xml文件
类似于html那种标签语言
但是用途却大不一样,xml一般用于小型数据传输(存储数据)

xml文件作用

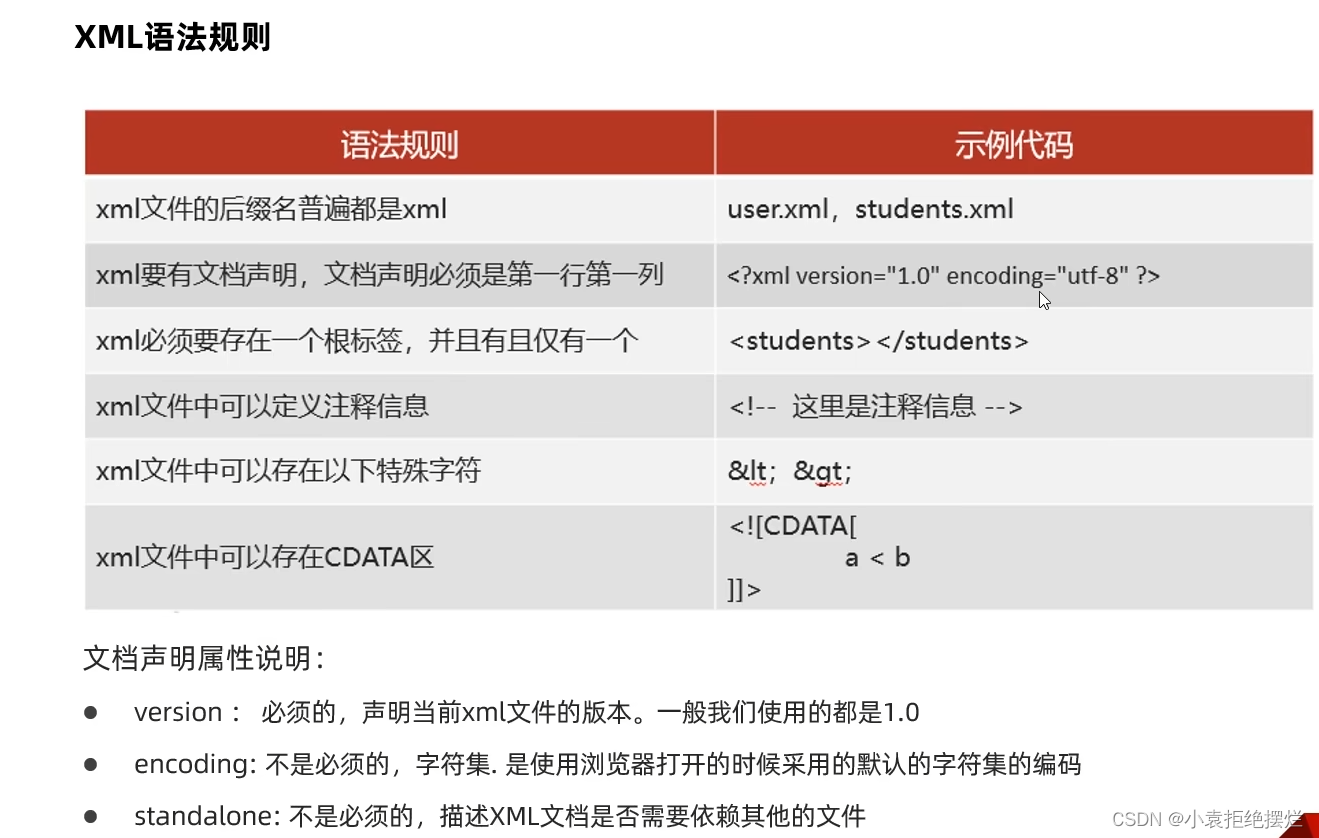
xml语法规则
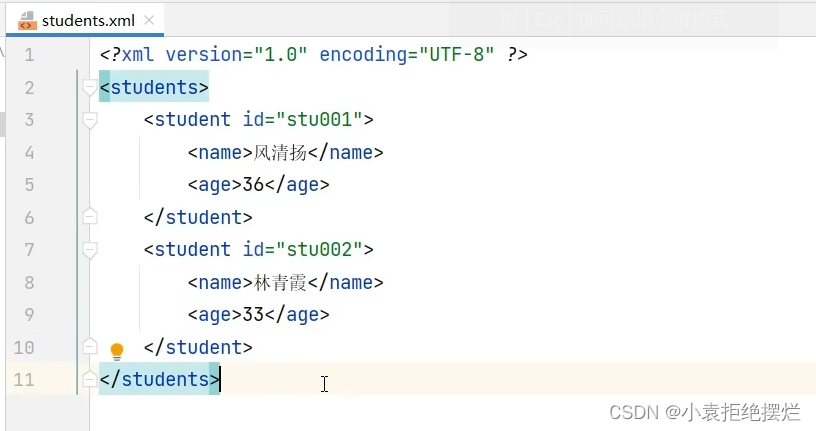
一个简单的xml文件案例
xml解析
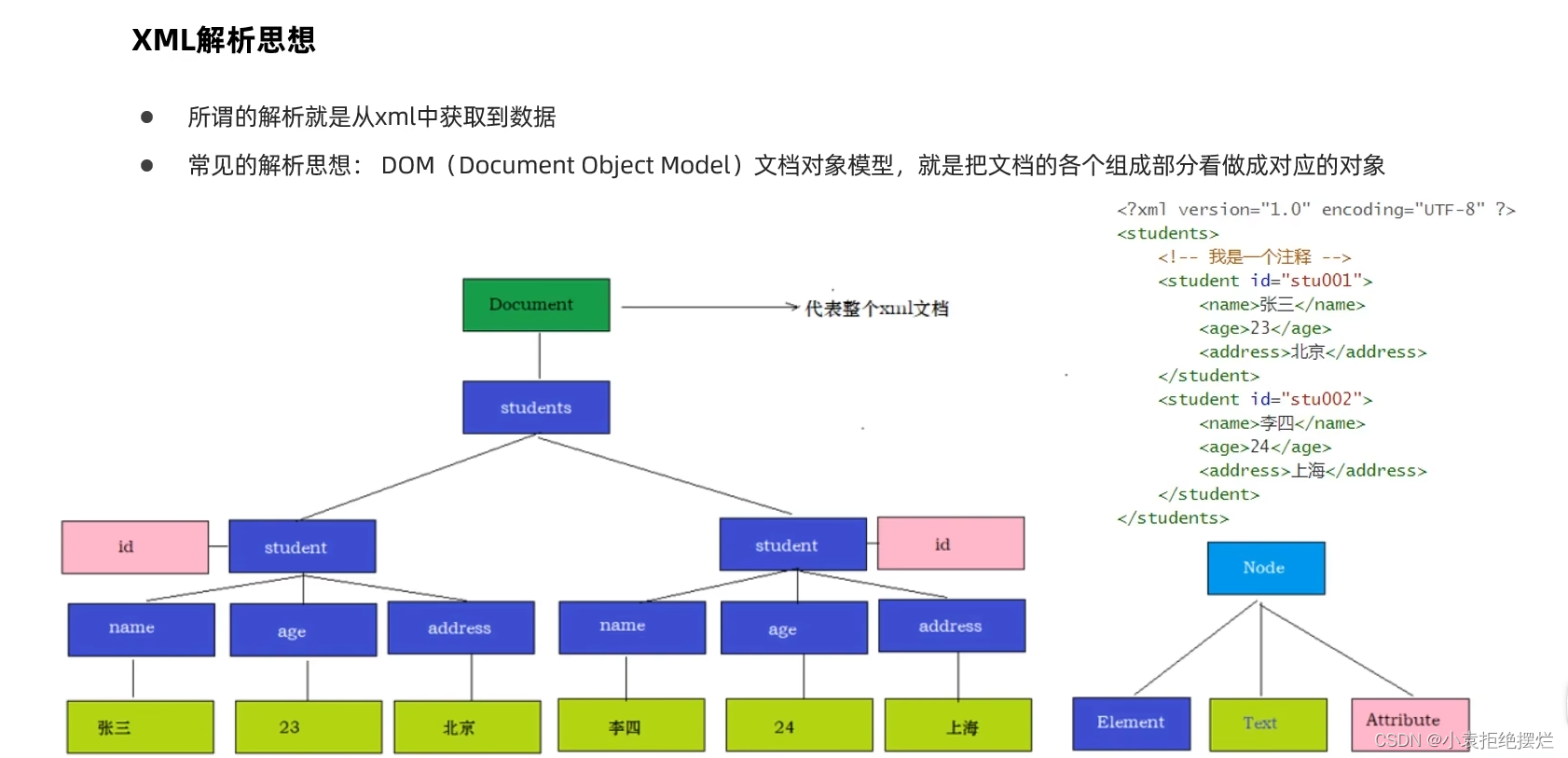
解析思想
所谓的xml解析
也就是从xml文件提取数据
解析思想:前端的文档对象模型
就对应的树形模型,每个标签,文本,属性都是一个对象,最底层标签为document(代表整个xml文档)

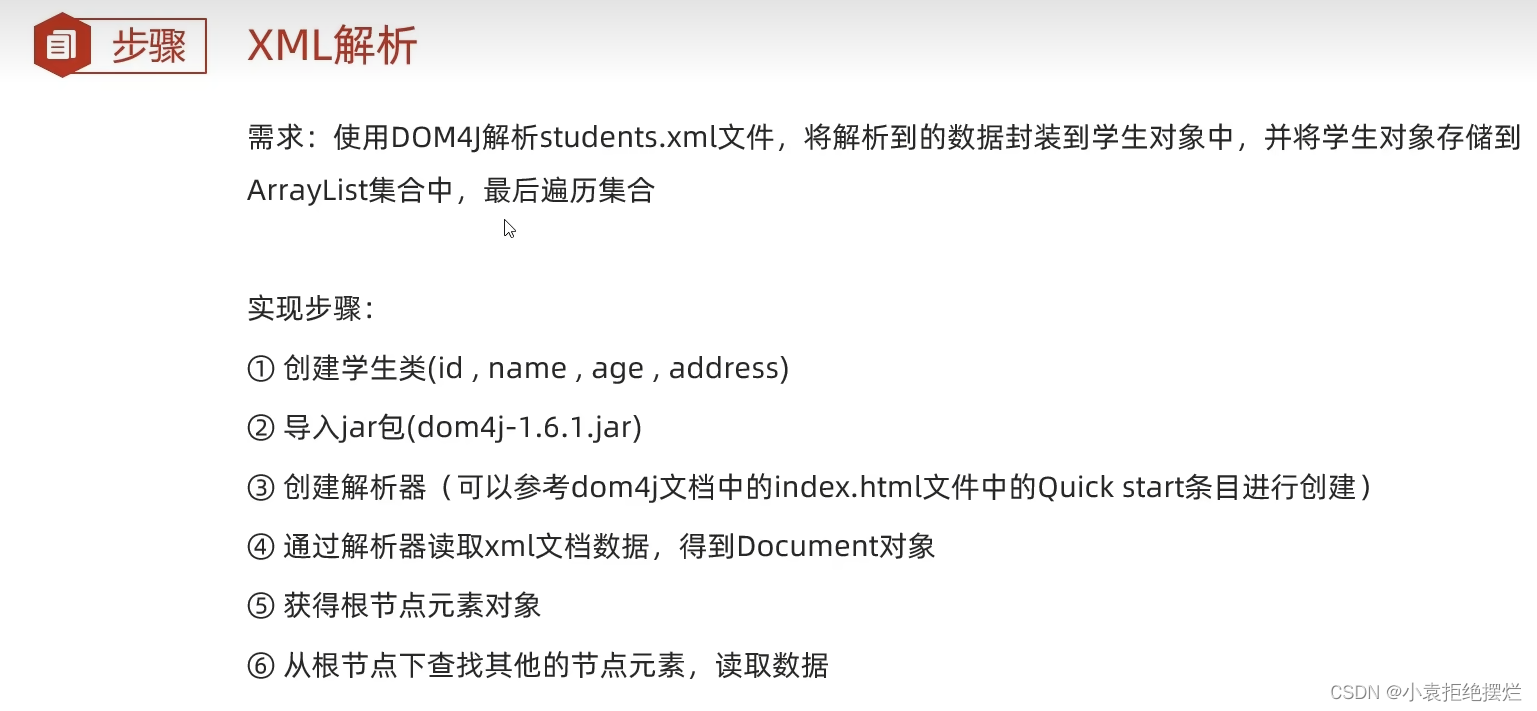
xml解析技术
会dom4j就可

dom4j解析代码实现
对应要求以及步骤
package com.itheima.utils;
import com.itheima.pojo.Emp;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.util.ArrayList;
import java.util.List;
public class xml {
//1.先创建一个对应xml的类-Emp类
//2.导入jar包(SpringBoot聚合了maven,直接用对应配置文件导入即可)
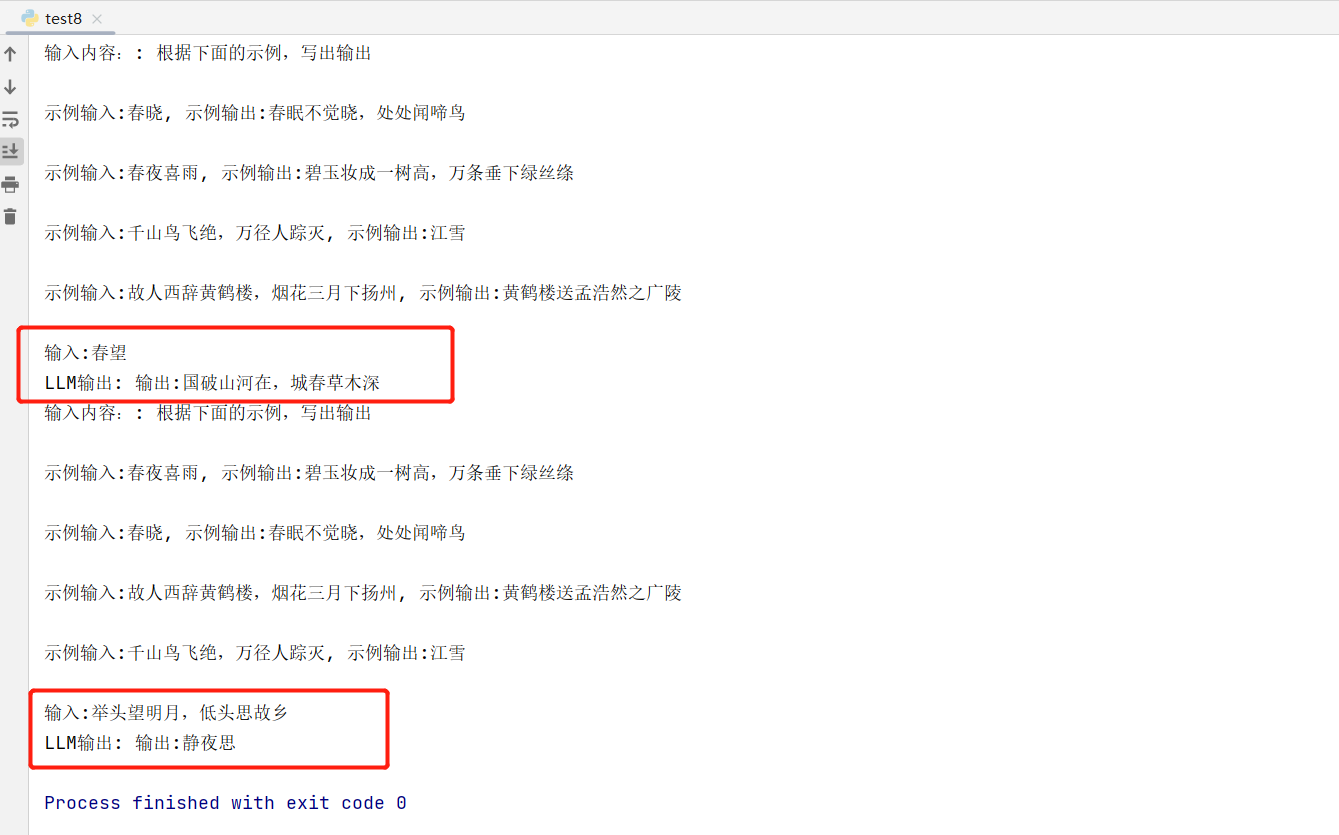
public static void main(String[] args) throws FileNotFoundException, DocumentException {
//3.创建解析器
SAXReader saxReader = new SAXReader();
//4.获取document对象
Document read = saxReader.read(new FileInputStream("/D:/Java/Java-Code/springboot-web-req-resp/target/classes/emp.xml"));
//5.获取根节点对象
Element rootElement = read.getRootElement();
//6.从根节点查找其他的节点元素
List<Element> emp = rootElement.elements("emp");
//搞一个存储Emp对象的集合
ArrayList<Emp> emps = new ArrayList<>();
//7.遍历集合得到每一个员工元素
for (Element empElement : emp) {
//8.获取元素
Element name = empElement.element("name");
Element age = empElement.element("age");
Element image = empElement.element("image");
Element gender = empElement.element("gender");
Element job = empElement.element("job");
//9.通过元素获取对应的文本(信息)
String nameText = name.getText();
String ageText = age.getText();
String imageText = image.getText();
String genderText = gender.getText();
String jobText = job.getText();
/*
可以直接这样,靠,超方便好吧
//获取 name 属性
String name = element.element("name").getText();
//获取 age 属性
String age = element.element("age").getText();
//获取 image 属性
String image = element.element("image").getText();
//获取 gender 属性
String gender = element.element("gender").getText();
//获取 job 属性
String job = element.element("job").getText();
*/
Emp emp1 = new Emp();
emp1.setName(nameText);
emp1.setAge(Integer.valueOf(ageText));
emp1.setImage(imageText);
emp1.setGender(genderText);
emp1.setJob(jobText);
emps.add(emp1);
}
for (Emp emp1 : emps) {
System.out.println(emp1);
}
}
}
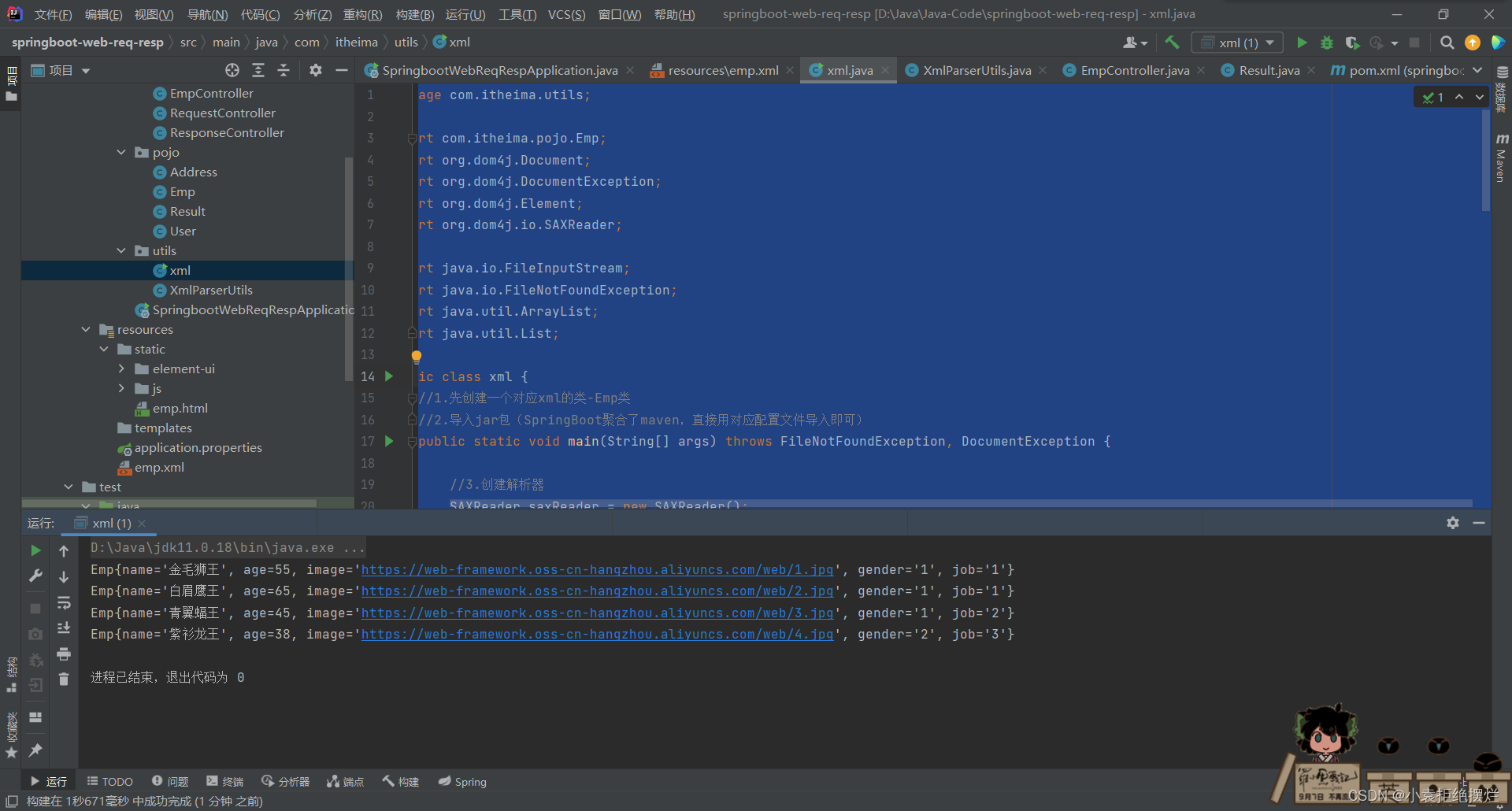
运行结果
XML的约束文档
可以看到我们的程序是要按照xml的格式去写的
我们需要一个约束来保证xml和解析同时开发
进行一个规范的处理

dtd文件
对应文件后缀名是dtd
怎么用
* 4 DTD约束开发的入门
* 想写一个约束文档,但是必须知道去约束一个XML文件。
* 用MyEclipse编写一个XML文档。
* 第一步:先编写一个XML的文档(被约束的内容)。
* src根目录下创建一个XML文件,操作步骤
* src→右击→New→XML(Basic Templates)→File name:book→next→Create xML file from an XML templates→next→“${encoding}”拿到的是workspace的编码集→finish
* Design:设计模式
* Source:源码
<?xml version="1.0" encoding="UTF-8"> MyEclipse已经把乱码问题解决掉了,会自动修改workspace的编码
<!DOCTYPE 书架 SYSTEM "book.dtd">
<书架> 根节点,只能有一个
<书> 作为根节点的一个子节点,有一些属性
<书名>陆小凤传奇</书名>
<作者>古龙</作者>
<售价>34.5元</售价>
<简介>这书不错啊</简介>
</书>
</书架>
* 第二步:编写DTD的约束文档(约束)
* 第三步:创建一个DTD文档
* 在src根目录下创建DTD文档,操作步骤:
* src→右击→others→dtd(查找:MyEclipse→XML→DTD)→next→book. dtd→next→finish
* 3.1 定义元素
* 语法:<!ELEMENT 元素名称 元素类型 > XML文档中可以出现的元素
* 3.2 判断哪些是复杂的元素,哪些是简单的元素
* 3.3 如果是简单元素(只包含文本内容)
* 元素类型写法:(#PCDATA) 可解析的字符数据,就是字符串
* 3.4 如果是复杂元素(下边包含子节点)
* 元素类型写法:(子节点1,子节点2,...) ,代表是有顺序的
* 编写book.dtd内容
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT 书架 (书)>
<!ELEMENT 书 (书名,作者,售价,简介)> 只能按照这样的顺序出现这4个,且不能重复
<!ELEMENT 书名 (#PCDATA)> 书名之间只能出现字符串,不能出现其它内容
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
<!ELEMENT 简介 (#PCDATA)>
* 第四步:在XML中引入DTD的约束文件。
* 将DTD与XML文档关联的三种方式,详见ppt。
* 4.1 引入本地的DTD的约束文件
* 写法:<!DOCTYPE 根节点 SYSTEM "DTD文件的地址" >
* 约束之后,出现的顺序、个数都完全的规定好了
*
* 5 DTD与XML结合在一起
* DTD与XML文档关联的三种方式
* 方式一:使用内部DTD
* 解释:直接写在XML文件的内部,开始部分。类似于CSS
* 语法:<!DOCTYPE 根节点 [DTD的代码]>
* 举例
<?XML version="1.0" encoding="UTF-8"?>
<!DOCTYPE 数据 [
<!ELEMENT 书架 (书)>
<!ELEMENT 书 (书名,作者,售价,简介)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
<!ELEMENT 简介 (#PCDATA)>
]>
<书架>
<书>
<书名>陆小凤传奇</书名>
<作者>古龙</作者>
<售价>34.5元</售价>
<简介>这书不错啊</简介>
</书>
</书架>
* 方式二:定义外部的DTD文件,引入外部的本地的DTD文件
* 语法:<!DOCTYPE 根节点 SYSTEM "DTD文件的地址">
* 方式三:引入外部的DTD文件,引入的是网络上的DTD文件
* 语法:<!DOCTYPE 根节点 PUBLIC "DTD文件的名称" "DTD文件的地址">
* Structs框架的配置文件就是采用DTD方式进行约束的,并且采用方式三引入的网络DTD文件。
百度搜索 Structs2配置文件
* 说明
我们自己写的话,前2种是主要的,因为网络咱们也没有。学到框架的话,有可能引入的是网络的DTD,例如Struts2,引入的就是网络的DTD的文件。
dtd约束语法
* 6 DTD的语法
* 《W3Cchool.chm》→单击导航栏XML→单击左侧DTD→...
* 元素定义
* 写法:<!ELEMENT 元素名称 元素类型 >
* 元素类型:
* (#PCDATA) :可解析的字符数据(字符串)
* (子节点1,子节点2,...) :当前的元素是复杂的元素,里面包含子节点1,子节点2,...
* EMPTY :空(没有标签主体)
* ANY :任意类型
* () :用来给元素分组
* 子节点之间的关系
* 子节点与子节点出现顺序的关系
* ,:代表子节点按着顺序出现的
* |:子节点只能出现一个
* 子节点出现的数量的关系
* +:子节点可以出现1次或多次
* *:子节点可以出现0次或多次(任意次)
* ?:子节点可以出现0次或1次
* 属性定义
* 写法1:<!ATTLIST 元素名称 属性名称 属性类型 约束 >
* 扩展 :<!ATTLIST 元素名称
属性名 属性类型 约束
属性名 属性类型 约束
......
>
* 举例
<?XML version="1.0" encoding="UTF-8"?>
<!DOCTYPE 数据 [
<!ELEMENT 书架 (书)>
<!ELEMENT 书 (书名,作者,售价,简介)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
<!ELEMENT 简介 (#PCDATA)>
<!ATTLIST 书
出版社 CDATA #REQUIRED
出版日期(2020-02-19|2020-02-20|2020-02-21) #REQUIRED
ISBN ID #REQUIRED
副主编 CDATA #IMPLIED //可选的
>
]>
<书架>
<书 ISBN="b1" 出版社="xxx出版社" 出版日期="2020-02-19">
<书名>陆小凤传奇</书名>
<作者>古龙</作者>
<售价>34.5元</售价>
<简介>这书不错啊</简介>
</书>
<书 ISBN="b2" 出版社="清华大学出版社" 出版日期="2020-02-20">
<书名>JavaEE高级开发</书名>
<作者>班长</作者>
<售价>99.5元</售价>
<简介>这书非常不错</简介>
</书>
</书架>
* 属性类型
* CDATA 字符数据(字符串)
* ENUMERATED 枚举 :只能从枚举列表中任选其一
* 写法:(值1|值2|值3)
* 举例:(鸡肉|牛肉|羊肉|牛肉)
* DTD中没有此关键字
* ID 表示属性的唯一取值
* 不能重复
* 不能只写数字
* 属性约束
* #REQUIRED 属性必须要出现的
* #IMPLIED 属性的出现是可选的
* #FIXED 固定值
* 写法:#FIXED "固定值"
* 默认值 提供默认值
schema文件
对应的文件后缀名为xsd
这种约束比较复杂可以自己去上网查一下