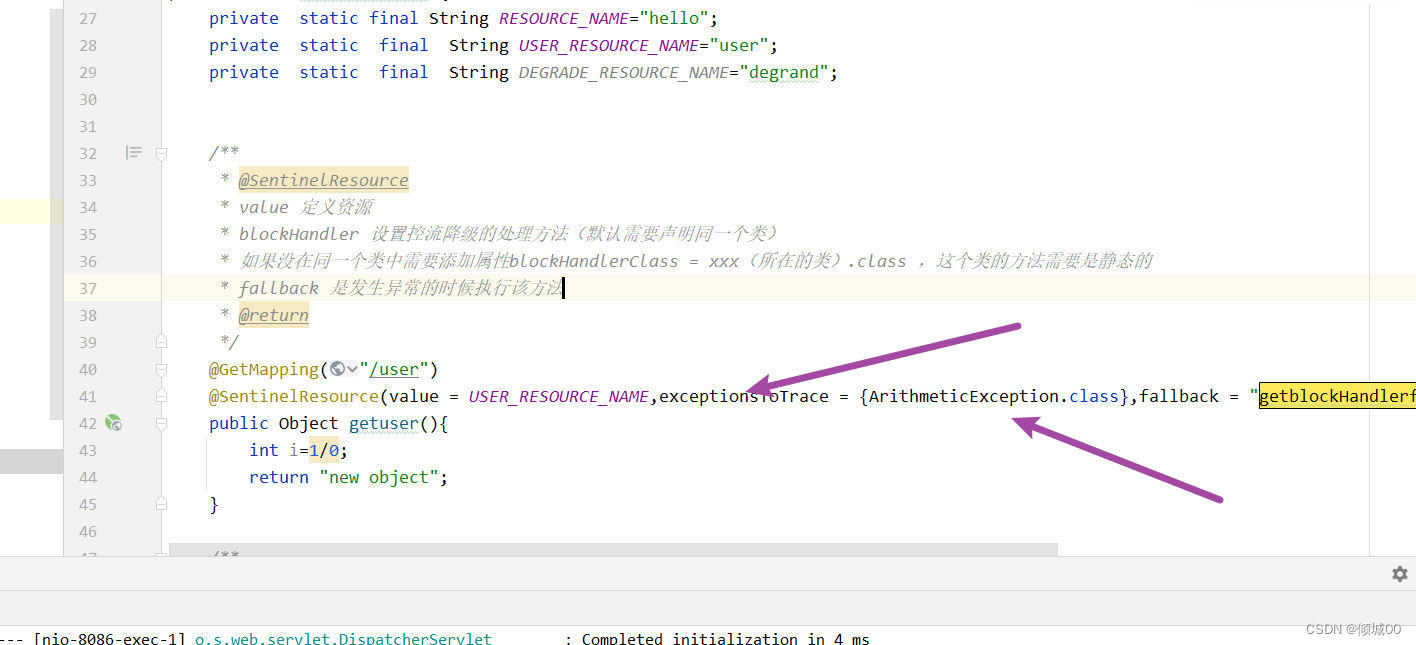
- 还有一个属性,是发生了异常不去处理,发生了这种异常不进行处理
13.8.3 控制台的方式进行部署
jar包下载
- 下载1.8.0
java -jar sentinel-dashboard-1.8.0.jar

- 账号密码是一样的
<!-- 整合控制台-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-transport-simple-http</artifactId>
</dependency>
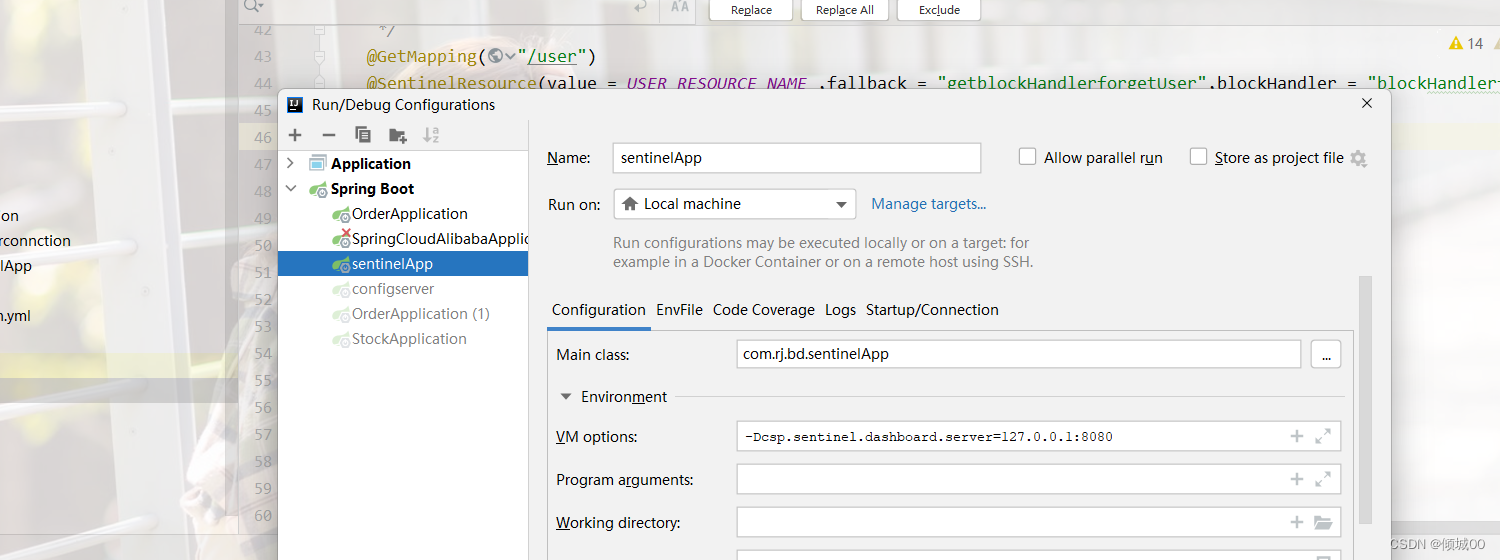
- 启动的时候添加JVM参数调试
-Dcsp.sentinel.dashboard.server=127.0.0.1:8080
随意访问一个接口就会显示了
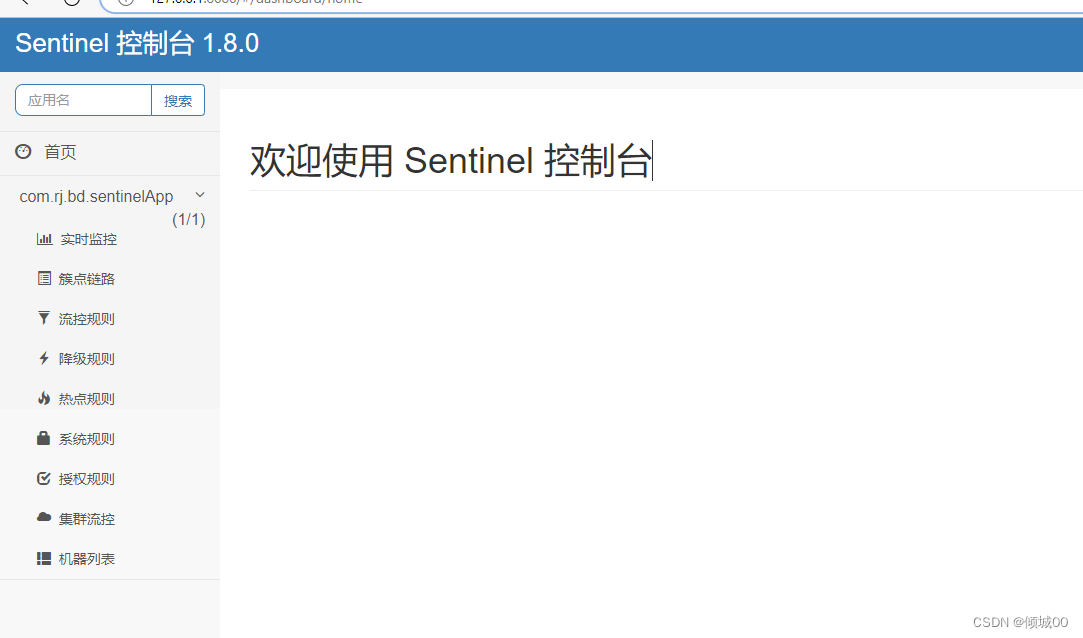
- 刚打开什么流控规则和代码规则都是之前在代码中设置的
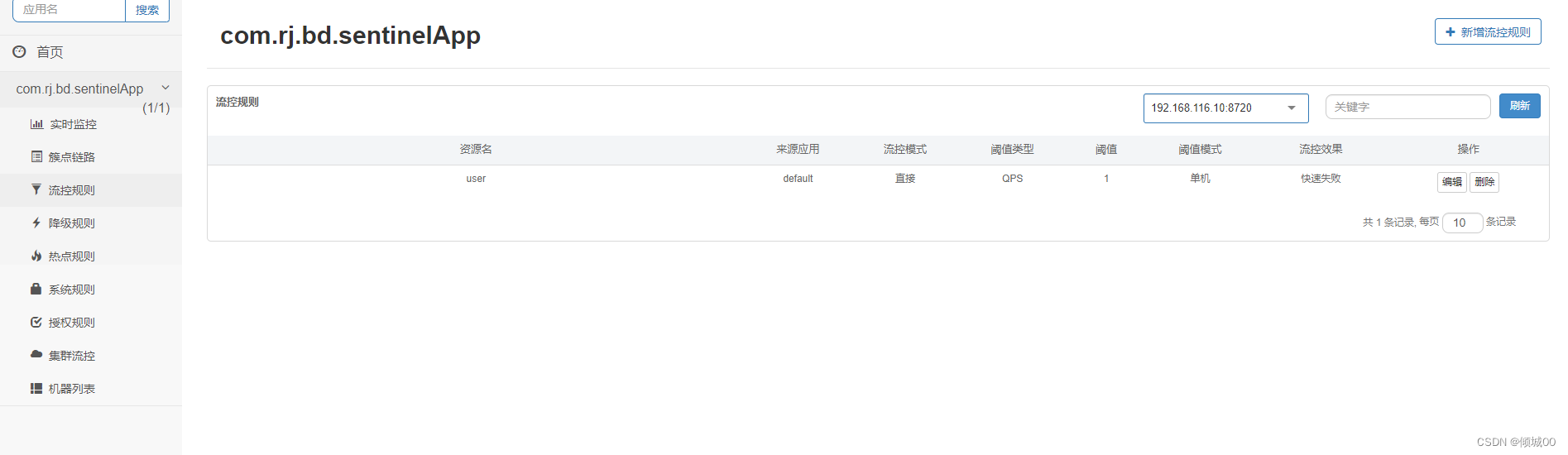
13.8.4 整合Springcloud-alibaba
- 将之前的order代码复制一份
<!-- Sentinel降级规则-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
</dependencies>
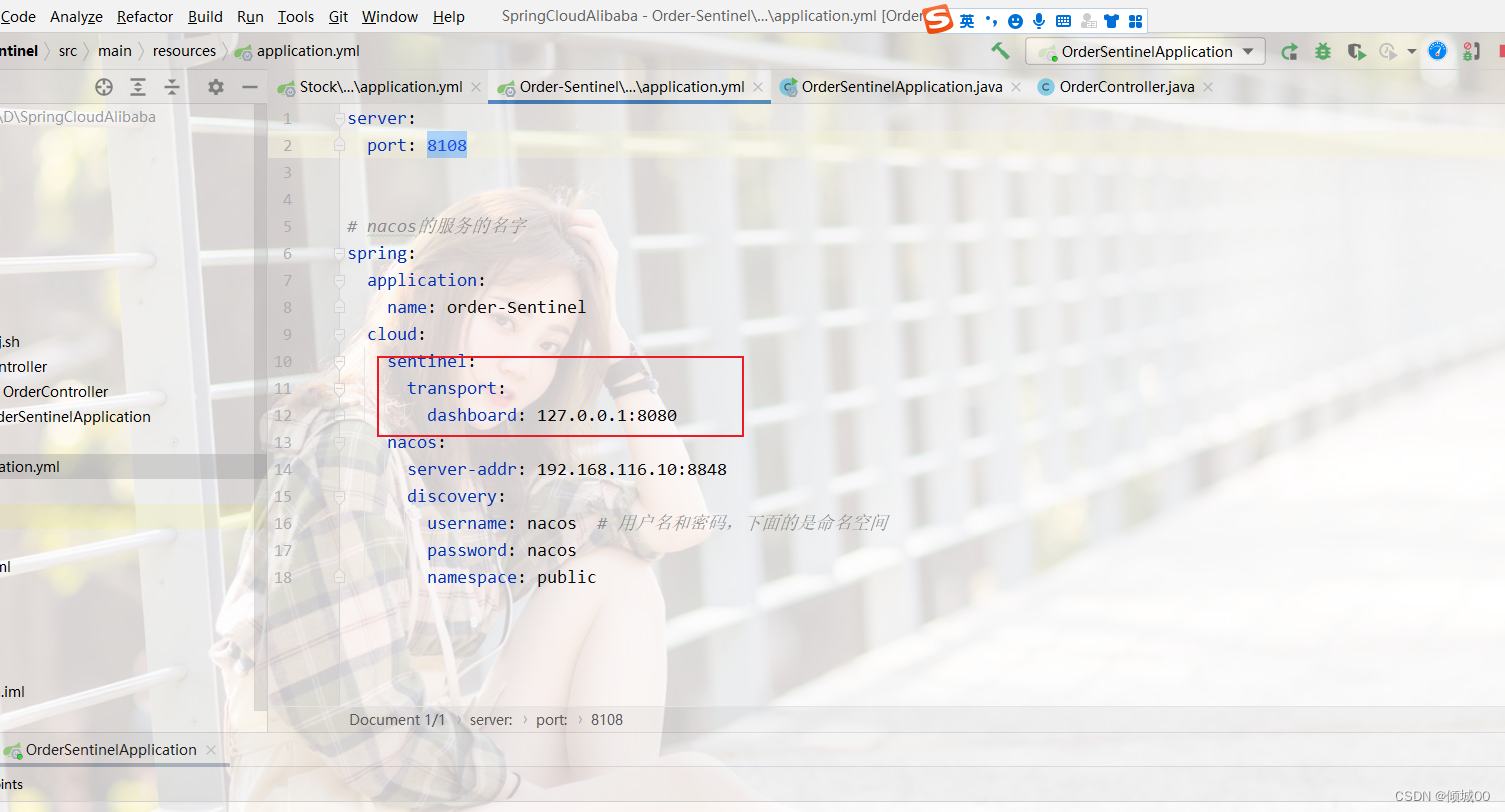
server:
port: 8108
# nacos的服务的名字
spring:
application:
name: order-Sentinel
cloud:
sentinel:
transport:
dashboard: 127.0.0.1:8080
nacos:
server-addr: 192.168.116.10:8848
discovery:
username: nacos # 用户名和密码,下面的是命名空间
password: nacos
namespace: public
- 这样就可以启动了,访问一下add接口。这样就可以设置规则了
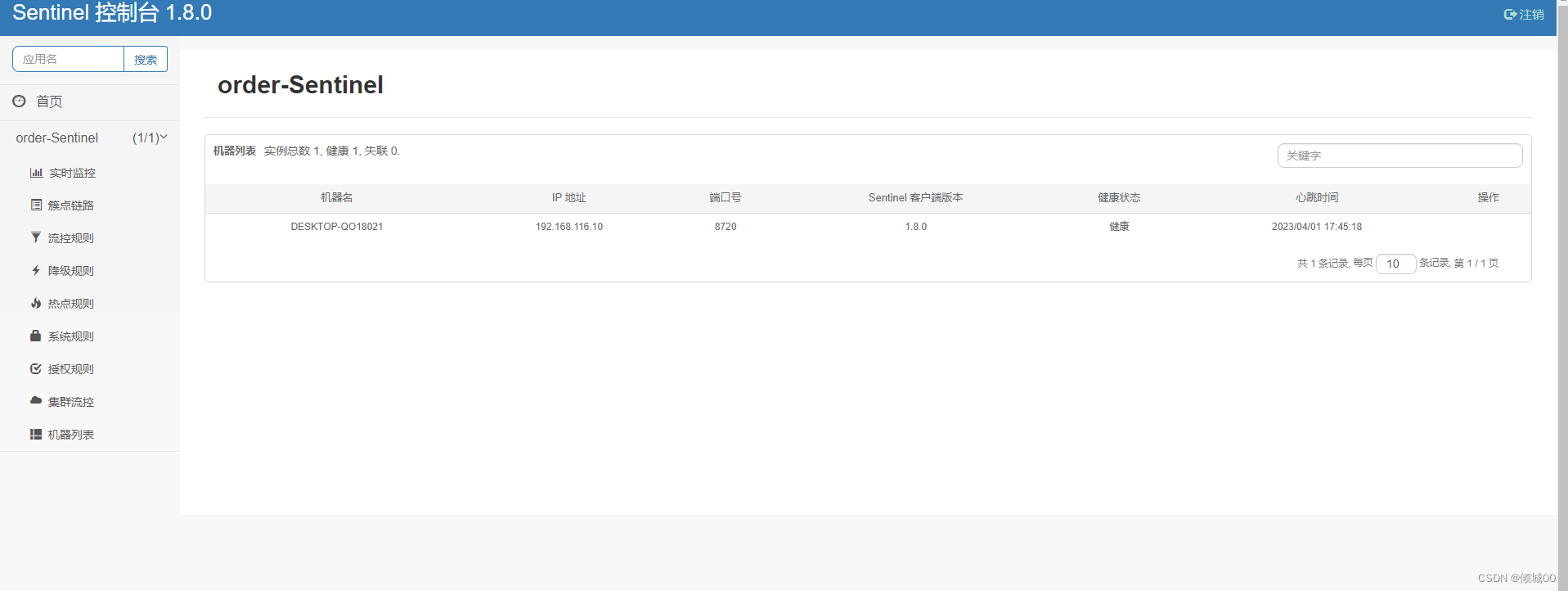
13.8.4 Qps- 服务熔断
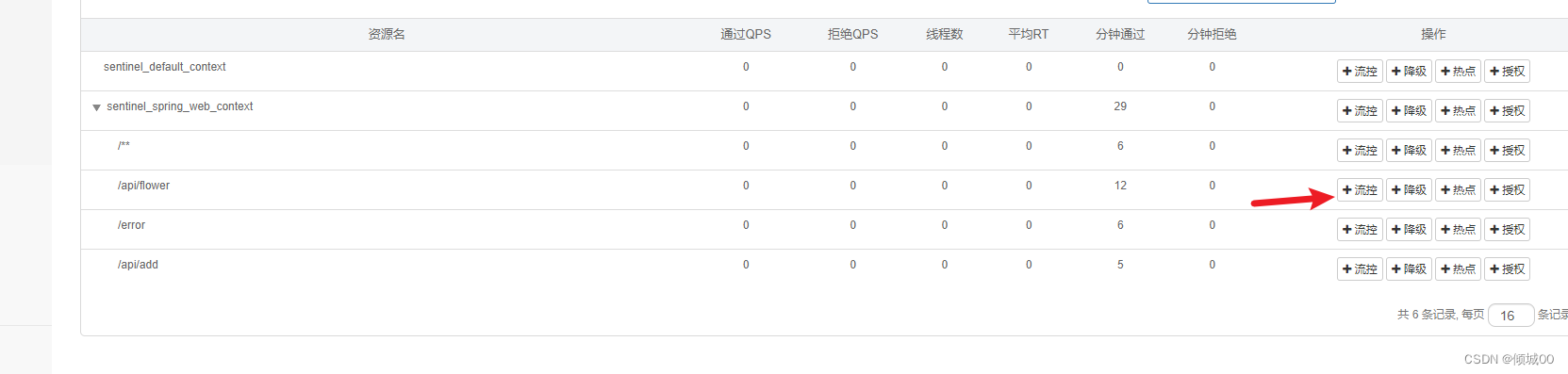

- Qbs:每秒请求数:就是服务器在一秒内处理了多少个请求
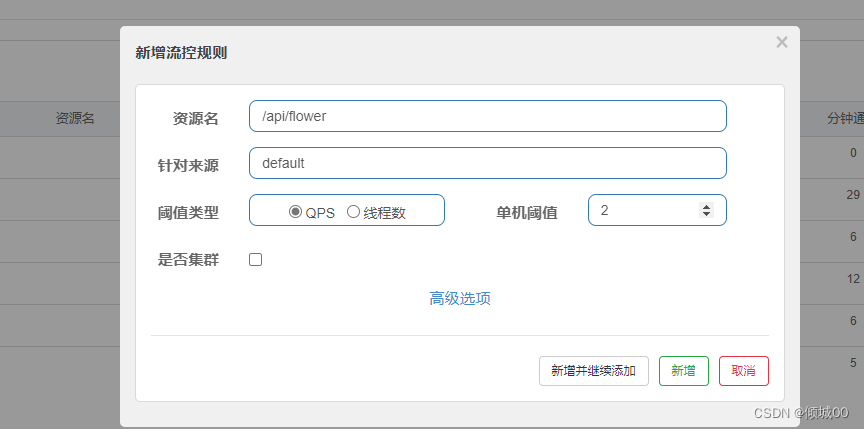

- 上面的提示是默认的提示,接下来使用自定义的

- 使用下面这个进行流控才会让我们的自定义注解生效
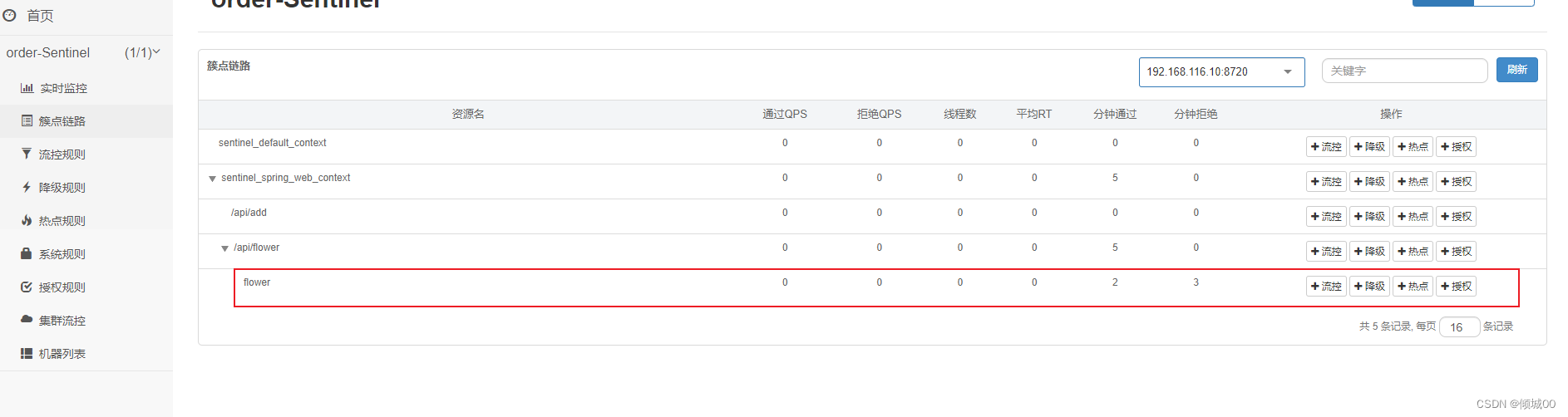
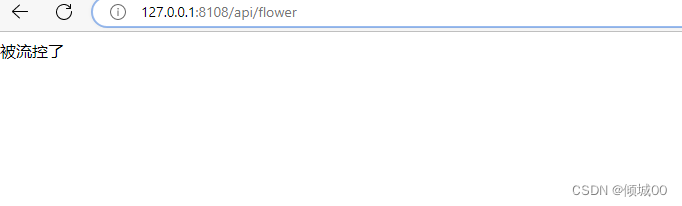
13.8.4 线程流控

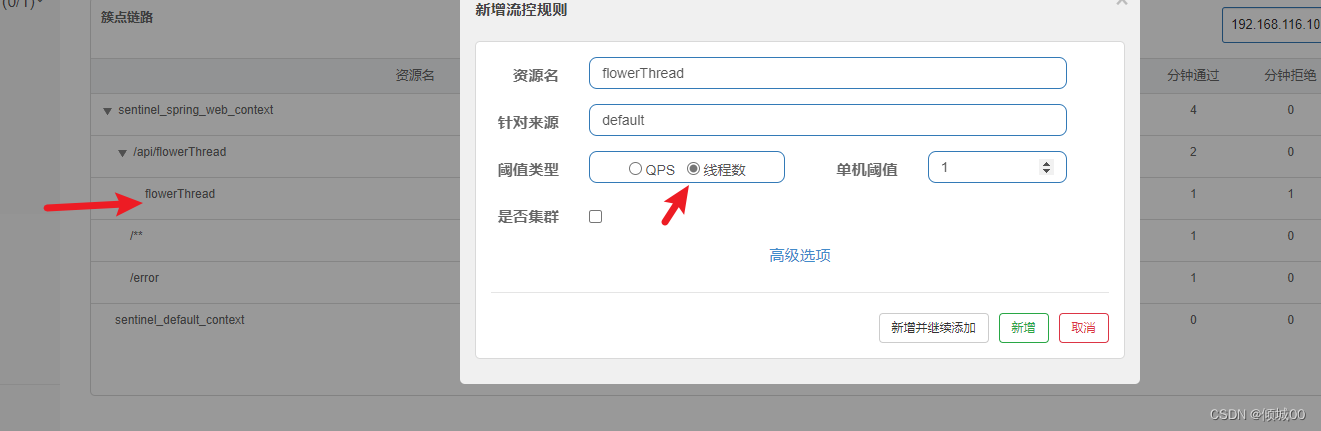
- 线程流控设置的是一个线程的意思是某一段时间内只能有一个线程在访问,两个浏览器访问让接口睡眠5s就可以看出,设置的是1,意思就是只能有一个线程在运行,多了就会被流控
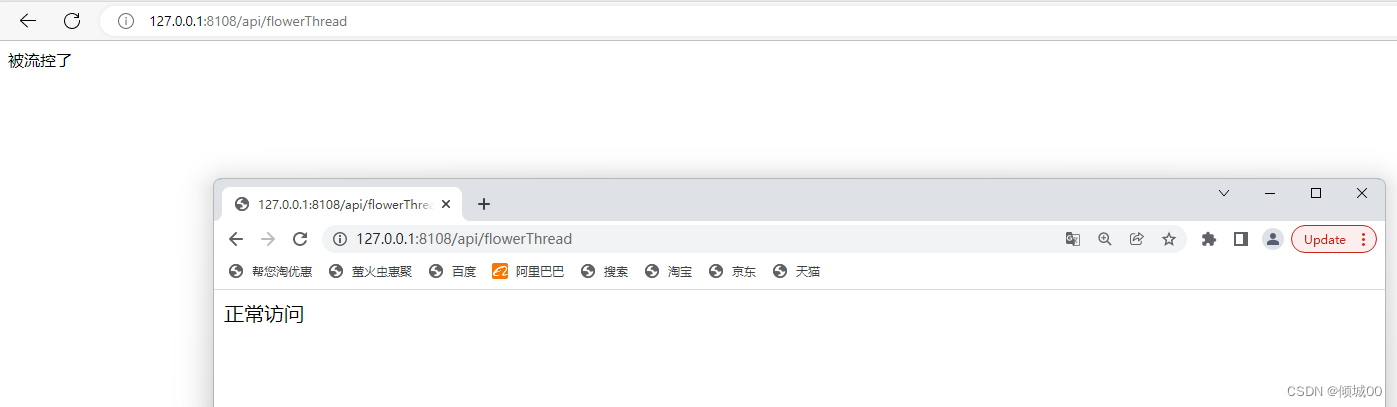
13.8.4 BlockException的统一返回数据
package com.bj.sh.excetion;
/**
* @author LXY
* @desc
* @time 2023--04--01--18:27
*/
public class Result <T>{
private Integer code;
private String message;
private T data;
public static Result getresule(Integer code ,String message){
return new Result(code,message);
}
public Result(Integer code, String message, T data) {
this.code = code;
this.message = message;
this.data = data;
}
public Result(Integer code, String message) {
this.code = code;
this.message = message;
}
public Integer getCode() {
return code;
}
public void setCode(Integer code) {
this.code = code;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}
package com.bj.sh.excetion;
import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.BlockExceptionHandler;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.csp.sentinel.slots.block.authority.AuthorityException;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeException;
import com.alibaba.csp.sentinel.slots.block.flow.FlowException;
import com.alibaba.csp.sentinel.slots.block.flow.param.ParamFlowException;
import com.alibaba.csp.sentinel.slots.system.SystemBlockException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* @author LXY
* @desc
* @time 2023--04--01--18:26
*/
@Component
public class MyBlockExcetin implements BlockExceptionHandler {
public void handle(HttpServletRequest httpServletRequest, HttpServletResponse response, BlockException e) throws Exception {
Result R=null;
if (e instanceof FlowException){
R=Result.getresule(100,"接口限流了");
}else if(e instanceof DegradeException){
R=Result.getresule(101,"服务降级了");
}else if(e instanceof ParamFlowException){
R=Result.getresule(102,"热点参数限流了");
}else if(e instanceof SystemBlockException){
R=Result.getresule(103,"触发系统保护规则");
}else if(e instanceof AuthorityException){
R=Result.getresule(104,"授权规则不通过");
}
response.setStatus(500);
response.setCharacterEncoding("utf-8");
response.setContentType(MediaType.APPLICATION_JSON_VALUE);
new ObjectMapper().writeValue(response.getWriter(),R);
}
}
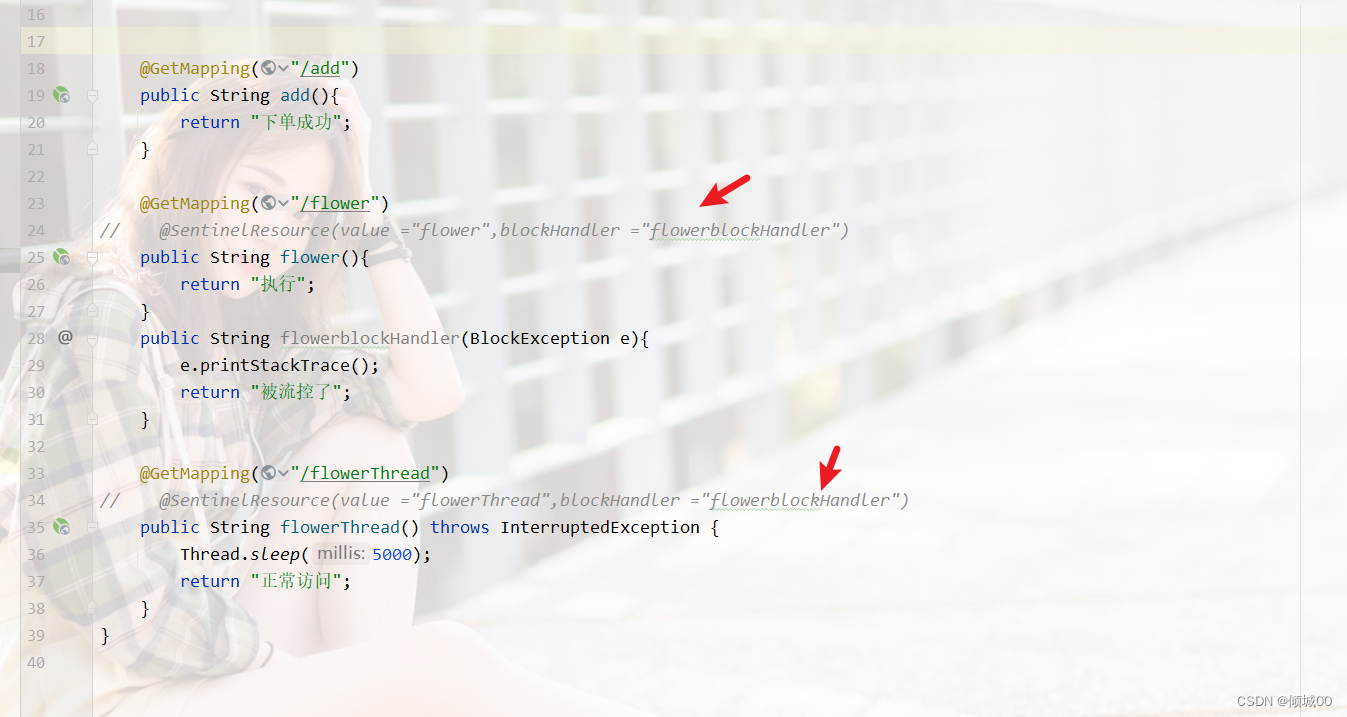
- 注释了
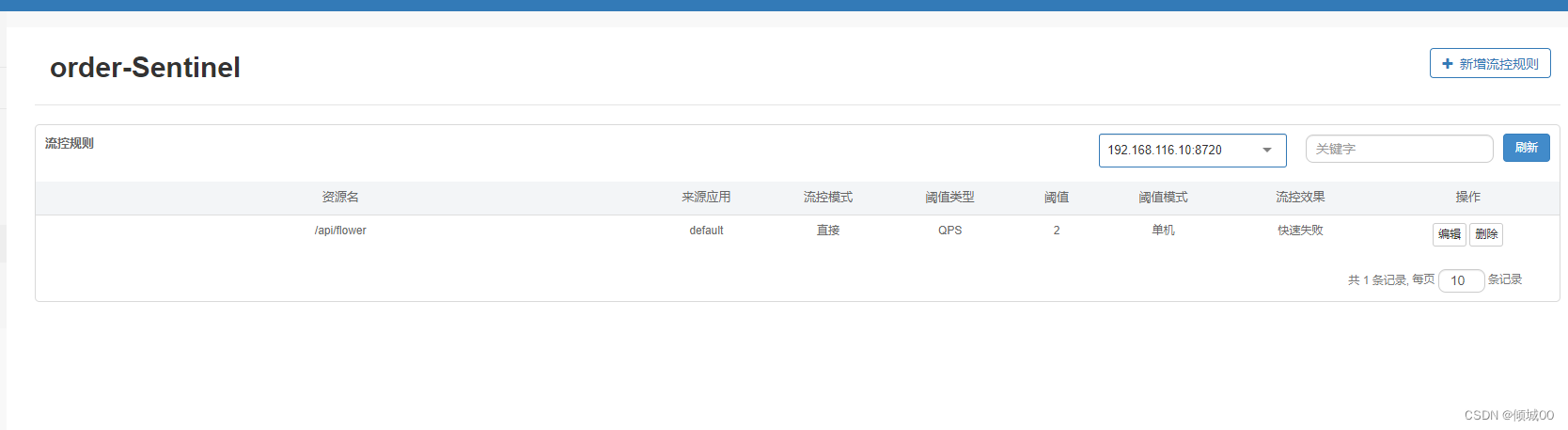
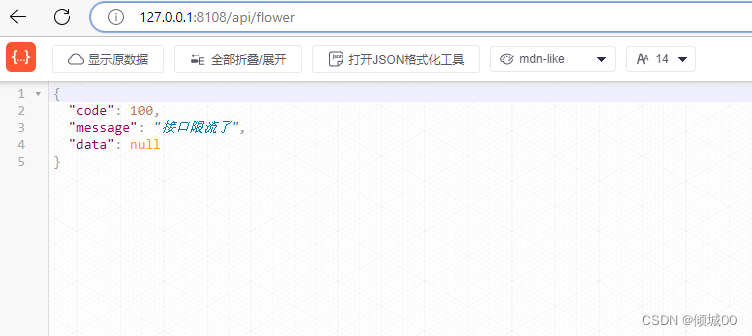
- 自定义异常生效了,可以使用注解,也可以使用统一异常处理
13.8.5 链路流控规则



- geUser是被调用者,test1是一个调用者,test2是一个调用者,这就是属于链路,只想唐test1调用的时候去流控,但是让test2去调用的时候不去流控
- 默认是关闭链路的,开启了之后才会生效
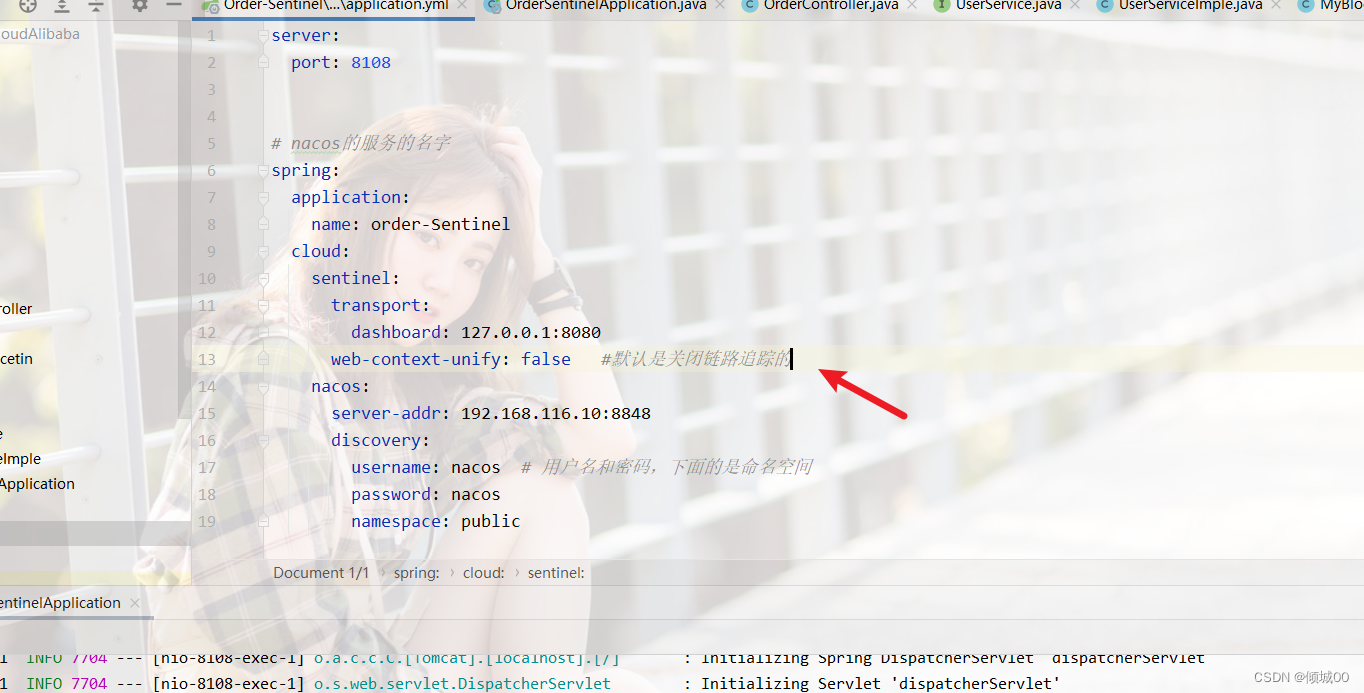
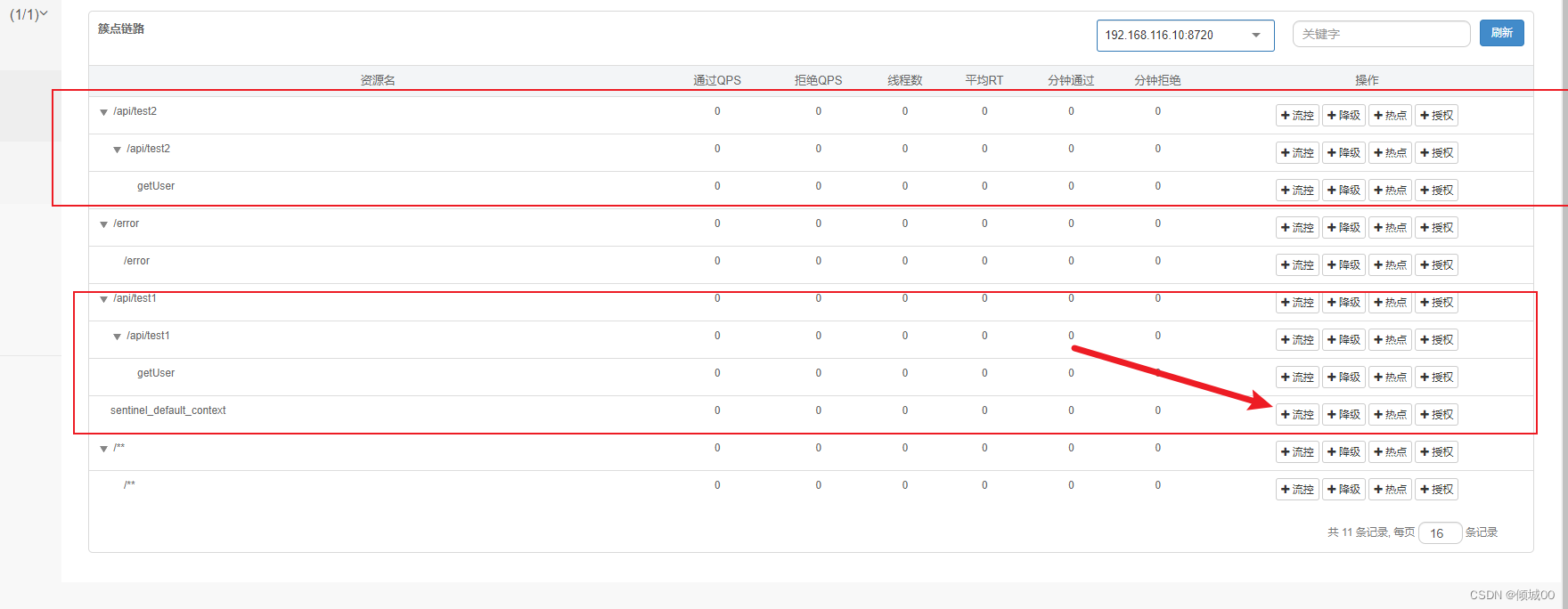
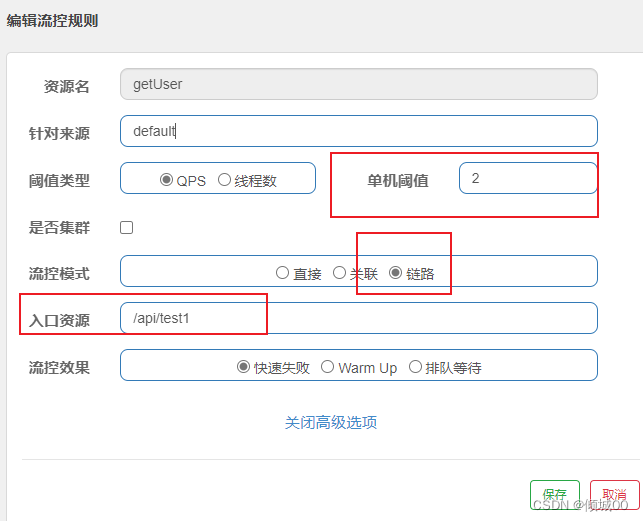
- 给getuser设置链路调用的Qps的阈值,让其调用泽合test1受到限制,test2因为没设置所以没有限制
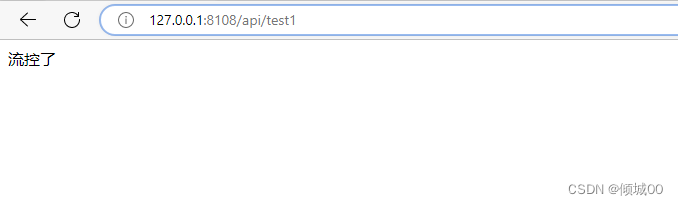
13.8.5 流控效果介绍
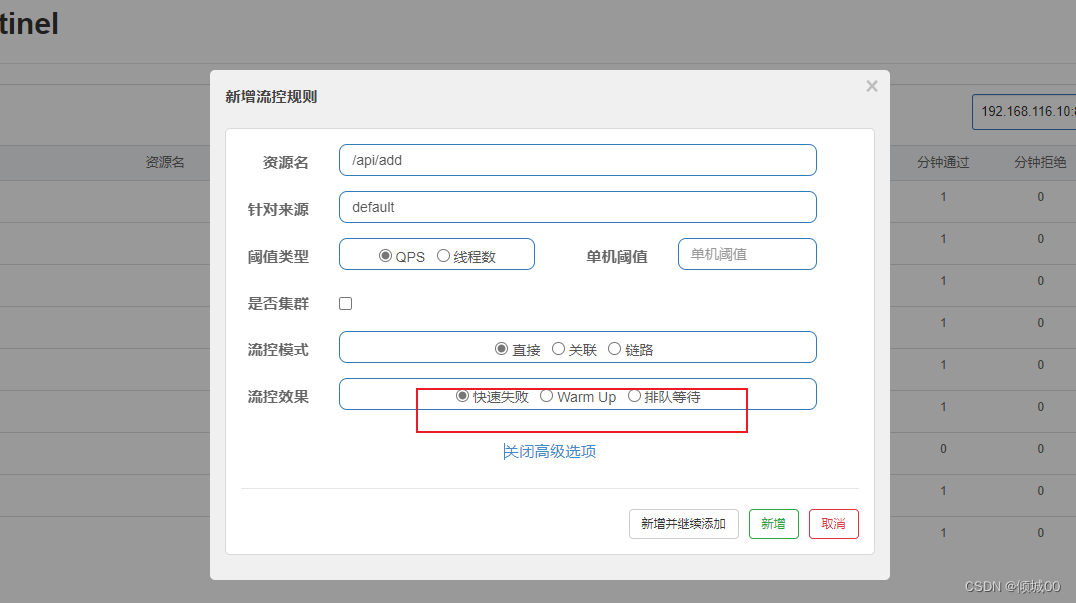
- 快速失败是超过了阈值直接产生失败,不管后面有多少个请求
- Warm up是余热可以设置市场,在这段时长可以慢慢的进来,不会直接失败,会在这个时间之内慢慢接受
- 排队等待是可以设置超时时间,在超时时间之内不会直接失败如果设置的阈值是10,超时时间是20,在20秒钟如果处理了10个就会在剩下的时间去处理更多的请求
13.8.6 Warm Up和排队等待
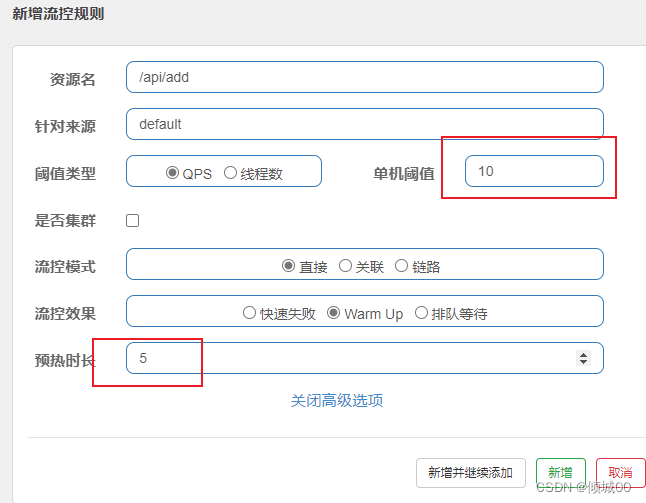
- 这样设置的是慢慢接受流量,5秒钟接受10个请求,多余就会拒绝
- 默认公式是第一次接受三个,即请求QPS 从thread/3开始,经过余热时长逐渐提升QPS阈值
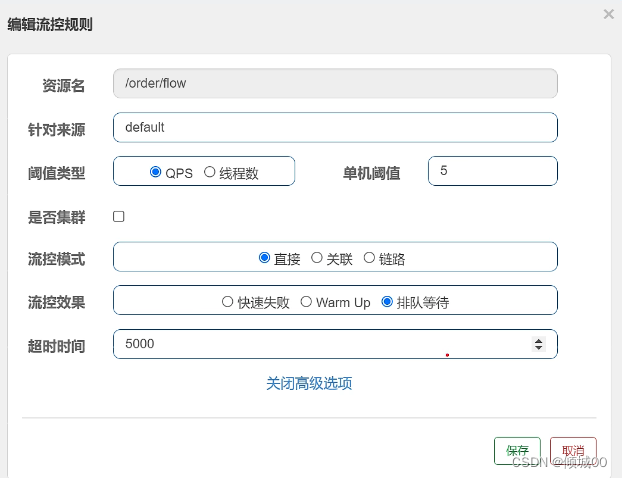
- 排队等待,假如现在是每1秒10个请求中间间隔一段时间在10个请求,设置的阈值是5,就会出现结果是10个请求,5个成功,5个失败
- 设置排队等待时间是5秒,意思就是先进来的10个,有5个执行,剩下的在5秒钟等待前面执行完毕他在执行,就不会出现直接请求了,如果在5秒内还没执行完毕就会直接挂掉
13.8.7 熔断降级
- 代码中是睡眠了5s

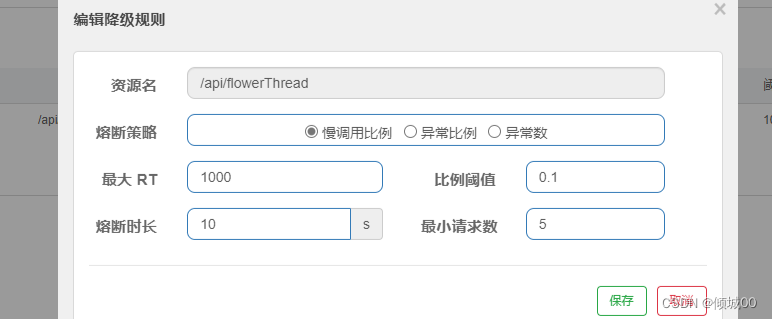
- 最大休RT设置的是1000 就是1秒,代码中睡眠的是5秒,符合慢调用
- 比例阈值是0.1,最小请求数是5.意思就是在5次请求中,1次有一次慢调用就直接降级
- 熔断市场是10秒
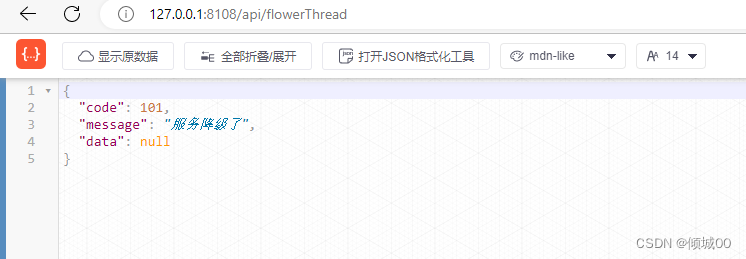
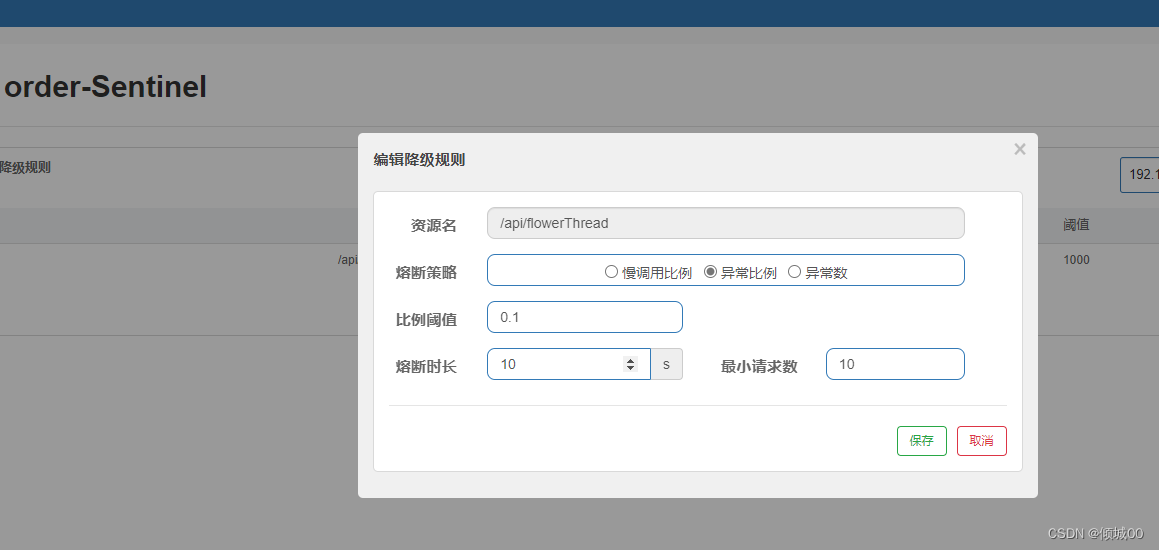
- 异常比例是在10次中有一次异常就熔断了
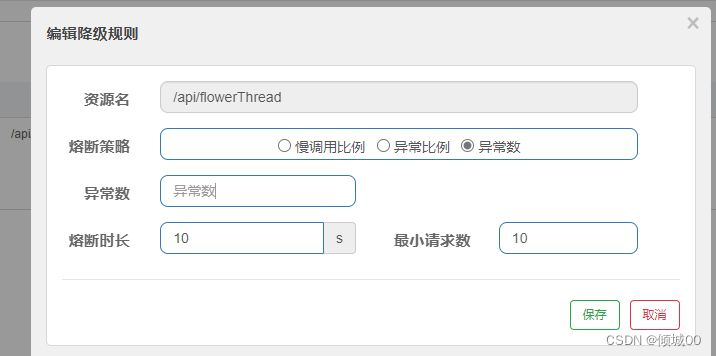
- 异常数是请求中有多少次异常就熔断
13.8.8 热点数据处理

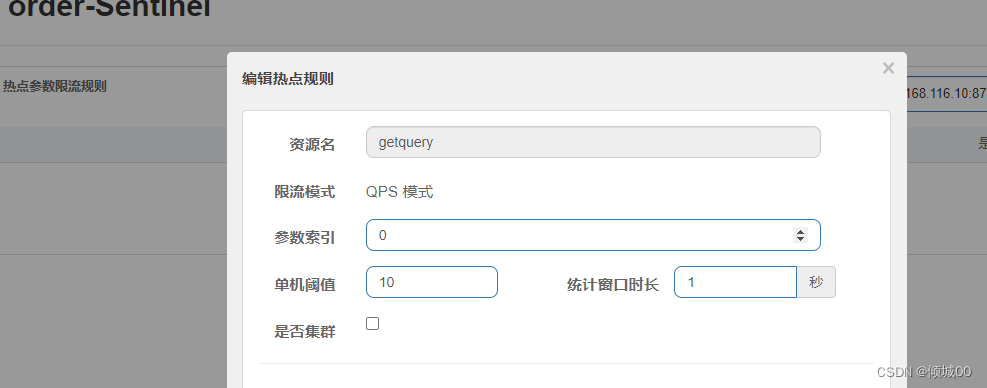
- 参数索引时你想给第几个参数设置,单击阈值是10
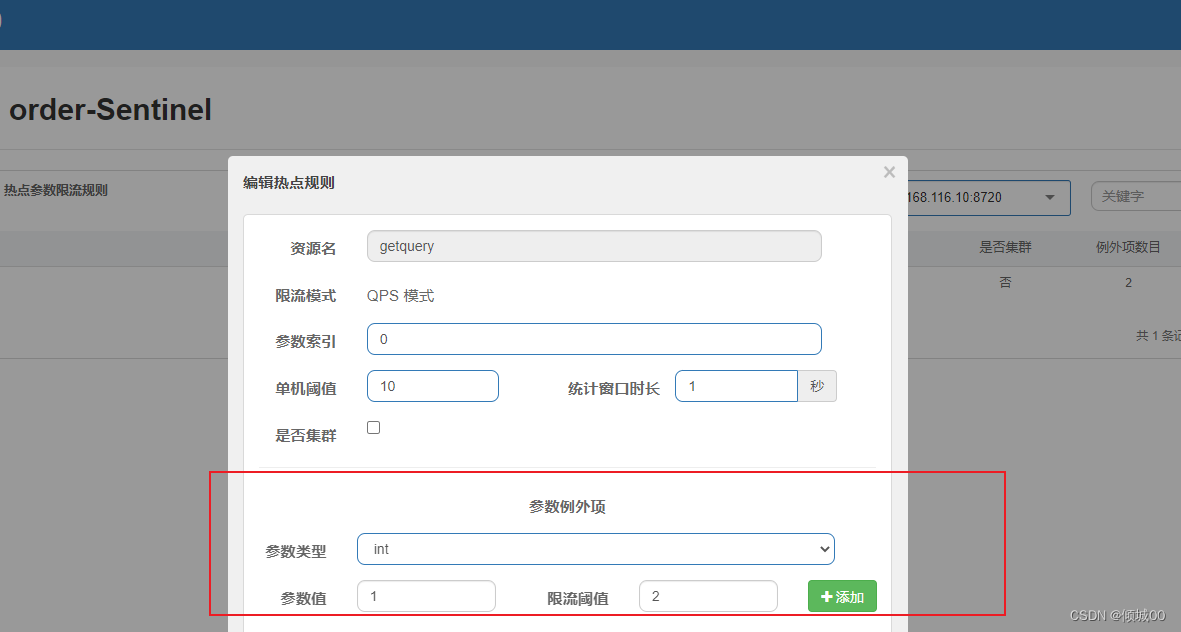
- 上面的参数设置的意思是,给低0个参数设置阈值,设置的值是1,阈值是2,2秒内传参都是1直接降级,传递其他参数,最高是1秒请求10次
13.8.9 规则持久化
- 在客户端创建的规则默认是保存在内存中的,服务重启了规则就丢失了

<!--macos掉sentinel的支持-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
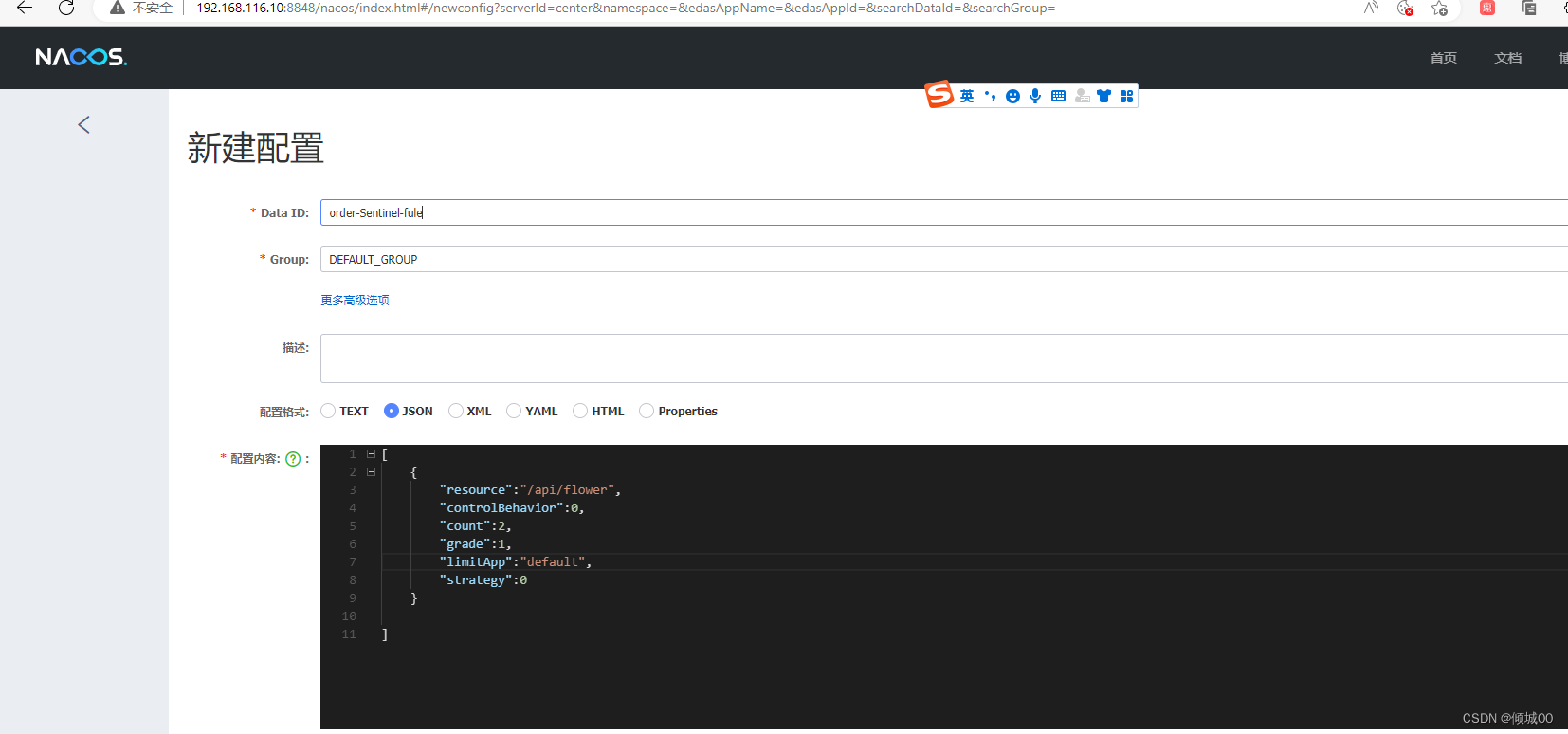
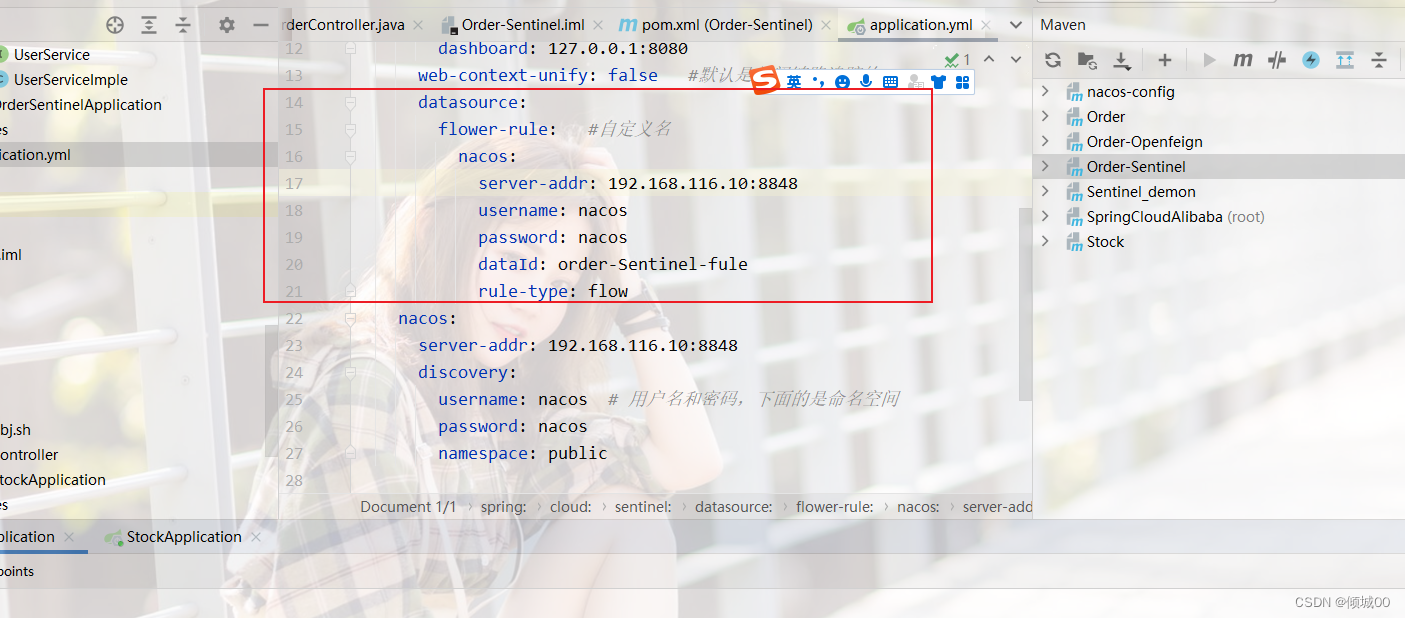
[
{
"resource":"/api/flower",
"controlBehavior":0,
"count":2,
"grade":1,
"limitApp":"default",
"strategy":0
}
]
datasource:
flower-rule: #自定义名
nacos:
server-addr: 192.168.116.10:8848
username: nacos
password: nacos
dataId: order-Sentinel-fule
rule-type: flow
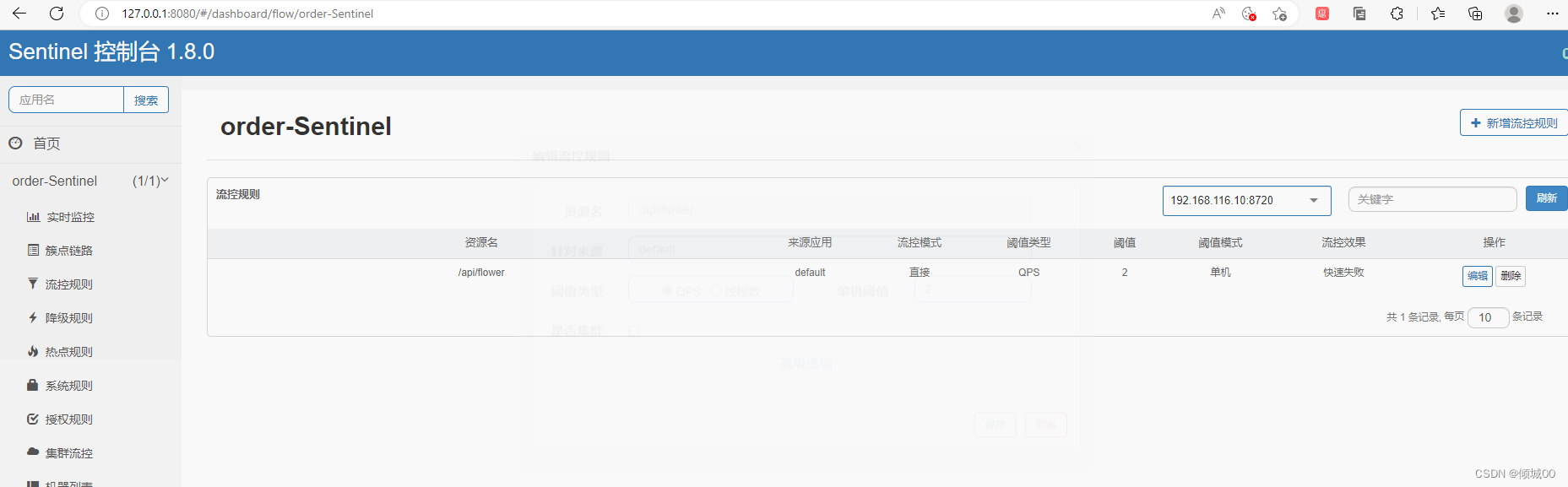
- 再次访问控制台发现创的规则是持久化状态了
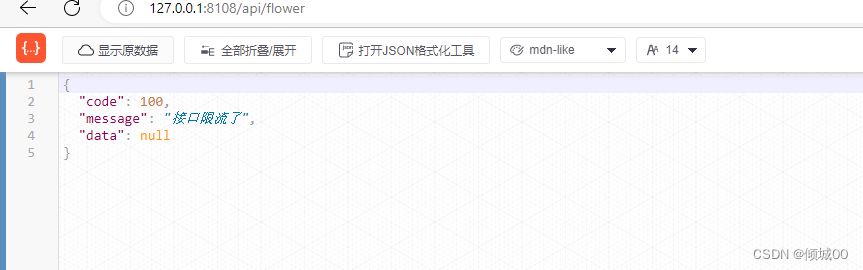
13.9 Seata (分布式事务)

- Spring中有一个注解是@Transational这个注解主要是解决本地事务的
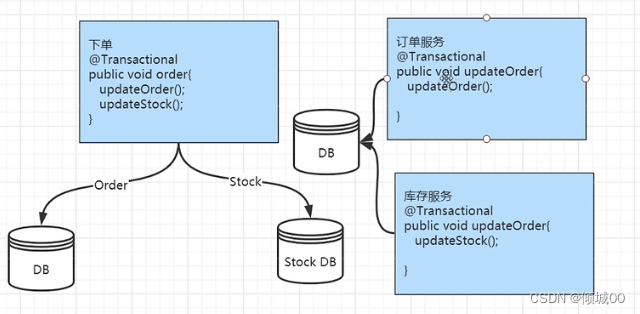
- 以上两种情况,第一种是多DB,第二种是两个接口一个DB都是用本地事务不能完成的
- Seata是一款开源的分布式解决方案,致力于提高高性能和简单易用的分布式事务服务,Seate提供了AT,TCC,SAGA,和XA事务模式,为用户打造驿站分布式解决方案
官网:https://seata.io/zh-cn/index.html
.
13.9.1 二阶段提交协议(2pc)
- 二阶段提交协议,第一阶段是一个预处理的阶段,第二阶段是一个提交/回滚的阶段
- 通俗来讲,预处理的作用就是保证数据能否可以被修改满不满足被修改的条件,让协调管理器去访问数据库做一个预处理的请求,然后会返回应答,yes or no 如果是yes的话进行下一步就是提交 如果是no就直接让其进行回滚,第二阶段也会返回应答,成功或者失败了,因为第一阶段返回的应答都是yes,第二阶段返回的应答不能说完全保证是yes,出no的几率很小,如果真的出了no,就只能让程序员进行干预了
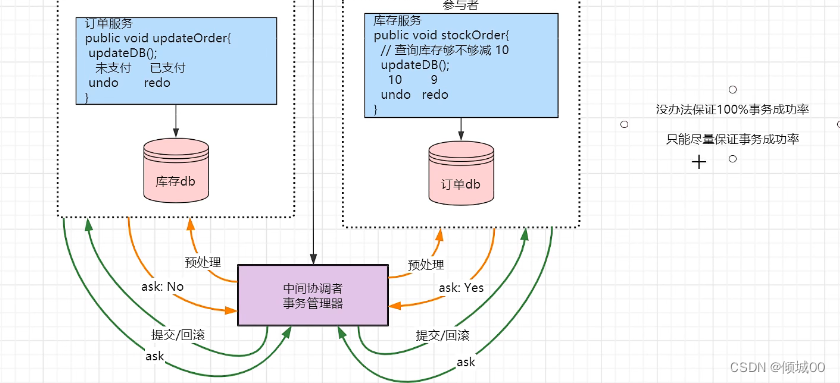
- 2pc存在的问题
-
- 同步阻塞,参与者在等待协调者的指令时,其实是在等待其他参与者的响应,再次过程中,参与者是无法进行其他操作的,也就是阻塞了其运行,倘若参与者和协调者之前因为网络异常一直收不到消息也会一直的阻塞下去
13.9.2 分布式解决方案:AT模式
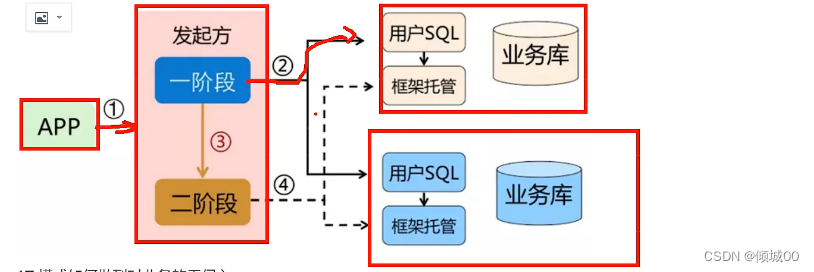
- 一阶段: seata会拦截sql,首先解析sql语义,找到业务sql要更新的业务数据,在业务数据被更新之前将其保存称为before image,然后执行业务sql,更细业务数据,在业务数据更新之后,在将其保存为 after image,生成行锁,这样保证了数据的操作原子性
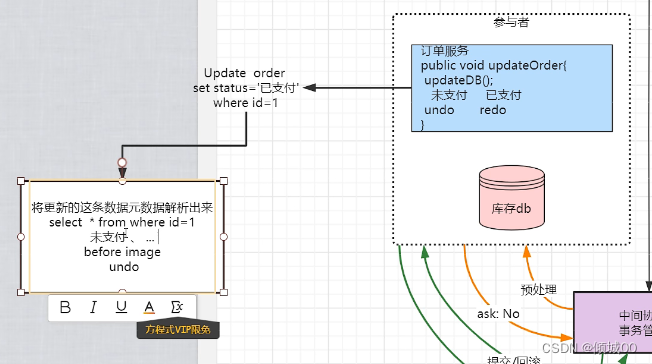
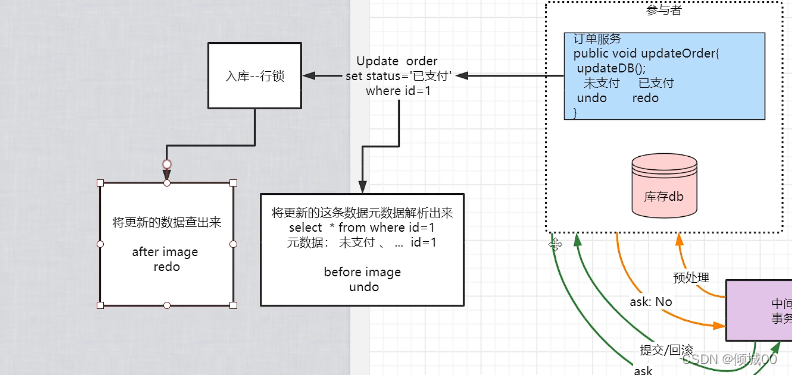
- 执行修改语句之前,首先是将sql解析,将数据查出来,查询之后将数据村委before image中作为之前的数据也就是回滚的数据
- 然后进行入库操作,是有行锁的,保证数据一致性,然后修改之后在讲数据查询出来,作为修改之后的数也就是提交之后的数据,after iage
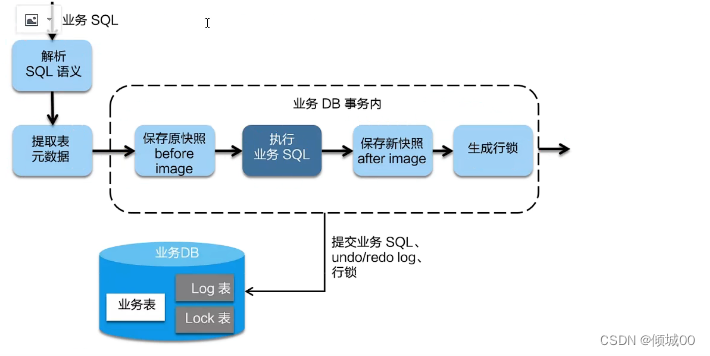
- 第二阶段提交的话,因为第一阶段已经将修改语句提交到了数据库,所以seatea在这一个阶段会将保存的快照数据和行锁删掉完成数据的清理
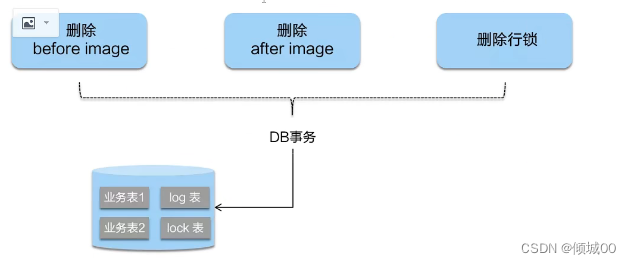
二阶段回滚的话就需要执行已执行的业务sql,还原回滚数据,回滚方式是用before image 还原业务数据,

13.9.3 分布式解决方案:TCC模式
- TCC模式是需要用户根据自己的业务场景实现Try,confirm,Cancel三个阶段,事务发起方在一阶段try,第二阶段是提交也就是confirm阶段,如果发生了异常就执行cancel阶段就是回滚
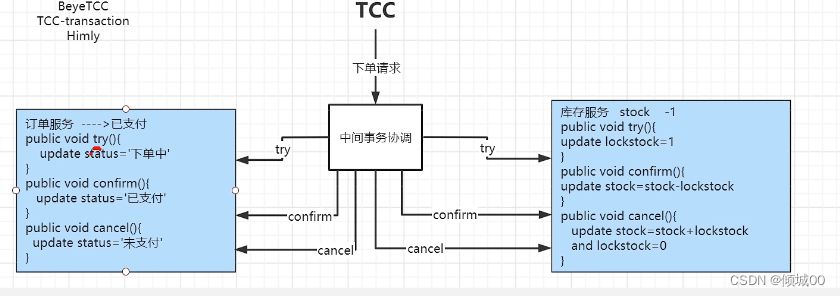
- 通俗来讲,两个模块,一个是支付,一个是下单-1
- 首先执行try,将状态修改为下单中,库存上锁,如果在这一阶段发生了异常,数置空就行,没有对数据进行了实质性的修改
- 第二阶段进行提交数据,修改订单数量和状态,如果出现了异常进行回滚执行cancel放大,将订单置空,库存恢复回去
13.9.4 MQ的可靠消息最终一致性
- 前面有发过rockermq的文章,里面有代码实现
13.9.5 Srate DB服务搭建

- 配置db的话修改如下文件
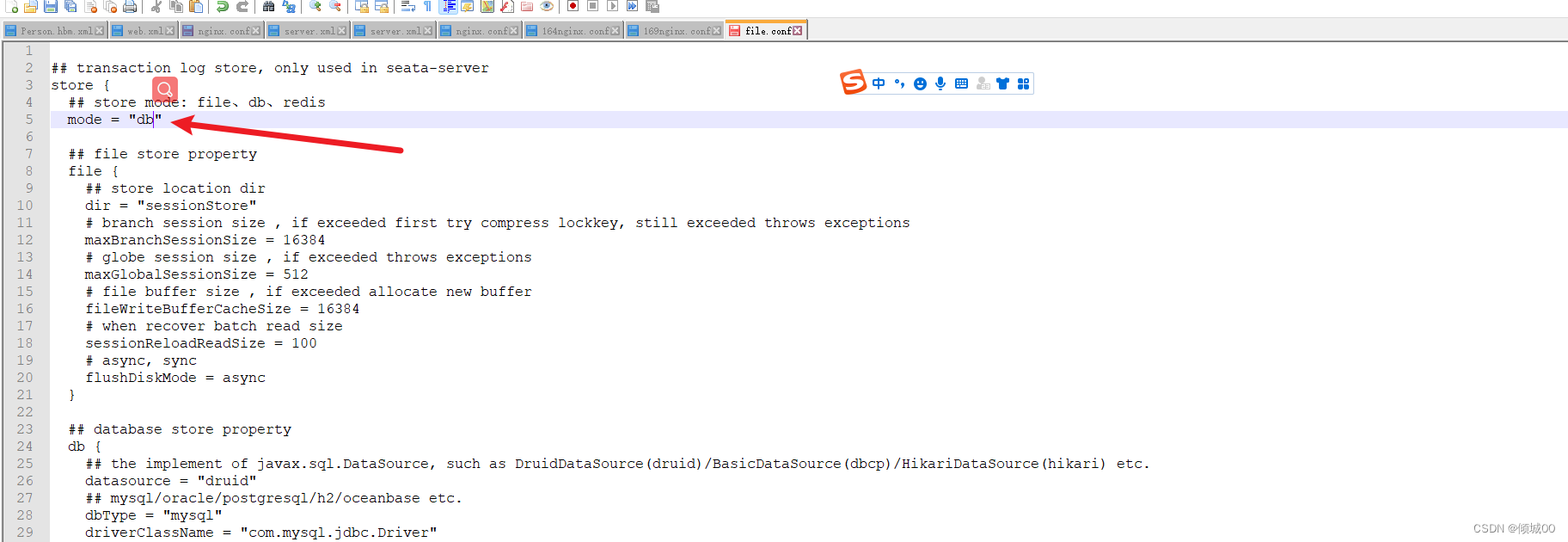

- 然后就是创建数据库

- 直接将整个项目下载下来了,咋mysql中执行第一个sql文件即可
- 这个表存的是事务参与者的信息
- 这个存储的是锁,锁的哪一行信息,哪一行主键信息
- 这个存储的是xid,事务id等

13.9.6 Srate db+nacos服务搭建
- 实现高可用db,nacos和db是缺一不可的


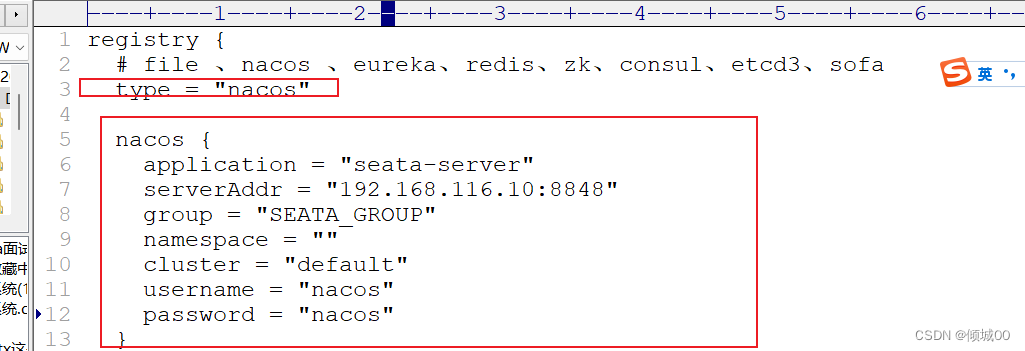
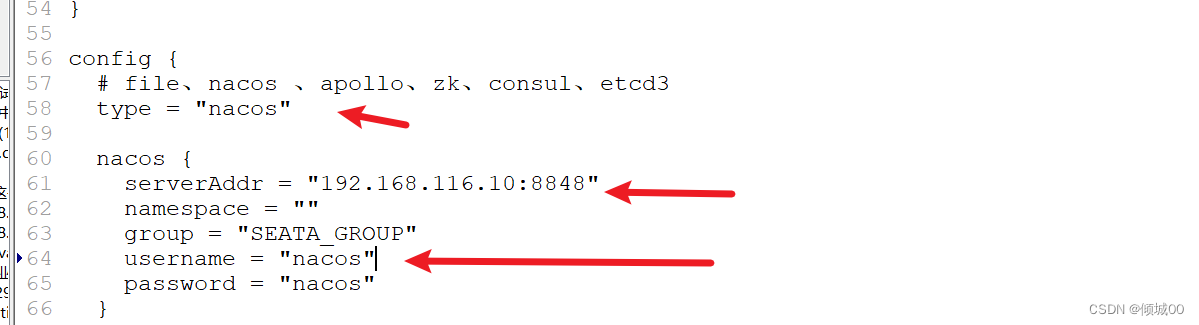
- 接下来修改这个文件,是喜爱git上下载的
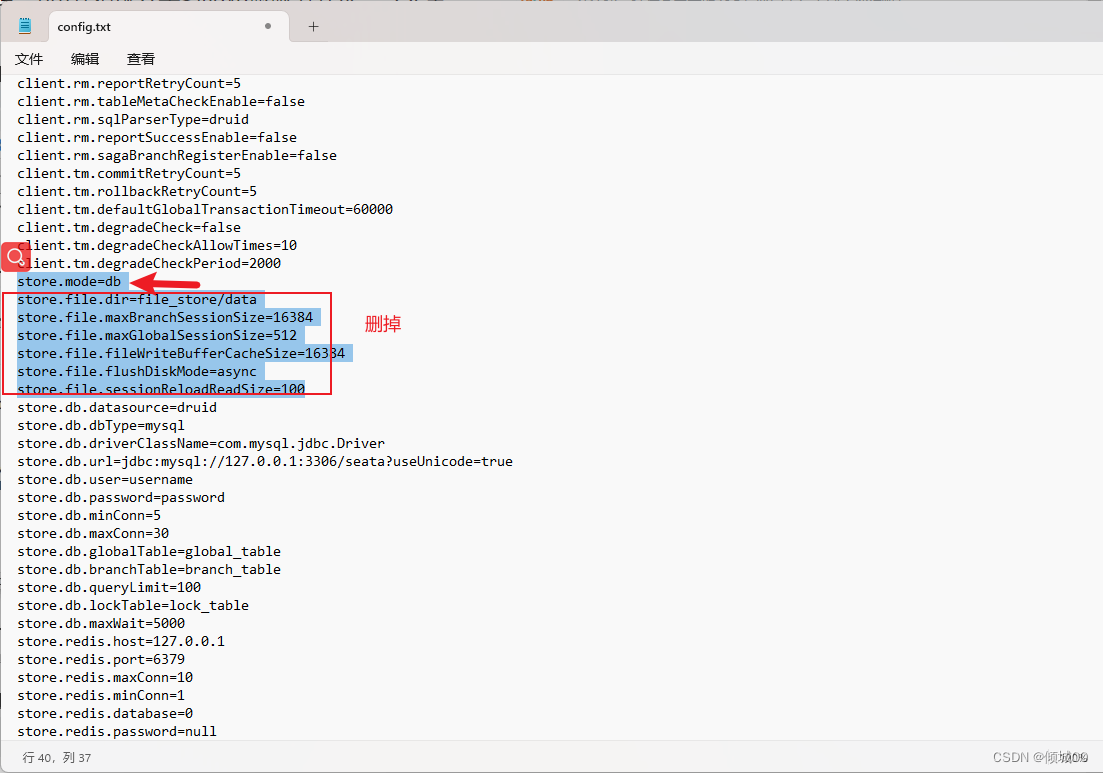
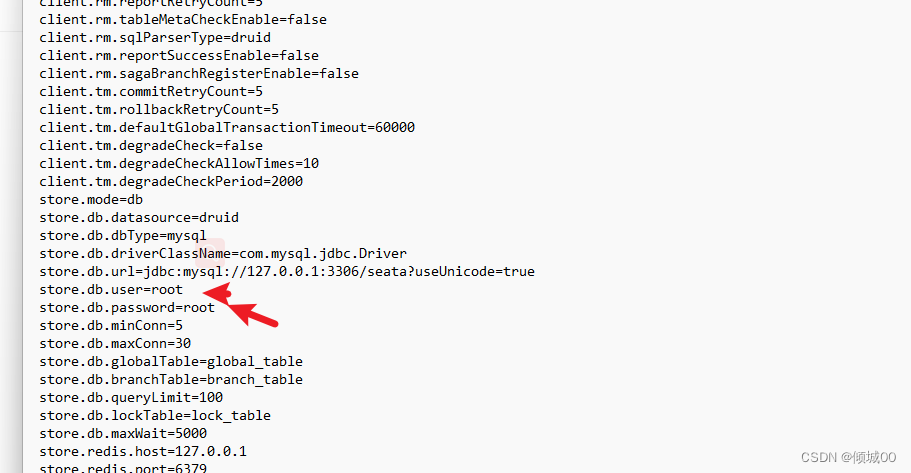
- 这个是事务分组是可以自定义的
- 加入说server部署在北京,就可以叫北京,但是北京停电了,宕机了,就可以将其切换到另外的城市部署


- 保存完毕之后去这个目录打开git 窗口,输入sh 文件名.sh,执行,默认是本地的
- 如果想添加的地方没在本地可以在启动的时候添加别的参数

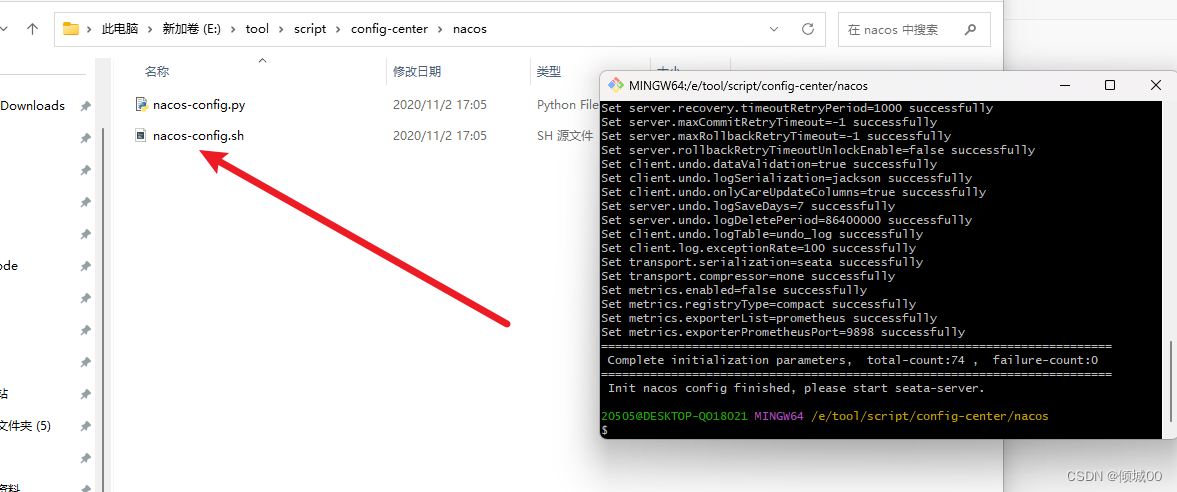
-
打开nacos之后会发现多了很多
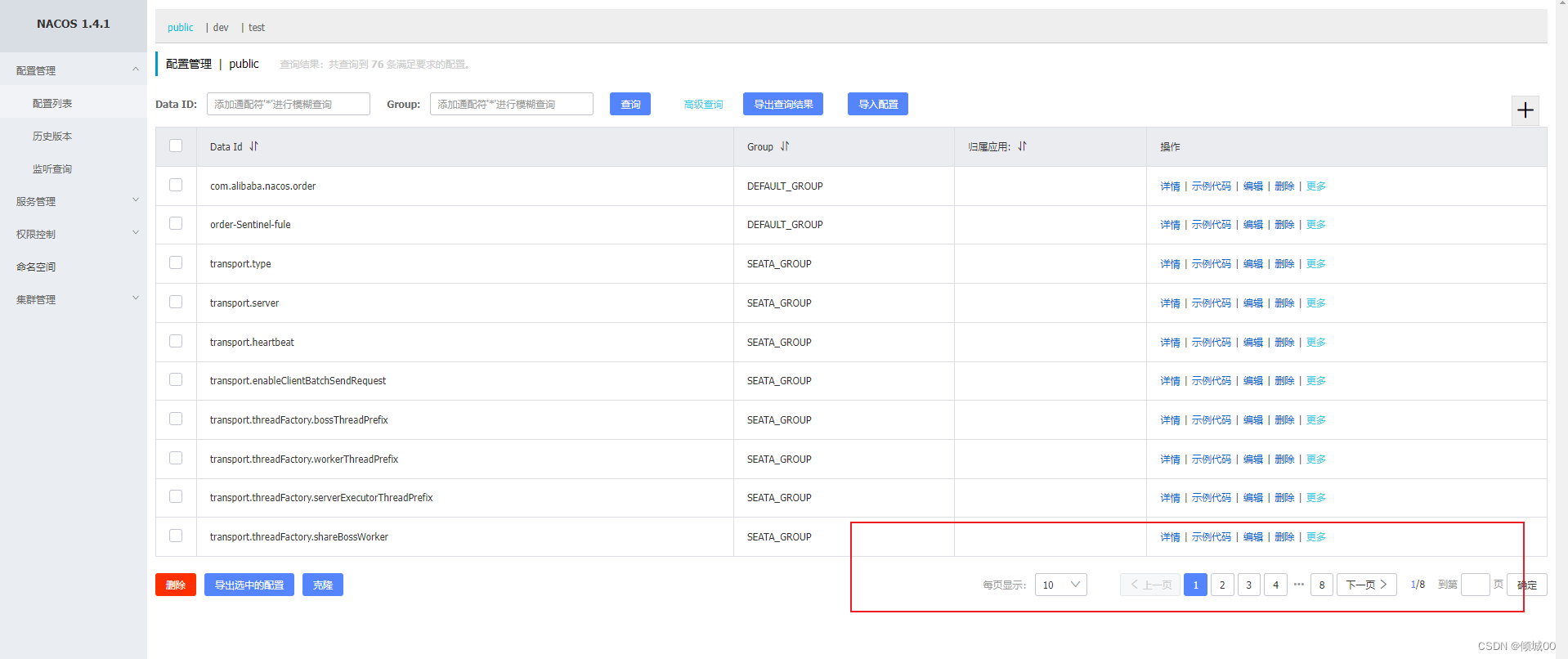
-
踩坑注意,如果启动的时候报这个错误
-
在bin目录同级创建log文件夹
-
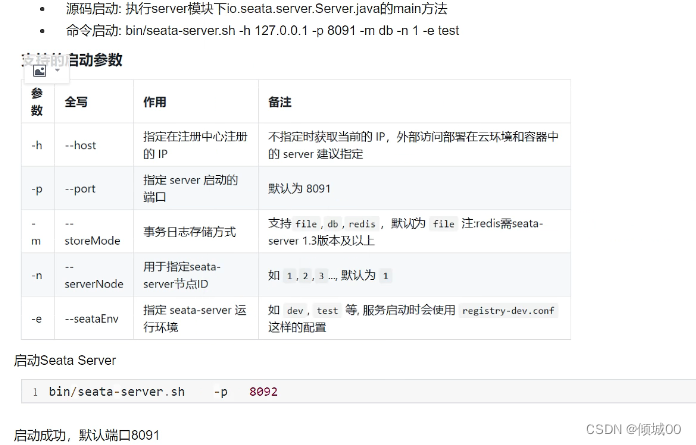
-
打开nacos发现已经注册上去了,即为成功
13.9.7 代码和环境搭建
- 模拟一个下单的远程调用,创建商品订单之后,将商品-1
- Seatas pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>SpringCloudAlibaba</artifactId>
<groupId>com.bj.sh</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>Seatas</artifactId>
<packaging>pom</packaging>
<modules>
<module>SeatasOrder</module>
<module>SeatascOMM</module>
</modules>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- nacos-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.20</version>
</dependency>
<dependency>
<groupId>net.jodah</groupId>
<artifactId>expiringmap</artifactId>
<version>0.5.8</version>
</dependency>
<!--openfegin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
</dependencies>
</project>
SeatascOMM pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>Seatas</artifactId>
<groupId>com.bj.sh</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>SeatascOMM</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
package com.rj.bd.connstion;
import com.rj.bd.Moden.commocity;
import com.rj.bd.Service.commocityService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author LXY
* @desc
* @time 2023--04--02--17:57
*/
@RestController
@RequestMapping("/api")
public class Connction {
@Autowired
commocityService service;
@GetMapping("/updatecommocity")
public Object updatecommocity(){
commocity commocity=new commocity();
commocity.setCount(99+"");
commocity.setSid("0012");
return service.updatecommocity(commocity);
}
}
package com.rj.bd.Dao;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.rj.bd.Moden.commocity;
import org.apache.ibatis.annotations.Mapper;
/**
* @author LXY
* @desc
* @time 2023--04--02--18:43
*/
@Mapper
public interface commocityDao extends BaseMapper<commocity> {
}
package com.rj.bd.Moden;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
* @author LXY
* @desc
* @time 2023--04--02--18:43
*/
@Data
@TableName("commocity")
public class commocity {
private String sid;
@TableField("Comm_name")
private String name;
@TableField("Comm_count")
private String count;
}
package com.rj.bd.Service;
import com.rj.bd.Moden.commocity;
/**
* @author LXY
* @desc
* @time 2023--04--02--18:45
*/
public interface commocityService {
int updatecommocity(commocity comm);
}
package com.rj.bd.Service;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.rj.bd.Dao.commocityDao;
import com.rj.bd.Moden.commocity;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* @author LXY
* @desc
* @time 2023--04--02--18:46
*/
@Service
public class commocityServiceImple implements commocityService{
@Autowired
commocityDao dao;
@Override
public int updatecommocity(commocity comm) {
QueryWrapper queryWrapper=new QueryWrapper();
queryWrapper.eq("sid",comm.getSid());
return dao.update(comm,queryWrapper);
}
}
server:
port: 8887
spring:
datasource:
url: jdbc:mysql://localhost:3306/testcommodity?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&AllowPublicKeyRetrieval=True
username: root
password: root
- SeatasOrder Pom
package com.rj.bd.connstion;
import com.rj.bd.Moden.Order;
import com.rj.bd.Service.OrderService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author LXY
* @desc
* @time 2023--04--02--17:57
*/
@RestController
@RequestMapping("/api")
public class Connction {
@Autowired
OrderService service;
@GetMapping("/creatorder")
public Object creatorder(){
Order order=new Order();
order.setSid(001);
order.setCommodityId("44564");
order.setStatus(1+"");
return service.creatOrder(order);
}
}
package com.rj.bd.Dao;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.rj.bd.Moden.Order;
import org.apache.ibatis.annotations.Mapper;
/**
* @author LXY
* @desc
* @time 2023--04--02--17:56
*/
@Mapper
public interface OrderDao extends BaseMapper<Order> {
}
package com.rj.bd.Moden;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
* @author LXY
* @desc
* @time 2023--04--02--17:54
*/
@Data
@TableName("ORDERS")
public class Order {
private Integer sid;
@TableField("commodity")
private String commodityId;
@TableField("statuss")
private String status;
}
package com.rj.bd.Service;
import com.rj.bd.Moden.Order;
/**
* @author LXY
* @desc
* @time 2023--04--02--17:58
*/
public interface OrderService {
public Object creatOrder(Order order);
}
package com.rj.bd.Service;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.rj.bd.Dao.OrderDao;
import com.rj.bd.Moden.Order;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* @author LXY
* @desc
* @time 2023--04--02--17:59
*/
@Service
public class OrderServiceInple implements OrderService{
@Autowired
OrderDao dao;
public Object creatOrder(Order order) {
return dao.insert(order);
}
}
server:
port: 8889
spring:
datasource:
url: jdbc:mysql://localhost:3306/testOrder?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&AllowPublicKeyRetrieval=True
username: root
password: root
- 数据库
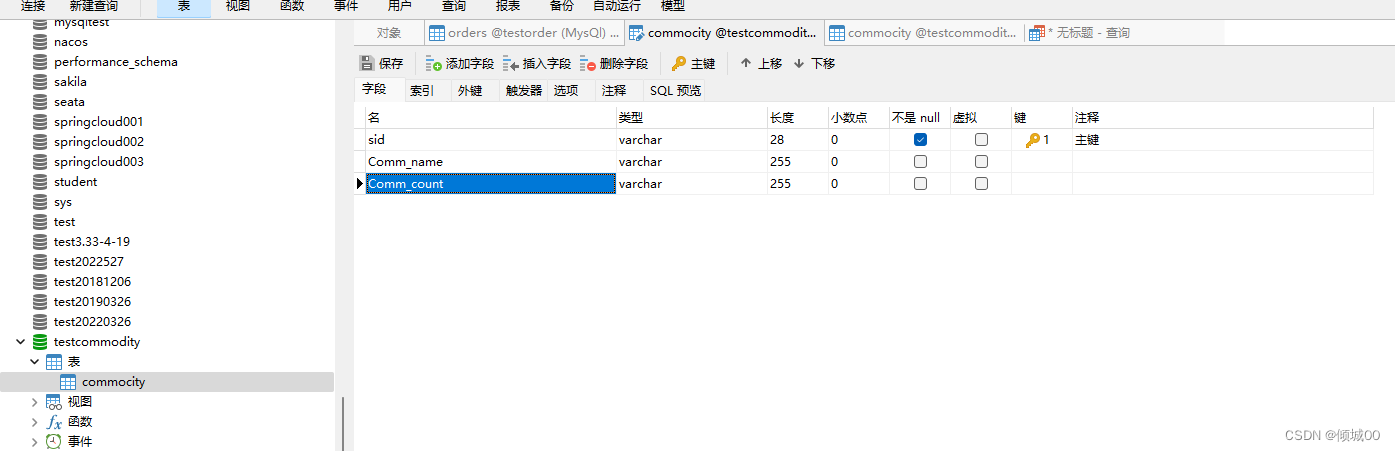
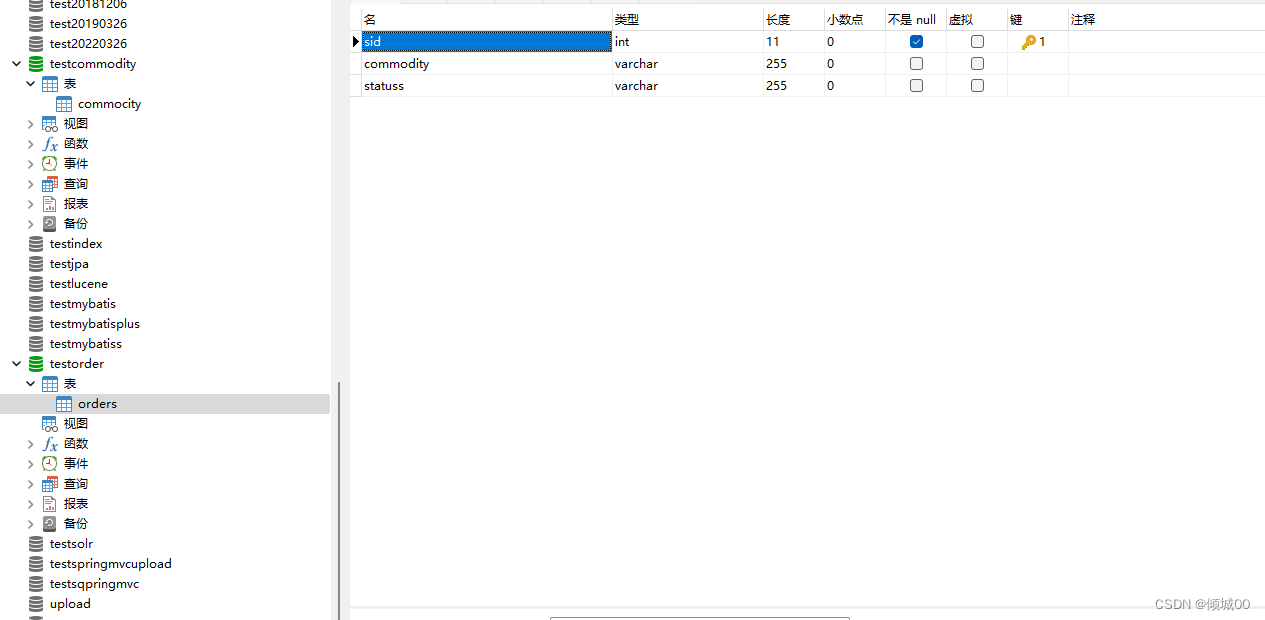
- 然后将两个服务注册到nacos中
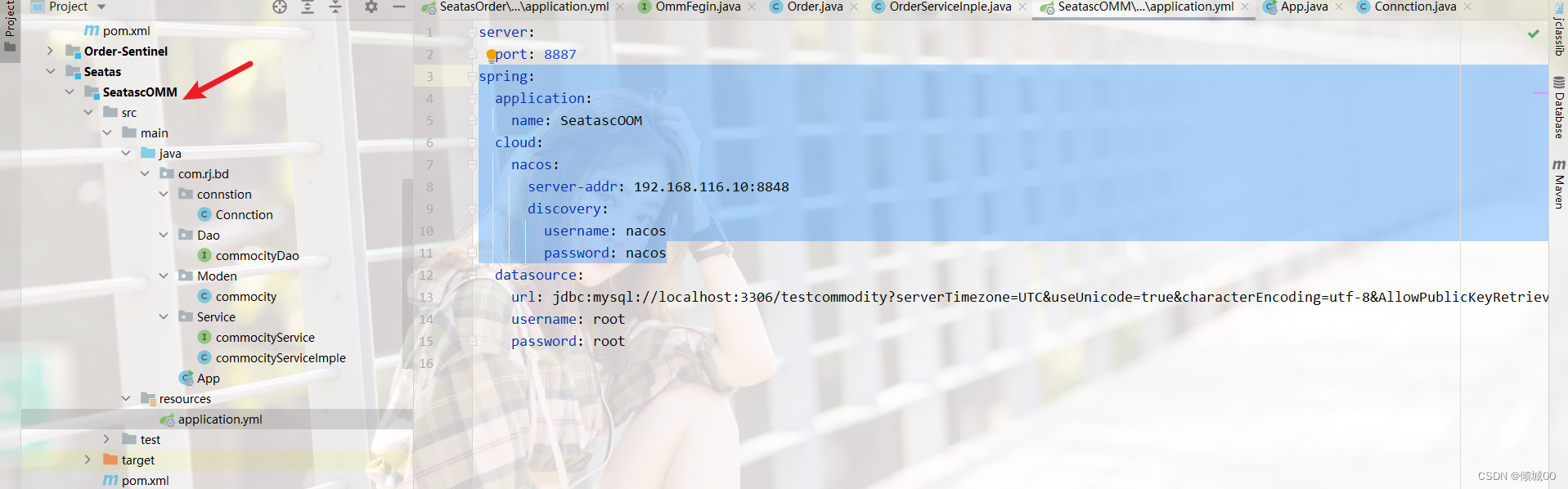
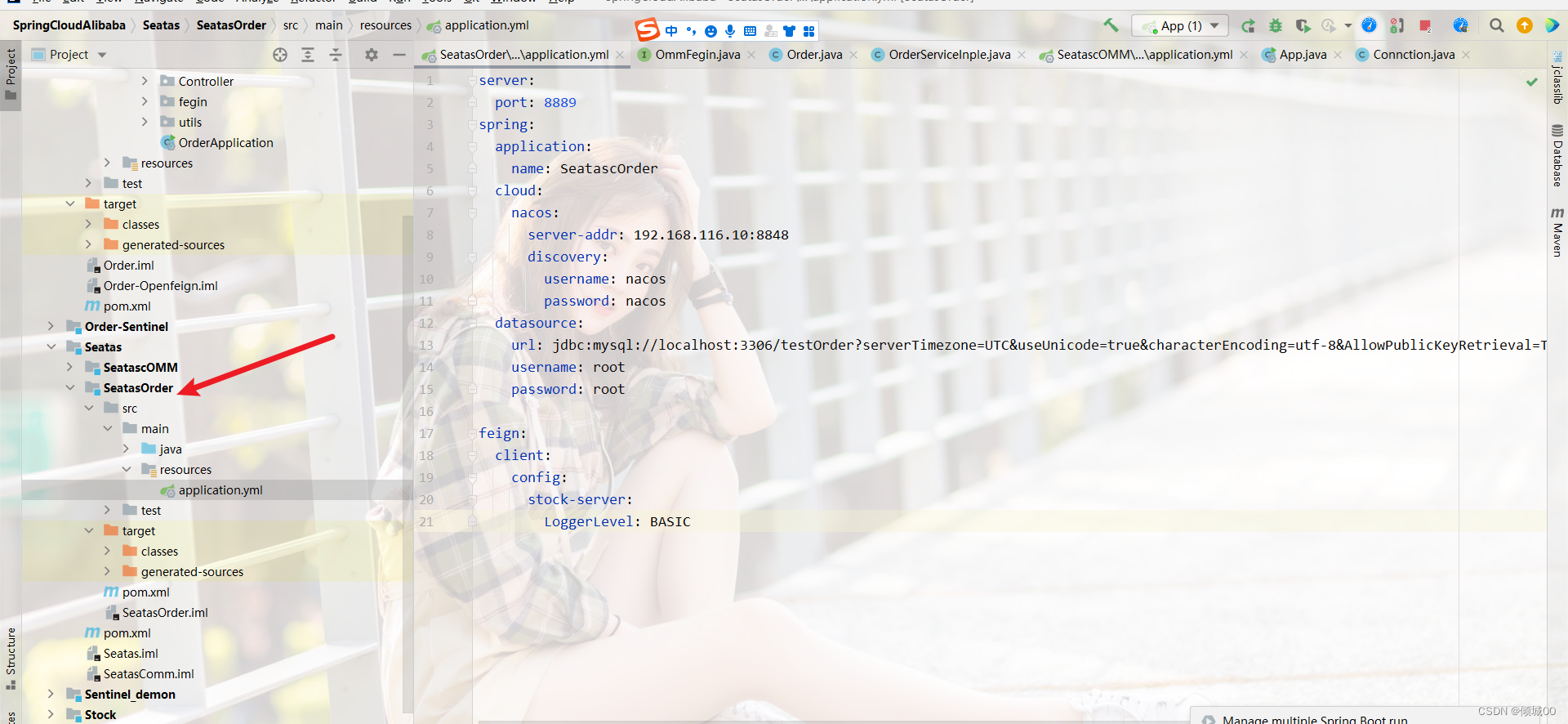
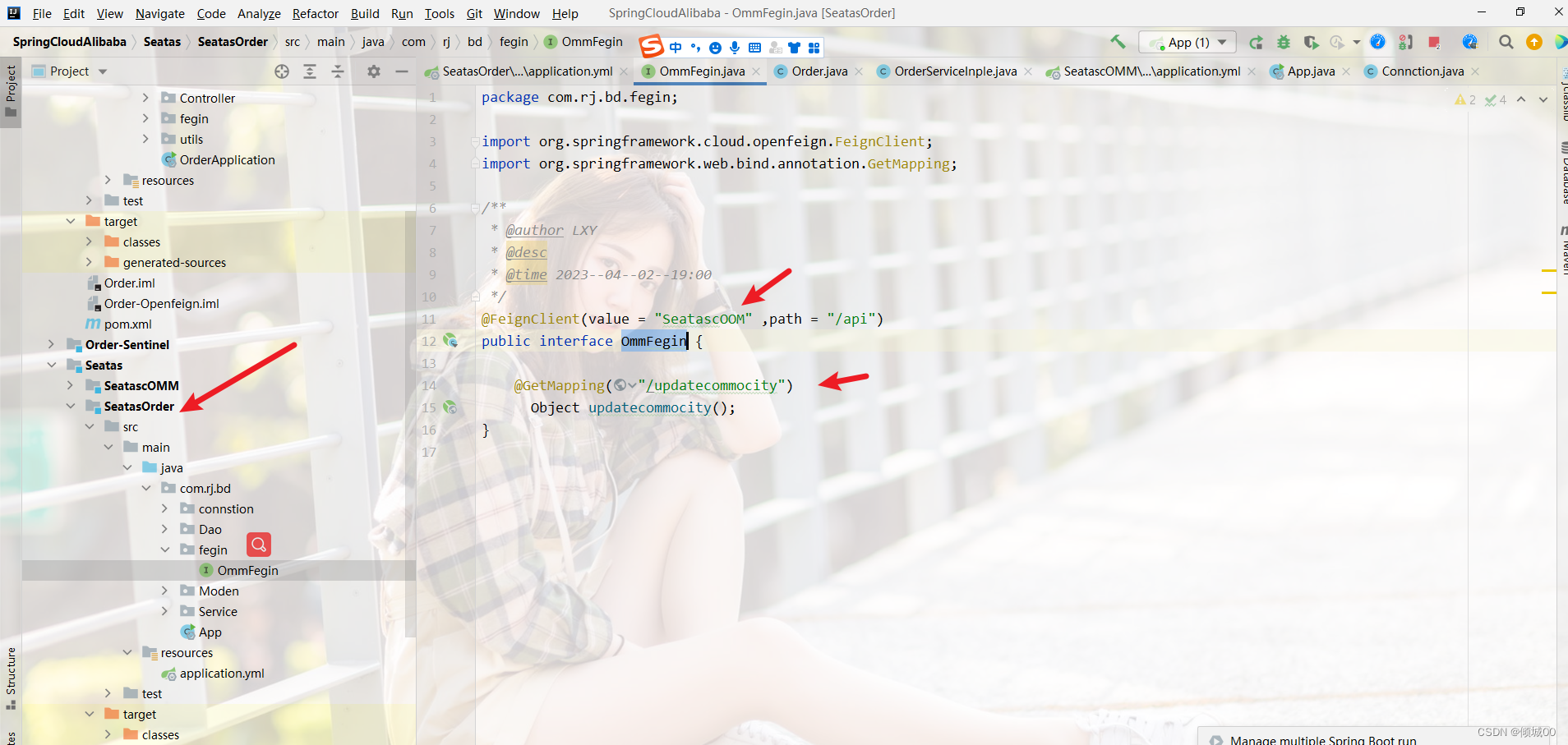
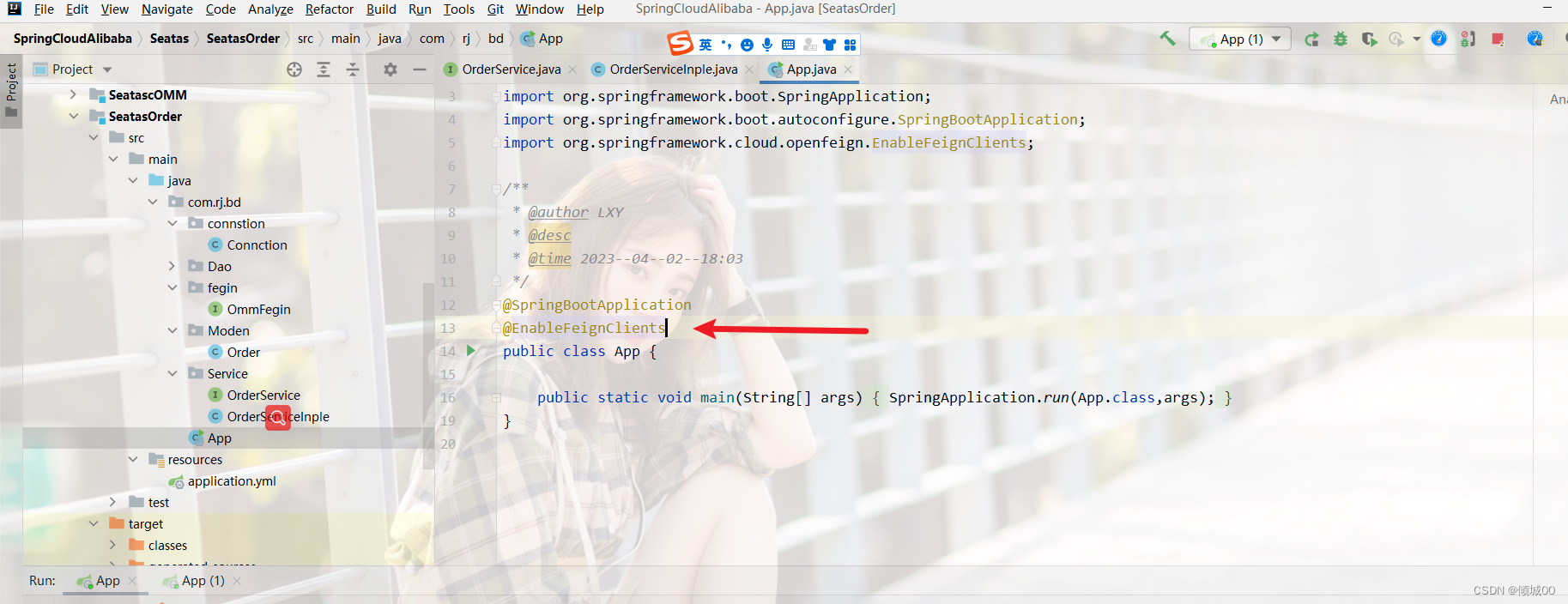
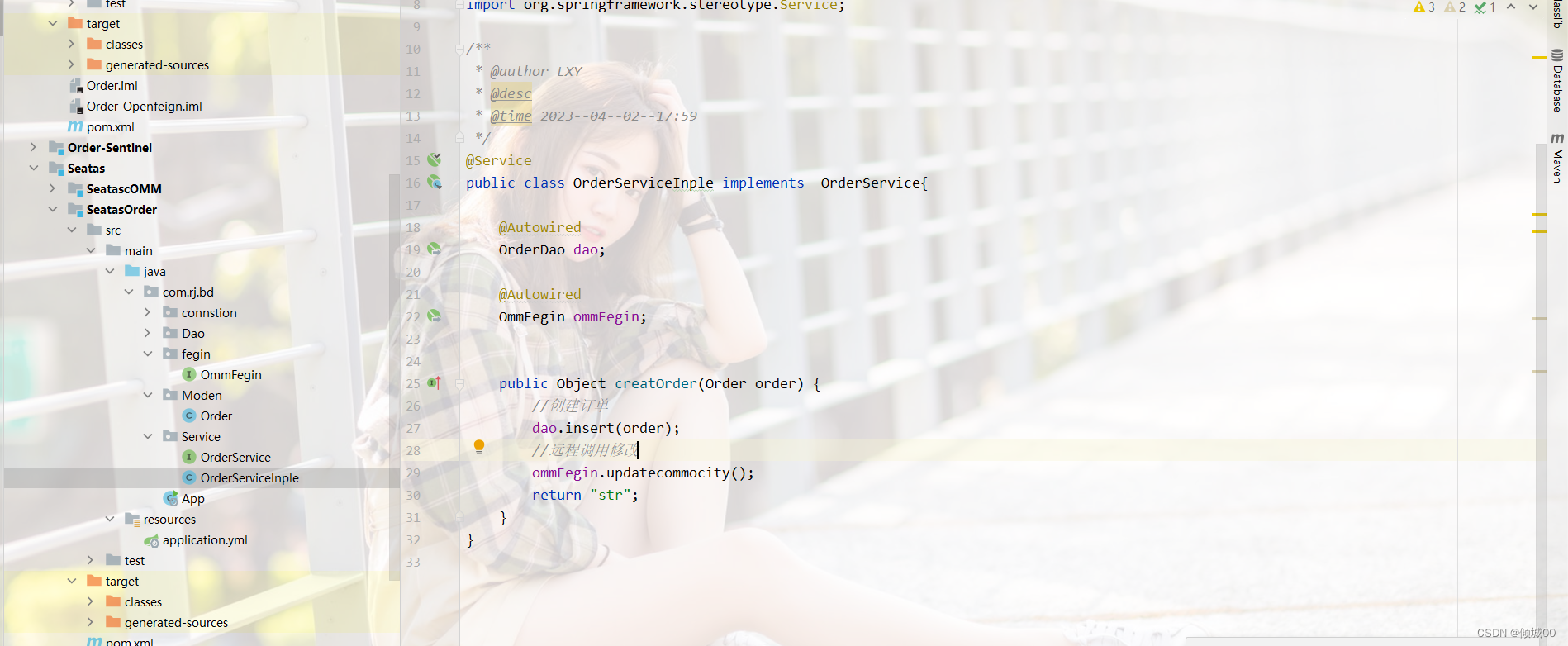
- 模拟一个下单的远程调用,创建商品订单之后,将商品-1
- 开启本地事务,发现只有订单回滚,商品因为远程调用的关系没有进行回滚
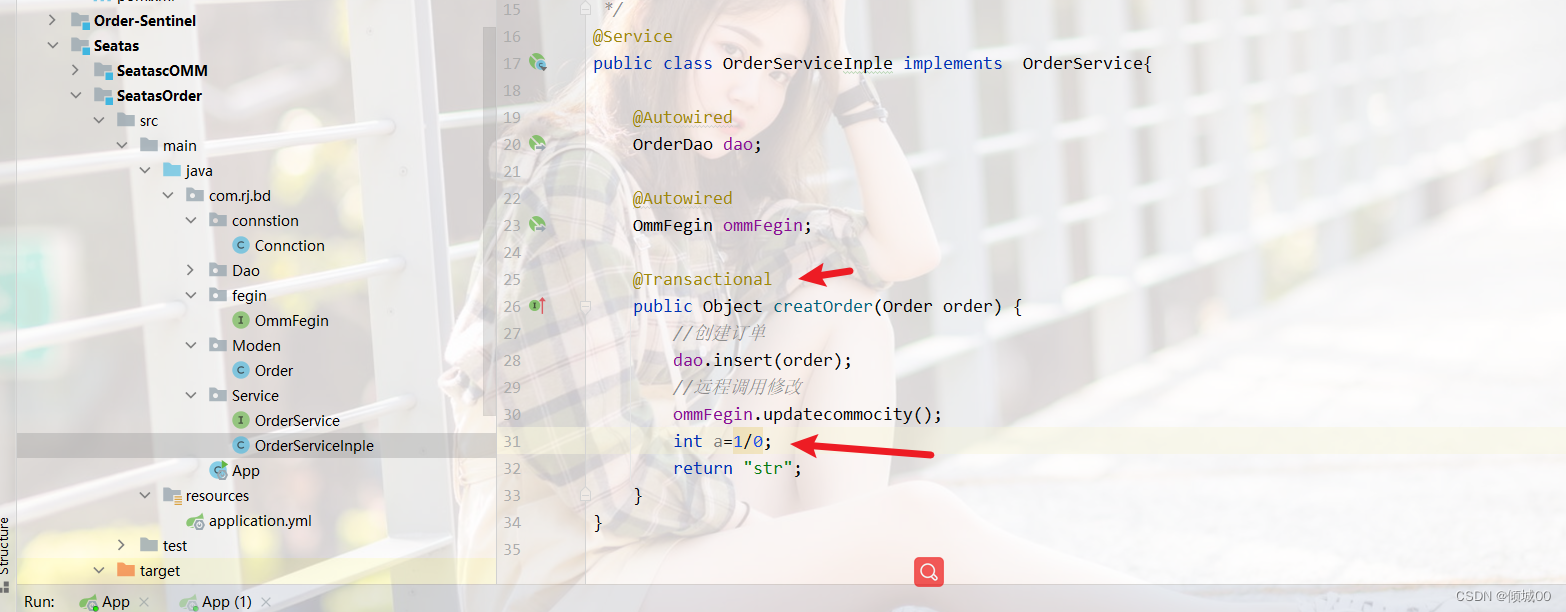
13.9.8 Seata解决分布式事务
- 开始搭建seata客户端,添加到父Seate中
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
create table undo_log
(
branch_id bigint not null comment 'branch transaction id',
xid varchar(100) not null comment 'global transaction id',
context varchar(128) not null comment 'undo_log context,such as serialization',
rollback_info longblob not null comment 'rollback info',
log_status int not null comment '0:normal status,1:defense status',
log_created datetime(6) not null comment 'create datetime',
log_modified datetime(6) not null comment 'modify datetime',
constraint ux_undo_log
unique (xid, branch_id)
)
comment 'AT transaction mode undo table' charset=utf8;
-
两个mysql库都添加这个表,这个表时锁表,和seata的日志记录回滚有关系
-
还有之前
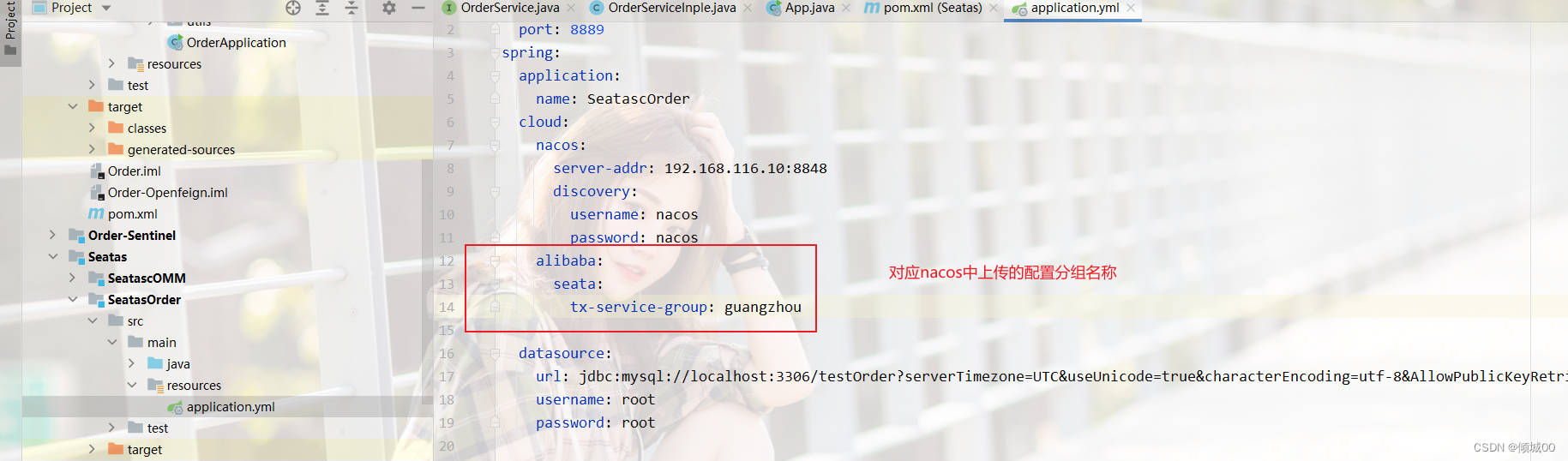
- 两个都更改
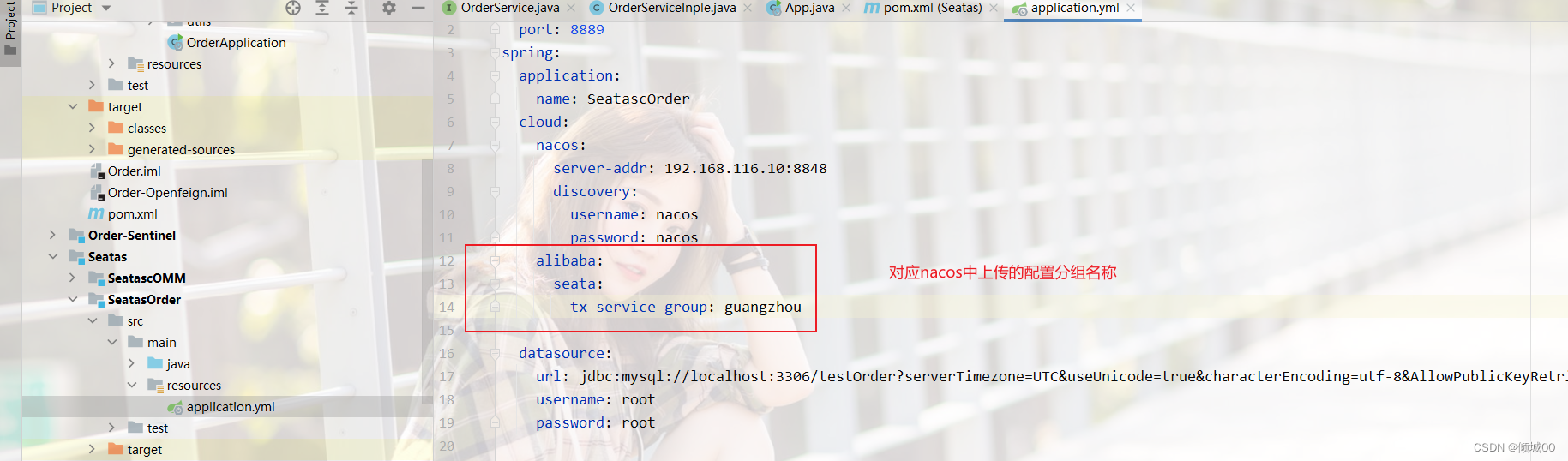
alibaba:
seata:
tx-service-group: guangzhou
- 接下来让客户端,去连接seata的服务端,两个都配置和配置读取配置文件
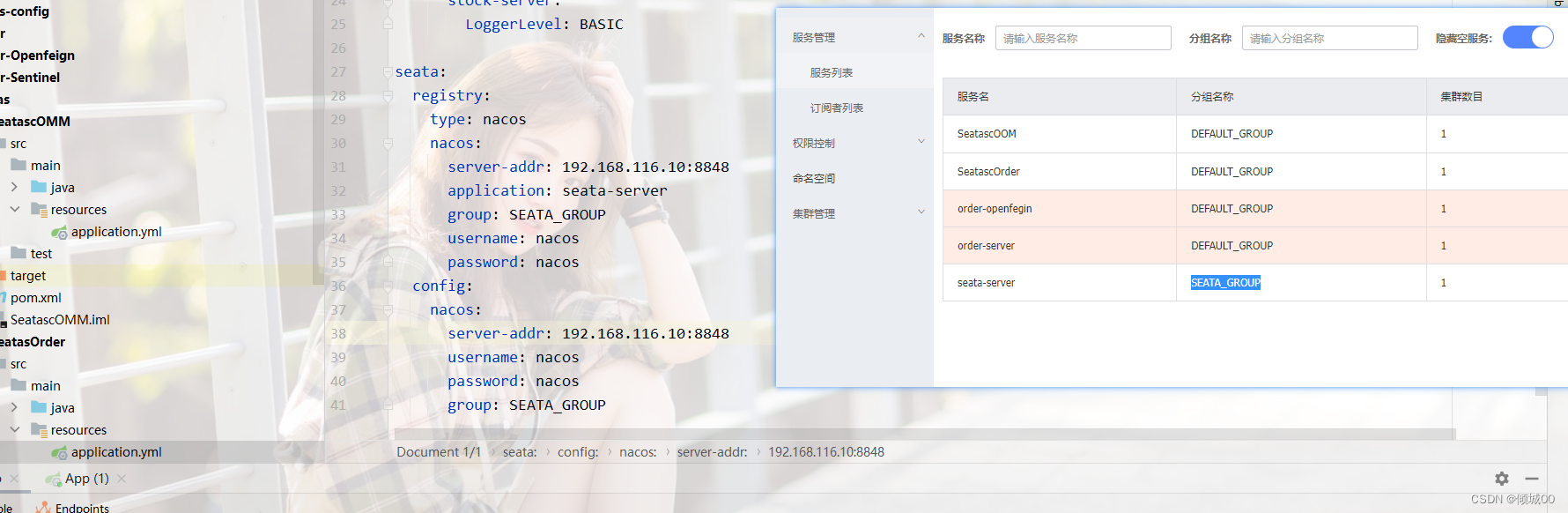
seata:
registry:
type: nacos
nacos:
server-addr: 192.168.116.10:8848
application: seata-server
group: SEATA_GROUP
username: nacos
password: nacos
config:
type: nacos
nacos:
server-addr: 192.168.116.10:8848
username: nacos
password: nacos
group: SEATA_GROUP
.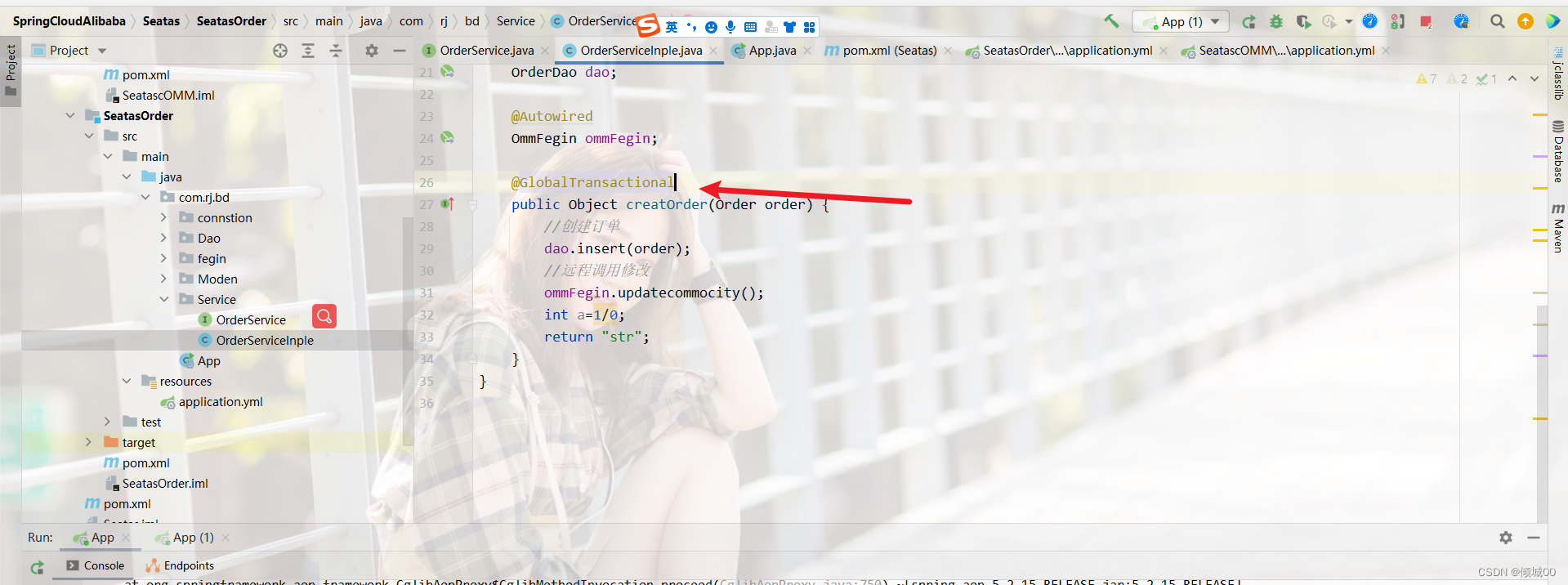
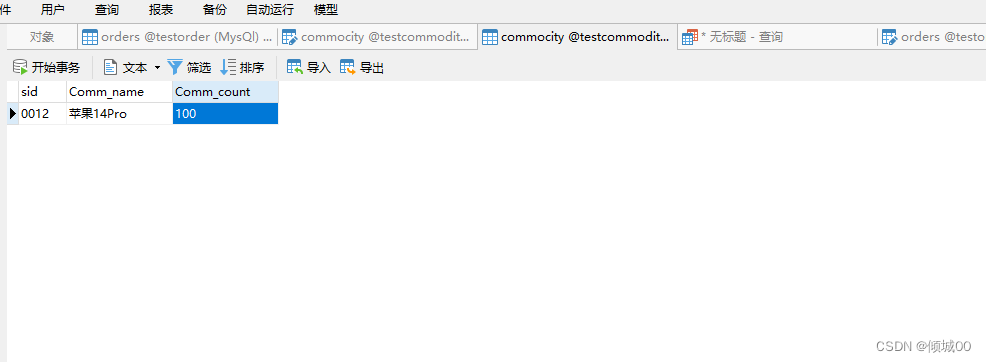
- 分布式事务成功,全部回滚了
13.9.9 Seate的分布式生命周期和原理
- TM请求TC开启一个全局事务,TC会生成一个XID作为全局事务的编号,XID,会在微服务的调用链路下传播,保证多个微服务的子事务关联在一起
- RM请求TC将本地事务注册为全局事务的分支事务,通过全局事务的XID进行关联
- TM请求TC告诉XID对应的全局事务是应该进行提交还是回滚
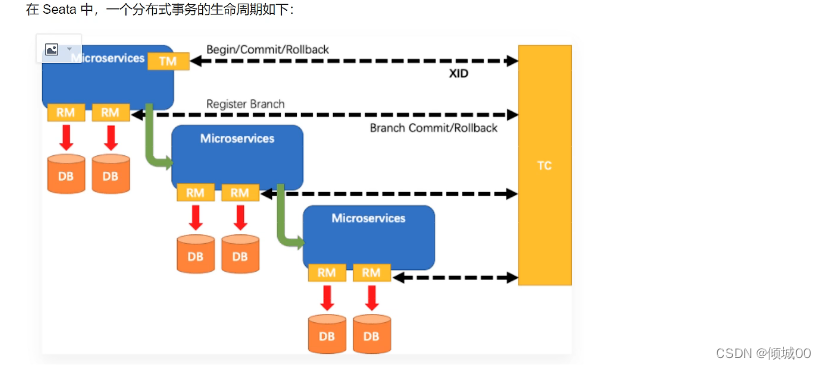

-
刚进入到程序中会产生一个全局的事务id
-
如果有多个事务的话就是有多个XID,通过XID去隔离起来的

-
每次执行一个数据库操作就会产生一个分支信息在这个表中进行记录那个类的什么数据

-
每次执行数据库产生分支信息还会产生锁表信息,锁的那个表,主键是多少,这样保证了数据的隔离性,不会别的客户操作这个数据去影响到他
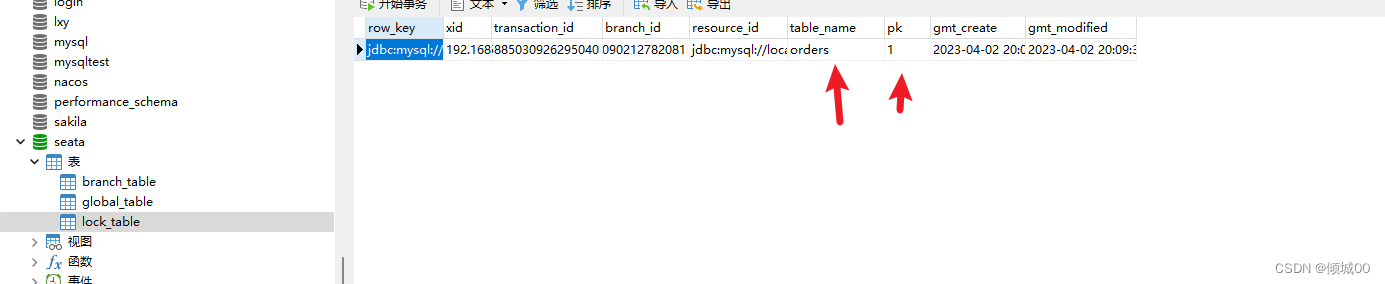
-现在端点打在了异常之前发现订单数据是插入了(因为还没有发生异常),现在是解析了sql,已经执行了sql将之前的元数据和之后的元数据都存储在了下面的表中,
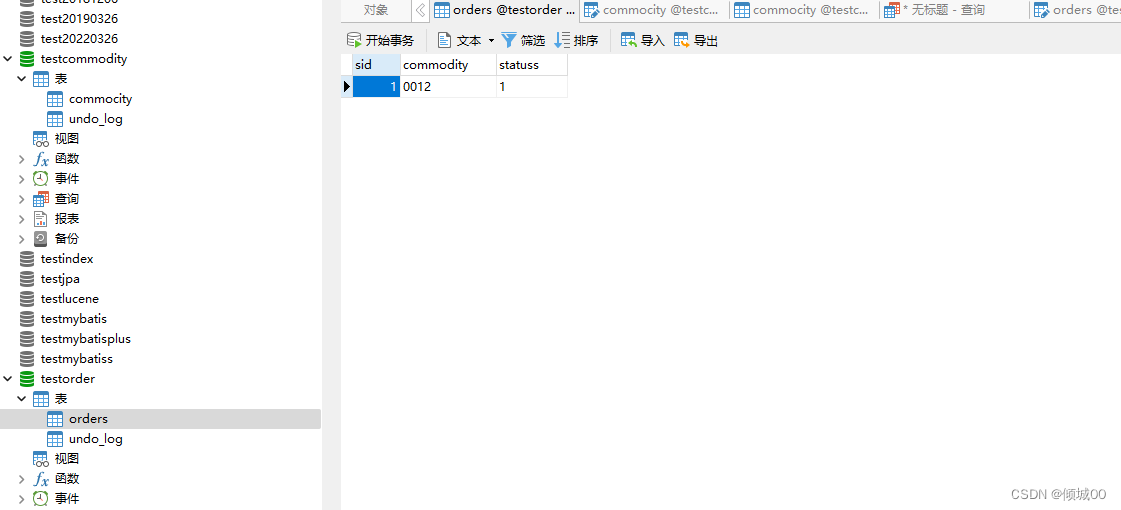
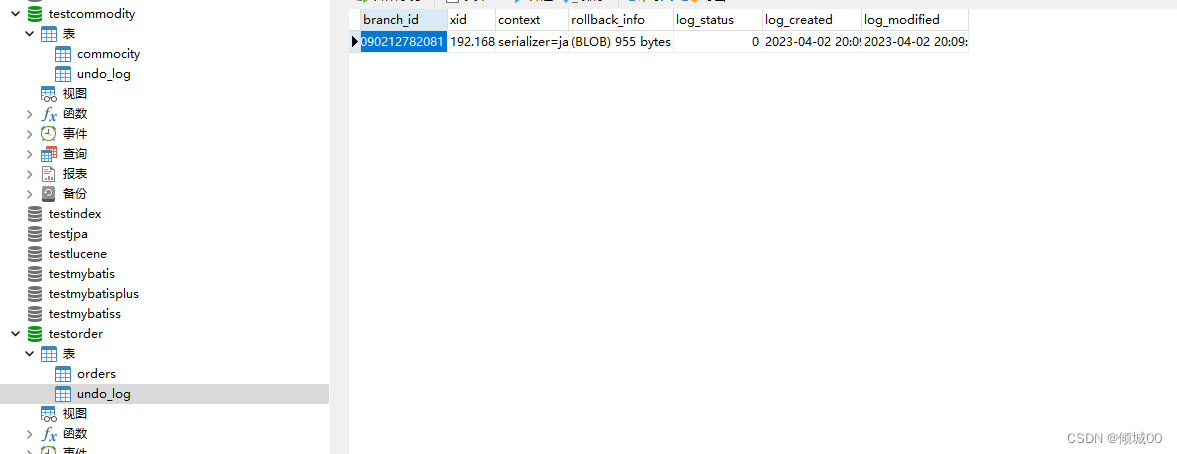
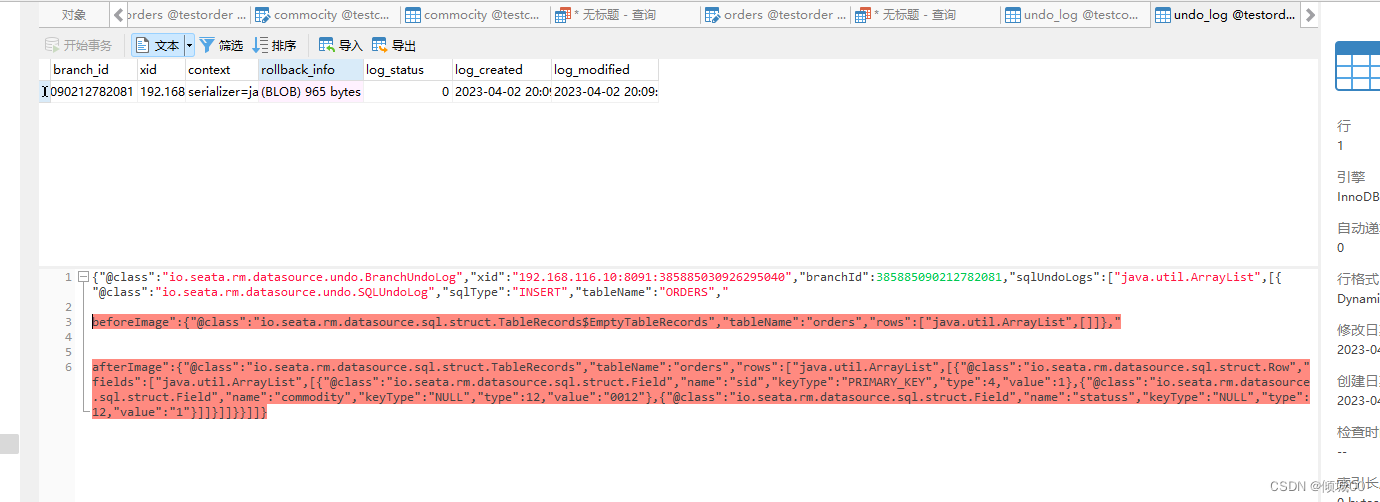
- 现在执行异常发生数据回滚了,之前插入的数据已经没了,发生了异常之后用undo_log中保存的元数据进行回滚,发生异常提交之前的数据,没有发生异常就提交之后的数据,执行流程就是这样的
13.10 getway
- 之前有讲过直接上实践
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>SpringCloudAlibaba</artifactId>
<groupId>com.bj.sh</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>getway</artifactId>
<dependencies>
<!-- <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
</dependencies>
</project>
- yml
server:
port: 8888
spring:
application:
name: getway-api
cloud:
gateway:
routes: #断言规则
- id: order_flow #路由的唯一表示
uri: http://127.0.0.1:8108 #转发到哪里去
#http://127.0.0.1:8888/getwayflow/api/flower 路由成
#http://127.0.0.1:8108/api/flower
predicates:
- Path=/getwayflow/api/**
filters: #
- StripPrefix=1 # 转发之前去掉1层路径/getwayflow
13.10.1 getway整合nacos
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
server:
port: 8888
spring:
application:
name: getway-api
cloud:
gateway:
routes: #断言规则
- id: order_flow #路由的唯一表示
uri: lb://order-Sentinel #转发到哪里去 lb的意思是负载均衡的访问
#http://127.0.0.1:8888/getwayflow/api/flower 路由成
#http://127.0.0.1:8108/api/flower
predicates:
- Path=/getwayflow/api/**
filters: #
- StripPrefix=1 # 转发之前去掉1层路径/getwayflow
13.10.1 请求日志配置
-Dreactor.netty.http.server.accessLogEnabled=true
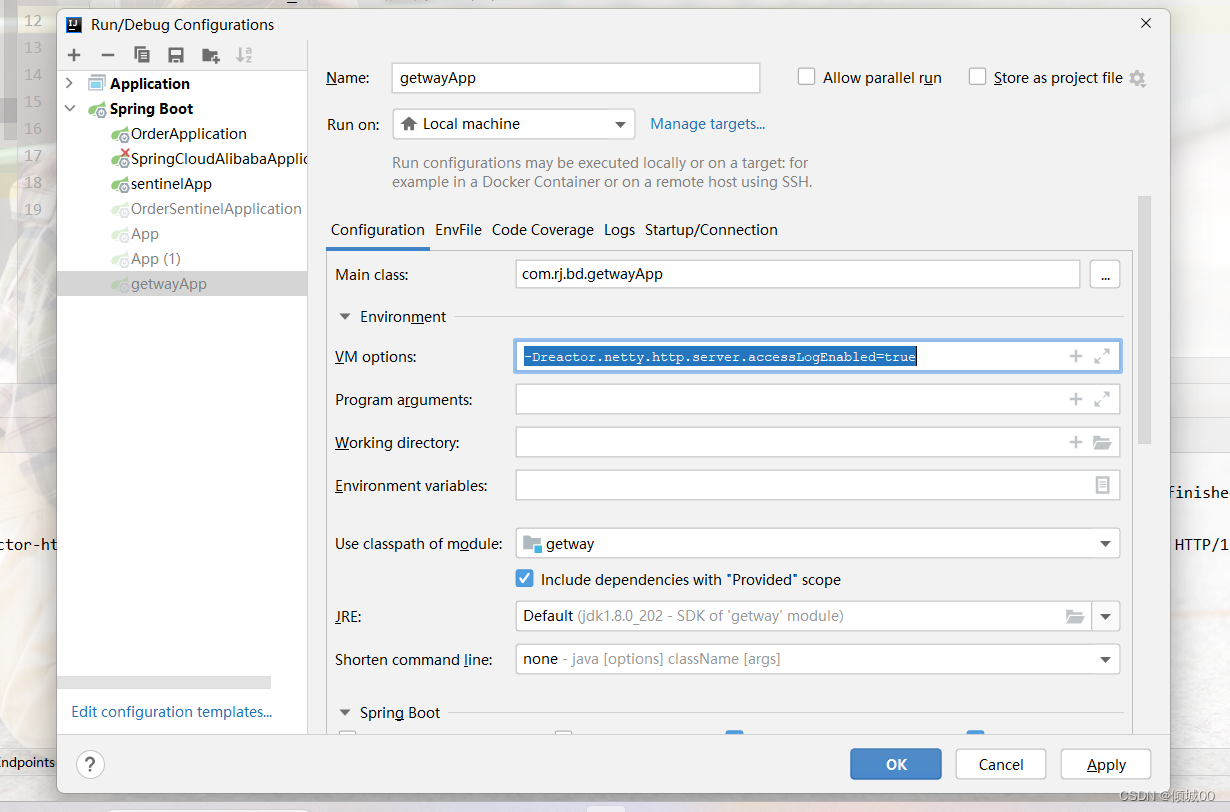

13.10.2 Sentinel 整合getway
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId>
</dependency>
<!-- Sentinel降级规则-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
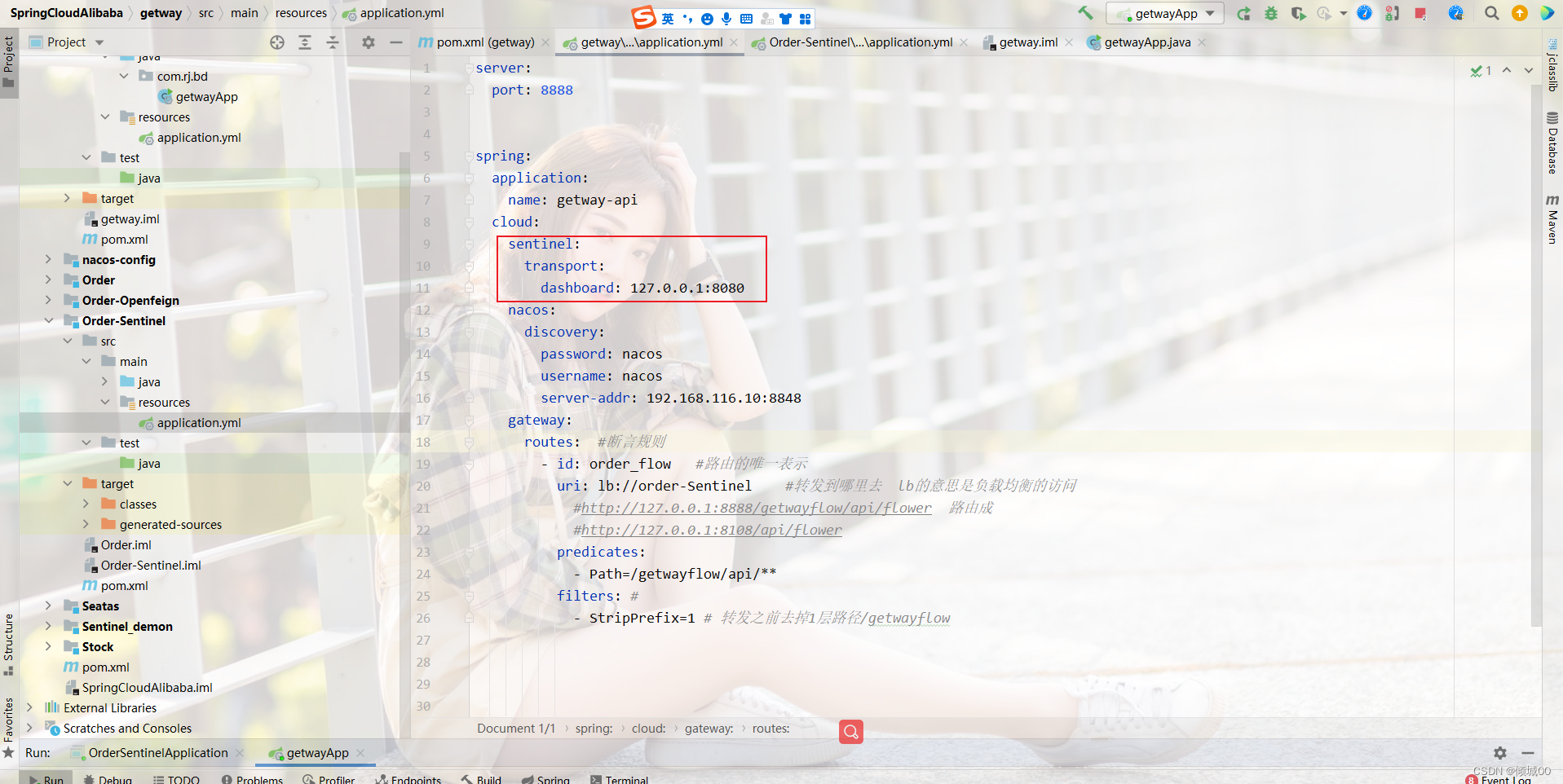
sentinel:
transport:
dashboard: 127.0.0.1:8080
- 这样显示的就是路由的唯一id,对路由进行流控
- 先简单的试一下
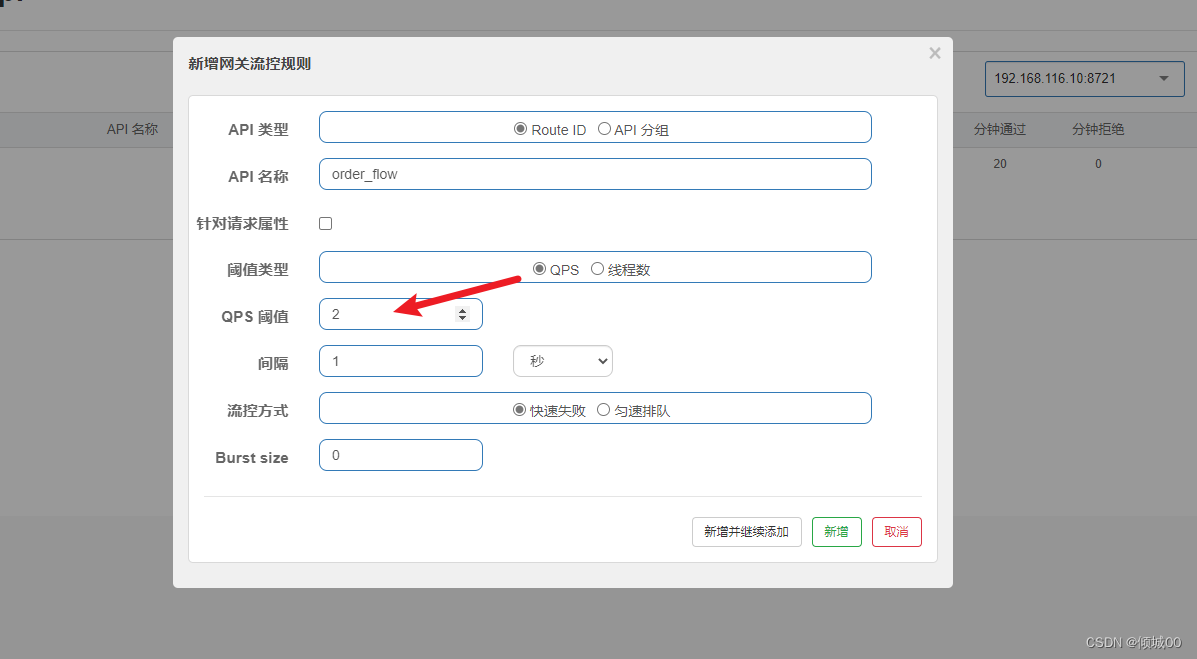
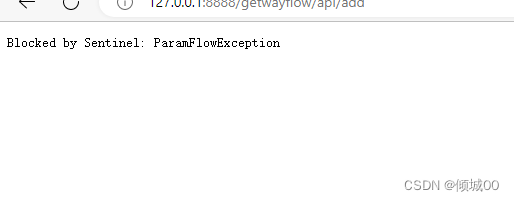
- 这里可以设置几秒钟的阈值,下图就是3秒钟超过3次就QPS
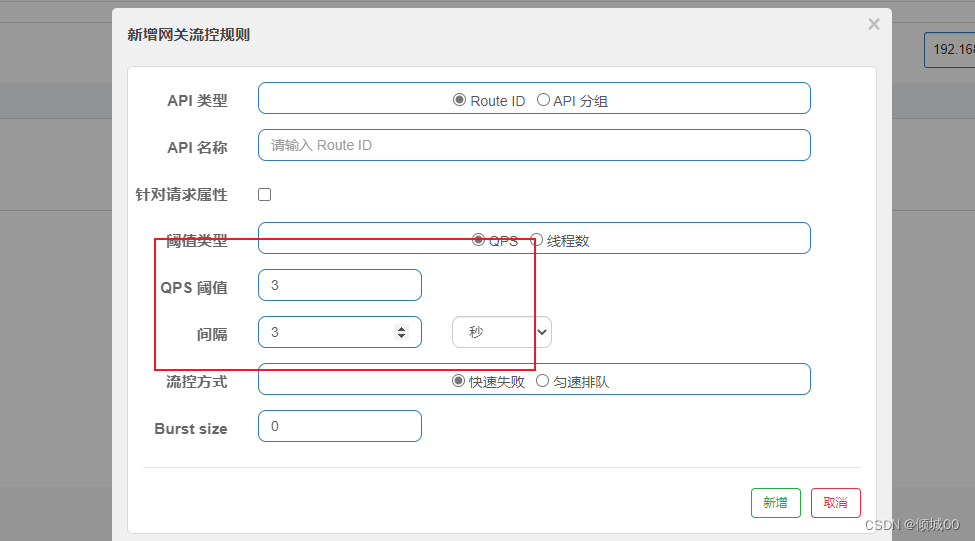
- 这个设置是宽容的意思,意思就是3秒钟超所3次QPS但是我让他宽容2次,就是3秒钟5次在QPS
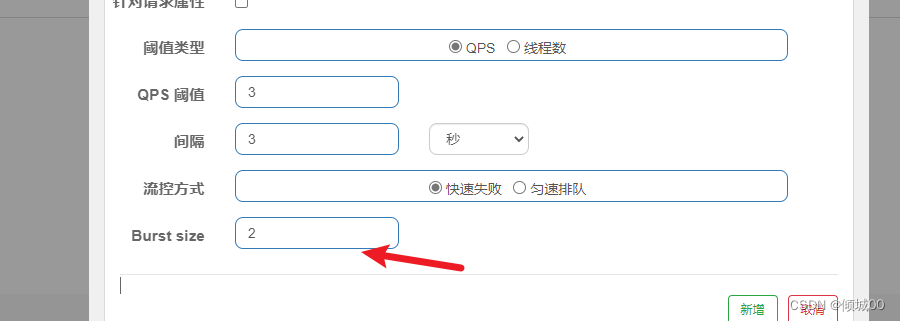
- 还可以通过ip进行控制
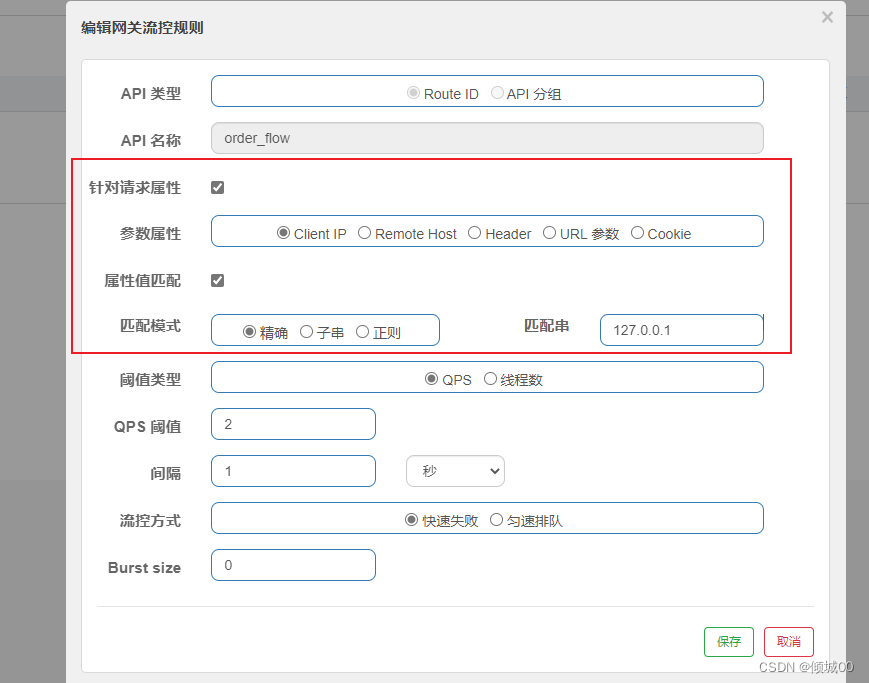
- 设置为1的话,1开头的都会进行流控
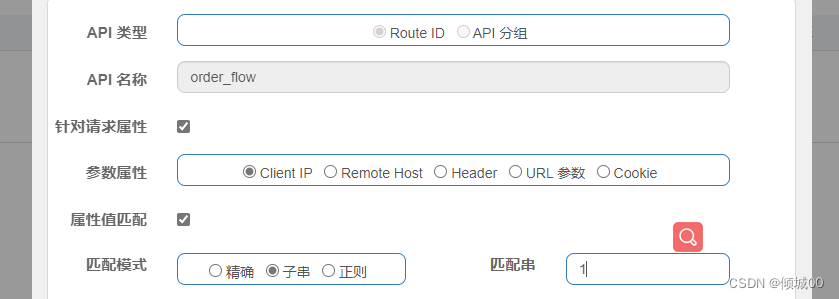
- 还能设置请求头,域名,url参数,cookle进行限流
13.10.3 Sentinel 整合getway自定义异常
package com.rj.bd.config.getway;
import com.alibaba.csp.sentinel.adapter.gateway.sc.callback.BlockRequestHandler;
import com.alibaba.csp.sentinel.adapter.gateway.sc.callback.GatewayCallbackManager;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.web.reactive.function.BodyInserters;
import org.springframework.web.reactive.function.server.ServerResponse;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import javax.annotation.PostConstruct;
import java.util.HashMap;
/**
* @author LXY
* @desc
* @time 2023--04--02--22:39
*/
@Configuration
public class config {
@PostConstruct
public void init(){
System.out.println("init is start ");
BlockRequestHandler blockRequestHandler = new BlockRequestHandler() {
public Mono<ServerResponse> handleRequest(ServerWebExchange serverWebExchange, Throwable throwable) {
// 自定义异常处理
HashMap<String, String> map = new HashMap<>();
map.put("code", "10099");
map.put("message", "服务器忙,请稍后再试!");
return ServerResponse.status(HttpStatus.OK)
.contentType(MediaType.APPLICATION_JSON)
.body(BodyInserters.fromValue(map));
}
};
GatewayCallbackManager.setBlockHandler(blockRequestHandler);
}
}

或者是在yml文件中配置
spring:
cloud:
sentinel:
scg:
fallback:
mode: response
response-body: "{'code':'10099', 'message': '服务器忙,请稍后再试!'}"
13.11 SkyWalking 链路追踪
官网: https://skywalking.apache.org/
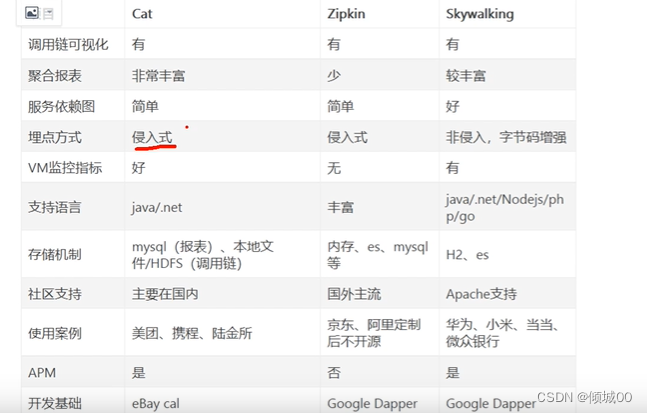
- 下载 skywalking
- https://skywalking.apache.org/downloads/

- tar.gz文件进行加压如下
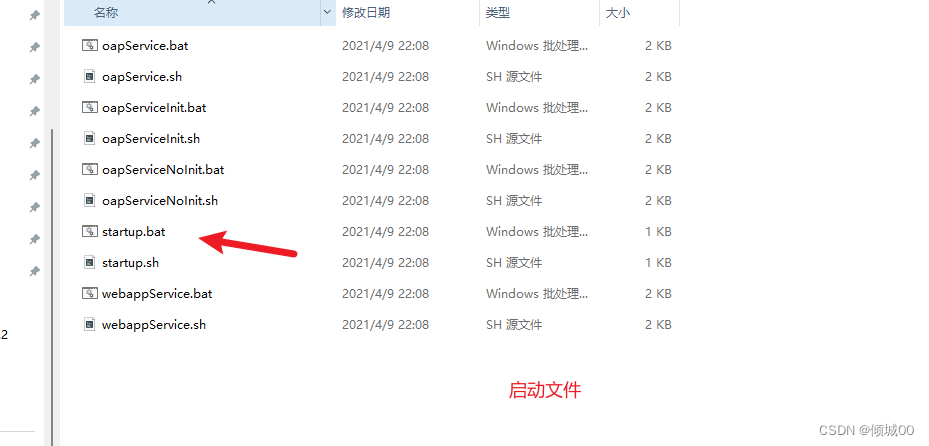 -
- - 双击启动,他还会同时运行这两个文件一个是监控收集服务
- webapp目录下是运行的前端的ui和所需要的jar包,修改ui启动端口
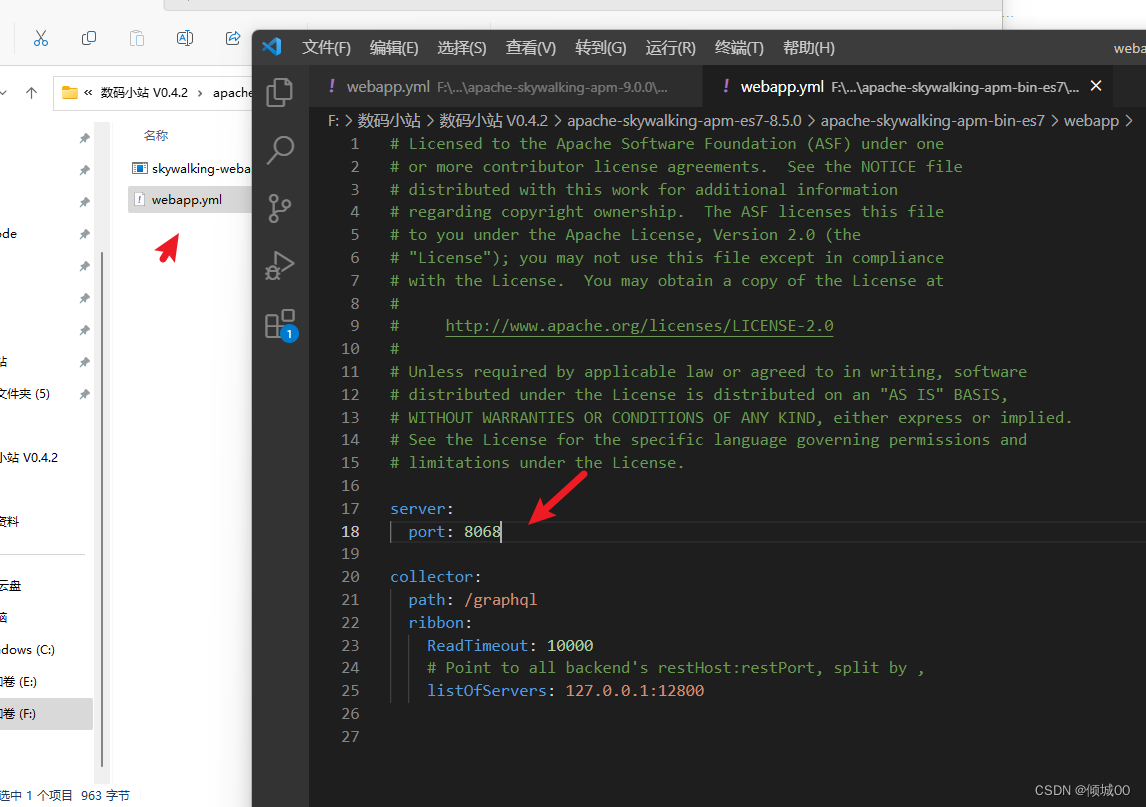
- oap-libs下是程序运行所需要的jar包
- config配置文件就是存放的常用的配置文件了
- 主要是修改这个h2的存储方式,h2是内存存储的意思就是重启就会没了,到时候会修改为mysql,也可以用es
- agent目录是需要和服务进行绑定的,这个jar包需要和微服务进行绑定
- 直接去bin目录去启动文件,不能有中文目录,有中文目录会启动失败会报错
- 启动的时候,不会再控制台输出日志,入职会输出在logs文件下
- 启动成功之后会启动两个服务,一个是skywalking-ope-server和skywalking-web-ui:8868
- skywalking-ope-server启动成功之后会暴露两个端口,11800和12800两个端口,分别为
监控收集数据的端口11800和接口前段请求的12800 - 修改端口可以修改config/applocation.yml
- 浏览监控数据,直接输入8868
13.11.1 SkyWalking 接入多个微服务
sykwalking跨多个微服务跟踪,只需要启动时添加javaagent即可
- 启动seata,sentelen,nacos,启动订单项目,启动商品库存项目,启动getway,让getwat可以通过代理去进行转发下单
- 项目启动的时候携带jvm参数
# skywalking-agent.jar 的本地磁盘路径
-javaagent:F:\tool\apache-skywalking-apm-es7-8.5.0\apache-skywalking-apm-bin-es7\agent\skywalking-agent.jar
# 在 skywalking 上显示的服务名,服务名是自定义的作为展示
-DSW_AGENT_NAME=api-gateway
# skywalking 的 collector 服务的IP及端口
-DSW_AGENT_COLLECTOR_BACKEND_SERVICES=127.0.0.1:11800
-
输入好jvm参数之后浏览访问一下getway和order的接口,然后访问skywaliking,就可以看到如下的数据
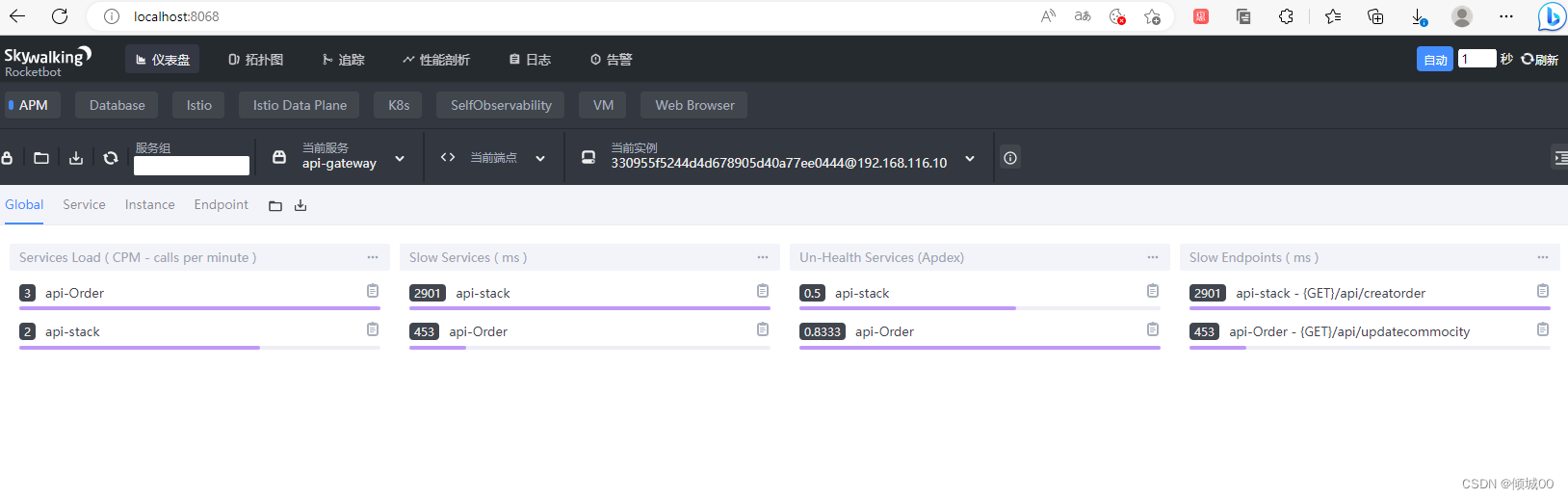
-
我们可以通过拓扑图看到访问关系
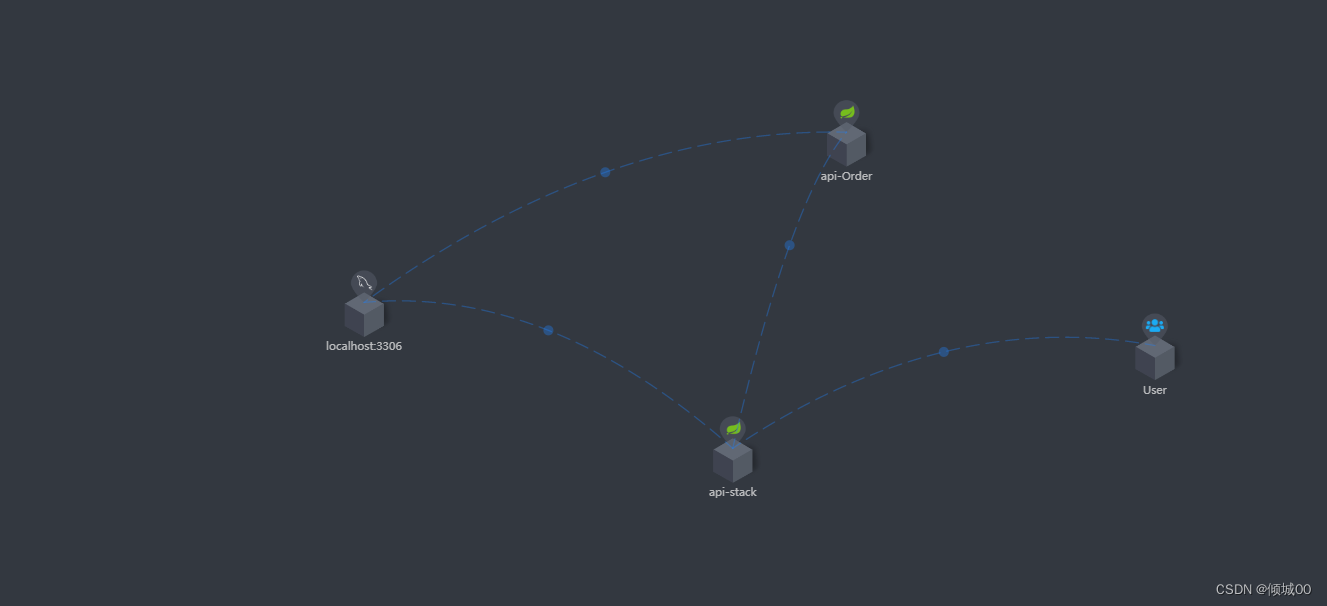
-
通过追踪如果接口出现异常了可以更加精确的发现是哪个接口出错了
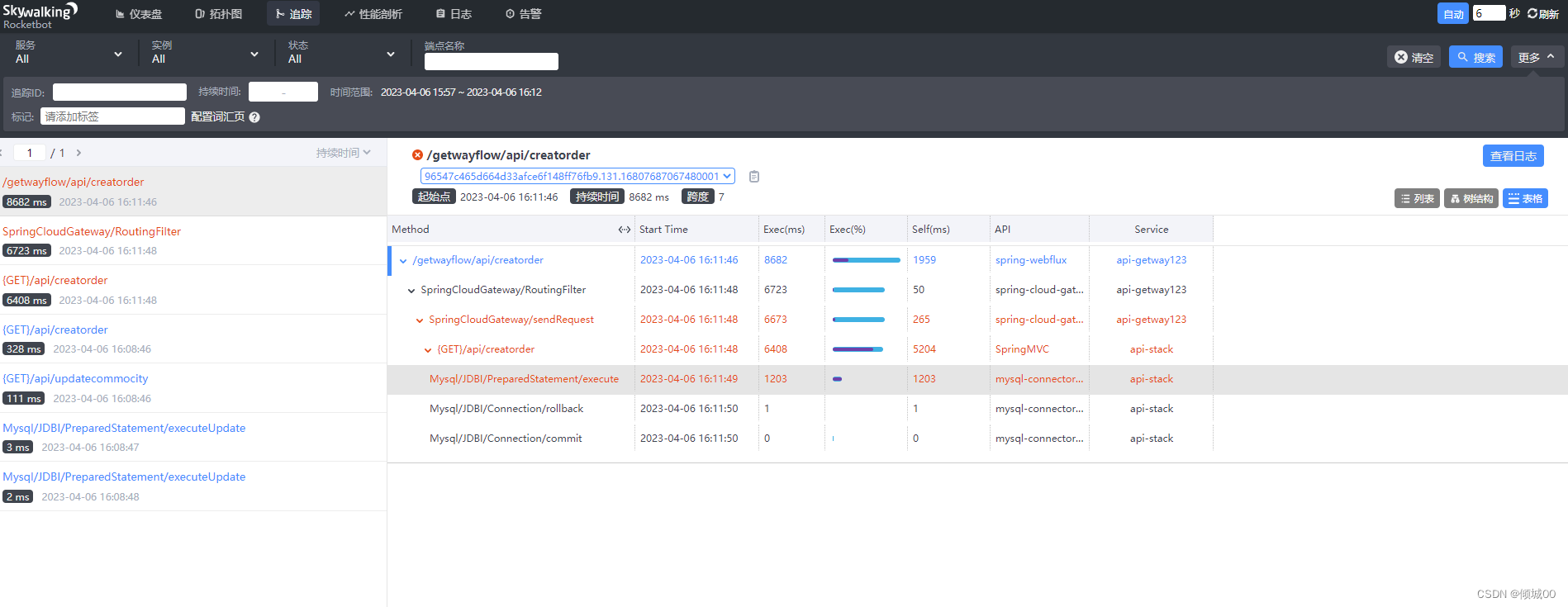
-
但是现在是有bug的,默认是不显示getway的服务,
-
在这个文件下下都是支持的jar包,但是你找不到getway的服务
-
复制这个路径下的这个jar包
-
复制过来之后重启服务
在进行访问,就可以看到getway了
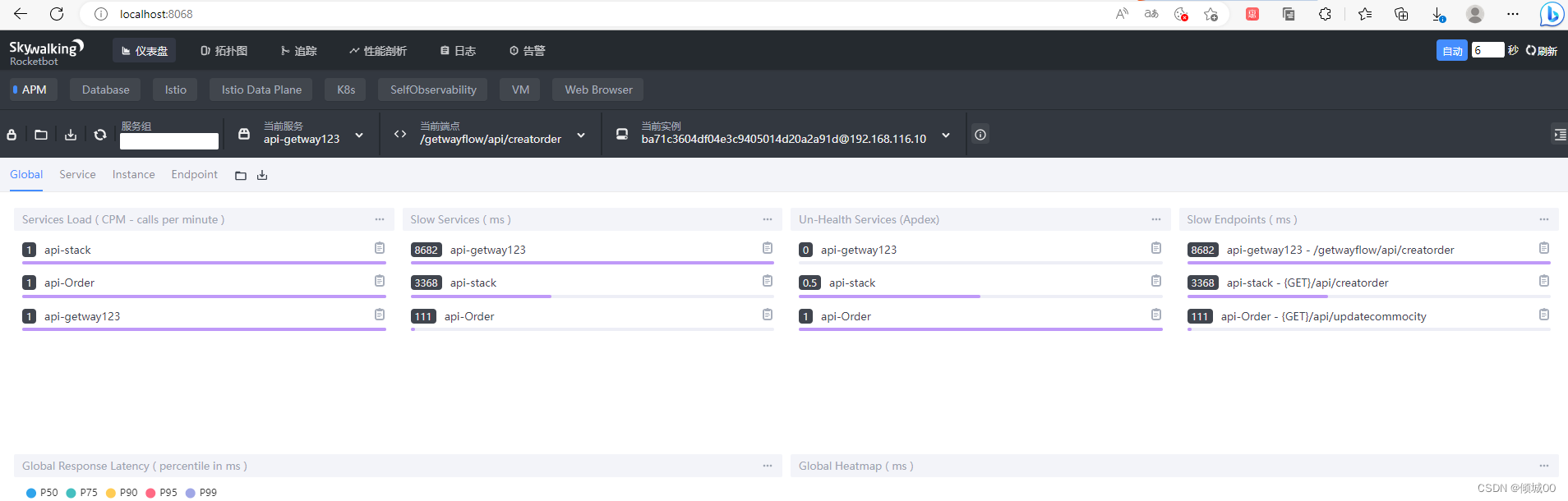
13.11.2 SkyWalking 持久化数据

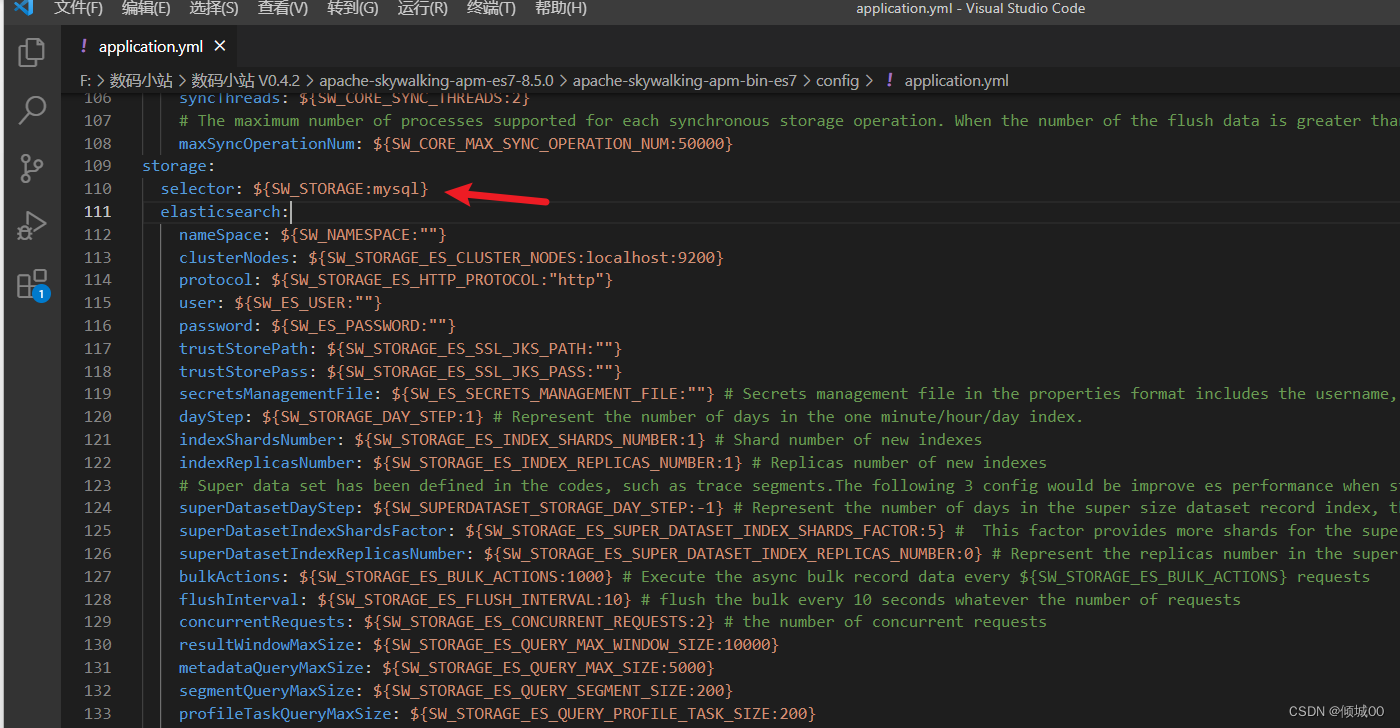
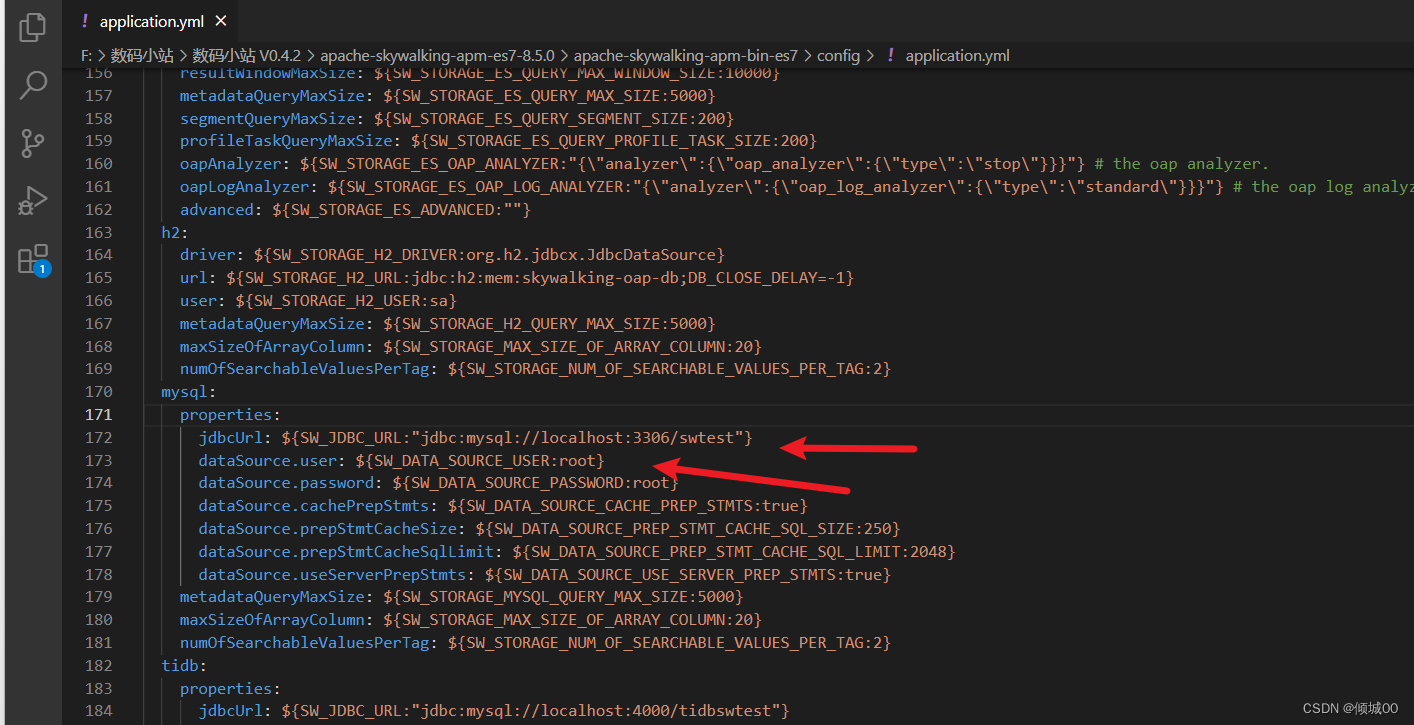
- 创建一个swtest数据库,表启动的时候就会自动创建,重启一下,在项目中找到mysql驱动,放到这个文件夹下
- 会自动生成表
- 再次重启数据还是有的
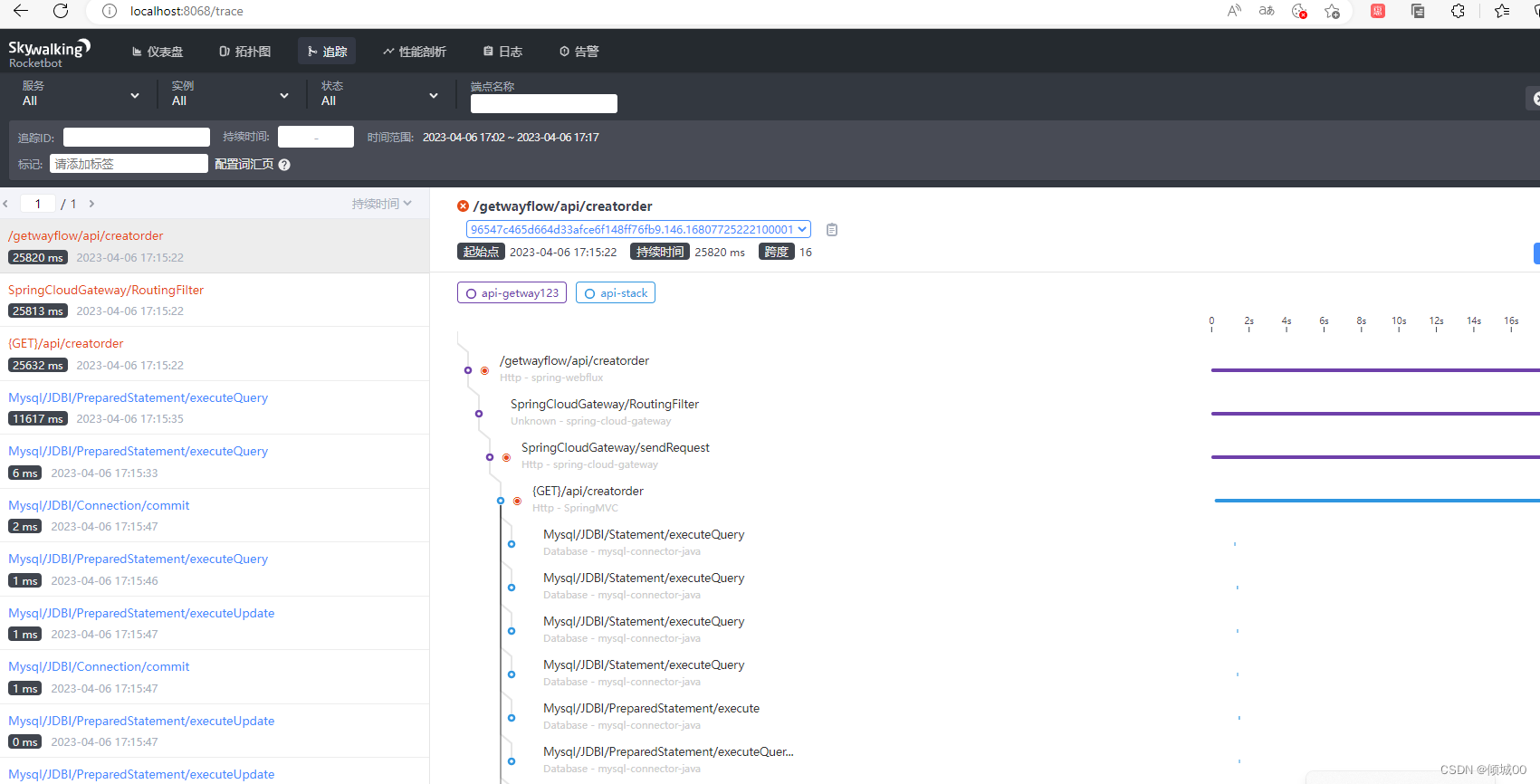
13.11.3 SkyWalking 自定义
- 可以查看到调用方法,返回值,传参信息等等
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>8.5.0</version>
</dependency>
@Trace //这个注解会看到调用的方法
@Tags({ @Tag(key = "creatOrder",value = "returnedobj"),
@Tag(key = "creatOrder",value = "arg[0]")}
)
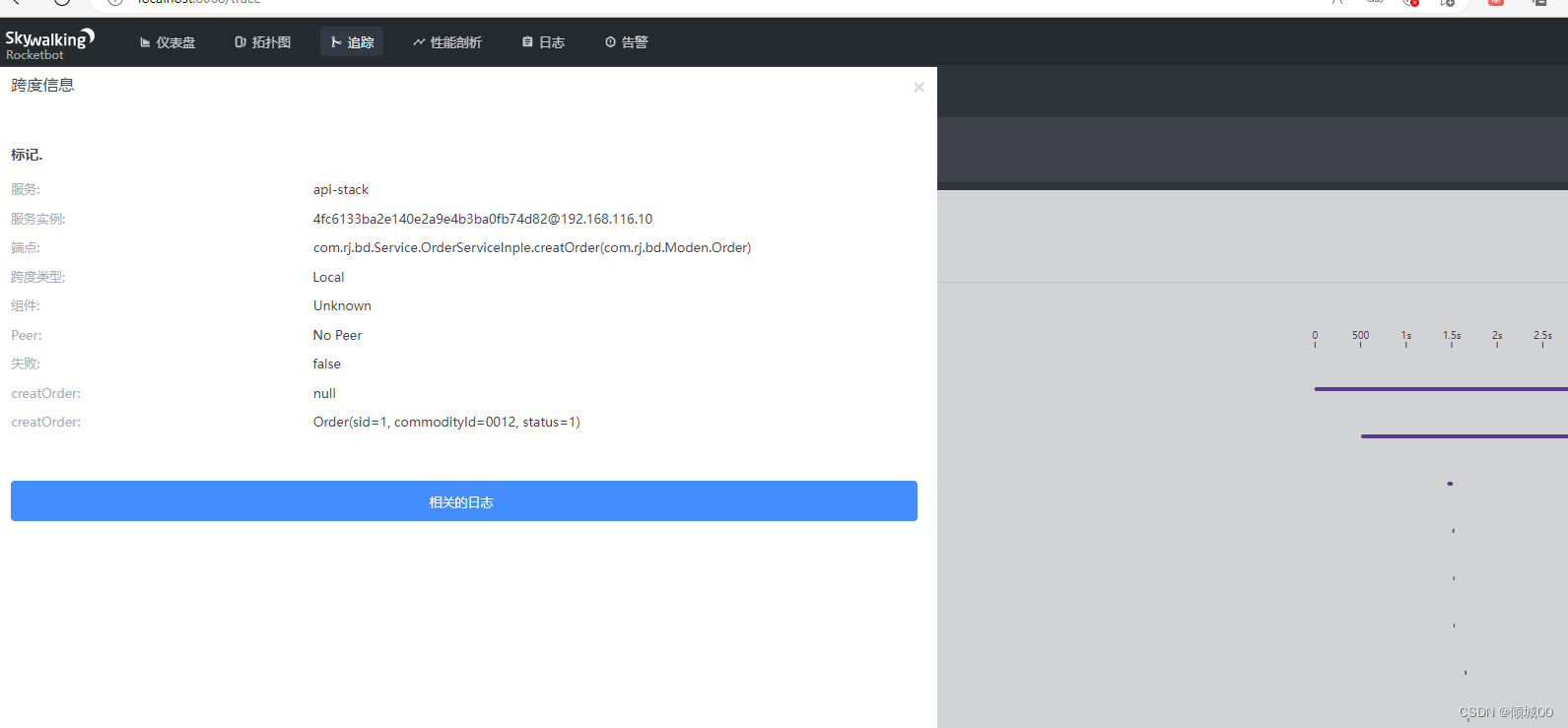
13.11.4 SkyWalking 的性能监控
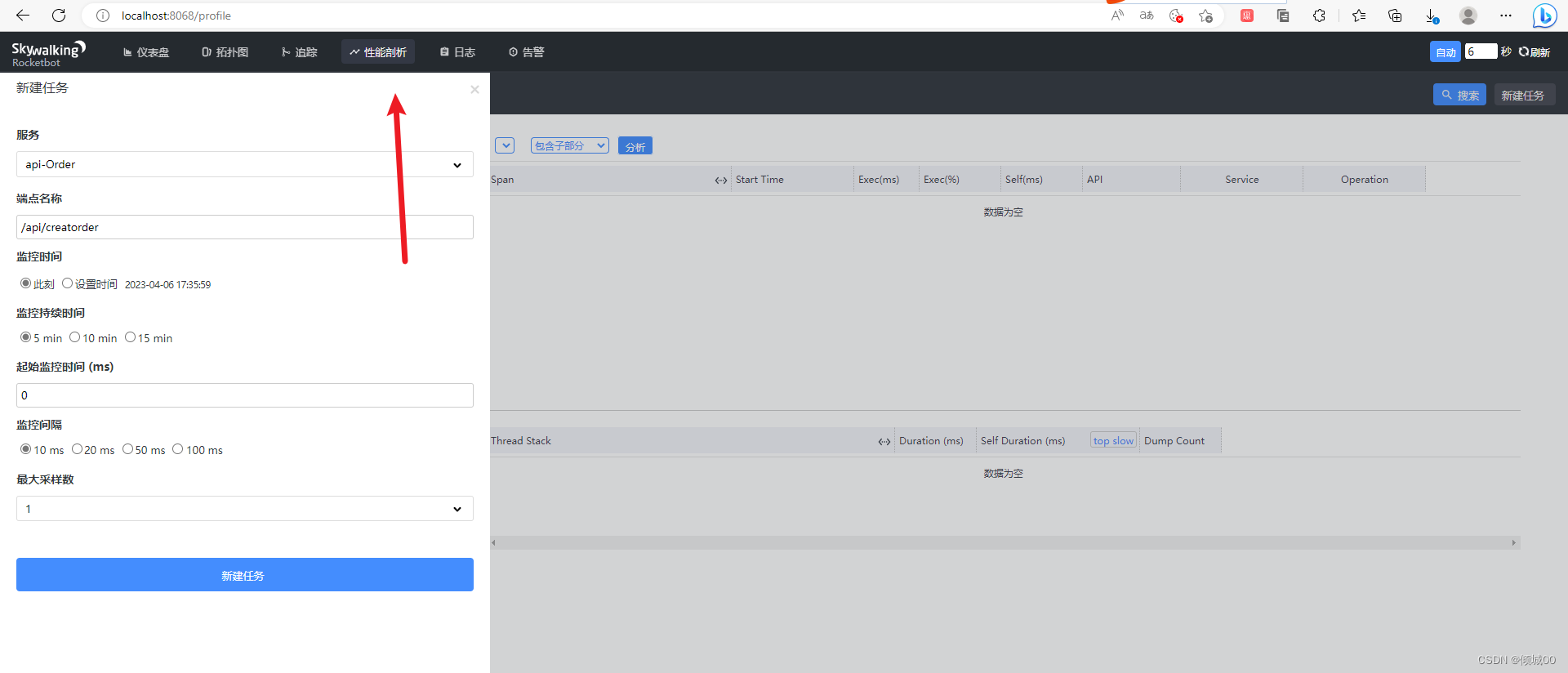
-告诉
- 告警功能