Lambda表达式
如果不适用lambda表达式的话,可以使用匿名内部类,但是代码会显得有点多
lambda表达式其实就是匿名内部类
Lambda表达式简化了匿名内部类的使用,语法更加简单。
语法规则
(参数类型 参数名称) -> {
代码体;
}Lambda表达式使用的接口只能有一个抽象方法,可以使用@FunctionalInterface修饰
Lambda表达式本质
1. Lambda表达式在程序运行的时候会形成一个类
2. 在类中新增了一个方法,这个方法的方法体就是Lambda表达式中的代码
3. 还会形成一个匿名内部类,实现接口,重写抽象方法
4. 在重写的方法中,会调用新生成的方法
XJad:反编译工具,可以查看生成的代码
Lambda表达式省略写法
1. 小括号内的参数类型可以省略
2. 如果小括号内有且仅有一个参数,则小括号可以省略
3. 如果大括号内有且仅有一个语句,可以同时省略大括号,return 关键字及语句分号。
Lambda表达式的使用前提
1. 方法的参数或局部变量类型必须为接口才能使用Lambda
2. 接口中有且仅有一个抽象方法(@FunctionalInterface)
Lambda表达式和匿名内部类的区别
-
所需类型不一样
-
匿名内部类的类型可以是 类,抽象类,接口
-
Lambda表达式需要的类型必须是接口
-
-
抽象方法的数量不一样
-
匿名内部类所需的接口中的抽象方法的数量是随意的
-
Lambda表达式所需的接口中只能有一个抽象方法
-
-
实现原理不一样
-
匿名内部类是在编译后形成一个class
-
Lambda表达式是在程序运行的时候动态生成class
-
Jdk8中接口改变
jdk8之前,接口中只能有静态常量和抽象方法;
jdk8之后,接口中可以有静态方法和默认方法;
默认方法
为什么要新增默认方法
如果没有默认方法,一个接口中新增一个抽象方法,所有实现类都必须重写该方法,不利于接口的扩展
默认方法使用default修饰
如果实现类没有重写默认方法,也可以直接调用接口中的默认方法
实现类也可以重写默认方法,这样调用的就是重写方法了
静态方法
静态方法也是为了接口扩展
静态方法不能被实现类重写,只能通过接口类型直接调用
函数式接口
使用Lambda表达式的前提是需要有函数式接口,而Lambda表达式使用时不关心接口名,抽象方法名。只关心抽象方法的参数列表和返回值类型。
为了更好的使用Lambda表达式,在JDK中提供了大量常用的函数式接口
Supplier
无参,有返回值
需要提供一个返回值类型T
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}Consumer
有参无返回值
需要提供一个泛型来定义参数类型
@FunctionalInterface
public interface Consumer<T> {
void accept(T var1);
default Consumer<T> andThen(Consumer<? super T> var1) {
Objects.requireNonNull(var1);
return (var2) -> {
this.accept(var2);
var1.accept(var2);
};
}
}consumer有一个默认方法andThen
如果一个方法的参数和返回值全部是Consumer类型,那么就可以实现效果,消费一个数据的时候,首先做一个操作,然后再做一个操作,实现组合,而这个方法就是Consumer接口中的default方法 andThen方法
Function
有参有返回值
T是参数,R是返回值
@FunctionalInterface
public interface Function<T, R> {
R apply(T var1);
default <V> Function<V, R> compose(Function<? super V, ? extends T> var1) {
Objects.requireNonNull(var1);
return (var2) -> {
return this.apply(var1.apply(var2));
};
}
default <V> Function<T, V> andThen(Function<? super R, ? extends V> var1) {
Objects.requireNonNull(var1);
return (var2) -> {
return var1.apply(this.apply(var2));
};
}
static <T> Function<T, T> identity() {
return (var0) -> {
return var0;
};
}
}andThen用于组合操作
compose方法的作用顺序和andThen方法刚好相反
静态方法identity,输入什么参数就返回什么参数
Predicate
有参,且返回值为boolean
@FunctionalInterface
public interface Predicate<T> {
boolean test(T var1);
default Predicate<T> and(Predicate<? super T> var1) {
Objects.requireNonNull(var1);
return (var2) -> {
return this.test(var2) && var1.test(var2);
};
}
default Predicate<T> negate() {
return (var1) -> {
return !this.test(var1);
};
}
default Predicate<T> or(Predicate<? super T> var1) {
Objects.requireNonNull(var1);
return (var2) -> {
return this.test(var2) || var1.test(var2);
};
}
static <T> Predicate<T> isEqual(Object var0) {
return null == var0 ? Objects::isNull : (var1) -> {
return var0.equals(var1);
};
}
}方法引用
在lambda表达式中进行其他方法调用
public class YinYong {
public static void main(String[] args) {
testTotal(arr -> total(arr) );
}
public static void total(int[] arr){
int sum = 0;
for(int i: arr){
sum += i;
}
System.out.println("sum:" + sum);
}
public static void testTotal(Consumer<int[]> consumer){
int arr[] = {1,2,3,4,5};
consumer.accept(arr);
}
}使用方法引用可以简写为:
public class YinYong2 {
public static void main(String[] args) {
testTotal(YinYong2::total);
}
public static void total(int[] arr){
int sum = 0;
for(int i: arr){
sum += i;
}
System.out.println("sum:" + sum);
}
public static void testTotal(Consumer<int[]> consumer){
int arr[] = {1,2,3,4,5};
consumer.accept(arr);
}
}方法引用应用场景
如果Lambda表达式所要实现的方案,已经有其他方法存在相同的方案,那么则可以使用方法引用。
方法引用的使用方式
instanceName::methodName 对象::方法名
Date date2 = new Date(2021,10,9);
Supplier<Integer> dateSup = date2::getYear;
Integer year = dateSup.get();
System.out.println(year);ClassName::staticMethodName 类名::静态方法
ClassName::methodName 类名::普通方法
// Function<String, Integer>中,String是参数类型,Integer是返回值类型
Function<String, Integer> function = String::length;
Integer length = function.apply("abcd");
System.out.println(length);
// BiFunction<String, Integer, String>中第一个String是BiFunction的apply方法的第一个参数hello
// Integer是apply方法的第二个参数3
// String 是返回值str
BiFunction<String, Integer, String> substringFunction = String::substring;
String str = substringFunction.apply("hello", 3);
System.out.println(str);ClassName::new 类名::new 调用的构造器
Supplier<LocalDate> now = LocalDate::now;
LocalDate localDate = now.get();
System.out.println(localDate);由于构造器的名称和类名完全一致,所以构造器引用使用::new的格式使用
// Long是Date的构造函数的参数类型,Date是构造函数返回值
Function<Long, Date> dateFunction = Date::new;
Date date = dateFunction.apply(123456789110L);
System.out.println(date);TypeName[]::new String[]::new 调用数组的构造器
// Integer是数组长度
Function<Integer, String[]> stringArr = String[]::new;
String[] strArr = stringArr.apply(5);方法引用是对Lambda表达式符合特定情况下的一种缩写方式,它使得我们的Lambda表达式更加的精简
Stream
没有stream之前,要对集合元素进行处理,就需要一遍遍的循环处理,很麻烦,代码量也比较大
这里的stream流和IO流没有任何关系
Stream流不是一种数据结构,不保存数据,而是对数据进行加工处理
获取stream流
通过Collection获取
Collection接口下的所有的实现都可以通过steam方法来获取Stream流,因为java.util.Collection 接口中加入了default方法 stream
List<String> list = new ArrayList<>();
list.stream();
Set<String> set = new HashSet<>();
set.stream();Map没有实现Collection接口,不能直接获取stream流,只能获取key、value或者entry的stream流
通过Stream的of方法
获取数组的stream流(基本数据类型的数组是不可以的int[])
String[] arr = {"a","b","c"};
Stream.of(arr);Stream流常用方法
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
|---|---|---|---|
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
终结方法:返回值类型不再是 Stream 类型的方法,不再支持链式调用。本小节中,终结方法包括 count 和forEach 方法。
非终结方法:返回值类型仍然是 Stream 类型的方法,支持链式调用。(除了终结方法外,其余方法均为非终结方法。)
Stream注意事项(重要)
-
Stream只能操作一次
-
Stream方法返回的是新的流
-
Stream不调用终结方法,中间的操作不会执行
forEach方法
/**
* Performs an action for each element of this stream.
*
* <p>This is a <a href="package-summary.html#StreamOps">terminal
* operation</a>.
*
* <p>The behavior of this operation is explicitly nondeterministic.
* For parallel stream pipelines, this operation does <em>not</em>
* guarantee to respect the encounter order of the stream, as doing so
* would sacrifice the benefit of parallelism. For any given element, the
* action may be performed at whatever time and in whatever thread the
* library chooses. If the action accesses shared state, it is
* responsible for providing the required synchronization.
*
* @param action a <a href="package-summary.html#NonInterference">
* non-interfering</a> action to perform on the elements
*/
void forEach(Consumer<? super T> action);对流中的元素进行遍历
// 打印list中的元素
list.stream().forEach(System.out::println);count
count方法用来统计其中的元素个数的
/**
* Returns the count of elements in this stream. This is a special case of
* a <a href="package-summary.html#Reduction">reduction</a> and is
* equivalent to:
* <pre>{@code
* return mapToLong(e -> 1L).sum();
* }</pre>
*
* <p>This is a <a href="package-summary.html#StreamOps">terminal operation</a>.
*
* @return the count of elements in this stream
*/
long count(); long count = list.stream().count();filter
filter方法的作用是用来过滤数据的,返回符合条件的数据
可以通过filter方法将一个流转换成另一个子集流
/**
* Returns a stream consisting of the elements of this stream that match
* the given predicate.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @param predicate a <a href="package-summary.html#NonInterference">non-interfering</a>,
* <a href="package-summary.html#Statelessness">stateless</a>
* predicate to apply to each element to determine if it
* should be included
* @return the new stream
*/
Stream<T> filter(Predicate<? super T> predicate); // 返回list中包含a的元素并打印出来
list.stream().filter(s-> s.contains("a")).forEach(System.out::println);limit
limit方法可以对流进行截取处理,只取前n个数据
/**
* Returns a stream consisting of the elements of this stream, truncated
* to be no longer than {@code maxSize} in length.
*
* <p>This is a <a href="package-summary.html#StreamOps">short-circuiting
* stateful intermediate operation</a>.
*
* @apiNote
* While {@code limit()} is generally a cheap operation on sequential
* stream pipelines, it can be quite expensive on ordered parallel pipelines,
* especially for large values of {@code maxSize}, since {@code limit(n)}
* is constrained to return not just any <em>n</em> elements, but the
* <em>first n</em> elements in the encounter order. Using an unordered
* stream source (such as {@link #generate(Supplier)}) or removing the
* ordering constraint with {@link #unordered()} may result in significant
* speedups of {@code limit()} in parallel pipelines, if the semantics of
* your situation permit. If consistency with encounter order is required,
* and you are experiencing poor performance or memory utilization with
* {@code limit()} in parallel pipelines, switching to sequential execution
* with {@link #sequential()} may improve performance.
*
* @param maxSize the number of elements the stream should be limited to
* @return the new stream
* @throws IllegalArgumentException if {@code maxSize} is negative
*/
Stream<T> limit(long maxSize);如果集合当前长度大于参数就进行截取,否则不操作
// 返回list中前5个元素并打印出来
list.stream().limit(5).forEach(System.out::println);skip
skip方法用于跳过前n个元素
/**
* Returns a stream consisting of the remaining elements of this stream
* after discarding the first {@code n} elements of the stream.
* If this stream contains fewer than {@code n} elements then an
* empty stream will be returned.
*
* <p>This is a <a href="package-summary.html#StreamOps">stateful
* intermediate operation</a>.
*
* @apiNote
* While {@code skip()} is generally a cheap operation on sequential
* stream pipelines, it can be quite expensive on ordered parallel pipelines,
* especially for large values of {@code n}, since {@code skip(n)}
* is constrained to skip not just any <em>n</em> elements, but the
* <em>first n</em> elements in the encounter order. Using an unordered
* stream source (such as {@link #generate(Supplier)}) or removing the
* ordering constraint with {@link #unordered()} may result in significant
* speedups of {@code skip()} in parallel pipelines, if the semantics of
* your situation permit. If consistency with encounter order is required,
* and you are experiencing poor performance or memory utilization with
* {@code skip()} in parallel pipelines, switching to sequential execution
* with {@link #sequential()} may improve performance.
*
* @param n the number of leading elements to skip
* @return the new stream
* @throws IllegalArgumentException if {@code n} is negative
*/
Stream<T> skip(long n); // 跳过list中前5个元素,并打印后面的元素
list.stream().skip(5).forEach(System.out::println);map
map方法可以将流中的元素映射到另一个流中
/**
* Returns a stream consisting of the results of applying the given
* function to the elements of this stream.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @param <R> The element type of the new stream
* @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>,
* <a href="package-summary.html#Statelessness">stateless</a>
* function to apply to each element
* @return the new stream
*/
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
将T类型的数据转换为R类型的数据
// 将list中所有元素拼接上abc并打印
list.stream().map(s-> s+"abc").forEach(System.out::println);sorted
sorted方法用于排序
/**
* Returns a stream consisting of the elements of this stream, sorted
* according to natural order. If the elements of this stream are not
* {@code Comparable}, a {@code java.lang.ClassCastException} may be thrown
* when the terminal operation is executed.
*
* <p>For ordered streams, the sort is stable. For unordered streams, no
* stability guarantees are made.
*
* <p>This is a <a href="package-summary.html#StreamOps">stateful
* intermediate operation</a>.
*
* @return the new stream
*/
Stream<T> sorted();
/**
* Returns a stream consisting of the elements of this stream, sorted
* according to the provided {@code Comparator}.
*
* <p>For ordered streams, the sort is stable. For unordered streams, no
* stability guarantees are made.
*
* <p>This is a <a href="package-summary.html#StreamOps">stateful
* intermediate operation</a>.
*
* @param comparator a <a href="package-summary.html#NonInterference">non-interfering</a>,
* <a href="package-summary.html#Statelessness">stateless</a>
* {@code Comparator} to be used to compare stream elements
* @return the new stream
*/
Stream<T> sorted(Comparator<? super T> comparator); // 将list中的数据进行排序
list.stream().sorted().forEach(System.out::println);
// 根据Comparator进行排序(字符串长度倒序)
list.stream().sorted((o1,o2)-> o2.length() - o1.length()).forEach(System.out::println);distinct
distinct方法用于去除重复数据
/**
* Returns a stream consisting of the distinct elements (according to
* {@link Object#equals(Object)}) of this stream.
*
* <p>For ordered streams, the selection of distinct elements is stable
* (for duplicated elements, the element appearing first in the encounter
* order is preserved.) For unordered streams, no stability guarantees
* are made.
*
* <p>This is a <a href="package-summary.html#StreamOps">stateful
* intermediate operation</a>.
*
* @apiNote
* Preserving stability for {@code distinct()} in parallel pipelines is
* relatively expensive (requires that the operation act as a full barrier,
* with substantial buffering overhead), and stability is often not needed.
* Using an unordered stream source (such as {@link #generate(Supplier)})
* or removing the ordering constraint with {@link #unordered()} may result
* in significantly more efficient execution for {@code distinct()} in parallel
* pipelines, if the semantics of your situation permit. If consistency
* with encounter order is required, and you are experiencing poor performance
* or memory utilization with {@code distinct()} in parallel pipelines,
* switching to sequential execution with {@link #sequential()} may improve
* performance.
*
* @return the new stream
*/
Stream<T> distinct(); // 去除list中重复元素
list.stream().distinct().forEach(System.out::println);Stream流中的distinct方法对于基本数据类型是可以直接出重的,但是对于自定义类型,需要重写hashCode和equals方法来移除重复元素。
match
match方法用于判断数据是否匹配指定的条件
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate); // 判断list中是否所有元素都包含a
boolean a = list.stream().allMatch(s -> s.contains("a"));
// 判断list中是否有元素包含a
boolean a2 = list.stream().anyMatch(s -> s.contains("a"));
// 判断list中是否所有元素都不包含a
boolean a3 = list.stream().noneMatch(s -> s.contains("a"));find
find方法用于查找某些数据
Optional<T> findFirst();
Optional<T> findAny(); // 获取list中第一个元素
Optional<String> first = list.stream().findFirst();
System.out.println(first.get());
// 获取list中任意元素
Optional<String> any = list.stream().findAny();
System.out.println(any.get());max
获取最大值
/**
* Returns the maximum element of this stream according to the provided
* {@code Comparator}. This is a special case of a
* <a href="package-summary.html#Reduction">reduction</a>.
*
* <p>This is a <a href="package-summary.html#StreamOps">terminal
* operation</a>.
*
* @param comparator a <a href="package-summary.html#NonInterference">non-interfering</a>,
* <a href="package-summary.html#Statelessness">stateless</a>
* {@code Comparator} to compare elements of this stream
* @return an {@code Optional} describing the maximum element of this stream,
* or an empty {@code Optional} if the stream is empty
* @throws NullPointerException if the maximum element is null
*/
Optional<T> max(Comparator<? super T> comparator); // 获取list中最大值
Optional<String> max = list.stream().max((Comparator.comparingInt(Integer::parseInt)));
System.out.println(max.get());min
获取最小值
/**
* Returns the minimum element of this stream according to the provided
* {@code Comparator}. This is a special case of a
* <a href="package-summary.html#Reduction">reduction</a>.
*
* <p>This is a <a href="package-summary.html#StreamOps">terminal operation</a>.
*
* @param comparator a <a href="package-summary.html#NonInterference">non-interfering</a>,
* <a href="package-summary.html#Statelessness">stateless</a>
* {@code Comparator} to compare elements of this stream
* @return an {@code Optional} describing the minimum element of this stream,
* or an empty {@code Optional} if the stream is empty
* @throws NullPointerException if the minimum element is null
*/
Optional<T> min(Comparator<? super T> comparator); // 获取list中最小值
Optional<String> min = list.stream().min((Comparator.comparingInt(Integer::parseInt)));
System.out.println(min.get());reduce
reduce方法将所有数据归纳得到一个数据
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner); // 将list中所有元素拼接起来,x的初始值是identity的值,后面x的值是上一次的计算结果
// y的值是list中的每个元素
String pinjie = list.stream().reduce("", (x, y) -> x + y);
// 获取list中长度最长的元素
String maxLength = list.stream().reduce("", (x, y) -> x.length() > y.length() ? x : y);reduce方法经常和map方法一起使用
先使用map方法把数据转换成想要的格式,再使用reduce进行处理
// 获取list中最长元素的长度
list.stream().map(x -> x.length()).reduce(0, (x,y) -> x > y ? x : y);mapToInt
将集合中的包装类型转换为基本数据类型,提高程序代码的效率
IntStream mapToInt(ToIntFunction<? super T> mapper);
LongStream mapToLong(ToLongFunction<? super T> mapper);
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper); List<Integer> integerList = Arrays.asList(1,2,3,4,5);
// 将List<Integer>中的Integer转成int类型
integerList.stream().mapToInt(s -> s.intValue()).forEach(System.out::println);
integerList.stream().map(s -> s.intValue()).forEach(System.out::println);
OptionalInt min1 = integerList.stream().mapToInt(Integer::valueOf).min();
System.out.println(min1.getAsInt());
// 会报错
// OptionalInt min2 = integerList.stream().map(Integer::valueOf).min();concat
将2个流合并为1个流
/**
* Creates a lazily concatenated stream whose elements are all the
* elements of the first stream followed by all the elements of the
* second stream. The resulting stream is ordered if both
* of the input streams are ordered, and parallel if either of the input
* streams is parallel. When the resulting stream is closed, the close
* handlers for both input streams are invoked.
*
* @implNote
* Use caution when constructing streams from repeated concatenation.
* Accessing an element of a deeply concatenated stream can result in deep
* call chains, or even {@code StackOverflowException}.
*
* @param <T> The type of stream elements
* @param a the first stream
* @param b the second stream
* @return the concatenation of the two input streams
*/
public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator<T> split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator<T>) a.spliterator(), (Spliterator<T>) b.spliterator());
Stream<T> stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return stream.onClose(Streams.composedClose(a, b));
} // 将两个list的流合并为一个新的流
Stream.concat(list.stream(), integerList.stream()).forEach(System.out::println);数据收集到集合中
// 将list中的数据流手机到Set<Integer>中
Set<Integer> setList = integerList.stream().collect(Collectors.toSet());
// 将list中的数据流手机到List<Integer>中
List<Integer> integers = integerList.stream().collect(Collectors.toList());
// 将list中的数据流手机到指定类型的集合中ArrayList中
ArrayList<String> strList = integerList.stream().map(s -> s + "a").collect(Collectors.toCollection(ArrayList::new));
数据收集到数组中
// 将数据收集到Object数组中
Object[] objArr = integerList.stream().toArray();
// 将数据收集到String数组中
String[] strArr = integerList.stream().toArray(String[]::new);聚合
// 求和
Integer sum = list.stream().collect(Collectors.summingInt(Integer::valueOf));
// 平均值
Double avg = list.stream().collect(Collectors.averagingInt(Integer::valueOf));
// 总量
Long count2 = list.stream().collect(Collectors.counting());分组操作
根据某个属性,对数据进行分组
List<Person> list = new ArrayList<>();
list.add(new Person(1, "tom", 12));
list.add(new Person(2, "tina", 18));
list.add(new Person(3, "tom", 19));
list.add(new Person(4, "bob", 21));
list.add(new Person(5, "tom", 21));
// 根据name进行分组
Map<String, List<Person>> nameMap = list.stream().collect(Collectors.groupingBy(Person::getName));
// 根据年龄分组 >=18一组,没满18一组
Map<String, List<Person>> ageMap = list.stream().collect(Collectors.groupingBy(p -> p.getAge() >= 18 ? "1" : "0"));
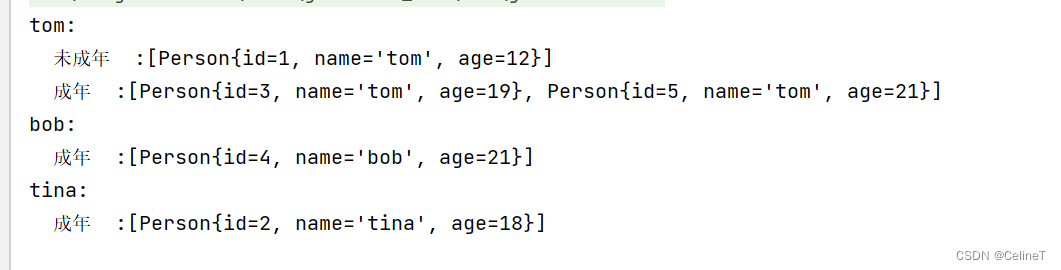
// 多级分组,先根据name分组,再根据成年未成年分组
Map<String, Map<String, List<Person>>> group = list.stream().collect(Collectors.groupingBy(Person::getName,
Collectors.groupingBy(p -> p.getAge() >= 18 ? "成年" : "未成年")));
group.forEach((k,v)->{
System.out.println(k+":");
v.forEach((k2,v2)->{
System.out.println(" " + k2 + " :"+v2);
});
});
class Person{
private int id;
private String name;
private int age;
public Person(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
分区操作
Collectors.partitioningBy会根据值是否为true,把集合中的数据分割为两个列表,一个true列表,一个false列表
// 根据是否成员分区
Map<Boolean, List<Person>> agePart = list.stream().collect(Collectors.partitioningBy(p -> p.getAge() >= 18));
agePart.forEach((k,v)->{
System.out.println(k+":"+ v);
});
拼接
Collectors.joining会根据指定的连接符,将所有的元素连接成一个字符串
// 将list中所有id拼接起来:12345
String ids = list.stream().map(p -> String.valueOf(p.getId())).collect(Collectors.joining());
// 将list中所有id通过-拼接起来:1-2-3-4-5
String ids2 = list.stream().map(p -> String.valueOf(p.getId())).collect(Collectors.joining("-"));
// 将list中所有id加前缀、后缀和拼接符拼接起来 @1-2-3-4-5#
String ids3 = list.stream().map(p -> String.valueOf(p.getId())).collect(Collectors.joining("-", "@","#"));
并行流
前面写的都是串行流,在一个线程执行
parallelStream其实就是一个并行执行的流,它通过默认的ForkJoinPool,可以提高多线程任务的速度。
获取并行流
List<String> list = Arrays.asList("a","b","c");
// 获取并行流的两种方式
Stream<String> stringStream = list.parallelStream();
Stream<String> parallel = list.stream().parallel();使用并行流可能会有数据安全问题
解决方案
-
加同步锁
-
使用线程安全的容器
-
通过Stream中的toArray/collect操作
Optional
Optional是一个没有子类的工具类,Optional是一个可以为null的容器对象,它的主要作用就是为了避免Null检查,防止NullpointerException
String str = "";
/* 获取optional对象 */
// of方法不能传入null值,会报NPE
Optional<String> op1 = Optional.of(str);
// ofNullable能传入null值
Optional<String> op2 = Optional.ofNullable(str);
// 通过empty方法直接创建一个空的Optional对象
Optional<Object> op3 = Optional.empty();
/* isPresent */
// 判断op1中是否有值
if(op1.isPresent()){
// 获取op1中的值,如果为空会报错,所以需要使用isPresent进行判断
String s1 = op1.get();
}
/* orElse */
// 如果op1中是空值,那么返回值是xxx;如果op1中本来有值,那么返回值是原值
String s2 = op1.orElse("xxx");
/* orElseGet */
// 如果op1中是空值,那么返回值是lambda表达式返回值
String s3 = op1.orElseGet(() -> "Hello");
/* ifPresent */
// 如果op1中有值,做lambda表达式中的操作
op1.ifPresent((s)->{
System.out.println(s);
});
// 获取Person中的name,并将name转为大写,person和name都有可能为空
Person1 person1 = new Person1();
Optional<Person1> op4 = Optional.of(person1);
if(op4.isPresent()){
String s4 = op4.map(Person1::getName)
.map(String::toUpperCase)
.orElse("");
System.out.println("s4:"+s4);
}
日期
老的日期存在的问题
java.util.Date是线程不安全的,
构造方法的year是从1990年开始的

没有时区支持
LocalDate、LocalTime、LocalDateTime常见用法
// 根据年月日生成LocalDate
LocalDate localDate = LocalDate.of(2023,12,31);
// 获取当前日期
LocalDate now = LocalDate.now();
// 生成指定的LocalTime
LocalTime localTime = LocalTime.of(13, 45, 56, 123456789);
// 获取当前时间
LocalTime now1 = LocalTime.now();
// 根据LocalDate和LocalTime生成时间
LocalDateTime localDateTime = LocalDateTime.of(now, now1);
// 生成指定的LocalDateTime
LocalDateTime localDateTime1 = LocalDateTime.of(2021, 11, 22, 9, 59, 23, 2345);
// 获取当前时间
LocalDateTime now2 = LocalDateTime.now();
int year = now2.getYear();
int month = now2.getMonthValue();
int day = now2.getDayOfMonth();
int week = now2.getDayOfWeek().getValue();
int hour = now2.getHour();
int minute = now2.getMinute();
int second = now2.getSecond();
int nano = now2.getNano();
System.out.println("year:" + year);
System.out.println("month:" + month);
System.out.println("day:" + day);
System.out.println("week:" + week);
System.out.println("hour:" + hour);
System.out.println("minute:" + minute);
System.out.println("second:" + second);
System.out.println("nano:" + nano);
/* 修改日期 */
// 修改localDateTime1的year为1998,生成一个新的对象,不会更改老对象的值
LocalDateTime localDateTime2 = localDateTime1.withYear(1998);
// 对日期时间进行加减
// 对localDateTime1加2天
LocalDateTime localDateTime3 = localDateTime1.plusDays(2);
// 对localDateTime1减3年
LocalDateTime localDateTime4 = localDateTime1.minusYears(3);
LocalDateTime localDateTime5 = localDateTime1.plusYears(-3);
Assert.assertEquals(localDateTime4,localDateTime5);
/* 比较日期 */
// 判断localDateTime2是否大于localDateTime3
boolean isAfter = localDateTime2.isAfter(localDateTime3);
// 判断localDateTime4是否小于localDateTime5
boolean isBefore = localDateTime4.isBefore(localDateTime5);
// 判断localDateTime4是否等于localDateTime5
boolean isEqual = localDateTime4.isEqual(localDateTime5);时间格式化、解析
LocalDateTime now = LocalDateTime.now();
// 将LocalDateTime转换为String
String format = now.format(DateTimeFormatter.ISO_LOCAL_DATE_TIME);
System.out.println(format);
String format1 = now.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
System.out.println(format1);
// 将String转换为LocalDateTime
LocalDateTime localDateTime = LocalDateTime.parse("2023-06-19 22:56:14", DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
System.out.println(localDateTime);Instant
时间戳,内部保存了从1970年1月1日 00:00:00以来的秒和纳秒
// 获取当前时间
Instant now1 = Instant.now();
// do something
// ...
Instant now2 = Instant.now();
// 时间差
int time = now2.getNano() - now1.getNano();时间差
Duration:计算LocalTime的时间差
Period:计算LocalDate的时间差
LocalTime time1 = LocalTime.of(12, 23, 34, 45);
LocalTime time2 = LocalTime.of(23, 34, 45, 56);
// 计算time2和time1的时间差 用后面的减前面的
Duration duration = Duration.between(time2, time1);
// 将时间差转换为天数
long days = duration.toDays();
// 将时间差转换为小时
long hours = duration.toHours();
// 将时间差转换为分钟
long minutes = duration.toMinutes();
// 将时间差转换为秒
long millis = duration.toMillis();
// 将时间差转换为纳秒
long nanos = duration.toNanos();
LocalDate date1 = LocalDate.of(2023, 12, 31);
LocalDate date2 = LocalDate.of(2021, 10, 1);
// 计算date2和date1的时间差
Period period = Period.between(date1, date2);
// 相差的年数
int years = period.getYears();
// 相差的月数
int months = period.getMonths();
// 相差的天数
int days1 = period.getDays();TemporalAdjuster 时间校正器
LocalDateTime dateTime = LocalDateTime.of(2023,6,19,20,58,12);
// 获取dateTime下个月第一天的日期
LocalDateTime dateTime2 = dateTime.with(TemporalAdjusters.firstDayOfNextMonth());
System.out.println("dateTime2 = " + dateTime2);
// 也可以自己实现时间修改逻辑
LocalDateTime dateTime3 = dateTime.with((temporal -> {
LocalDateTime localDateTime = (LocalDateTime)temporal;
return localDateTime.plusMonths(1).withDayOfMonth(1);
}));
System.out.println("dateTime3 = " + dateTime3);时区
Java8 中加入了对时区的支持,LocalDate、LocalTime、LocalDateTime是不带时区的,带时区的日期时间类分别为:ZonedDate、ZonedTime、ZonedDateTime
// 获取所有时区
Set<String> zoneIds = ZoneId.getAvailableZoneIds();
// 获取标准的时间(我国属于东八区,比标准时间快8个小时)
ZonedDateTime utc = ZonedDateTime.now(Clock.systemUTC());
System.out.println("utc = " + utc);
// 计算机默认的时区 Asia/Shanghai
ZonedDateTime defultTime = ZonedDateTime.now();
System.out.println("defultTime = " + defultTime);
ZonedDateTime americaTime = ZonedDateTime.now(ZoneId.of("America/Marigot"));
System.out.println("americaTime = " + americaTime);
JDK新的日期和时间API的优势
-
新版日期时间API中,日期和时间对象是不可变,操作日期不会影响原来的值,而是生成一个新的实例
-
提供不同的两种方式,有效的区分了人和机器的操作
-
TemporalAdjuster可以更精确的操作日期,还可以自定义日期调整期
-
线程安全
重复注解
JDK 8引入了重复注解的概念,允许在同一个地方多次使用同一个注解。在JDK 8中使用@Repeatable注解定义重复注解。
@MyAnnotation("zhangsan")
@MyAnnotation("lisi")
public class AnnotationTest {
@MyAnnotation("abc")
@MyAnnotation("def")
public void test(){
}
public static void main(String[] args) throws NoSuchMethodException {
Class<AnnotationTest> clazz = AnnotationTest.class;
// 获取类上的注解
MyAnnotation[] clazzAnnotations = clazz.getDeclaredAnnotationsByType(MyAnnotation.class);
// 获取clazzAnnotations中第一个注解的值
String value = clazzAnnotations[0].value();
// 获取方法上的注解
MyAnnotation[] methodAnnotations = clazz.getMethod("test").getAnnotationsByType(MyAnnotation.class);
}
}
@Repeatable(MyAnnotations.class)
@Retention(RetentionPolicy.RUNTIME)
@interface MyAnnotation{
String value();
}
@Retention(RetentionPolicy.RUNTIME)
@interface MyAnnotations{
MyAnnotation[] value();
}类型注解
JDK 8为@Target元注解新增了两种类型: TYPE_PARAMETER , TYPE_USE 。
-
TYPE_PARAMETER :表示该注解能写在类型参数的声明语句中。 类型参数声明如: <T>
-
TYPE_USE :表示注解可以再任何用到类型的地方使用。
public class AnnotationTest2 {
/**
* <T>
* <T>
* @param t
* @param <T> 表示是个泛型方法,就像有static修饰的方法是个静态方法一样;
* 表示传入参数有泛型,<T>存在的作用,是为了保证参数中能够出现T这种数据类型。
*/
public <T> void test(T t){
}
public <@A T> void test2(T t){
}
public void test3(@B String name, @B Integer age){
}
}
// 表示该注解能写在泛型中
@Target(ElementType.TYPE_PARAMETER)
@interface A{
}
// 在任何用到类型的地方使用
@Target(ElementType.TYPE_USE)
@interface B{
}